异数OS-织梦师-PBFT(六) 走出区块链,加速破解PBFT
.
异数OS-织梦师-PBFT(六) 走出区块链,加速破解PBFT 拜占庭
本文来自异数OS社区
github: https://github.com/yds086/HereticOS
异数OS社区QQ群: 652455784
异数OS-织梦师(消息中间件 ,区块链,游戏开发方向)群: 476260389
异数OS-织梦师-Xnign(Nginx方向)群: 859548384
关于PBFT
PBFT的应用环境非常广泛,是各类分布式平台的基础技术和必要组件,用于提高分布式系统的安全与可用性,因此也是区块链领域的最有前途的技术之一,他解决了POW之类算法先天TPS过低的问题,实现安全的分布式交易加速,但是PBFT在传统操作系统下性能表现并不佳,存在性能天花板瓶颈,这限制了PBFT在主流分布式系统中的应用,在中心化不强烈要求安全的交易场合,PBFT只能躺在教科书中供人参考膜拜,而不能走进实际项目,所以当异数OS可以提供稳定服务后,也开始着手整理PBFT中间件的问题,使之能够落地实现,下文主要目标则是分析PBFT的性能瓶颈,以及攻破与落地方案。
PBFT原理与性能分析

从上图,我们知道PBFT的请求流程主要经历request,pre-prepare,prepare,commit,reply这5个阶段, 其中prepare,commit这两个阶段是PBFT功能实现的本质,他通过两个阶段的广播使得分布式系统中所有节点在一次请求中达到共识,这两个阶段的代价不菲,那么我们来计算下PBFT的性能开销。
PBFT TPS性能分析
PBFT约定系统中将军节点数量n=3f+1,prepare,commit阶段每个将军需要向n-1数量的的节点广播并得到2f+1数量节点的确认后才可以进入下一个阶段,那么系统TPS就由最后完成的f个将军节点决定,大概三分之一。
假设每个将军节点完成1次请求的IO代价为a,整个系统的IO代价为t,将军所在系统的IO性能为iops,系统最终性能为tps
则有
t=n*a
a=请求确认IO数量+广播推送IO数量+pre-prepare IO数量 + reply IO数量
tps=iops/a
===》
请求确认IO数量=2*(n-1) //两个阶段,每个阶段n-1次确认
广播推送IO数量=2*(n-1) //两个阶段,每个阶段n-1次确认
则
a=2*(n-1)+2*(n-1)+1+1
t=n*(4n-2)
最终有:
a=4n-2
t=4n^2-2n
tps=iops/(4n-2)
PBFT 潜伏期推测
潜伏会导致压力无法给满,降低系统使用效率,PBFT在prepare,commit任务阶段所有节点会依次完成,每个节点都需要等待2f+1个节点的确认,因此最快的prepare阶段的 f个节点需要等待其次快的f个节点广播完成,之后最快的f个节点进入commit阶段,而其次快的f个节点则需要等待最慢的f个节点广播prepare后才能进入commit,因此总是有三分之一的节点需要等待三分之一的节点,因此PBFT的最大系统IO利用率仅三分之一,这在将军数量较多的情况下,会非常明显。
PBFT的应用性能瓶颈
由上一节内容我们得知PBFT tps=iops/(4n-2),由于潜伏期影响,因此预计tps=iops/(3*(4n-2)),通过这项公式我们得知,PBFT的性能天花板有三个因素,1个是将军节点数量,1个是操作系统IOPS性能,1个是潜伏期。
举个例子典型的操作系统比如linux ,最大iops是12w,1个4将军的PBFT则最终tps=3000,当然这个tps相对其他一些分布式算法已经很高了,因此也有人说PBFT的性能很高_
PBFT 安全分析
PBFT的目标是去中心来实现安全保障,其设计允许三分之一节点作恶,因此本质上讲,PBFT安全不安全主要看允许的作恶节点的数量,POW算法需要二分之一节点在算力上被攻破,PBFT看起来更少,因此你家发行的虚拟币安全不安全就看你家有多少PBFT将军节点提供给黑客去攻破,如果黑客提供的PBFT节点数量超过三分之一,将可以拒绝交易的确认,超过三分之二则可以修改交易的内容。
PBFT的区块链主要利用公网,由上述公式t=4n^2-2n 我们得知为了安全,我么不可能无限制的增加将军节点数,将军数每提高1倍,性能则下降到之前的1/4,要保持TPS性能,则需要提升操作系统IO性能4倍,而linux操作系统自从百兆网卡诞生后,IO性能已经有20年没有提升过上限了,某些区块链产品吹牛逼说几万节点全连接,那么上面这个公式看看假设1W节点,那么每个请求则需要全网1亿次广播,1亿次消息确认,公网出口带宽100G,消息转发性能100M,显然这点带宽1s还不够提供1次交易的,双十一几千万TPS怕是要排队好几十年了。
基于异数OS的 PBFT破解思路
天下功夫维快不破,不破不立,破而后立…
上述分析我们得知,PBFT要安全,要TPS,最终途径唯有性能。在linux平台增加将军节点来提高安全或者降低将军节点数来提高性能都是本末倒置的做法,你要攻破PBFT,你就要有超过全网三分之一的IO性能,你要安全的话,公网性能怕是不够给你提供安全保障,考虑到这些矛盾,异数OS则给出了如下几个破解思路。
1.提供100倍以上Linux将军节点的IO性能
100倍IO性能的单节点性能将可以带来10倍的将军数量提升,这将大大提升安全冗余。
2.利用异数OS 虚拟容器交换机技术卸载公网压力
公网的带宽和性能显然是不足以让PBFT安全落地的,因此我们需要考虑将PBFT将军流量本地化(类似CDN),本地化将军需要两个前提,1是提供足够多的将军,通过上图我们得知,流量与将军节点所占数量成正比。那么你需要卸载多少公网流量则相应的就要提供多少将军。2是你的本地交换机网络容量要大于公网,100G公网流量以及100M TCP消息转发确认需要的传统linux服务器大概1000台,那么这个规模大概相当于1台异数OS的容器化节点(AMD epyc 的异数OS IO性能大概500M 4Tbps),那么我们做上10台异数OS容器化集群,大概IO算力就相当于整个阿里云了。
异数OS PBFT系统设计
酝酿待续中。
异数OS PBFT系统压力测试
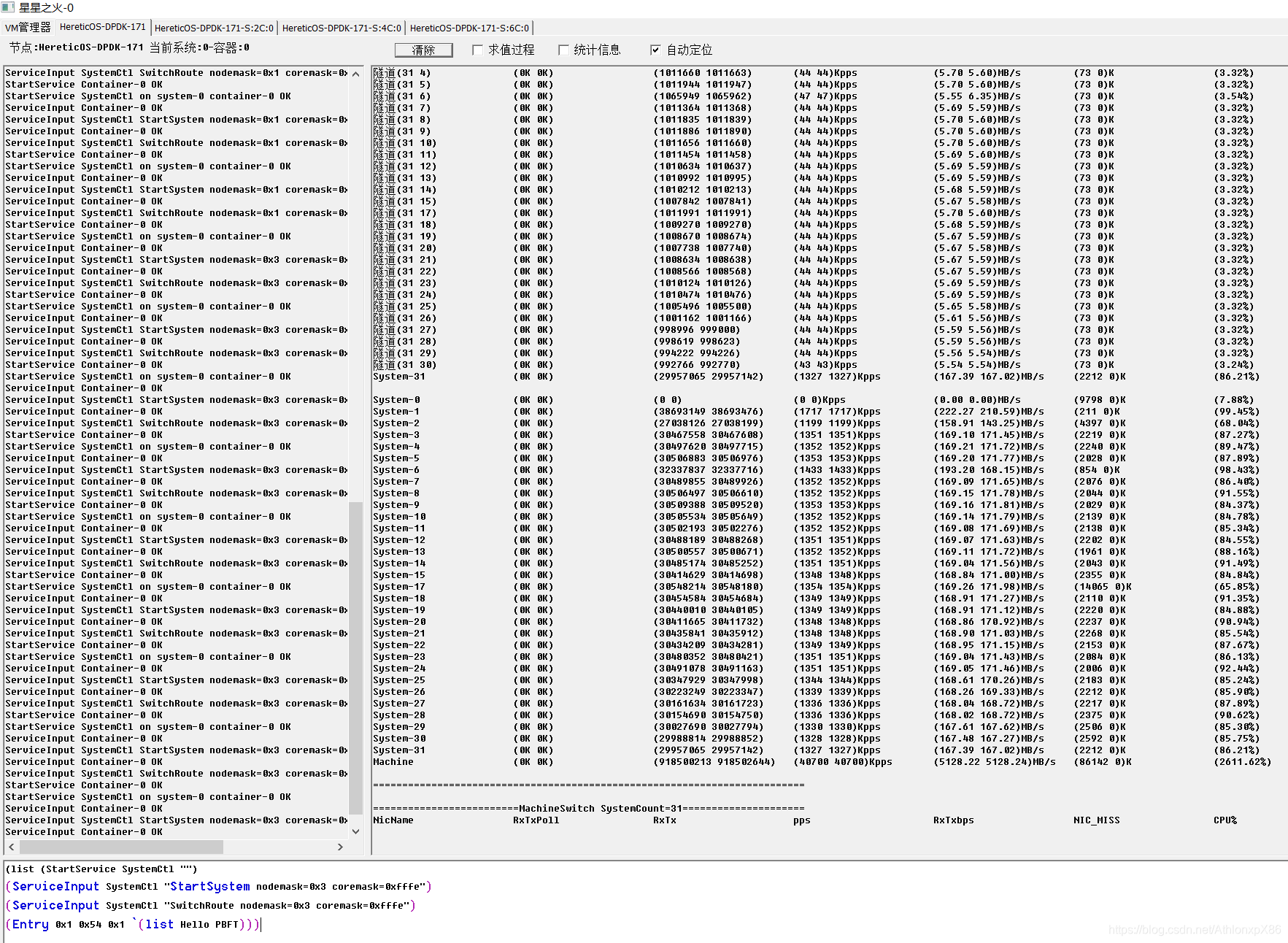
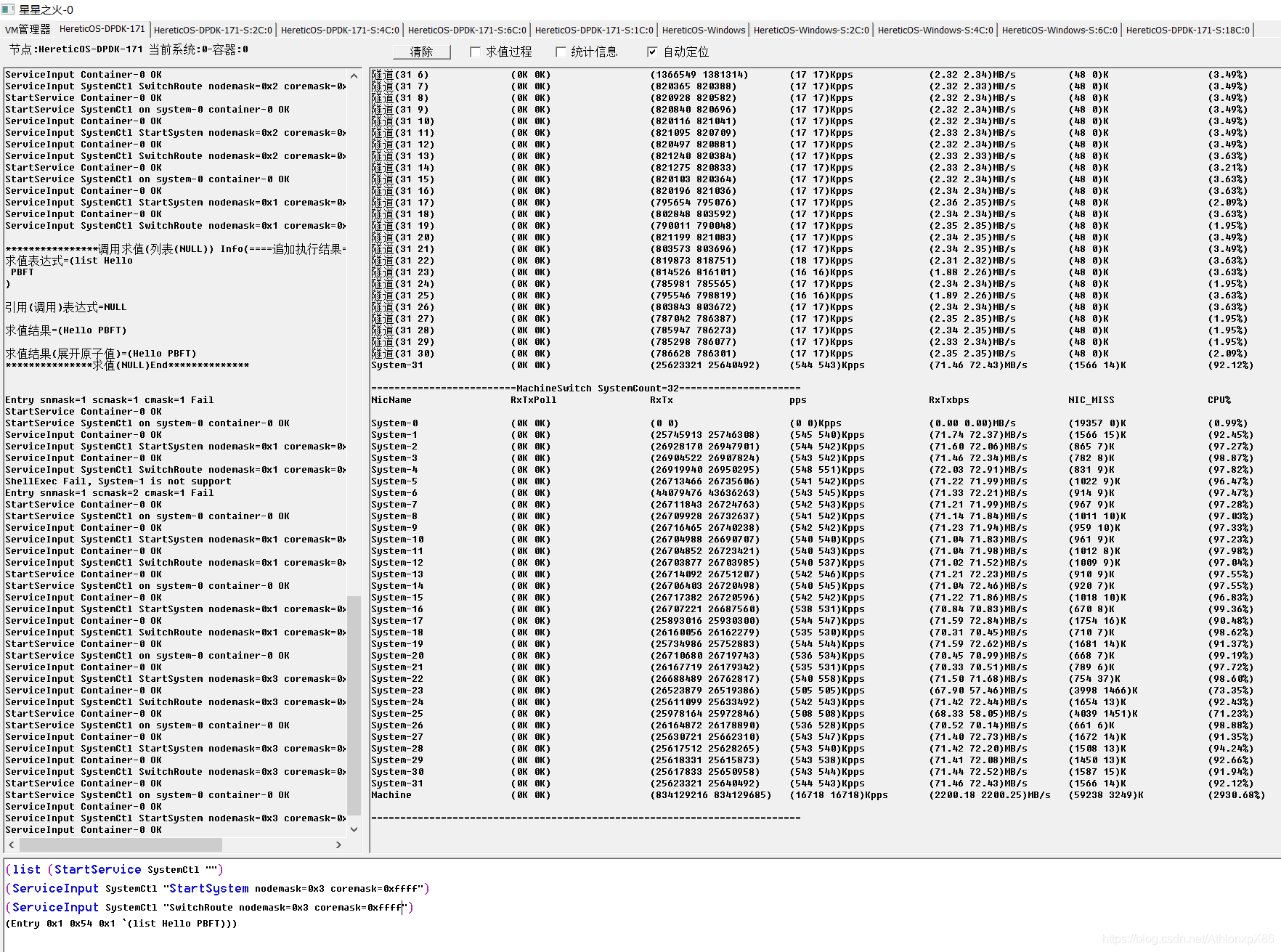
测试环境 异数OS 2670 v1*2 +异数OS虚拟容器交换机环境,没有使用物理网卡,用的异数OS虚拟容器交换机,因为目前还没有物理网卡能提供这样大的消息转发性能,关于异数OS虚拟容器交换机会在以后博客中详细介绍。
为了降低带宽影响,PBFT 消息尺寸我们选择100字节左右(总带宽的十分之一左右),这样能更反应系统的IO吞吐性能,我们在容器集群上做了4将军 31将军 61将军 4096将军节点的性能测试。每种场景代表不同的需求模式,4节点我们更注重的是TPS性能,31将军则压满单个2670节点,但显然由于PBFT潜伏期问题,CPU并不能吃满,因此为了吃满CPU,我们又压了61将军节点,让cpu利用率得以提高,最后为了挑战下PBFT的破解性能,我们模拟了4096将军节点,这个数量非常吃系统资源,他会创建3200W个TCP链接(2*4095*4095),同时对应1.2亿个异数OS线程用于4096个将军府模拟(1个将军府=1个将军+4096个通讯战士)。
4将军节点
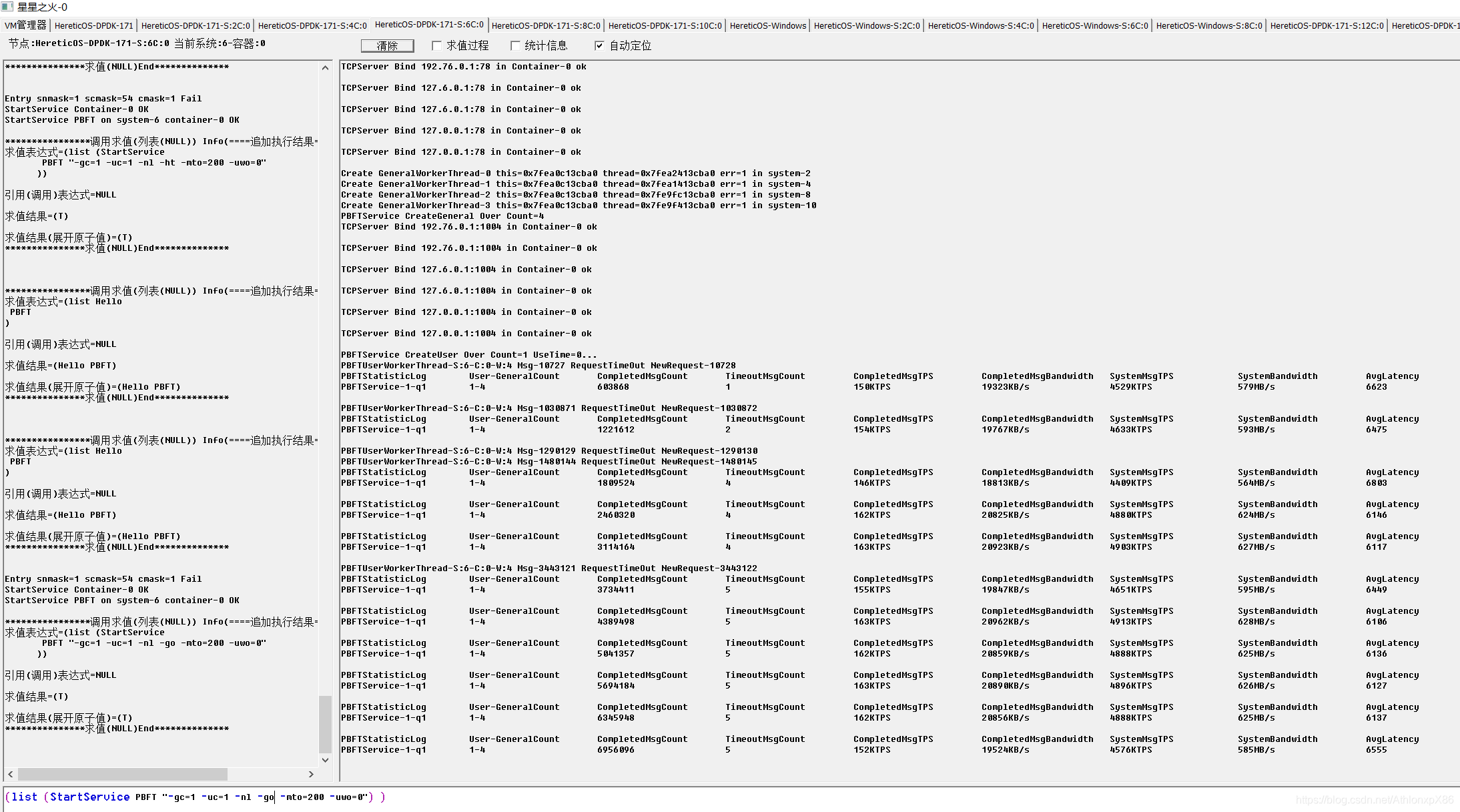
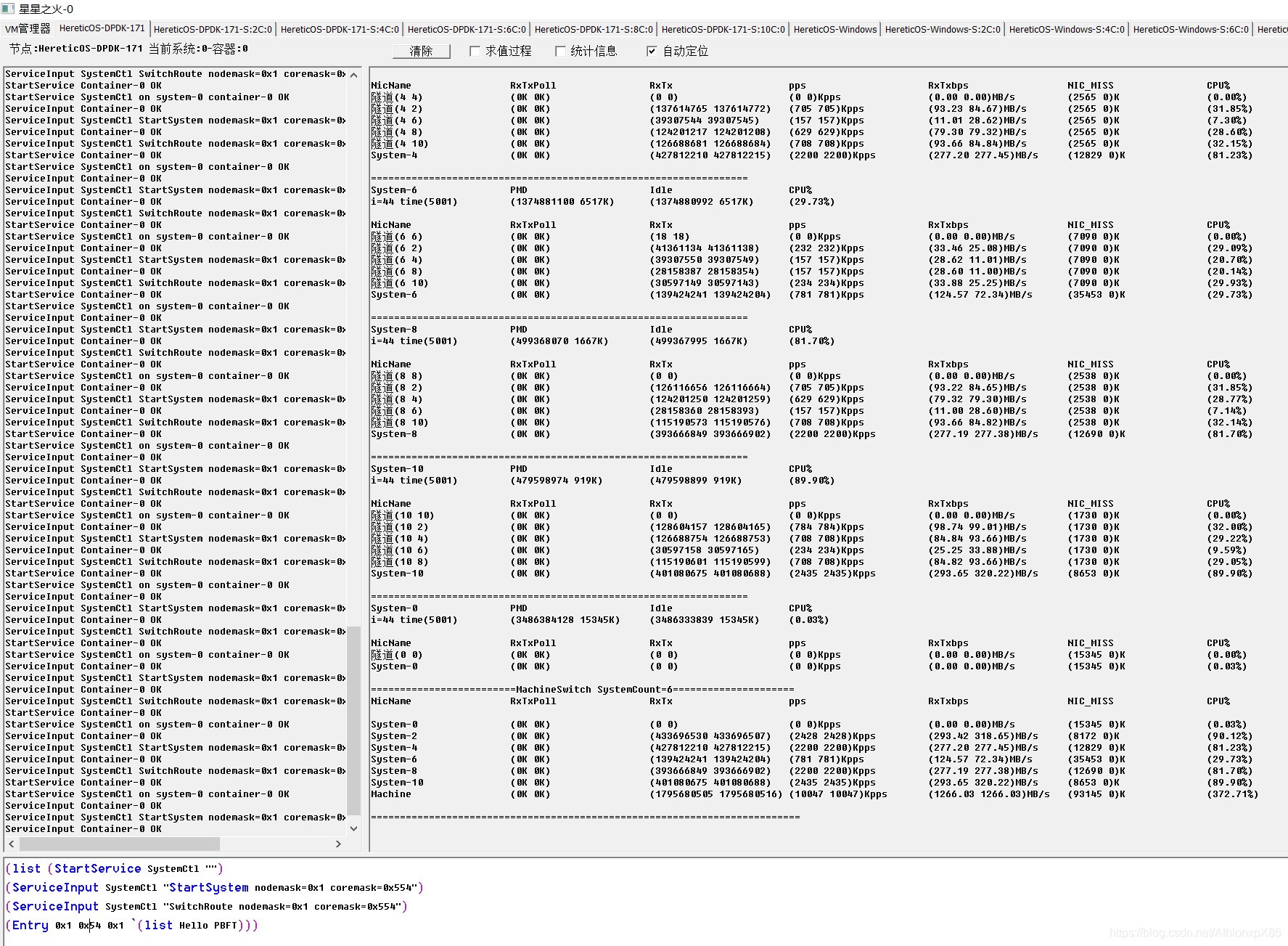
31将军节点单路
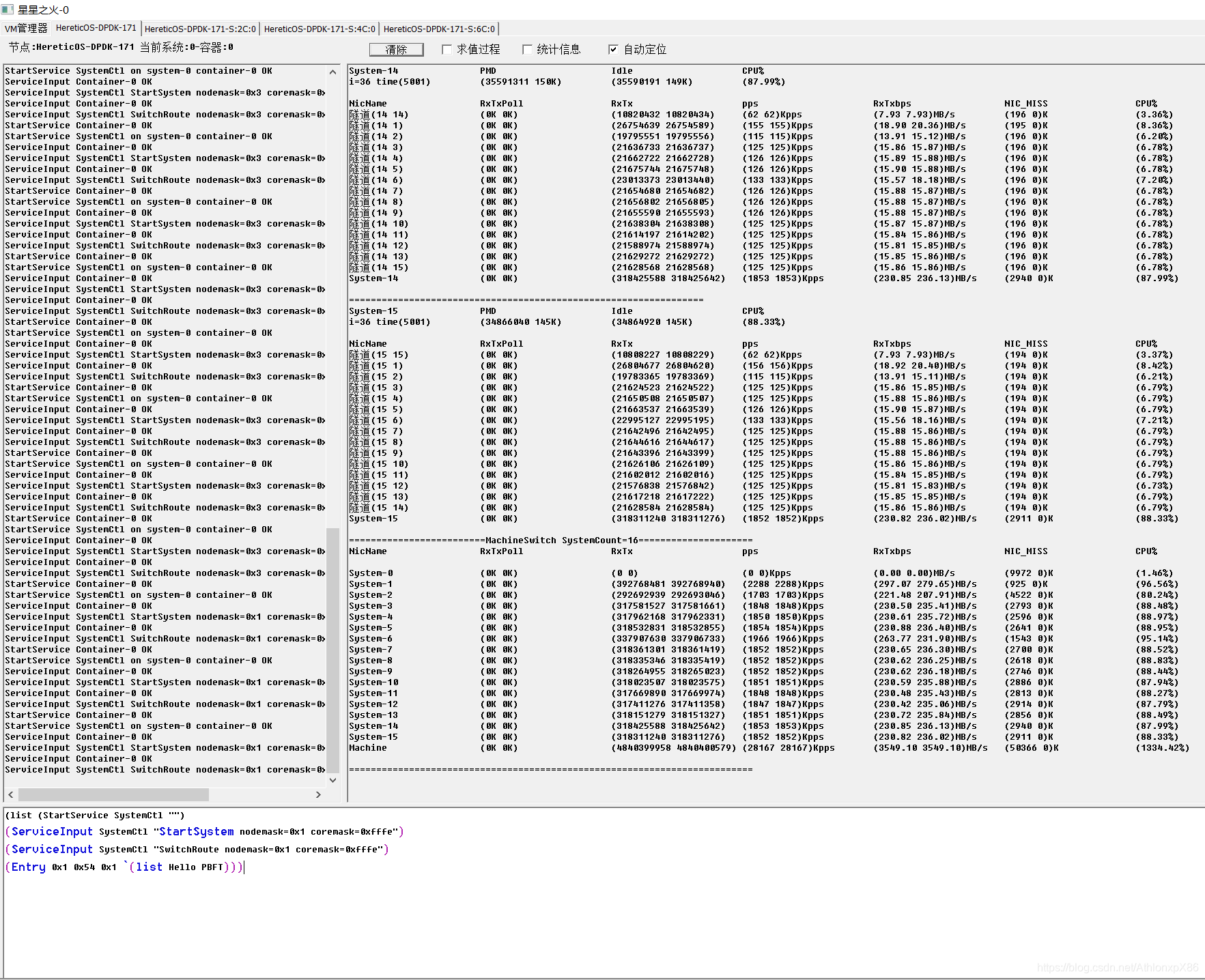
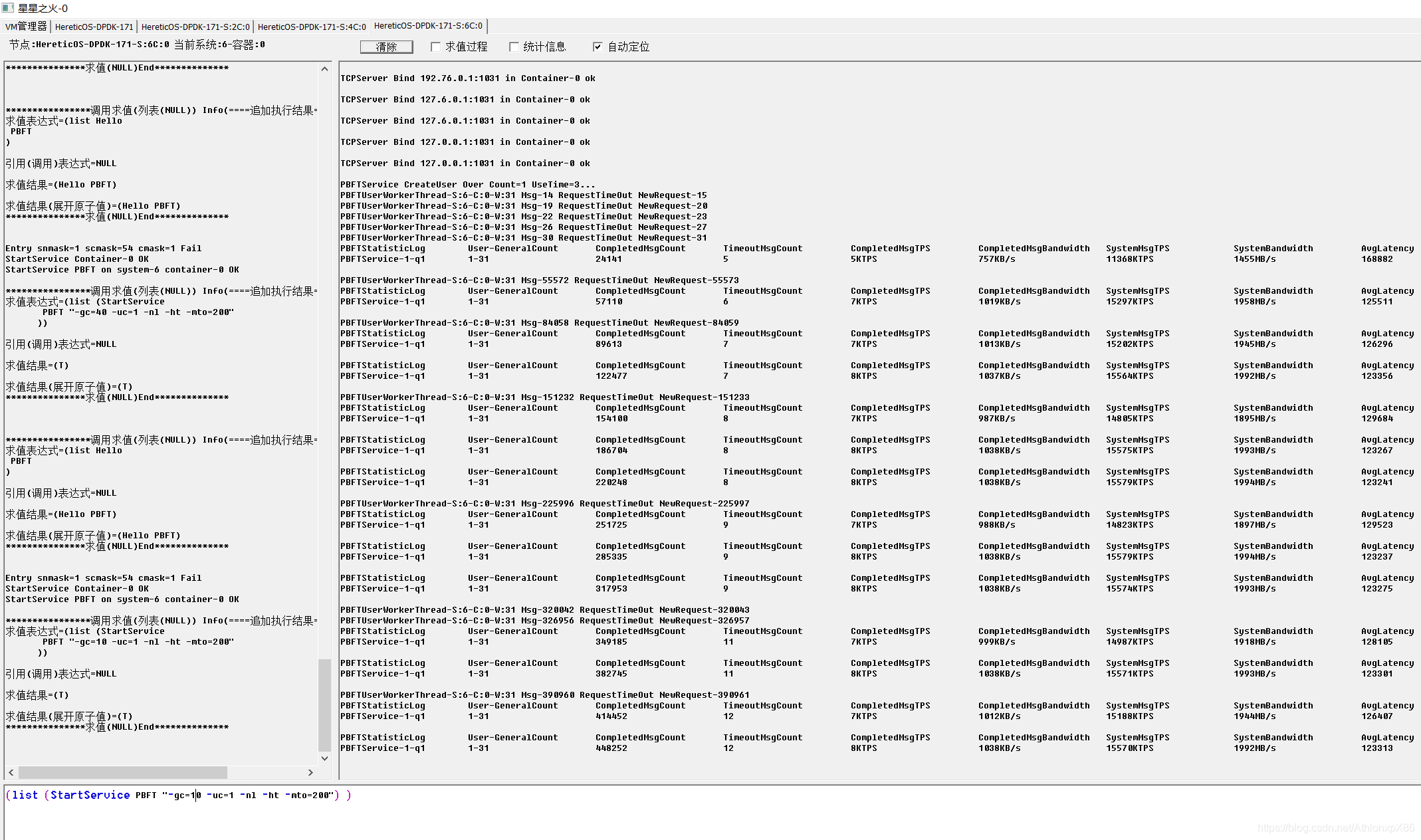
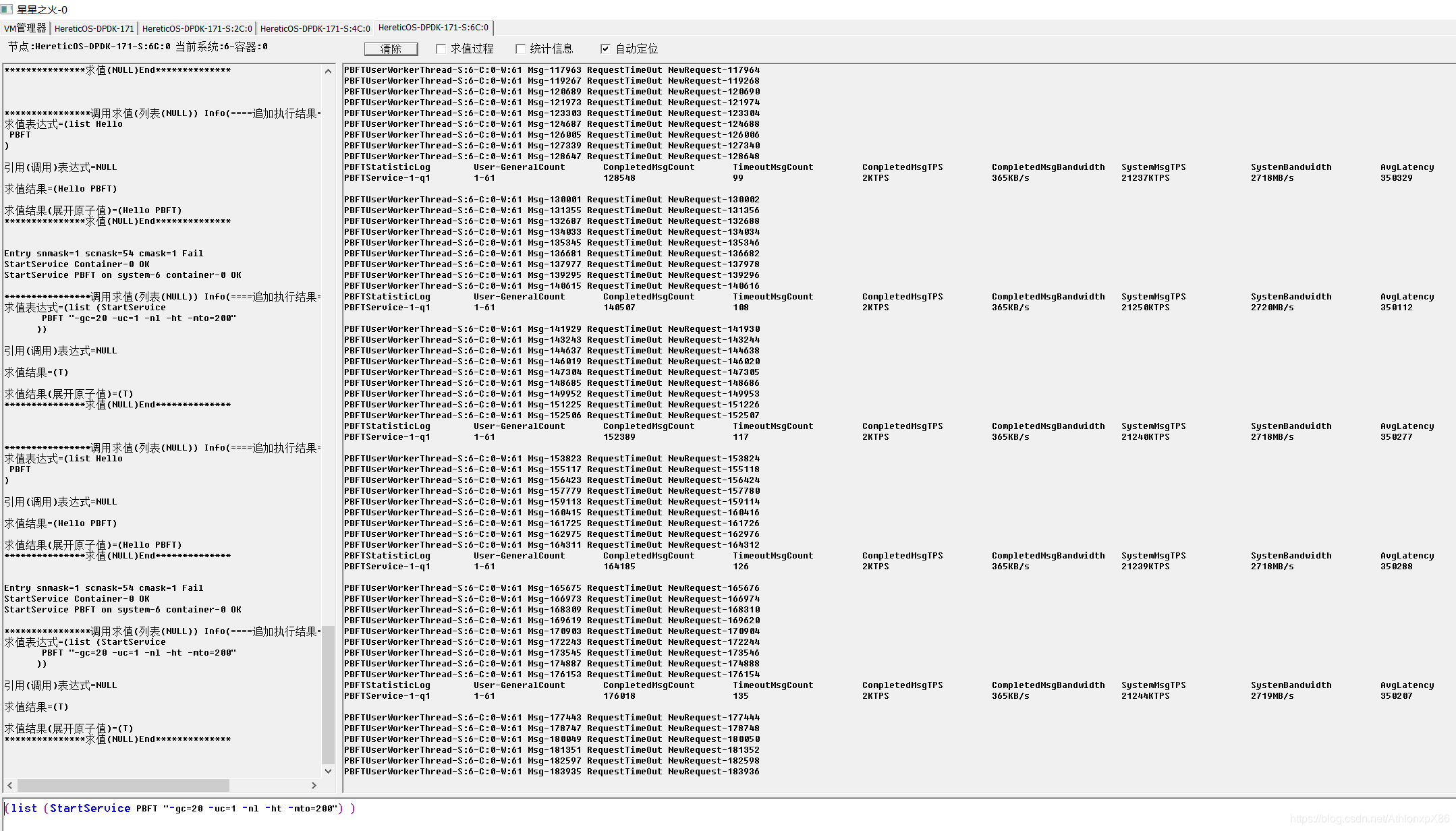
61将军节点双路
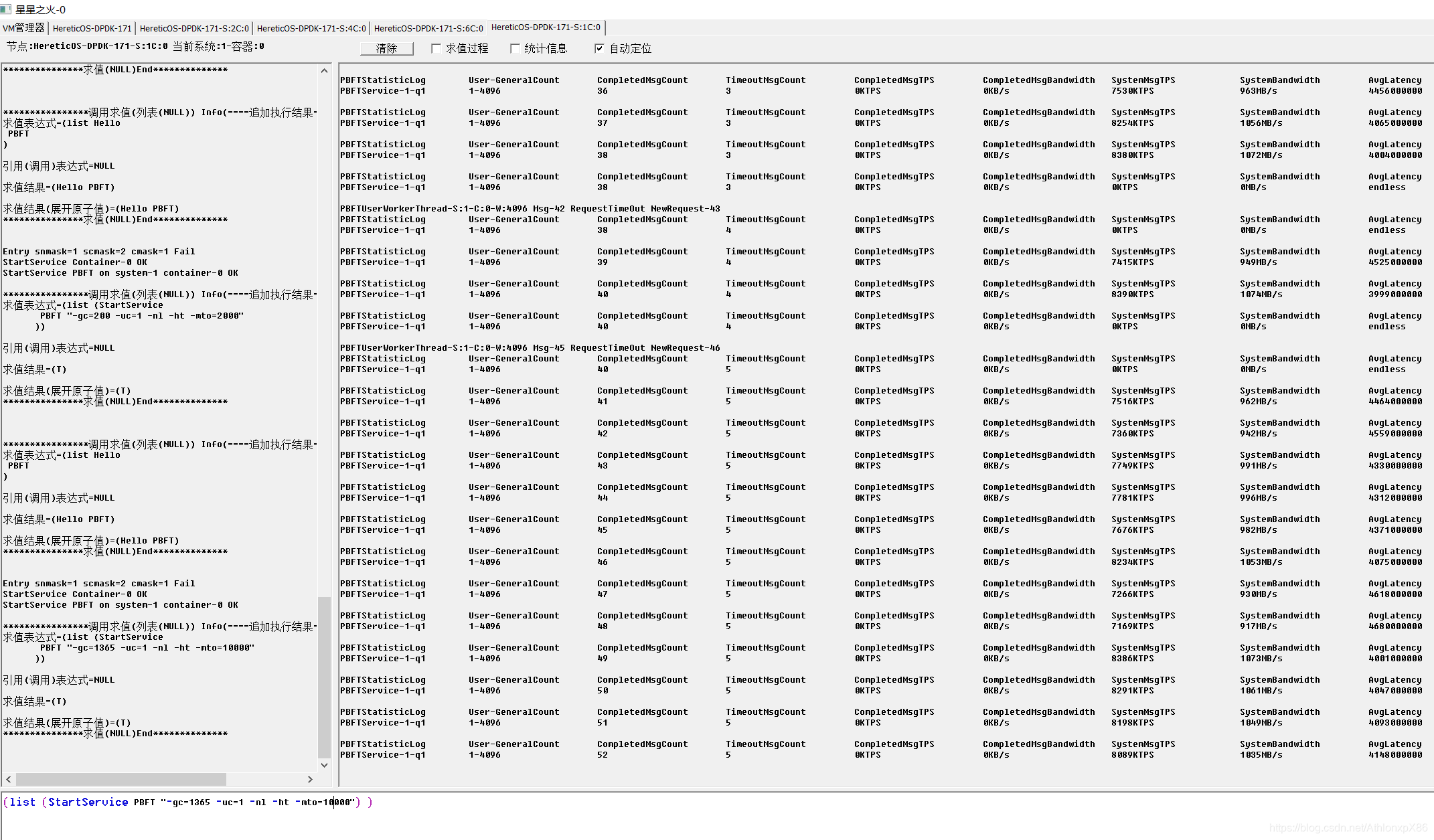
4096将军节点 双路
压测总结
| 测试特性 | 4将军 | 31将军 | 61将军 | 4096将军 | linux 4将军理论性能 | Hyperledger Fabric 4将军实际性能 |
|---|---|---|---|---|---|---|
| 应用请求TPS | 160K TPS | 8K TPS | 2K TPS | 0.25 TPS | 3000 TPS | 400TPS |
| 总消息广播确认TPS | 2*4.5M | 2*15M | 2*21M | 2*800W | 2*6W | ? |
| IOPS | 10M*2 | 28M*2 | 40M*2 | 17M*2 | 12W*2 | ? |
| 容器交换机包转发性能 | 10M | 28M | 40M | 17M | 12W | ? |
4将军时我们发现每将军CPU并不能占满CPU,因此我们在31节点 61节点将军则是中开启CPU HT技术,并在每个CPU上分配两个将军节点,我们发现PBFT在HT环境下可以成倍提升消息吞吐量,降低PBFT CPU潜伏期, 由于架构设计约束,我们以将军府为单位分配给异数OS云容器,因此4将军并不能利用多核优势,因此4将军的情况后面我们可能会考虑分布式将将军府中每一个士兵通讯员都分派到不同系统云容器中去,在4096将军测试中我们发现系统IO性能下降60%,系统需要更多的内存资源 CPU资源来维护将军府的TCP超时错误,因此未来可以考虑使用异数OS RPC代理技术让在同一个系统中需要链接相同目标将军的将军共享TCP链接,以此降低海量TCP链接的资源消耗。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号