国产CPU 申威1621 异数OS基础组件理论性能测试报告
国产CPU 申威1621 异数OS基础组件理论性能测试报告
文章目录
前言
一直以来,异数OS都希望能够支援国产CPU生态的建设,这次机缘来到来到成都申威,看到了传说中的申威CPU,并做了异数OS基础组件的理论测试,在此感谢成都申威提供的SW 1621测试环境,期望国产CPU能走上市场化发展的正轨,进入民用领域,从此摆脱舆论束缚,让市场锤炼出民族的英雄与战士。
测试平台
CPU SW1621 4 node 每node 4cpu,主频1.6GHz,8通道64G DDR3。
测试项目
- SW1621 异数OS 容器虚拟交换机模拟性能测试
- SW1621 异数OS TCP协议栈理论性能模拟测试
SW1621 异数OS 容器虚拟交换机模拟性能测试
A->B->C->A 三节点回环转发
异数OS虚拟交换机模块 三核 跨核以及本地模式
本地模式中ABC三个节点都在本地CPU核完成回环三个操作由本地核完成。
跨核模式中ABC三个节点分别分配到3个不同cpu核完成。
本地转发性能主要影响异数OS集群本地系统内容器间网络交换性能。
跨核模式主要影响异数OS集群本地系统之间容器间网络交换性能。
分数与意义说明
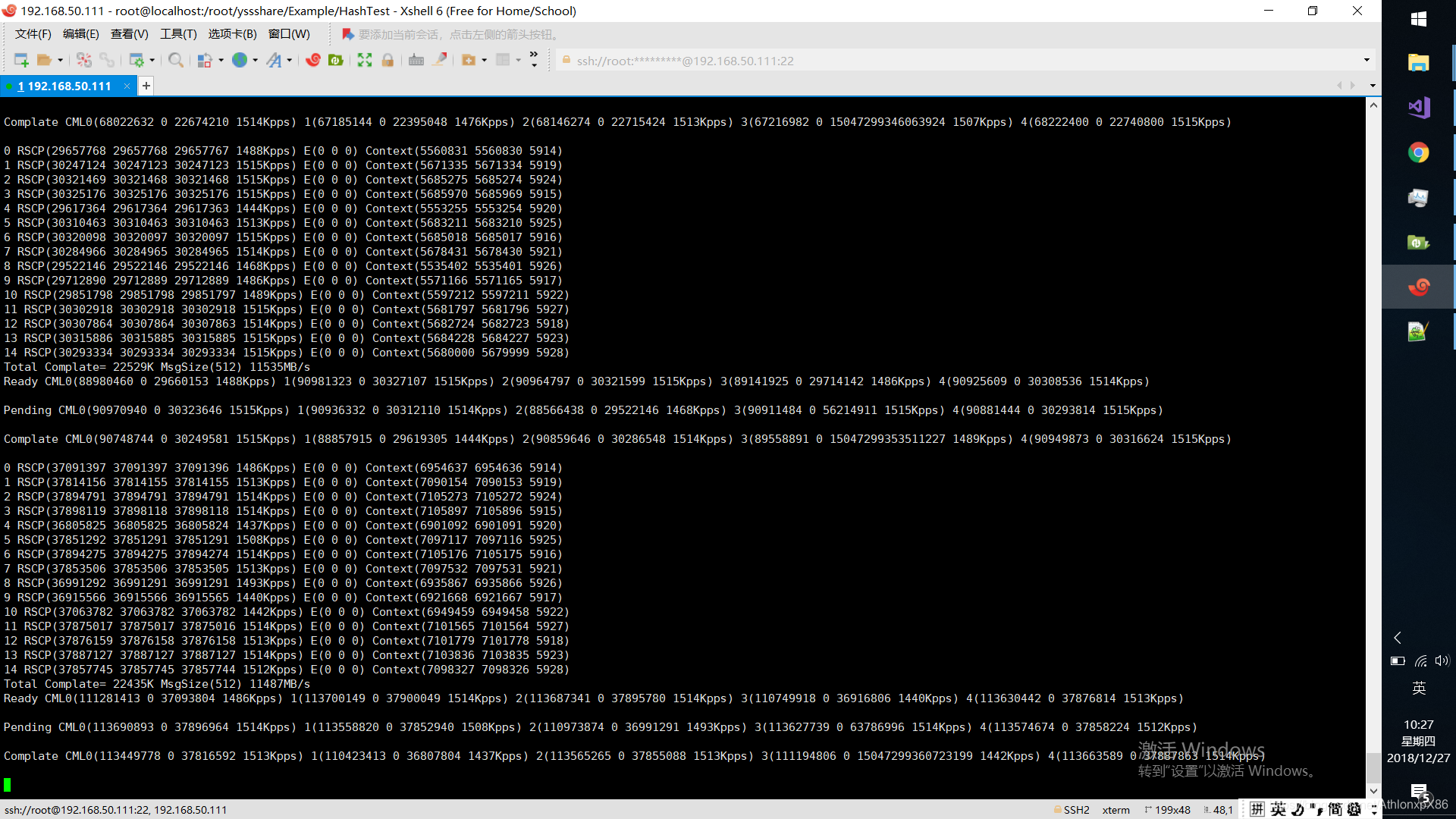
SW1621本地转发 1400字节转发的分数是600kpps*15*3 600kpps是指单位时间内完成一次A->B->C->A回环操作的次数,*15是指15CPU核实例,*3指一次回环转发操作的数量(A->B->C->A 一次回环3次转发)。
跨核由于ABC都需要占用一个CPU节点因此只有5个实例,分数是*5

SW1621 异数OS TCP协议栈理论性能模拟测试
单核环境
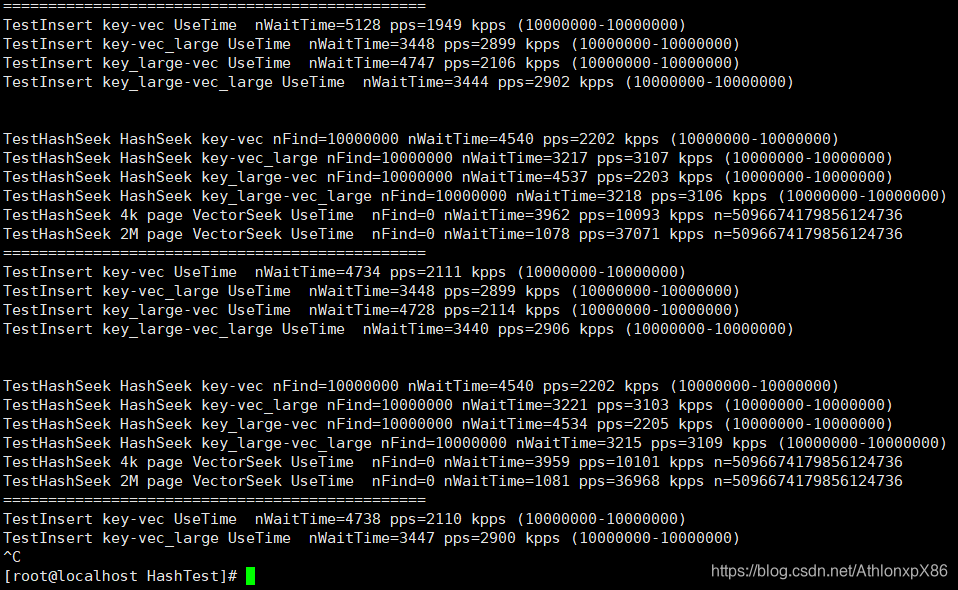
创建1000W TCP session.
新建性能 2.9M(I7 2680QM 2.6G 5.2M)
随机查询性能 3.1M(I7 2680QM 2.6G 15M)
测试总结
申威CPU跨核带宽最大7.5GB/s(3*5核),本地模式36GB/s (3*15核) 大于128字节时IO性能下降明显。
申威给的STREAM测试成绩使用MP技术,STREAM的任务是无交叉关联的,任务可多核无关并发分配,因此MP可编译期任务划分到本地线程,运行时内存拷贝使用本地CPU内存拷贝模式,因此不具有跨核内存拷贝参考意义。
如果需要测试多核交叉互联拷贝性能,测需要改变STREAM代码,如下
//原来的代码
void tuned_STREAM_Copy()
{
ssize_t j;
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
}
//改造为跨核访问的代码
void tuned_STREAM_Copy()
{
ssize_t j;
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[rand(j)];
}
推测跨核模式由于CPU内联交换总线延迟较大,吞吐下降,未来实用环境中使用异数OS多隧道交换技术吞吐可能会有改善(测试程序只有1并发隧道)
初步数据分析,申威1621可以满足Xnign-X1的性能需求,异数OS TCP协议栈7层IO密集型应用性能预计15核可达到1400字节200W IOPS(20Gbps带宽) 或者64字节15M IOPS(10Gbps带宽),未来numa内存调校优化后,预计可以满足Xnign-X2的硬件需求,配合异数OS在5G领域开发定制产品应该会有不错的竞争力,实现直线超车。
(Xnign-X1的http性能相当于intel全家cpu+linux+nginx性能的20倍)。
下面是Xnign产品性能参数介绍
https://blog.csdn.net/AthlonxpX86/article/details/85279871
测试程序运行结果图
1.15核512字节本地交换
2.TCP Session模拟测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号