异数OS-织梦师-异数OS虚拟容器交换机(七) 走进4Tbps网络应用时代,加速5G应用真正落地
.
异数OS-织梦师-异数OS虚拟容器交换机(七) 走进4Tbps网络应用时代,加速5G应用真正落地
本文来自异数OS社区
github: https://github.com/yds086/HereticOS
异数OS社区QQ群: 652455784
异数OS-织梦师(消息中间件 ,区块链,游戏开发方向)群: 476260389
异数OS-织梦师-Xnign(Nginx方向)群: 859548384
序言
本文测试数据由AMD服务器供应商 正昱科技提供的EPYC 7551完成,再次感谢他们提供的热心支持,他们是一群充满理想,充满朝气的中小创业者,愿每一位中小创业者在布满荆棘的道路上都能够如此,将希望的种子播撒到世界最寒冷的地方,带给那里一线光明,也照亮自己的未来。
文章目录
- 异数OS-织梦师-异数OS虚拟容器交换机(七) 走进4Tbps网络应用时代,加速5G应用真正落地
- 本文来自异数OS社区
- 序言
- @[toc]
- 关于异数OS虚拟容器交换机技术背景
- 异数OS容器虚拟交换机方案
- 容器交换机性能测试
- Xnign吞吐性能测试
- 128核本地系统L1 L2 HT系统本地压测
- 64核不开HT 本地系统L1 L2(历史数据)
- 128核本地系统L1 L2 HT系统交叉压测
- 128核本地系统CCX内系统交叉压测
- 128核本地系统CCX间系统交叉压测
- 128核本地系统同Socket Node间系统交叉压测
- 128核本地系统不同Socket Node间系统交叉压测
- PBFT压测
- 未来的考虑
关于异数OS虚拟容器交换机技术背景
随着CPU技术发展,未来可能会出现几百上千核的CPU ,而异数OS会将每个CPU核抽象为一个容器集群节点,这样本地容器集群规模就变得比较庞大,本地容器集群内流量交换压力与日俱增,因此需要一个虚拟交换机做本地容器流量转发,异数OS虚拟交换机是很早以前完成的,用于异数OS原型验证实验,但并没有真想让他落地成为一个OS组件,原因是异数OS虚拟交换机在容器操作系统本地运行,会占用不少内存带宽,他大概会占用50%的CPU 内存带宽资源。所以理论上应该由硬件交换技术去完成,但随着需求的不断妥协,我们发现这个虚拟交换机将变得不可替代,原因有以下几点
1. PCIE 网卡以及交换机网络延迟约束
主流的网卡以及交换机设备的延迟最多只能做到10us,这可能是照顾linux windows等落后操作系统的原因,但这对异数OS来讲是降低性能的罪犯,异数OS的应用延迟一般在300ns-1us(Xnign 1链接大概200ns),延迟对于一些应用系统来讲是致命的,比如一些分布式事务,分布式锁,PBFT等,这些都是7层应用的重量级基础技术,而CPU的LLC以及AMD Infinity Fabric 以及Intel ring qpi等CPU总线已经可以将数据交换延迟降低到0.5-2us,这个级别的延迟,对于异数OS来讲,具有数量级级别的加速意义,它可以将分布式事务的TPS性能相对Linux等操作系统提速1000倍。
2.主流网卡带宽不足
目前主流网卡硬件只能提供100G带宽,且单点无法形成交换网络,而CPU 比如 EPYC等已经已经可以达到4T的数据交换容量,而且EPYC 二代的架构推测可能已经支持一个CPU交换机,吞吐预计还能提升数倍,因此任何硬件网卡交换方案都几乎都无法承载异数OS容器集群的本地流量,网卡交换方案只能作为一种外部互联的折中替补方案,异数OS需要一个本地虚拟交换机来卸载本地集群转发流量,只将外部流量转移给网卡交换设备。
3.网卡做交换机不专业,不灵活,且生态兼容圈太小
主流的网卡比如intel 网卡需要考虑复杂的sr-iov vmdq等技术来帮助异数OS设计容器化网络交换机,但目前看来还是比较难适配的,在综合考虑 macvlan rss fdir sr-iov vmdq等方案折中来实现一个容器交换机的过程中,发现这些技术目前并不能完全满足异数OS的需求,在做本地容器网络交换时出现一些功能障碍,且会增加方案复杂度,降低兼容性,因此需要一个虚拟交换机来满足一些硬件网卡无法提供的能力,并降低硬件设备方案复杂度(只使用L2 L3普通硬件交换设备,不依赖SDN白盒交换技术设备)。
4.网卡SDN生态政治站队文化严重,发展缓慢
几年下来找不到一个国内能定制网卡的厂商,都是些见风使舵依附势力天天想着骗钱忽悠的表演家。
异数OS容器虚拟交换机方案
由于异数OS 容器交换机需要对本地容器做流量转发,因此他需要考虑异数OS容器技术以及CPU NUMA互联总线架构做优化流量转发,因此设计时根据不同场景做了不同的优化策略,形成了一套在异数OS容器环境下有效的低延迟大带宽网络资源规划转发方案,目前EPYC平台实现最大4.8Tbps 500mpps的 Xnign http流量生成并转发。
考虑到本地集群需要,我们按照NUMA容器布局架构,规划127 IP网段来分配非本地容器,用于本地集群流量转发。
异数OS 127网段IP格式定义如下
127.SystemID.ContainerID.0/8
下表为IP NUMA 容器划分,对应交换技术以及性能指标的对应关系,注意下表中PPS是指在Xnign 1000字节页面(1400包尺寸)环境下压测得到,因此并不算是最大PPS,一些场景可能会因为带宽约束导致PPS不是最大值,延迟带宽相关测试数据见后文。
| 交换技术 | 容器作用范围 | IP范围定义 | EPYC Xnign 1链接延迟 | PPS(EPYC Xnign压力) | 带宽(EPYC Xnign压力) | IOPS(EPYC Xnign压力) | PBFT消息转发量 |
|---|---|---|---|---|---|---|---|
| CPU 本地L1 L2 | 本地系统内容器间交换 | 127.0.0.0/8 127.本地系统ID.容器ID.0/8 |
350ns | 450Mpps | 4 Tbps | 450M*2 | |
| HT核本地L1 L2 | HT系统内容器间交换 | 127.HT内系统ID.容器ID.0/8 | 720ns | 260Mpps | 2Tbps | 260M*2 | |
| CCX内 L3 共享 | CCX内系统容器间交换 | 127.CCX内系统ID.容器ID.0/8 | 720ns | 225Mpps | 1.6Tbps | 225M*2 | |
| Infinity Fabric 内部互联总线 | CCX之间系统容器间交换 | 127.CCX内系统ID.容器ID.0/8 | 1.3us | 140Mpps | 1Tbps | 140M*2 | 4将军 300W TPS |
| Infinity Fabric同Socket外部总线 | 同Socket Node之间系统容器间交换 | 127.同Socket Node间系统ID.容器ID.0/8 | 1.9us | 83Mbps*3? | 550Gbps*3? | 83M*2*3? | 241将军 20M*2 TPS |
| Infinity Fabric Socket间互联总线 | CPU Socket 间系统容器间交换 | 127.CPU Socket 间系统ID.容器ID.0/8 | 2.5us | 70Mpps | 450Gbps | 70M*2 | 241将军 33M*2 TPS |
| PCIE网卡交换设备 | 外部网络容器间交换 | 192.0.0.0/24 具体由容器编排工具确定 |
10us | fdir最大实现2M*128 | 100G*4 |
容器交换机性能测试
单独测试虚拟交换机转发性能无意义,因为虚拟交换机运行在容器环境下,对容器应用负载会有较大影响,因此我们的容器交换机压测时都时都是正常应用负载来做压测,比如Xnign http流量,PBFT rpc消息广播确认等。 下面的测试数据在正昱科技提供的双路 EPYC 7551下完成, 16内存通道。
Xnign吞吐性能测试
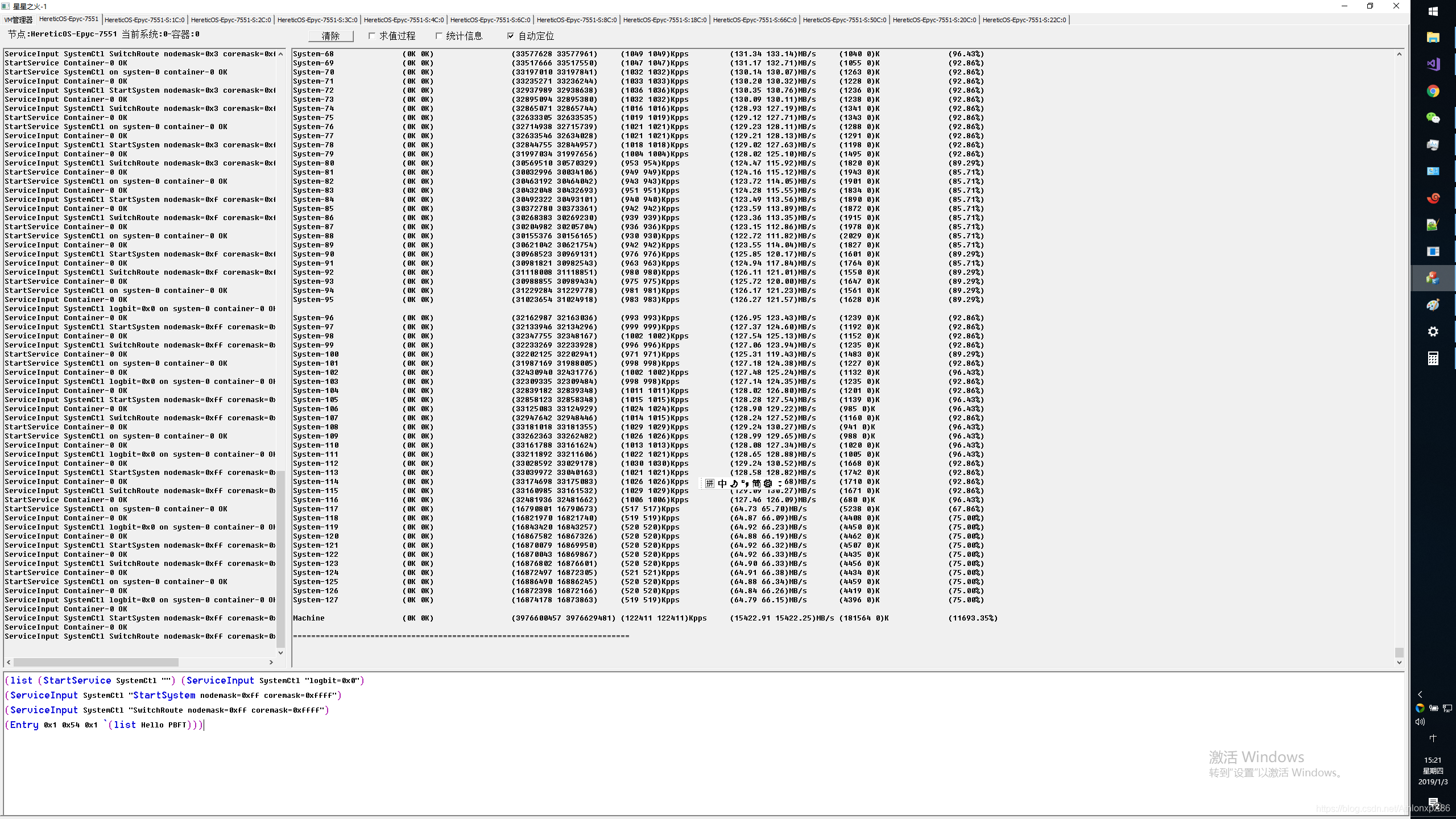
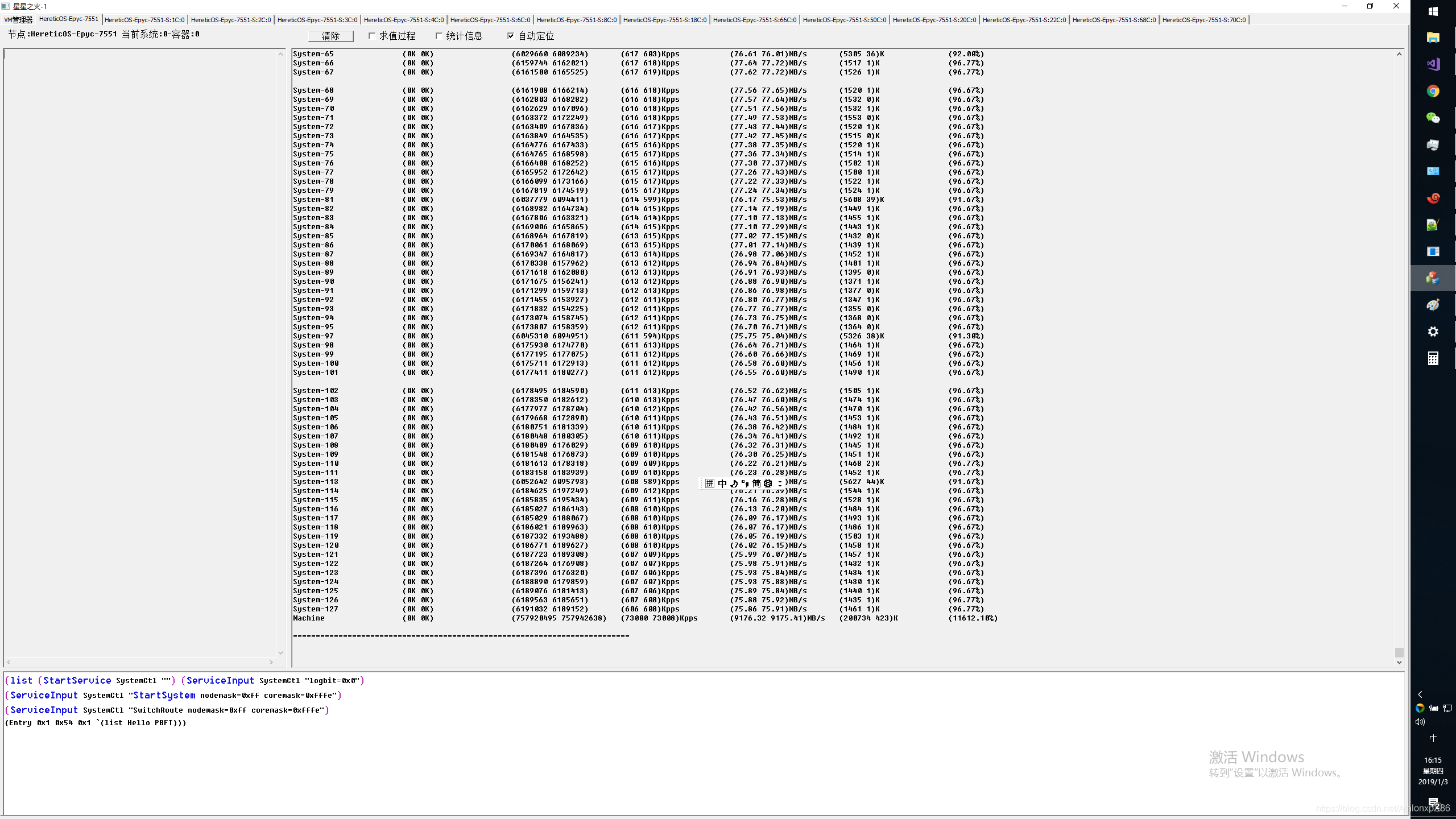
Xnign 由于IO压力相对简单,因此我们使用Xnign来做系统带宽 QPS IOPS等性能测试。
下图是Xnign 压测 1000字节 每系统节点8线程。
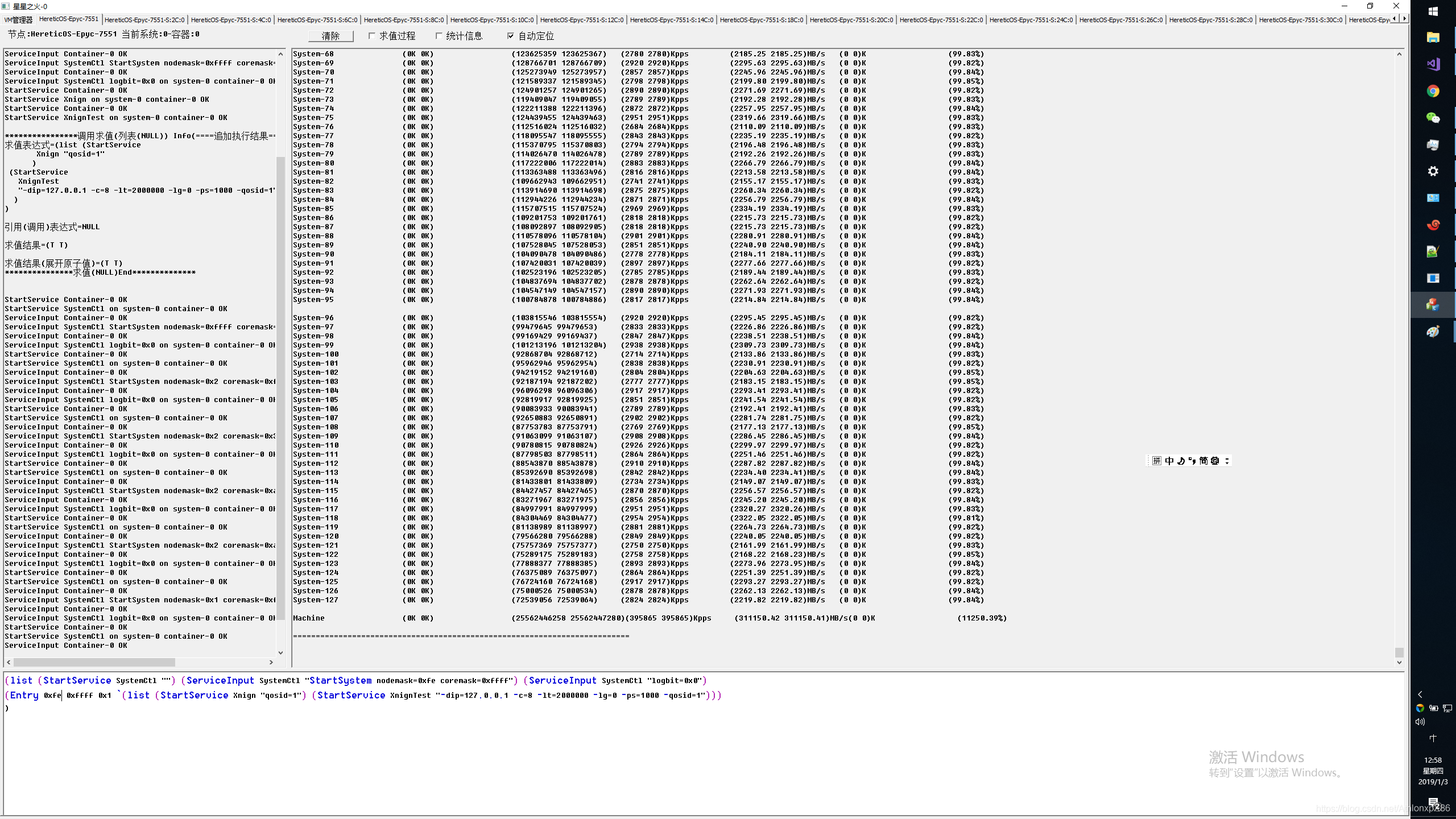
128核本地系统L1 L2 HT系统本地压测
CPU开启HT本地 L1 L2压测,可以看到正昱科技提供的EPYC 112核(写博客是才发现少开了一个节点15核,好吧)压测整体流量达到双向总计620GB流量(4.8Tbps),此时Xnign QPS达到2亿,虚拟容器交换机包交换性能达到400Mpps,相信全开后能达到450Mpps。
64核不开HT 本地系统L1 L2(历史数据)
128核本地系统L1 L2 HT系统交叉压测
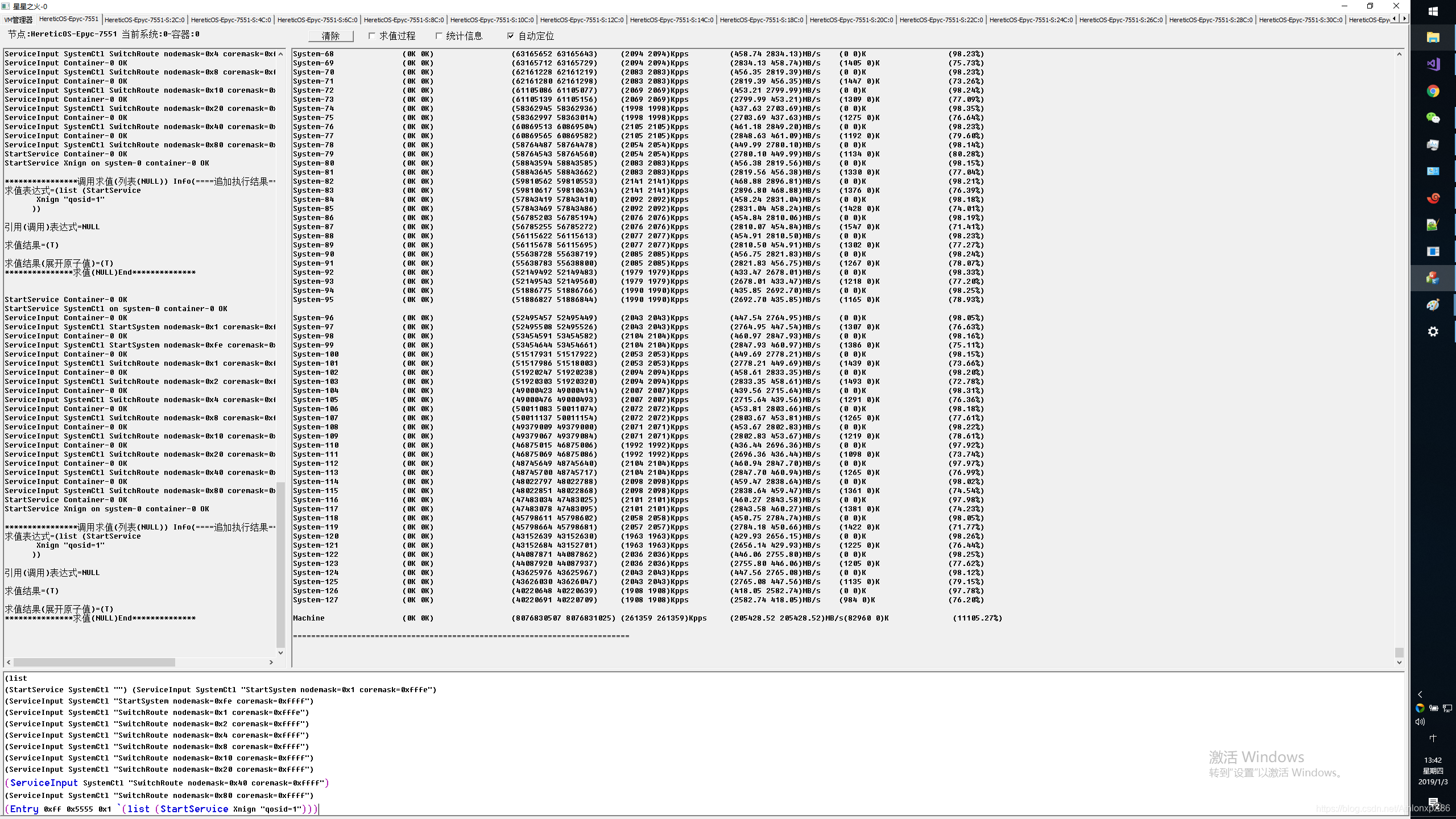
128核本地系统CCX内系统交叉压测
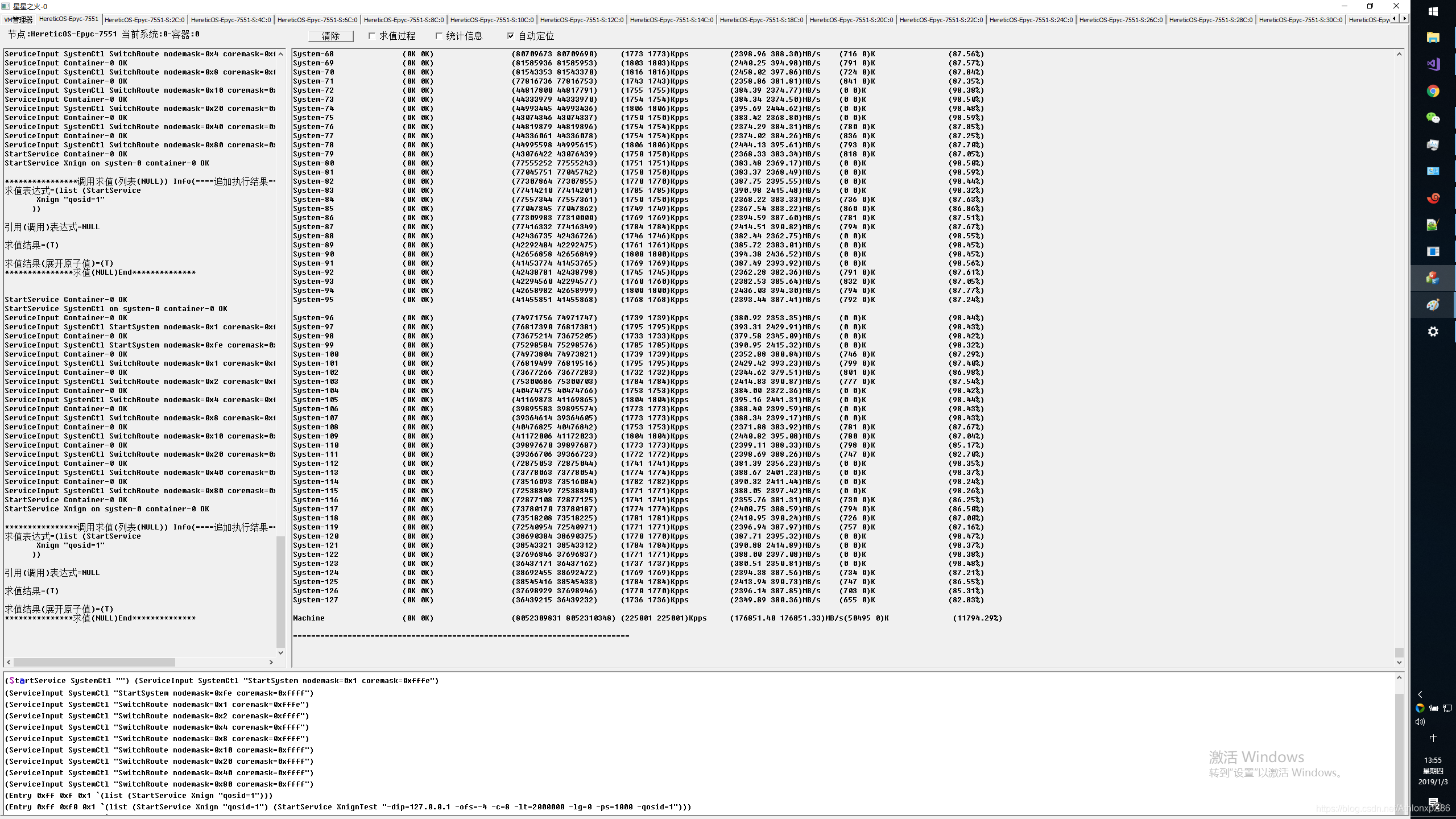
128核本地系统CCX间系统交叉压测
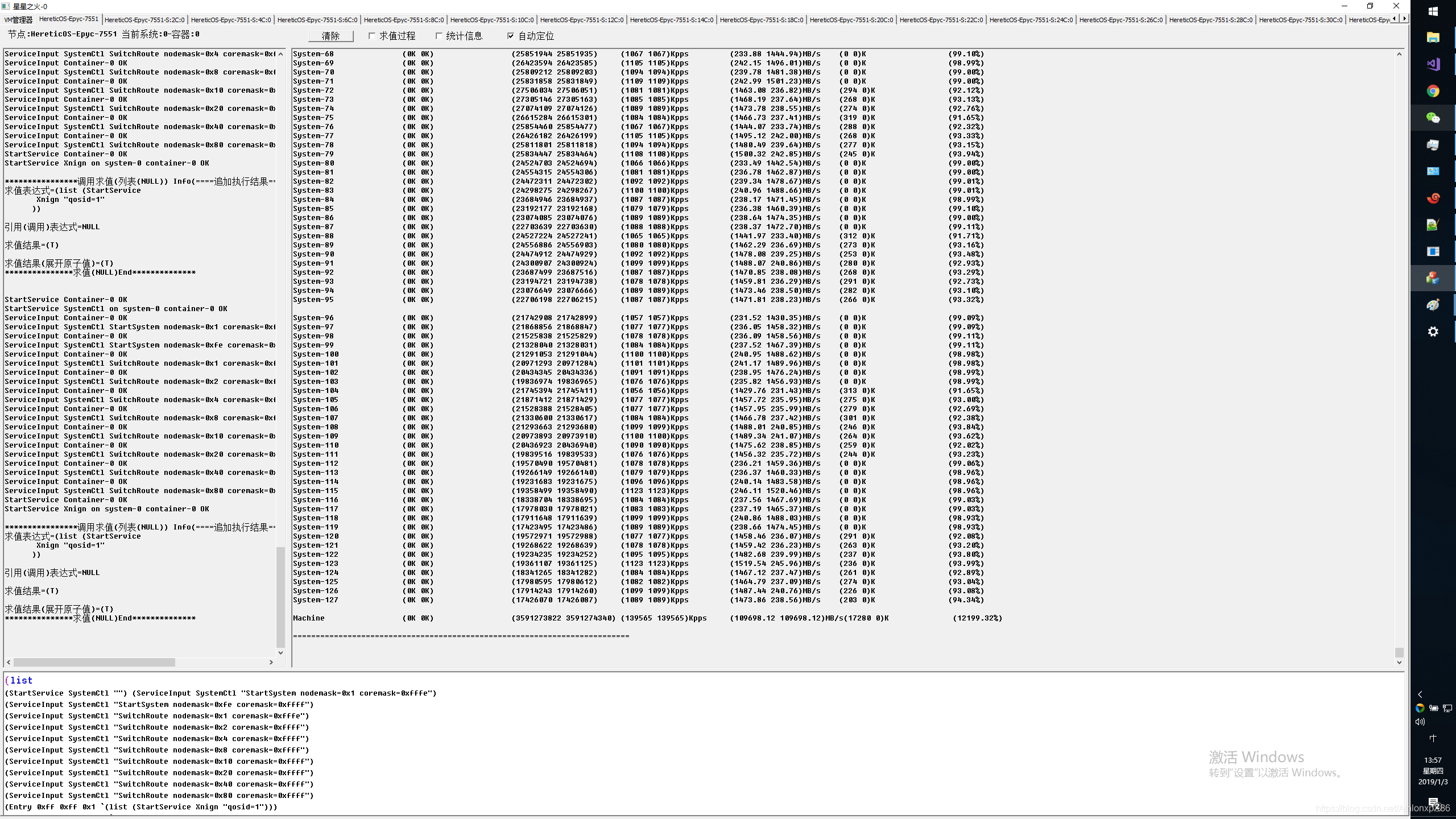
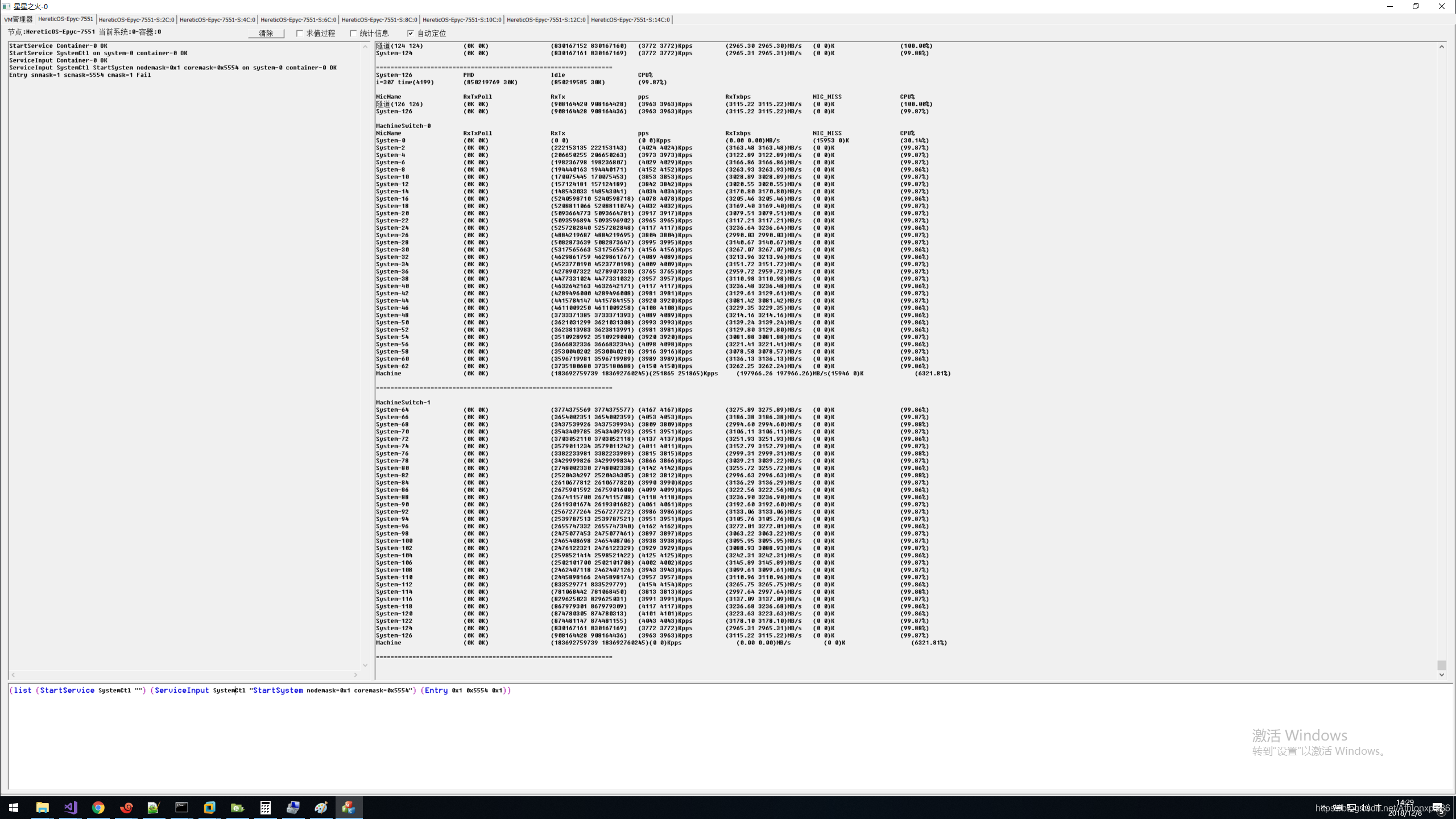
128核本地系统同Socket Node间系统交叉压测
写完博客,后来才发现AMD 同Socket 4路Node是全连接,每个Node有3条Infinity Fabric,而本测试只压了1条Infinity Fabric,所以如果三个方向都压测,可能成绩会提升3倍。
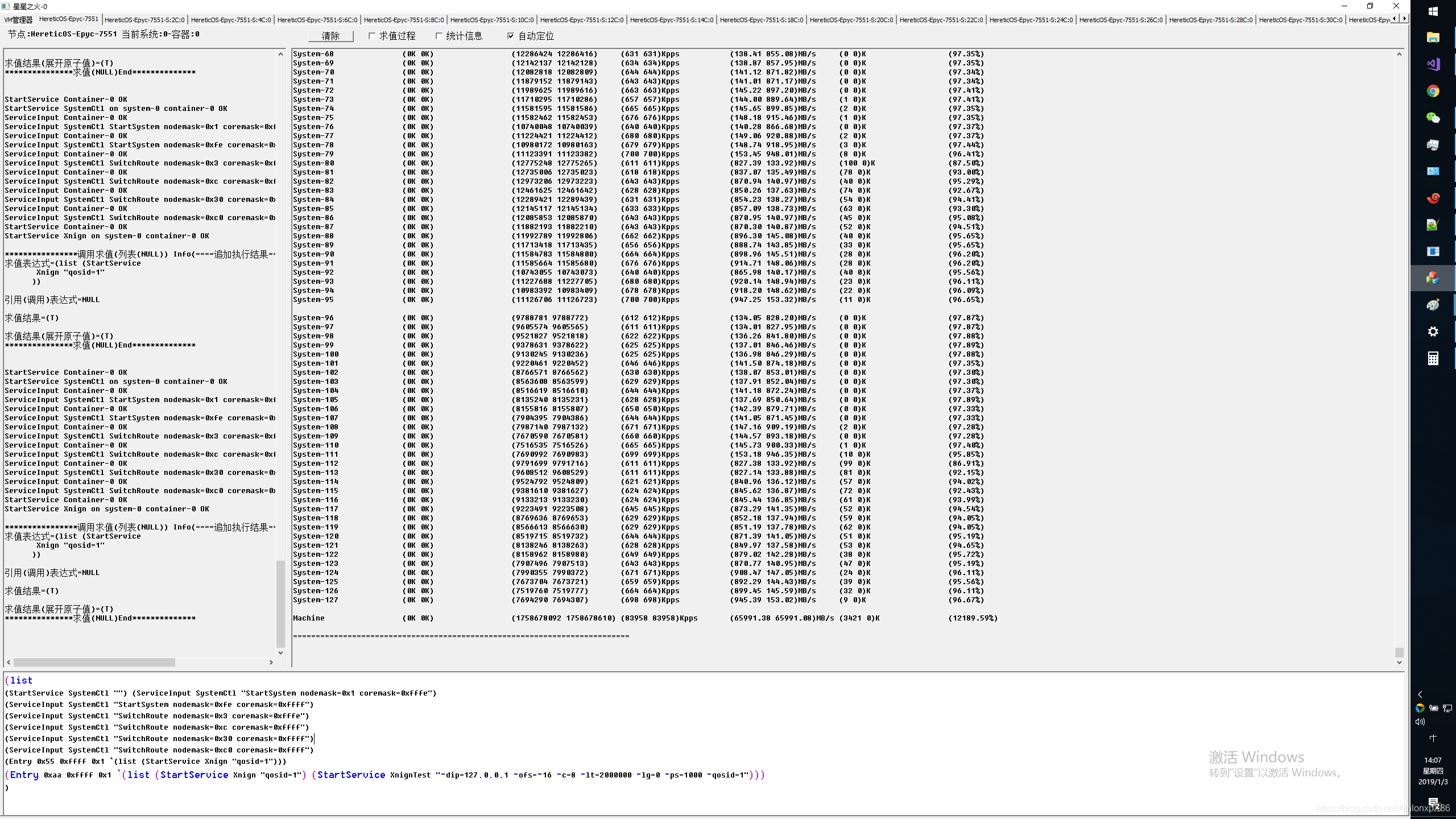
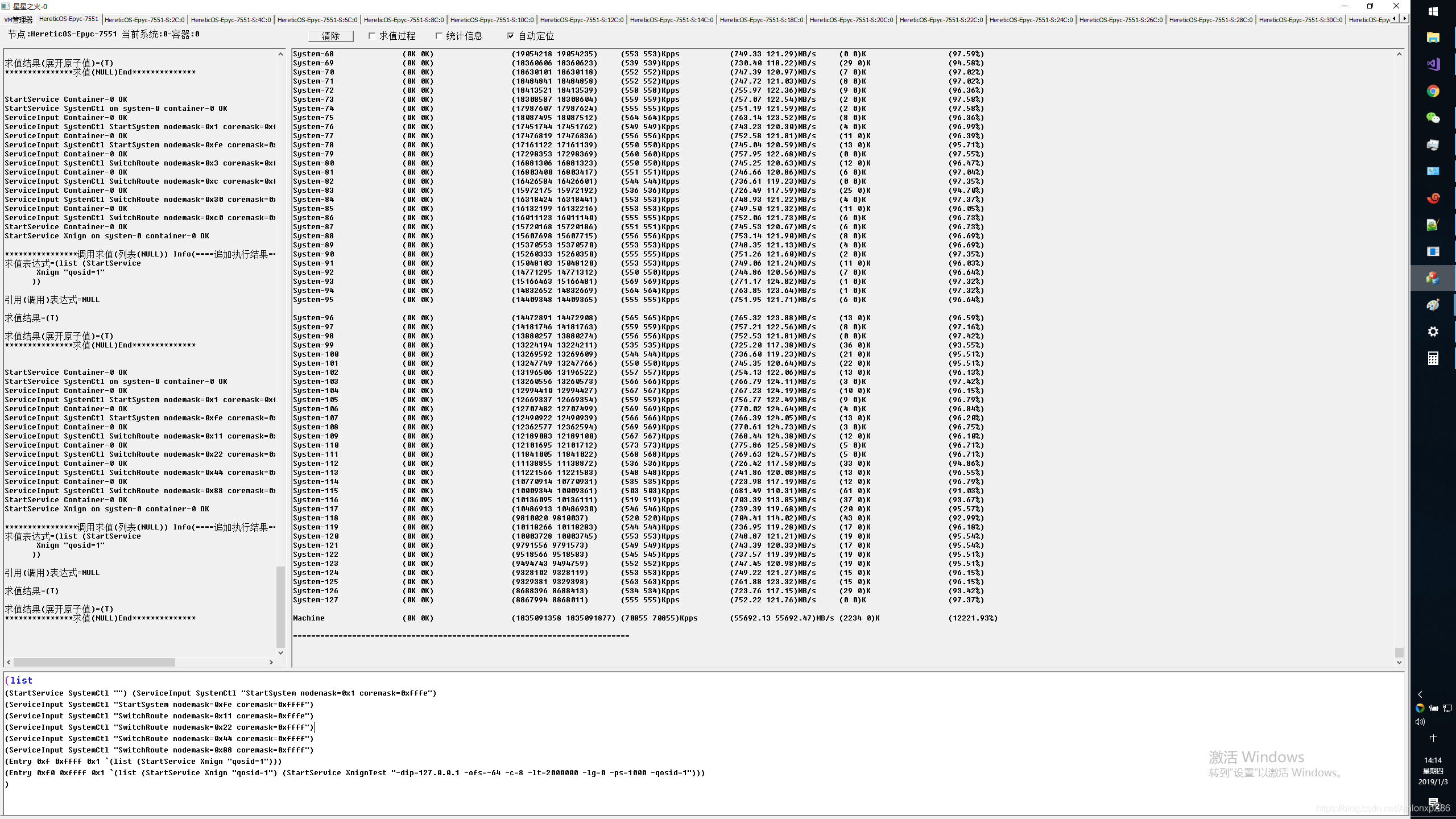
128核本地系统不同Socket Node间系统交叉压测
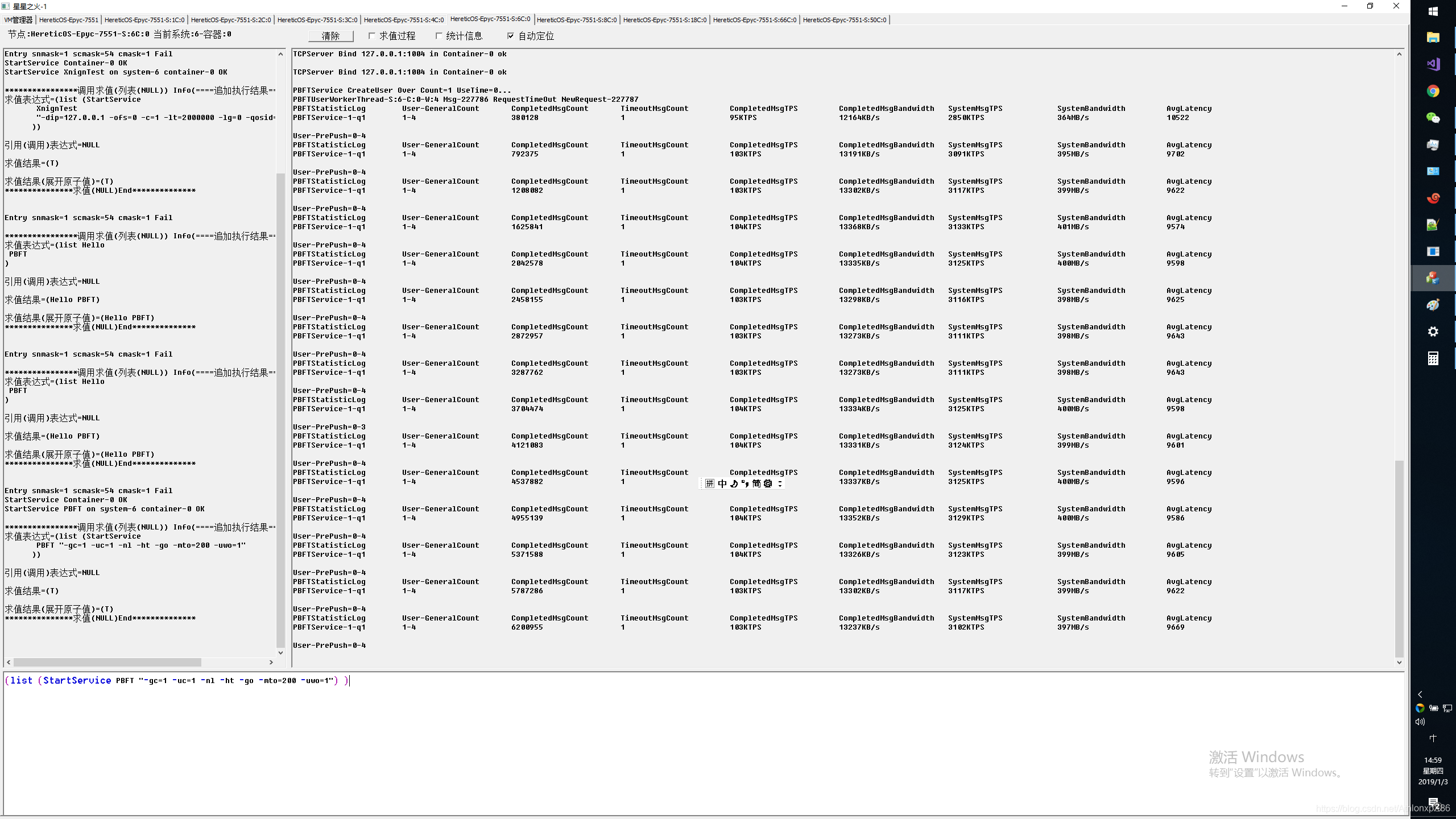
PBFT压测
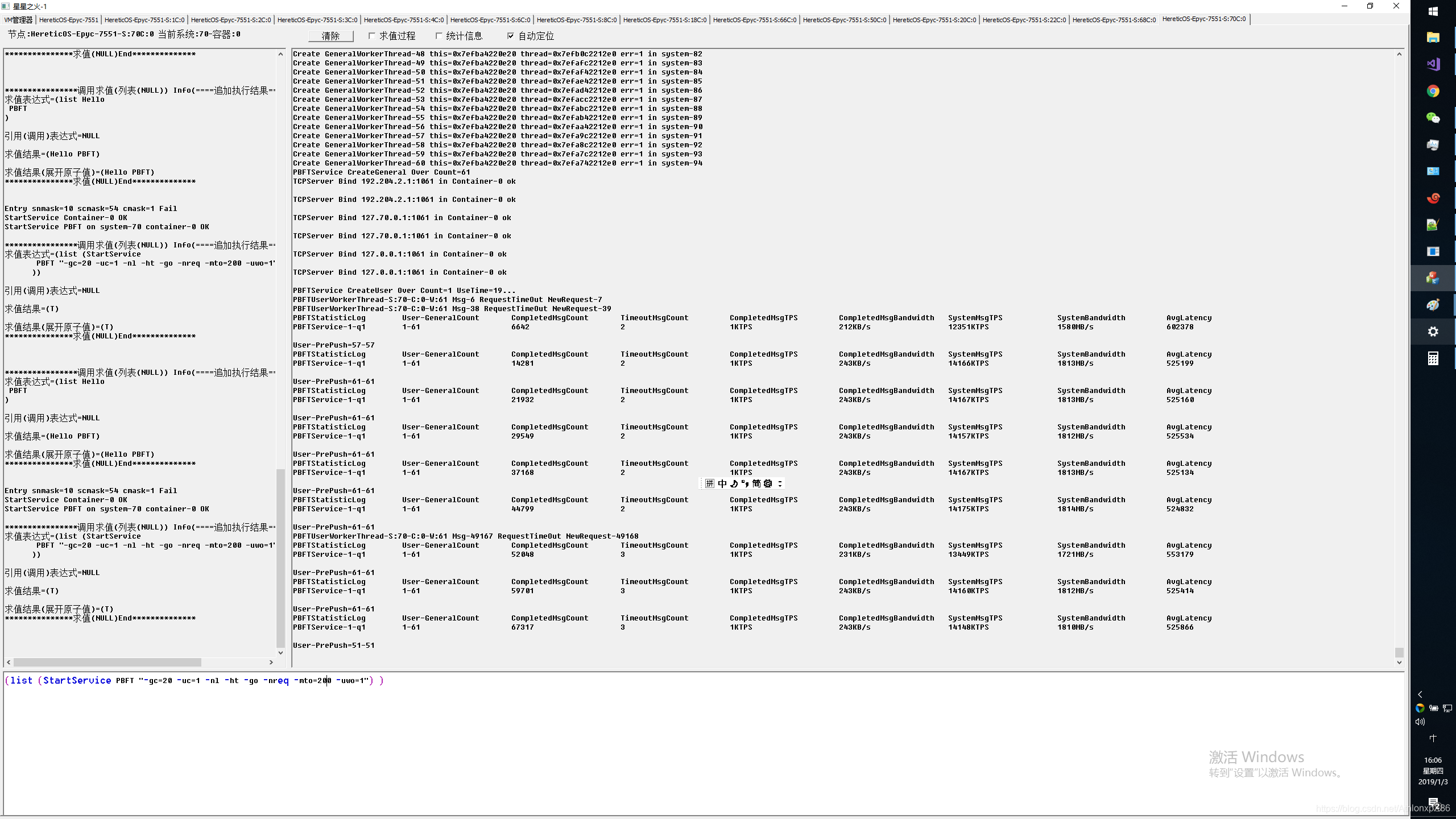
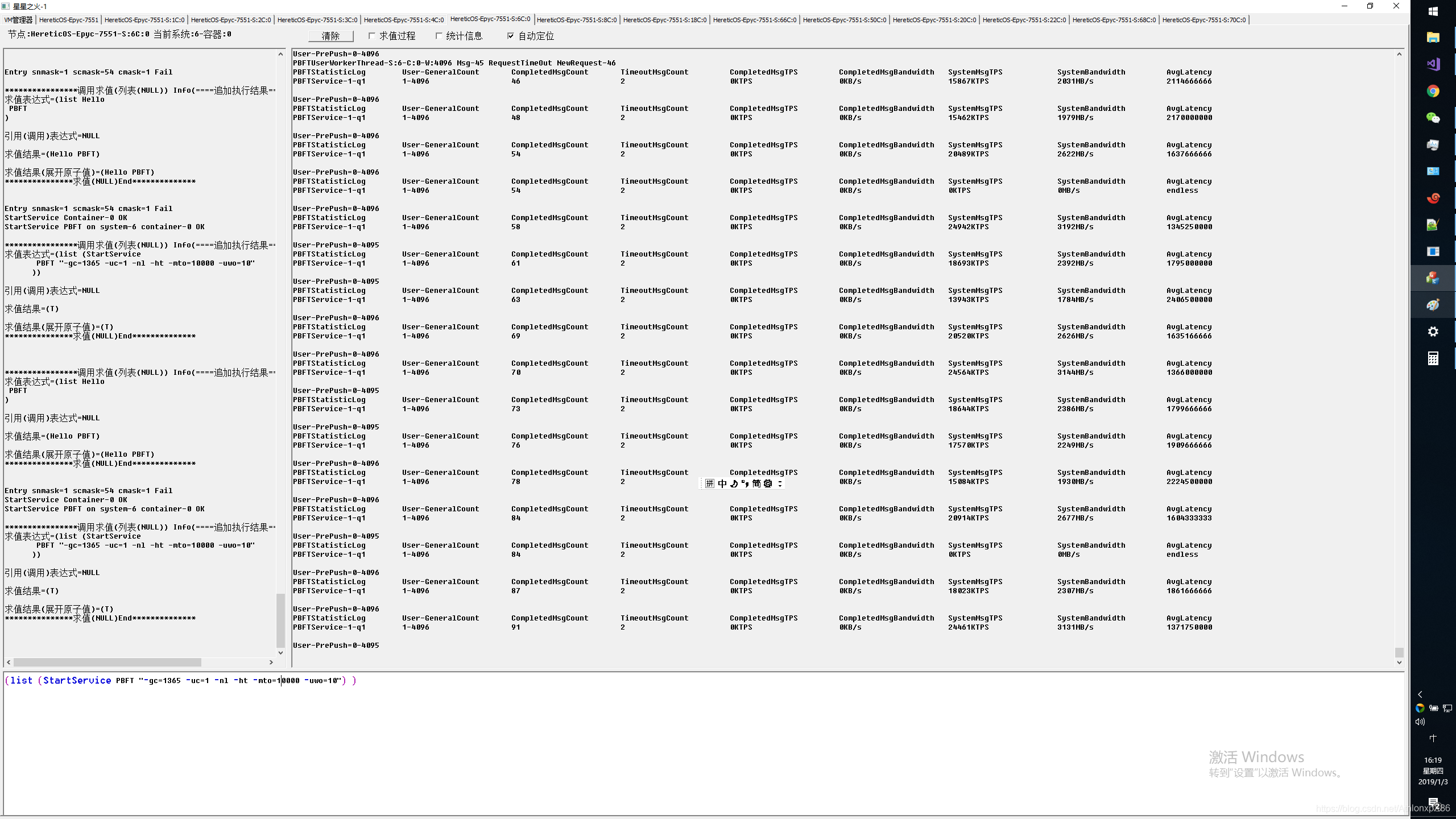
PBFT应用潜伏期较大,因此对IO延迟以及线程实时响应能力,错误处理能力要求极高,与Xnign压测不同的是PBFT需要所有节点全连接,最慢的节点以及最慢的通讯路径将拖累系统总体IO性能,并可能造成超时停机,因此我们用PBFT可以来模拟对分布式事务以及分布式锁等性能能依赖较高的应用性能测试,主要测试有4将军,61将军,241将军,4096将军,最后我们压测了极限8191将军,他将创建1.2亿TCP RPC链接(2*8191*8191),对应4.8亿异数OS工作线程.
4将军
忘记放进CCX内的系统环境,延迟有些高,成绩不是很理想。
61将军 2节点32核
241将军 8节点128核

4096将军 8节点128核
8191将军 8节点128核
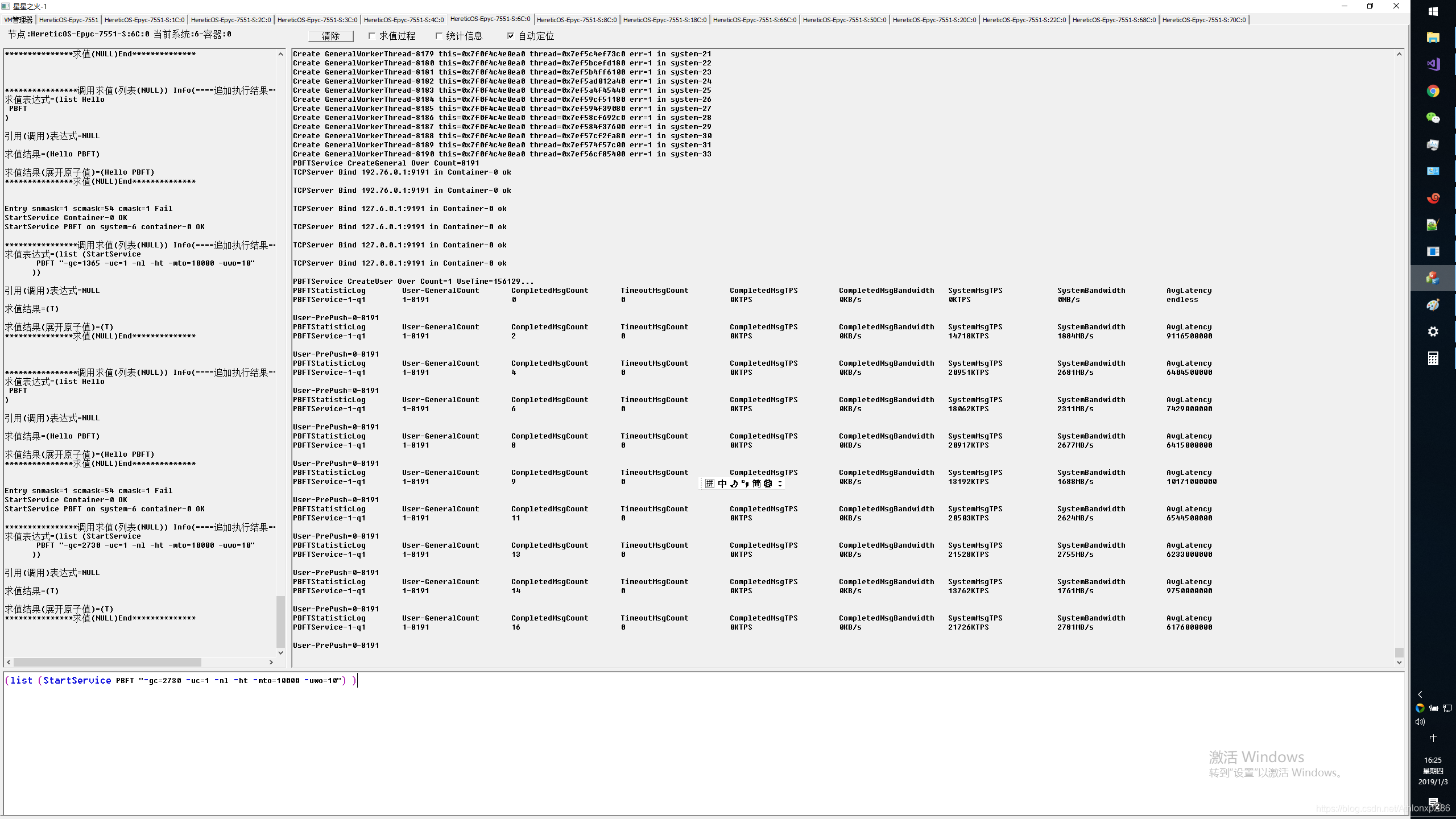
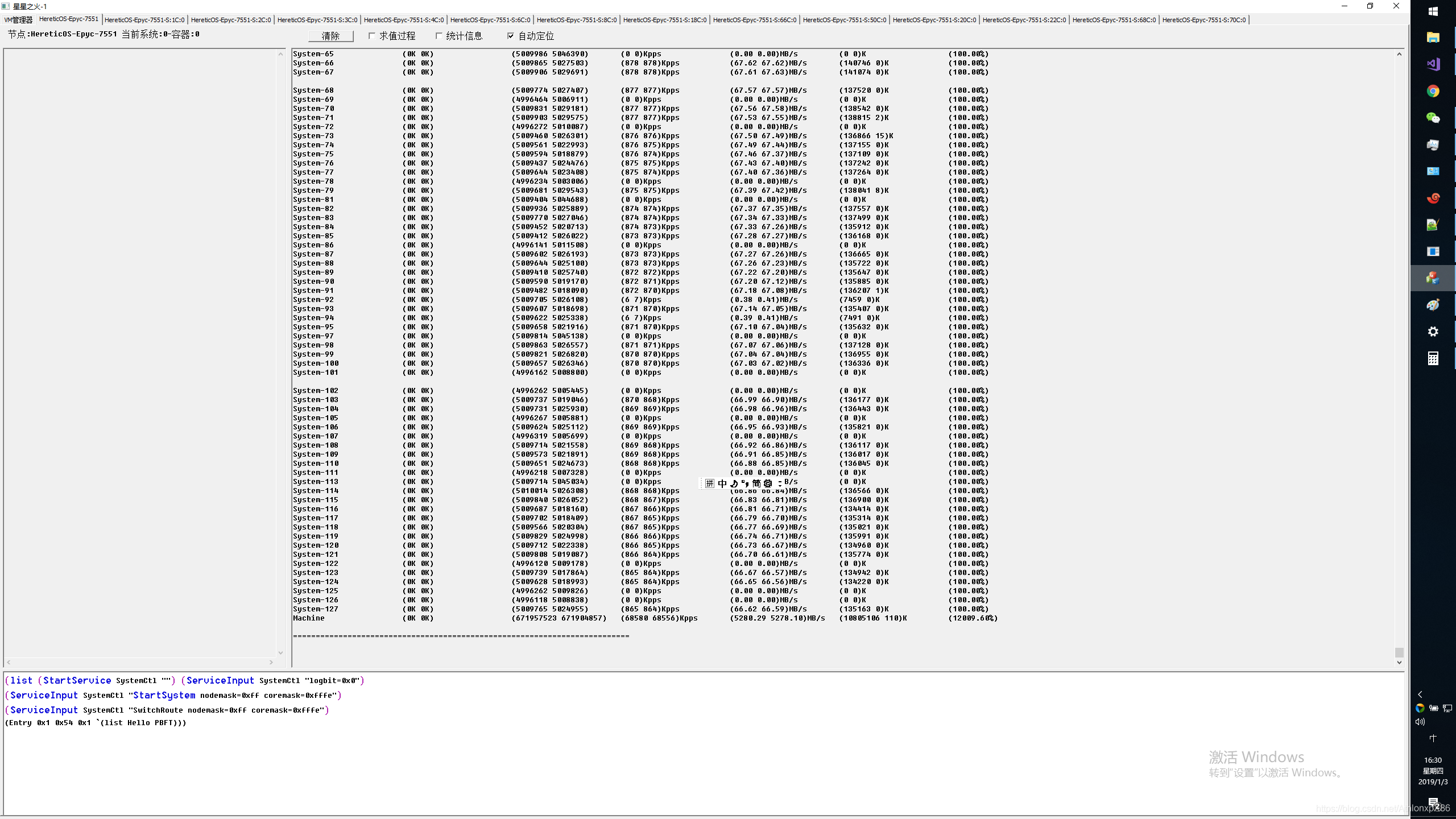
未来的考虑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号