
CF455D Serega and Fun 题解
1.CF1916E Happy Life in University 题解2.CF763E Timofey and our friends animals题解3.CF1270G Subset with Zero Sum4.CF1045G AI robots题解5.CF940F Machine Learning题解6.CF678F Lena and Queries题解7.CF1921F Sum of Progression 题解8.CF526F Pudding Monsters 题解
9.CF455D Serega and Fun 题解
10.CF351D Jeff and Removing Periods 题解11.CF452F Permutation 与 P2757 [国家集训队] 等差子序列 题解12.CF911G Mass Change Queries 题解13.CF145E Lucky Queries 题解14.CF1515F Phoenix and Earthquake 题解15.CF765F Souvenirs 题解16.CF1764H Doremy's Paint 2 题解17.CF1000F One Occurrence题解18.CF813E Army Creation 题解19.CF1706E Qpwoeirut and Vertices 题解20.CF620E New Year Tree 题解21.CF1454F Array Partition 题解22.CF1771F Hossam and Range Minimum Query 题解23.CF1931F Chat Screenshots 另一种题解24.CF896C Willem, Chtholly and Seniorious 题解25.CF55D Beautiful numbers 题解26.CF916E Jamie and Tree 题解27.CF696B Puzzles 题解28.CF383C Propagating tree 题解29.CF1436E Complicated Computations 题解30.CF817F MEX Queries 题解31.CF1638E Colorful Operations 题解32.CF1618G Trader Problem 题解33.CF794F Leha and security system 题解34.CF371E Subway Innovation 题解35.CF1200E Compress Words 题解36.CF1884D Counting Rhyme 题解37.CF1982F Sorting Problem Again 题解题目链接:CF 或者洛谷
本题是可以用平衡树去做的,具体的为每个
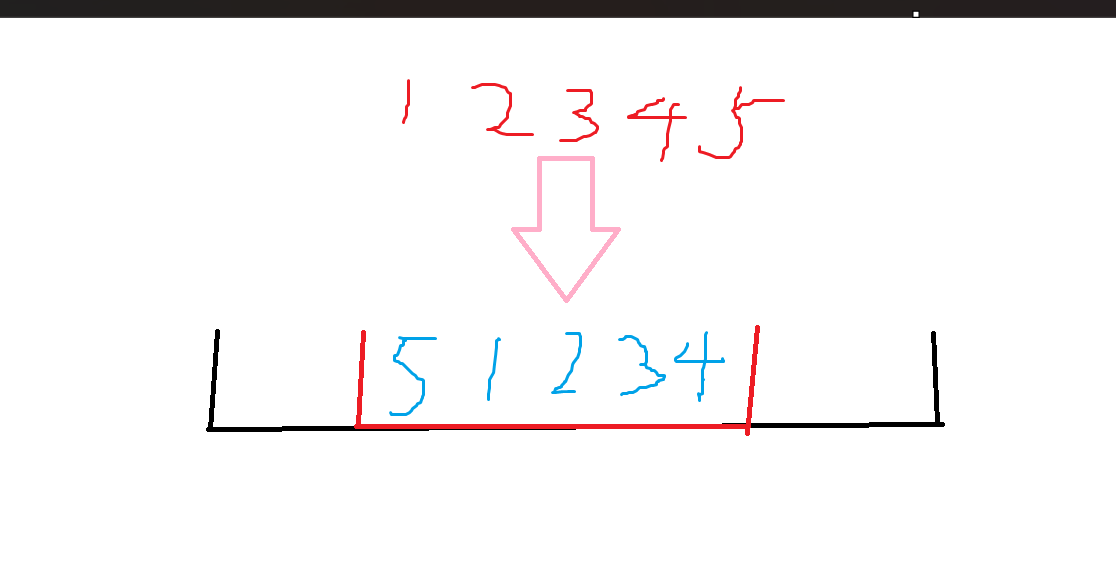
黑色的代表一个块,考虑暴力修改情况,假如原来的数字为
令
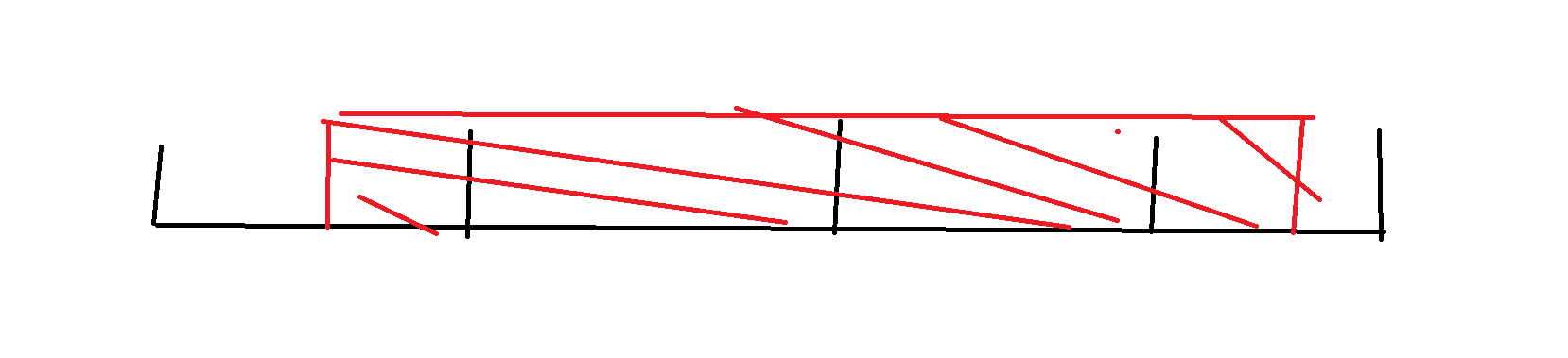
假如这是多块修改,中间整块怎么处理,我们容易发现:
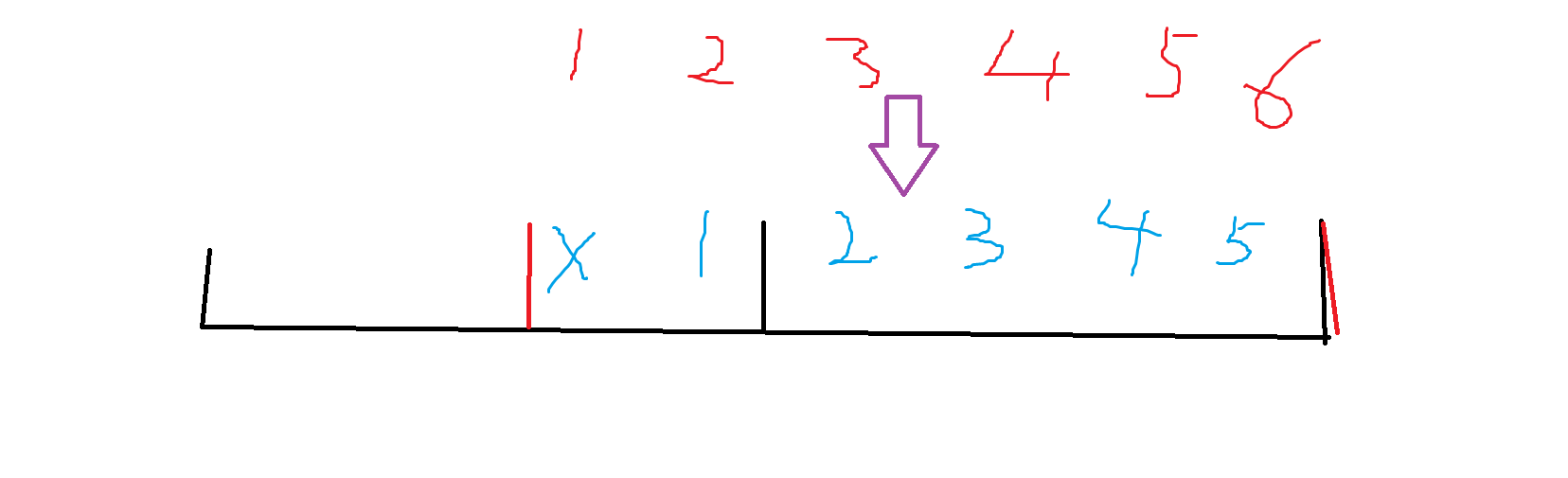
观察下这时候有啥变化,
看看查询,问查
参照代码
#include <bits/stdc++.h> // #pragma GCC optimize("Ofast,unroll-loops") // #pragma GCC optimize(2) // #define isPbdsFile #ifdef isPbdsFile #include <bits/extc++.h> #else #include <ext/pb_ds/priority_queue.hpp> #include <ext/pb_ds/hash_policy.hpp> #include <ext/pb_ds/tree_policy.hpp> #include <ext/pb_ds/trie_policy.hpp> #include <ext/pb_ds/tag_and_trait.hpp> #include <ext/pb_ds/hash_policy.hpp> #include <ext/pb_ds/list_update_policy.hpp> #include <ext/pb_ds/assoc_container.hpp> #include <ext/pb_ds/exception.hpp> #include <ext/rope> #endif using namespace std; using namespace __gnu_cxx; using namespace __gnu_pbds; typedef long long ll; typedef long double ld; typedef pair<int, int> pii; typedef pair<ll, ll> pll; typedef tuple<int, int, int> tii; typedef tuple<ll, ll, ll> tll; typedef unsigned int ui; typedef unsigned long long ull; typedef __int128 i128; #define hash1 unordered_map #define hash2 gp_hash_table #define hash3 cc_hash_table #define stdHeap std::priority_queue #define pbdsHeap __gnu_pbds::priority_queue #define sortArr(a, n) sort(a+1,a+n+1) #define all(v) v.begin(),v.end() #define yes cout<<"YES" #define no cout<<"NO" #define Spider ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr); #define MyFile freopen("..\\input.txt", "r", stdin),freopen("..\\output.txt", "w", stdout); #define forn(i, a, b) for(int i = a; i <= b; i++) #define forv(i, a, b) for(int i=a;i>=b;i--) #define ls(x) (x<<1) #define rs(x) (x<<1|1) #define endl '\n' //用于Miller-Rabin [[maybe_unused]] static int Prime_Number[13] = {0, 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37}; template <typename T> int disc(T* a, int n) { return unique(a + 1, a + n + 1) - (a + 1); } template <typename T> T lowBit(T x) { return x & -x; } template <typename T> T Rand(T l, T r) { static mt19937 Rand(time(nullptr)); uniform_int_distribution<T> dis(l, r); return dis(Rand); } template <typename T1, typename T2> T1 modt(T1 a, T2 b) { return (a % b + b) % b; } template <typename T1, typename T2, typename T3> T1 qPow(T1 a, T2 b, T3 c) { a %= c; T1 ans = 1; for (; b; b >>= 1, (a *= a) %= c)if (b & 1)(ans *= a) %= c; return modt(ans, c); } template <typename T> void read(T& x) { x = 0; T sign = 1; char ch = getchar(); while (!isdigit(ch)) { if (ch == '-')sign = -1; ch = getchar(); } while (isdigit(ch)) { x = (x << 3) + (x << 1) + (ch ^ 48); ch = getchar(); } x *= sign; } template <typename T, typename... U> void read(T& x, U&... y) { read(x); read(y...); } template <typename T> void write(T x) { if (typeid(x) == typeid(char))return; if (x < 0)x = -x, putchar('-'); if (x > 9)write(x / 10); putchar(x % 10 ^ 48); } template <typename C, typename T, typename... U> void write(C c, T x, U... y) { write(x), putchar(c); write(c, y...); } template <typename T11, typename T22, typename T33> struct T3 { T11 one; T22 tow; T33 three; bool operator<(const T3 other) const { if (one == other.one) { if (tow == other.tow)return three < other.three; return tow < other.tow; } return one < other.one; } T3() { one = tow = three = 0; } T3(T11 one, T22 tow, T33 three) : one(one), tow(tow), three(three) { } }; template <typename T1, typename T2> void uMax(T1& x, T2 y) { if (x < y)x = y; } template <typename T1, typename T2> void uMin(T1& x, T2 y) { if (x > y)x = y; } constexpr int N = 1e5 + 10; constexpr int SIZE = sqrt(N); constexpr int CNT = (N + SIZE - 1) / SIZE + 1; int cnt[CNT][N]; //每个块维护桶 deque<int> val[N]; //每个块维护双端队列 int pos[N], s[N], e[N], idx[N]; //每个点的块编号,块起始和终止,每个点对应的块内编号(从0开始,即是对应双端队列的下标编号) int a[N]; int n, q; inline void update(const int l, const int r) { const int L = pos[l], R = pos[r]; if (L == R) { int pre = val[L][idx[r]]; forn(i, l, r)swap(val[L][idx[i]], pre); return; } //注意每个块都有一个删除和增加的数 int pre = val[R][idx[r]]; cnt[R][pre]--; cnt[L][pre]++; forn(i, l, e[L])swap(val[L][idx[i]], pre); cnt[L][pre]--; forn(i, L+1, R-1) { val[i].push_front(pre), cnt[i][pre]++; pre = val[i].back(), val[i].pop_back(), cnt[i][pre]--; } cnt[R][pre]++; forn(i, s[R], r)swap(val[R][idx[i]], pre); } //查询常规查询即可 inline int query(const int l, const int r, const int k) { const int L = pos[l], R = pos[r]; int ans = 0; if (L == R) { forn(i, l, r)ans += val[L][idx[i]] == k; return ans; } forn(i, l, e[L])ans += val[L][idx[i]] == k; forn(i, s[R], r)ans += val[R][idx[i]] == k; forn(i, L+1, R-1)ans += cnt[i][k]; return ans; } int last; inline void solve() { cin >> n; const int blockSize = sqrt(n); const int blockCnt = (n + blockSize - 1) / blockSize; forn(i, 1, n)cin >> a[i], pos[i] = (i - 1) / blockSize + 1, idx[i] = (i - 1) % blockSize; forn(i, 1, blockCnt)s[i] = (i - 1) * blockSize + 1, e[i] = i * blockSize; e[blockCnt] = n; forn(i, 1, blockCnt) { forn(j, s[i], e[i]) { val[i].push_back(a[j]); cnt[i][a[j]]++; } } cin >> q; while (q--) { int op, l, r; cin >> op >> l >> r; l = (l + last - 1) % n + 1, r = (r + last - 1) % n + 1; if (l > r)swap(l, r); if (op == 1)update(l, r); else { int k; cin >> k; k = (k + last - 1) % n + 1; cout << (last = query(l, r, k)) << endl; } } } signed int main() { // MyFile Spider //------------------------------------------------------ // clock_t start = clock(); int test = 1; // read(test); // cin >> test; forn(i, 1, test)solve(); // while (cin >> n, n)solve(); // while (cin >> test)solve(); // clock_t end = clock(); // cerr << "time = " << double(end - start) / CLOCKS_PER_SEC << "s" << endl; }
合集:
codeforces题解集1


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统