

P5501 [LnOI2019] 来者不拒,去者不追 题解
题目链接:来者不拒,去者不追
直接在线查询题目所给的式子是很困难的,我们考虑单点考察贡献。对于一个已经确定的式子,我们发现加入一个数或者删除一个数的贡献如图所示:
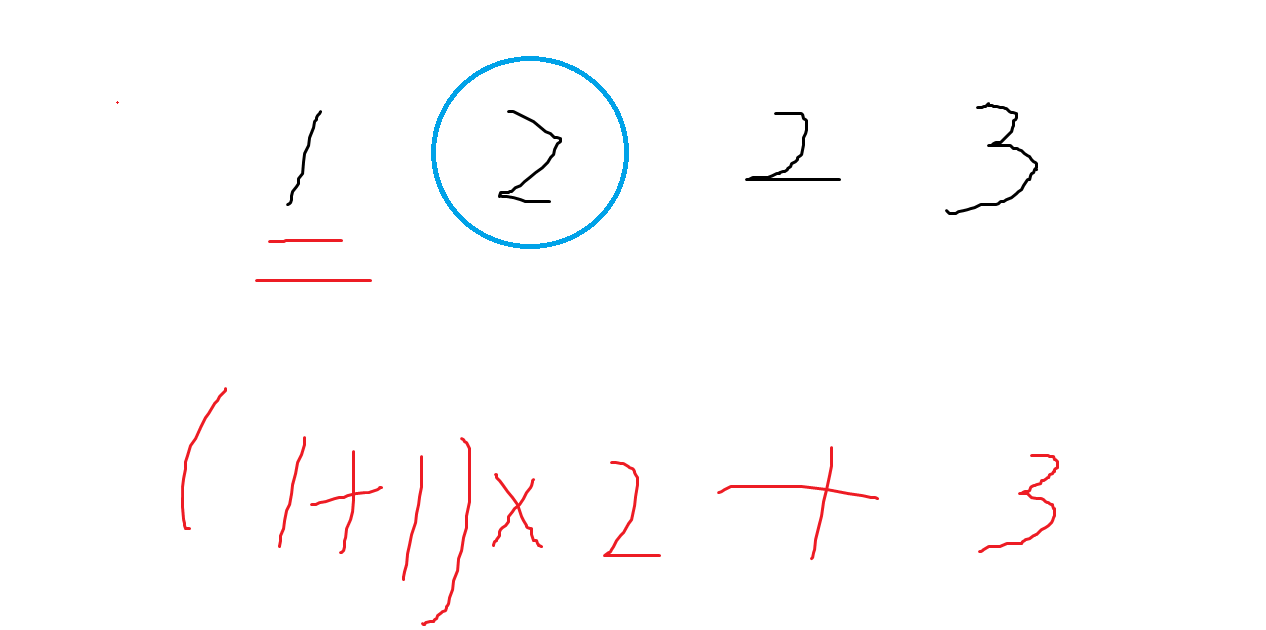
如图所示,在原有的序列为 \((1,2,3)\) 当中,我们加入新的 \(2\) 进去,我们观察到每个数的贡献的变化是这样,比 \(2\) 小的数并未更改贡献,比 \(2\) 大的数每个人的 \(kth\) 增大 \(1\),所以比 \(2\) 的数每个都会比原来多 \(1\) 个贡献。所以整体来看,比 \(2\) 大的数的贡献,即为它们之和。最后就是等于当前的 \(2\) 的贡献,很显然它的 \(kth\) 为比它小的数的数量 \(+1\),所以它的贡献为 \((cnt_{<2}+1)\times 2\)。删除分析同理,这两个过程显然互逆。接下来我们如果写一个暴力的做法:
普通莫队,在每次 \(add\) 和 \(del\) 时需要立马算出贡献,很显然的是上述式子,我们可以用树状数组轻松维护,那么很显然,这样一来,我们的单次修改是 \(\log{V_{max}}\),总复杂度为 \(O(n\sqrt{n}\log{V_{max}})\)。显然是不行的,这里需要使用莫队二次离线来解决,这里讲讲如何使用莫队二次离线解决这类下标移动是具有“可差性”问题。
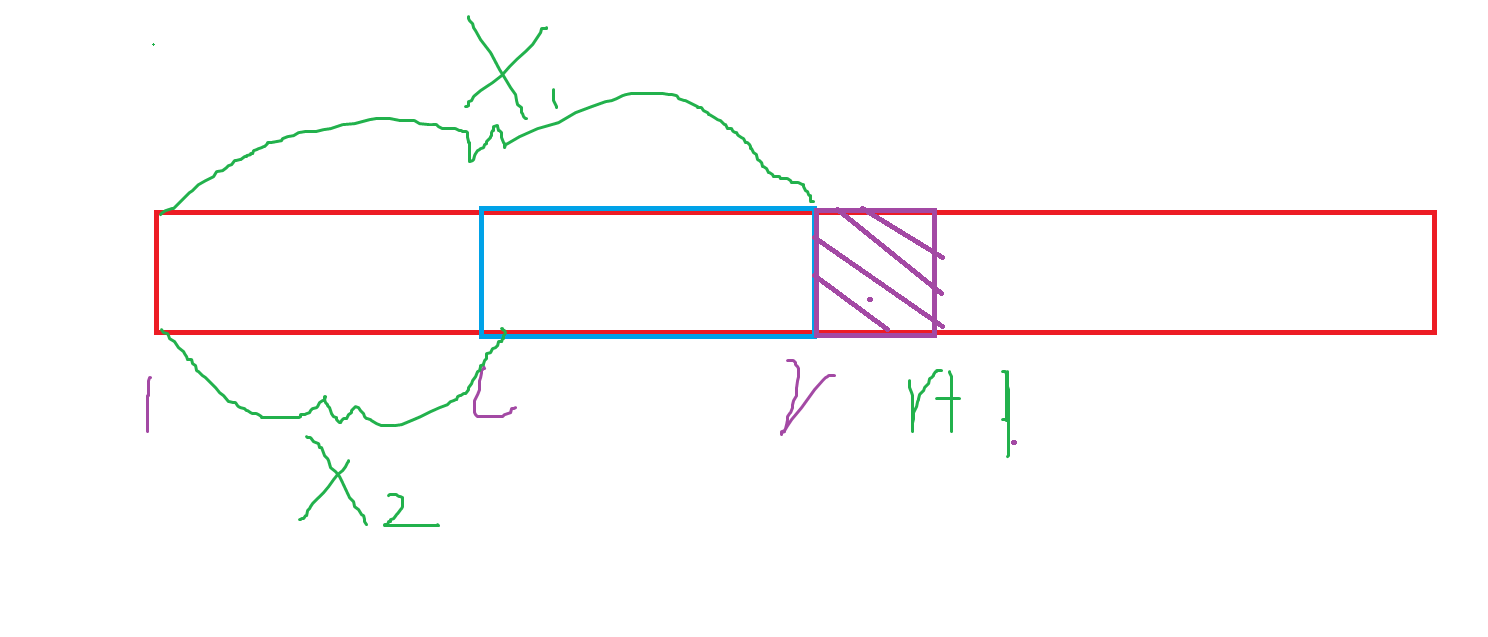
这是莫队最简单移动操作,会从 \(r\) 移动到 \(r+1\),我们观察到它会增加一个 \(r+1\) 对 \([l,r]\) 的贡献,这个贡献之前说过,使用树状数组我们需要 \(\log{V_{max}}\) 才能算出来,我们现在转化为前缀和的形式计算:
很显然的是,它会增加 \([l,r]\) 上比它的数的总和,而这部分可以拆成前缀和做差,就是式子的前半部分。而需要找到比它小的数一样可以前缀和做差,最后 \(+1\) 得到 \(kth\) 然后再乘上自身贡献,总的就是上述的式子,我们可以将式子拆开并合并:
注意,我们需要拆成凑成 \(kth+1\) 的形式,方便统一,然后注意最后注意别漏了 \(kth\) 中有个 \(1\) 的贡献。自己手动拆下上述式子就能理解意思。我们注意到有前面和后面的式子是两种不同的统一的式子:
-
前面 \(=加入a_{r+1} 对 集合\{a_1,a_2,....a_r\}的贡献\)。
-
后面 \(=加入a_{r+1} 对 集合 \{a_1,a_2,....a_{l-1}\}的贡献\)。
剩余还要记得加上一个数的贡献。
考虑一下这二者如果拓展到 \(r \rightarrow qeuryR\) 上,一堆点的增加会有怎样的变化。
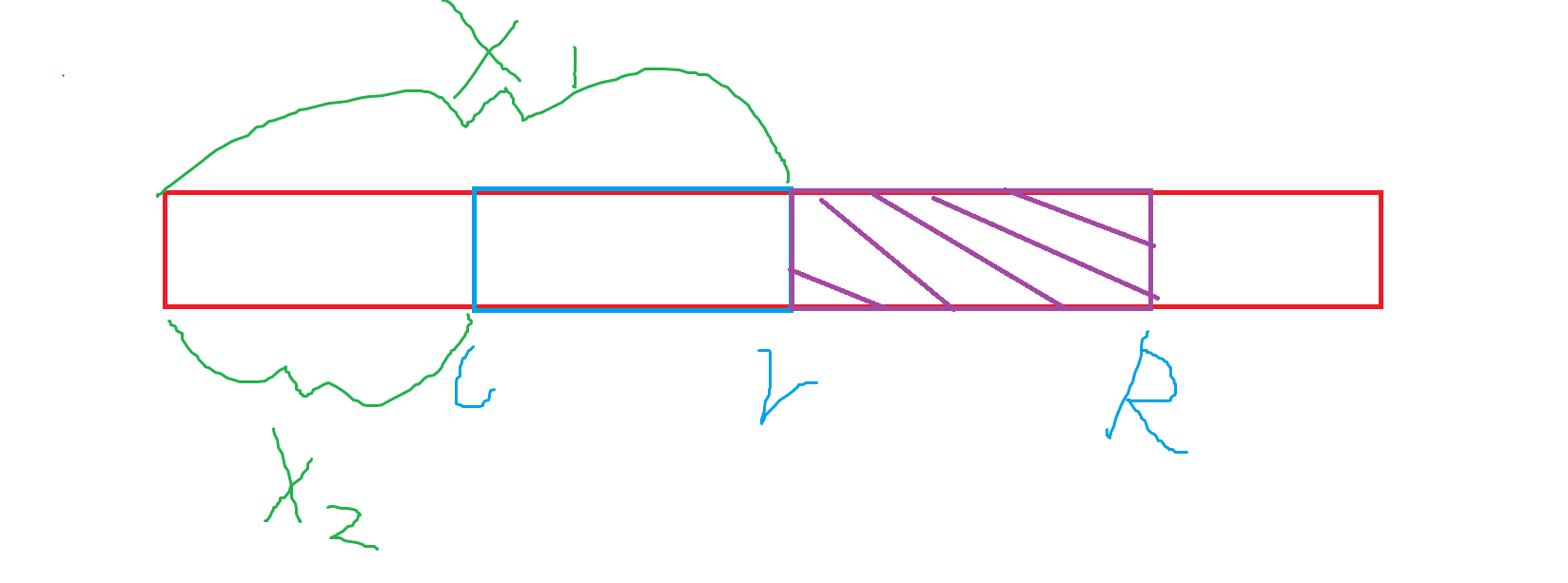
我们注意到,第一种贡献在这种情况下其实就是一个 \(单点对前缀集合的贡献\),我们可以直接暴力预处理出来,然后可以考虑直接前缀和做差,也可以考虑就单点修改就行。暴力预处理,就拿树状数组从左到右遍历前缀集合,然后预处理就行。时间复杂度为 \(O(n\log{V_{max}})\),然后我使用的就是莫队最基本的 \(add 和 del\) 时加入这部分贡献。
第二种贡献则是莫队二次离线的核心,也是难点。此时此刻抽象出来就是 \([r+1,R]\) 这部分新增的区间对 \([1,l-1]\) 这部分前缀集合的贡献。假如每个点都能做到 \(O(1)\) 查找,我们暴力的去算单个貌似复杂度并不高。但考虑这玩意抽象出来就是:
我们注意到总移动块长根据莫队的原理可以知道为 \(m\log{n}\),如果我们能做到 \(O(1)\) 查询,那么暴力完全够的。而这玩意抽象一下,不就是经典扫描线问题吗,当修改到某个前缀区间的时候再计算贡献,最多 \(n\) 次修改。那么之前提过的如何去平滑修改和查询的复杂度显然就是最经典的“值域分块”了。
具体的,我们这样维护。对于值域分块而言,我们分两类,一个是用于维护一整个值域块的信息,一个是维护值域块内的单点信息。而这里显然我们借助类似树状数组前缀和的思想,维护这些块的前缀信息即可。即前缀值域块信息,和值域块内的前缀单点信息。
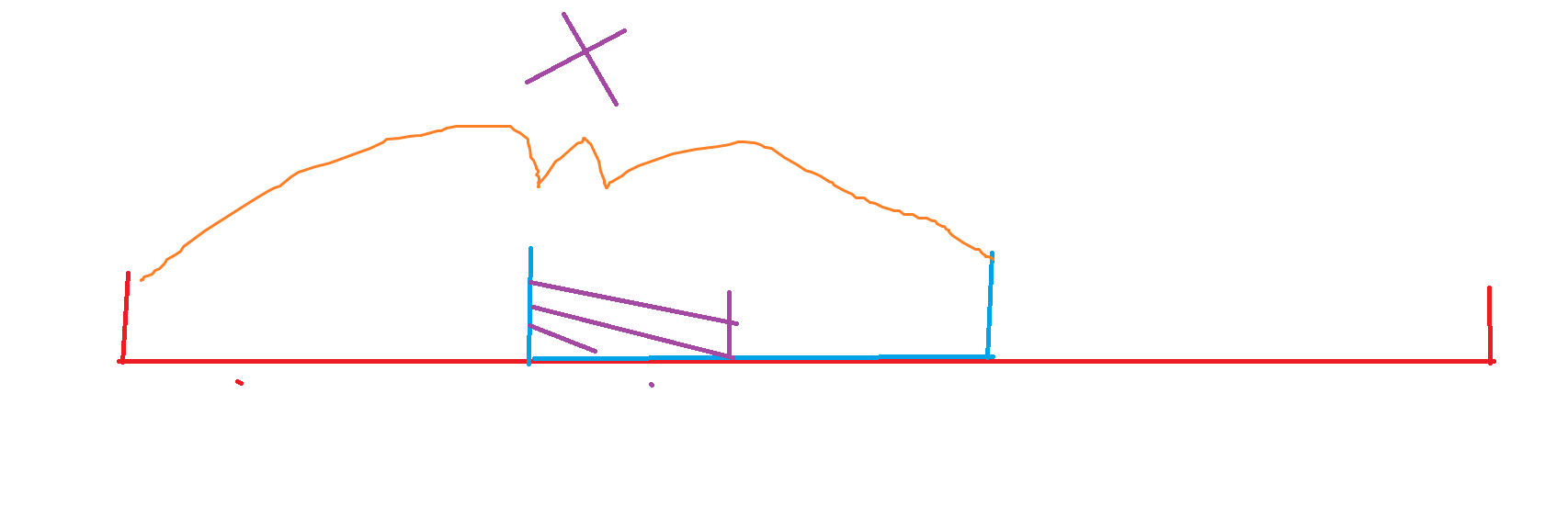
如图,蓝色就是一个值域块,我们维护值域块的前缀信息,就是对于当前块而言,前面所有值域块的总和 \(本题维护数量 cnt 与和 sum\),同时块内维护单点前缀和信息,即为紫色部分。查询的是先对块进行前缀和做差,拿到蓝色整块到最后最后一块的信息,然后我们再去掉单点前缀和的贡献,即紫色部分的贡献,如下图所示。
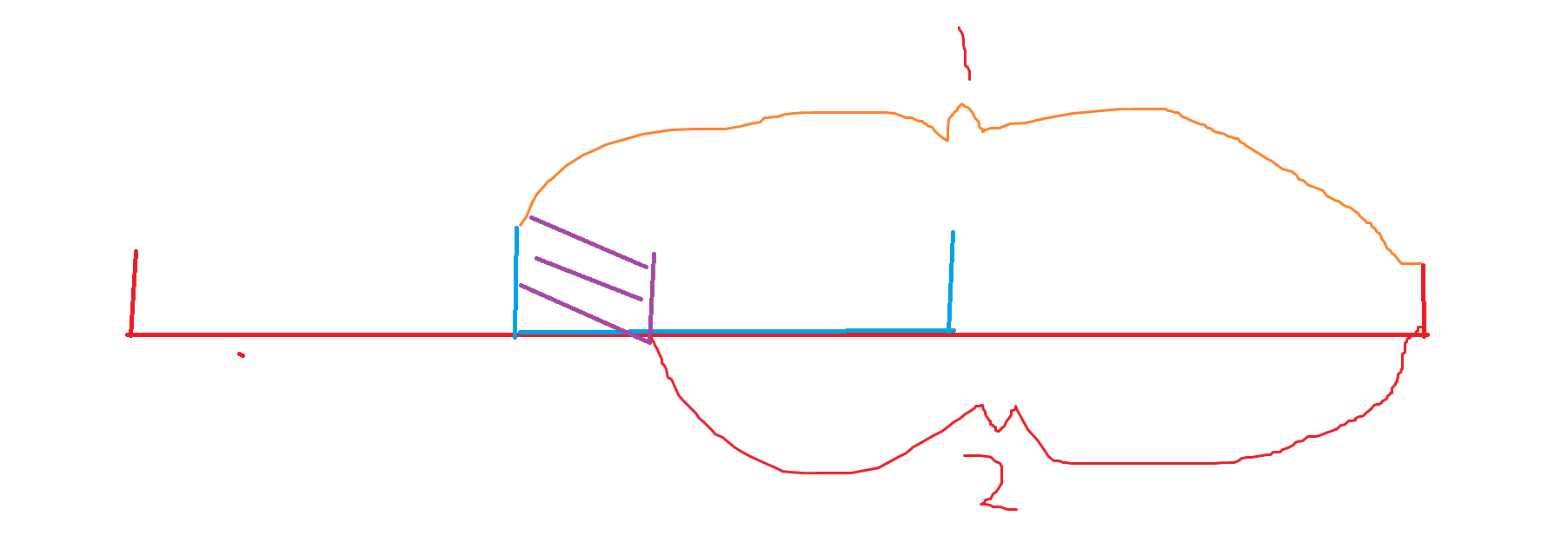
这样一来我们就可以 \(\sqrt{V_{max}} 的修改\),\(O(1) 的查询\)。这样一来就能拿到比某个数更大的数量以及它们的和,而小的数量,直接总数量做差即可得到。
所以上述第二部分贡献,我们可以用扫描线解决,记录下哪部分移动区间对哪部分前缀区间的影响,加还是减,其他三种情况可以同理可得。
最后的细节
注意下每次,我们的查询是 \(kth\),而不只是比它小的数量,记得 \(+1\),其次传统的扫描线都不从 \(0\) 开始,本题需要,因为究其原因是空集也有贡献,举个例子,\(1\) 加入到空集 \(\ \varnothing\) 当中,也是有 \(1\) 的贡献的。所以我们应当从下标为 \(0\) 开始扫描,还需要计算来自空集的贡献。然后注意下值域分块中我们查询的是 \(\ge x\) 的信息,所以很显然为我们查询的那个数需要 \(+1\),所以记得值域上界不是本题的 \(1e5\) 而是 \(1e5+1\)。而小于的数量,显然等于总的减去大于的数量再减去等于的数量,还需要注意每个答案是对前面那个查询的答案的差分,所以答案是需要最后算前缀和恢复的。剩余见注释即可。
参照代码
#include <bits/stdc++.h>
//#pragma GCC optimize("Ofast,unroll-loops")
#define isPbdsFile
#ifdef isPbdsFile
#include <bits/extc++.h>
#else
#include <ext/pb_ds/priority_queue.hpp>
#include <ext/pb_ds/hash_policy.hpp>
#include <ext/pb_ds/tree_policy.hpp>
#include <ext/pb_ds/trie_policy.hpp>
#include <ext/pb_ds/tag_and_trait.hpp>
#include <ext/pb_ds/hash_policy.hpp>
#include <ext/pb_ds/list_update_policy.hpp>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/exception.hpp>
#include <ext/rope>
#endif
using namespace std;
using namespace __gnu_cxx;
using namespace __gnu_pbds;
typedef long long ll;
typedef long double ld;
typedef pair<int, int> pii;
typedef pair<ll, ll> pll;
typedef tuple<int, int, int> tii;
typedef tuple<ll, ll, ll> tll;
typedef unsigned int ui;
typedef unsigned long long ull;
typedef __int128 i128;
#define hash1 unordered_map
#define hash2 gp_hash_table
#define hash3 cc_hash_table
#define stdHeap std::priority_queue
#define pbdsHeap __gnu_pbds::priority_queue
#define sortArr(a, n) sort(a+1,a+n+1)
#define all(v) v.begin(),v.end()
#define yes cout<<"YES"
#define no cout<<"NO"
#define Spider ios_base::sync_with_stdio(false);cin.tie(nullptr);cout.tie(nullptr);
#define MyFile freopen("..\\input.txt", "r", stdin),freopen("..\\output.txt", "w", stdout);
#define forn(i, a, b) for(int i = a; i <= b; i++)
#define forv(i, a, b) for(int i=a;i>=b;i--)
#define ls(x) (x<<1)
#define rs(x) (x<<1|1)
#define endl '\n'
//用于Miller-Rabin
[[maybe_unused]] static int Prime_Number[13] = {0, 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37};
template <typename T>
int disc(T* a, int n)
{
return unique(a + 1, a + n + 1) - (a + 1);
}
template <typename T>
T lowBit(T x)
{
return x & -x;
}
template <typename T>
T Rand(T l, T r)
{
static mt19937 Rand(time(nullptr));
uniform_int_distribution<T> dis(l, r);
return dis(Rand);
}
template <typename T1, typename T2>
T1 modt(T1 a, T2 b)
{
return (a % b + b) % b;
}
template <typename T1, typename T2, typename T3>
T1 qPow(T1 a, T2 b, T3 c)
{
a %= c;
T1 ans = 1;
for (; b; b >>= 1, (a *= a) %= c)if (b & 1)(ans *= a) %= c;
return modt(ans, c);
}
template <typename T>
void read(T& x)
{
x = 0;
T sign = 1;
char ch = getchar();
while (!isdigit(ch))
{
if (ch == '-')sign = -1;
ch = getchar();
}
while (isdigit(ch))
{
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
x *= sign;
}
template <typename T, typename... U>
void read(T& x, U&... y)
{
read(x);
read(y...);
}
template <typename T>
void write(T x)
{
if (typeid(x) == typeid(char))return;
if (x < 0)x = -x, putchar('-');
if (x > 9)write(x / 10);
putchar(x % 10 ^ 48);
}
template <typename C, typename T, typename... U>
void write(C c, T x, U... y)
{
write(x), putchar(c);
write(c, y...);
}
template <typename T11, typename T22, typename T33>
struct T3
{
T11 one;
T22 tow;
T33 three;
bool operator<(const T3 other) const
{
if (one == other.one)
{
if (tow == other.tow)return three < other.three;
return tow < other.tow;
}
return one < other.one;
}
T3() { one = tow = three = 0; }
T3(T11 one, T22 tow, T33 three) : one(one), tow(tow), three(three)
{
}
};
template <typename T1, typename T2>
void uMax(T1& x, T2 y)
{
if (x < y)x = y;
}
template <typename T1, typename T2>
void uMin(T1& x, T2 y)
{
if (x > y)x = y;
}
constexpr int N = 5e5 + 10;
constexpr int MX = 1e5 + 1; //值域上界
int n, m;
int pos[N]; //序列分块每个点的块编号
struct Mo
{
int l, r, id;
bool operator<(const Mo& other) const
{
return pos[l] ^ pos[other.l] ? l < other.l : pos[l] & 1 ? r < other.r : r > other.r;
}
} node[N];
ll bitCnt[N], bitSum[N]; //树状数组计算>=x的信息
ll curr[N]; //预处理每个数的前缀集合贡献
inline void add(int x, const int val)
{
while (x)bitSum[x] += val, bitCnt[x]++, x -= lowBit(x);
}
inline pll query(int x)
{
ll ans = 0;
ll cnt = 0;
while (x <= MX)ans += bitSum[x], cnt += bitCnt[x], x += lowBit(x);
return pll(cnt, ans); //大于等于数的数量,以及它们的和
}
vector<tii> seg[N]; //扫描线,[l,r,id],id为正则为+,否则为-
int a[N];
int preCnt[N], prePosCnt[N]; //值域块的前缀数量和块内的单点前缀数量
ll preSum[N], prePosSum[N]; //值域块的前缀和和块内的单点前缀和
int valPos[N], valCnt, valSize, s[N], e[N]; //值域块每个点下标编号,值域块数量,值域块大小,每个值域块的起点和终点
ll ans[N]; //答案
ll repeat[N]; //用于去掉等于的贡献
inline void addVal(const int val)
{
const int blockPos = valPos[val]; //找到值域块编号
forn(i, blockPos, valCnt)preCnt[i]++, preSum[i] += val;
forn(i, val, e[blockPos])prePosCnt[i]++, prePosSum[i] += val;
}
inline pll queryVal(const int val)
{
const int blockPos = valPos[val]; //找到值域块编号
ll ansCnt = 0, ansSum = 0;
ansCnt += preCnt[valCnt] - preCnt[blockPos - 1];
ansSum += preSum[valCnt] - preSum[blockPos - 1];
//要去掉[块起点,val-1]的信息,特判下就行,因为每个块前面不是下标0,无法得到pre[0]=0进行做差
//如果换成二维数组,每个块内编号可以取模得到:(val-1)%valSize+1,这种可以使用pre[0]=0,可以不需要特判
ansCnt -= val - 1 >= s[blockPos] ? prePosCnt[val - 1] : 0;
ansSum -= val - 1 >= s[blockPos] ? prePosSum[val - 1] : 0;
return pll(ansCnt, ansSum);
}
inline void solve()
{
cin >> n >> m;
const int siz = sqrt(n);
forn(i, 1, n)cin >> a[i], pos[i] = (i - 1) / siz + 1;
forn(i, 1, n)
{
auto [cnt,sum] = query(a[i] + 1);
curr[i] = (i - cnt - repeat[a[i]]) * a[i] + sum; //当前总共有i-1个数
add(a[i], a[i]);
repeat[a[i]]++;
}
memset(repeat, 0, sizeof repeat);
forn(i, 1, m)
{
auto& [l,r,id] = node[i];
cin >> l >> r, id = i;
}
sortArr(node, m);
int l = 1, r = 0;
//注意关于那个1的贡献
forn(i, 1, m)
{
auto [L,R,id] = node[i];
auto& Ans = ans[id];
if (l > L)seg[r].emplace_back(L, l - 1, id);
while (l > L)Ans += a[--l], Ans -= curr[l];
if (l < L)seg[r].emplace_back(l, L - 1, -id);
while (l < L)Ans -= a[l], Ans += curr[l++];
if (r < R)seg[l - 1].emplace_back(r + 1, R, -id);
while (r < R)Ans += a[++r], Ans += curr[r];
if (r > R)seg[l - 1].emplace_back(R + 1, r, id);
while (r > R)Ans -= a[r], Ans -= curr[r--];
}
//莫队二次离线算扫描线的贡献
valSize = sqrt(MX);
valCnt = (MX + valSize - 1) / valSize;
forn(i, 1, MX)valPos[i] = (i - 1) / valSize + 1;
forn(i, 1, valCnt)s[i] = (i - 1) * valSize + 1, e[i] = i * valSize;
e[valCnt] = MX;
forn(i, 0, n)
{
//特判空集不加入数
if (i)addVal(a[i]), repeat[a[i]]++;
for (const auto [l,r,id] : seg[i])
{
ll add_del = id / abs(id);
forn(j, l, r)
{
auto [Cnt,Sum] = queryVal(a[j] + 1);
Cnt = i - Cnt - repeat[a[j]] + 1; //总共是i个数
ans[abs(id)] += add_del * (Cnt * a[j] + Sum);
}
}
}
forn(i, 1, m)ans[node[i].id] += ans[node[i - 1].id];//最后答案是对前一个答案的差分,需要算前缀和恢复。
forn(i, 1, m)cout << ans[i] << endl;
}
signed int main()
{
Spider
//------------------------------------------------------
int test = 1;
// read(test);
// cin >> test;
forn(i, 1, test)solve();
// while (cin >> n, n)solve();
// while (cin >> test)solve();
}
