
Cache设计
Cache原理
利用程序的局部性原理,缩减CPU的访存时间,让CPU能够更好的发挥性能
- 空间局部性:最近被访问的块邻近的块很有可能被访问
- 时间局部性:最近被的访问的块很有可能被再次访问
Cache设计的两大原则
- 高命中率,要求高命中率减少块的置换操作
- 对CPU透明,即CPU访问内存和访问Cache为同一种方式,无需改变
Cache设计的四个问题
- 从主存取得的块如何在Cache中存放
- 如何访问主存放入Cache中的块
- 当Cache未命中时置换数据块的策略
- 怎样保持Cache块中数据与主存块的数据同步
三种Cache与主存地址映射策略
全相联映射
Cache数据块称为行,主存数据块称为块,其中行大小==块大小。全相联映射中,主存一个块地址、块号、块内容都被一起存于Cache的行中
主存中的块被复制到Cache的任意行中
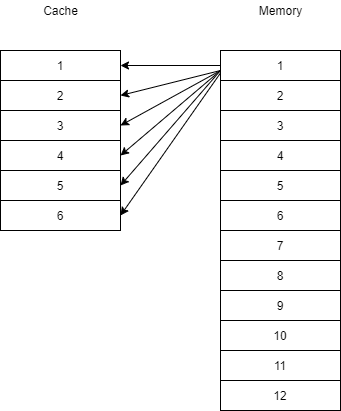
CPU访问一个主存地址时,为了快速检索,指令中的块号与Cache所有行号的标记同时在比较器中比较,若命中则从Cache中读取一个字,否则在主存地址中读取
全相联映射其主要缺点是高速比较器电路难于设计和实现,因此适合小容量Cache
直接映射
主存被划分为n个和Cache大小相同的区,区内的块只能存入对应Cache行内
Cache行号 i 和主存块号 j 关系为 i = j mode m,其中m为Cache的大小

直接映射其优点是硬件简单,成本低,地址变换速度快,但其缺点是每个主存块有一个固定行号可以存放。
当连续两个访存指令要求访问块号相距m整数倍的两个块时,因两个块同时映射到同一个Cache行内,所以会产生冲突,需要置换行块,导致置换操作频繁,降低Cache效率
组相联
将Cache划分为若干个大小相同的组,而主存不同区内,区内的对应块可以换入Cache对应的组中,在组中可以存放在任意行
当Cache分组的大小为1时,组内只有一个块,此时为直接映射;当Caceh分组大小为整个Cache大小时,只有一个分组,此时为全相联
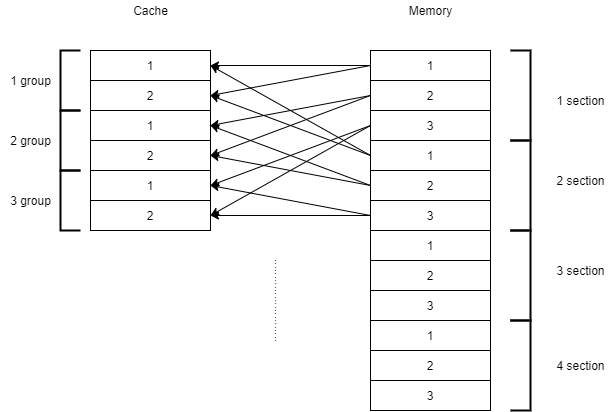
组相联模式结合了适度兼顾了全相联和直接映射的优点,被普遍采用
Cache替换策略
LFU算法
LFU,最不经常使用算法,将一段时间内被访问次数最少的行换出。每行设置一个计数器,当新行调入Cache,该新行计数器为0。当某个行被读取一次,该行的计数器+1,需要换出行时寻找到计数器最低的行将其换出。
LRU算法
LRU,近期最少使用算法,将近期内最长久未被访问过的行换出。同样如LFU为每行设置一个计数器,但是Cache行每次被命中其计数器清零,其它各行计数器+1,与LFU算法相反,需要置换出行时将计数器值最高的行换出
随机替换
随机换出行,无固定规则。研究表明随机替换的性能只是稍稍逊于前两种算法
Cache写操作策略
写回法
write back,copy back:CPU命中Cache时,只修改Cache行中的数据内容,仅当Cache该块被换出时,将数据写回主存;CPU未命中Cache时,将该块从主存复制到Cache行中,再对其修改。Cache中每行都置一个修改位,记录该块是否被修改,若该行被换出是修改位为0,则直接抛弃
写回法优点是减少访问主存的次数,但是写回法会导致Cache行中的数据与对应主存块中的数据不一致,产生隐患
全写法
write through:CPU命中Cache时,同时修改Cache行和主存块中的内容,主存和Cache同步;当CPU未命中Cache时,有两种策略,一是WTWA法,将主存块置换如Cache行中,对Cache行修改,另一种是WTNWA法,直接修改主存块,不置换入Cache中
全写法的优点是简单,Cache和主存同步,不会发生数据不一致,但是其频繁的访问主存操作导致Cache性能降低
写一次法
write once:CPU第一次命中Cache时,同时修改Cache行中和主存块中的内容,后面再命中时采用写回法的策略;CPU未命中时采用写回法策略
写一次法结合了写回法和全写法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号