
DDCA —— 内存一致性
 CS6810 Chapter 5. Multi-threading, Synchronization, Consistency. 的学习笔记,详细介绍了同步、构造锁、缓存锁、Test-and-Test-and-Set、负载链接和条件存储,以及内存一致性模型和事务内存。
CS6810 Chapter 5. Multi-threading, Synchronization, Consistency. 的学习笔记,详细介绍了同步、构造锁、缓存锁、Test-and-Test-and-Set、负载链接和条件存储,以及内存一致性模型和事务内存。
1. 同步(Synchronization)
1.1 构造锁(Locks)
- 原子(atomic)执行:应用程序的某些部分必须独占执行(原子性),这意味着在这些部分执行期间,其他并行进程无法访问或修改相关数据。比如一个账户转账操作,需要保证资金不会被同时修改,避免出现不一致的状态。
- 锁的作用:锁(Lock)用于保护数据或代码块,确保在某个时间点只有一个进程可以进入关键部分(Critical Section)。当一个进程获取锁后,其他进程必须等待,直到锁被释放为止,从而保证数据的安全访问。
- 硬件原语:硬件需要支持一些基本操作(如原子性操作)来帮助实现锁。这些操作可以是硬件级别的指令(如原子加锁指令)或者其他机制,提供构建锁所需的功能。
- 缓存一致性机制:锁的正确性依赖于缓存一致性机制。也就是说,当一个进程更新锁的状态时,其他进程最终会感知到这个更新。例如,如果一个进程将锁设为“占用”状态,其他进程可以通过缓存一致性机制感知这个状态并等待。
1.2 同步(Synchronization)
-
最简单的硬件原语是原子读-改-写(atomic read-modify-write),它极大地简化了同步的实现(如锁(locks)、屏障(barriers)等)。
-
原子交换:交换寄存器和内存的内容。原子交换确保了在执行这一操作时,不会有其他处理器或线程同时访问该内存位置。通过原子交换,可以实现对共享资源的排他性访问。

-
测试并设置(Test & Set):这是原子交换的一个特殊应用,用于检查内存 Lock 的状态,并将该 Lock 设置为1。操作步骤如下:
-
首先将内存 Lock 的内容加载到寄存器中。
-
将该内存 Lock 设置为1。
测试并设置(Test & Set)操作的结果是可以判断某个位置是否已经被占用,通常用于实现锁机制。
如果该 Lock 变量中为 0,则表示当前没有人持有该 Lock,并且没有人正在执行临界区(Critical Section),这样其他人就可以继续获取该 Lock;
-
-
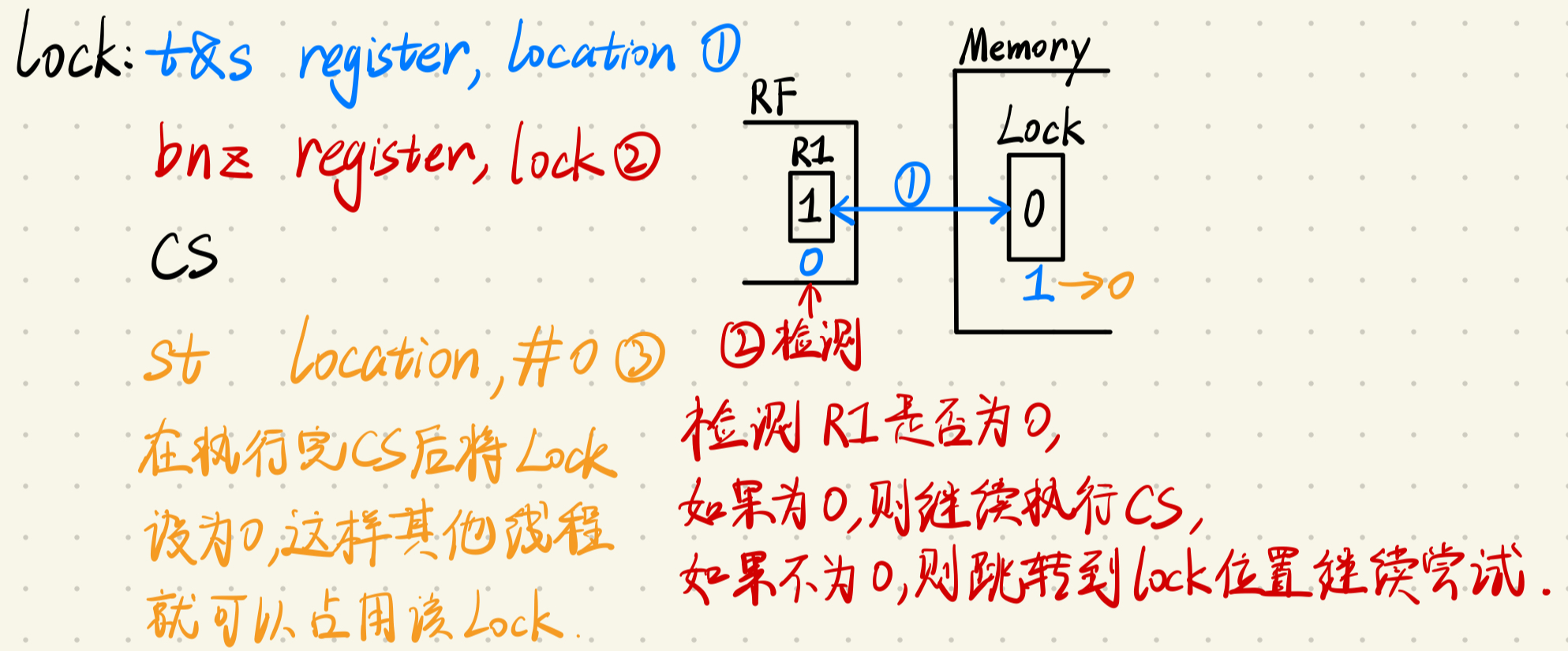
lock 的实现示例:
lock: t&s register, location bnz register, lock ;检查寄存器的内容,如果不为零, ;则意味着锁已经被其他进程占用,当前进程需要继续等待。 CS ;表示临界区(Critical Section),即访问共享资源的代码段 ;只有获得锁的进程可以进入该区域。 st location, #0 ;退出临界区后,将内存位置重置为0,释放锁。
假设一开始 Lock 未被获取,即它是空闲的,其他线程可以自由地进入这个临界区(Critical Section)。
1.3 缓存锁(Caching Locks)
在传统的自旋锁机制中,如果锁存在于内存中,每次获取锁的尝试都会导致总线上产生大量通信流量(因为每次操作都需要访问内存)。这会造成总线拥堵,导致其他进程难以进行有效的进展。
通过引入缓存锁,可以解决这个问题。具体来说:
- 缓存锁的好处:将锁存储在缓存中,而不是直接存储在内存中。这样,每次更新锁时,通过缓存一致性协议可以确保其他处理器能够及时看到锁的状态更新。
- 独占访问:一旦一个进程成功获取了锁,它会以“独占”状态持有锁,这样可以直接在缓存中更新锁的状态,而不需要频繁访问内存。
- 本地自旋:其他等待锁的进程可以在各自的本地缓存副本上进行自旋操作,而不是直接访问内存。这种方式减少了总线上频繁的通信流量,降低了系统开销。

1.4 锁的一致性 Traffic(Coherence Traffic for a Lock)
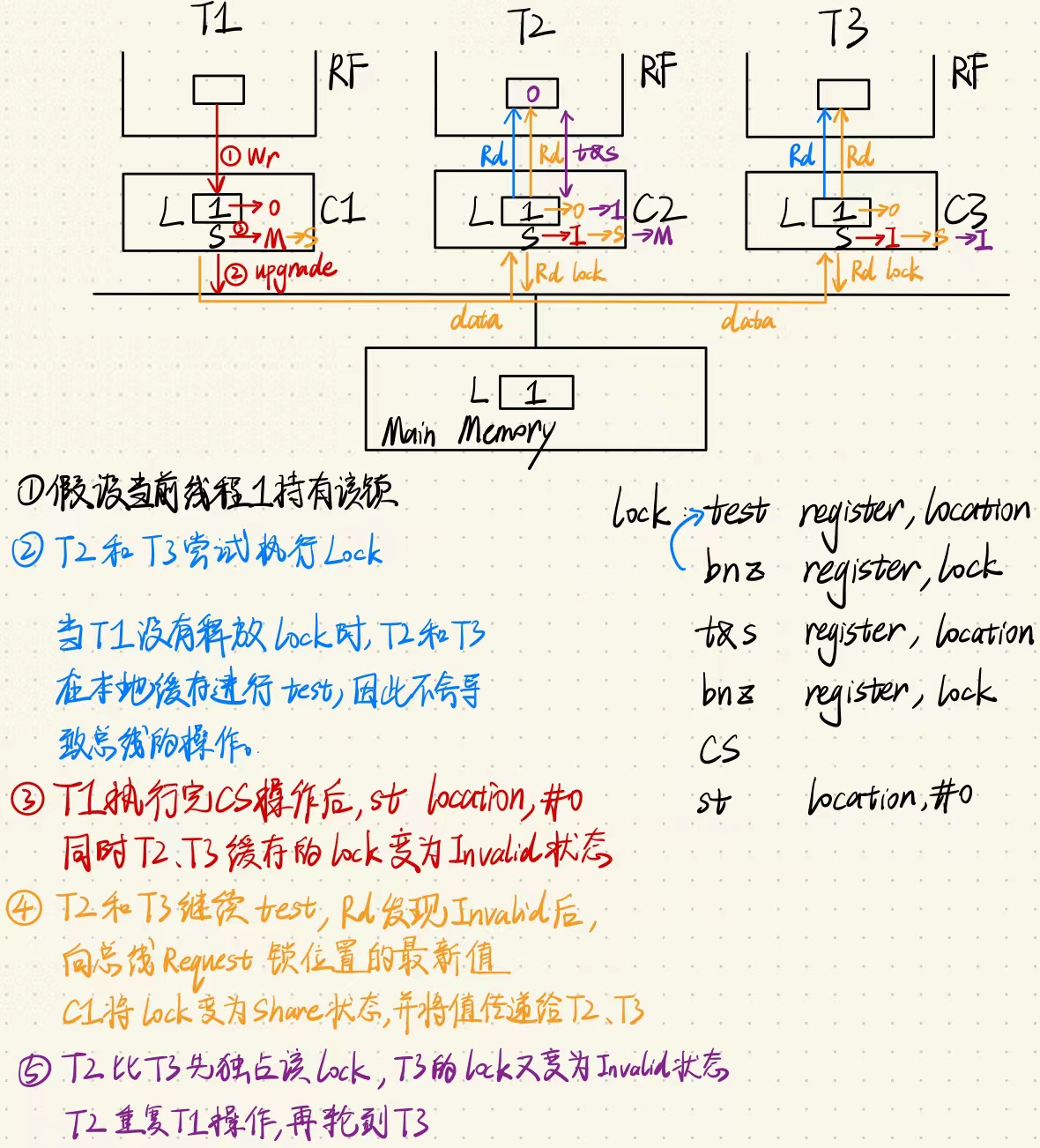
在多处理器系统中,锁机制通常用于控制对共享资源的访问。为了减少不必要的一致性流量,锁的一致性协议会采取一定措施,尽量减少在等待锁时的通信开销。即test & test & set。
- 自旋锁和写操作:当多个进程在等待一个锁时,如果每个进程直接进行交换操作(写操作),则每次交换都会触发无效操作,迫使其他进程的缓存副本失效,导致锁的所有权不断在进程之间转换。这会产生大量的一致性流量。
- 读取本地副本减少流量:为了减少一致性流量,等待锁的进程可以通过读取本地缓存副本的方式进行自旋。读取操作不会生成一致性流量,因此,多个进程可以在各自的缓存中自旋,而不会干扰其他进程的缓存状态。
- 锁释放和重新获取:当锁拥有者将锁值设为0以释放锁时,其他进程缓存中的锁副本会被无效化。此时,每个等待进程会尝试读取锁状态,这会导致缓存未命中,从而重新获取该缓存块的副本。如果进程读取到0,则它会尝试执行交换操作(需要获取该块的独占状态)。第一个获取到独占状态的进程将获得锁,而其他进程则继续自旋等待。
这种机制减少了不必要的一致性流量,使得锁的管理更加高效,同时确保了对共享资源的访问控制。
1.5 Test-and-Test-and-Set
lock: test register, location
bnz register, lock
t&s register, location
bnz register, lock
CS
st location, #0
1.6 负载链接(Load-Linked,LL)和条件存储(Store Conditional,SC)
Load-Linked(LL)和 Store Conditional(SC)是一种用于实现原子操作的机制,通常在并发编程中用于实现线程安全的操作。与其他锁机制相比,LL-SC 提供了更灵活且低开销的原子操作方式。
-
Load-Linked (LL):LL 操作读取一个内存地址的值,并在内部的某个表中记录这个地址。此后,处理器可以进行一些计算,而不立即锁定或更新这个地址。
-
Store Conditional (SC):SC 操作试图将值写入与 LL 操作相同的内存地址,但只有在该地址自 LL 操作以来没有被其他进程或线程修改过时,SC 操作才会成功。这种机制确保了在没有其他干扰的情况下,该 LL-SC 操作可以被视为原子的。
LL 读取 x 存入 R1,并将 X 地址放入一个表中,该表监视其他进程是否修改过 x,对 R1 进行一系列操作后,SC R1 至 x,若 x 没有被修给过则 SC 成功;若 x 被修改过,则 SC 失败,并在 R1 中设置一个 tag。在该操作完成后检查 R1,若 R1 没有问题,则命令完成,若 R1 被设置了 tag,则重新执行该命令。
在实现中,SC 操作在失败时不会产生总线流量(不需要进行额外的数据传输),这样减少了缓存一致性协议带来的通信开销。因此,LL-SC 的硬件实现比传统的 test&test&set 更加高效,因为后者在失败时需要不断地重试并产生大量总线流量。
总结来说,LL-SC 机制既允许较高的并发度,又降低了硬件和通信开销,因此常用于需要高效原子操作的并行系统中。
1.7 低一致性 Traffic 的自旋锁
lockit: LL R2, 0(R1) ;加载链接指令(Load Linked),将R1+0处的数据加载到寄存器R2中
;这条指令不会引发缓存一致性流量,意味着它不会使缓存内容无效化。
BNEZ R2, lockit ;当锁不可用时,程序会一直“自旋(spin)”在这里
DADDUI R2, R0, #1 ;put value R0+1 in R2
SC R2, 0(R1) ;store-conditional succeeds if no one
;updated the lock since the last LL
BEQZ R2, lockit ;confirm that SC succeeded, else keep trying
- 如果有 i 个进程在等待锁,有多少个总线事务?
- 1 次写事务:释放者(Releaser)执行解锁操作。
i次读未命中(read-miss)请求:所有等待的进程都会尝试读取锁的状态,这会导致i次读未命中请求。i次(或 1 次)响应:缓存系统返回i次读未命中请求的响应,可能是每个请求都有响应,也可能是只需要一次响应就能满足所有等待者。- 1 次写事务:成功获取锁的进程(Acquirer)执行写操作,以表示锁已被占用。
- 0 次
SC失败:假设在一次SC成功之前没有其他进程更改锁状态,则SC只需一次即可成功。失败的SC计数为零。 i-1次读未命中请求:剩余的i-1个进程将继续尝试获取锁状态,从而发出i-1次读未命中请求。i-1次(或 1 次)响应:与之前类似,系统可能为每个读未命中提供独立的响应,也可能通过一次响应满足所有请求。
优化点:i 和 i-1 的读未命中请求及其响应可通过缓存机制减少到 1 次,以进一步降低总线事务的数量。
1.8 带宽需求的进一步减少
- Ticket Lock(票据锁):
每个到达的进程都会自动获取一个票据并递增票据计数器(使用LL-SC指令完成)。获取票据后,进程会不断检查now-serving变量,看看是否轮到自己执行。执行完成后,该进程会将now-serving变量递增,允许下一个排队的进程进入。- 解释:票据锁通过分发“票据”来实现公平性,使每个进程按到达顺序进入临界区。进程在等待期间只需检查
now-serving变量,无需反复发送请求,降低了带宽需求。
- 解释:票据锁通过分发“票据”来实现公平性,使每个进程按到达顺序进入临界区。进程在等待期间只需检查
- Array-Based Lock(基于数组的锁):
这种锁机制不使用单一的now-serving变量,而是采用一个now-serving数组,每个进程等待属于自己的特定数组元素。- 特点:这种方式实现了公平性,低延迟,低带宽需求,并具有高扩展性。
- 解释:由于每个进程都等待在不同的变量上,因此在争用时不会相互影响,减少了总线带宽压力。然而,这种方法需要更多的存储空间来维护数组。
- Queueing Locks(队列锁):
队列锁由目录控制器(directory controller)记录请求的到达顺序。当锁变为可用时,控制器将锁传递给下一个排队的进程。这样只有一个进程会收到无效和更新通知。- 解释:这种方法确保进程按到达顺序依次获得锁,减少了多个进程反复请求导致的通信和带宽开销。由于仅有一个进程会收到锁状态的更新,无效化流量也得到了控制。
2. 内存一致性模型(Memory Consistence Model)
2.1 Coherence Vs. Consistency
Coherence(缓存一致性):
- 缓存一致性关注的是单个内存地址的操作规则。
- Write Propagation:比如,多个核心可能同时访问一个内存地址。缓存一致性保证,当某核心对该地址写入一个值时,其他核心最终会看到这个值,而不会永久停留在旧的状态。
- Write Serialization:同时,它也要求对同一内存地址的写操作有一致的顺序(全局一致性)。无论在哪个核心,所有人都必须以相同顺序观察这些写操作。
- 即:对于
x,看到x <- 5, x <- 7顺序一致 - 但是:对于
x, y,看到x <- 7, y <- 8顺序不一定一致
- 即:对于
Consistency(一致性模型):
- 一致性模型则是更广泛的概念,定义了对多个内存地址进行操作的行为规则。例如:
- 顺序一致性是最严格的一种模型,要求所有核心观察到的指令执行顺序与程序中写明的顺序一致。
- 更弱的模型可能允许某些优化,如乱序执行,导致不同核心看到的操作顺序不同。
- 即:对于
x, y,看到x <- 7, y <- 8顺序一致
- 硬件会提供一个特定的模型,程序员需要在这个模型下工作,编写能够正确运行的程序。
2.1.1 程序示例
-
Sequential Consistency
- Program order
- 每条指令都以原子方式执行
2.2 Sequential Consistency(顺序一致性)

假设:
- 在一个程序中,程序的顺序得以保留。
- 每条指令以原子方式执行。
- 不同线程的指令可以以任意方式交错执行。
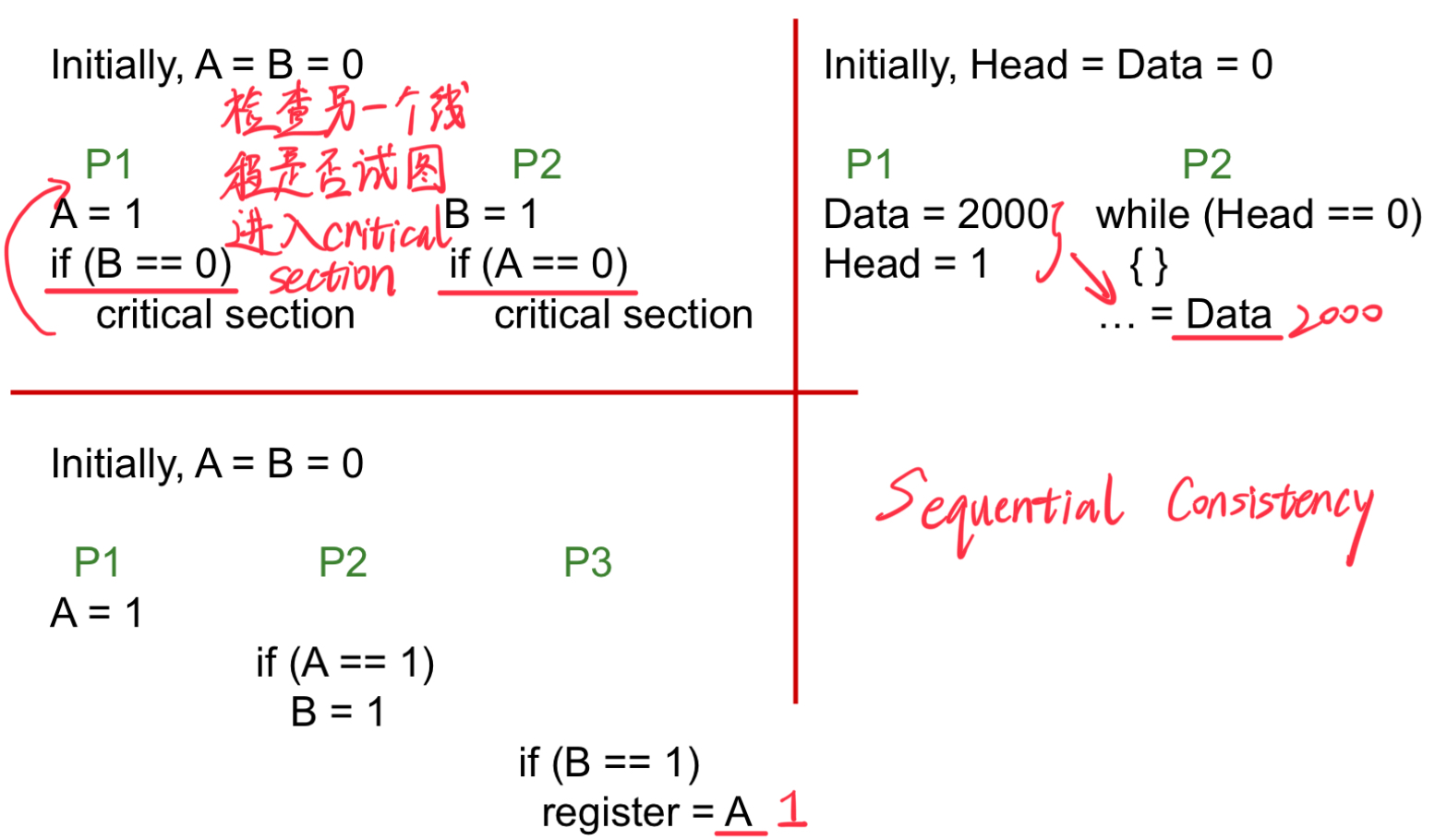
有效执行序列(Valid executions):
abAcBCDe...ABCDEFabGc...abcAdBe...aAbBcCdDe...- ...
顺序一致性(Sequential Consistency,SC)是一种内存一致性模型,规定所有处理器对共享内存的读写操作,必须看起来以全局固定的顺序执行,并且这种顺序与各处理器的程序顺序一致。
程序员通常假设程序具有顺序一致性,这使得推理程序行为变得更加简单。
然而,硬件创新可能会破坏这种顺序一致性模型。
例如,如果我们引入写缓冲区、乱序执行,或者在一致性协议中丢弃确认信号(ACKS),那么以前运行正常的程序可能会产生意外的输出。
-
写缓冲区(Write Buffers):写操作先存入缓冲区,延迟写入内存,可能导致其他处理器看到的是旧值,而非最新值。
-
乱序执行(Out-of-Order Execution):为了提高性能,处理器可能重新排序指令的执行顺序,导致程序的操作顺序看起来与源码不一致。
-
丢弃ACKS(Acknowledgment):在缓存一致性协议中,ACK用于确保更新操作被其他处理器确认。如果ACK丢失或被忽略,可能导致不同处理器对内存的视图不一致。
2.2.1 Consistency Example-1
一个乱序执行(Out-of-Order, OOO)核心不会检测到处理 A 的指令和处理 B 的指令之间的依赖性;因此,这些操作可能被重新排序。这种情况对单线程是没有问题的,但在多线程中会引发问题。
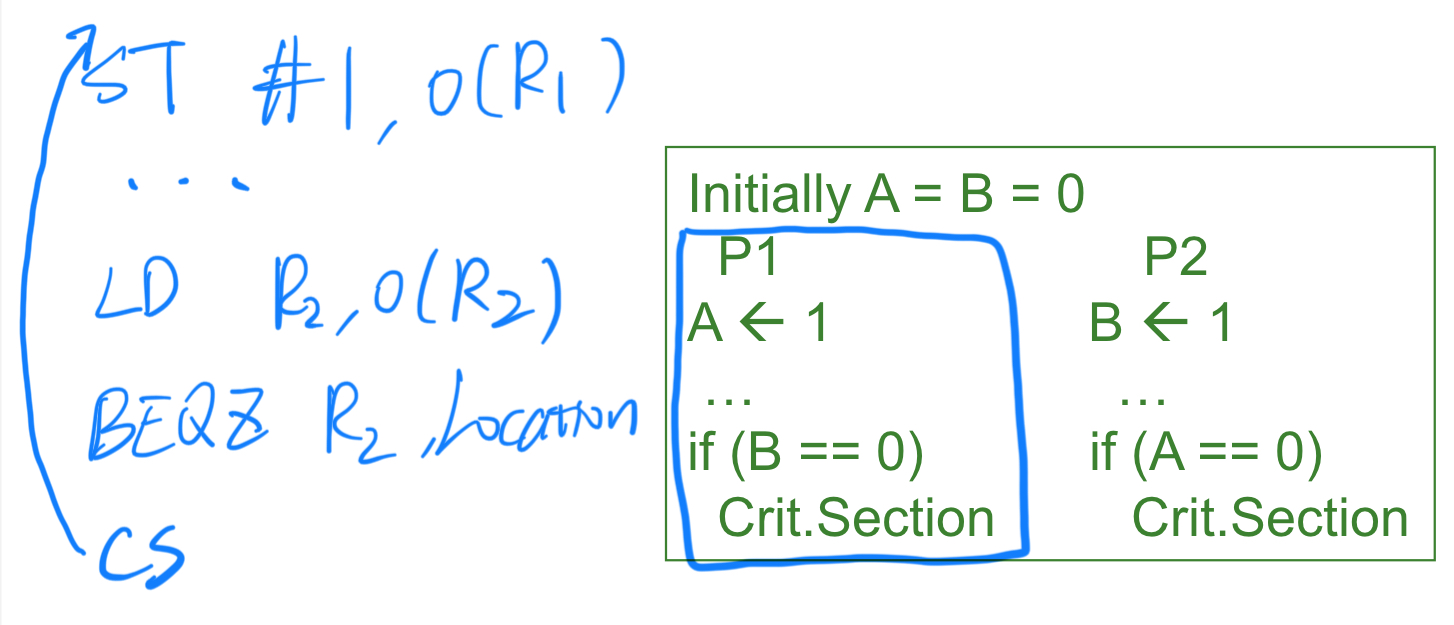
说明:一致性模型允许程序员了解硬件可以进行哪些操作重排的假设。
2.2.2 Consistency Example-2
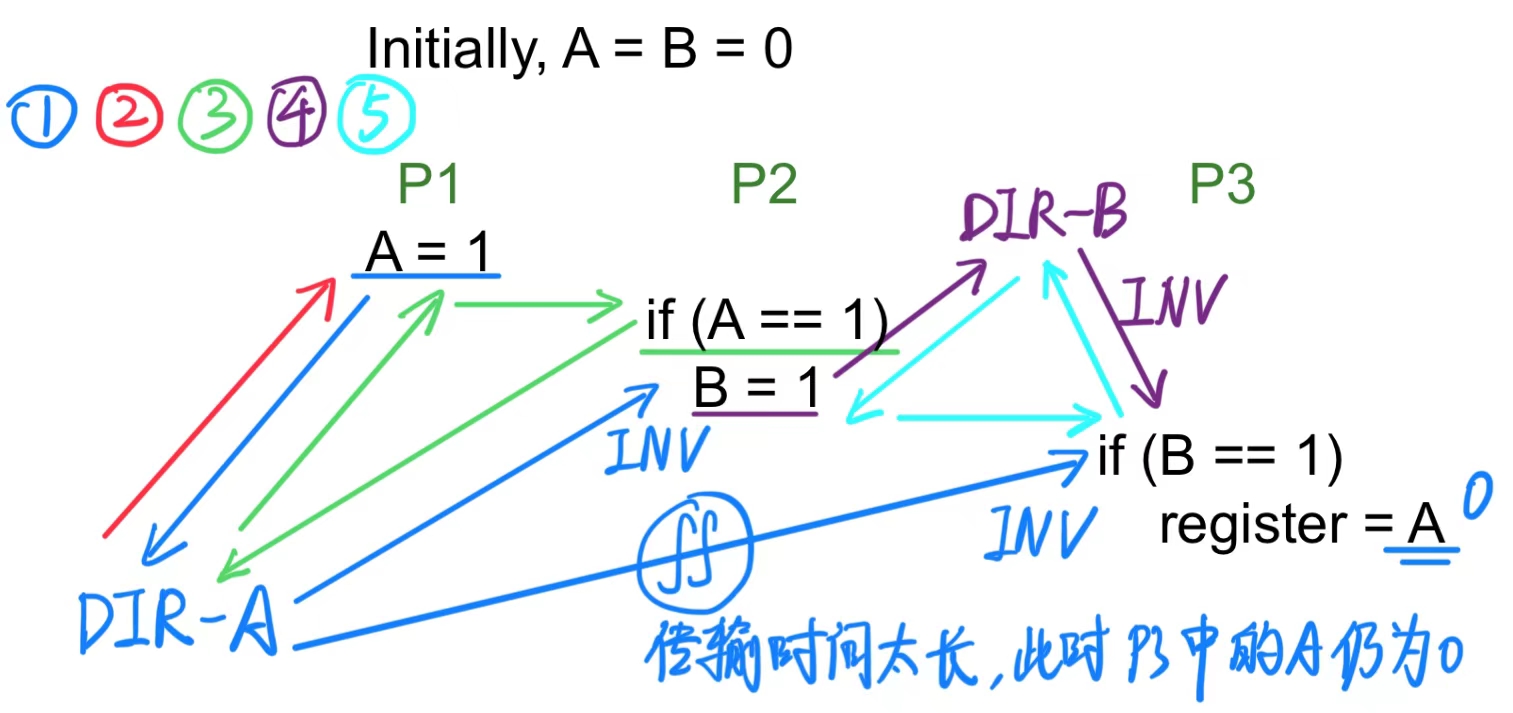
如果一致性协议中的无效操作(Coherence Invalidation)不需要确认信号(ACKs),我们无法确保所有线程都看到 A 的最新值。
就如上图中由于 DIR-A 的 INV 信号传输到 P3 的传输时间太长,导致 P3 执行时没有读取到 A=1。
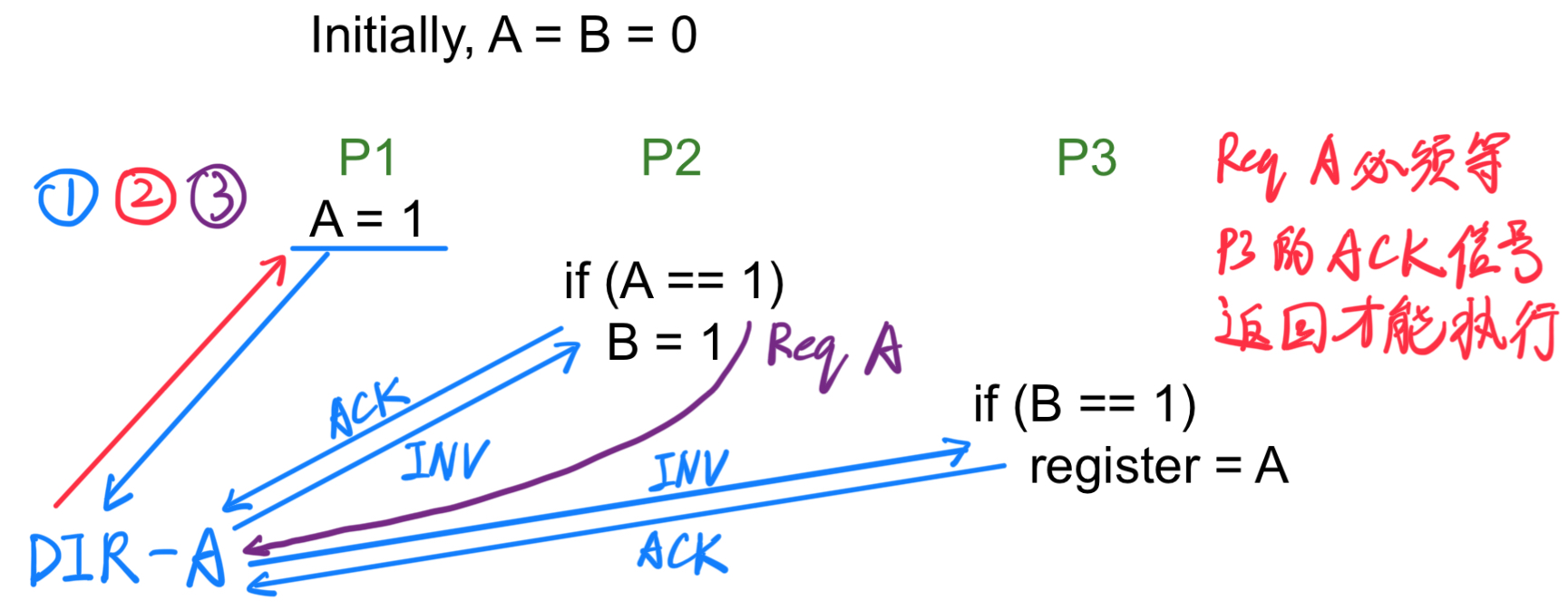
在有 ACK 信号的传输过程如上所示,P2 的 Req A 信号必须等 P3 的 ACK 信号返回才能执行。
2.2.3 总结
如果一个多处理器系统的执行结果可以通过以下方式实现,则该系统是顺序一致的:
- 在每个处理器内部保持程序指令的执行顺序;
- 不同处理器对内存的访问以任意顺序交错执行。
可以通过以下方法实现顺序一致性:
- 保持程序顺序:每个处理器内的指令按照编程的先后顺序执行;
- 写操作序列化:确保所有处理器以相同的顺序观察到对共享变量的写操作;
- 先更新后读取:一个值在被读取之前,所有处理器都必须看到这个值的更新。
这种模型对于程序员来说非常直观,但执行效率极低。
由于这种方法非常慢,有以下替代方案:
- 对硬件进行优化(例如,验证加载操作);
- 提供一个放松的内存一致性模型,并使用内存屏障(fences)来控制关键操作的顺序。
2.3 Relaxed Consistency Models(放松一致性模型)
我们希望拥有一种直观的编程模型(例如顺序一致性),同时也希望实现高性能。
在程序的某些部分,我们关心数据竞争(data races)和指令重排(reordering)的限制,而在其他部分则不太关注。
因此,大多数情况下我们会放松顺序一致性的约束,但在代码的特定部分会严格执行这些约束。
内存屏障指令(Fence instructions) 是一种特殊的指令,要求在它之前的所有内存访问必须完成之后,才能继续执行接下来的操作(达到顺序一致性的效果)。
2.3.1 Fences
定义:Fence 指令是一种显式的同步机制,用于强制某种顺序的内存访问。
功能:
- 在执行后续操作之前,Fence 指令要求所有之前的内存访问(读写操作)必须完成。
- 它有效地为代码中插入了一个屏障,确保之前的操作在程序和硬件层面都不会被乱序执行。

3. 事务内存(Transaction Memory)
3.1 事务(Transactions)
-
锁机制的问题
-
复杂性:使用锁进行同步时,程序员必须手动管理共享资源,确保每个线程正确加锁和解锁。这容易出错,尤其是在复杂的多线程程序中。
-
死锁风险:如果线程按照错误的顺序获取多个锁,或者一个线程忘记释放锁,会导致程序无法前进(即死锁)。
-
性能问题:锁是阻塞的,这意味着一个线程持有锁时,其他线程必须等待,从而可能降低并行性。
-
-
事务内存的引入
事务内存是一种硬件或软件机制,用于替代传统锁同步,简化并行编程:
- 核心思想:程序的并发部分以事务的形式运行,类似数据库事务的概念。
- 事务开始:标记一段代码开始执行。
- 投机执行:事务内部的所有操作会暂时保存在缓冲区中,而不会立即更新到共享内存。
- 事务结束:检查是否存在冲突(如两个事务同时修改了同一资源)。
- 如果没有冲突,事务的结果提交到共享内存。
- 如果检测到冲突,事务会回滚(取消),并可能重新执行。
- 这样,不需要显式地使用锁,避免了死锁和其他同步错误。
- 核心思想:程序的并发部分以事务的形式运行,类似数据库事务的概念。
-
优势
- 提高性能:锁的阻塞机制可能导致性能瓶颈,而事务采用投机执行,大大提高了并行效率。
- 消除死锁:没有显式的加锁操作,自然避免了由于锁管理不当导致的死锁问题。
- 简化编程:程序员只需将关键代码块用
transaction begin和transaction end包裹,无需担心加锁解锁的复杂性。硬件/软件会自动管理事务的冲突检测和回滚。
3.1.1 Example-1
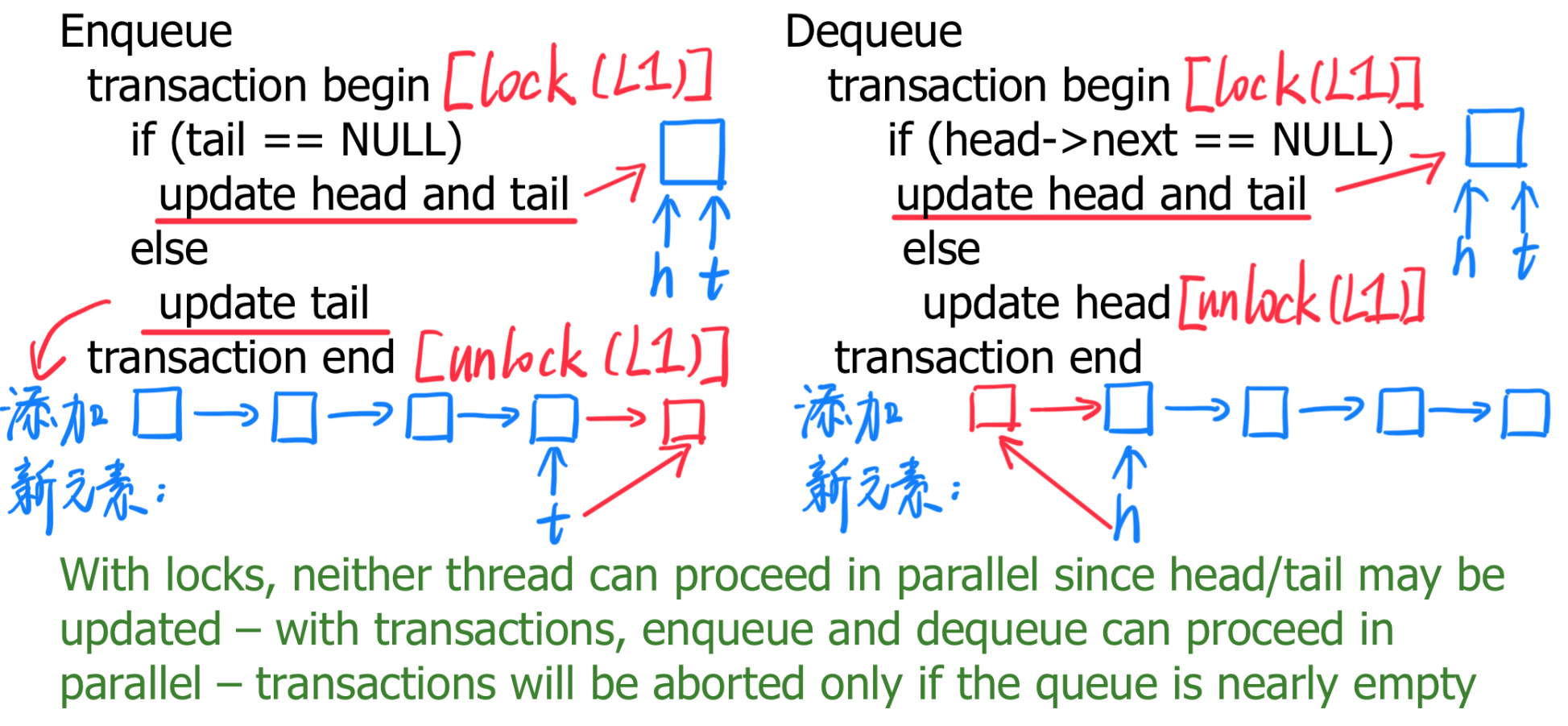
- Producer-consumer关系:
Producer将任务放入工作队列的尾部(tail),consumer从工作队列的头部(head)拉取任务。- 使用锁的缺点:由于
head和tail的更新需要加锁,两个线程(Producer和consumer)无法并行进行操作。 - 使用事务的优势:
- 入队(enqueue)和出队(dequeue)操作可以并行进行。
- 只有当队列几乎为空时,事务才会中止(abort)。
3.1.2 Example-2
-
如下图所示,
T1只改变了head,T2只改变了tail,那么这两个事务可正常执行。
-
如下图所示,
T1改变了head和tail,T2只改变了tail,那么T2不能正常执行,事务会回滚(abort)到开始状态,并尝试重新执行。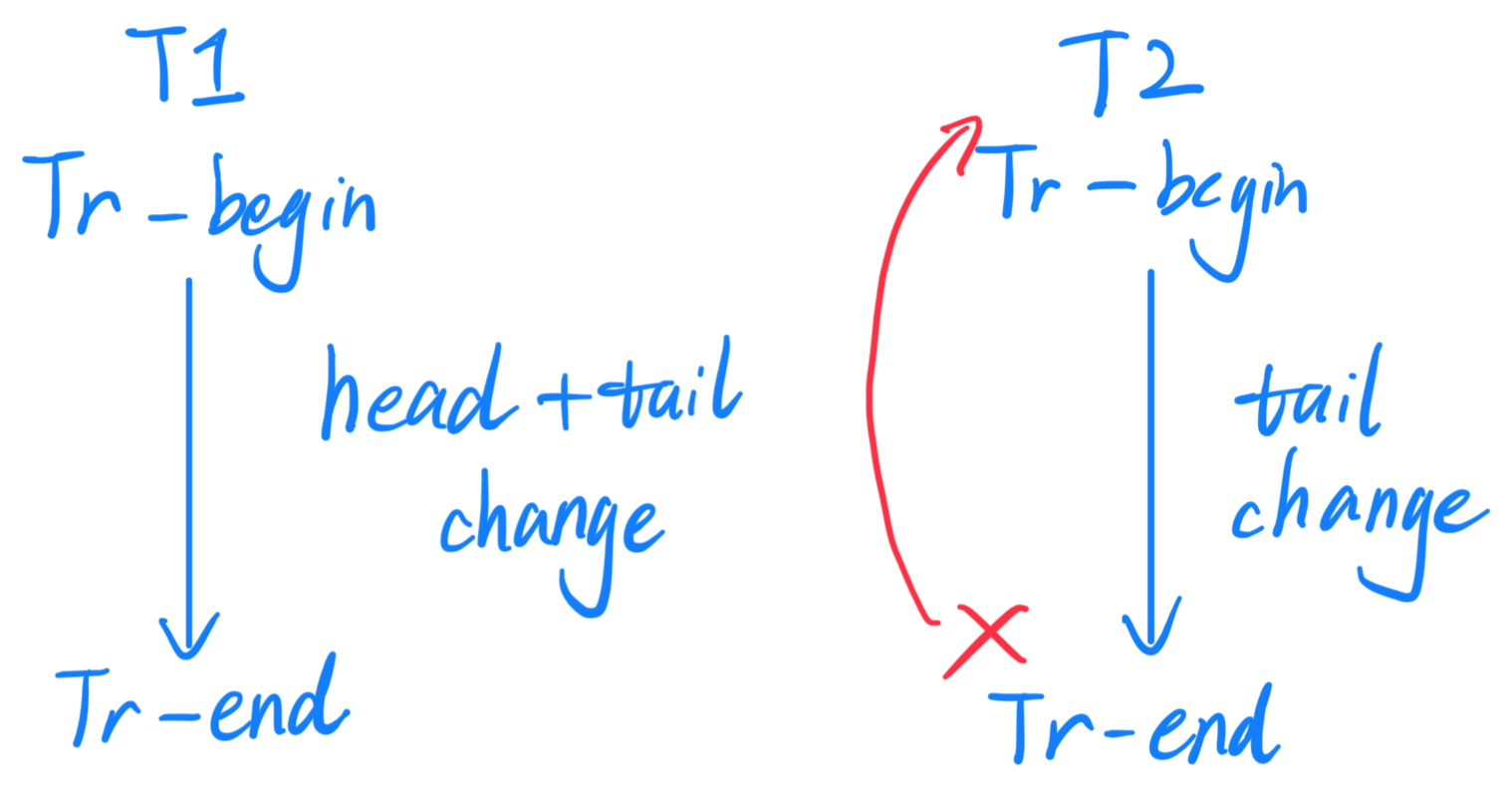
3.1.3 事务语义(Transactional Semantics)
-
隔离性
事务的隔离性意味着,当事务正在执行时,其他事务或线程无法看到它的中间状态,或者影响它的操作。事务会表现得像是在一个独立的环境中运行,直到它完成后,才将结果提交到共享系统。这种特性使得事务操作对程序员来说更加直观和可靠。
-
原子性
原子性指事务的所有操作(读、写等)要么全部完成,要么全部不完成。这确保了:
-
如果事务被中途打断(如发生冲突或系统问题),不会留下任何不完整的状态。
-
事务的结果是要么成功提交所有操作,要么将所有改变回滚到事务开始前的状态。
-
-
事务失败和重试
如果在事务执行过程中,出现以下问题:
-
冲突:例如,其他线程同时修改了事务要操作的共享变量。
-
系统错误:例如,资源不可用或事务无法满足一致性要求。
事务会回滚(abort)到开始状态,并尝试重新执行。这种机制可以自动解决数据冲突,减轻程序员的负担。
transaction begin // 事务开始 read shared variables // 读取共享变量 arithmetic // 执行算术运算或其他逻辑 write shared variables // 修改共享变量 transaction end // 事务结束(如果事务满足条件(如没有冲突),则提交所有操作) -
3.2 事务内存(TM)实现
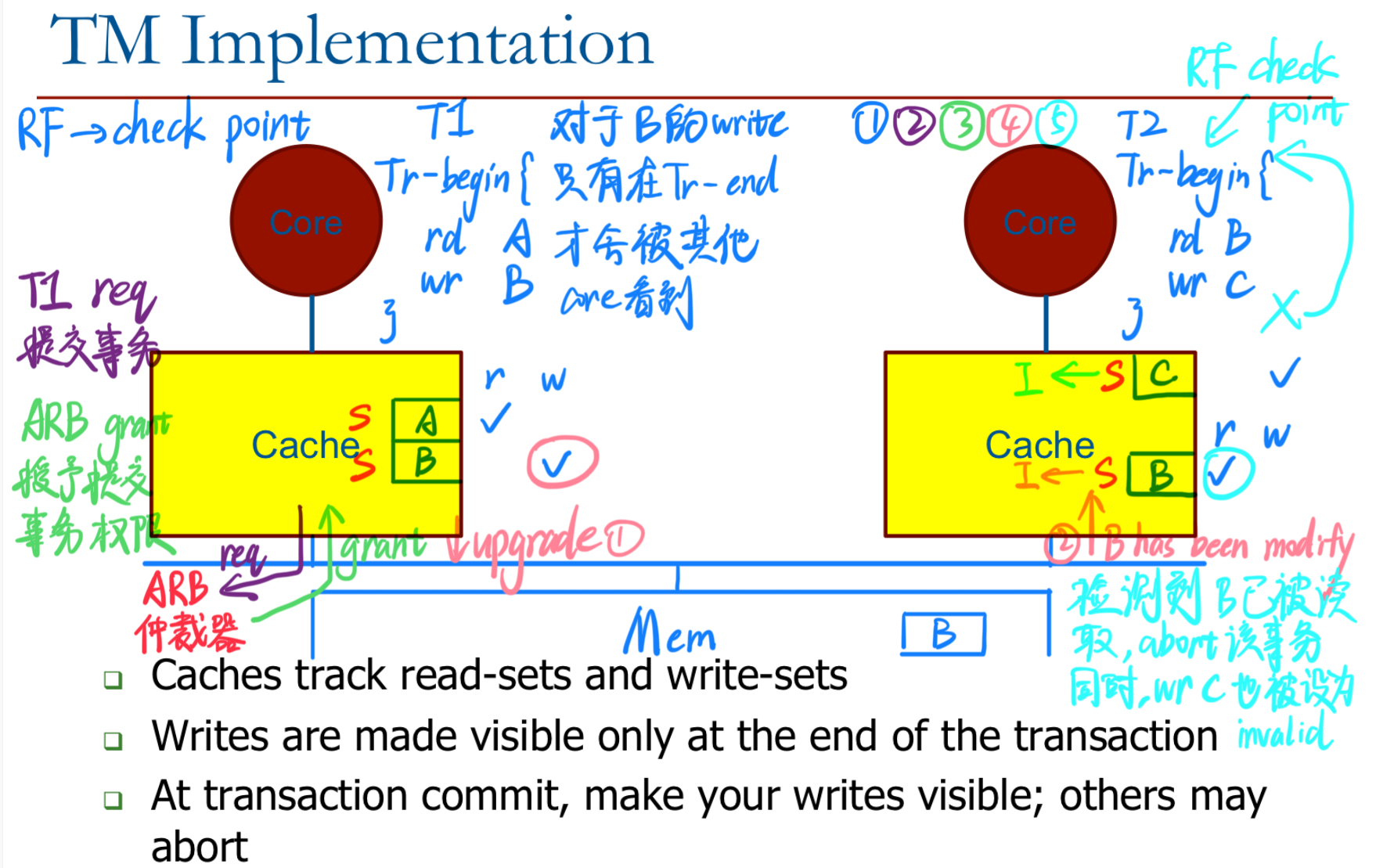
- 缓存跟踪事务中的读取集合(read-sets)和写入集合(write-sets)。
- 写入操作仅在事务结束时才对其他内核可见。
- 在事务提交时,将事务的写入操作对其他内核可见;如果检测到冲突,其他事务可能会回滚(abort)。
3.2.1 检测冲突 - 基本实现
写操作可以缓存(不能直接写入主存):
- 如果缓存块需要被驱逐,标记为溢出(暂时中止事务)。
- 在事务中止时,使写入的缓存行无效。
跟踪读取集合和写入集合:
- 对每个事务,缓存中设置位(bits)以记录读取集合(read-set)和写入集合(write-set)。
在其他事务提交时进行比较:
- 比较其他事务的写入集合和当前事务的读取集合。
- 如果有重叠(匹配),当前事务中止。
在事务结束时提交意图:
- 广播事务的写入集合。
- 如果多个事务的写入集合没有交集,它们可以并行提交。
3.2.2 事务内存的优点总结
编程简单性(粗粒度锁的优点):
- 粗粒度锁:用少量的锁保护大块的代码区域,编程简单,但并发度低。
- 事务内存:提供类似粗粒度锁的简单性,程序员可以轻松将代码划分为事务块(
begin和end),无需关心细粒度的同步问题,减少编程复杂性。
高性能(细粒度锁的优点):
- 细粒度锁:对不同数据或代码块分别加锁,可以提高并发性能,但编程复杂且容易出错。
- 事务内存:通过记录读写集合、延迟写入(写操作只在事务提交时生效)等机制,实现了性能优化,接近细粒度锁的效率,减少锁争用问题。
避免死锁:
- 死锁的成因:多个线程持有不同的锁,并相互等待对方释放资源,形成循环等待。
- TM 如何避免死锁:事务在检测到冲突时会自动回滚并重试,从而打破锁等待的循环,避免死锁发生。
3.3 设计空间
数据版本管理(Data Versioning):
- 急切版本(Eager):基于撤销日志(undo log)
- 懒惰版本(Lazy):基于写缓冲区(write buffer)
冲突检测(Conflict Detection):
- 乐观检测(Optimistic detection):在提交时检查冲突(在事务执行期间乐观地继续)
- 悲观检测(Pessimistic detection):每次读/写操作都检查冲突(减少提交时的工作量)
3.3.1 "Lazy" 实现
适用于基于 Snoop 协议的小型多处理器的实现
- 针对小规模多处理器系统,使用基于总线监听 Snoop 的缓存一致性协议实现事务内存。
”Lazy“ 版本管理与 ”Lazy“ 冲突检测
- 对冲突的解决持乐观态度,认为冲突最终可以解决。
- 延迟处理冲突问题,直到事务提交时再检查和解决冲突。
不支持事务并行提交
- 多个事务无法同时完成提交操作,需要按顺序逐个提交。
当事务发出读请求时:如果数据块尚未在缓存中,则以只读模式(read-only)获取该数据块,并为该缓存行设置 rd-bit(读取位)。
当事务发出写请求时:如果数据块尚未在缓存中,则以只读模式获取该数据块,为该缓存行设置 wr-bit(写入位),并在缓存中修改数据。
如果带有 wr-bit 的缓存行被驱逐(evicted),事务必须中止(abort),或者依赖某种软件机制来保存溢出的数据。
当一个事务到达结束时,它需要将其写操作持久化:在事务的最后阶段才提交写操作,使数据持久化。
一个中央仲裁器负责协调(在基于总线的系统中易于实现):
-
胜出的事务将占用总线,直到所有需要写入的缓存行地址被广播出去(这是事务的提交过程)。
-
无需立即回写到主存,只需将这些缓存行的其他副本无效化即可。
当其他事务(尚未开始提交)检测到它的读集合中的缓存行被无效化时:
- 该事务意识到自己失去了原子性。
- 随后,它会中止(清除其读和写标记)并重新开始执行。
3.3.2 ”Lazy“ 实现总结
”Lazy“ 版本控制:
- 实现方式:事务在执行期间不会直接修改全局共享数据(“主副本”),而是将更改保存在本地缓存中。
- 优点:减少全局数据的频繁修改,避免不必要的冲突。
- 影响:提交阶段需要一次性将本地修改同步到主副本,导致提交开销较大。
”Lazy“ 冲突检测:
- 实现方式:事务执行期间不主动检查冲突,仅在事务结束提交时进行检查。
- 优点:减少冲突检测的频率,优化事务执行速度。
- 影响:如果多个事务冲突,会在提交时触发冲突处理(例如回滚),可能影响提交效率。
快速回滚:
- 回滚步骤:
- 清除缓存中的事务标志位。
- 刷新流水线,清除受影响的指令。
- 恢复到之前保存的寄存器检查点。
- 优点:回滚操作简洁高效,降低了事务失败的处理成本。
提交较慢:
- 原因:
- 提交阶段需要进行冲突检测,确保本地修改不会与其他事务冲突。
- 写操作的缓存一致性更新(如通知其他处理器缓存无效)被推迟到提交时完成。
- 影响:虽然执行过程中性能较高,但事务提交阶段可能成为性能瓶颈。
无死锁风险:
- 原因:在总线竞争中,第一个获取总线控制权的事务优先提交,打破了可能的循环等待。
- 结果:有效避免了传统加锁机制中死锁问题的发生。
饥饿问题:
- 成因:由于某些事务总是被其他事务抢先(例如,总是无法获取总线),可能长期无法完成提交。
- 解决办法:需要引入饥饿避免机制,例如优先级提升或轮询机制,确保每个事务都有机会完成。
3.3.3 "Eager" 实现
写操作立即生效:
- 在“提前”实现中,写操作会立即更新到内存中,而不是等到事务结束后再统一提交。
其他事务读取时返回最新值:
- 如果在此期间其他事务尝试读取该值,会返回最新的更新值,同时内存中也可能被更新为最新值。
保留旧值以备回滚:
-
为了防止当前事务因冲突被中止(abort)时丢失旧数据,写操作之前会将旧值保存到一个日志(log)中。
-
日志存储位置:日志存储在虚拟内存中,可以在缓存中操作,因此性能开销不大。
这种方法被称为 Eager Versioning。
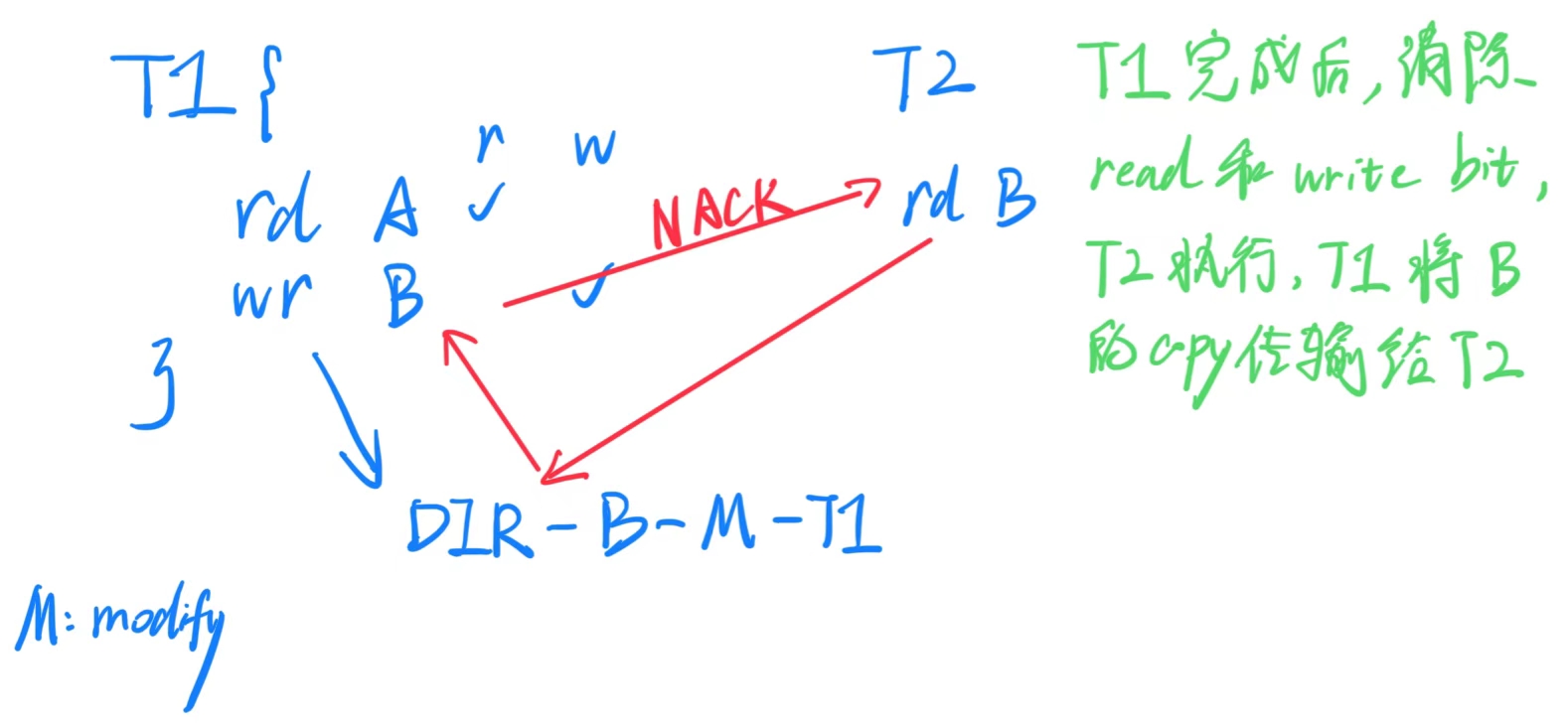
由于事务 A 的写操作立即生效,可能会导致另一个事务 B 的读/写操作出现未命中,并被重定向到事务 A。
在此时,我们检测到冲突(因为两个事务都未到达其结束点,因此这是 ”Eager“ 的冲突检测):两个事务同时操作同一缓存行,并且至少有一个事务进行了写操作。
一种解决方案:请求方停滞。事务 A 向事务 B 发送一个 NACK(否定应答);事务 B 等待并重试,希望事务 A 能够提交并将最新的缓存行交给 B。
- 结果:两个事务都不需要中止。
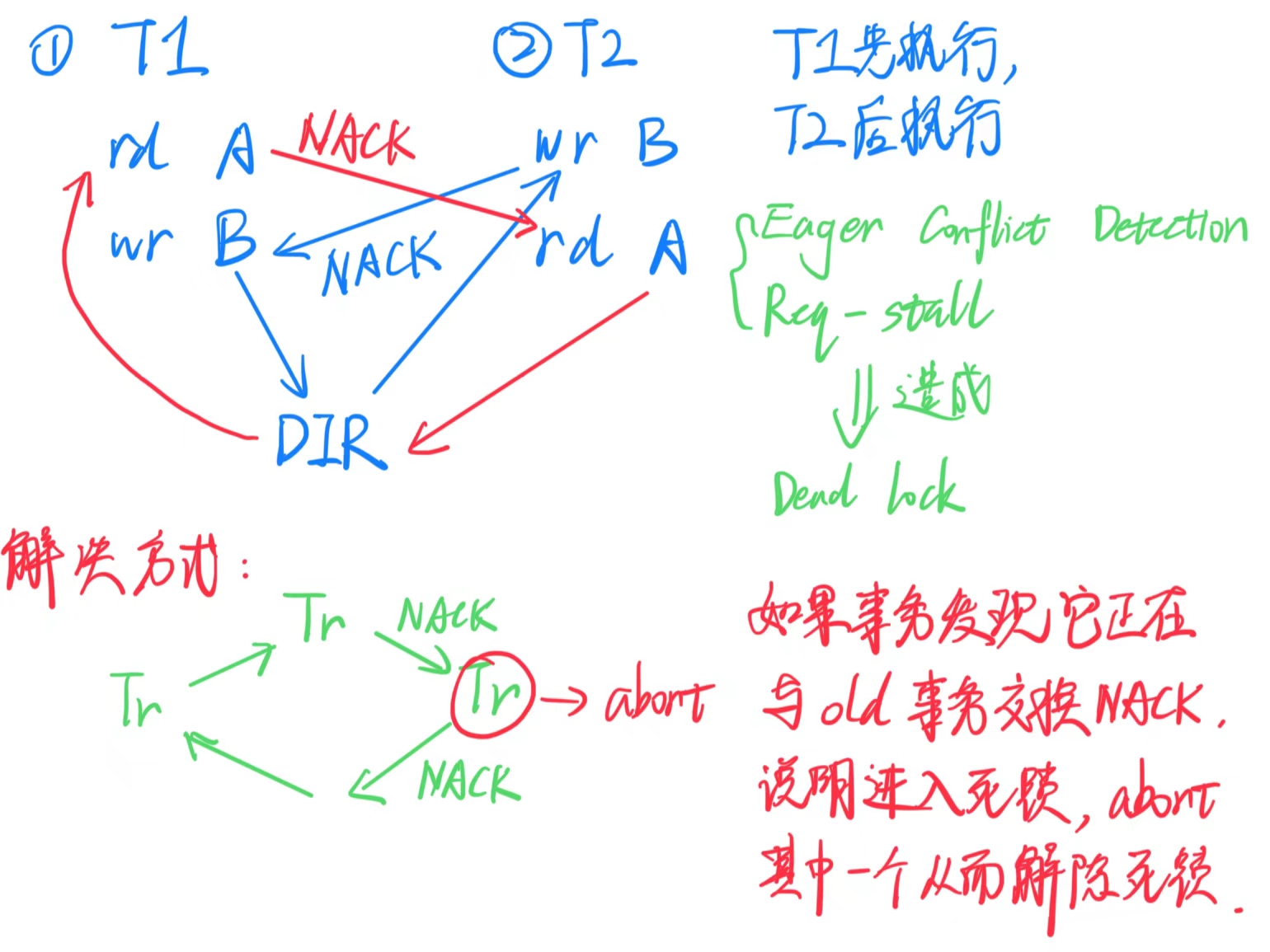
可能导致死锁:每个事务都在等待另一个事务完成
需要一个独立的(硬件/软件)争用管理器来检测这些死锁并强制其中一个事务中止
3.3.4 ”Eager“ 实现总结
事务间的读写冲突与停滞:
- 在急切(Eager)*实现中,事务按照顺序进行。当*Tr-B 尝试执行写操作时,如果Tr-A已经读取某个值,但不想使其缓存行失效,Tr-B 可能必须等待Tr-A 完成操作后才能继续。这种依赖关系可能导致事务的停滞,尤其是在高并发的情况下。
饿死问题:
- 饿死(Starvation) 是指某些事务因资源不断被其他事务占用而无法执行的情况。在这个上下文中,如果有很多新的读取事务(比如Tr-A),而Tr-B必须等待,Tr-B 可能会因一直无法获取所需资源而被饿死。解决这个问题通常需要额外的软硬件机制来确保事务公平性和资源分配。
日志存储与事务大小:
- 在急切实现中,事务的日志存储在虚拟内存中。这意味着事务的日志不会因为物理缓存大小而受限,因此可以处理更大的事务。这是因为虚拟内存提供了一个较大的内存空间,事务数据不会因缓存溢出而丢失。
提交和中止的成本:
- 提交操作(commit)的成本相对较低,因为它只需将事务的数据写入最终的存储位置,且不需要额外的处理步骤。
- 然而,中止操作(abort)的成本较高,因为必须从日志中恢复之前的状态和数据,确保系统保持一致性。尽管中止操作较为罕见,但它需要较高的计算资源和时间。
3.3.5 讨论
- “急切(Eager)”优化常见情况,并且在可能发生冲突时不会浪费能量
- 事务内存实现需要相对较低的硬件支持
- 多个商业实现示例:Sun Rock、AMD ASF、IBM BG/Q、Intel Haswell
- 事务通常很短——超过95%的事务会完全适配缓存
- 事务通常会成功提交——不到10%的事务会被中止
- 99.9%的事务不进行I/O操作
- 再次应用阿姆达尔定律(Amdahl's Law):优化常见情况!
本文作者:Astron_fjh
本文链接:https://www.cnblogs.com/Astron-fjh/p/18606117
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步