
DDCA —— 缓存一致性
 Computer Architecture Lecture20 和 CS6810 Chapter 5. Multiprocessors, Coherence. 的学习笔记,详细介绍了对称共享内存多处理器(SMP)和分布式内存多处理器(DMM),以及基于Snoop的缓存一致性协议和基于目录的缓存一致性协议。
Computer Architecture Lecture20 和 CS6810 Chapter 5. Multiprocessors, Coherence. 的学习笔记,详细介绍了对称共享内存多处理器(SMP)和分布式内存多处理器(DMM),以及基于Snoop的缓存一致性协议和基于目录的缓存一致性协议。
1. 多处理器内存组织结构
1.1 SMP/集中式共享内存
- 集中式共享内存多处理器(Centralized shared-memory multiprocessor)或对称共享内存多处理器(Symmetric shared-memory multiprocessor,SMP)
- 多个处理器连接到一个集中式内存 —— 因为所有处理器看到的是相同的内存结构 -> 即统一内存访问(uniform memory access,UMA)
- 共享内存意味着所有处理器都可以访问整个内存地址空间。
- 集中式内存会成为带宽瓶颈吗?—— 如果使用大型缓存并且处理器数量少于12个,则不会。
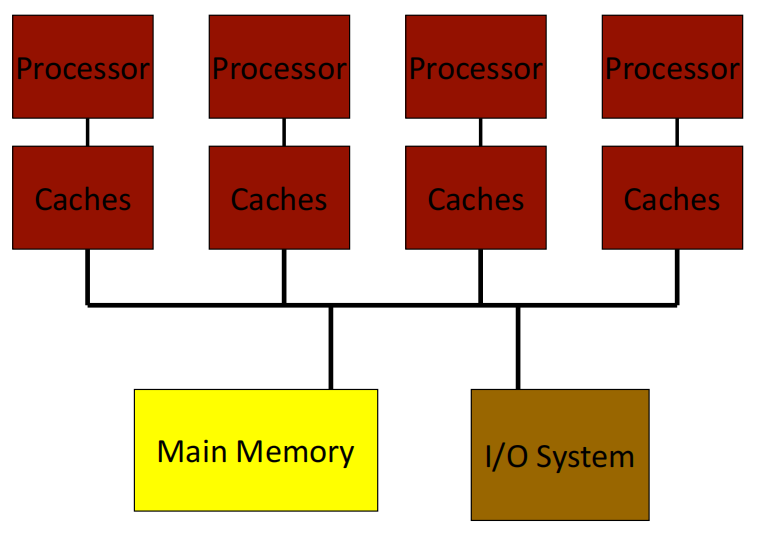
图中的 Main Memory 为 Shared Memory,处理器广播 Bus,每个处理器可以看到其他处理器的 request 和 response。
1.2 分布式内存多处理器
为了更好的扩展性,内存在多个处理器之间分布 -> 分布式内存多处理器(distributed memory multiprocessors,DMM)
- 如果一个处理器可以直接访问另一个处理器的本地内存,那么地址空间是共享的 -> 分布式共享内存(DSM)多处理器
- 如果内存严格是本地的,我们需要通过 message 来通信数据 -> 计算机集群或多计算机系统
- 非统一内存架构(Non-uniform memory architecture,NUMA),因为本地内存的延迟比远程内存更低
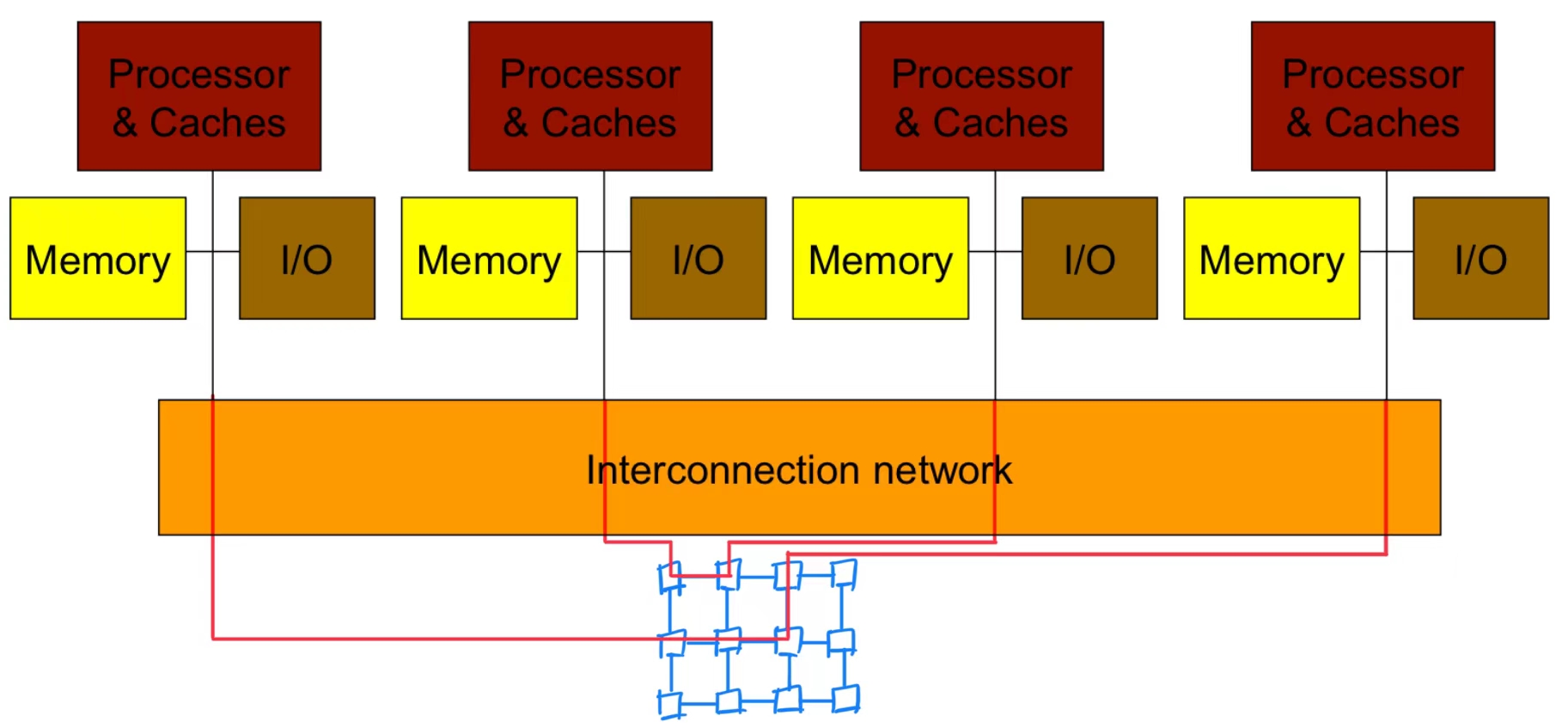
图中,将 Memory 分开集成到每个处理器芯片中,将 Memory 从 Shared Memory 变为 Local Memory,处理器之间通过 Interconnection network 通信。
2. 缓存一致性协议(Cache Coherence Protocols)
2.1 Shared-Memory vs. Massage-Passing
Shared-memory(共享内存):
- 易于理解的编程模型
- 通信是隐式的,硬件处理保护
- 硬件控制缓存
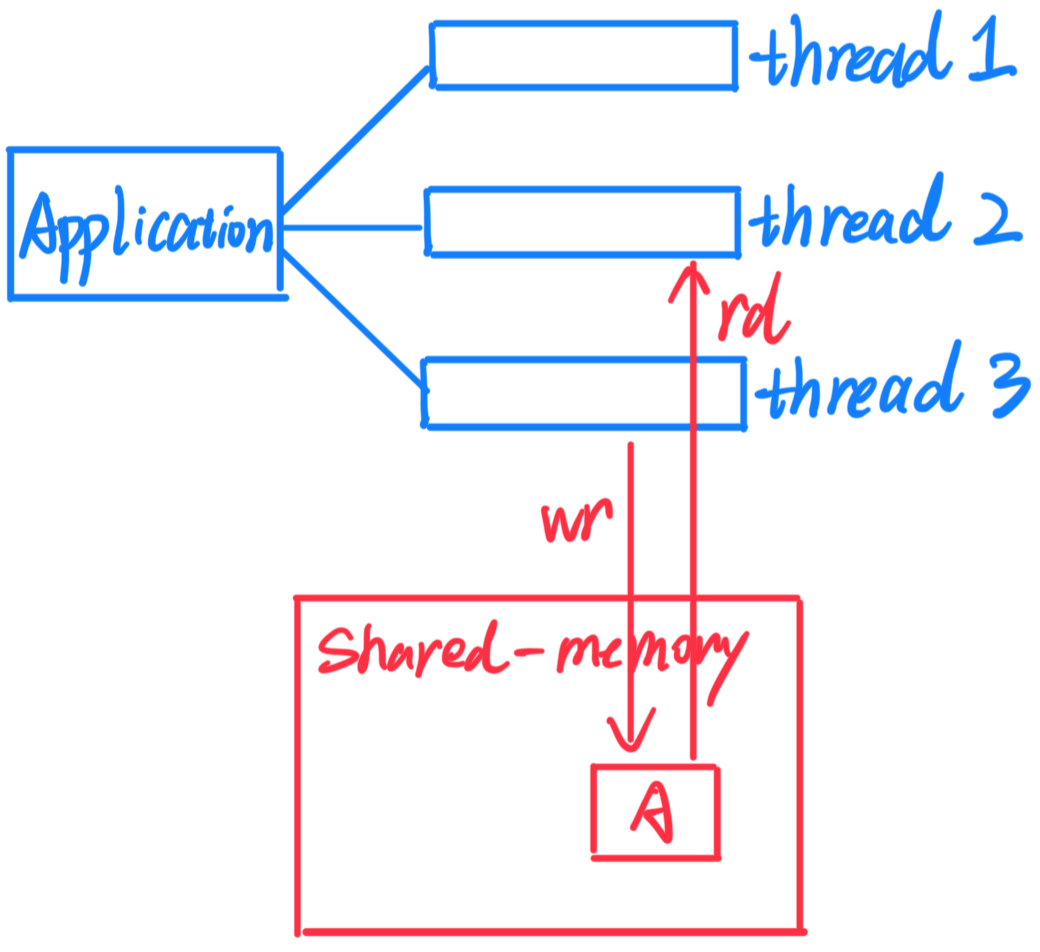
如下图所示,对于一个application,它有很多thread,每个thread都能对shared-memory读取或写入。
Message-passing(消息传递):
- 没有缓存一致性 -> 硬件更简单
- 显式通信 -> 方便程序员批量重构代码
- 发送方可以发起数据传输
如下图所示,thread 2需要最新的 A 数据,Message-passing的操作过程。

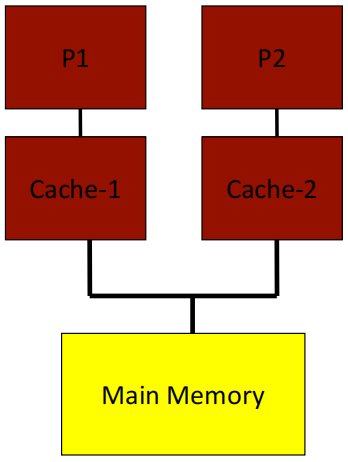
2.2 SMPs(Symmetric shared-memory multiprocessors)
- 集中式主存和多个缓存 -> 会产生相同数据的多个副本
- 如果系统能够在读取时返回该数据的最近写入值,那么该系统是缓存一致的
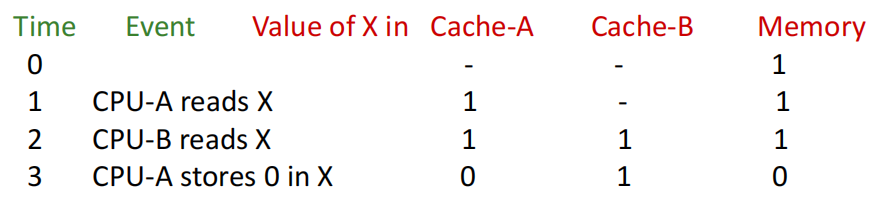
- 缓存不一致例子:Time 3时,Cache-A 和 Cache-B 缓存不一致
2.3 缓存一致性(Cache Coherence)
- 基本问题:如果多个处理器缓存同一个块,如何确保它们都能看到一致的状态?
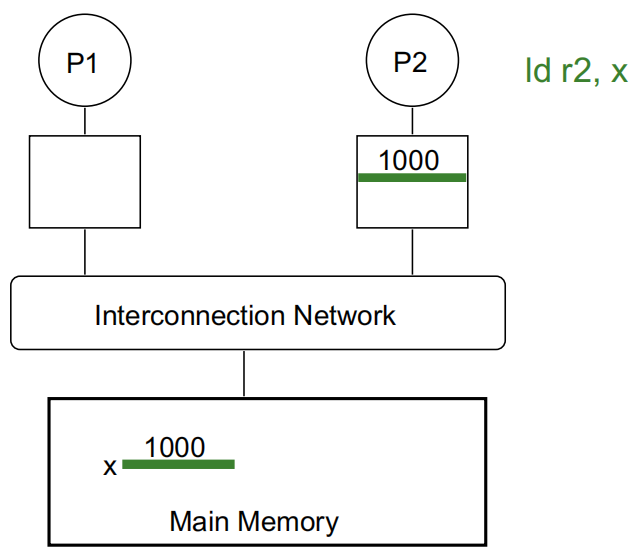
P2 执行 ld r2, x:
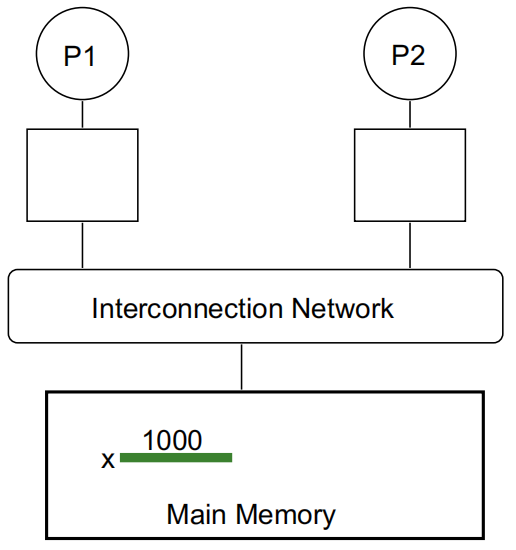
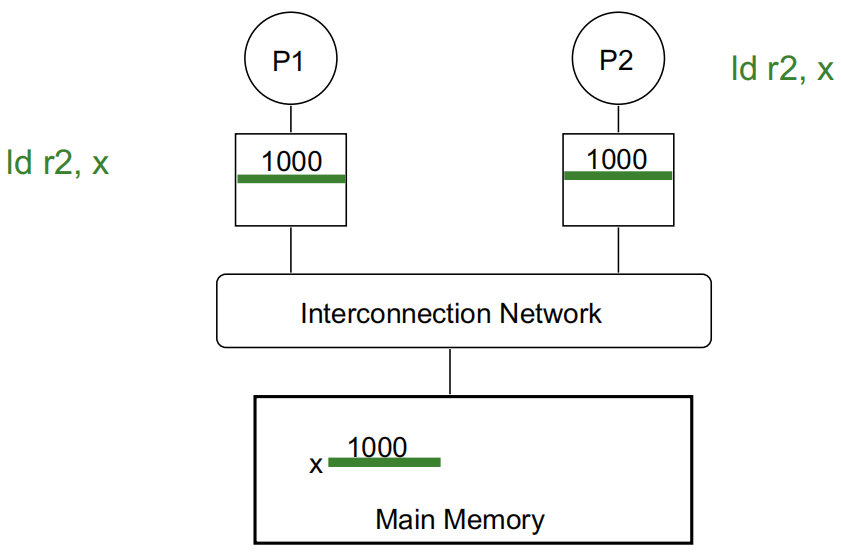
P1 执行 ld r2, x:
P1 修改 x 的值:
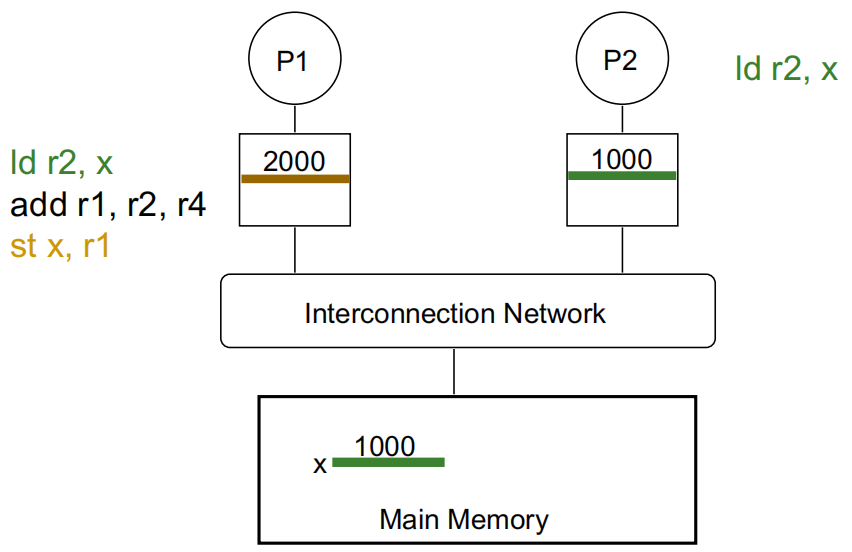
P2 再读取 x 的值,若没有缓存一致性,将读取错误的值:
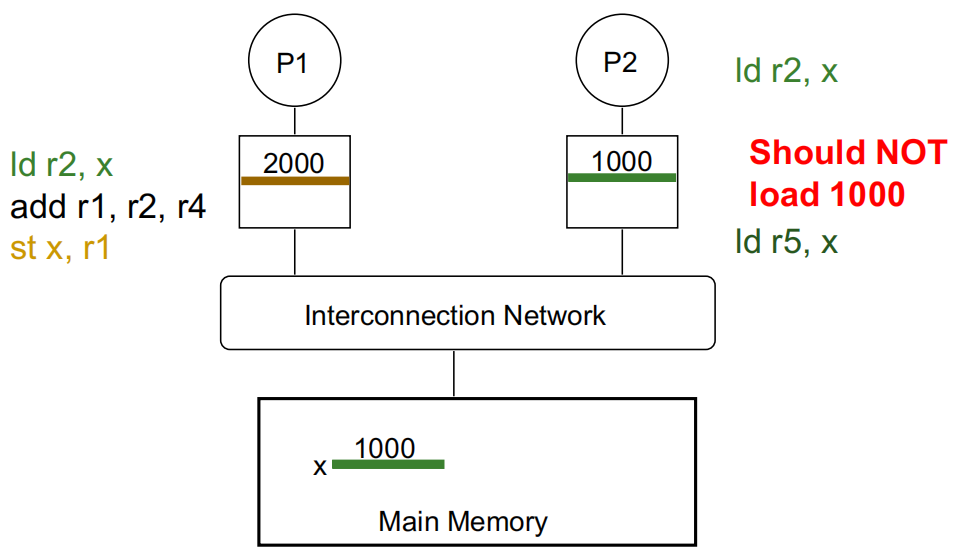
一个内存系统是一致的,如果:
- 写传播:P1 写入 X 后,经过足够的时间,P2 读取 X 并得到 P1 写入的值。
- 写序列化:两个处理器对同一位置进行的写操作被所有处理器以相同的顺序观察到。
- 内存一致性模型定义了“时间经过”的概念,也就是说,一个处理器的操作在其他处理器可见之前的等待时间,并定义了与其他位置的读/写操作的顺序(大致如此——后续会详细讨论)。
2.4 缓存一致性协议
目录式(Directory-based):一个位置(目录)跟踪某个内存块的共享状态(适用于 DMM)
Snooping:每个缓存块都带有该块的共享状态,所有缓存控制器监视共享总线,以便在必要时更新该块的共享状态(适用于SMP)
- 写失效:在写入之前,处理器通过使其他所有副本失效来获得该块的独占访问权
- 写更新:当一个处理器写入时,它会更新该块的其他共享副本
3. 基于Snoop的缓存一致性协议
3.1 SMP 基于 Snoop 的缓存一致性协议流程
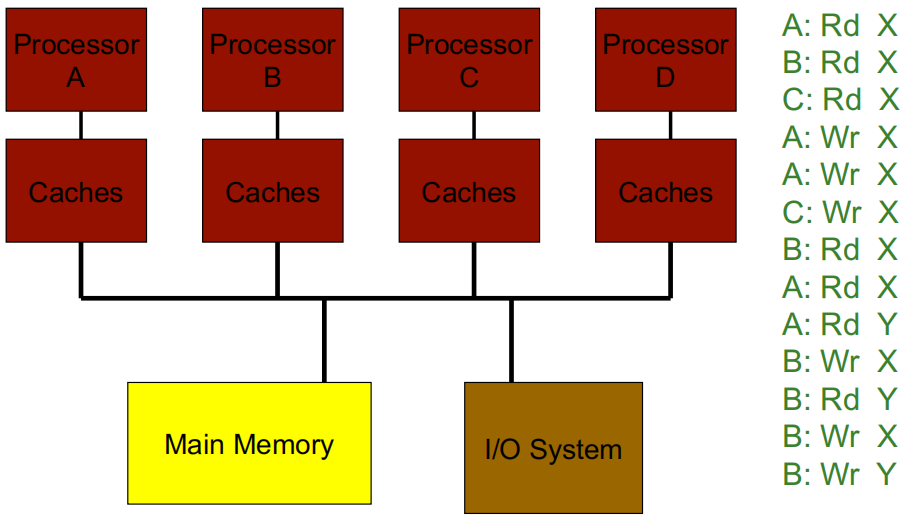
Example 1:

Example 2:
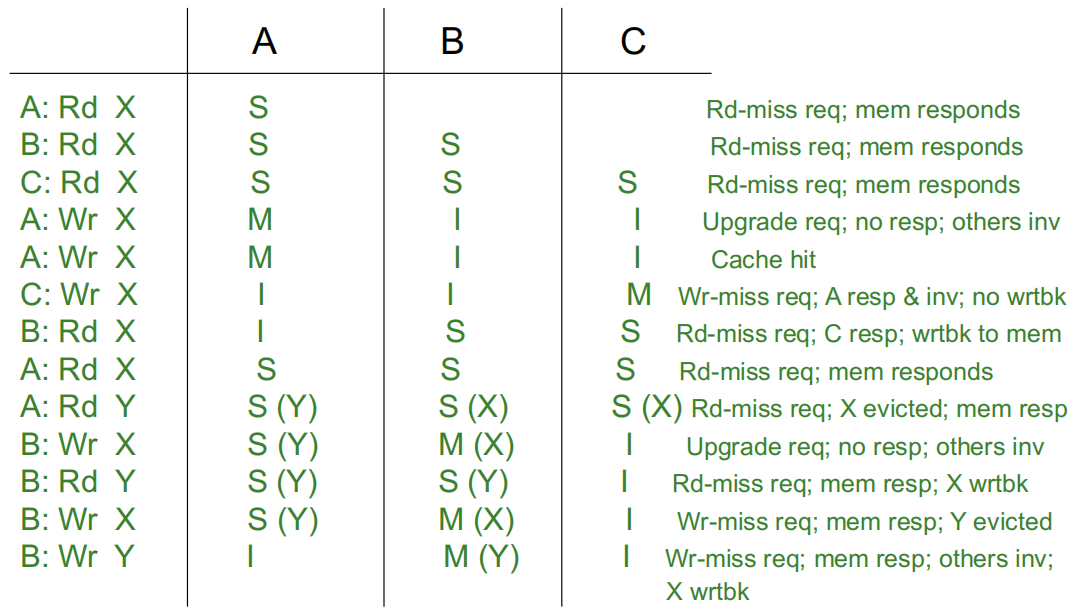
-
P1读取X:
-
缓存1中没有找到X,所以P1向总线发送请求。
-
主存接收到请求并响应,把X放入缓存1,并将其状态标记为“共享”状态。
-
-
P2读取X:
-
缓存2中没有找到X,因此P2向总线发送请求。
-
所有缓存都会 snoop 这个请求。缓存1检测到该请求,但因为这是一个读取请求,所以缓存1不执行任何操作。
-
主存再次响应请求,将X放入缓存2中,并将其状态设为“共享”状态。
-
-
P1写入X:
-
缓存1中X的状态为“共享”,而“共享”状态只能提供读取权限,所以P1在写入前需要获得独占权限。
-
P1向总线发送写入请求,缓存2检测到这个请求后,将自己缓存中的X设为“无效”状态(表示它已失效)。
-
缓存1将X的状态更改为“修改”状态,这表示缓存1拥有唯一的有效副本,并且可以进行修改。
-
-
P2读取X:
-
缓存2中X的状态为“无效”,因此P2再次向总线发送读取请求。
-
缓存1检测到这个请求,并意识到自己拥有X的唯一有效副本,因此它将自身的X状态降级为“共享”状态,并将数据响应给缓存2。
-
X被放入缓存2中,状态为“共享”,主存也更新了X的值以确保一致性。
-
Example 3:
3.2 设计问题
-
Invalidate(失效):这是指当一个处理器对数据块进行写操作时,需要让其他处理器缓存中该数据的副本失效。这是为了确保在多处理器系统中,所有处理器读取到的数据都是最新的。失效操作可以通过嗅探总线来执行。
-
Find Data(寻找数据):当一个处理器需要某个数据块时,它可能不知道该数据块是否在其他处理器的缓存中,因此需要有一种机制来在系统中找到所需的数据。Snoop协议通过监视总线上的请求来帮助查找数据位置。
-
Writeback/Writethrough(回写/直写):这是两种缓存更新策略。直写(Writethrough)会直接将数据写入主存,从而减少缓存一致性问题的复杂性,但会增加存储带宽消耗。回写(Writeback)则是在数据块被替换或失效时才写入主存,减少了写入主存的次数,但增加了保持一致性的复杂性。
-
Cache Block States(缓存块状态):在缓存一致性协议中,缓存块会有不同的状态,例如MESI协议中的“修改(Modified)”、“共享(Shared)”、“独占(Exclusive)”、“无效(Invalid)”。这些状态用于描述每个缓存块的权限和有效性,以确保数据的一致性。
-
Contention for Tags(标签竞争):由于多个处理器会同时访问缓存中的数据块,可能会导致标签竞争的问题。标签竞争指处理器需要某个缓存块时,需要频繁查看自己的缓存块状态,即缓存块 Tag。
-
Enforcing Write Serialization(强制写序列化):在多处理器系统中,写操作的顺序很重要。强制写序列化是指确保同一个数据块的写操作按照特定顺序进行,这样可以避免不同处理器读到不一致的数据。
3.3 协议示例
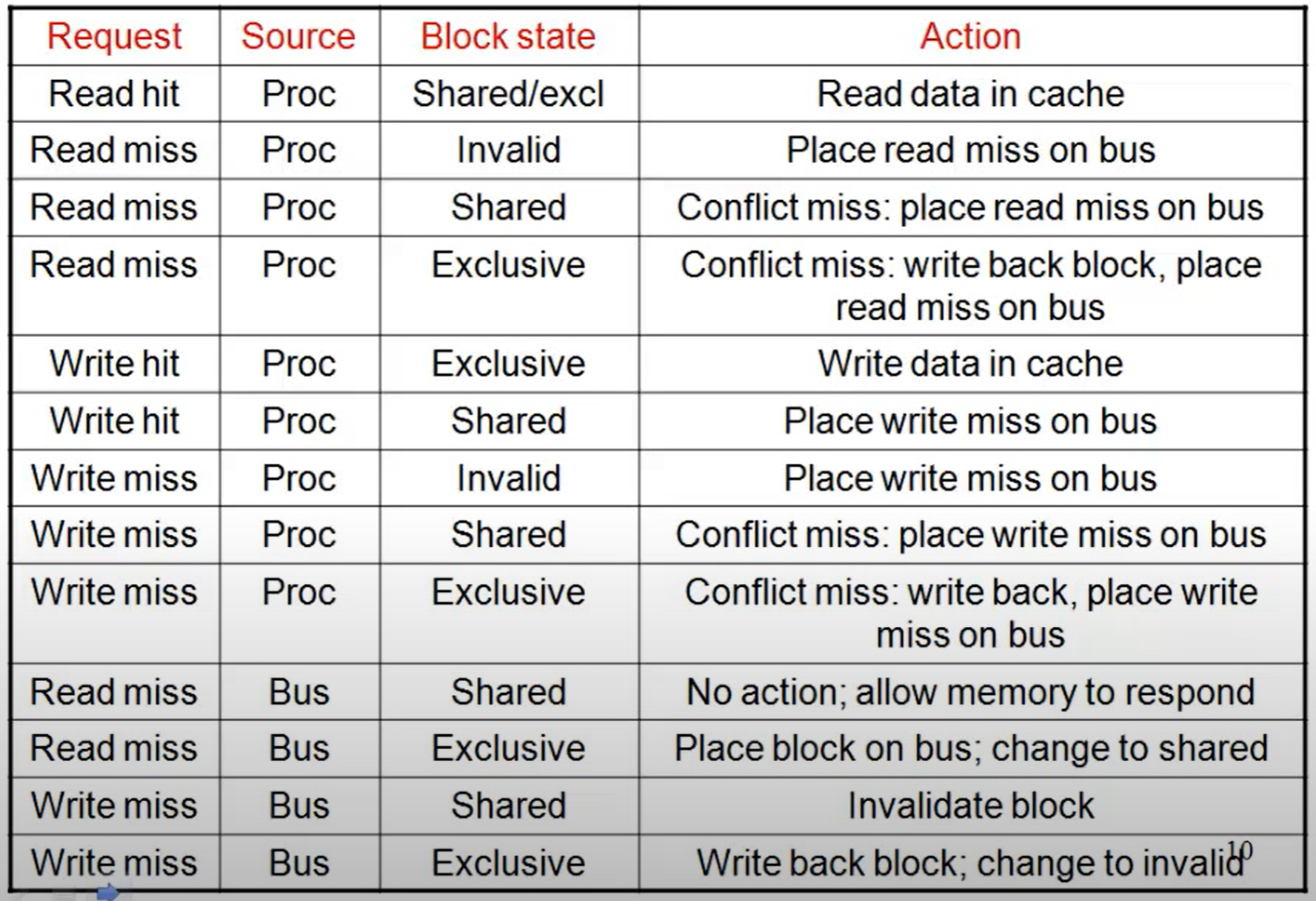
4. 基于目录的缓存一致性协议
在一个多处理器系统中,为了实现高扩展性,系统将物理内存分布在各个处理器节点之间。这意味着每个处理器拥有自己的一部分物理内存,而不再是所有处理器共享一个集中式的内存区域。为了管理这些分布式的内存区域,目录结构也随之分布,每个目录负责记录与其对应内存块的共享状态信息。
- 物理内存的分布:系统中的物理内存分布在各个处理器节点中,这样可以让每个处理器更快地访问本地内存(与远程内存相比,访问延迟更低)。这种方式提升了系统的可扩展性,使得添加新的处理器和内存更加简单。
- 目录的分布:每个处理器节点中的内存都有一个对应的目录来记录其共享状态。这个目录包含信息,说明其他处理器是否在其缓存中存有这部分内存的副本。这样,系统不再需要所有处理器嗅探(snoop)总线来获得一致性信息,减少了带宽和开销。
- 物理地址确定内存位置:每个内存块的物理地址决定了其在系统中所属的节点。处理器可以通过地址直接找到内存所在的位置,而不必广播请求。
- 可扩展互连与消息路由:处理节点通过一种可扩展的互连网络相连,而不是传统的总线结构。传统总线结构下,所有请求都是广播式的,但在可扩展互连中,消息会通过路由机制直接从发送方传送到接收方。由于消息不再广播,处理器无法监视所有请求,因此必须依赖目录来跟踪内存块的共享状态。
4.1 DMM 基于目录的缓存一致性协议
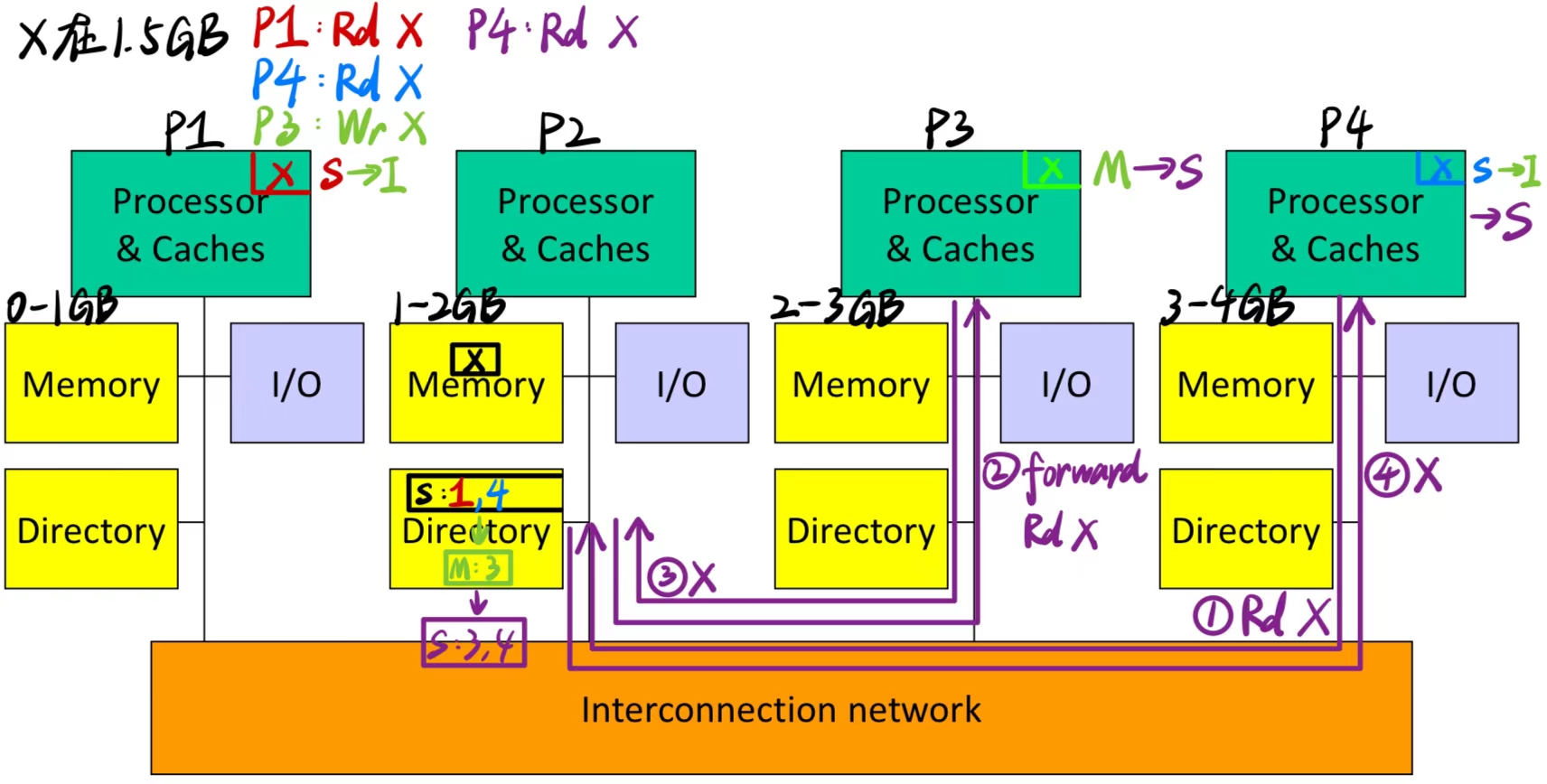
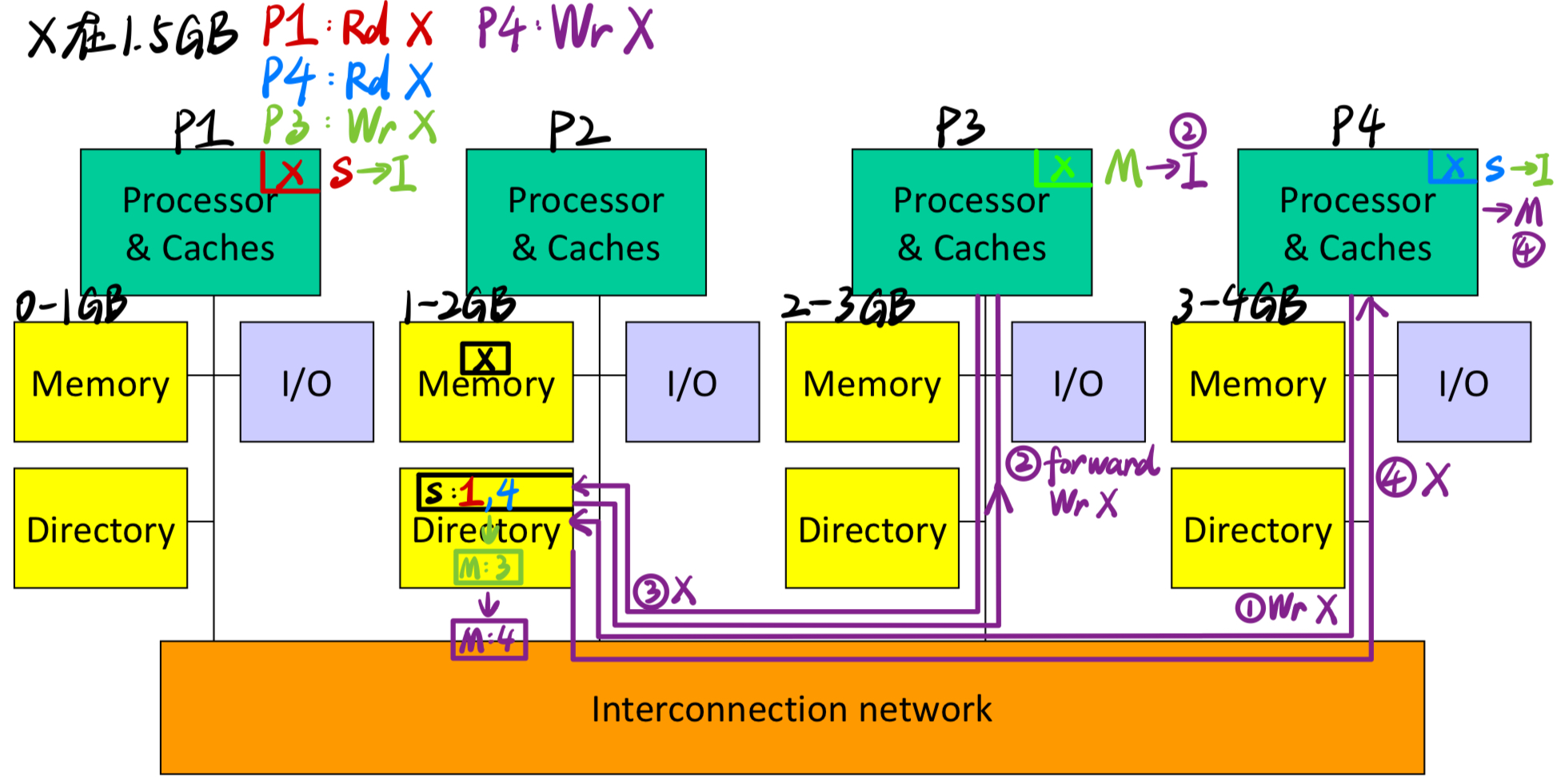
Example1 :
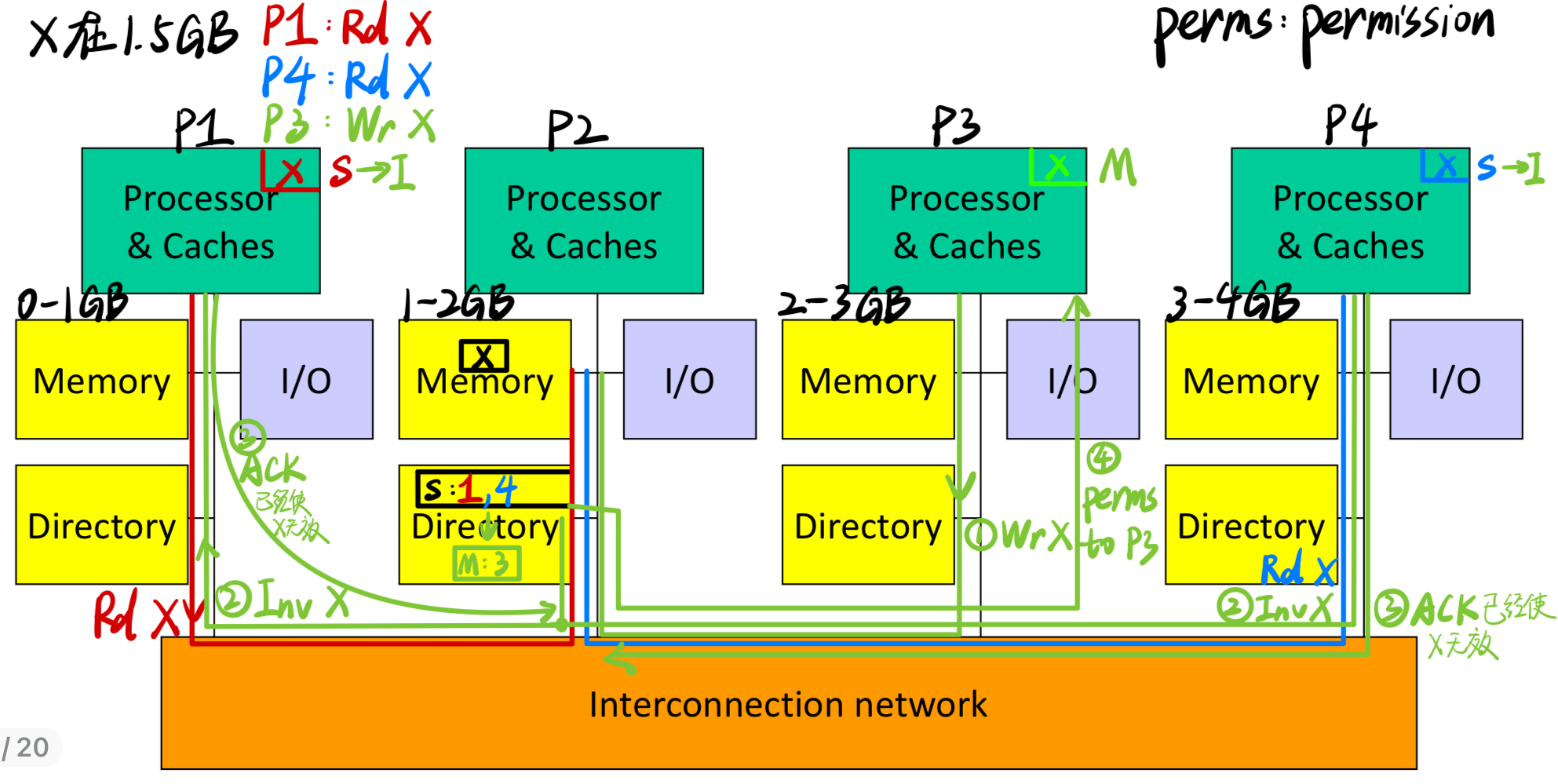
- 当第4条指令为:P4: Rd X
- 当第4条指令为:P4: Wr X
Example 2:
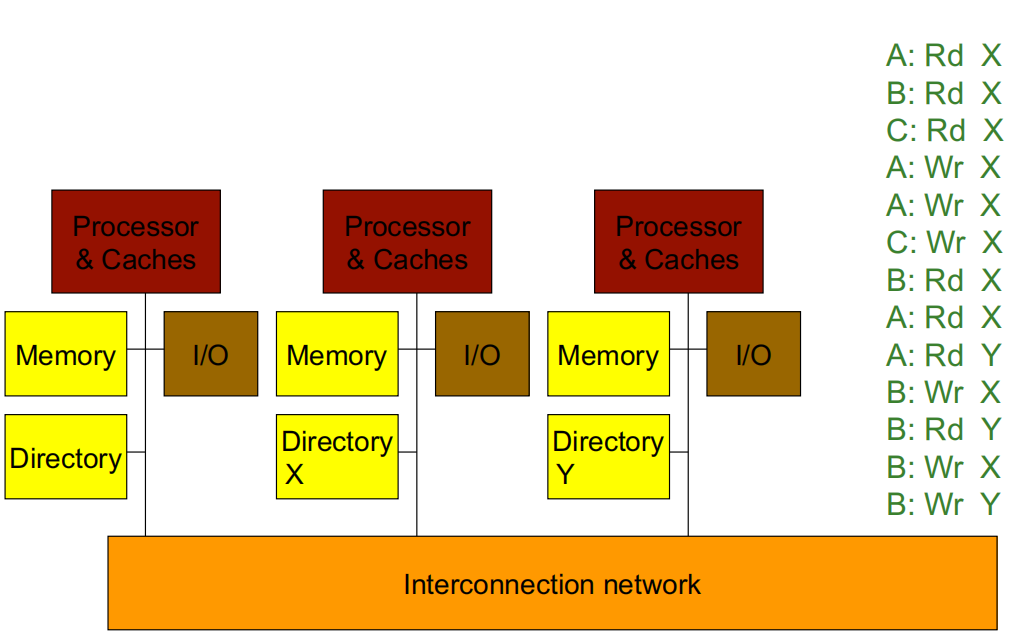
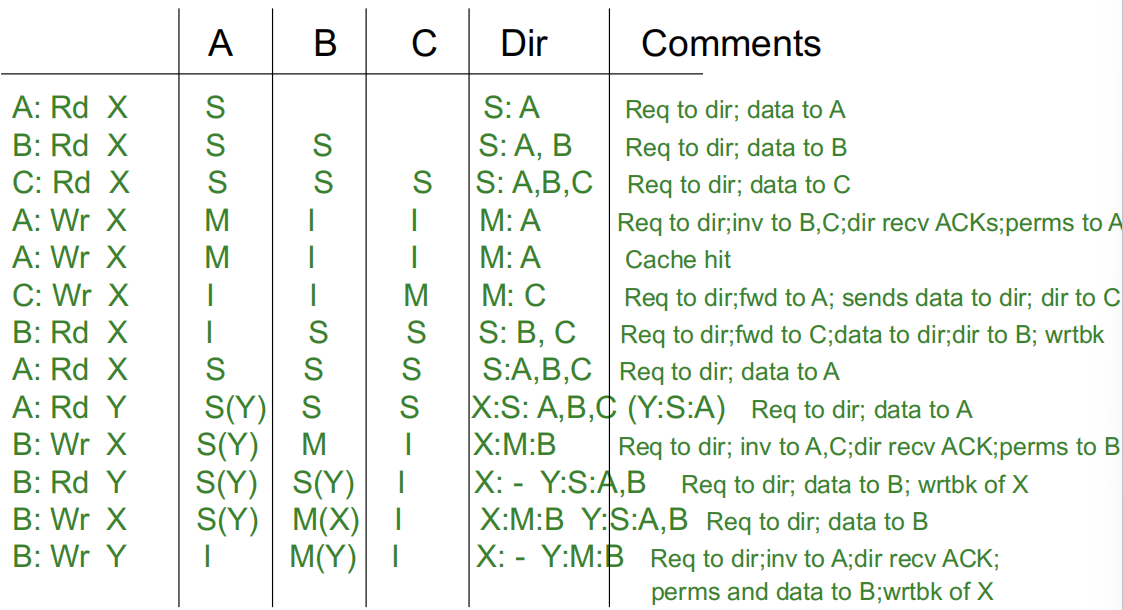
4.2 缓存块状态
目录中内存块可以有的不同状态是什么?
- 注意,我们需要记录每个缓存的信息,以便发送失效(invalidate)消息。
- 为了提高效率,内存块的状态也存储在缓存中。
- 现在,目录充当仲裁者:如果有多个写操作同时发生,目录会确定它们的顺序。
4.3 目录操作
- 如果内存块处于未缓存状态:
- 读未命中:发送数据,将块设为共享状态
- 写未命中:发送数据,将块设为独占状态
- 如果内存块处于共享状态:
- 读未命中:发送数据,将节点添加到共享者列表中
- 写未命中:发送数据,使共享者失效,将块设为独占状态
- 如果内存块处于独占状态:
- 读未命中:请求当前所有者提供数据,将数据写入内存,发送数据,将块设为共享状态,将节点添加到共享者列表中
- 数据回写:将数据写入内存,将块设为未缓存状态
- 写未命中:请求当前所有者提供数据,将数据写入内存,发送数据,更新新的所有者身份,保持独占状态
5. 多线程编程模式
5.1 Ocean Kernel
Procedure Solve(A)
begin
diff = done = 0;
while (!done) do
diff = 0;
for i <- 1 to n do
for j <- 1 to n do
temp = A[i,j];
A[i,j] <- 0.2 * (A[i,j] + neighbors);
diff += abs(A[i,j] – temp);
end for
end for
if (diff < TOL) then done = 1;
end while
end procedure
5.2 共享地址空间模型下的并行编程
int n, nprocs;
float **A, diff;
LOCKDEC(diff_lock);
BARDEC(bar1);
main()
begin
read(n); read(nprocs);
A <- G_MALLOC();
initialize (A);
CREATE (nprocs,Solve,A); // 创建 nprocs 个并行任务,每个任务调用 Solve(A) 函数进行计算
WAIT_FOR_END (nprocs); // 等待所有任务完成
end main
-
同步:通过
BARRIER(bar1, nprocs)在不同计算阶段对进程进行同步,以确保所有进程在同一时间点进入下一步。 -
锁机制:使用
LOCK(diff_lock)和UNLOCK(diff_lock)对diff进行加锁保护,避免多个处理器同时访问修改,确保线程安全。
procedure Solve(A)
int i, j, pid, done=0;
float temp, mydiff=0;
int mymin = 1 + (pid * n/procs);
int mymax = mymin + n/nprocs -1;
while (!done) do
mydiff = diff = 0;
BARRIER(bar1,nprocs); // 对进程进行同步
for i <- mymin to mymax
for j <- 1 to n do
...
endfor
endfor
LOCK(diff_lock);
diff += mydiff;
UNLOCK(diff_lock);
BARRIER (bar1, nprocs); // 对进程进行同步
if (diff < TOL) then done = 1;
BARRIER (bar1, nprocs);
endwhile
5.3 消息传递模型下的并行编程
main()
read(n); read(nprocs);
CREATE (nprocs-1, Solve);
Solve();
WAIT_FOR_END (nprocs-1);
-
与共享地址空间模型不同,这里各个进程通过显式的消息发送(SEND)和接收(RECEIVE)操作进行通信。这种方式适用于分布式内存系统,其中每个处理器都有自己的独立内存区域。
-
在
while (!done)循环中,每个进程先通过SEND和RECEIVE函数向相邻进程发送和接收边界行,以便在计算时使用相邻行的最新数据。 -
非主进程 (
pid != 0) 通过SEND将自己的mydiff发送给主进程,然后RECEIVE接收是否结束的标志done。
procedure Solve()
int i, j, pid, nn = n/nprocs, done=0;
float temp, tempdiff, mydiff = 0;
myA <- malloc(...)
initialize(myA);
while (!done) do
mydiff = 0;
if (pid != 0)
SEND(&myA[1,0], n, pid-1, ROW);
if (pid != nprocs-1)
SEND(&myA[nn,0], n, pid+1, ROW);
if (pid != 0)
RECEIVE(&myA[0,0], n, pid-1, ROW);
if (pid != nprocs-1)
RECEIVE(&myA[nn+1,0], n, pid+1, ROW);
for i <- 1 to nn do
for j <- 1 to n do
...
endfor
endfor
if (pid != 0)
SEND(mydiff, 1, 0, DIFF);
RECEIVE(done, 1, 0, DONE);
else
for i <- 1 to nprocs-1 do
RECEIVE(tempdiff, 1, *, DIFF);
mydiff += tempdiff;
endfor
if (mydiff < TOL) done = 1;
for i <- 1 to nprocs-1 do
SEND(done, 1, I, DONE);
endfor
endif
endwhile
本文作者:Astron_fjh
本文链接:https://www.cnblogs.com/Astron-fjh/p/18544947
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步