
CUDA 编程学习 (5)——内存访问性能
 现代DRAM结构由于核心速度限制,通过burst模式和多Banks结构提高带宽。CUDA中,warp级聚合内存访问减少DRAM请求,提升效率。分块访问模式通过将数据加载到共享内存中,降低全局内存访问频率,进一步优化CUDA内存访问性能。
现代DRAM结构由于核心速度限制,通过burst模式和多Banks结构提高带宽。CUDA中,warp级聚合内存访问减少DRAM请求,提升效率。分块访问模式通过将数据加载到共享内存中,降低全局内存访问频率,进一步优化CUDA内存访问性能。
1. DRAM 带宽
1.1 DRAM 核心阵列结构
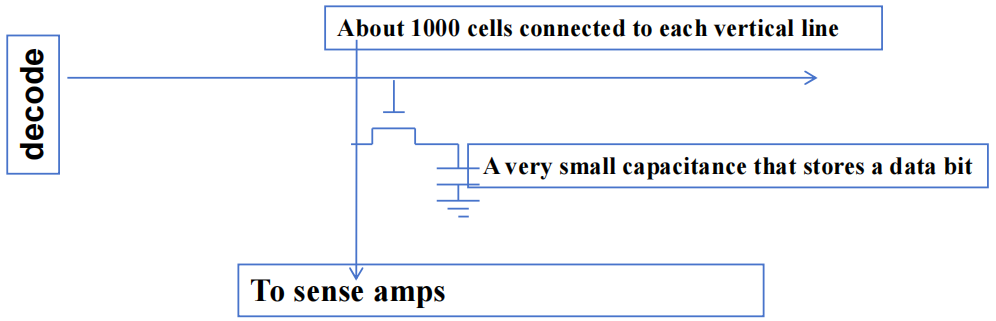
- 每个 DRAM 核心阵列约有
- 每个 bits 存储在由一个晶体管组成的微小电容器中
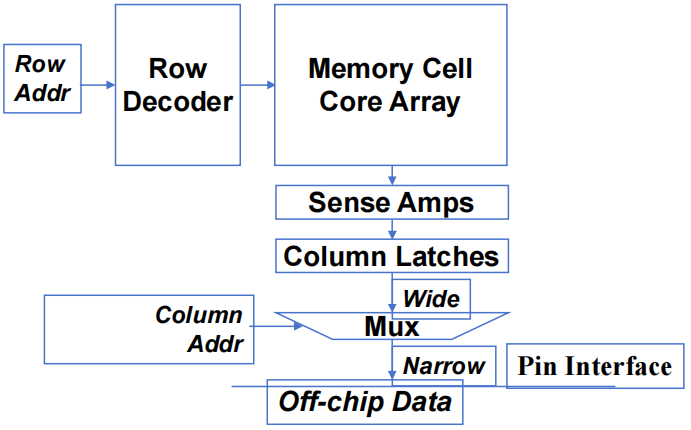
- 超小型(8x2-bit)DRAM 内核阵列
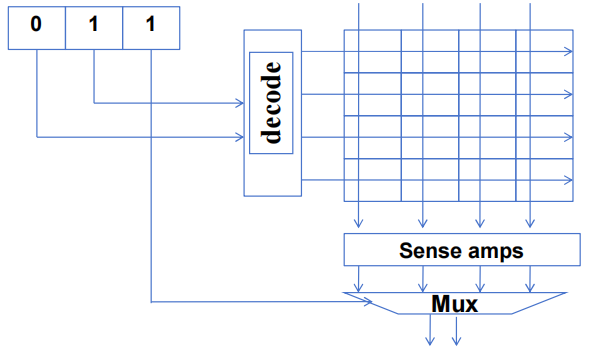
1.2 DRAM 核心阵列速度慢
-
从核心阵列单元读取数据的过程非常缓慢
-
DDR:Core speed =
-
DDR2 / GDDR3:Core speed =
-
DDR3 / GDDR4:Core speed =
-
-
1.3 DRAM Bursting
- 对于 DDR{2,3} SDRAM 内核,时钟频率为接口速度的
- 将同一行的 DRAM bits 一次性加载(
- DDR3 / GDDR4:
- 将同一行的 DRAM bits 一次性加载(
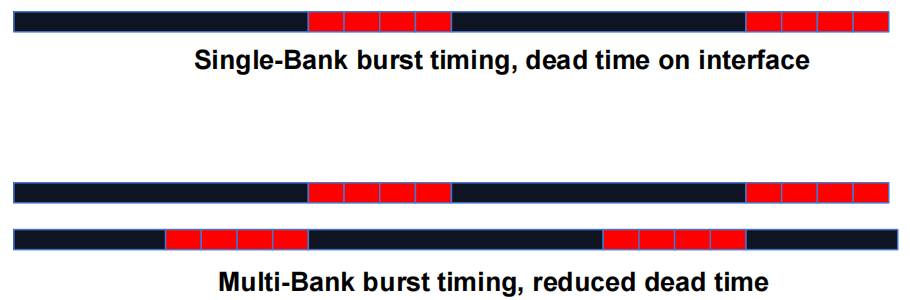
1.3.1 DRAM Bursting Timing 示例
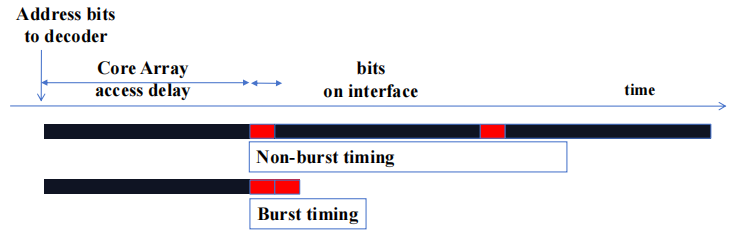
现代 DRAM 系统设计为始终以 burst 模式访问。burst bytes 被传输到处理器,但在访问非连续位置时会被丢弃。
1.3.2 DRAM Bursting with Banking
- 多个 DRAM Banks 结构
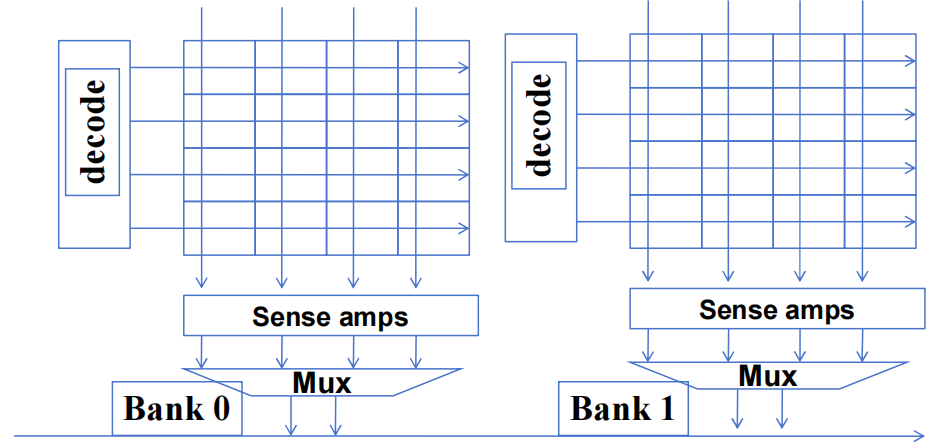
- DRAM Bursting with Banking
1.4 GPU 片外内存子系统
- NVIDIA RTX6000 GPU
- global memory 峰值带宽 =
- global memory 峰值带宽 =
- global memory (GDDR6) 接口 @7GHz
- 对于 GDDR6 32 位接口,我们只能维持约
- 我们需要更大的带宽(
2. CUDA 中的内存聚合
2.1 DRAM Burst —— 系统视图

-
每个地址空间被划分为 burst 段
- 每当访问一个位置时,同一 burst 段中的所有其他位置也会被传送到处理器中
-
基本示例如图:16-byte 地址空间,4-byte burst 段
- 实际上,我们至少有 4GB 的地址空间,burst 段大小为 128-byte 或更多
2.2 内存聚合
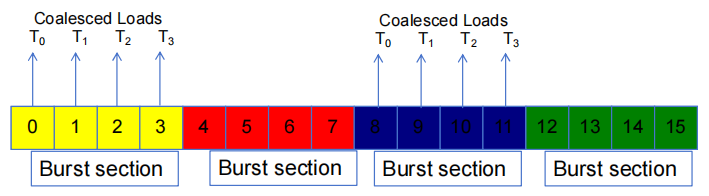
当一个 warp 中的所有 thread 都执行一个 load 指令时,如果所有被访问的位置都属于同一 burst 段,那么只会发出一个 DRAM 请求,并且访问是完全聚合的。
2.3 非聚合访问
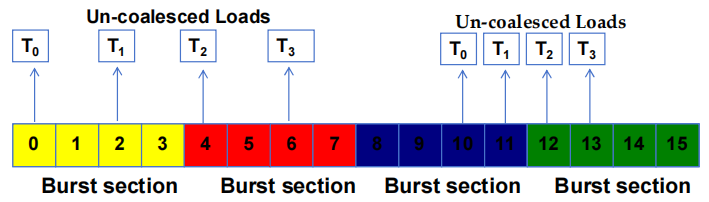
- 当被访问的位置跨越 burst 段边界时:
- 聚合失败
- 发出多个 DRAM 请求
- 访问未完全聚合
- 访问和传输的部分 bytes 未被 threads 使用
2.4 如何判断一个访问是否聚合
- 如果数组访问中的索引形式为
- 线性内存空间中的二维 C 阵列(按地址递增的线性化顺序)
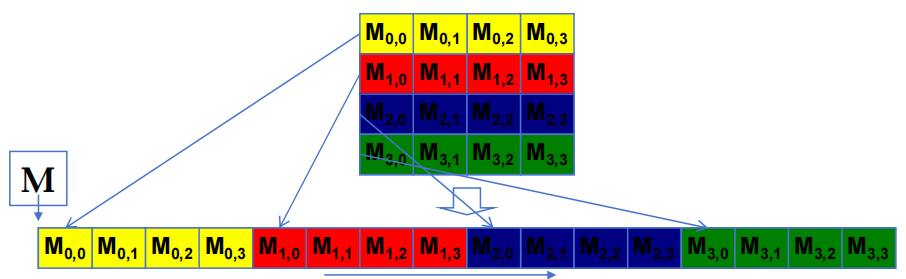
2.4.1 基本矩阵乘法的两种访问模式
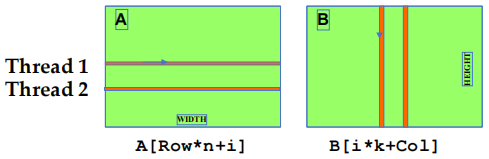
i 是 kernel code 内积循环中的循环计数器,A 大小为
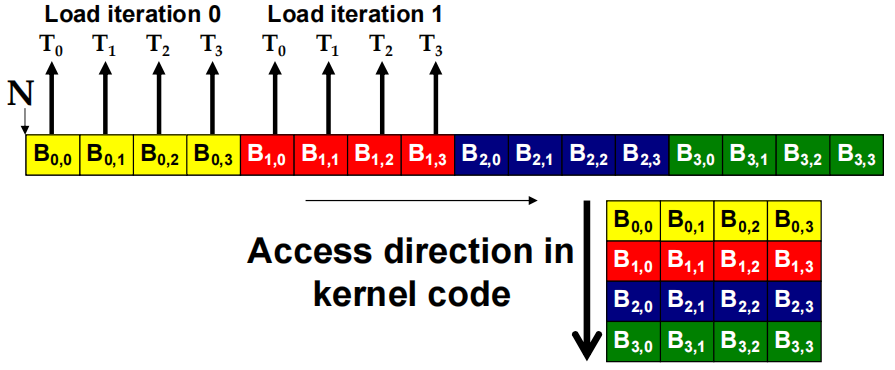
- B 访问模式是聚合的
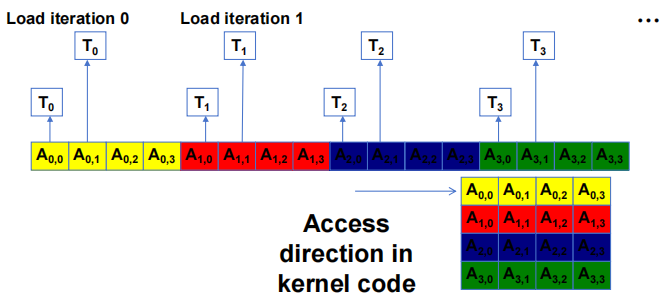
- A 访问模式不是聚合的
2.4.2 加载输入 tiles
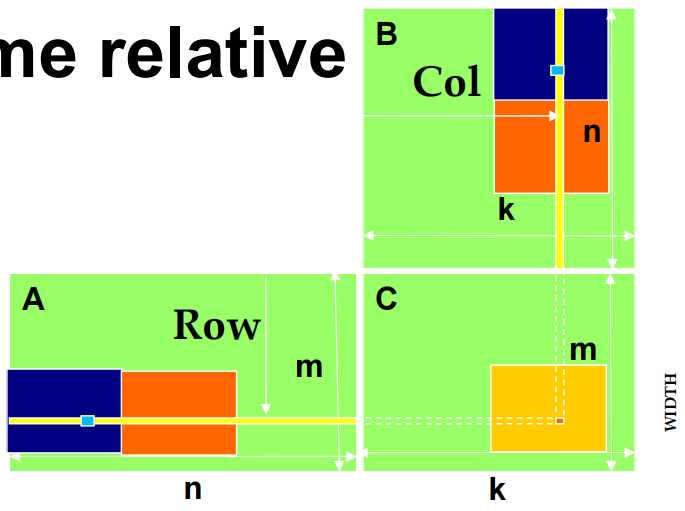
让每个 thread 在与其 C 元素相同的相对位置加载一个 A 元素和一个 B 元素。
int tx = threadIdx.xint ty = threadIdx.y
访问 tile 0 2D 索引:
A[Row][tx]B[ty][Col]
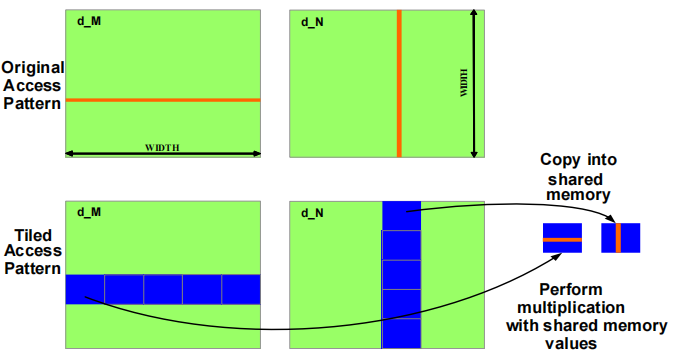
原始访问模式 (Original Access Pattern)
在左上角的 d_M 矩阵和右上角的 d_N 矩阵中,红色线条代表传统的逐元素访问方式。在这种模式下:
- 每个线程直接从全局内存中获取所需的矩阵元素,并进行计算。
- 这种访问方式可能导致频繁的全局内存访问,效率较低,因为每次访问都要从全局内存中读取数据。
分块访问模式 (Tiled Access Pattern)
在分块访问模式中:
d_M和d_N矩阵被分成多个小块(蓝色区域),每个小块会被加载到共享内存中。- 每个线程块只需要将其负责的矩阵 tile 拷贝到共享内存,然后对共享内存中的数据进行计算。
- 通过将小块 tile 加载到共享内存中,线程可以更快地重复使用共享内存中的数据,从而减少了全局内存的访问频率,提高了整体性能。
本文作者:Astron_fjh
本文链接:https://www.cnblogs.com/Astron-fjh/p/18519222
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10亿数据,如何做迁移?
· 推荐几款开源且免费的 .NET MAUI 组件库
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· c# 半导体/led行业 晶圆片WaferMap实现 map图实现入门篇
· 易语言 —— 开山篇