数据的存储(1):字节序与比特序
前言
在计算机的发展过程中,由于不同硬件体系在数据高低有效位及存储方式理解上的差异,出现了大端和小端这两种截然相反的对数据的位进行解释的模式。大小端模式本身没有优劣之分,但我们在开发过程中,需要时刻考虑设备大小端差异可能会对程序带来的影响,其中最典型的就是字节序和比特序问题。
字节序
大多数计算机使用字节作为最小的可寻址的内存单元。对于多字节的数据,一般都会被存储为连续的字节序列,但是组成数据的字节在内存中的存放顺序不同,对于不同的硬件体系也会有不同的解释。通常字节序规则分为两种:
- 小端法(little-endian):在内存中,数据按照最低有效字节到最高有效字节的顺序进行存储,即数据的高位字节在高地址处,低位字节在低地址处。大多数Intel体系下的机器都是使用的小端模式;
- 大端法(big-endian):在内存中,数据按照最高有效字节存储到最低有效字节的顺序进行存储,即数据的高位字节在低地址处,低位字节在低地址处。通常网络字节序都是采用的大端法。
以一个简单的整型数0x12345678为例,可以查看其在使用小端法和大端法存储时的差异:
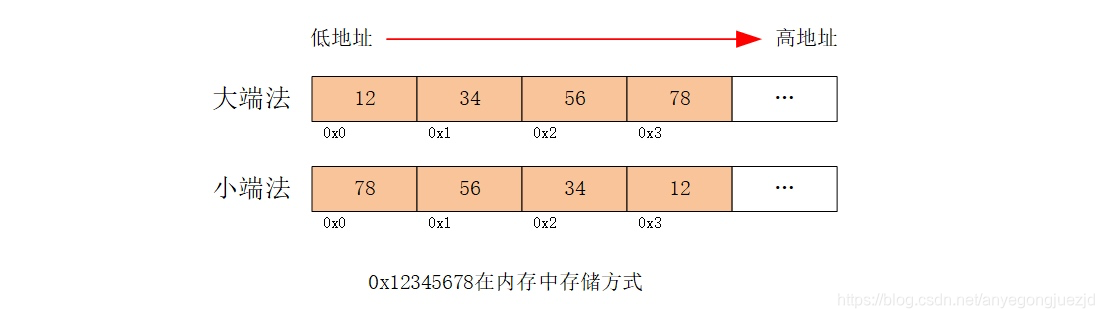
一般来说,机器的字节序对于上层应用完全是不可见的,程序编译时已经帮我们进行了处理,但是在一些特殊的场景中,典型的如在不同类型的机器之间传输数据时,就必须要考虑字节序差异的问题。
使用union确认系统的字节序
对于特定的硬件体系结构,使用的字节顺序基本都是确定的,Linux下可以使用lscpu命令进行查看。更通用的,我们可以自己编写程序使用union联合体来进行确认:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
union CheckEndianness{
int i_val;
char c_val;
}endian = {0};
endian.i_val = 1;
printf("c_val is %d.\n", endian.c_val);
return 0;
}
上述程序中,c_val的值始终存储于最低内存地址中。运行上述程序,如果c_val显示的结果为1,则说明当前机器是小端模式;若c_val显示的结果为0,则说明当前机器是大端模式。
比特序
字节序关注的是多字节数据的不同字节在内存中排列顺序,而比特序关注的是单个字节内bit的排列顺序。对于某个确定的计算机系统,比特序通常与字节序保持一致,即:
- 大端模式:在大端系统中,数据每个字节的最高有效位(Most Significant Bit)存放在内存最低bit位处;
- 小端模式:在小端系统中,数据每个字节的最低有效位(Least Significant Bit)存放在内存最低bit位处。
考虑一个最简单的单字节的数据0x34,在不同机器上的存储:
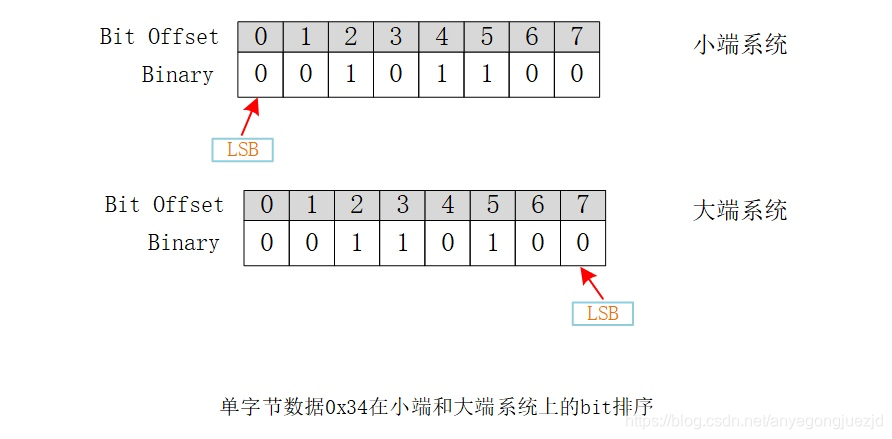
从图中可以看到,小端系统默认从内存的低比特位开始存储数据,而大端系统则从内存的高比特位开始存储。在大部分情况下,计算机系统已经隐式帮我们做了转换处理,只有在一些极特殊的场景下,比如使用位域,我们需要考虑比特序差异可能带来的影响。
大小端差异的本质
实际上,大端机器和小端机器区别的本质是由于处理器的数据引脚和系统地址总线的连接方向的不同,这导致了不同的机器会按照不同的方法来解释高低字节以及单个字节内的高低位顺序。在此我们以32位整型数0x12345678为例,查看多字节的数据在大端和小端机器上内存布局的差异:

我们可以看到内存中位的排列顺序后,大端和小端系统上,除了明显的字节排列上的差异,对于数据特定的某个字节在内存中的比特序列是完全相反的。在日常的数字书写规则中,我们一般都是从左到右进行书写,并且都是先写数字的高位再写低位,从这点上看,大端系统的表示更符合我们平常的书写习惯;而小端系统上,由于实际数据的高低有效位与内存bit的高低位是一致的,对于我们日常进行数据运算来说要更容易理解一些。
写在最后
在考虑字节序和比特序问题时,有一个简单的规则:在对数据进行整存整取时,此时不需要考虑序列的差异,系统默认会帮我们处理一切;但是在对数据进行零存整取或者整存零取时,就必须关注大小端可能会带来的差异。
相关参考
- 《深入理解计算机系统》
- 《计算机组成与体系结构性能设计》
- 《Byte and Bit Order Dissection》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号