KNN分类算法及实例
本文介绍机器学习中入门的KNN(K-Nearest Neighbors )分类算法。
参考:
- https://scikit-learn.org.cn/view/695.html
- https://zhuanlan.zhihu.com/p/38430467
- https://zhuanlan.zhihu.com/p/53084915
- https://zhuanlan.zhihu.com/p/23191325
一:KNN分类概述
KNN分类器作为有监督学习中较为通俗易懂的分类算法,在各类分类任务中经常使用。
KNN模型的核心思想很简单,即近朱者赤、近墨者黑,它通过将每一个测试集样本点与训练集中每一个样本之间测算欧氏距离,然后取欧氏距离最近的K个点(k是可以人为划定的近邻取舍个数,K的确定会影响算法结果),并统计这K个训练集样本点所属类别频数,将其中频数最高的所属类别化为该测试样本点的预测类别。
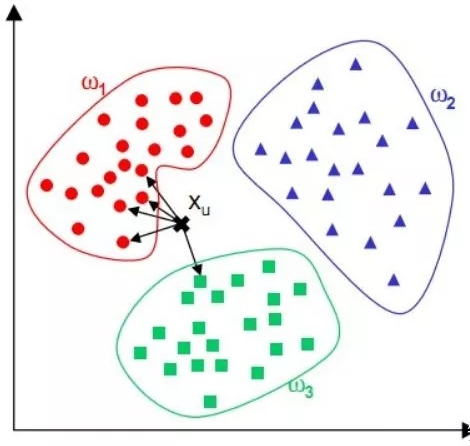
KNN用于分类
如下图所示,图中的正方形和三角形是打好了label的数据,分别代表不同的标签,那个绿色的圆形是我们待分类的数据。
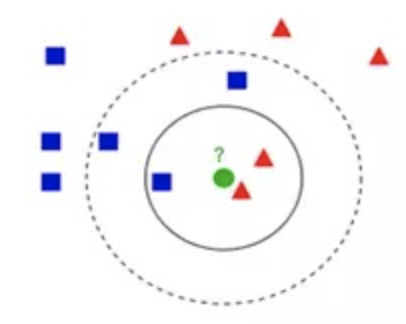
- 如果选K=3,那么离绿色点最近K个点中有2个三角形和1个正方形,这3个点投票,三角形的比例占2/3,于是绿色的这个待分类点属于三角形类别。
- 如果选K=5,那么离绿色点最近K个点中有2个三角形和3个正方形,这5个点投票,蓝色的比例占3/5,于是绿色的这个待分类点属于正方形类别。
从上述例子看到,KNN本质是基于一种数据统计的方法,其实很多机器学习算法也是基于数据统计的。同时, KNN是一种instance-based learning,属于lazy learning, 即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,就可以直接开始分类。其中,每次判断一个未知的样本点时,就在该样本点附近找K个最近的点进行投票,这就是KNN中K的意义,通常K是不大于20的整数。
一般来说,KNN分类算法的计算过程:
- 计算待分类点与已知类别的点之间的距离
- 按照距离递增次序排序
- 选取与待分类点距离最小的K个点
- 确定前K个点所在类别的出现次数
- 返回前K个点出现次数最高的类别作为待分类点的预测分类
K值的选择
如果选择较小的K值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差会减小,只有输入实例较近的训练实例才会对预测结果起作用。但缺点是“学习”的估计误差会增大,预测结果会对近邻实例点非常敏感。如果邻近的实例点恰巧是噪声,预测就会出错。换句话说,K值得减小就意味着整体模型非常复杂,容易发生过拟合。
如果选择较大的K值,就相当于用较大邻域中的训练实例进行预测,其实优点是减少学习的估计误差,但缺点是学习的近似误差会增大。这时与输入实例较远的训练实例也会起预测作用,使预测发生错误,k值的增大就意味着整体的模型变得简单,容易发生欠拟合。可以假定极端条件K=N,那么无论输入实例是什么,都将简单的预测它属于训练实例中最多的类。这时,模型过于简单,完全忽略训练中的大量有用信息,是不可取的。
在应用中,通常采用交叉验证法来选择最优K值。从上面的分析也可以知道,一般K值取得比较小。我们会选取K值在较小的范围,同时在验证集上准确率最高的那一个确定为最终的算法超参数K。
距离度量选择
- 闵可夫斯基距离(Minkowski distance)
- 欧氏距离
- 曼哈顿距离
距离度量的方式在聚类等算法中都很常见,本文不再详细描述
KNN的优缺点
优点:
1)算法简单,理论成熟,既可以用来做分类也可以用来做回归。
2)可用于非线性分类。
3)没有明显的训练过程,而是在程序开始运行时,把数据集加载到内存后,不需要进行训练,直接进行预测,所以训练时间复杂度为0。
4)由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属的类别,因此对于类域的交叉或重叠较多的待分类样本集来说,KNN方法较其他方法更为适合。
5)该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量比较小的类域采用这种算法比较容易产生误分类情况。
缺点:
1)需要算每个测试点与训练集的距离,当训练集较大时,计算量相当大,时间复杂度高,特别是特征数量比较大的时候。
2)需要大量的内存,空间复杂度高。
3)样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少),对稀有类别的预测准确度低。
4)是lazy learning方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢。
二:实例
本文以Kaggle中的例题为例,我做了一些编辑和修改:https://www.kaggle.com/asprant/who-says-you-can-t-use-knn-for-big-dataset
例题是一个基因分类的问题,通过给定基因片段的碱基对数目来预测该基因片段属于那种基因,数据集格式:

代码:
导入需要的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
import warnings
warnings.filterwarnings("ignore")
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.model_selection import StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from tqdm.notebook import tqdm
这里主要还是用到sklearn
定义一些函数:
# 常见的用于减小内存的预处理
def reduce_mem_usage(df, verbose=True):
numerics = ['int8','int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem))
return df
# Custom print function by @kartik2khandelwal
def my_print(s):
a = 4
for i in s:
a+=1
return print('-' * a + '\n' + '| ' + s + ' |' + '\n' + '-' * a)
# quantile是pandas中的分位函数,此方法用于将样本中过大或过小的值处理为空值以免影响分类结果
def quantile(df):
for i in df.columns:
low = df[i].quantile(0.005)
high = df[i].quantile(0.99)
df[i] = df[i].apply(lambda x:np.NaN if(x > high or x < low) else x)
my_print('DataFrame columns are now in Quantile Range')
return df
# IterativeImputer用于空值的插补,详见:https://scikit-learn.org.cn/view/280.html
def iterative_imputer(df):
my_print(f'Null Values - {df.isnull().sum().sum()}')
my_print('Applying Iterative Imputer...')
imputer = IterativeImputer(max_iter=10)
data = imputer.fit_transform(df)
df = pd.DataFrame(data, columns=list(df.columns))
my_print('Iterative Imputer Applied !!!')
my_print(f'Null Values Left - {df.isnull().sum().sum()}')
return df
数据集的导入
df = pd.read_csv('../input/tabular-playground-series-feb-2022/train.csv')
X_test = pd.read_csv('../input/tabular-playground-series-feb-2022/test.csv')
X_test.drop('row_id', axis=1, inplace=True)
X_test = reduce_mem_usage(X_test)
df = reduce_mem_usage(df)
目标编码(本例中用的手动方式)
d = {'Salmonella_enterica': 0, 'Enterococcus_hirae': 1, 'Escherichia_coli': 2, 'Streptococcus_pyogenes': 3,
'Campylobacter_jejuni': 4, 'Streptococcus_pneumoniae': 5, 'Staphylococcus_aureus': 6,
'Escherichia_fergusonii': 7, 'Bacteroides_fragilis': 8, 'Klebsiella_pneumoniae': 9}
d_inv = {v: k for k, v in d.items()}
剥离输入和输出
X = df.drop(['target', 'row_id'], axis=1)
y = df['target']
y = y.map(d)
数据清洗,这里操作是擦除过大/小的值并插补
X = quantile(X)
X = iterative_imputer(X)
模型训练
N_SPLITS = 5
y_preds = []
# 将数据切分为训练集或测试集
folds = StratifiedKFold(n_splits=N_SPLITS, shuffle=True)
for fold, (train_id, test_id) in enumerate(folds.split(X, y)):
X_train = X.iloc[train_id]
y_train = y.iloc[train_id]
X_valid = X.iloc[test_id]
y_valid = y.iloc[test_id]
model = KNeighborsClassifier(3)
model.fit(X_train, y_train)
valid_score = model.score(X_valid, y_valid)
print(f'Fold: {fold + 1}')
my_print(f'Training Accuracy :- {(model.score(X_train, y_train)*100).round(2)}%')
my_print(f'Validation Accuracy :- {(model.score(X_valid, y_valid)*100).round(2)}%')
y_preds.append(model.predict(X_test))
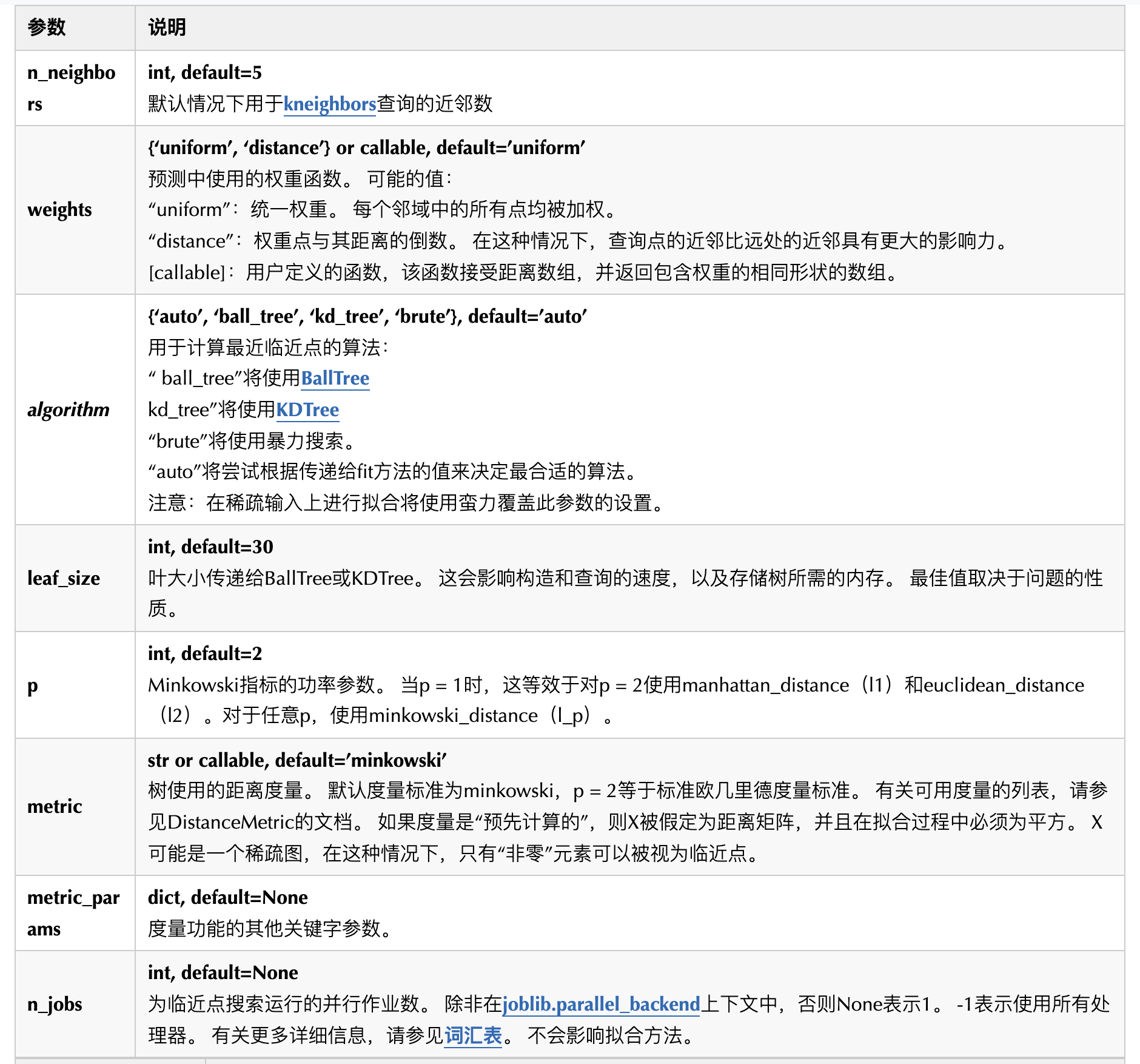
这里介绍一下KNeighnborsClassifier这个函数的参数:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号