Pandas笔记(二)
本文介绍常用Pandas列(Series)数据特征提取方法
我们以一组酒的数据为例,将数据保存到reviews,然后用heads()预览一下:
import pandas as pd
pd.set_option("display.max_rows", 5)
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
reviews.head()
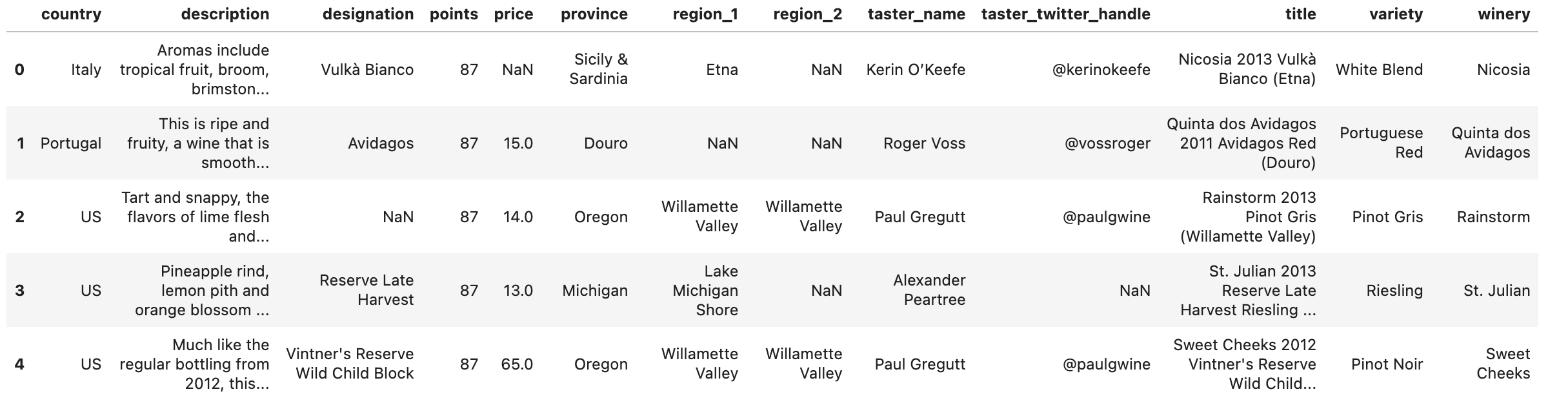
后面列出一些针对Series的方法:
- 求平均值
mean_points = reviews.points.means()
- 求中值
median_points = reviews.points.median()
- 输出集合
countries = reviews.country.unique()
这里返回一个list
- 输出元素个数
reviews_per_country = reviews.country.value_counts()
注意输出格式:
US 54504
France 22093
...
China 1
Egypt 1
Name: country, Length: 43, dtype: int64
- 最大索引和最小索引
idxmax()和idxmin()
bargain_idx = (reviews.points / reviews.price).idxmax()
bargain_wine = reviews.loc[bargain_idx, 'title']
- 用map匹配数据
通过lambda函数创建新的Series
price_mean = reviews.price.mean()
centered_price = reviews.price.map(lambda p: p - price_mean)
n_trop = reviews.description.map(lambda desc: "tropical" in desc).sum()
n_fruity = reviews.description.map(lambda desc: "fruity" in desc).sum()
descriptor_counts = pd.Series([n_trop, n_fruity], index=['tropical', 'fruity'])
- 用apply匹配数据
通过传递函数创建新的Series,可以指定对象为行或者列
def stars(row):
if row.country == 'Canada':
return 3
elif row.points >= 95:
return 3
elif row.points >= 85:
return 2
else:
return 1
star_ratings = reviews.apply(stars, axis='columns')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号