Pandas笔记(一)
最近在Kaggle上学习Machine Learning,对于机器学习工程师来说pandas实在太重要,写几篇博客作pandas课程的笔记
1. DataFrame的创建
DataFrame可以看作一个数据表格,创建一个带索引的DataFrame:
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])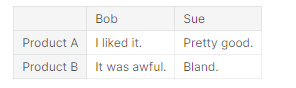
Series是DataFrame的一列数据,DataFrame可以看作一个Series的集合,创建一个带索引的Series
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')Out:
2015 Sales 30
2016 Sales 35
2017 Sales 40
Name: Product A, dtype: int64
2. DataFrame的读写
从csv中读取数据:
data = pd.read_csv('datasets/train.csv')写csv:
data.to_csv('datasets/output.csv')
从excel中读取:
import pandas as pd
original_data = pd.read_excel('datasets/xxx.xlsx', 'Sheet1')
3. 数据的预览
显示行列数
original_data.shape显示前5行
original_data.head()预览数据统计
original_data.describe()4. 数据的索引和切片
取列:
reviews.countryreviews['country']取country列第一个值:
reviews['country'][0]loc和iloc:
参考:Pandas loc/iloc用法详解 (biancheng.net)
| 方法名称 | 说明 |
|---|---|
| .loc[] | 基于标签索引选取数据 |
| .iloc[] | 基于整数索引选取数据 |
iloc
reviews.iloc[0]取第0行元素
reviews.iloc[:, 0]取第0列
reviews.iloc[:3, 0]取前3行,0列
reviews.iloc[1:3, 0]取1~3行,0列
reviews.iloc[[0, 1, 2], 0]取第0,1,2行,0列
reviews.iloc[-5:]取第0,1,2行,0列
loc
reviews.loc[0, 'country']取第0行,country列
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]取所有行,列索引为列表中的列
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]reviews.loc[(reviews.country == 'Italy') | (reviews.points >= 90)]reviews.loc[reviews.country.isin(['Italy', 'France'])]reviews.loc[reviews.price.notnull()]条件索引示例
5. 查找替换
关于replace这篇博客比较详细
转载:
查看代码# -*- coding: utf-8 -*-
"""
Created on Tue Jul 21 10:52:00 2020
@author: Admin
"""
import pandas as pd
import numpy as np
#构造数据
df=pd.DataFrame({'a':['?',7499,'?',7566,7654,'?',7782],'b':['SMITH', '.','$','.' ,'MARTIM','BLAKE','CLARK'],
'c':['CLERK','SALESMAN','$','MANAGER','$','MANAGER','$'],
'd':[7902,7698,7698,7839,7698,7839,7839],
'e':['1980/12/17','1981/2/20','1981/2/22','1981/4/2','1981/9/28','1981/5/1','1981/6/9'],
'f':[800,1600,1250,2975,1230,2859,2450],
'g':[np.nan,300.0,500.0,np.nan,1400.0,np.nan,np.nan],
'h':[20,30,30,20,30,30,10]})
#替换全部或者某行某列
#全部替换,这二者效果一样
df.replace(20,30)
df.replace(to_replace=20,value=30)
#某一列或者某几列
df['h'].replace(20,30)
df[['b','c']].replace('$','rmb')
#某一行或者几行
df.iloc[1].replace(1600,1700)
df.iloc[1:3].replace(30,40)
#inplace=True
df.replace(20,30,inplace=True)
df.iloc[1:3].replace(30,40,inplace=True)
#用list或者dict进行单值或者多值填充,
#单值
#注意,list是前者替换后者,dict字典里的建作为原值,字典里的值作为替换的新值
df.replace([20,30])
df.replace({20:30})
#多值,list是list逗号后的值替换list的值,dict字典里的建作为原值,字典里的值作为替换的新值
df.replace([20,1600],[40,1700]) #20被40替换,1600被1700替换
df.replace([20,30],'b') #20,30都被b替换
df.replace({20:30,1600:1700})
df.replace({20,30},{'a','b'}) #这个和list多值用法一样
#,method
#其实只需要传入被替换的值,
df.replace(['a',30],method='pad')
df.replace(['a',30],method='ffill')
df.replace(['a',30],method='bfill')
#可以直接这样表达
df.replace(30,method='bfill') #用30下面的最靠近非30的值填充
df.replace(30,method='ffill') #用30上面最靠近非30的值填充
df.replace(30,method='pad') #用30上面最靠近非30的值填充
#一般用于空值填充
df.replace(np.nan,method='bfill')
#limit
df.replace(30,method='bfill',limit=1) #现在填充的间隔数
#正则替换
#转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\
#如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义
df.replace(r'\?|\.|\$',np.nan) #和原来没有变化
df.replace(r'\?|\.|\$',np.nan,regex=True)#用np.nan替换?或.或$原字符
df.replace([r'\?',r'\$'],np.nan,regex=True)#用np.nan替换?和$
df.replace([r'\?',r'\$'],[np.nan,'NA'],regex=True)#用np.nan替换?用NA替换$符号
df.replace(regex={r'\?':None})
#当然,如果不想使用inplace=True,也可以这样子表达
df=df.replace(20,30)
df.replace(20,30,inplace=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号