Python - opencv(十)特征匹配和图像拼接
参考:
https://blog.csdn.net/qq_40369926/article/details/88597406
https://www.bilibili.com/video/BV1PV411774y?p=58
手机的全景拍照功能可以将数张照片无缝凭借成一张长照片,用的便是特征匹配和图像拼接的相关算法。本文介绍基于Python-opencv的实现
SIFT特征匹配
理论部分懒得码字,搬运博客原文:
SIFT(Scale Invariant Feature Transform,尺度不变特征变换匹配算法)是由David G. Lowe教授在1999年(《Object Recognition from Local Scale-Invariant Features》)提出的高效区域检测算法,在2004年(《Distinctive Image Features from Scale-Invariant Keypoints》)得以完善。
SIFT可以应用到物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对等方向。
SIFT算法的特点:
稳定性
独特性
多量性
高速性
可扩展性
SIFT算法可以的解决问题:
目标的旋转、缩放、平移(RST)
图像放射/投影变换(视点viewpoint)
光照影响(illumination)
部分目标遮挡(occlusion)
杂物场景(clutter)
噪声
SIFT原理
1.检测尺度空间极值
检测尺度空间极值就是搜索所有尺度上的图像位置,通过高斯微分函数来识别对于尺度和旋转不变的兴趣点。其主要步骤可以分为建立高斯金字塔、生成DOG高斯差分金字塔和DOG局部极值点检测。为了让大家更清楚,我先简单介绍一下尺度空间,再介绍主要步骤。
(1)尺度空间
一个图像的尺度空间,定义为一个变化尺度的高斯函数与原图像的卷积。即:
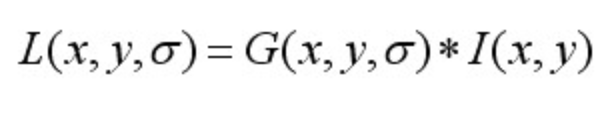
其中,*表示卷积计算。
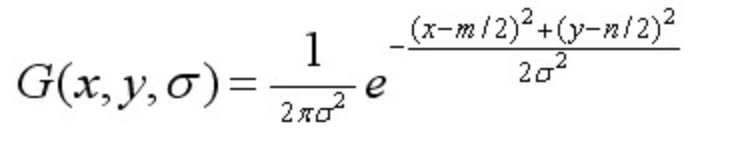
其中,m、n表示高斯模版的维度,(x,y)代表图像像素的位置。为尺度空间因子,值越小表示图像被平滑的越少,相应的尺度就越小。小尺度对应于图像的细节特征,大尺度对应于图像的概貌特征,效果如下图所示,尺度从左到右,从上到下,依次增大。

(2)建立高斯金字塔
尺度空间在实现时,使用高斯金字塔表示,高斯金字塔的构建分为两部分:
1.对图像做不同尺度的高斯模糊
2.对图像做降采样(隔点采样)
图像的金字塔模型是指,将原始图像不断降阶采样,得到一系列大小不一的图像,由大到小,从下到上构成的塔状模型。原图像为金子塔的第一层,每次降采样所得到的新图像为金字塔的上一层(每层一张图像),每个金字塔共n层。金字塔的层数根据图像的原始大小和塔顶图像的大小共同决定。

为了让尺度体现其连续性,高斯金字塔在简单降采样的基础上加上了高斯滤波。如上图所示,将图像金字塔每层的一张图像使用不同参数做高斯模糊,使得金字塔的每层含有多张高斯模糊图像,将金字塔每层多张图像合称为一组(Octave),金字塔每层只有一组图像,组数和金字塔层数相等,每组含有多层Interval图像。
高斯图像金字塔共o组、s层, 则有:
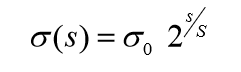
其中,σ表示尺度空间坐标,s表示sub-level层坐标,表示初始尺度,S表示每组层数(一般为3~5)
(3)建立DOG高斯差分金字塔
为了有效提取稳定的关键点,利用不同尺度的高斯差分核与卷积生成。
DOG函数:

DOG在计算上只需相邻高斯平滑后图像相减,因此简化了计算!

可以通过高斯差分图像看出图像上的像素值变化情况。(如果没有变化,也就没有特征。特征必须是变化尽可能多的点。)DOG图像描绘的是目标的轮廓。
(4)DOG局部极值检测
特征点是由DOG空间的局部极值点组成的。为了寻找DOG函数的极值点,每一个像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域 的相邻点大或者小。

中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个 点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。
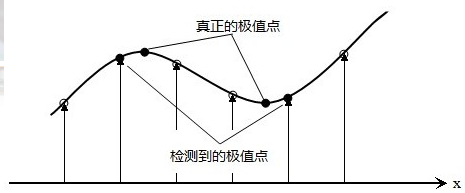
2.关键点的精确定位
以上方法检测到的极值点是离散空间的极值点,以下通过拟合三维二次函数来精确确定关键点的位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点(因为DOG算子会产生较强的边缘响应),以增强匹配稳定性、提高抗噪声能力。
(1)关键点的精确定位
利用已知的离散空间点插值得到的连续空间极值点的方法叫做子像素插值(Sub-pixel Interpolation)。
为了提高关键点的稳定性,需要对尺度空间DOG函数进行曲线拟合。利用DOG函数在尺度空间的Taylor展开式(拟合函数)为:
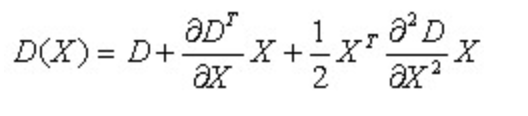
其中,![]() 。求导并让方程等于零,可以得到极值点的偏移量为:
。求导并让方程等于零,可以得到极值点的偏移量为:
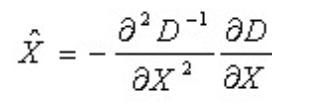
对应极值点,方程的值为:
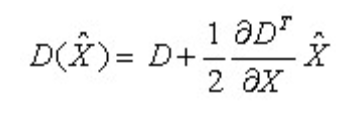
其中, ![]() 代表相对插值中心的偏移量,当它在任一维度上的偏移量大于0.5时(即x或y或),意味着插值中心已经偏移到它的邻近点上,所以必须改变当前关键点的位置。同时在新的位置上反复插值直到收敛;也有可能超出所设定的迭代次数或者超出图像边界的范围,此时这样的点应该删除,在Lowe中进行了5次迭代。另外,|D(x)|过小的点易受噪声的干扰而变得不稳定,所以将小于某个经验值(Lowe论文中使用0.03,Rob Hess等人实现时使用0.04/S)的极值点删除。
代表相对插值中心的偏移量,当它在任一维度上的偏移量大于0.5时(即x或y或),意味着插值中心已经偏移到它的邻近点上,所以必须改变当前关键点的位置。同时在新的位置上反复插值直到收敛;也有可能超出所设定的迭代次数或者超出图像边界的范围,此时这样的点应该删除,在Lowe中进行了5次迭代。另外,|D(x)|过小的点易受噪声的干扰而变得不稳定,所以将小于某个经验值(Lowe论文中使用0.03,Rob Hess等人实现时使用0.04/S)的极值点删除。
(2)去除边缘响应
由于DOG函数在图像边缘有较强的边缘响应,因此需要排除边缘响应DOG函数的峰值点在边缘方向有较大的主曲率,而在垂直边缘的方向有较小的主曲率。主曲率可以通过计算在该点位置尺度的2×2的Hessian矩阵得到,导数由采样点相邻差来估计:
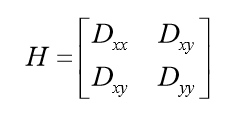
![]() 表示DOG金字塔中某一尺度的图像x方向求导两次。
表示DOG金字塔中某一尺度的图像x方向求导两次。
D的主曲率和H的特征值成正比。令 α ,β为特征值,则

该值在两特征值相等时达最小。Lowe论文中建议阈值T为1.2,即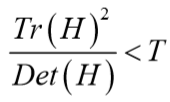 时保留关键点,反之剔除。
时保留关键点,反之剔除。
在Lowe的论文中,取r=10。下图右侧为消除边缘响应后的关键点分布图。

3.关键点主方向分配
关键点主方向分配就是基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,使得描述符具有旋转不变性。
对于在DOG金字塔中检测出的关键点,采集其所在高斯金字塔图像3σ邻域窗口内像素的梯度和方向分布特征。梯度的模值和方向如下:
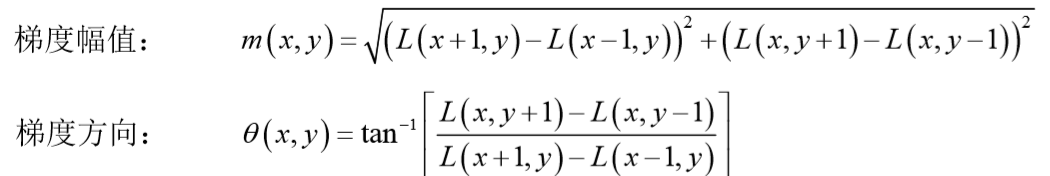
L为关键点所在的尺度空间值,按Lowe的建议,梯度的模值m(x,y)按σ=1.5σ_oct的高斯分布加成,按尺度采样的3σ原则,邻域窗口半径为3*1.5σ_oct。
在完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向。梯度直方图将0~360度的方向范围分为36个柱(bins),其中每柱10度。如下图所示,直方图的峰值方向代表了关键点的主方向,(为简化,图中只画了八个方向的直方图)。

方向直方图的峰值代表了该特征点处邻域梯度的方向,以直方图中最大值作为该关键点的主方向。为了增强匹配的鲁棒性,只保留峰值大于主方向峰值80%的方向作为该关键点的辅方向。Lowe的论文指出大概有15%关键点具有多方向,但这些点对匹配的稳定性至为关键。检测结果如下图:

至此,将检测出的含有位置、尺度和方向的关键点即是该图像的SIFT特征点。
4.关键点的特征描述
通过以上步骤,对于每一个关键点,拥有三个信息:位置、尺度以及方向。接下来就是为每个关键点建立一个描述符,用一组向量将这个关键点描述出来,使其不随各种变化而改变,比如光照变化、视角变化等。这个描述子不但包括关键点,也包含关键点周围对其有贡献的像素点,并且描述符应该有较高的独特性,以便于提高特征点正确匹配的概率。
SIFT描述子是关键点邻域高斯图像梯度统计结果的一种表示。通过对关键点周围图像区域分块,计算块内梯度直方图,生成具有独特性的向量,这个向量是该区域图像信息的一种抽象,具有唯一性。
Lowe建议描述子使用在关键点尺度空间内4*4的窗口中计算的8个方向的梯度信息,共4*4*8=128维向量表征。表示步骤如下:
(1)计算描述子所需的图像区域
(2)将坐标轴旋转为关键点的方向

(3)将邻域内的采样点分配到对应的子区域内
(4)插值计算每个种子八个方向的梯度

(5)描述符向量元素门限化(阈值)
(6)描述符向量元素归一化
关键点匹配
分别对模板图(参考图,reference image)和实时图(观测图, observation image)建立关键点描述子集合。目标的识别是通过两点 集内关键点描述子的比对来完成。具有128维的关键点描述子的相似 性度量采用欧式距离。
代码示例:
1. Brute-Force暴力匹配方法
代码:
import cv2
img1 = cv2.imread('../pics/part.jpg')
img2 = cv2.imread('../pics/whole.jpg')
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 1v1 mapping
bf = cv2.BFMatcher(crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None, flags=2)
cv2.imshow('match', img3)
cv2.waitKey()
# multi mapping
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
good = []
for m,n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
img4 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good, None, flags=2)
cv2.imshow('match k', img4)
cv2.waitKey()(别人做的效果,本人实验效果很差)

2. ransec 算法进行图像拼接
因为没有找到很好的素材做,本人自己拍了几个样张做拼接效果都很差,搬运一篇别人做好的:
https://www.jb51.net/article/183678.htm
代码:
1 import cv2 2 import numpy as np 3 from matplotlib import pyplot as plt 4 import time 5 MIN = 10 6 starttime=time.time() 7 img1 = cv2.imread('1.jpg') #query 8 img2 = cv2.imread('2.jpg') #train 9 10 #img1gray=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY) 11 #img2gray=cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY) 12 surf=cv2.xfeatures2d.SURF_create(10000,nOctaves=4,extended=False,upright=True) 13 #surf=cv2.xfeatures2d.SIFT_create()#可以改为SIFT 14 kp1,descrip1=surf.detectAndCompute(img1,None) 15 kp2,descrip2=surf.detectAndCompute(img2,None) 16 17 FLANN_INDEX_KDTREE = 0 18 indexParams = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5) 19 searchParams = dict(checks=50) 20 21 flann=cv2.FlannBasedMatcher(indexParams,searchParams) 22 match=flann.knnMatch(descrip1,descrip2,k=2) 23 24 good=[] 25 for i,(m,n) in enumerate(match): 26 if(m.distance<0.75*n.distance): 27 good.append(m) 28 29 if len(good)>MIN: 30 src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2) 31 ano_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2) 32 M,mask=cv2.findHomography(src_pts,ano_pts,cv2.RANSAC,5.0) 33 warpImg = cv2.warpPerspective(img2, np.linalg.inv(M), (img1.shape[1]+img2.shape[1], img2.shape[0])) 34 direct=warpImg.copy() 35 direct[0:img1.shape[0], 0:img1.shape[1]] =img1 36 simple=time.time() 37 38 #cv2.namedWindow("Result", cv2.WINDOW_NORMAL) 39 #cv2.imshow("Result",warpImg) 40 rows,cols=img1.shape[:2] 41 left, right = (0,0) 42 43 for col in range(0,cols): 44 if img1[:, col].any() and warpImg[:, col].any():#开始重叠的最左端 45 left = col 46 break 47 for col in range(cols-1, 0, -1): 48 if img1[:, col].any() and warpImg[:, col].any():#重叠的最右一列 49 right = col 50 break 51 52 res = np.zeros([rows, cols, 3], np.uint8) 53 for row in range(0, rows): 54 for col in range(0, cols): 55 if not img1[row, col].any():#如果没有原图,用旋转的填充 56 res[row, col] = warpImg[row, col] 57 elif not warpImg[row, col].any(): 58 res[row, col] = img1[row, col] 59 else: 60 srcImgLen = float(abs(col - left)) 61 testImgLen = float(abs(col - right)) 62 alpha = srcImgLen / (srcImgLen + testImgLen) 63 res[row, col] = np.clip(img1[row, col] * (1-alpha) + warpImg[row, col] * alpha, 0, 255) 64 65 warpImg[0:img1.shape[0], 0:img1.shape[1]]=res 66 final=time.time() 67 img3=cv2.cvtColor(direct,cv2.COLOR_BGR2RGB) 68 plt.imshow(img3,),plt.show() 69 img4=cv2.cvtColor(warpImg,cv2.COLOR_BGR2RGB) 70 plt.imshow(img4,),plt.show() 71 print("simple stich cost %f"%(simple-starttime)) 72 print("\ntotal cost %f"%(final-starttime)) 73 cv2.imwrite("simplepanorma.png",direct) 74 cv2.imwrite("bestpanorma.png",warpImg) 75 else: 76 print("not enough matches!")
效果:
运行结果
原图1.jpg

原图2.jpg

特征点匹配

直接拼接和平滑对比
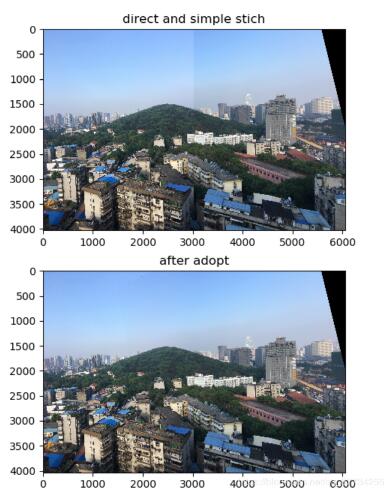
效果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号