Python导出Docx的Comment
用Python写了一段代码,用于将docx中的comment进行导出,导出到另外一个docx文件
用到的Lib:
docx,zipfile,bs4
原理:docx文件重命名为.zip文件,然后解压缩,会发现很多个xml文件
其中comment存放在 word/comments.xml。
另外一个文件 word/commentsExtended.xml,存放comment之间的关系,以及是否完成。
用bs4的BeautifulSoup对文件进行Parse
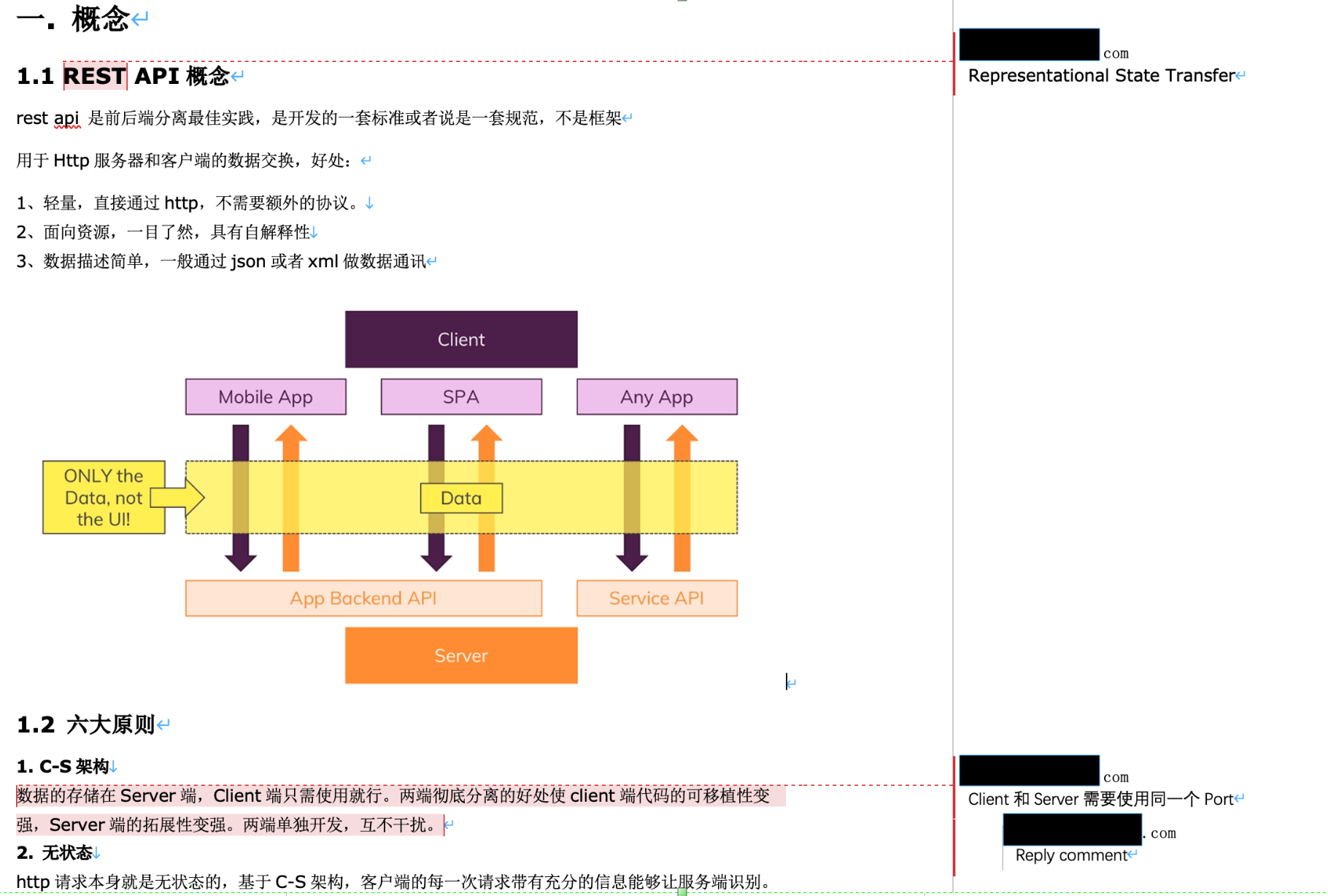
docx文件comment示例:
代码:
1 from zipfile import ZipFile 2 from bs4 import BeautifulSoup 3 from docx import Document 4 5 DOC = Document('untitled.docx') 6 7 8 def export_docx(filename): 9 z = ZipFile(filename) #Mac下无法直接通过zipfile解压,可以手动重命名文件再解压 10 xml = z.read('word/comments.xml') 11 xml_ex = z.read('word/commentsExtended.xml') 12 wordObj = BeautifulSoup(xml.decode("utf-8"), features="html.parser") 13 wordObjEx = BeautifulSoup(xml_ex.decode("utf-8"), features="html.parser") 14 15 new_heading = 'Comments From ' + filename 16 print(new_heading) 17 DOC.add_heading(new_heading, 1) 18 19 # 用于存放comment之间的从属关系的字典,每条comment都有一个独特id 20 commentRelationDic = {} 21 comments = wordObjEx.findAll("w15:commentex") 22 for comment in comments: 23 id = comment.attrs['w15:paraid'] 24 if 'w15:paraidparent' in comment.attrs.keys(): 25 commentRelationDic[id] = True 26 else: 27 commentRelationDic[id] = False 28 comments = wordObj.findAll("w:comment") 29 for comment in comments: 30 author = comment.attrs['w:author'] 31 id = comment.next.attrs['w14:paraid'] 32 if not id in commentRelationDic: 33 DOC.add_paragraph('\n') 34 print('\n') 35 elif not commentRelationDic[id]: 36 DOC.add_paragraph('\n') 37 print('\n') 38 texts = comment.findAll("w:t") 39 comment_text = '' 40 for text in texts: 41 comment_text += text.text 42 p = DOC.add_paragraph() 43 p.add_run(author + '\n').bold = True 44 p.add_run(comment_text) 45 print("%s :"%author) 46 print(comment_text) 47 DOC.add_page_break() 48 DOC.save('Comments.docx') 49 50 51 if __name__ == '__main__': 52 export_docx(DOC)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号