《Engineering a Complier》学习笔记(三)
Parser (语义分析器)
1. 概述
Parser是编译器front-end的第二步,Parser将Scanner识别出的词语按照语义进行分类,并将词语构建成源编程语言的语法模型。
“ The parser derives a syntactic structure for the program, fitting the words into a grammatical model of the source programming language. ”
摘录来自: Keith D. Cooper. “Engineering a Compiler。”
为什么正则表达式不能处理语义?
考虑这种case:我们处理一个数学表达式如 a + b * c,我们构建一个看似可行的正则表达式:
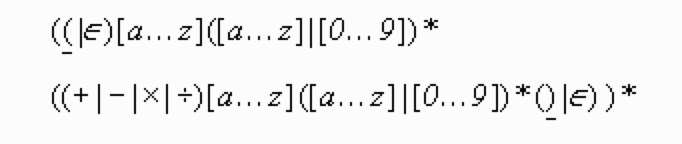
然而,上式既可以匹配"a + b * c",又可以匹配" (a + b) * c" , 正则表达式不能处理括号。
正则表达式无法处理一些重要的语言特征。
2. 上下文无关法
参考:https://blog.csdn.net/antony1776/article/details/86412211
Context-free grammar(CFG):就是上下文无关文法,是一种形式文法(formal grammar)。形式文法是形式语言(formal language)的文法,由一组产生规则(production rules)组成,描述该形式语言中所有可能的字符串形式。形式文法一般可分为四大类:无限制文法(unrestricted grammars),上下文相关文法,上下文无关文法和正则文法(Regular grammar)。
Terminal symbols: 终结符,可以理解为基础符号,词法符号,是不可替代的,天然存在,不能通过文法规则生成!
Nonterminal symbols: 非终结符,或者句法变量。
Production rules: grammar 是由终结符集和、非终结符集和和产生规则共同组成。产生规则定义了符号之间如何转换替代。规则的左侧是规则头,是可以被替代的符号;右侧是规则体,是具体的内容。
上下文无关法由一个四维的元组( T, NT, S, P) 组成:
T: 终结符的集合
NT: 非终结符的集合
S: 语法的目标语义,在语言中等价于语句
P: 代表语法的迭代规则 NT → ( T ∪ NT) +
示例:处理( a + b ) * c
我们构建这样一个CFG:

上图中,Expr,Op为非终结符, (, ), name, +, -, *, / 为终结符, 依次对语法进行解析,生成Parse tree(语法树),也叫 “concrete syntax tree”
语法树的生成可以从左向右Leftmost,也可以从右向左Rightmost,下面给出Rightmost示例:
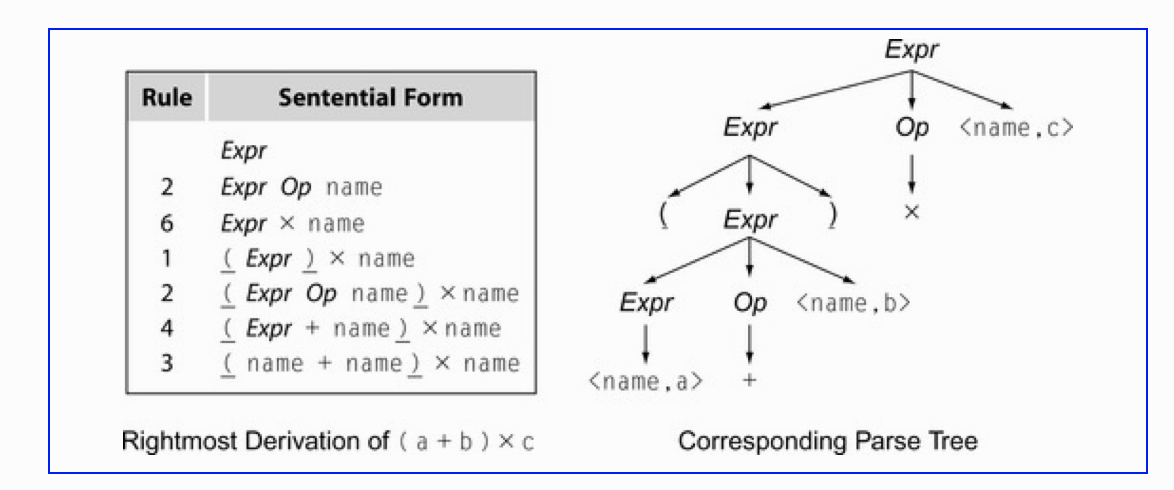
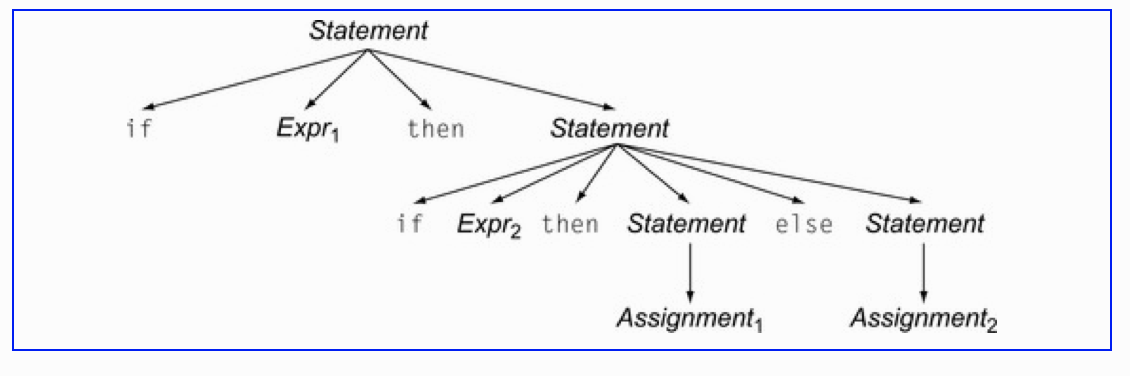
像处理一些复杂点的逻辑,如if...then...else...,语法树的生成:

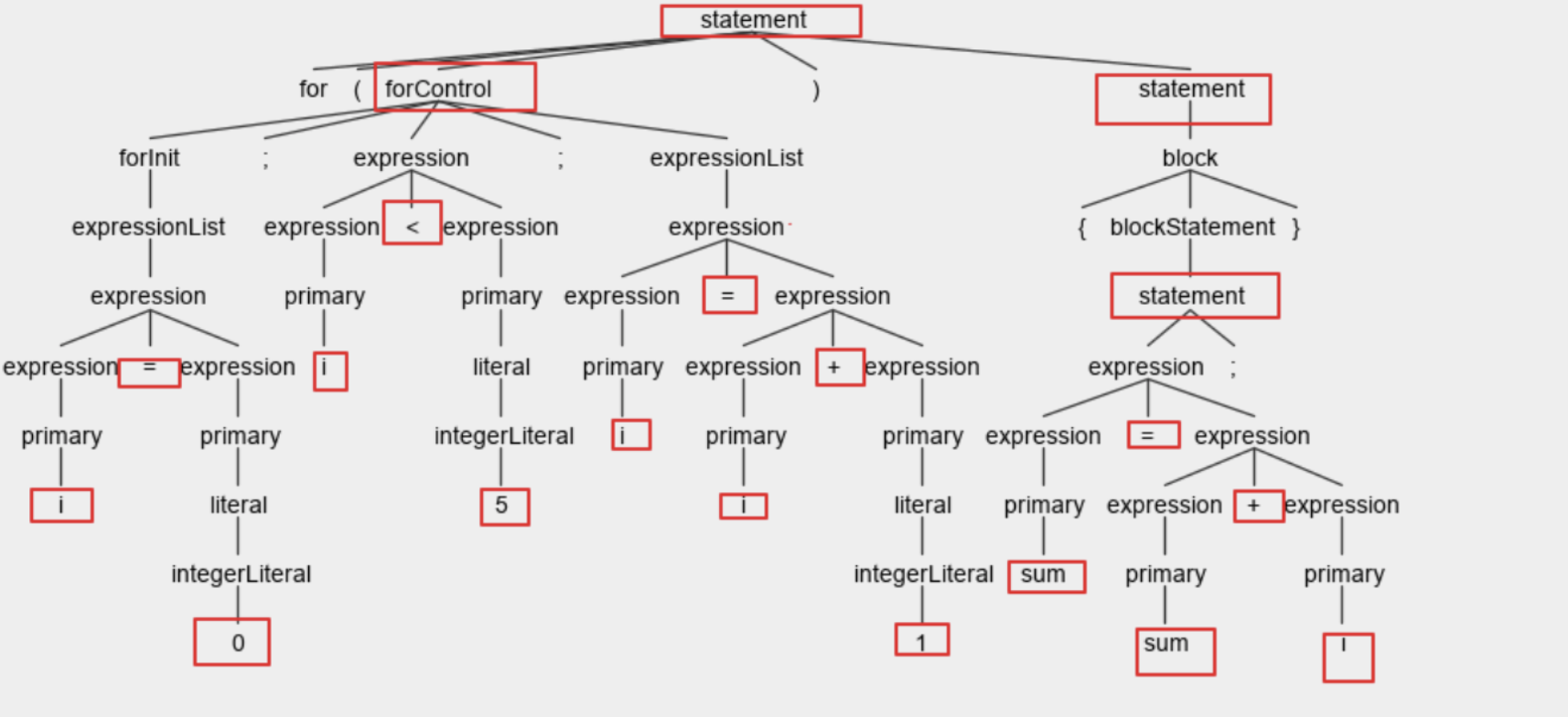
一个简单的for循环的语法树:
1 for (int i = 0 ; i< 5; i=i+1) { sum = sum+i; }
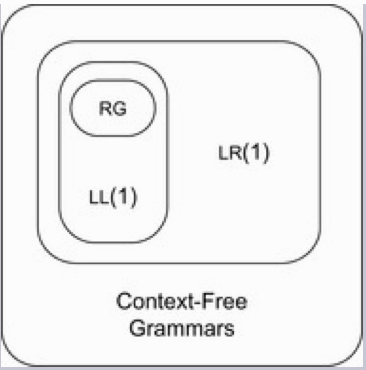
CFG的种类:LR(1),LL(1),RE,抽象CFG
之间的从属关系:
3. 自顶向下的分析方法
自顶向下的分析方法:对于给定输入的字符串ω,从文法的开始符号S出发进行最左推导,直到得到一个合法的句子或发现一个非法结果。在推导的过程中用一切可能的方法为ω构建语法树。
执行自上而下分析的伪代码:

如 a + b * c 理想状态下用自顶向下的分析方法:
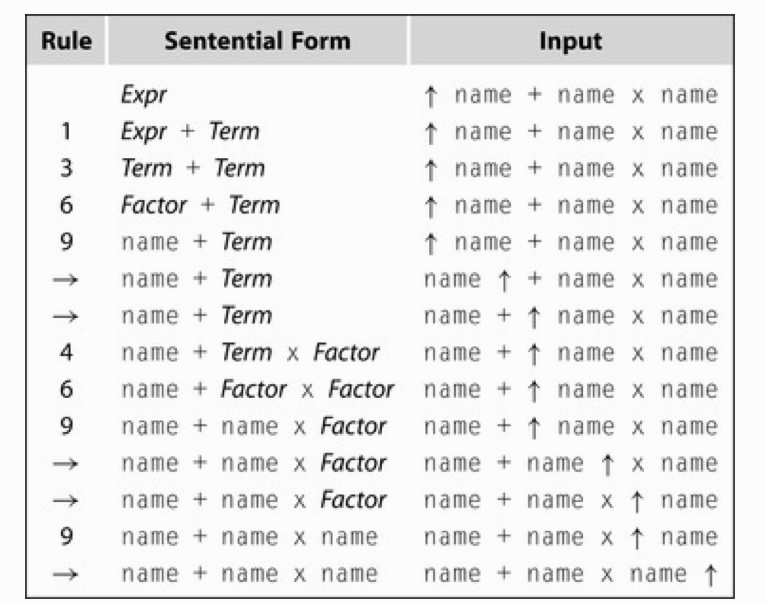
这种处理方法还需要执行消除左递归的步骤来处理异常:
(1)消除左递归
若文法中存在形如 A→Aa的产生式,由于最左推导,可能会产生死循环

右递归转换:

加入右递归转换后的CFG:

将上例进行右递归转换的结果:
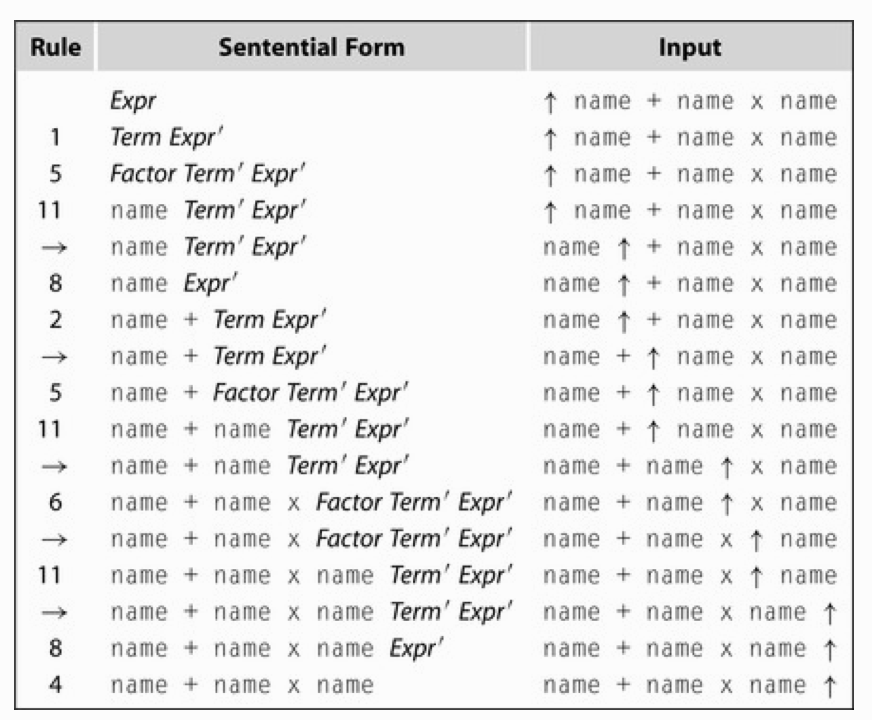
非直接左递归:如这样的产生式:
α → β, β → γ,γ → αδ creates the situation that α → +αδ.
要消除所有的非直接左递归循环,需要将所有的非直接左递归转化为直接左递归,然后再对其使用右递归转换。

(2)可回溯的分析方法
Backtrack-free Parsing是一种可以预测正确的rule production的分析方法。
包含如下两个集合:
FIRST(α)集合:从α出发可以推导出所有以终结符号开头的序列中的开头终结符号的集合
构建CFG的FIRST集:

FOLLOW(A)集合:从文法开始符号可以推导出的所有含A句型中紧跟在A之后的终结符号构成的集合
构建FOLLOW集:

(3)递归下降分析法
为每一个非终结符构造一个子程序,每个子程序的过程体按该产生式的候选项分情况展开,遇到终结符即进行匹配,而遇到非终结符则调用相应子程序。直到所有非终结符都展开为终结符并得到匹配。
对于上述案例CFG递归下降展开伪代码:

(4)构建LL规则表
实现了上述匹配规则以后,可以构建一个LL-Driven Table.
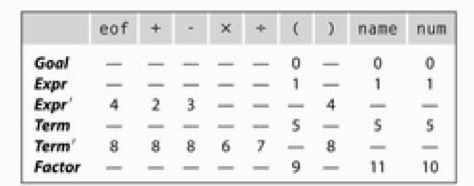
创建表的步骤

表建好后,对于语义的解析可以通过查表来得到相应的规则。
4. 自底向上的分析方法
也成为shift-reduce法,基本思想是对ω从左到右进行扫描,边移进边分析,一旦栈顶符号串形成某个句型的可归约串,就用某个产生式的非终结符来替代。以此迭代,生成语法树。
LR法是一种规范归约的分析法,规范归约是规范推导(Rightmost Derivation)的逆过程。
常见的LR分析法如LR(1)法,含义:
L: Left-to-right scan
R: Reverse-rightmost derivation
1: 1 symbol of lookahead
一个LR(1)分析器由3个部分组成:
(1)驱动器,对于所有LR分析器,驱动程序都是相同的
(2)分析表,包括一个GOTO表和一个ACTION表,都可用二维数组表示
(3)分析栈,包括文法符号栈和相应的状态栈
LR的执行框架:

上图中,LR的4种Action:
Shift:当Action[Si, a]=Sj ,把a移进文法符号栈并转向Sj
Reduce:当在文法符号栈顶形成句柄β时,把β归约为A→β的非终结符A。若β的长度为r,则弹出文法符号栈顶的r个符号,然后将A压入文法符号栈中。
Accept:当文法符号栈中只剩下文法开始的符号S,并且输入符号串已经结束时,分析成功。
Error:当输入串中出现不该有的文法符号时报错
例如,想解析一个带有括号的语法,可构建ACTION和GOTO表如下所示:
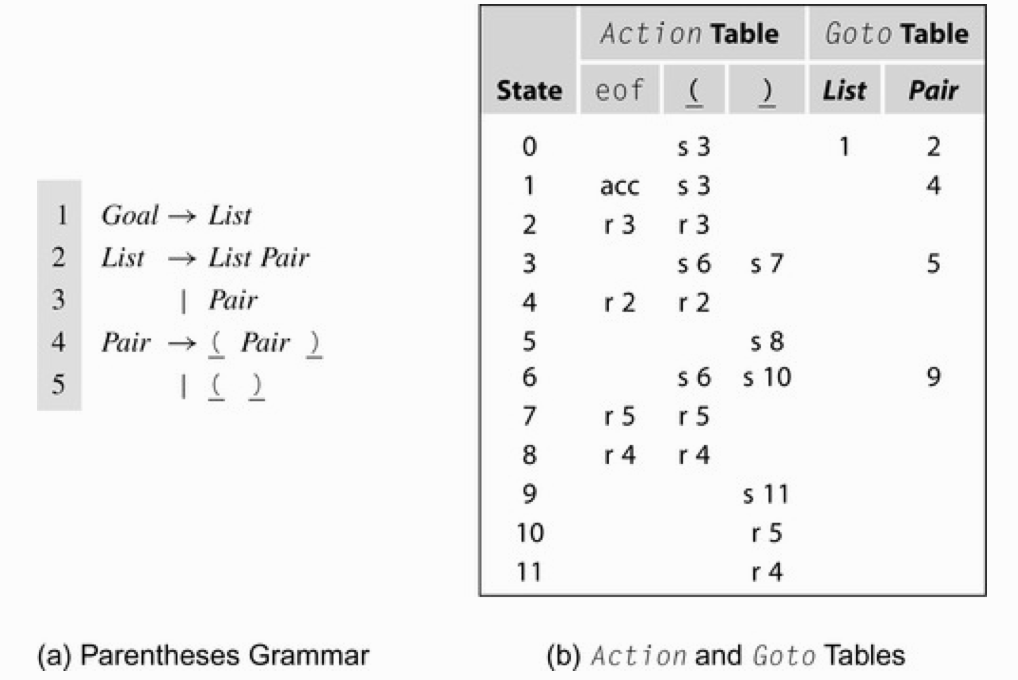
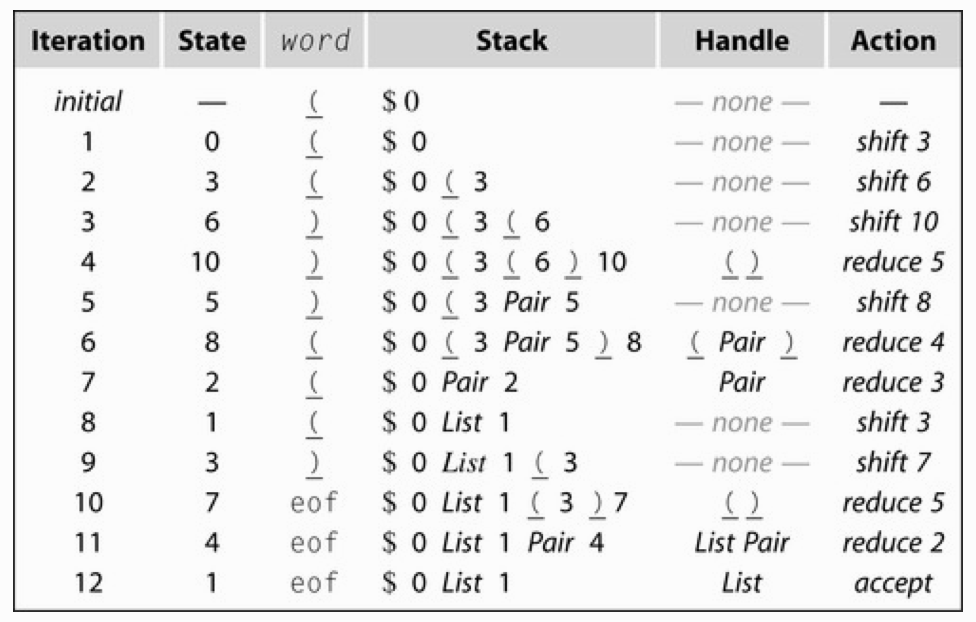
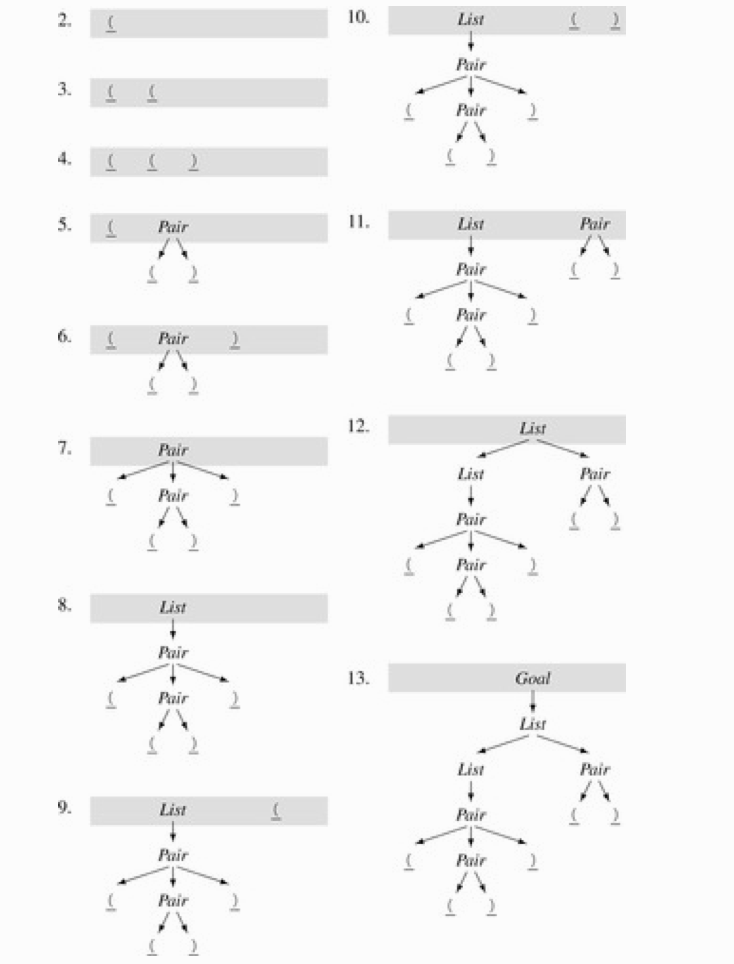
解析具体状态展开如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号