Spark+Kafka集群环境的搭建
1.大数据平台环境的搭建
1.1环境准备
搭建Hadoop集群环境一般建议三个节点以上,一个作为Hadoop的NameNode节点。另外两个作为DataNode节点。在本次实验中,采用了三台CentOS 7.5作为实验环境。
CentOS Linux release 7.5.1804 (Core)
java openjdk version "1.8.0_161"
hadoop-3.3.0
1.2安装Java环境(master + slave1 + salve2)
将所需要的java 文件解压到合适的目录,并将整个java 目录添加进/etc/profile,并source /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
export HADOOP_HOME=/home/postgres/hadoop/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
1.3修改机器的用户名和ip
# 外部IP(一般是千兆网)
192.168.65.140 master
192.168.65.141 slave1
192.168.65.142 slave2
# 内部IP(一般是万兆网)
10.0.0.140 main
10.0.0.141 worker1
10.0.0.142 worker2
1.4每台机器配置ssh免密登录(master + slave1 + salve2)
需要说明的是ssh免密登录的配置不是双向的,是单向的。也就是说,每个节点都需要和另外两个节点进行ssh的免密配置。
[hadoop@master ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/zyjiang/.ssh/id_rsa):
/home/zyjiang/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/zyjiang/.ssh/id_rsa.
Your public key has been saved in /home/zyjiang/.ssh/id_rsa.pub.
The key fingerprint is:
ef:4e:16:cd:32:41:11:20:44:91:bb:fa:40:c2:14:b5 zyjiang@etl1
The key's randomart image is:
+--[ RSA 2048]----+
| ...o=o..+o |
| . ... . |
| . E . . |
| o . + |
| o . .S + o |
| o . . + |
| .. + |
| .. + |
| .. .o |
+-----------------+
此时会在用户目录的.ssh下,生成秘钥文件。现在需要将此验证文件拷贝至slave1节点,
[hadoop@master ~]$ ssh-copy-id hadoop@slave1
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
zyjiang@etl0's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop@slave1'"
and check to make sure that only the key(s) you wanted were added.
[hadoop@master ~]$
1.5安装Hadoop,修改配置文件(master + slave1 + slave2)
# 首先将hadoop导入到server中。
# 然后再将此压缩包安放至某一个目录下
tar xvf hadoop-3.3.0.tar.gz
# 然后在同级目录下创建两个目录
mkdir hdfs
mkdir tmp
在/etc/profile目录下追加:
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=1g"
export ZOOKEEPER_HOME=/home/postgres/zookeeper
export KAFKA_HOME=/home/postgres/kafka
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export MAVEN_HOME=/home/postgres/maven
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH
export HADOOP_HOME=/home/postgres/hadoop/hadoop-3.3.0
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$MAVEN_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$PATH
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh修改配置文件java路径
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/yarn-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml修改core-site文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/postgres/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.65.140:9000</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.65.140:9000</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>false</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/hdfs-site.xml修改hdfs-site文件
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/postgres/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>file:/home/postgres/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/yarn-site.xml修改yarn-site文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
</configuration>
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/mapred-site.xml```修改mapred-site文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.65.140:10020</value>
<description>指定mapreduce使用yarn框架</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/postgres/hadoop/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/postgres/hadoop/hadoop-3.3.0</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/postgres/hadoop/hadoop-3.3.0</value>
</property>
</configuration>
vim /home/postgres/hadoop/hadoop-3.3.0/etc/hadoop/workers修改workers文件(这里用的是内部IP的hostname)
worker1
worker2
手动创建文件夹:/home/postgres/hadoop/hdfs/logs 和 data目录,并分配777权限。
在hadoop初始化启动后,在master上xxx/name/namesecondary/下会自动创建./current/VERSION文件路径。
1.6测试hadoop集群是否配置好
在master运行:hadoop namenode -format
如果有必要,运行DataNode命令:hadoop datanode -format
master+slave1+slave2启动集群: start-all.sh
1.6.1验证各个节点的集群配置:在各个节点运行jps
master : jps
19781 NameNode
20008 SecondaryNameNode
64605 Jps
slave1 : jps
27426 Jps
54186 DataNode
slave2 : jps
50290 DataNode
23350 Jps
1.6.2验证各个节点的集群配置:命令行
hadoop dfsadmin -report
按照上述的配置情况:一个namenode节点,两个datanode节点,整个集群监控情况如下:
[postgres@master dfs]$ hadoop dfsadmin -report
WARNING: Use of this script to execute dfsadmin is deprecated.
WARNING: Attempting to execute replacement "hdfs dfsadmin" instead.
Configured Capacity: 96841113600 (90.19 GB)
Present Capacity: 93542649856 (87.12 GB)
DFS Remaining: 93542633472 (87.12 GB)
DFS Used: 16384 (16 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.65.141:9866 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 48420556800 (45.10 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 1649238016 (1.54 GB)
DFS Remaining: 46771310592 (43.56 GB)
DFS Used%: 0.00%
DFS Remaining%: 96.59%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Mon Dec 21 03:52:21 EST 2020
Last Block Report: Sun Dec 20 23:11:20 EST 2020
Num of Blocks: 0
Name: 192.168.65.142:9866 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 48420556800 (45.10 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 1649225728 (1.54 GB)
DFS Remaining: 46771322880 (43.56 GB)
DFS Used%: 0.00%
DFS Remaining%: 96.59%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Mon Dec 21 03:52:20 EST 2020
Last Block Report: Sun Dec 20 23:01:38 EST 2020
Num of Blocks: 0
1.6.3验证各个节点的集群配置: 浏览器查看
输入 http://[master ip]:9870 就可以在浏览器看到hdfs集群的监控情况。
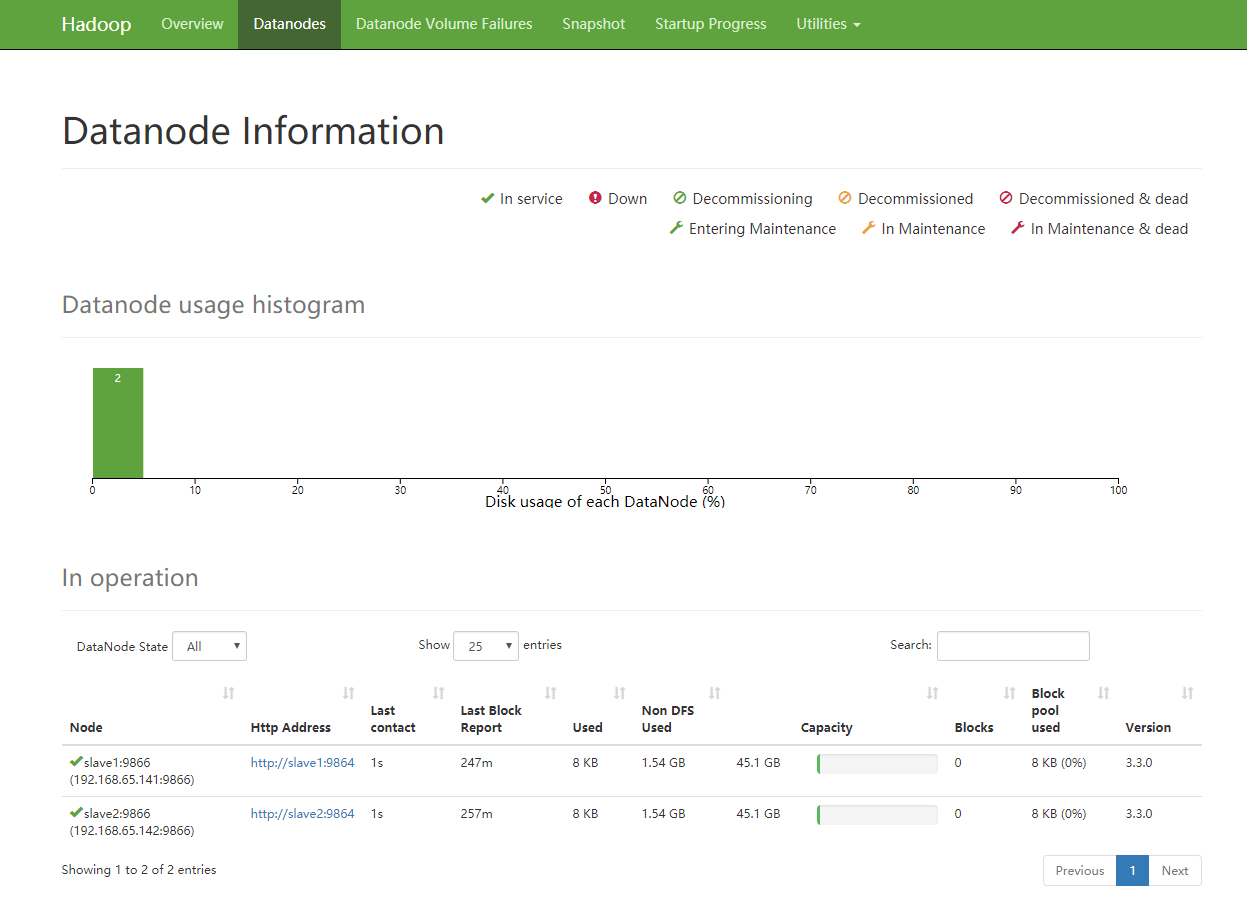
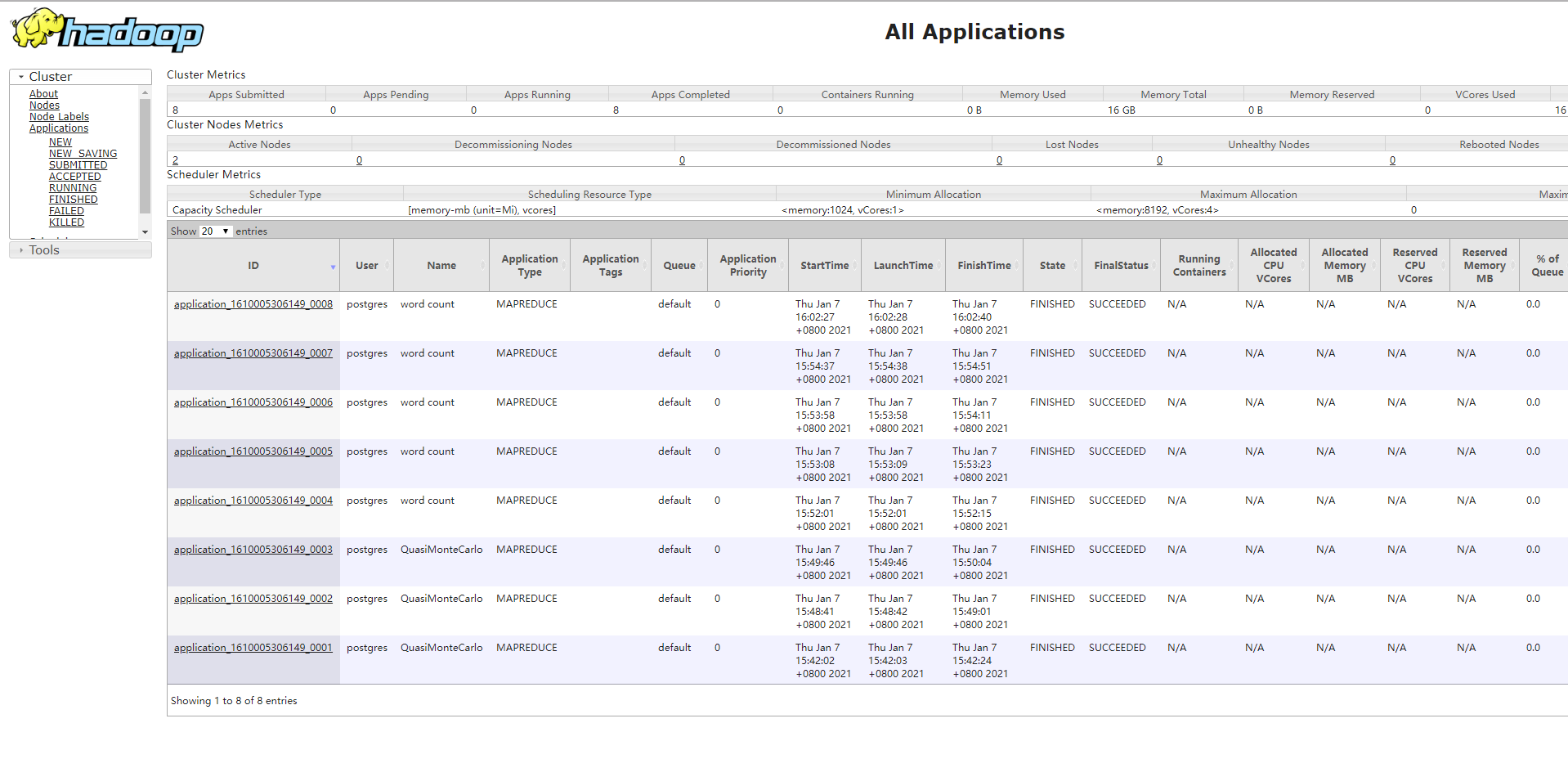
输入 http://[master ip]:8001就可以在浏览器看到hadoop集群的监控情况。
1.6.4验证环境搭建:验证HDFS
可以尝试向Hadoop中插入第一个mapreduce任务:
hdfs dfs -mkdir /HadoopTest 在文件系统中创建一个目录
hdfs dfs -put a.txt /HadoopTest 向创建的目录中存放第一个a.txt文件
hdfs dfs -ls /HadoopTest 查看文件系统的情况
[postgres@master hadoop]$ hdfs dfs -ls /HadoopTest
Found 1 items
-rw-r--r-- 3 postgres supergroup 3692 2021-01-06 22:16 /HadoopTest/a.txt
hdfs dfs -text /HadoopTest/a.txt 查看所需要查询文件的内容
-- a.txt 的主要内容 --
drop table vcbj_mx.db01.jzy;
drop extension citus;
create extension citus;
select master_add_node('localhost','15432');
1.6.5验证mapreduce是否搭建成功
检验是否搭建成功的方法就是,运行一个官方的demo查看是否可以运行。
[postgres@master hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 5 5
Number of Maps = 5
Samples per Map = 5
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Starting Job
2021-01-07 02:49:45,009 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at master/192.168.65.140:8032
2021-01-07 02:49:45,234 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/postgres/.staging/job_1610005306149_0003
2021-01-07 02:49:45,330 INFO input.FileInputFormat: Total input files to process : 5
2021-01-07 02:49:45,358 INFO mapreduce.JobSubmitter: number of splits:5
2021-01-07 02:49:45,882 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1610005306149_0003
2021-01-07 02:49:45,882 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-01-07 02:49:46,029 INFO conf.Configuration: resource-types.xml not found
2021-01-07 02:49:46,029 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-01-07 02:49:46,078 INFO impl.YarnClientImpl: Submitted application application_1610005306149_0003
2021-01-07 02:49:46,120 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1610005306149_0003/
2021-01-07 02:49:46,121 INFO mapreduce.Job: Running job: job_1610005306149_0003
2021-01-07 02:49:51,223 INFO mapreduce.Job: Job job_1610005306149_0003 running in uber mode : false
2021-01-07 02:49:51,224 INFO mapreduce.Job: map 0% reduce 0%
2021-01-07 02:50:01,419 INFO mapreduce.Job: map 40% reduce 0%
2021-01-07 02:50:02,423 INFO mapreduce.Job: map 100% reduce 0%
2021-01-07 02:50:05,443 INFO mapreduce.Job: map 100% reduce 100%
2021-01-07 02:50:06,454 INFO mapreduce.Job: Job job_1610005306149_0003 completed successfully
2021-01-07 02:50:06,551 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=116
FILE: Number of bytes written=1592451
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1360
HDFS: Number of bytes written=215
HDFS: Number of read operations=25
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=5
Launched reduce tasks=1
Data-local map tasks=5
Total time spent by all maps in occupied slots (ms)=40347
Total time spent by all reduces in occupied slots (ms)=2066
Total time spent by all map tasks (ms)=40347
Total time spent by all reduce tasks (ms)=2066
Total vcore-milliseconds taken by all map tasks=40347
Total vcore-milliseconds taken by all reduce tasks=2066
Total megabyte-milliseconds taken by all map tasks=41315328
Total megabyte-milliseconds taken by all reduce tasks=2115584
Map-Reduce Framework
Map input records=5
Map output records=10
Map output bytes=90
Map output materialized bytes=140
Input split bytes=770
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=140
Reduce input records=10
Reduce output records=0
Spilled Records=20
Shuffled Maps =5
Failed Shuffles=0
Merged Map outputs=5
GC time elapsed (ms)=1436
CPU time spent (ms)=2290
Physical memory (bytes) snapshot=1626021888
Virtual memory (bytes) snapshot=16829157376
Total committed heap usage (bytes)=1371013120
Peak Map Physical memory (bytes)=286470144
Peak Map Virtual memory (bytes)=2804334592
Peak Reduce Physical memory (bytes)=197947392
Peak Reduce Virtual memory (bytes)=2810527744
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=590
File Output Format Counters
Bytes Written=97
Job Finished in 21.614 seconds
Estimated value of Pi is 3.68000000000000000000
最终运行后,发现可以得出正确的结果,虽然不太准确。。。。
下面运行另一个demo:统计某个文件中的所有单词。
[postgres@master hadoop-3.3.0]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /HadoopTest/a.txt /HadoopTest/output
2021-01-07 02:54:36,684 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at master/192.168.65.140:8032
2021-01-07 02:54:37,029 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/postgres/.staging/job_1610005306149_0007
2021-01-07 02:54:37,231 INFO input.FileInputFormat: Total input files to process : 1
2021-01-07 02:54:37,685 INFO mapreduce.JobSubmitter: number of splits:1
2021-01-07 02:54:37,816 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1610005306149_0007
2021-01-07 02:54:37,817 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-01-07 02:54:37,964 INFO conf.Configuration: resource-types.xml not found
2021-01-07 02:54:37,964 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-01-07 02:54:38,013 INFO impl.YarnClientImpl: Submitted application application_1610005306149_0007
2021-01-07 02:54:38,043 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1610005306149_0007/
2021-01-07 02:54:38,044 INFO mapreduce.Job: Running job: job_1610005306149_0007
2021-01-07 02:54:43,127 INFO mapreduce.Job: Job job_1610005306149_0007 running in uber mode : false
2021-01-07 02:54:43,128 INFO mapreduce.Job: map 0% reduce 0%
2021-01-07 02:54:47,191 INFO mapreduce.Job: map 100% reduce 0%
2021-01-07 02:54:52,216 INFO mapreduce.Job: map 100% reduce 100%
2021-01-07 02:54:53,226 INFO mapreduce.Job: Job job_1610005306149_0007 completed successfully
2021-01-07 02:54:53,301 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=3996
FILE: Number of bytes written=538013
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3800
HDFS: Number of bytes written=3617
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=1979
Total time spent by all reduces in occupied slots (ms)=2058
Total time spent by all map tasks (ms)=1979
Total time spent by all reduce tasks (ms)=2058
Total vcore-milliseconds taken by all map tasks=1979
Total vcore-milliseconds taken by all reduce tasks=2058
Total megabyte-milliseconds taken by all map tasks=2026496
Total megabyte-milliseconds taken by all reduce tasks=2107392
Map-Reduce Framework
Map input records=118
Map output records=122
Map output bytes=4138
Map output materialized bytes=3996
Input split bytes=108
Combine input records=122
Combine output records=92
Reduce input groups=92
Reduce shuffle bytes=3996
Reduce input records=92
Reduce output records=92
Spilled Records=184
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=98
CPU time spent (ms)=890
Physical memory (bytes) snapshot=478830592
Virtual memory (bytes) snapshot=5614559232
Total committed heap usage (bytes)=381157376
Peak Map Physical memory (bytes)=282718208
Peak Map Virtual memory (bytes)=2802245632
Peak Reduce Physical memory (bytes)=196112384
Peak Reduce Virtual memory (bytes)=2812313600
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=3692
File Output Format Counters
Bytes Written=3617
之前的运行结果会显示失败的个数等信息,如上述显示:没有任何报错信息。接下来查看输出文件夹下有多少个文件。一个是_SUCCESS,part-r-00000。
[postgres@master hadoop-3.3.0]$ hadoop fs -ls /HadoopTest/output/
Found 2 items
-rw-r--r-- 3 postgres supergroup 0 2021-01-07 02:54 /HadoopTest/output/_SUCCESS
-rw-r--r-- 3 postgres supergroup 3617 2021-01-07 02:54 /HadoopTest/output/part-r-00000
然后查看每个文件的内容,因为上述运行的结果是统计单词的个数(估计是数空格)。所以part-r-00000就是将a.txt文件中的内容进行单词的统计,并将结果按照英文字母排序。
[postgres@master hadoop-3.3.0]$ hadoop fs -text /HadoopTest/output/part-r-00000
citus; 2
create 1
drop 2
extension 2
master_add_node('localhost','15432'); 1
select 1
table 1
vcbj_mx.db01.jzy; 1
2.安装Spark(master + slave1 + slave2)
2.1. 准备工作
2.1.1 安装scala
准备一个scala的安装包scala-2.13.4.rpm
[postgres@master ~]$ rpm -ihv scala-2.13-4.rpm
Preparing... ################################# [100%]
Updating / installing...
1:scala-2.13.4-1 ################################# [100%]
[postgres@master ~]$ scala
Welcome to Scala 2.13.4 (OpenJDK 64-Bit Server VM, Java 1.8.0_161).
Type in expressions for evaluation. Or try :help.
scala>
2.1.1 安装Maven
解压缩maven压缩包apache-maven-3.6.3-bin.tar.gz
[postgres@master ~]$ tar xvf apache-maven-3.6.3-bin.tar.gz
[postgres@master ~]$ mv apache-maven-3.6.3 maven
将maven的路径配置进/etc/profile的PATH路径,并检查安装是否生效。
[postgres@master maven]$ mvn -v
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /home/postgres/maven
Java version: 1.8.0_161, vendor: Oracle Corporation, runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-862.el7.x86_64", arch: "amd64", family: "unix"
2.2. 安装Spark
首先配置maven的环境变量,在/etc/profile下添加如下信息:
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=1g"
修改scala的版本信息为2.13
[postgres@master maven]$ ./change-scala-version.sh 2.13
./../assembly/pom.xml
./../mllib/pom.xml
./../resource-managers/yarn/pom.xml
./../resource-managers/kubernetes/core/pom.xml
./../resource-managers/kubernetes/integration-tests/pom.xml
./../resource-managers/mesos/pom.xml
./../pom.xml
./../examples/pom.xml
./../streaming/pom.xml
./../common/network-common/pom.xml
./../common/sketch/pom.xml
./../common/tags/pom.xml
./../common/network-yarn/pom.xml
./../common/kvstore/pom.xml
./../common/network-shuffle/pom.xml
./../common/unsafe/pom.xml
./../graphx/pom.xml
./../core/pom.xml
./../sql/catalyst/pom.xml
./../sql/hive/pom.xml
./../sql/core/pom.xml
./../sql/hive-thriftserver/pom.xml
./../repl/pom.xml
./../hadoop-cloud/pom.xml
./../launcher/pom.xml
./../mllib-local/pom.xml
./../tools/pom.xml
./../external/kinesis-asl/pom.xml
./../external/avro/pom.xml
./../external/kafka-0-10-sql/pom.xml
./../external/kinesis-asl-assembly/pom.xml
./../external/kafka-0-10-token-provider/pom.xml
./../external/kafka-0-10-assembly/pom.xml
./../external/kafka-0-10/pom.xml
./../external/spark-ganglia-lgpl/pom.xml
./../external/docker-integration-tests/pom.xml
./../docs/_plugins/copy_api_dirs.rb
解压spark安装包
[postgres@slave1 ~]$ tar xvf spark-3.0.1.tgz
由于spark和hadoop里面关于启动集群的指令是一样的,所以这里就不打算配置spark的环境变量了。想用直接去目录直接运行即可。
2.2.1 spark配置
进入spark的安装目录,即可查看所有的文件如下:
[postgres@slave1 spark-3.0.1-bin-hadoop3.2]$ ls
bin examples LICENSE NOTICE README.md work
conf jars licenses python RELEASE yarn
data kubernetes logs R sbin
修改conf/spark-env.sh文件
export HADOOP_HOME=/home/postgres/hadoop/hadoop-3.3.0
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export SPARK_MASTER_IP=192.168.65.140
export SPARK_MASTER_HOST=192.168.65.140
export SPARK_LOCAL_IP=192.168.65.140
#export SPARK_LOCAL_DIRS=/home/postgres/spark-3.0.1-bin-hadoop3.2
export SPARK_HOME=/home/postgres/spark-3.0.1-bin-hadoop3.2
export SPARK_WORKER_MEMORY=512M
export SPARK_EXECUTOR_MEMORY=512M
export SPARK_DRIVER_MEMORY=512M
export SPARK_EXECUTE_CORES=1
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retaindApplications=3 -Dspark.history.fs.logDirectory=hdfs://192.168.65.140:9000/historyServerForSpark/logs"
修改conf/spark-defaults.conf文件
spark.eventLog.enable=true
spark.enentLog.dir=hdfs://192.168.65.140:9000/historyServerForSpark/logs
spark.enentLog.compress=true
修改slaves文件
# A Spark Worker will be started on each of the machines listed below.
main
worker1
worker2
将上述文件分别拷贝至slave1,slave2中。
scp -r spark-3.0.1-bin-hadoop3.2 postgres@slave1:~
scp -r spark-3.0.1-bin-hadoop3.2 postgres@slave2:~
修改过后不要忘了将conf/spark-env.sh中的SPARK_LOCAL_IP修改为对应节点的IP,否则将报错。
2.2.2 启动spark
在master节点启动spark
spark-3.0.1-bin-hadoop3.2/sbin/start-all.sh
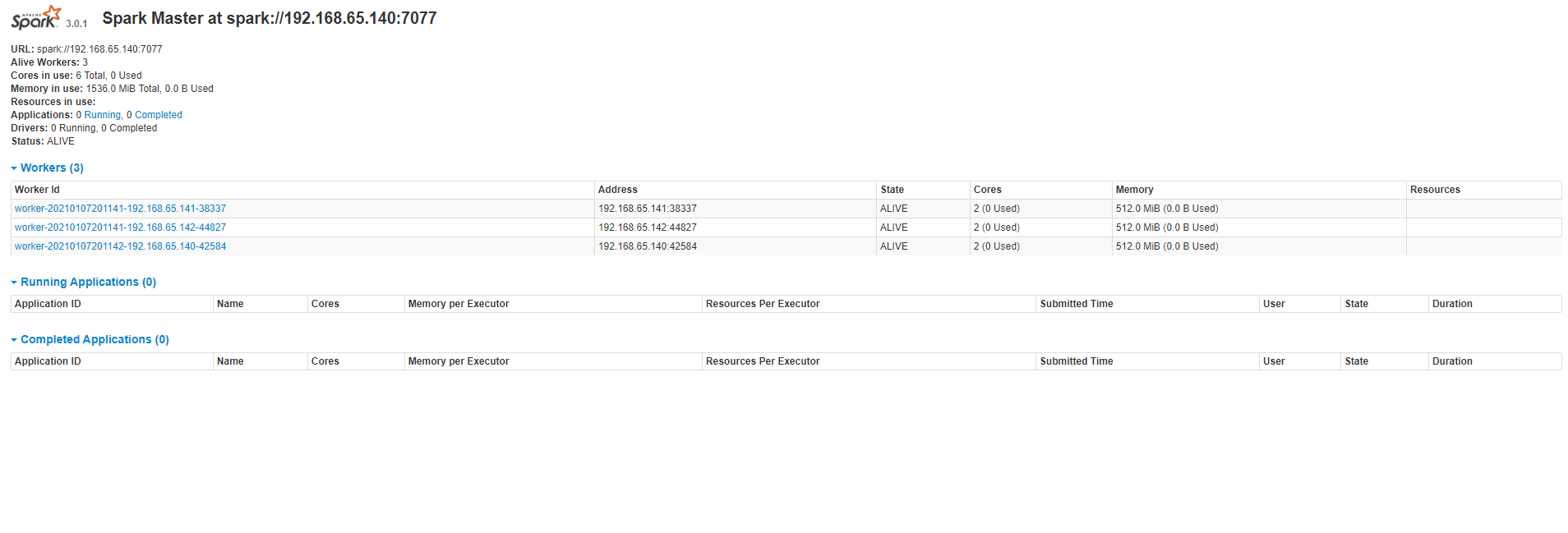
spark-3.0.1-bin-hadoop3.2/sbin/start-history-server.sh

2.3 验证spark任务是够能够顺利运行
首先验证其在master上运行spark业务的正确性。--master spark://192.168.65.140:7077
[postgres@master spark-3.0.1-bin-hadoop3.2]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.65.140:7077 examples/jars/spark-examples_2.12-3.0.1.jar
2021-01-07 21:41:26,794 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2021-01-07 21:41:27,023 INFO spark.SparkContext: Running Spark version 3.0.1
2021-01-07 21:41:27,115 INFO resource.ResourceUtils: ==============================================================
2021-01-07 21:41:27,116 INFO resource.ResourceUtils: Resources for spark.driver:
2021-01-07 21:41:27,116 INFO resource.ResourceUtils: ==============================================================
2021-01-07 21:41:27,117 INFO spark.SparkContext: Submitted application: Spark Pi
2021-01-07 21:41:27,180 INFO spark.SecurityManager: Changing view acls to: postgres
2021-01-07 21:41:27,180 INFO spark.SecurityManager: Changing modify acls to: postgres
2021-01-07 21:41:27,180 INFO spark.SecurityManager: Changing view acls groups to:
2021-01-07 21:41:27,181 INFO spark.SecurityManager: Changing modify acls groups to:
2021-01-07 21:41:27,181 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(postgres); groups with view permissions: Set(); users with modify permissions: Set(postgres); groups with modify permissions: Set()
2021-01-07 21:41:27,470 INFO util.Utils: Successfully started service 'sparkDriver' on port 45433.
2021-01-07 21:41:27,495 INFO spark.SparkEnv: Registering MapOutputTracker
2021-01-07 21:41:27,530 INFO spark.SparkEnv: Registering BlockManagerMaster
2021-01-07 21:41:27,551 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2021-01-07 21:41:27,552 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
2021-01-07 21:41:27,556 INFO spark.SparkEnv: Registering BlockManagerMasterHeartbeat
2021-01-07 21:41:27,567 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-37aa361d-04d2-4dd6-a970-7d15d9ed17e0
2021-01-07 21:41:27,591 INFO memory.MemoryStore: MemoryStore started with capacity 93.3 MiB
2021-01-07 21:41:27,606 INFO spark.SparkEnv: Registering OutputCommitCoordinator
2021-01-07 21:41:27,691 INFO util.log: Logging initialized @2677ms to org.sparkproject.jetty.util.log.Slf4jLog
2021-01-07 21:41:27,758 INFO server.Server: jetty-9.4.z-SNAPSHOT; built: 2019-04-29T20:42:08.989Z; git: e1bc35120a6617ee3df052294e433f3a25ce7097; jvm 1.8.0_161-b14
2021-01-07 21:41:27,778 INFO server.Server: Started @2765ms
2021-01-07 21:41:27,801 INFO server.AbstractConnector: Started ServerConnector@596df867{HTTP/1.1,[http/1.1]}{192.168.65.140:4040}
2021-01-07 21:41:27,802 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
2021-01-07 21:41:27,821 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@47747fb9{/jobs,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,823 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1fe8d51b{/jobs/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,824 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@22680f52{/jobs/job,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,826 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@503d56b5{/jobs/job/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,827 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@433ffad1{/stages,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,828 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2575f671{/stages/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,828 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@ecf9fb3{/stages/stage,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,831 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@37d3d232{/stages/stage/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,831 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@581d969c{/stages/pool,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,832 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2b46a8c1{/stages/pool/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,832 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@29caf222{/storage,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,833 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5851bd4f{/storage/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,834 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2f40a43{/storage/rdd,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,834 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@69c43e48{/storage/rdd/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,835 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3a80515c{/environment,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,836 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1c807b1d{/environment/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,836 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1b39fd82{/executors,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,837 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@21680803{/executors/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,837 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@c8b96ec{/executors/threadDump,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,838 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2d8f2f3a{/executors/threadDump/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,846 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7048f722{/static,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,846 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@51c929ae{/,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,848 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@29d2d081{/api,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,849 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62c5bbdc{/jobs/job/kill,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,850 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1bc53649{/stages/stage/kill,null,AVAILABLE,@Spark}
2021-01-07 21:41:27,851 INFO ui.SparkUI: Bound SparkUI to 192.168.65.140, and started at http://master:4040
2021-01-07 21:41:27,880 INFO spark.SparkContext: Added JAR file:/home/postgres/spark-3.0.1-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.1.jar at spark://master:45433/jars/spark-examples_2.12-3.0.1.jar with timestamp 1610073687880
2021-01-07 21:41:27,899 WARN spark.SparkContext: Please ensure that the number of slots available on your executors is limited by the number of cores to task cpus and not another custom resource. If cores is not the limiting resource then dynamic allocation will not work properly!
2021-01-07 21:41:28,167 INFO client.StandaloneAppClient$ClientEndpoint: Connecting to master spark://192.168.65.140:7077...
2021-01-07 21:41:28,224 INFO client.TransportClientFactory: Successfully created connection to /192.168.65.140:7077 after 36 ms (0 ms spent in bootstraps)
2021-01-07 21:41:28,326 INFO cluster.StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20210107214128-0001
2021-01-07 21:41:28,328 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20210107214128-0001/0 on worker-20210107201141-192.168.65.142-44827 (192.168.65.142:44827) with 2 core(s)
2021-01-07 21:41:28,329 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20210107214128-0001/0 on hostPort 192.168.65.142:44827 with 2 core(s), 512.0 MiB RAM
2021-01-07 21:41:28,329 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20210107214128-0001/1 on worker-20210107201142-192.168.65.140-42584 (192.168.65.140:42584) with 2 core(s)
2021-01-07 21:41:28,329 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20210107214128-0001/1 on hostPort 192.168.65.140:42584 with 2 core(s), 512.0 MiB RAM
2021-01-07 21:41:28,330 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20210107214128-0001/2 on worker-20210107201141-192.168.65.141-38337 (192.168.65.141:38337) with 2 core(s)
2021-01-07 21:41:28,330 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20210107214128-0001/2 on hostPort 192.168.65.141:38337 with 2 core(s), 512.0 MiB RAM
2021-01-07 21:41:28,342 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 38555.
2021-01-07 21:41:28,353 INFO netty.NettyBlockTransferService: Server created on master:38555
2021-01-07 21:41:28,355 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2021-01-07 21:41:28,363 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, master, 38555, None)
2021-01-07 21:41:28,378 INFO storage.BlockManagerMasterEndpoint: Registering block manager master:38555 with 93.3 MiB RAM, BlockManagerId(driver, master, 38555, None)
2021-01-07 21:41:28,380 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, master, 38555, None)
2021-01-07 21:41:28,381 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, master, 38555, None)
2021-01-07 21:41:28,432 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20210107214128-0001/1 is now RUNNING
2021-01-07 21:41:28,437 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20210107214128-0001/2 is now RUNNING
2021-01-07 21:41:28,486 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20210107214128-0001/0 is now RUNNING
2021-01-07 21:41:28,638 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@13a37e2a{/metrics/json,null,AVAILABLE,@Spark}
2021-01-07 21:41:28,834 INFO cluster.StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
2021-01-07 21:41:29,597 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:38
2021-01-07 21:41:29,620 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
2021-01-07 21:41:29,620 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
2021-01-07 21:41:29,621 INFO scheduler.DAGScheduler: Parents of final stage: List()
2021-01-07 21:41:29,622 INFO scheduler.DAGScheduler: Missing parents: List()
2021-01-07 21:41:29,633 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
2021-01-07 21:41:29,777 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.1 KiB, free 93.3 MiB)
2021-01-07 21:41:29,998 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1816.0 B, free 93.3 MiB)
2021-01-07 21:41:30,000 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on master:38555 (size: 1816.0 B, free: 93.3 MiB)
2021-01-07 21:41:30,005 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1223
2021-01-07 21:41:30,111 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
2021-01-07 21:41:30,112 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
2021-01-07 21:41:32,203 INFO resource.ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 512, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
2021-01-07 21:41:32,894 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.65.140:47270) with ID 1
2021-01-07 21:41:33,078 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.65.140:43026 with 93.3 MiB RAM, BlockManagerId(1, 192.168.65.140, 43026, None)
2021-01-07 21:41:33,147 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 192.168.65.140, executor 1, partition 0, PROCESS_LOCAL, 7397 bytes)
2021-01-07 21:41:33,150 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 192.168.65.140, executor 1, partition 1, PROCESS_LOCAL, 7397 bytes)
2021-01-07 21:41:33,750 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.65.140:43026 (size: 1816.0 B, free: 93.3 MiB)
2021-01-07 21:41:34,995 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1866 ms on 192.168.65.140 (executor 1) (1/2)
2021-01-07 21:41:35,009 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 1859 ms on 192.168.65.140 (executor 1) (2/2)
2021-01-07 21:41:35,009 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
2021-01-07 21:41:35,028 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 5.364 s
2021-01-07 21:41:35,043 INFO scheduler.DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
2021-01-07 21:41:35,043 INFO scheduler.TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
2021-01-07 21:41:35,047 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 5.449970 s
Pi is roughly 3.1400157000785005
2021-01-07 21:41:35,090 INFO server.AbstractConnector: Stopped Spark@596df867{HTTP/1.1,[http/1.1]}{192.168.65.140:4040}
2021-01-07 21:41:35,091 INFO ui.SparkUI: Stopped Spark web UI at http://master:4040
2021-01-07 21:41:35,094 INFO cluster.StandaloneSchedulerBackend: Shutting down all executors
2021-01-07 21:41:35,094 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
2021-01-07 21:41:35,139 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2021-01-07 21:41:35,209 INFO memory.MemoryStore: MemoryStore cleared
2021-01-07 21:41:35,209 INFO storage.BlockManager: BlockManager stopped
2021-01-07 21:41:35,236 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2021-01-07 21:41:35,239 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2021-01-07 21:41:35,243 INFO spark.SparkContext: Successfully stopped SparkContext
2021-01-07 21:41:35,261 INFO util.ShutdownHookManager: Shutdown hook called
2021-01-07 21:41:35,262 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-e215e080-0640-4b85-9d9b-34cbd2ea691f
2021-01-07 21:41:35,263 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-2ce83886-c353-4630-8cae-2abd7d6ef759
接下来验证其在yarn架构下程序运行的正确性--master yarn
[postgres@master spark-3.0.1-bin-hadoop3.2]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
2021-01-07 21:44:31,421 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2021-01-07 21:44:31,658 INFO spark.SparkContext: Running Spark version 3.0.1
2021-01-07 21:44:31,738 INFO resource.ResourceUtils: ==============================================================
2021-01-07 21:44:31,739 INFO resource.ResourceUtils: Resources for spark.driver:
2021-01-07 21:44:31,740 INFO resource.ResourceUtils: ==============================================================
2021-01-07 21:44:31,740 INFO spark.SparkContext: Submitted application: Spark Pi
2021-01-07 21:44:31,797 INFO spark.SecurityManager: Changing view acls to: postgres
2021-01-07 21:44:31,797 INFO spark.SecurityManager: Changing modify acls to: postgres
2021-01-07 21:44:31,798 INFO spark.SecurityManager: Changing view acls groups to:
2021-01-07 21:44:31,798 INFO spark.SecurityManager: Changing modify acls groups to:
2021-01-07 21:44:31,798 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(postgres); groups with view permissions: Set(); users with modify permissions: Set(postgres); groups with modify permissions: Set()
2021-01-07 21:44:32,091 INFO util.Utils: Successfully started service 'sparkDriver' on port 41202.
2021-01-07 21:44:32,123 INFO spark.SparkEnv: Registering MapOutputTracker
2021-01-07 21:44:32,153 INFO spark.SparkEnv: Registering BlockManagerMaster
2021-01-07 21:44:32,177 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2021-01-07 21:44:32,178 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
2021-01-07 21:44:32,224 INFO spark.SparkEnv: Registering BlockManagerMasterHeartbeat
2021-01-07 21:44:32,236 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-1948b4bf-c9ac-4eb9-b245-353f55bf52e2
2021-01-07 21:44:32,260 INFO memory.MemoryStore: MemoryStore started with capacity 93.3 MiB
2021-01-07 21:44:32,299 INFO spark.SparkEnv: Registering OutputCommitCoordinator
2021-01-07 21:44:32,385 INFO util.log: Logging initialized @2655ms to org.sparkproject.jetty.util.log.Slf4jLog
2021-01-07 21:44:32,456 INFO server.Server: jetty-9.4.z-SNAPSHOT; built: 2019-04-29T20:42:08.989Z; git: e1bc35120a6617ee3df052294e433f3a25ce7097; jvm 1.8.0_161-b14
2021-01-07 21:44:32,478 INFO server.Server: Started @2749ms
2021-01-07 21:44:32,502 INFO server.AbstractConnector: Started ServerConnector@3dddbe65{HTTP/1.1,[http/1.1]}{192.168.65.140:4040}
2021-01-07 21:44:32,502 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
2021-01-07 21:44:32,522 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2a2bb0eb{/jobs,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,524 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@182b435b{/jobs/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,525 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2fa7ae9{/jobs/job,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,527 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@60afd40d{/jobs/job/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,528 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3f2049b6{/stages,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,529 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@ea27e34{/stages/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,529 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@e72dba7{/stages/stage,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,531 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@24855019{/stages/stage/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,532 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4d4d8fcf{/stages/pool,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,532 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6f0628de{/stages/pool/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,533 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1e392345{/storage,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,534 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4ced35ed{/storage/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,534 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7bd69e82{/storage/rdd,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,535 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@51b01960{/storage/rdd/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,536 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@27dc79f7{/environment,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,536 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3aaf4f07{/environment/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,537 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@18e8473e{/executors,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,538 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1a38ba58{/executors/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,538 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6058e535{/executors/threadDump,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,539 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1deb2c43{/executors/threadDump/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,546 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1cefc4b3{/static,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,547 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@27a0a5a2{/,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,548 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@33aa93c{/api,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,549 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@10ad20cb{/jobs/job/kill,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,549 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2c282004{/stages/stage/kill,null,AVAILABLE,@Spark}
2021-01-07 21:44:32,551 INFO ui.SparkUI: Bound SparkUI to 192.168.65.140, and started at http://master:4040
2021-01-07 21:44:32,579 INFO spark.SparkContext: Added JAR file:/home/postgres/spark-3.0.1-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.1.jar at spark://master:41202/jars/spark-examples_2.12-3.0.1.jar with timestamp 1610073872579
2021-01-07 21:44:32,913 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.65.140:8032
2021-01-07 21:44:33,148 INFO yarn.Client: Requesting a new application from cluster with 2 NodeManagers
2021-01-07 21:44:33,630 INFO conf.Configuration: resource-types.xml not found
2021-01-07 21:44:33,631 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-01-07 21:44:33,647 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
2021-01-07 21:44:33,647 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
2021-01-07 21:44:33,648 INFO yarn.Client: Setting up container launch context for our AM
2021-01-07 21:44:33,648 INFO yarn.Client: Setting up the launch environment for our AM container
2021-01-07 21:44:33,655 INFO yarn.Client: Preparing resources for our AM container
2021-01-07 21:44:33,705 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
2021-01-07 21:44:37,172 INFO yarn.Client: Uploading resource file:/tmp/spark-be864c7a-c7d6-4085-bfaa-530707a3576b/__spark_libs__7342527753535148040.zip -> hdfs://192.168.65.140:9000/user/postgres/.sparkStaging/application_1610005306149_0010/__spark_libs__7342527753535148040.zip
2021-01-07 21:44:39,768 INFO yarn.Client: Uploading resource file:/tmp/spark-be864c7a-c7d6-4085-bfaa-530707a3576b/__spark_conf__1580188524874956877.zip -> hdfs://192.168.65.140:9000/user/postgres/.sparkStaging/application_1610005306149_0010/__spark_conf__.zip
2021-01-07 21:44:40,216 INFO spark.SecurityManager: Changing view acls to: postgres
2021-01-07 21:44:40,217 INFO spark.SecurityManager: Changing modify acls to: postgres
2021-01-07 21:44:40,217 INFO spark.SecurityManager: Changing view acls groups to:
2021-01-07 21:44:40,217 INFO spark.SecurityManager: Changing modify acls groups to:
2021-01-07 21:44:40,217 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(postgres); groups with view permissions: Set(); users with modify permissions: Set(postgres); groups with modify permissions: Set()
2021-01-07 21:44:40,267 INFO yarn.Client: Submitting application application_1610005306149_0010 to ResourceManager
2021-01-07 21:44:40,313 INFO impl.YarnClientImpl: Submitted application application_1610005306149_0010
2021-01-07 21:44:41,327 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:41,329 INFO yarn.Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1610073880279
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1610005306149_0010/
user: postgres
2021-01-07 21:44:42,331 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:43,343 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:44,344 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:45,346 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:46,348 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:47,349 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:48,351 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:49,353 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:50,354 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:51,356 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:52,358 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:53,359 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:54,360 INFO yarn.Client: Application report for application_1610005306149_0010 (state: ACCEPTED)
2021-01-07 21:44:55,028 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> slave2, PROXY_URI_BASES -> http://slave2:8088/proxy/application_1610005306149_0010), /proxy/application_1610005306149_0010
2021-01-07 21:44:55,363 INFO yarn.Client: Application report for application_1610005306149_0010 (state: RUNNING)
2021-01-07 21:44:55,363 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.65.142
ApplicationMaster RPC port: -1
queue: default
start time: 1610073880279
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1610005306149_0010/
user: postgres
2021-01-07 21:44:55,365 INFO cluster.YarnClientSchedulerBackend: Application application_1610005306149_0010 has started running.
2021-01-07 21:44:55,383 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 36592.
2021-01-07 21:44:55,383 INFO netty.NettyBlockTransferService: Server created on master:36592
2021-01-07 21:44:55,390 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2021-01-07 21:44:55,405 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, master, 36592, None)
2021-01-07 21:44:55,420 INFO storage.BlockManagerMasterEndpoint: Registering block manager master:36592 with 93.3 MiB RAM, BlockManagerId(driver, master, 36592, None)
2021-01-07 21:44:55,422 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, master, 36592, None)
2021-01-07 21:44:55,423 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, master, 36592, None)
2021-01-07 21:44:55,695 INFO ui.ServerInfo: Adding filter to /metrics/json: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
2021-01-07 21:44:55,697 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2ae62bb6{/metrics/json,null,AVAILABLE,@Spark}
2021-01-07 21:44:55,754 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
2021-01-07 21:45:02,753 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: 30000000000(ns)
2021-01-07 21:45:03,775 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:38
2021-01-07 21:45:03,792 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
2021-01-07 21:45:03,792 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
2021-01-07 21:45:03,793 INFO scheduler.DAGScheduler: Parents of final stage: List()
2021-01-07 21:45:03,794 INFO scheduler.DAGScheduler: Missing parents: List()
2021-01-07 21:45:03,798 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
2021-01-07 21:45:04,048 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.1 KiB, free 93.3 MiB)
2021-01-07 21:45:04,110 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1816.0 B, free 93.3 MiB)
2021-01-07 21:45:04,112 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on master:36592 (size: 1816.0 B, free: 93.3 MiB)
2021-01-07 21:45:04,115 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1223
2021-01-07 21:45:04,136 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
2021-01-07 21:45:04,137 INFO cluster.YarnScheduler: Adding task set 0.0 with 2 tasks
2021-01-07 21:45:05,722 INFO resource.ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 512, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
2021-01-07 21:45:06,299 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.65.141:48554) with ID 1
2021-01-07 21:45:06,591 INFO storage.BlockManagerMasterEndpoint: Registering block manager slave1:35191 with 93.3 MiB RAM, BlockManagerId(1, slave1, 35191, None)
2021-01-07 21:45:06,707 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, slave1, executor 1, partition 0, PROCESS_LOCAL, 7404 bytes)
2021-01-07 21:45:07,262 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on slave1:35191 (size: 1816.0 B, free: 93.3 MiB)
2021-01-07 21:45:07,943 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, slave1, executor 1, partition 1, PROCESS_LOCAL, 7404 bytes)
2021-01-07 21:45:07,947 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1272 ms on slave1 (executor 1) (1/2)
2021-01-07 21:45:07,982 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 39 ms on slave1 (executor 1) (2/2)
2021-01-07 21:45:07,983 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
2021-01-07 21:45:08,004 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 4.138 s
2021-01-07 21:45:08,008 INFO scheduler.DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
2021-01-07 21:45:08,008 INFO cluster.YarnScheduler: Killing all running tasks in stage 0: Stage finished
2021-01-07 21:45:08,009 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 4.234207 s
Pi is roughly 3.150515752578763
2021-01-07 21:45:08,038 INFO server.AbstractConnector: Stopped Spark@3dddbe65{HTTP/1.1,[http/1.1]}{192.168.65.140:4040}
2021-01-07 21:45:08,039 INFO ui.SparkUI: Stopped Spark web UI at http://master:4040
2021-01-07 21:45:08,042 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
2021-01-07 21:45:08,080 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
2021-01-07 21:45:08,081 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
2021-01-07 21:45:08,084 INFO cluster.YarnClientSchedulerBackend: YARN client scheduler backend Stopped
2021-01-07 21:45:08,091 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2021-01-07 21:45:08,130 INFO memory.MemoryStore: MemoryStore cleared
2021-01-07 21:45:08,131 INFO storage.BlockManager: BlockManager stopped
2021-01-07 21:45:08,136 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2021-01-07 21:45:08,138 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2021-01-07 21:45:08,141 INFO spark.SparkContext: Successfully stopped SparkContext
2021-01-07 21:45:08,167 INFO util.ShutdownHookManager: Shutdown hook called
2021-01-07 21:45:08,168 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-8888c902-039e-4aa4-b417-7d06526c5db5
2021-01-07 21:45:08,169 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-be864c7a-c7d6-4085-bfaa-530707a3576b
2.3.1 spark-shell
尝试在spark-shell中运行一个业务:
[postgres@master bin]$ ./spark-shell
2021-01-08 01:12:59,287 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://master:4040
Spark context available as 'sc' (master = local[*], app id = local-1610086387821).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.1
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val data=sc.textFile("/HadoopTest/a.txt")
data: org.apache.spark.rdd.RDD[String] = /HadoopTest/a.txt MapPartitionsRDD[3] at textFile at <console>:24
scala> data.collect
[Stage 0:> (0 + 2 res1: Array[String] = Array(drop table vcbj_mx.db01.jzy;, drop extension citus;, create extension citus;, select master_add_node('localhost','15432');)
scala> val splitdata=data.flatMap(line => line.splir(" "));
<console>:25: error: value splir is not a member of String
val splitdata=data.flatMap(line => line.splir(" "));
^
scala> val splitdata=data.flatMap(line => line.split(" "));
splitdata: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[4] at flatMap at <console>:25
scala> splitdata.collect
res2: Array[String] = Array(drop, table, vcbj_mx.db01.jzy;, drop, extension, citus;, create, extension, citus;, select, master_add_node('localhost','15432');)
scala> val mapdata = splitdata.map(word => (word,1));
mapdata: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at map at <console>:25
scala> mapdata.collect
res3: Array[(String, Int)] = Array((drop,1), (table,1), (vcbj_mx.db01.jzy;,1), (drop,1), (extension,1), (citus;,1), (create,1), (extension,1), (citus;,1), (select,1), (master_add_node('localhost','15432');,1))
scala>
可以发现,已经将文件中按照,空格进行了自动分隔和整理。
3.Spark运行一些基本demo
3.1 Spark运行一些官方自带的测试文件jar包中的实例程序
需要注意的是,如下所有的测试实例程序。有些会将测试程序的结果直接打印在屏幕上面;有些则会生成一些parquet文件存放在HDFS中,需要通过一些特别手段查看parquet文件中的内容。
一般来说,会使用spark-submit命令来执行集群层面的业务。
而且还会在http://192.168.65.140:8088上看到集群运行过此业务的痕迹。
3.1.1 计算圆周率
- 使用本机计算圆周率
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.65.140:7077 examples/jars/spark-examples_2.12-3.0.1.jar
- yarn模式计算圆周率
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.2 计算local KMeans
- 本机计算localkmeans
./bin/spark-submit --class org.apache.spark.examples.LocalKMeans --master spark://192.168.65.140:7077 examples/jars/spark-examples_2.12-3.0.1.jar
- yarn计算localkmeans
./bin/spark-submit --class org.apache.spark.examples.LocalKMeans --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.3 计算线性回归
- 使用yarn模式线性回归
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.ml.LinearRegressionWithElasticNetExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.LinearRegressionWithSGDExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.4 计算逻辑回归
- 使用yarn模式逻辑回归
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.LogisticRegressionWithLBFGSExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.ml.LogisticRegressionWithElasticNetExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.5 计算支持向量积
- SVM
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.SVMWithSGDExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.6 计算朴素贝叶斯
- 贝叶斯
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.NaiveBayesExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.7 计算决策树
- 决策树
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.DecisionTreeClassificationExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.8 计算随机森林
- 随机森林
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.RandomForestClassificationExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.9 计算KMeans
- kmeans
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.KMeansExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.1.10 计算混合高斯
- 混合高斯
./bin/spark-submit --jars examples/jars/scopt_2.12-3.7.1.jar --class org.apache.spark.examples.mllib.GaussianMixtureExample --master yarn examples/jars/spark-examples_2.12-3.0.1.jar
3.2 Spark运行一些官方自带测试文件中的源代码
3.2.1 spark-submit运行Python源代码
一般来说spark目录中有python:其中python目录就是运行py文件所需的环境目录。包括必要的运行文件库等。
python目录的结构如下:
├── lib
├── pyspark
│ ├── ml
│ ├── mllib
│ ├── sql
│ ├── streaming
│ │ └── tests
│ ├── testing
│ └── tests
├── test_coverage
└── test_support
├── hello
└── sql
需要运行的python文件如下:简单地计算圆周率的值。当通过spark-submit运行的时候,python内部的环境等因素已经被spark整合,所以在运行py文件的时候,不用担心python的路径问题,直接使用spark-submit运行即可,非常方便。
./spark/bin/spark-submit /home/postgres/...path of python file.../pi.py
from __future__ import print_function
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
3.2.2 spark-submit运行Java源代码
不同于Python的原理,spark运行java源代码的时候,需要先将java代码打包成jar包,并将jar包上传至集群中。接着再通过此jar包,和jar包内的class来运行编写的java代码。
-
准备java代码
此JAVA代码计算pi的近似值。需要注意的是第一行当中
package spark.examples标记了当前java文件需要打包的路径。后面生成jar包、运行代码的指令也需要依据此处灵活变动。也就是说
package spark.examples,package org.apache.spark.examples需要的指令是不同的。package spark.examples; //package org.apache.spark.examples; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.sql.SparkSession; import java.util.ArrayList; import java.util.List; /** * Computes an approximation to pi * Usage: JavaSparkPi [partitions] */ public final class Jiang { public static void main(String[] args) throws Exception { SparkSession spark = SparkSession .builder() .appName("JavaSparkPi") .getOrCreate(); JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext()); int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2; int n = 100000 * slices; List<Integer> l = new ArrayList<>(n); for (int i = 0; i < n; i++) { l.add(i); } JavaRDD<Integer> dataSet = jsc.parallelize(l, slices); int count = dataSet.map(integer -> { double x = Math.random() * 2 - 1; double y = Math.random() * 2 - 1; return (x * x + y * y <= 1) ? 1 : 0; }).reduce((integer, integer2) -> integer + integer2); System.out.println("=========================="); System.out.println("Pi is roughly " + 4.0 * count / n); System.out.println("=========================="); spark.stop(); } } -
添加CLASSPATH环境
由于spark目录下有jars目录,其中包含了spark集群需要用到的所有jar包,所以在将java文件编译成class文件之前,需要将这些jar包添加到CLASSPATH变量中,才能保证所有的java文件不会因为包找不到而报错。
export CLASSPATH=.:/home/postgres/spark/jars/*:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$CLASSPATH如上述的代码所示,CLASSPATH中添加了spark目录中的jars包,并使用*标记了当前目录中的所有jar包。
-
编译java代码生成class文件
由于上述已经部署过CLASSPATH的路径,这里可以直接使用javac的命令进行java文件的编译,并生成了class文件。
javac ...path of java file.../Jiang.java -
将class文件打包成jar包
此处打包的时候,需要尤其注意。在第一步当中,
package xxxxxxxx表示Jiang.class这个类在xxx.jar这个包中的目录。例子如下:# package spark.examples 表示Jiang.class在xxx.jar这个包中的目录为spark/examples/Jiang.class ./ └── spark └── examples └── Jiang.class # 需要注意的是,下面的命令一定要在当前目录下执行。 # 要保证被打包的class文件所在的目录要和源代码中定义的package目录一致 # 直接打包某个class文件 # jar cvf 表示每次新建,都会生成一个新的jar包 # jar uvf 表示每次更新内容,每次都会往jar包中心加入一个class文件 jar cvf ...Path of Jar File.../xxx.jar spark/examples/Jiang.class jar uvf ...Path of Jar File.../xxx.jar spark/examples/Jiang.class # 直接打包目录 # jar cvf 表示每次新建一个jar包 # jar uvf 表示每次更新jar包内容 jar cvf ...Path of Jar File.../xxx.jar spark jar uvf ...Path of Jar File.../xxx.jar spark# package org.apache.spark.examples 表示Jiang.class在xxx.jar这个包中的目录为spark/examples/Jiang.class ./ └── org └── apache └── spark └── examples └── Jiang.class # 需要注意的是,下面的命令一定要保证被打包的class文件所在的目录要和源代码中定义的package目录一致 # 直接打包某个class文件, cvf表示每次新建 # jar cvf 表示每次新建,都会生成一个新的jar包 # jar uvf 表示每次更新内容,每次都会往jar包中心加入一个class文件 jar cvf ...Path of Jar File.../xxx.jar org/apache/spark/examples/Jiang.class jar uvf ...Path of Jar File.../xxx.jar org/apache/spark/examples/Jiang.class # 直接打包目录 # jar cvf 表示每次新建一个jar包 # jar uvf 表示每次更新jar包内容 jar cvf ...Path of Jar File.../xxx.jar org jar uvf ...Path of Jar File.../xxx.jar org在jar包文件生成以后,可以直接
vim xxx.jar查看jar包中的内容,可以发现之前命令打包成的class文件。在整个jar包中,目录结构就跟
Jiang.java中package Jiang是一一对应的关系。" zip.vim version v27 " Browsing zipfile /home/postgres/Jiang_1.jar " Select a file with cursor and press ENTER META-INF/ META-INF/MANIFEST.MF Jiang/Jiang.class将class文件通过jar命令打包的使用说法如下:
Usage: jar {ctxui}[vfmn0PMe] [jar-file] [manifest-file] [entry-point] [-C dir] files ... Options: -c create new archive -t list table of contents for archive -x extract named (or all) files from archive -u update existing archive -v generate verbose output on standard output -f specify archive file name -m include manifest information from specified manifest file -n perform Pack200 normalization after creating a new archive -e specify application entry point for stand-alone application bundled into an executable jar file -0 store only; use no ZIP compression -P preserve leading '/' (absolute path) and ".." (parent directory) components from file names -M do not create a manifest file for the entries -i generate index information for the specified jar files -C change to the specified directory and include the following file If any file is a directory then it is processed recursively. The manifest file name, the archive file name and the entry point name are specified in the same order as the 'm', 'f' and 'e' flags. Example 1: to archive two class files into an archive called classes.jar: jar cvf classes.jar Foo.class Bar.class Example 2: use an existing manifest file 'mymanifest' and archive all the files in the foo/ directory into 'classes.jar': jar cvfm classes.jar mymanifest -C foo/ . -
运行此jar包和class
./bin/spark-submit --class Jiang.Jiang --master yarn ...path of jar file.../xxx.jar -
查看结果
2021-01-21 03:01:03,895 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at Jiang.java:54) finished in 1.389 s 2021-01-21 03:01:03,898 INFO scheduler.DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job 2021-01-21 03:01:03,899 INFO cluster.YarnScheduler: Killing all running tasks in stage 0: Stage finished 2021-01-21 03:01:03,900 INFO scheduler.DAGScheduler: Job 0 finished: reduce at Jiang.java:54, took 1.456527 s ========================== Pi is roughly 3.14574 ========================== 2021-01-21 03:01:03,908 INFO server.AbstractConnector: Stopped Spark@7048f722{HTTP/1.1,[http/1.1]}{192.168.65.140:4040} 2021-01-21 03:01:03,910 INFO ui.SparkUI: Stopped Spark web UI at http://master:4040 2021-01-21 03:01:03,913 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread 2021-01-21 03:01:03,950 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors 2021-01-21 03:01:03,951 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down 2021-01-21 03:01:03,954 INFO cluster.YarnClientSchedulerBackend: YARN client scheduler backend Stopped 2021-01-21 03:01:03,962 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 2021-01-21 03:01:03,968 INFO memory.MemoryStore: MemoryStore cleared 2021-01-21 03:01:03,969 INFO storage.BlockManager: BlockManager stopped 2021-01-21 03:01:03,994 INFO storage.BlockManagerMaster: BlockManagerMaster stopped 2021-01-21 03:01:03,997 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 2021-01-21 03:01:04,004 INFO spark.SparkContext: Successfully stopped SparkContext 2021-01-21 03:01:04,007 INFO util.ShutdownHookManager: Shutdown hook called 2021-01-21 03:01:04,007 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-2f96fc71-66c1-442d-a750-2e29ef43dc9e 2021-01-21 03:01:04,009 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-ff447991-bce6-4ea4-99b8-aeab9059b01e
3.3 Kafka的安装
3.3.1 zookeeper的安装
- 1.解压zookeeper安装包:
tar zxvf apache-zookeeper-3.6.2-bin.tar.gz - 2.向
/etc/profile中添加如下内容:
export ZOOKEEPER_HOME= ....path of zookeeper ....
export PATH=$ZOOKEEPER_HOME/bin:$PATH
- 3.修改
zoo.cfg文件
# ZooKeeper服务器心跳时间,单位为ms
tickTime = 2000
# 允许follower连接并同步到leader的初始化响应时间,以tickTime的倍数来表示
initLimit = 10
# leader与follower心跳检测的最大容忍时间,响应超过syncLimit*tickTime,leader认为follower“死掉”,从服务器列表中删除follower
syncLimit = 5
# 数据目录
dataDir=/tmp/zookeeper/data
# 日志目录
dataLogDir=/tmp/zookeeper/log
# ZooKeeper对外服务端口
clientPort=2181
# 分别配置几个IP地址和端口
server.0=192.168.65.140:2888:3888
server.1=192.168.65.141:2888:3888
server.2=192.168.65.142:2888:3888
- 4.创建数据目录和日志目录:
mkdir -p /tmp/zookeeper/data,mkdir -p /tmp/zookeeper/log - 5.写入服务器编号(不同节点的服务器有所不同):
touch /tmp/zookeeper/data/myid
echo 0 >> /tmp/zookeeper/data/myid以及echo 1 >> /tmp/zookeeper/data/myid ....
- 6.启动zookeeper服务
[root@slave1 bin]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/postgres/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
3.3.2 kafka的安装
- 1.解压zookeeper安装包:
tar zxvf kafka_2.12-2.6.0.tgz - 2.修改
/etc/profile文件,添加如下内容:
export KAFKA_HOME=/home/postgres/kafka
export PATH=$KAFKA_HOME/bin:$PATH
- 3.修改配置文件
$KAFKA_HOME/config/server.properties主要关注以下参数:
#broker的编号,如果集群中有多个broker,则每个broker的编号需要设置的不同
broker.id=0
#broker对外提供的服务入口地址(localhost可改为指定ip,9092为端口号)
listeners=PLAINTEXT://localhost:9092
#存放消息日志文件的地址
log.dirs=/tmp/kafka-logs
#Kafka所需的zookeeper集群地址(其中ip1,ip2,ip3为集群ip)
zookeeper.connect=ip1:9092,ip2:9092,ip3:9092/kafka
- 4.启动kafka
cd $KAFKA_HOME
bin/kafka-server-start.sh config/server.properties
# 由于执行该命令会有较多输出,需要将kafka服务放入后台执行
bin/kafka-server-start.sh -daemon config/server.properties
或
bin/kafka-server-start.sh config/server.properties &
- 5.查看kafka进程信息,其中Kafka.Kafka就是Kafka的服务进程:
[root@slave1 ~]# jps -l
40646 kafka.Kafka
53033 org.apache.zookeeper.server.quorum.QuorumPeerMain
54186 org.apache.hadoop.hdfs.server.datanode.DataNode
54159 sun.tools.jps.Jps
- 6.新建topic
bin/kafka-topics.sh --zookeeper ip:9092/kafka --create --topic topic-demo --replication-factor 3 --partitions 4
# <--topic> 指定主题名称
# <--create> 是创建主题的动作指令
# <--zookeeper> 指定zookeeper服务地址
# <--partitions> 指定分区个数
# <--repliaction-factor> 指定副本因子
3.4 Spark接受kafka中的数据,进行简单的处理
为了实现数据从kafka到Spark的整个流程,需要将kafka和Spark联合起来进行工作。大致流程就是:数据首先进入Kafka中,然后spark时刻从Kafka中获取某个topic中的数据流,然后简单地统计数据流中的单词个数。并将单词的个数打印在屏幕上。
3.4.1 准备Kafka生产者
kafka是传递消息用的消息队列,消息的生产者将需要传递的消息交给kafka进行传递。Kafka的消费者消费者模型demo一般需要生产者producer 不断地向消息队列中输送字符流,消费者consumer不断地从消息队列中去除消息流。
kafka-demo
├── include ················································ (运行所需的头文件)
│ ├── rdkafkacpp.h
│ ├── rdkafka.h
│ └── rdkafka_mock.h
├── lib ···················································· (运行所需的库文件)
│ ├── librdkafka.a
│ ├── librdkafka++.a
│ ├── librdkafka.so -> librdkafka.so.1
│ ├── librdkafka++.so -> librdkafka++.so.1
│ ├── librdkafka.so.1
│ ├── librdkafka++.so.1
│ └── pkgconfig
│ ├── rdkafka.pc
│ ├── rdkafka++.pc
│ ├── rdkafka-static.pc
│ └── rdkafka++-static.pc
├── Makefile
└── src
├── myconsumer.c ··································· (消费者代码)
└── myproducer.c ··································· (生产者代码)
3.4.2 Spark消费Kafka中的数据
当Kafka需要和spark联合工作的时候,一般是spark的业务从kafka中获取消息,并进行处理。在spark的官方文件夹中,可以发现其中所写的demo中有JavaDirectKafkaWordCount.java文件其中主要是直接消费Kafka中的数据。具体用法如下:
Usage: JavaDirectKafkaWordCount <brokers> <groupId> <topics>
<brokers> is a list of one or more Kafka brokers
<groupId> is a consumer group name to consume from topics
<topics> is a list of one or more kafka topics to consume from
并对消息进行单词个数的处理。前文已经叙述过spark运行java代码的方法:将java文件编译成可以直接使用的class文件,然后将class文件打包成jar包,然后通过spark-submit运行此jar包。
-
1.运行jar包之前的准备:首先需要另外下载几个jar包,否则编译报错。
spark-streaming-kafka_2.11-1.6.3.jar,kafka-clients-2.6.0.jar存放进jars/文件夹。 -
2.设置Kafka的brokers,topic
brokers : 192.168.65.140 : 9092
groupId : 0
topic : topic-demo
-
3.运行jar包,指定运行Kafka运行所需的brokers,groupId,topic
./bin/spark-submit --master yarn --class org.apache.spark.examples.streaming.JavaDirectKafkaWordCount examples/jars/spark-examples_2.12-3.0.1.jar 192.168.65.140:9092 0 topic-demo -
4.运行数据的生产者模型
./myproducer 192.168.65.140:9092 topic-demo "asdkf asdfalsdf asldfalsjgla Ljlakjelwk埃里克森搭建拉克丝 laksjdlfj" # 向192.168.65.140:9092的kafka 服务中的topic-demo发送:“asdkf asdfalsdf asldfalsjgla Ljlakjelwk埃里克森搭建拉克丝 laksjdlfj” 消息流。 -
5.下载缺乏的jar包
kafka-clients-2.6.0.jar
spark-streaming-kafka_2.11-1.6.3.jar
spark-streaming-kafka-0-10_2.12-2.4.4.jar
spark-stream-kafa这个包,我不记得是上面哪个起作用了,反正是叫spark-stream-kafka就对了 -
6.查看spark分析消息流的结果,按照空格分隔各个单词。
2021-01-26 03:22:51,007 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 23.0 (TID 35) in 18 ms on slave1 (executor 1) (1/1) 2021-01-26 03:22:51,007 INFO cluster.YarnScheduler: Removed TaskSet 23.0, whose tasks have all completed, from pool 2021-01-26 03:22:51,008 INFO scheduler.DAGScheduler: ResultStage 23 (print at JavaDirectKafkaWordCount.java:92) finished in 0.024 s 2021-01-26 03:22:51,008 INFO scheduler.DAGScheduler: Job 11 is finished. Cancelling potential speculative or zombie tasks for this job 2021-01-26 03:22:51,008 INFO cluster.YarnScheduler: Killing all running tasks in stage 23: Stage finished 2021-01-26 03:22:51,009 INFO scheduler.DAGScheduler: Job 11 finished: print at JavaDirectKafkaWordCount.java:92, took 0.025954 s ------------------------------------------- Time: 1611649370000 ms ------------------------------------------- (asldfalsjgla,1) (asdfalsdf,1) (laksjdlfj,1) (Ljlakjelwk埃里克森搭建拉克丝,1) (asdkf,1) 2021-01-26 03:22:51,009 INFO scheduler.JobScheduler: Finished job streaming job 1611649370000 ms.0 from job set of time 1611649370000 ms 2021-01-26 03:22:51,009 INFO scheduler.JobScheduler: Total delay: 1.009 s for time 1611649370000 ms (execution: 0.995 s) 2021-01-26 03:22:51,009 INFO rdd.ShuffledRDD: Removing RDD 24 from persistence list 2021-01-26 03:22:51,010 INFO rdd.MapPartitionsRDD: Removing RDD 23 from persistence list 2021-01-26 03:22:51,011 INFO rdd.MapPartitionsRDD: Removing RDD 22 from persistence list 2021-01-26 03:22:51,012 INFO rdd.MapPartitionsRDD: Removing RDD 21 from persistence list 2021-01-26 03:22:51,013 INFO kafka010.KafkaRDD: Removing RDD 20 from persistence list 2021-01-26 03:22:51,014 INFO scheduler.ReceivedBlockTracker: Deleting batches: 2021-01-26 03:22:51,014 INFO scheduler.InputInfoTracker: remove old batch metadata: 1611649366000 ms至此数据经过kafka消息队列,spark获取并处理的整个流程大致如上。
番外篇——spark的源码编译步骤
本次编译使用的spark源码版本为3.0.0,查询源码中pom.xml后,该项目maven版本为3.6.3,java版本为1.8,scala版本为2.12
一、安装maven
1、解压maven到指定目录
tar zxvf maven.tar.gz /home/
2、修改配置文件setting.xml
vim $MAVEN_HOME/conf/setting.xml
添加maven本地仓库路径(maven会将依赖下载到该路径,windows系统默认为C://.m2/)
<localRepository>/home/ceres/maven_repository</localRepository>
注:外网可在此添加镜像mirror配置,若项目的pom.xml中没有对应依赖的镜像,maven会在该镜像中查询并下载。
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
3、修改系统配置文件或者用户配置文件.profile
添加MAVEN_HOME和PATH
export MAVEN_HOME=/home/ceres/maven
export PATH=$MAVEN_HOME/bin::$PATH
source .profile
4、检查maven是否配置成功
mvn -version
二、安装jdk
略
三、安装scala
1、解压scala到指定目录
tar zxvf scala.tar.gz /home/
2、修改系统配置文件或者用户配置文件.profile
添加SCALA_HOME和PATH
export SCALA_HOME=/home/ceres/maven
export PATH=$SCALA_HOME/bin:$PATH
source .profile
3、检查scala是否配置成功
scala -version
四、编译spark
1、mvn编译
set MAVEN_OPTS=-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m
mvn -DskipTests clean package
2、make_distribution编译
Spark内网编译
1、拷贝maven、scala对应安装包
2、将外网已经编译完成的spark源码对应的maven_repository打包拷贝至内网
3、配置maven本地仓库路径指向拷贝过来的maven_repository
4、同样使用mvn编译,编译参数同外网编译

