基于TensorFlow的食物图像识别
参考https://github.com/sourcedexter/tfClassifier/tree/master/image_classification
https://download.csdn.net/download/yang_china/11467532?spm=1001.2101.3001.5697
主要介绍如何在win10系统中使用TensorFlow环境运行一个最基本的图像分类器。
一、基础知识
1.物体分类的思想
物体分类,也就是训练系统识别各个物体,如猫咪、狗狗、汽车等。TensorFlow是谷歌开发出的人工智能学习系统,相当于我们的运行环境。
2.神经网络与Inception v3体系结构模型
神经网络示意图如下:
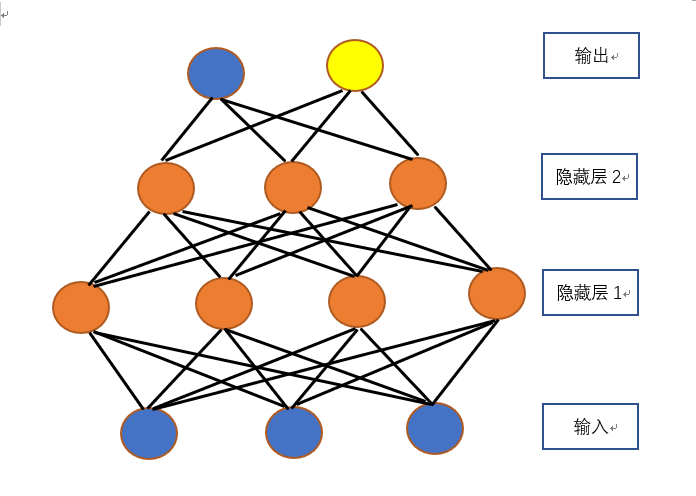
通俗了讲,就是将若干个输入,进行若干次操作(线性或者非线性),最后输出结果。Inception v3模型是谷歌发布的一个深层卷积网络模型。我们使用的retrain_new.py脚本就是使用了Inception v3模型进行一个迁移学习。
3.训练集、测试集和验证集
训练集用来训练模型,验证集用来验证模型是否进行了过拟合,测试集用来测试模型的准确程度。三种图片集的比例会对准确度产生影响。
4.学习速率
不同的学习速率会导致不同的结果。如果速率过大,会导致准确率在训练的过程中不断上下跳动,如果速率过小会导致在训练结束前无法到达预期准确度。
二、环境搭建
1.具体环境搭建可以查看之前的文章。
主要逐注意版本对应。
2.TensorFlow环境搭建(gpu)
(1)直接pip安装。命令:
pip install tensorflow-gpu
这样就安装好TensorFlow了,但是我们还需要GPU加速,所以还需要安装cuda和cuDnn(专门为deep learning准备的加速库)。
(2)cuda安装
下载完后正常安装就可以了。
(3)cuDnn库下载
下载完后解压缩,将三个文件拷贝到相应的文件中即可。一定注意对应覆盖。
(4)测试
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
查看是否输出。
三.基本使用
1.数据集的收集与创建
我用的是2018全球AI挑战赛的数据集。链接:https://challenger.ai/datasets/lad2018
2.训练模型
训练模型使用retrain_new.py脚本。在命令行运行,命令格式如下:
python retrain_new.py --model_dir 存放classify_image_graph_def.pb的路径 --image_dir 刚才的创建的DataSet的路径 --output_graph 产生的,pb文件的存放路径 --output_labels 产生的output_labels.txt的 存放路径 --how_many_training_steps 训练步数 -- learning_rate 学习速率 --testing_percentage 测试集比例 --validation_percentage 验证集比例
示例命令:
python retrain_new.py --model_dir E:\tfclassifier\image_classification\inception --image_dir E:\tfclassifier\DataSet --output_graph E:\tfclassifier\image_classification\output_dir\output_graph.pb --output_labels E:\tfclassifier\image_classification\output_dir\output_labels.txt --how_many_training_steps 500 --learning_rate 0.3 --testing_percentage 10 --validation_percentage 10
说明:
- model_dir参数:指定了model的存放位置,就是我们的inception文件夹
- image_dir参数:指定了数据集的位置
- output_graph参数:产生的output_graph.pb文件的存放路径(后面要用)
- output_labels 参数:产生的output_labels.txt的存放路径(后面要用)
- how_many_training_steps参数:训练步数,和学习速率配合调整(我用的500)
- learning_rate参数:学习速率,和训练步数配合调整(我用的0.3,常用的有0.001,0.01,0.1,0.3,1,3,可自己调整尝试一下)
- testing_percentage参数:测试集比例
- validation_percentage参数:验证集比例
3.测试模型
核心的文件是output_graph.pb文件(我们训练所产生的图,是一个二进制文件)和output_labels.txt文件。
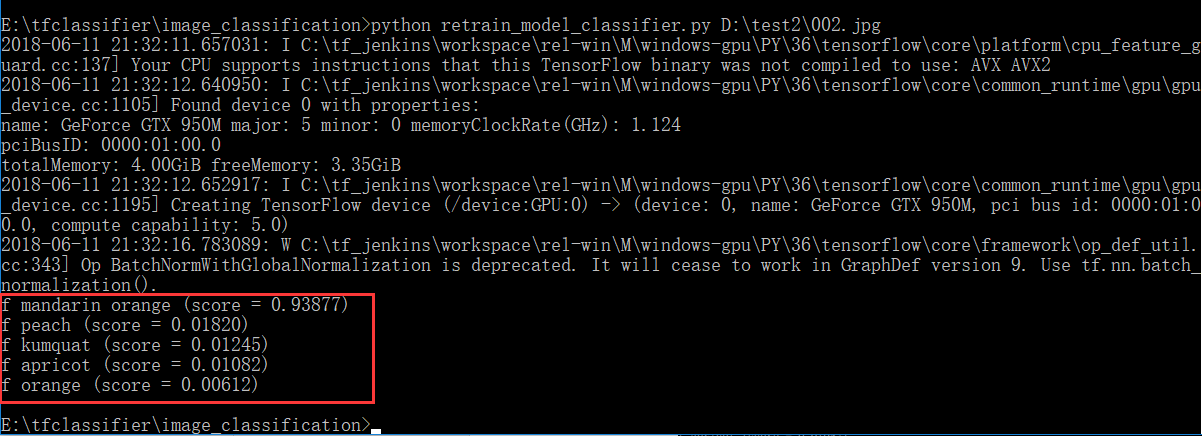
使用retrain_model_classifier.py脚本来测试模型。命令格式如下:
cd E:\tfclassifier\image_classification(进入retrain_model_classifier.py脚本所在的目录)python retrain_model_classifier.py 要识别图片的路径
然后会看到一些版本信息,和输出结果:
四.遇到的问题以及解答
1.版本对应问题
python版本,cuda版本和cuDNN版本都是对应的,如果结果中出现了乱码,很大概率是版本的问题。
2.带参数的python脚本编写与运行
想让python脚本带参数,可以在python脚本的末尾添加如下格式的代码:

运行时需要在python xxx.py后加上“--image_dir 参数”就可以了。
3.测试脚本的调整
要不断训练、测试,不断调整参数,直到训练快要结束的时候,验证比例达到稳定,并且在90以上,我们才认为系统较为完善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号