第三次作业——结对编程
第三次作业——结对编程
| github地址 | https://github.com/damaoya/WordCount.git |
| 结对伙伴的作业地址 | 大猫呀 |
一.设计与讨论
1)下面是我和结对伙伴的讨论照

2)PSP表格
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
25 |
30 |
|
Estimate |
估计这个任务需要多少时间 |
25 |
30 |
|
Development |
开发 |
870 |
1000 |
|
Analysis |
需求分析 (包括学习新技术) |
60 |
50 |
|
Design Spec |
生成设计文档 |
30 |
25 |
|
Design Review |
设计复审 (和同事审核设计文档) |
60 |
40 |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
20 |
15 |
|
Design |
具体设计 |
75 |
80 |
|
Coding |
具体编码 |
450 |
500 |
|
Code Review |
代码复审 |
105 |
160 |
|
Test |
测试(自我测试,修改代码,提交修改) |
70 |
130 |
|
Reporting |
报告 |
80 |
80 |
|
Test Report |
测试报告 |
30 |
30 |
|
Size Measurement |
计算工作量 |
20 |
25 |
|
Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 |
30 |
25 |
|
|
合计 |
1620 |
1840 |
3)项目设计思路
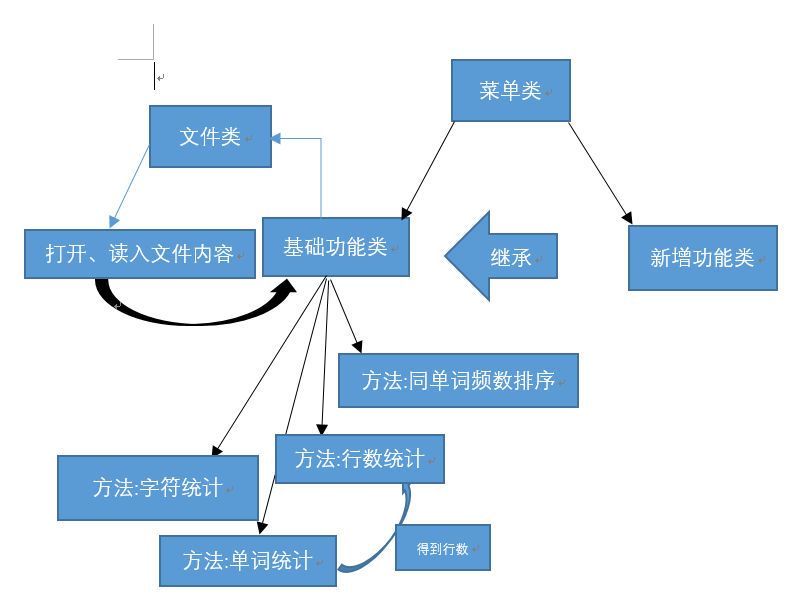
- 此次设计的程序主要是在字符串的操作上,所以对文件方面就不会有太过复杂的操作,我们第一个想法是从文件中读出所有内容并保存到一个字符串后,就结束所有的文件操作(基础功能方面)。
- 之后的第一个要求是统计文件字符数(除汉字),去汉字后引用string.Length语句就能轻松办到。
- 第二个要求需要统计单词数,要求较复杂,我们的想法起初是直接按照ToLower().split(' ',','),按空格和‘,’分离每个单词并小写化后成为数组单元,然后直接进入循环判断,但是实际操作的时候出现了问题,单用split()并不能去除换行符,于是伙伴建议在split()前使用Replace()语句将换行符"\r\n"换成空字符"",但是最后的结果反而多出了为空的元素(可能里面是空格或者其他的东西),所以使用了GetHashCode()语句得到此元素的哈希代码,做了个判断语句以去除该元素。默认所有数组元素为单词,将计为总数,然后判断数组若小于4以及数组元素大于4时若前4位元素的Ascii码是否为a—z之外,若满足条件,则在总数中减去1。
- 行数可以直接通过统计从未去换行符之前的数组元素获得,关键语句IndexOfAny(),所以找行数的步骤可以直接在统计单词时进行。
- 第五个要求我们试图引用了第二个要求里的数组,引用了计数数组和排序集合Dictionary<string,int>,然后将排序后的集合与计数数组一一对应,然后输出。
4)基础功能的步骤设计图
二.代码说明与运行效果
1)代码说明
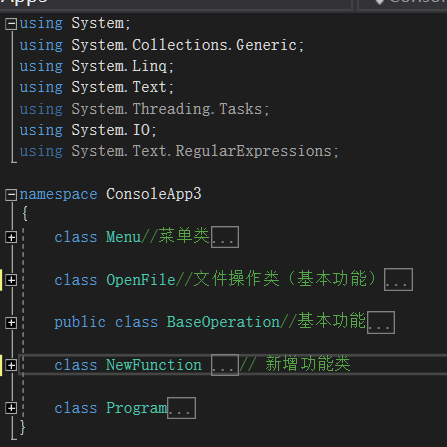
1.按照思路创建了多个类,分别是选择类(Menu)用作选择的菜单、文件操作类(OpenFile)用于基本功能里的文件操作,基本功能类和新增功能类
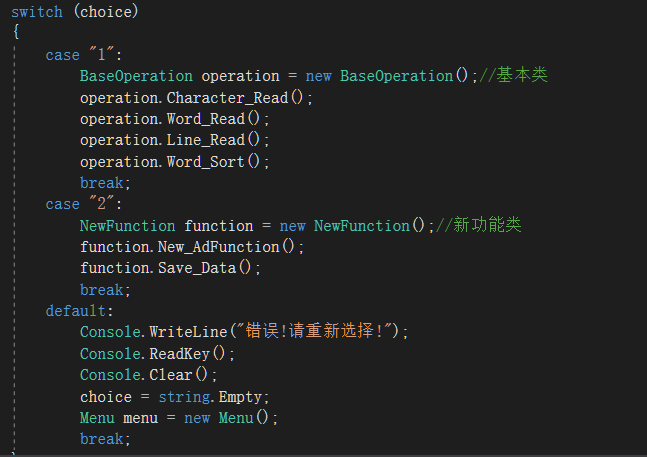
2.菜单类根据用户输入选择1.只进行基本功能的BaseOperation(),2.继承BaseOperation()所有功能且有自己独特功能的NewFunction()
3.文件操作类分两方法,按读取形式打开文件的方法OpenFile()和读取并返回读取内容的方法F_ToEnd()

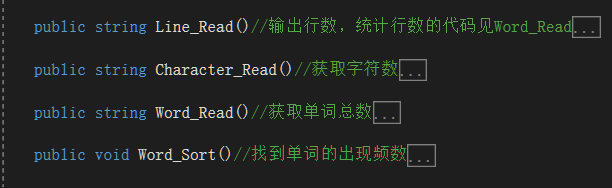
4.BaseOperation类全局变量有4个(作用详见代码后的补充说明),方法成员有4个分别对应基本操作的字符操作的4个需求(将方法设为需返回是方便新增功能中将运行输出结果写入文件output.txt的操作)
5.主要说明单词总数统计方法(Word_Read)和单词出现频数统计方法(Word_Sort)的代码
[1]统计单词总数时使用了将字符串按空格和','分成数组单元的的方法split(),去除换行符前引用计数方法IndexOfAny()找到换行符“\r”的个数,然后判断并输出满足要求的单词数。
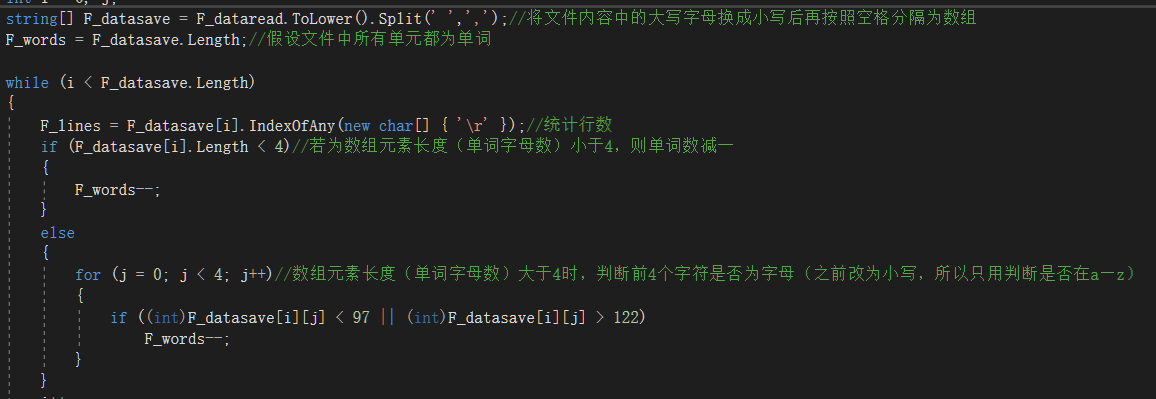
[2]统计单词出现频数时出现了单词数中出现了为空的数组元素,所以使用了GetHashCode()语句得到此元素的哈希代码,做了个判断语句以去除数组中的同类元素。

[3]由于无法找到一个方法使两个数组一一对应,于是使用了集合类Dictionary<>实现了单词频数排序和输出。
for (i = 0; i < F_data.Length; i++)
{
if (F_data[i] == "")
{
F_data[i].Trim(' ', ',');//为保险起见,再次去除数组元素前后的空格及“,”
continue;
}
for (j = i + 1; j < F_data.Length; j++)
{
if (F_data[i] == F_data[j])//若第i个单词与第j个单词相等,频数加一,第j个单词改为空字符串(避免重复读入不同位置的同一单词)
{
word_quantity_r[i]++;
F_data[j] = "";
}
}
word_list.Add(F_data[i], word_quantity_r[i]);//将单词与对应频数放入集合(Dictionary)
if (F_data[i].Length < 4)//排除非单词
{
word_list.Remove(F_data[i]);
}
else
{
for (k = 0; k < 4; k++)
{
if ((int)F_data[i][k] < 97 || (int)F_data[i][k] > 122)
word_list.Remove(F_data[i]);
}
for (k = 4; k < F_data[i].Length; k++)
if ((int)F_data[i][k] < 97 && (int)F_data[i][k] > 122)
word_list.Remove(F_data[i]);
}
}
var Sort = word_list.OrderByDescending(objDic => objDic.Value).ThenByDescending(objDic => objDic.Key);
//先按照频数降序排序,再按照单词对应ASC码进行排序
foreach (KeyValuePair<string, int> pair in Sort)
{
Console.WriteLine("< "+pair.Key + " >: " +pair.Value);//输出单词及频数
}
6.新增功能类,继承了基础功能类的所有方法和成员,并添加了两个新功能

2)效能分析
三.总结
分析和生成代码的过程虽然十分的艰难,特别是复审阶段时出现了个人审核时未出现的Bug,花了很多的时间修改代码,但是完成之后很有成就感,而且双人乃至多人项目能够审核到更多单人审核中看不到的错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号