Inception&MobileNets
Inception v1
paper:《Going deeper with convolutions》
GoogLeNet夺得2014年ImageNet冠军,其最大的特点就是使用了Inception模块。Inception v1初始结构如下:
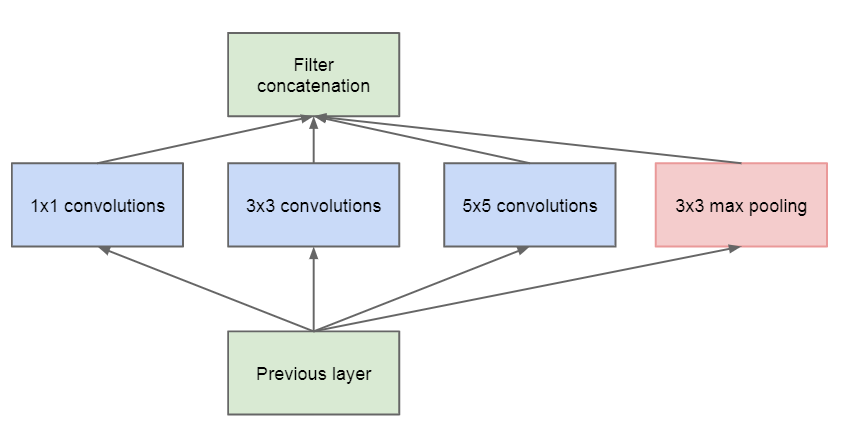
由于图像中需要识别的物体大小差异、位置差异很大,很难确定合适的卷积核大小。Inception v1采用多种不同大小的卷积核并行处理,包括\(1\times1\),\(3\times3\),\(5\times5\)。采用不同大小的卷积核增加了网络的宽度的同时,最重要的是拥有了不同大小的感受野,能够提取更多不同尺度的特征。
另外,之前网络每一层卷积后都需加一个激活函数或池化来增加非线性。Inception则通过不同尺度的卷积合成后,获得非线性。
Inception还使用global average pooling代替了全连接层。用GAP替代FC全连接层,有两个有点:一是GAP在特征图与最终的分类间转换更加简单自然;二是不像FC层需要大量训练调优的参数,降低了空间参数会使模型更加健壮,抗过拟合效果更佳。
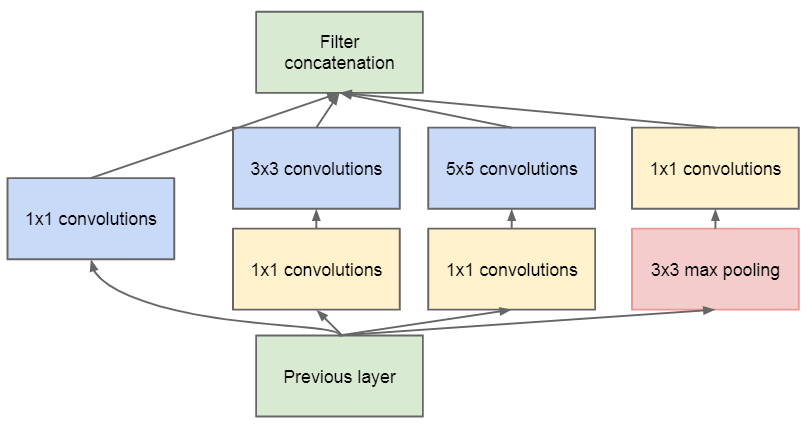
然而Inception原始版本,由于\(5\times5\)卷积核参数过多,带来了巨大的计算量,因此不得不采用\(1\times1\)的卷积核进行降维,最终结构如图:
Inception v2
paper: Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift
Rethinking the Inception Architecture for Computer Vision
首先Inception v2提出了Batch Normalization(简称BN)的方法。BN是一个正则化方法,在加快训练速度的同时也大幅提高了Inception的性能,控制梯度爆炸防止梯度消失。传统的深度学习网络在训练过程中,输入值在随着网络深度加深,其值往往会向函数取值区间两端靠近,从而导致梯度消失,网络收敛越来越慢。
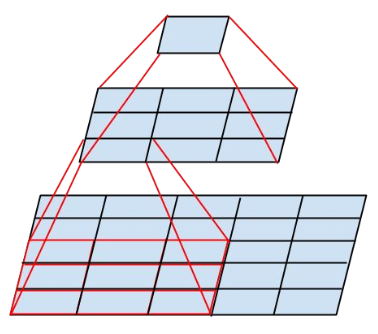
在另一篇文章中,Inception v2修改了卷积内部的计算逻辑,通过将卷积分解简化计算。
大尺寸的卷积核具有更大的感受野,同时也具有更多的参数。作者提出通过两个\(3\times3\)的卷积代替\(5\times5\)的大卷积,在感受野不变的情况下减少参数量。

Inception v3
paper:Rethinking the Inception Architecture for Computer Vision
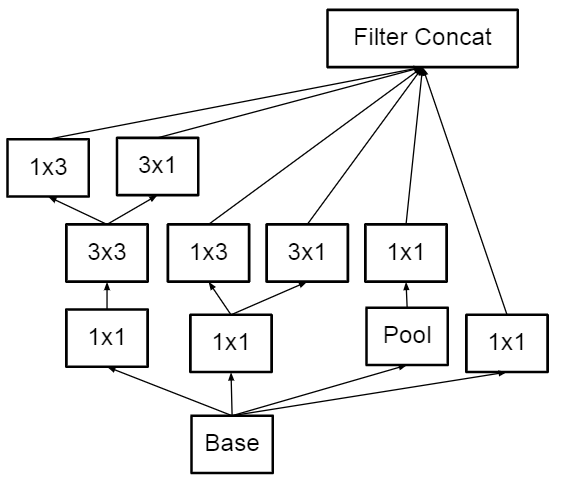
Inception v3是和v2一起提出,同样是将卷积分解,v3将\(7\times7\)的卷积分解为\(1\times7\)和\(7\times1\)不对称的小核,从而进一步降低计算量。

然而,经过测试,在网络模型的前期使用该分解方式效果并不理想。通常在网络中期,n取7效果更好。
模块中卷积也可横向分解,以此来产生高维的稀疏特征。
Inception v4
paper: Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Inception v4改动并不大。作者通过实验对Inception模块进行了规范,即输出不同尺寸特征图下的block。如要输出\(35\times35\),\(17\times17\),\(8\times8\)的特征图应该用的Inception Block。
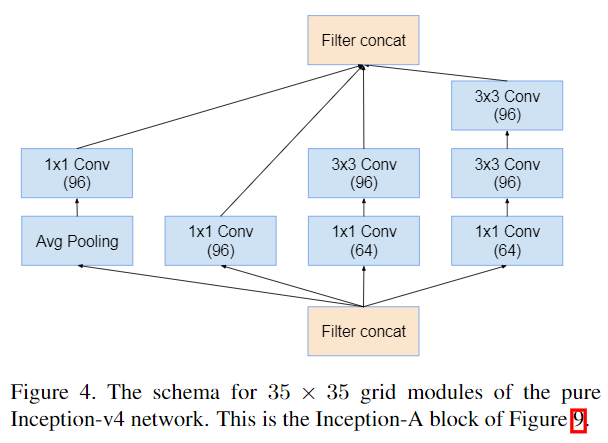
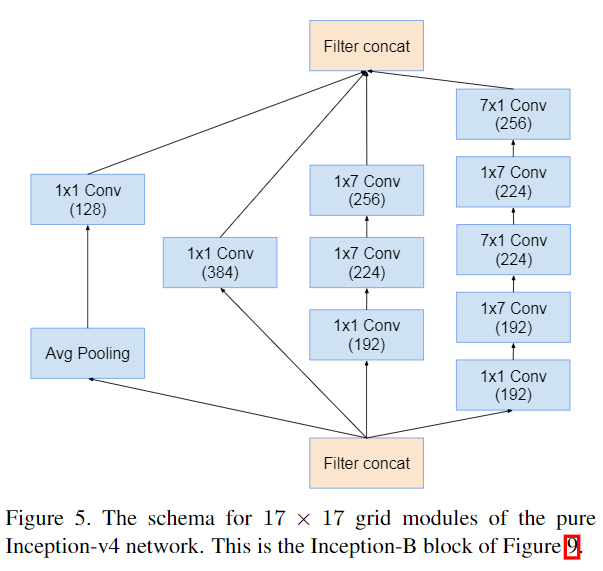
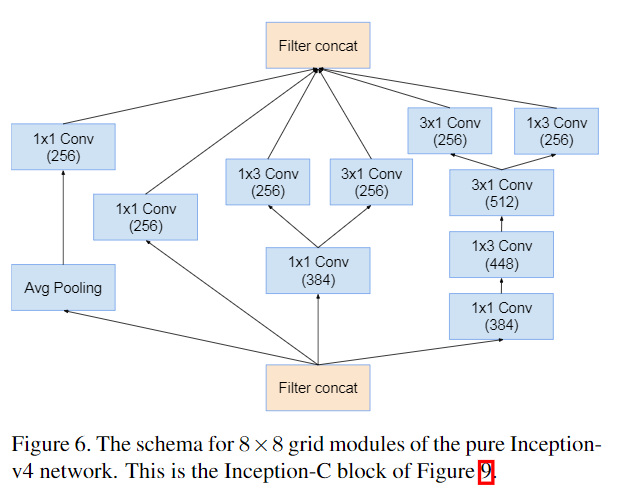
Inception-ResNet
Inception-ResNet正如其名,在Inception模块中引入ResNet的残差结构。为了保证残差与Inception子网络的输出维度相同,加入一个\(1\times1\)conv调整维度。
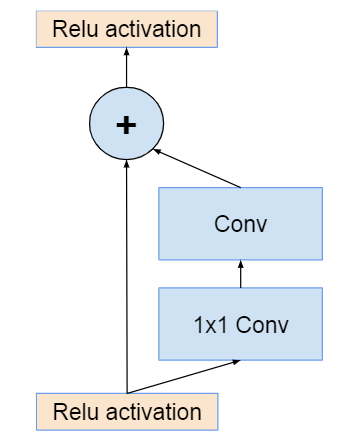
MobileNets
MobileNets最主要的思想是采用了depthwise separable convolution(深度可分离卷积),将standard convolutions(标准卷积)分解为depthwise convolution(深度卷积)和pointwise convolution(逐点卷积)。
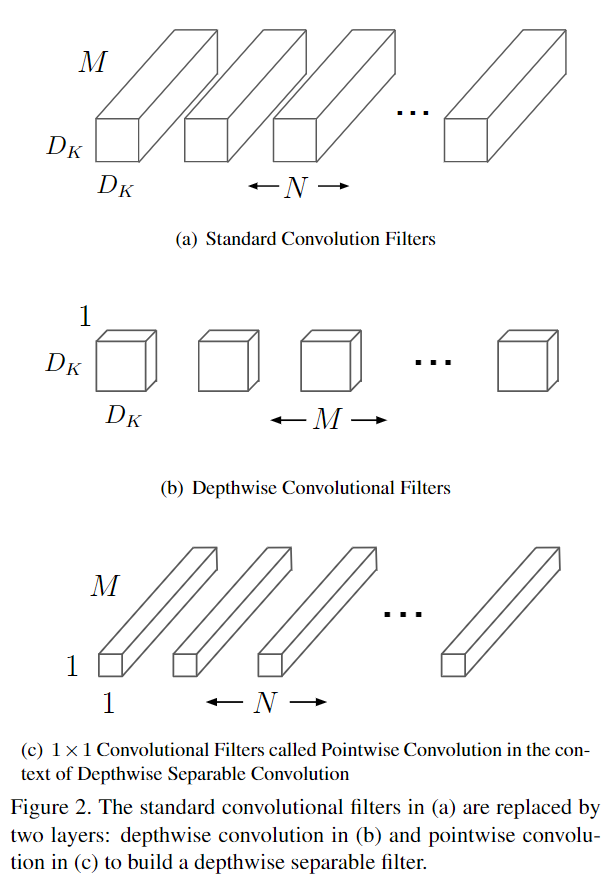
假设我们有一个输入图片,这个输入图片的维度是11 x 11 x 3,标准卷积为3 x 3 x 3 x 6(假设stride为2,padding为1),那么可以得到输出为6 × 6 × 16(6 = (11-3+2*1)/2+1)的输出结果。现在输入图片不变,先通过一个维度是3 × 3 × 1 × 3的深度卷积(输入是3通道,这里有3个卷积核分别作用在3个通道上),得到6 × 6 × 3的中间输出,然后再通过一个维度是1 × 1 × 3 ×16的1 ×1卷积,同样得到输出为6 × 6 × 16。
然后进行推导
设:
输入图片大小是\(D_F\times D_F\times M\),\(D_F\)表示宽、高,\(M\)表示通道数。
步长为1,padding取值使输出图片宽高不变。
输出图片大小是\(D_F\times D_F\times N\),\(D_F\)表示宽、高,\(N\)表示通道数。
卷积核尺寸是\(D_K\times D_K\)。
则:
标准卷积计算量:
深度可分离卷积计算量:
两中卷积方式计算量比值:

