

五. Python基础(5)--语法
1 ● break结束的是它所在的循环体, continue是让它所在的循环体继续循环
# 打印: 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 10 9 10 for i in range(1, 10): print(i , end = ' ') for i in range(10, 20): print(i , end = ' ') break # break是结束它所在的循环体 |
2 ● 打印: 1 10 2
# 方法1 is_first = True for i in range(1, 10): if i < 3: print(i) else: break for j in range(10, 20): if is_first: print(j) is_first = False # break 如果这里有break, 11, 12,13,...19的循环不会再进行, 这个内部的循环直接结束, 不过写不写break, 结果都是一样的.
# 方法2 flag = False for i in range(1, 10): print(i) if flag: # ① 在外循环进行第二轮循环之前, flag已经变成True break for j in range(10,20): print(j) flag = True break # 内循环只进行一轮, 并且在这轮循环内, flag已经变成True |
3 ● 删除奇数的索引项
# 已知: li = [11,22,33,44,55,66] # 要求删除奇数索引的元素 # 方法1: 保留偶数项目 tmp_list = [] for i in range(0, len(li)): if i % 2 == 0: tmp_list.append(li[i]) print(tmp_list)
# 方法2: # 从后往前删, 因为如果从前往后删, 每删一个元素,索引不是指原list的索引 for i in range(len(li)-1, -1, -1): # 不包括-1, 包括0 if i % 2 == 1: del li[i] print(li)
# 方法3: # 使用list的slicing功能 del li[0 : len(li) : 2] # 注意说法: 奇数索引的元素 print(li) # 这里通过步长删除列表元素, python内部已经避免了列表长度变化的问题. # 结果: [22, 44, 66] |
4 ● 删除字典元素
如果遍历词典时, 然后删除符合预期条件的字典元素,程序会报错:
|
dic = {'u1': 'v1', 'k2': 'v2', 'k3': 'v3'} # 不要在循环字典的过程当中修改字典的大小(注意: 词典的值是可以改的) tmp_list =[] for key in dic.keys(): if 'k' in key: tmp_list.append(key)
for item in tmp_list: # 此时循环的是列表, 删除的是字典元素 del dic[item]
print(dic)
# 结果: {'u1': 'v1'} |
在遍历中删除元素是不好的设计习惯 . |

5 ● 元组特别案例
v1 = (1) print(type(v1)) v2 = (1,) # 当元组只有一个元素时, 一定要加逗号 # 如果是v1 = [1], type(v1)的值是<class 'list'> print(type(v2)) # <class 'int'> # <class 'tuple'> |
6 ● 强转过程中需要注意的地方
# 强转字符串为list和tuple时会进行迭代. |
|


7 ● False和True的总结
False: 0, None, '', [], {}, () |
True: 除上面所有的 |
8 ● 域宽(filed width)
%10d 这里的10表示域宽(filed width) |
print("我今年%10d岁了"%(5)) |
我今年 5岁了. |
9 ● 字典和列表的结合
li = [11, 22, 33, 44, 55, 66, 77, 88, 99] # 生成一词典, 大于66的属于'k1'这个键, 小于66的属于'k2'这个键, # 方法1: dic = {} for i in li: if i > 66: if 'k1' not in dic.keys(): dic['k1'] = [i] # 需要什么就随时创立什么, 这里是需要一个list就创立一个lsit # 比较麻烦的写法是: # tmp_list = [i] # dic['k1'] =tmp_list else: dic['k1'].append(i) elif i < 66: if 'k2' not in dic.keys(): dic['k2'] = [i] else: dic['k2'].append(i) # esle : 如果对其它情况不作处理, 可以省略这一语句 print(dic)
li = [11, 22, 33, 44, 55, 66, 77, 88, 99] # 生成一词典, 大于66的属于'k1'这个键, 小于66的属于'k2'这个键, dic = {} for i in li: if i >66: if 'k1' in dic.keys(): dic['k1'].append(i) else: dic['k1'] = [i] elif i < 66: if 'k2' in dic.keys(): dic['k2'].append(i) else: dic['k2'] = [i]
print(dic) |
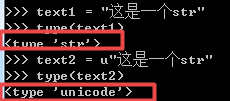
1. ● 字符串类型
Py2的字符串类型有两种:
Py3的字符串前加或不加'u', 都是str类型, str在外存和网络传输中的形式是bytes类型:
|
仔细阅读下面的文章: http://blog.chinaunix.net/uid-27838438-id-4227131.html http://blog.csdn.net/ryfdizuo/article/details/42102505 http://www.cnblogs.com/tingyugetc/p/5727383.html 上面文章提到python3.x中不能查看字符串的Unicode序列, 实际上可以通过下面的方法查看:
python2.x中:
|
对于python2来说: decode 的是将其他编码的字符串转换成 Unicode 编码,例如: name.decode("GB2312"),表示将GB2312编码的字符串name转换成Unicode编码 encode 的是将Unicode编码转换成其他编码的字符串,eg name.encode("GB2312"),表示将GB2312编码的字符串name转换成GB2312编码 |


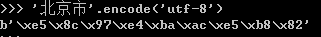



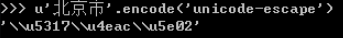






2 ● 深浅拷贝区别简述
※ 要说清楚Python中的深浅拷贝,需要搞清楚下面一系列概念: 变量-引用-对象(可变对象,不可变对象)-切片-拷贝(浅拷贝,深拷贝) ① Python中变量与C/C++/Java中不同,它是指对象的引用(引用是自动形成的从变量到对象的指针),Python是动态类型,程序运行时候,会根据对象的类型来确认变量到底是什么类型。 ② Python中的变量并不直接存储值,而是存储了值的内存地址或者引用,这也是变量类型随时可以改变的原因。
例如: >>> a = 3 在运行a=3后,变量a变成了对象3的一个引用。
※ 共享引用, 例如: >>> a = 3 >>> b = a 在运行赋值语句b = a之后,变量a和变量b指向了同一个对象的内存空间. |
浅拷贝: 只拷贝最外层对象的内容, 对于内部嵌套的对象, 只拷贝其引用. 深拷贝: 拷贝所有层的对象的内容.
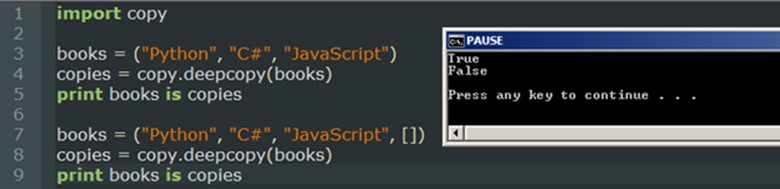
加深理解: Python中对象的赋值都是进行对象引用(内存地址)的传递. 深浅拷贝都是对源对象的复制,占用不同的内存空间 如果源对象只有一级目录的话,源做任何改动,不影响深浅拷贝对象 如果源对象不止一级目录的话,源做任何改动,都要影响浅拷贝,但不影响深拷贝 序列对象的切片其实是浅拷贝,即只拷贝顶级的对象 对于非容器类型(如数字、字符串、和其他'原子'类型的对象)没有被拷贝一说 如果元祖变量只包含原子类型对象,则不能深拷贝,例如:
|
浅拷贝只拷贝父对象,不会拷贝对象的内部的子对象. 深拷贝拷贝对象及其子对象. |
※ 知识拓展: C++中的浅拷贝和深拷贝
shallow copy(浅拷贝): 默认的复制构造函数实现的是浅拷贝. 浅拷贝只是简单地复制指向数据的指针,并不复制数据本身。 The default copy constructor realizes shallow copy, Shallow copy just simply copies the pointers that point to data, and doesn't copy the data.
deep copy(深拷贝): 我们可以自己写一个复制构造函数来实现深拷贝, 该拷贝构造函数不仅可以实现原对象和新对象之间数据成员的拷贝,而且可以为新的对象分配单独的内存资源。 不仅复制指针,并且复制指针指向数据的本身。 We can write a copy constructor by ourselves to realize deep copy, which can not only realize the cloning of an original object to get a new one, but also allocate memory space for the new object. |
 posted on
posted on
