

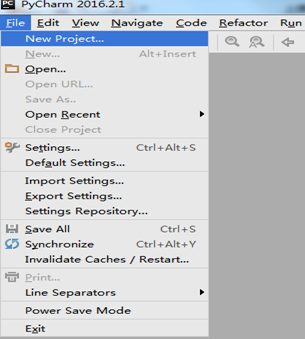
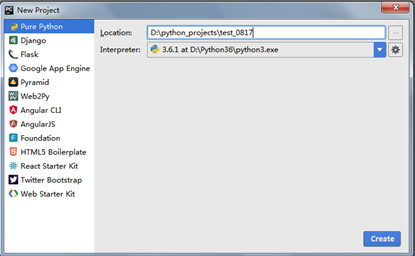
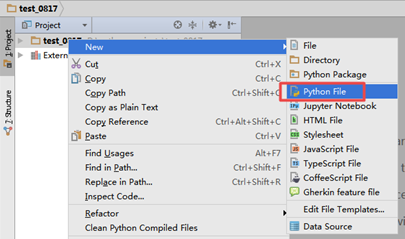
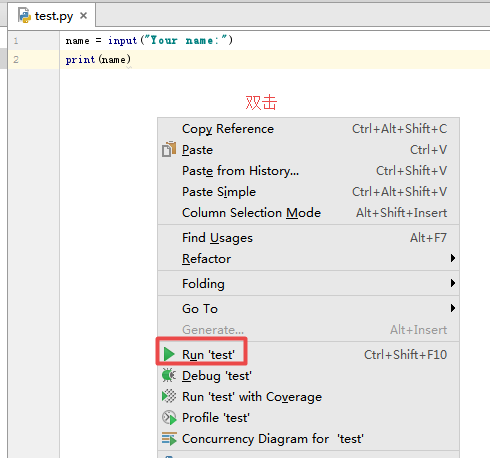
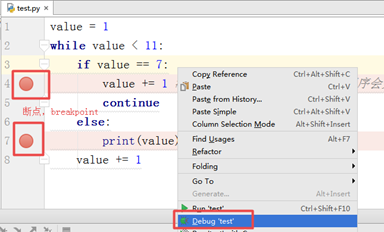
二. Python基础(2)--语法
'''# 形式1 n = 1 while n < 4: name = input("请输入姓名\n") if name == "Arroz": print("Welcome!") exit() else: print("Wrong name!") n += 1'''
# 形式2 n = 1 while True: name = input("请输入姓名\n") if name == "Arroz": print("Welcome!") exit() else: print("Wrong Name!") n += 1 # 打印"Wrong Name"以后要根据n的值才判断是否允许进一步输入 if n >3: break |
|
|
|
|
|
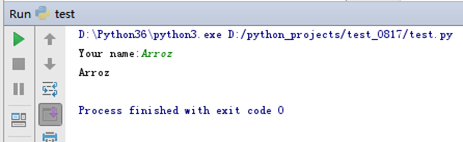
目的:将数字和字符串相结合 |
%s,%d→(代替缺失部分的)占位符(placeholder) "s"代表"string","d"代表"decimal" |
msg_1 = "我叫%s"%("Arroz") # 括号可以省略 msg_2 = "我叫%s,年龄%d,爱好%s"%("Arroz", 18, "和平") # 括号不可以省略 name = input("Your name:") age = input("Your age:") hobby = input("Your hobby:") msg_3 = "我叫%s,年龄%s,爱好%s"%(name,age, hobby) print(msg_1) print(msg_2) print(msg_3) |
4、数的进制和编码(Number Bases and Encoding)
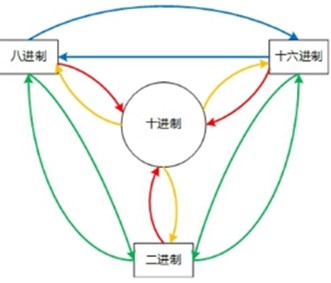
● N进制的计数法,就是"逢N进一"(仔细体会, 为什么二进制的11加1后变成了100)
进制类型 types of number bases | 数码 digit | 举例 example |
十进制数 decimal | 0~9 | 100、-8、0 |
二进制 binary | 0, 1 | 1000, 10000 |
八进制数octal | 0~7,以数字0开头 | 010、-024 |
十六进制数hexadecimal | 0~9,A~F或a~f,以0x或0X开头 | 0x8a、-0X1F |
● "three" in base two / base-ten "two" →(210)二进制的3
the second, third, fourth, etc power of x (= x2, x3, x4, etc) →x的二次﹑ 三次﹑ 四次等幂(= x2﹑ x3﹑ x4等)
● conversion between different number system
4.1.1 二进制、八进制、十六进制转换成(convert into)十进制:
(1010)10 =1× 10^3+0× 10^2+1× 10^1+0× 10^0
(1010)2 =l× 2^3+0 × 2^2+l× 2^1+0 × 2^0=(10)10
(1010)8 =l× 8^3+0 × 8^2+l× 8^1+0 × 8^0=(520)10
(BAD)16 =11× 16^2+10×l6^1+13×16^0=(2989)10
二进制转换成八进制:从右向左,每3位一组(不足3位左补0),转换成八进制
000 ~ 0 001 ~ 1 010 ~ 2 011 ~ 3 100 ~ 4 101 ~ 5 110 ~ 6 111 ~ 7 |
例:(1101001)2=(001,101,001)2=(151)8
(246)8=(010,100,110)2=(10100110)2
二进制转换成十六进制:从右向左,每4位一组(不足4位左补0),转换成十六进制
0000 ~ 0 0001 ~ 1 0010 ~ 2 0011 ~ 3 0100 ~ 4 0101 ~ 5 0110 ~ 6 0111 ~ 7 1000 ~ 8 1001 ~ 9 1010 ~ A 1011 ~ B 1100 ~ C 1101 ~ D 1110 ~ E 1111 ~ F |
例: (11010101111101)2=(0011,0101,0111,1101)2=(357D)16
(4B9E)16=(0100,1011,1001,1110)2=(100101110011110)2
十进制整数转换为二进制:方法是除以2取余,逆序排列,以(89)10为例,如下:
89 ÷ 2 余1 44 ÷ 2 余0 22 ÷ 2 余0 11 ÷ 2 余1 5 ÷ 2 余1 2 ÷ 2 余0 1 余1 例如: (89)10 = (1011001)2 (5)10 = (101)2 (2)10 = (10)2 |
再如: Convert 35710 to the corresponding binary number.
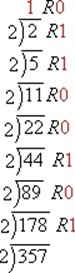
※ R refers to "remainder (余数)"
十进制小数的转换为二进制:方法是乘以2取整,顺序排列,以(0.625)10为例,如下:
十进制 | 八进制 | 二进制 | 十六进制 |
0 | 0 | 0 | 0 |
1 | 1 | 1 | 1 |
2 | 2 | 10 | 2 |
3 | 3 | 11 | 3 |
4 | 4 | 100 | 4 |
5 | 5 | 101 | 5 |
6 | 6 | 110 | 6 |
7 | 7 | 111 | 7 |
8 | 10 | 1000 | 8 |
9 | 11 | 1001 | 9 |
10 | 12 | 1010 | a |
11 | 13 | 1011 | b |
12 | 14 | 1100 | c |
13 | 15 | 1101 | d |
14 | 16 | 1110 | e |
15 | 17 | 1111 | f |
16 | 20 | 10000 | 10 |
※word size/word length (字长): The number of bits in a word. 一个字中的二进制位的数目。
位(比特:bit,b,小写):度量数据的最小单位. 字节(Byte,B,大写):最常用的基本单位,1字节=8位
K (千)字节(Kilobyte) 1K / 1KB / 1kB = 1024 Byte M(兆)字节(Megabyte) 1M = 1024 K G(吉) 字节(Gigabyte) 1G = 1024 M T(太)字节(Terabyte) 1T = 1024 G |
①ASCII编码(American Standard Code for Information Interchange)
Unicode→字符集,它为每一个字符分配一个码位/码点(Code Point)。例如:"知"的码位是30693;记作 U+77E5(30693 的十六进制为 0x77E5;)。 ※ Unicode是为整合全世界所有语言的字符而诞生的, 任何字符在Unicode中都对应一个值,这个值称为码位/码点(code point)。代码点的值通常写成 U+ABCD 的格式。而文字和码位/码点之间的对应关系就是UCS-2(Universal Character Set coded in 2 octets),即用两个字节来表示码位/码点集合,其取值范围为 U+0000~U+FFFF(2^16=65536个)。为了能表示更多的文字,人们又提出了UCS-4,即用四个字节表示码位/码点集合。它的范围为 U+00000000~U+7FFFFFFF(2^31=2147483648个),其中 U+00000000~U+0000FFFF和UCS-2是一样的。
※ 现在UCS-2的使用更广泛.
※ UCS-2和UCS-4只规定了码位/码点集合和字符之间的对应关系,并没有规定代码点在计算机中如何存储。规定存储方式的称为UTF(Unicode Transformation Format),其中应用较多的就是UTF-16和UTF-8了。
※ UTF-32 是一个 UCS-4 的子集,使用32-位元的码值,只用0到10FFFF的码位。
※ 字符串在Python内部的表示是的 Unicode 编码,因此,在做编码转换时,通常需要以的 Unicode 作为中介,即先将其他编码的字符串解码(decode)成的 Unicode ,再从的 Unicode 编码(encode)成另一种编码。 decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。 encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
※ A universal character name(UCN, 统一字名) looks like \uFFFD or \U0010FFFD.
※ 统一码是"请", "a"等字符, 统一字名是\u8BF7等十六进制数.
UTF-8、UTF-16、UTF-32→编码规则,实现Unicode的不同方案,可以想象为汉字的隶书、楷书、行书等。8, 16, 32表示的单位, 不是大小. 用UTF-8: 以8位为单位来标识文字, 每个字符需要1至4个字节。 UTF-16: 以16位为单位来标识文字, 每个字符需要2个或者4个字节 UTF-32: 以32位为单位来标识文字, 每个字符需要4个字节。
※ GBK和UTF-8可以"Unicode"为中介来实现编码的转换。
※ 16进制数的每一位可由4位二进制数表示,所以1个字节可以用2位16进制数表示。 |
在2.x中, 字符串分为str字符串(用'xxx'表示)以及unicode字符串(用u'xxx'表示) 在3.x中, 只有unicode字符串, 写u'xxx'和'xxx'是完全一样的,如果要表示Python 2.x中的'xxx'表示的str, 就必须写成b'xxx',以此表示"二进制字符串"。
2.x中, 文本用str和unicode这两种数据类型表示. unicode通过编码转换成str,str通过解码转转换成unicode。 3.x中, 文本用str和bytes这两种数据类型表示. str类型与2.x中unicode类似,bytes与2.x中的str类似。bytes通过解码转化成str,str通过编码转化成bytes。 |
utf-8是一种"宽度可变的编码(variable-width encoding)",那么utf-8中的汉字占用多少字节? |
占2个字节的:〇 占3个字节的:基本等同于GBK,含21000多个汉字; 占4个字节的:中日韩超大字符集里面的汉字,有5万多个; |
一个utf8数字占1个字节。 一个utf8英文字母占1个字节。 |
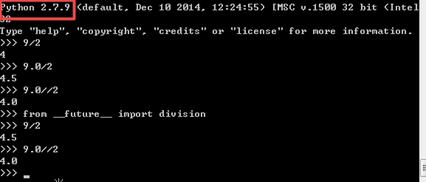
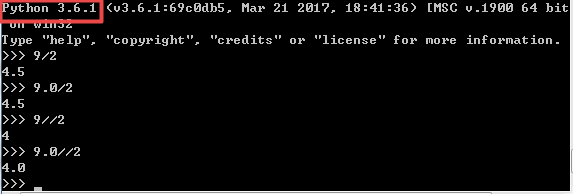
① 除法:注意 python2中需要引入:"from __future__ import division",才能实现和Python3一样的效果。
|
|
注意:①若字符串内有双引号,可使用单引号将字符串括起来;若字符串内同时有单引号和双引号,可用三个双引号(或三个单引号)将字符串括起来。
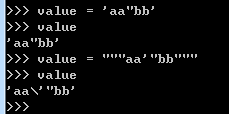

 posted on
posted on
