开源框架(二): 核心拦截器责任链
 开源框架(二): 核心拦截器责任链
开源框架(二): 核心拦截器责任链
OKHttp源码分析(二):核心拦截器责任链
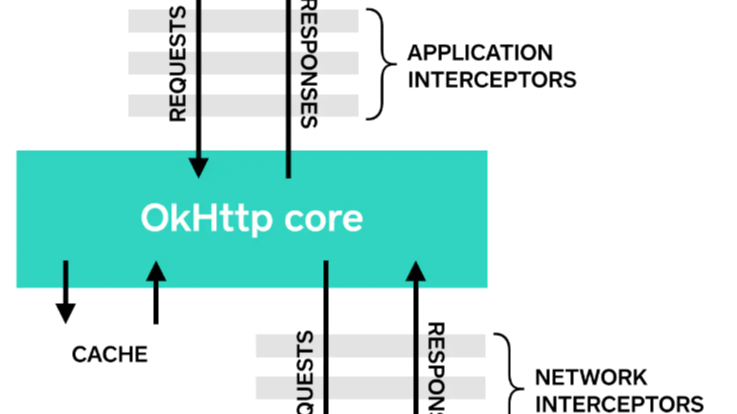
上次提到 无论是同步还是异步请求实际上真正执行请求的工作都在 getResponseWithInterceptorChain() 中。这个 方法就是整个OkHttp的核心:拦截器责任链
分发线程池
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(
0, //核心线程
Integer.MAX_VALUE, //最大线程
60, //空闲线程闲置时间
TimeUnit.SECONDS, //闲置时间单位
new SynchronousQueue<Runnable>(), //线程等待队列
Util.threadFactory("OkHttp Dispatcher", false) //线程创建工厂
);
}
return executorService;
}
在OkHttp的分发器中的线程池定义如上,其实就和 Executors.newCachedThreadPool() 创建的线程一样。首先核
心线程为0,表示线程池不会一直为我们缓存线程,线程池中所有线程都是在60s内没有工作就会被回收。而最大线程 Integer.MAX_VALUE 与等待队列 SynchronousQueue 的组合能够得到最大的吞吐量。即当需要线程池执行任务时,如果不存在空闲线程不需要等待,马上新建线程执行任务!等待队列的不同指定了线程池的不同排队机制。一般来说,等待队列 BlockingQueue 有: ArrayBlockingQueue 、 LinkedBlockingQueue 与 SynchronousQueue 。
假设向线程池提交任务时,核心线程都被占用的情况下:
ArrayBlockingQueue :基于数组的阻塞队列,初始化需要指定固定大小。
当使用此队列时,向线程池提交任务,会首先加入到等待队列中,当等待队列满了之后,再次提交任务,尝试加入队列就会失败,这时就会检查如果当前线程池中的线程数未达到最大线程,则会新建线程执行新提交的任务。所以最终可能出现后提交的任务先执行,而先提交的任务一直在等待。
LinkedBlockingQueue :基于链表实现的阻塞队列,初始化可以指定大小,也可以不指定。 当指定大小后,行为就和ArrayBlockingQueu 一致。而如果未指定大小,则会使用默认的 Integer.MAX_VALUE 作为队列大小。这时候就会出现线程池的最大线程数参数无用,因为无论如何,向线程池提交任务加入等待队列都会成功。最终意味着所有任务都是在核心线程执行。如果核心线程一直被占,那就一直等待。
SynchronousQueue : 无容量的队列。使用此队列意味着希望获得最大并发量。因为无论如何,向线程池提交任务,往队列提交任务都会失败。而失败后
如果没有空闲的非核心线程,就会检查如果当前线程池中的线程数未达到最大线程,则会新建线程执行新提交的任务。完全没有任何等待,唯一制约它的就是最大线程数的个数。因此一般配合 Integer.MAX_VALUE 就实现了真正的无等待。
但是需要注意的时,我们都知道,进程的内存是存在限制的,而每一个线程都需要分配一定的内存。所以线程并不能无限个数。那么当设置最大线程数为 Integer.MAX_VALUE 时,OkHttp同时还有最大请求任务执行个数: 64的限
制。这样即解决了这个问题同时也能获得最大吞吐。
拦截器责任链
常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下 一个接收者,依此类推
OkHttp中的 getResponseWithInterceptorChain() 中的流程为

请求会被交给责任链中的一个个拦截器。默认情况下有五大拦截器:
-
RetryAndFollowUpInterceptor 第一个接触到请求,最后接触到响应;
在这个 拦截器中主要功能就是判断是否需要重试与重定。重试的前提是出现了 RouteException 或者 IOException 。一但在后续的拦截器执行过程中出现这两个异常,就会 通过 recover 方法进行判断是否进行连接重试。 重定向发生在重试的判定之后,如果不满足重试的条件,还需要进一步调用 followUpRequest 根据 Response 的响 应码(当然,如果直接请求失败, Response 都不存在就会抛出异常)。 followup 最大发生20次。
- 请求阶段发生了 RouteException 路由异常,连接未成功,请求还没发出去。
- IOException会进行判断是否重新发起请求。(socket流正在读写数据的时候断开连接) HTTP2才会抛出ConnectionShutdownException。所以对于HTTP1 requestSendStarted一定是true
- 协议异常,如果是那么直接判定不能重试;
- 超时异常,可能由于网络波动造成了Socket连接的超时,可以使用不同路线重试
- SSL证书异常/SSL验证失败 不能重试
- 重定向 308 永久重定向 307 临时重定向
流程:

-
BridgeInterceptor 桥接拦截器
对用户构建的 Request 进行添加或者删除相关头部信息,以转化成能够真正进行网络请求的 Request 将符合网络 请求规范的Request交给下一个拦截器处理,并获取 Response 如果响应体经过了GZIP压缩,那就需要解压,再构 建成用户可用的 Response 并返回
- 补全请求头
- Content-Type 请求体类型
- Content-Length/Transfer-Encoding 请求题解析方式
- Host 请求的主机站点
- Connetcion Keep-Alive 保持长连接
- Accept-Encoding Gzip 支持gzip压缩
- Cookie cookie身份识别
- User - Agent 请求的用户信息, 操作系统,浏览器
- 解析响应体
- 保持Cookie 下次请求则会读取对应的数据进入请求头
- 使用gzip返回的数据,则使用Gzip包装便于解析
- 补全请求头
-
CacheInterceptor 缓存拦截器
在发出请求前,判断是否命中缓存。如果命中则可以不请求,直接使用缓存的响应。 (只会存 在Get请求的缓存)在缓存拦截器中判断是否可以使用缓 存,或是请求服务器都是通过 CacheStrategy 判断。(策略很复杂) 下下文 HTTP 缓存技术
- 从缓存中获得对应请求的响应缓存
- 创建 CacheStrategy ,创建时会判断是否能够使用缓存
- 交给下一个责任链继续处理
- 后续工作,返回304则用缓存的响应;否则使用网络响应并缓存本次响应(只缓存Get请求的响应)
-
ConnectInterceptor 与服务器完成TCP连接
这个拦截器中的所有实现都是为了获得一份与目标服务器的连接,在这个连接上进行HTTP数据的收发。处理一下连接复用等问题
-
CallServerInterceptor 与服务器通信;
利用 HttpCodec 发出请求到服务器并且解析生成 Response,封装请求数据与解析响应数据(如:HTTP报文)。首先调用 httpCodec.writeRequestHeaders(request); 将请求头写入到缓存中(直到调用 flushRequest() 才真正发 送给服务器)。
HTTP 缓存技术
对于一些具有重复性的 HTTP 请求,比如每次请求得到的数据都一样的,我们可以把这对「请求-响应」的数据都缓存在本地,那么下次就直接读取本地的数据,不必在通过网络获取服务器的响应了。
HTTP 缓存有两种实现方式,分别是强制缓存和协商缓存。
什么是强制缓存?
强缓存指的是只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边。
如下图中,返回的是 200 状态码,但在 size 项中标识的是 from disk cache,就是使用了强制缓存。

强缓存是利用下面这两个 HTTP 响应头部(Response Header)字段实现的,它们都用来表示资源在客户端缓存的有效期:
Cache-Control, 是一个相对时间;Expires,是一个绝对时间;
如果 HTTP 响应头部同时有 Cache-Control 和 Expires 字段的话,Cache-Control的优先级高于 Expires 。
Cache-control 选项更多一些,设置更加精细,所以建议使用 Cache-Control 来实现强缓存。具体的实现流程如下:
- 当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 Cache-Control,Cache-Control 中设置了过期时间大小;
- 浏览器再次请求访问服务器中的该资源时,会先通过请求资源的时间与 Cache-Control 中设置的过期时间大小,来计算出该资源是否过期,如果没有,则使用该缓存,否则重新请求服务器;
- 服务器再次收到请求后,会再次更新 Response 头部的 Cache-Control。
什么是协商缓存?
当我们在浏览器使用开发者工具的时候,你可能会看到过某些请求的响应码是 304,这个是告诉浏览器可以使用本地缓存的资源,通常这种通过服务端告知客户端是否可以使用缓存的方式被称为协商缓存。
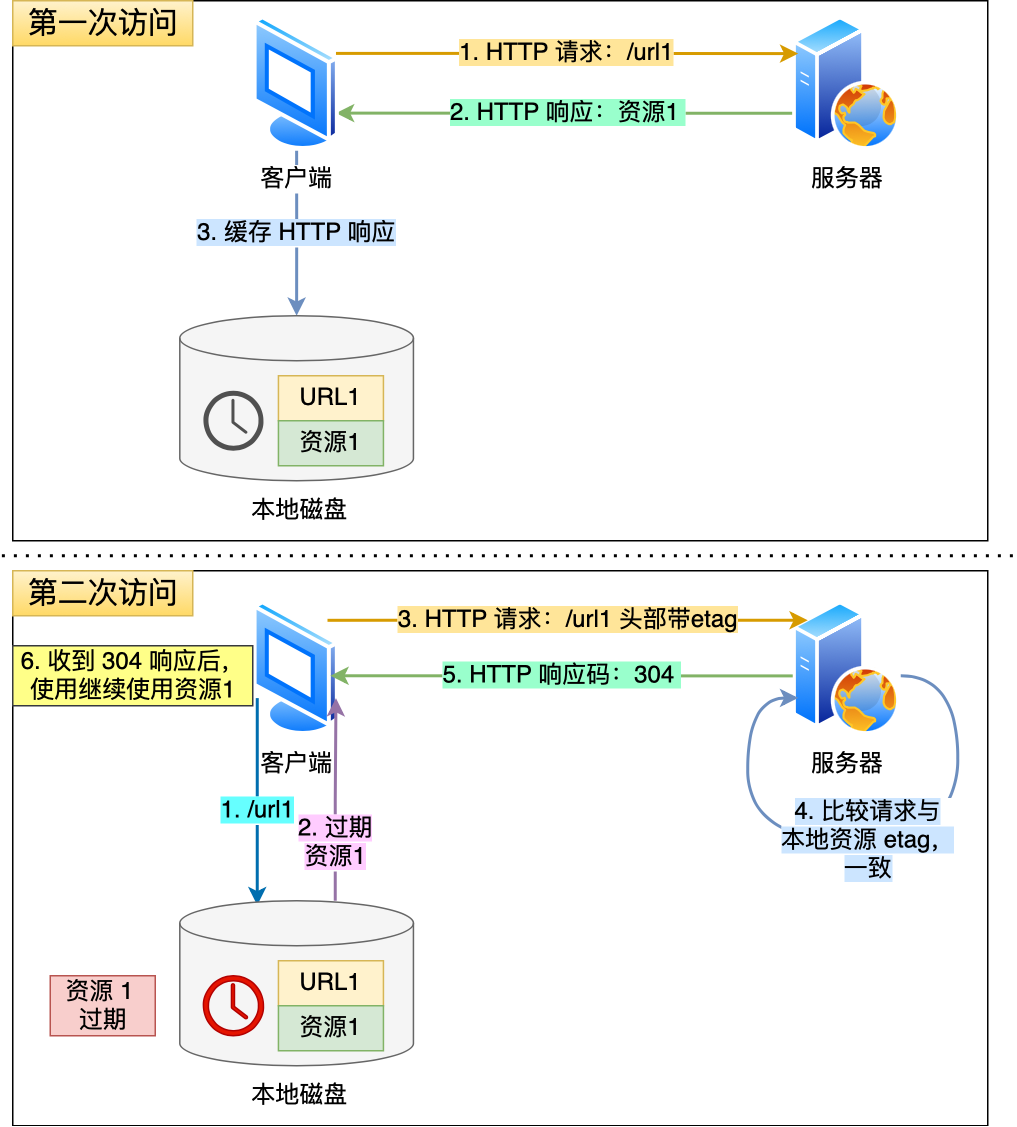
上图就是一个协商缓存的过程,所以协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。
协商缓存可以基于两种头部来实现。
第一种:请求头部中的 If-Modified-Since 字段与响应头部中的 Last-Modified 字段实现,这两个字段的意思是:
- 响应头部中的
Last-Modified:标示这个响应资源的最后修改时间; - 请求头部中的
If-Modified-Since:当资源过期了,发现响应头中具有 Last-Modified 声明,则再次发起请求的时候带上 Last-Modified 的时间,服务器收到请求后发现有 If-Modified-Since 则与被请求资源的最后修改时间进行对比(Last-Modified),如果最后修改时间较新(大),说明资源又被改过,则返回最新资源,HTTP 200 OK;如果最后修改时间较旧(小),说明资源无新修改,响应 HTTP 304 走缓存。
第二种:请求头部中的 If-None-Match 字段与响应头部中的 ETag 字段,这两个字段的意思是:
- 响应头部中
Etag:唯一标识响应资源; - 请求头部中的
If-None-Match:当资源过期时,浏览器发现响应头里有 Etag,则再次向服务器发起请求时,会将请求头If-None-Match 值设置为 Etag 的值。服务器收到请求后进行比对,如果资源没有变化返回 304,如果资源变化了返回 200。
第一种实现方式是基于时间实现的,第二种实现方式是基于一个唯一标识实现的,相对来说后者可以更加准确地判断文件内容是否被修改,避免由于时间篡改导致的不可靠问题。
如果 HTTP 响应头部同时有 Etag 和 Last-Modified 字段的时候, Etag 的优先级更高,也就是先会判断 Etag 是否变化了,如果 Etag 没有变化,然后再看 Last-Modified。
注意,协商缓存这两个字段都需要配合强制缓存中 Cache-control 字段来使用,只有在未能命中强制缓存的时候,才能发起带有协商缓存字段的请求。

使用 ETag 字段实现的协商缓存的过程如下;
-
当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 ETag 唯一标识,这个唯一标识的值是根据当前请求的资源生成的;
-
当浏览器再次请求访问服务器中的该资源时,首先会先检查强制缓存是否过期,如果没有过期,则直接使用本地缓存;如果缓存过期了,会在 Request 头部加上 If-None-Match 字段,该字段的值就是 ETag 唯一标识;
-
服务器再次收到请求后,
会根据请求中的 If-None-Match 值与当前请求的资源生成的唯一标识进行比较:
- 如果值相等,则返回 304 Not Modified,不会返回资源;
- 如果不相等,则返回 200 状态码和返回资源,并在 Response 头部加上新的 ETag 唯一标识;
-
如果浏览器收到 304 的请求响应状态码,则会从本地缓存中加载资源,否则更新资源。
参考资料:
OkHttp拦截器详解 - 简书 (jianshu.com)
[小林Coding](3.1 HTTP 常见面试题 | 小林coding (xiaolincoding.com))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号