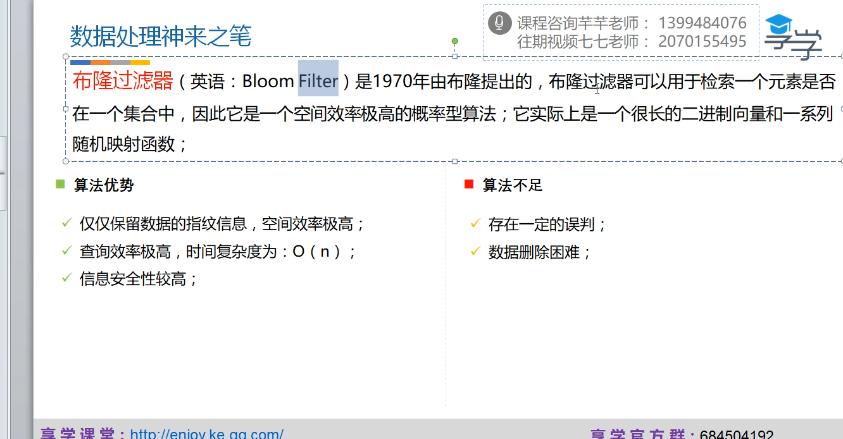
大数据判存算法:海量数据中快速判断某个数据是否存在
大数据判存算法:海量数据中快速判断某个数据是否存在

不存在的单号对应不到 相应的位置。例如 上图对应 3,7。虽然3是1,但是7不是1。所以它不存在。有误判的可能性,但是可以控制误判效率

50亿的快递,怎么判断我的快递存在吗?存在在哪家快递?
站在巨人的肩膀上,别重复造轮子了!Google Guava实现了布隆过滤器!
- 带你深入guava源码;
- 通过实战手把手教你布隆过滤器的使用;
源代码分析:

BitArray bits;比特数组
numHashFunctions : 哈希函数个数
put实现:
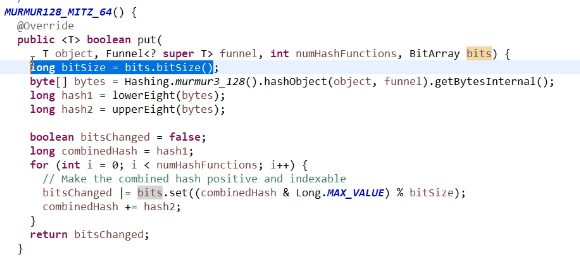
hash算法:用的murmur3_128。
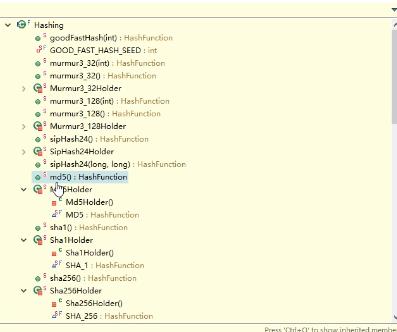
hash算法用很多,不同的有不同的场景:
murmur3:快速查询。
md5 : 信息摘要算法
crc:数字校验,数字签名
对得到的Hash进行计算,把得到的hash值分为几个计算单元,取模运算,找到对应上数组的位置。
应用:
在人群中找到嫌疑人。

错误率 太高 30%
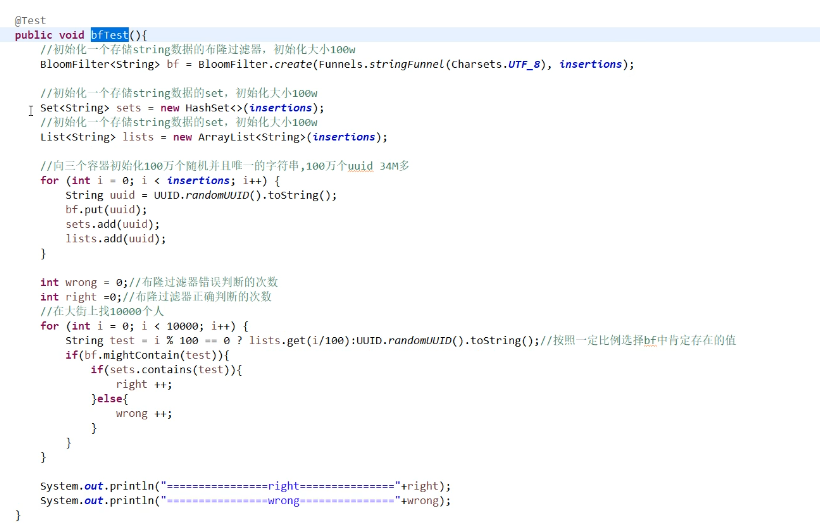
调试源码。
默认的错误率是 30% 经过google工程师大量的测试,要想控制在30%的错误率,100W 应该 使用 730W的数组。5个 hash 函数
BloomFilter 有三个参数(数据类型,数据大小,错误率)
我们把错误率设置为 0.01 那么需要 14377587个数组(自动分配),hash函数个数为10。
想要错误率低,查询效率低了,空间需要量比较大。
不能杜绝误判,可以控制误判
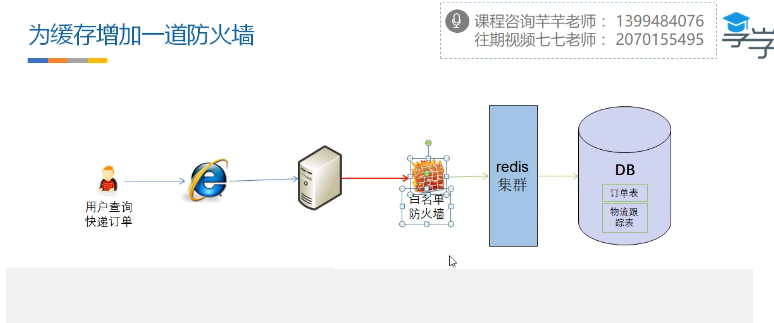
防火墙 不可能所有的都被拦截,有的请求会透过过滤器,落到数据库里面查询,只要别太多的数据使数据库挂掉就行。合理的控制错误率,不要使得数据库的算力被浪费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号