Linux三剑客 之 awk学习与应用
最近在调gps模块,要把代码里打印的NMEA的msg给抓出来,单独存在一个文件里,素来听闻awk的强大,这次打算借这个机会学习一波:
也就是说,大概是从下面这样的log中,过滤出$开头的所有行,并删除每一行前面的无关内容:
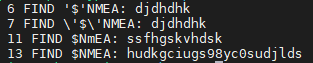
2019年 02月 28日 星期四 12:02:04 CST 2019年 03月 03日 星期日 22:39:29 CST hello sed hello sed test : djdhdhk test '$'NMEA: djdhdhk test \'$\'NMEA: djdhdhk $fjdshfkjhdjkf 896874h32gkjdsgfdsjf dfsdu09we7r8923ycdsioyv-92yhgfihdlvhd0f9vu $NmEA: ssfhgskvhdsk dfjskhvudisb hjksghfgjdhojfoh $NMEA: hudkgciugs98yc0sudjlds
要想完成这件事,需要掌握以下知识:
然后就是具体操作了:
awk '{for(i=1;i<NF;i++) {if($i ~ /\$/){ printf(" %s FIND %s %s\n",NR, $i, $(i+1)) } } }' log.txt
输出以下内容:
如果不想要行号和提示,则只需
awk '{for(i=1;i<NF;i++) {if($i ~ /\$/){ printf(" %s %s\n", $i, $(i+1)) } } }' log.txt
如果$后面有多个字段,我们都想输出出来,那么可以这样,因为代码稍长,我们写个awk脚本,然后在awk -f 指定这个脚本
#!/bin/awk
{
for(i=1;i<NF;i++) {
if($i ~ /\$/){
for(j=i;j<=NF;j++)
{ printf("%s ", $j) }
printf("\n")
break
}
}
}
使用的时候awk -f awk.txt log.txt 这样就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号