


GPU专栏(四) 基于块的渲染(Tile Based Rendering)
IMG使用了基于块的渲染管线,而且是更进一步,名为TBDR, 在这之前,我们先来了解一下TBR, 这些都是移动端GPU常用到的技术。
Q1:什么是TBR, 以及为什么要用TBR?
我觉得要回答这个问题,前提是要先了解一下,GPU的显存、GPU内部的on-chip color buffer, 以及系统内存之间的关系;
显存,类似于系统的内存,但它是显卡专用的内存。显存主要用来缓存 GPU 处理过的或者即将提取的渲染数据。显存主要包括容量、频率和位宽这三个参数。


带显存的GPU一般是桌面端PC专享,因为不需考虑功耗,可着高性能使劲造就行;也正是配合着支持大带宽的显存,桌面端才肆无忌惮的使用IMR技术。比如之前片元着色完成后,假设后面会有alpha blending, 那么就不可避免的会有大量的读改写过程。
for draw in renderPass: for primitive in draw: for vertex in primitive: execute_vertex_shader(vertex) for fragment in primitive: execute_fragment_shader(fragment)

所谓IMR就是,无脑对每一次drawcall都执行,这样的情况下,即使远处的物体被近处的物体覆盖而无法显示,但是还是会被过绘制,缺点是显而易见的,对gpu的性能可能带来不必要的浪费。
以往这些都是依赖消耗GPU大量的显存带宽来完成(上图中Framebuffer Working Set的部分),在移动端GPU中,显然不可能有这种享受。移动端GPU要考虑性能功耗的平衡,而且没有显存可用,只能和CPU共用系统内存,所以没办法,只能想办法优化。首先是硬件上搞了个片上内存,也就是IMG文档中的那个on-chip color buffer, 然后呢,这个片上内存显然不会很大,但是速度很快,比系统内存要快;基于这种特性,按照分块来处理着色过程就是很自然的想法了。首先是每个draw call,只执行vertex shader, 确定好图元的位置后,并不直接执行frag shader, 而是开始进行分块,也就是Tilling, tile大小大概是16x16, 然后呢,每个tile中会由一个list记录在此tile中的所有片元,所有的这些完成后才会进行光栅化以及进入frag shader的处理,然后frag shader就会遍历每个tile, 然后再对每个tile中的片元执行着色,以及做alpha blending等,所有这些都是在片上内存中完成的,减少了对系统内存的大量读写操作。最终所有tile处理完,才写入DDR中。这么一搞,就节省了系统带宽,降低了功耗而且减少了性能的浪费。上述过程对应的伪代码就是:
# Pass one for draw in renderPass: for primitive in draw: for vertex in primitive: execute_vertex_shader(vertex) append_tile_list(primitive) # Pass two for tile in renderPass: for primitive in tile: for fragment in primitive: execute_fragment_shader(fragment)
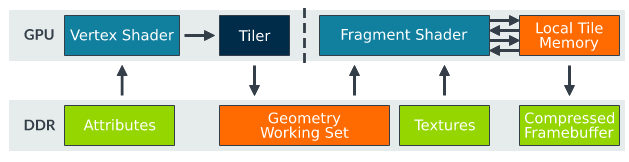
基于tile的渲染还可以结合FBC技术进一步压缩带宽【比如IMG的TFBC技术】,这大概也就是为什么你看到了IMG的FBC也是分块的原因吧。
当然,上述方式要说缺点也是有的,那就是增加了Geometry Working Set的开销,所以还是有关于权衡的艺术。


