
融汇贯通系列之--栈(二)实战巩固
上一章节中讲了不少理论,纸上得来终觉浅,绝知此事要躬行。今天我们就在arm-linux平台下,做一些测试,加深我们的理解。看看编译器是如何使用栈的。话不多说,上代码:
#include <stdio.h> int fun(int a, int b) { int c = 10; return c * (a + b); } int main() { int a1 = 10; int a2 = 10; char b = 'h'; int c[10]; int res = fun(a1, a2); printf("res = %d\n", res); return 0; }
对生成的可执行文件test_stack, 执行objdump -SD test_stack, 得到的反汇编的部分关键结果如下
00010440 <fun>: 10440: e52db004 push {fp} ; (str fp, [sp, #-4]!) 10444: e28db000 add fp, sp, #0 10448: e24dd014 sub sp, sp, #20 1044c: e50b0010 str r0, [fp, #-16] 10450: e50b1014 str r1, [fp, #-20] ; 0xffffffec 10454: e3a0300a mov r3, #10 10458: e50b3008 str r3, [fp, #-8] 1045c: e51b2010 ldr r2, [fp, #-16] 10460: e51b3014 ldr r3, [fp, #-20] ; 0xffffffec 10464: e0823003 add r3, r2, r3 10468: e51b2008 ldr r2, [fp, #-8] 1046c: e0030392 mul r3, r2, r3 10470: e1a00003 mov r0, r3 10474: e28bd000 add sp, fp, #0 10478: e49db004 pop {fp} ; (ldr fp, [sp], #4) 1047c: e12fff1e bx lr 00010480 <main>: 10480: e92d4800 push {fp, lr} 10484: e28db004 add fp, sp, #4 10488: e24dd038 sub sp, sp, #56 ; 0x38 1048c: e3a0300a mov r3, #10 10490: e50b3008 str r3, [fp, #-8] 10494: e3a0300a mov r3, #10 10498: e50b300c str r3, [fp, #-12] 1049c: e3a03068 mov r3, #104 ; 0x68 104a0: e54b300d strb r3, [fp, #-13] 104a4: e51b100c ldr r1, [fp, #-12] 104a8: e51b0008 ldr r0, [fp, #-8] 104ac: ebffffe3 bl 10440 <fun> 104b0: e50b0014 str r0, [fp, #-20] ; 0xffffffec 104b4: e51b1014 ldr r1, [fp, #-20] ; 0xffffffec 104b8: e59f0010 ldr r0, [pc, #16] ; 104d0 <main+0x50> 104bc: ebffff89 bl 102e8 <printf@plt> 104c0: e3a03000 mov r3, #0 104c4: e1a00003 mov r0, r3 104c8: e24bd004 sub sp, fp, #4 104cc: e8bd8800 pop {fp, pc} 104d0: 00010544 andeq r0, r1, r4, asr #10
// 从上main反汇编结果中可以看到fp对一个函数还是很重要的,因为这个函数中的局部变量基本上都是靠fp+偏移量来索引的,所以一旦发生函数跳//转的时候,是需要把当前的老的fp先压栈保存,后面函数返回的时候还能接着恢复原先的fp, 要不然局部变量岂不是全乱套了。
先从main函数看起,进入main函数的时候,先执行了push {fp, lr} 这个是把当前fp寄存器和lr寄存器的内容压栈,这也意味着它俩是在main返回之前要恢复的内容。然后是add fp,sp, #4 意思是fp = sp + 4. 这个地方是啥意思呢,刚刚不是才入栈吗。是这样的,刚才只是保存它,但是我们还是要用fp来索引各个局部变量啊后面,所以刚才push完事后,sp 指向的是lr, sp + 4正好是fp.
然后是sub sp, sp, #56 这个比较明显,把sp指针-56, 我们这里记得arm是满减栈,这里先一下子划走了一部分空间,sp指向栈顶,那么现在开始,fp到sp之间的这段空间就是main函数的活动记录。这里我们来算一下main里面局部变量占用的size:
3 * sizeof(int) + sizeof(char) + 10 * sizeof(int) = 53,奇怪了,为啥这里是56呢。我们先往下看:
1048c: e3a0300a mov r3, #10 10490: e50b3008 str r3, [fp, #-8] 10494: e3a0300a mov r3, #10 10498: e50b300c str r3, [fp, #-12] 1049c: e3a03068 mov r3, #104 ; 0x68
104a0: e54b300d strb r3, [fp, #-13]
r3 = 10, 然后str r3, [fp, #-8] 是把r3的内容存到fp-8的地址中,正好是main函数活动记录中的第一个有效的空间, strb是一个Byte的str, 正好对应我们的char类型。刚才我们算的是53,实际上是56,所谓我合理猜测,那个char在栈中也是占了4个字节,可能是有对齐的原因在里面吧。做了一个简单的实验验证了我的猜想。令c[0] = 0, c[9] =0; 然后再反汇编就可以大概清楚整个栈的分布如下:
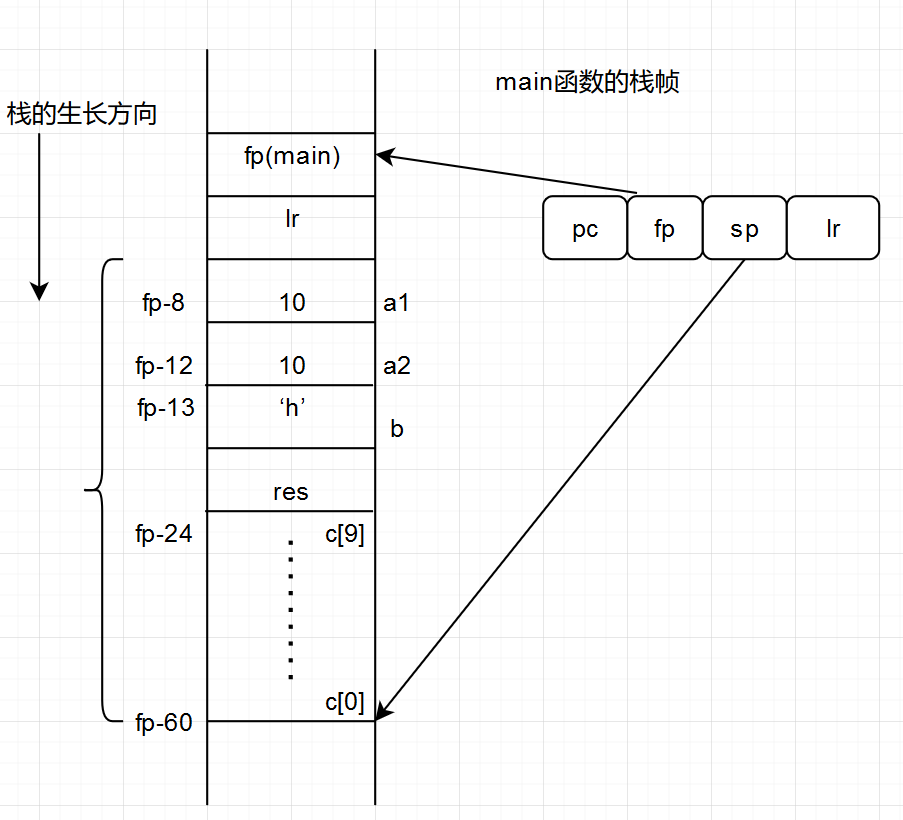
然后就是调用fun的环节了,可以看到
104a4: e51b100c ldr r1, [fp, #-12] 104a8: e51b0008 ldr r0, [fp, #-8] 104ac: ebffffe3 bl 10440 <fun>
这里可以明显的看到参数是从右往左load到r1, r0的,这里竟然不是压栈,看来可能是因为传的参数不够大,编译器把参数优化到cpu寄存器里去了。然后就是一个bl 10400 跳到了fun的地盘。到了fun的地盘,栈又要开始生长了。
10440: e52db004 push {fp} ; (str fp, [sp, #-4]!) 10444: e28db000 add fp, sp, #0 10448: e24dd014 sub sp, sp, #20
1044c: e50b0010 str r0, [fp, #-16]
10450: e50b1014 str r1, [fp, #-20] ; 0xffffffec
首先是fp压栈,这里压的是main的fp, 然后是fp = sp + 0; 这个fp就是fun自己的fp了,然后是sp = sp - 20;
这两步执行完,fp寄存器指向了新的位置,sp也指向了新的位置。这里有点奇怪的是fun的栈竟然有20个Byte?
可是我们明明只有一个int c啊?带着这个疑问继续往下跟:
10454: e3a0300a mov r3, #10 10458: e50b3008 str r3, [fp, #-8] 1045c: e51b2010 ldr r2, [fp, #-16] 10460: e51b3014 ldr r3, [fp, #-20] ; 0xffffffec 10464: e0823003 add r3, r2, r3 10468: e51b2008 ldr r2, [fp, #-8] 1046c: e0030392 mul r3, r2, r3 10470: e1a00003 mov r0, r3 10474: e28bd000 add sp, fp, #0 10478: e49db004 pop {fp} ; (ldr fp, [sp], #4) 1047c: e12fff1e bx lr
可以看到,fun一开始是把r0, r1的值压倒自己的栈中,这一步其实就是把函数的参数入栈,然后后面是把栈中的参数再ldr到r2,r3寄存器中,
再然后就是用add,mul完成运算,最终的结果存在r0中。再往后就是sp = fp + 0; 这一步很猛。sp的值现在变成了fp,也就是说sp现在指向的位置是fun的栈帧的基地址,然后后面的连招是pop {fp}, 好家伙,这个是把sp当前指向的地址的内容pop出来给到fp志存器,也就是现在fp又变回指向main的栈帧的基地址了,同时由于pop, sp还要再-4。最后是bx lr, PC跳转到bl之后的位置继续运行,这么一搞,我们就又回到了main作用域内。下面通过一张图来形象的表达这个阶段:

回到main的世界后,我们继续往下看:
104b0: e50b0014 str r0, [fp, #-20] ; 0xffffffec 104b4: e51b1014 ldr r1, [fp, #-20] ; 0xffffffec 104b8: e59f0010 ldr r0, [pc, #16] ; 104d0 <main+0x50> 104bc: ebffff89 bl 102e8 <printf@plt> 104c0: e3a03000 mov r3, #0 104c4: e1a00003 mov r0, r3 104c8: e24bd004 sub sp, fp, #4 104cc: e8bd8800 pop {fp, pc} 104d0: 00010544 andeq r0, r1, r4, asr #10
还记得前面res的位置是fp - 20吗,以及fun函数中把返回值存在了r0里面,这里就是先把r0的内容存到fp -20 的位置,然后后面就是调用printf之前先把res给ldr到r1中,然后呢,是把pc + 16的这个地址给 ldr到r0。
//这里有个知识点,pc + 16是如何等于104d0的?
其实是流水线导致的,当指令执行到ldr r0, [pc, #16]时,pc的值要超前这个指令的地址应该是+8
也就是说虽然当前的指令的地址是104b8, 但是pc是104b8 + 8,然后再加上16就正好是104d0了。
原因就在于arm的三级流水线架构,也就是说pc指向的是取指令的地址,pc-4是解码的地址,pc-8是执行的地址。
再然后就是bl到printf处执行;
000102e8 <printf@plt>: 102e8: e28fc600 add ip, pc, #0, 12 //ip = pc+0x00>>12 102ec: e28cca10 add ip, ip, #16, 20 ; 0x10000 102f0: e5bcfd1c ldr pc, [ip, #3356]! ; 0xd1c
这一块有点难啃,涉及系统调用和动态库,我们放到后面去看。


