哈夫曼编码的一个实际应用
1|0介绍:
本问题是来自于课堂上老师关于贪心问题的第三讲.Huffman编码是最有效的二进制编码,其中贪心策略主要体现在根据频度来设置编码长度.最早在数据结构的便有学习到,当时采用的建树方式是带指针的结构体+小顶堆(使用小顶堆的优势在于堆是动态的,同时也有较高的效率——插入和删除并调整的效率约为O(lgN),查找最小的效率为O(1)),从理论上来说也是比较容易理解的.然而在一般的做题中我们实际只需要用数组模拟即可(好吧,其实也是因为没有学过c++里的堆模板).比较惭愧的是好久没写建树相关的内容了,差点不会写了,因此这里记录一下.
2|0来源
3|0Description
4|0Input
5|0Output
6|0Sample Input
7|0Sample Output
8|0分析问题:
-
哈夫曼编码介绍
-
有以下一串字符编码:
11233324234我们需要对其进行二进制(因为哈夫曼编码就是一种二进制编码,依据老师的表述,如果去掉这一限制就很难称得上说有最好的编码了)压缩以使最后获得编码最小.
-
显然,基本的编码策略是针对不同的字符进行不同的编码压缩,让我们列出它们的种类和频度(这一字符在语句出现的次数)来进行比较一下,对于这个集合我们可以称为字典(包含了所有的字符):
序号 字符 频度 1 1 2 2 2 3 3 3 4 4 4 2 -
首先,我们需要建立对应的数学模型.设总的编码长度为wpl,每个字符的编码长度为,每个字符的频度(也就是权值)为,则(0<=k<=字符的个数),其中是确定的,为了使wpl最小,当比较大的时候,我们需要使尽量小.具体的解决思路便是贪心
-
贪心:每次我们取出两个最小的点,用这两个节点合并成为新的节点,新节点的权重是子节点的权重之和,如此反复直到只有一个子结点就构建了一个一棵树,我们称为哈夫曼树.
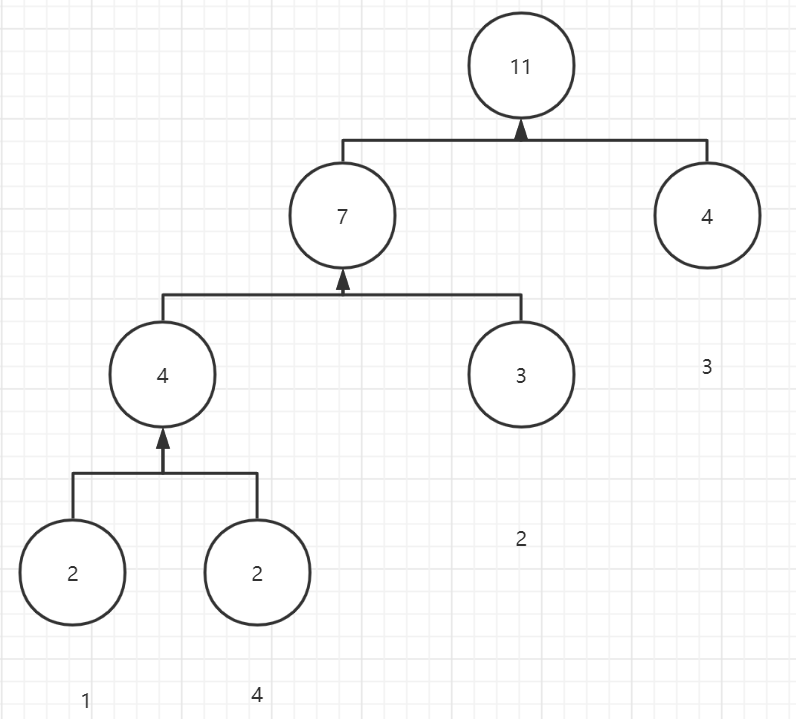
注:圆内的权重,圆外是对应字符
可以看到该树有一下几个特点:
- 是一棵二叉树且没有度为1的节点
- n个字符节点均为叶节点.由于我们每次总是去掉2个结点,增加一个节点直到最后生成的一个节点,所以最后会产生n-1个结点,共2n-1个结点
-
依据要求,关于编码我们可以确立两个基本的准则:
-
这个编码应该越简单越好
-
为了便于解析以及不引起混淆,一个编码不应该是另一个编码的前缀和
如对于:0,01这两个编码显然是无效的.
-
-
基于霍夫曼树,我们只要对树的左右边进行标号即可——左0右1或者左1右0,由此我们可以得出霍夫曼编码的另一个特定是不唯一.最终的编码(以左0右1为例):
序号 符号 Huffman编码 1 1 000 2 2 01 3 3 1 4 4 001
注:有时对于同一个字典可以构造不同形式的Huffman(如频度相同的字典),也就是异构的.
-
-
Huffman构造
- 数据结构:结构体数组,因为这里我们在意的仅仅是节点之间的父子关系,使用对应的属性记录即可.
- 求取最小值与倒数第二小的值:由于整道题的数据范围并不大,每一轮我们可以遍历一次,先判断当前数是不是小于最小值,如果小于,先将最小值赋值给倒数第二小的值,再将当前遍历到的值赋给最小值,否则将当前遍历到的值赋给倒数第二小的值.
-
解码
-
将原数据的十六进制编码转化为二进制编码:这里看到老师巧妙地使用了这个数组:
-
转码:使用一个map,另外还有一个无法判断非法编码的问题,我们可以通过编码的最大长度进行判定.
-
-
扩展
-
有损压缩与无损压缩
无损压缩:如Huffman编码
有损压缩:如常见的mp4,mp3,牺牲了一些人耳不太敏感的频段.
-
注:由于写完已经错过了交题的时间,代码只通过了样例,恐怕还有些细节性的问题(对于这点我应该很有信心!!!)
注(11.25):代码已更新,因为没有去掉调试的两个内容导致错了好几发,最后还是提交成功了,但是之所以能ac的原因个人推测还是老师数据太弱了!
__EOF__
本文链接:https://www.cnblogs.com/Arno-vc/p/14013034.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix