python学习第十四节(正则)
python2和python3都有两种字符串类型
str
bytes
re模块
find一类的函数都是精确查找。
字符串是模糊匹配
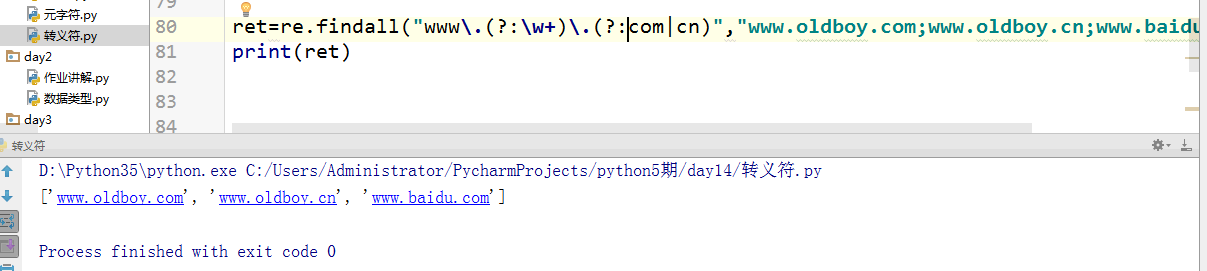
findall(pattern,string,flags)

replace函数
'hello python'.replace('p','P')
'hello Python'
a='sadfadf232wwewfr323rwef34534trwef'
import re
w=re.findall('\d','sadfadf232wwewfr323rwef34534trwef')
w=re.findall('\d+','sadfadf232wwewfr323rwef34534trwef')
print(w)
re.findall 将所有符合规则的结果保存到一个列表里。
re.findall(pattern,string)
key: 元字符 (有特殊功能的字符)
通配符:
. 点 能匹配任何一个除换行符以外的符号,也就是说点能代表任何符号。
* [0,+00] 0到无穷次的范围
+ [1,+00] 1到无穷次的范围
? [0,1] 0个或1个
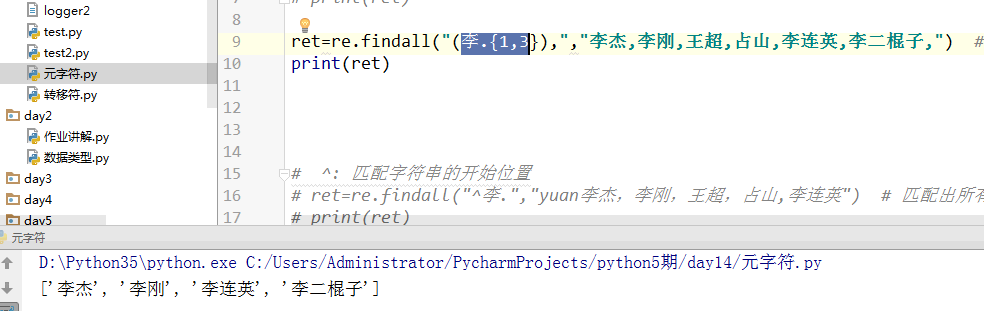
{} {n,m} 可以写{3,5} 3到5个 也可以写{3} 3个 ,也可以写{0,} 无穷次的意思

字符集:
[] 用法,re.findall("a[bd]c","safasdfaefsdf") 里面[bd]是或者的关系,或者是b或者是d 都显示出来
如果[]中加了标点符号,标点符号和字母是同级别的 过滤的是a,b等内容。
[] 中如果加上通配符,那么并没有通配符的意义,只是匹配相关符号内容的东西
[0-9] 只是匹配一个数字,如果需要找4位的数字,[0-9]{4}
[] 字符集中 有特殊意义的字符为: - ^ \
^ 开始匹配
$ 结尾匹配
():分组

(ad) 匹配这个组
(ad)+yuan 图中下面这个匹配的是蓝色内容,但是分组优先显示()分组内的内容,所以结果是ad
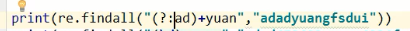
如上图所示,可以取消()的优先级,将蓝色内容打印出来,?:这个语法就是取消优先级,不光显示分组,还可以显示其他内容。

如上图,该打印出的内容为3,因为数字很多,匹配到的是yuan,但是显示分组内容3
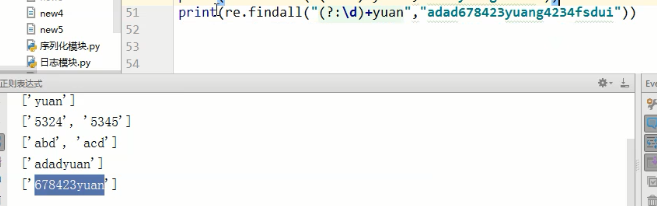
取消分组特性
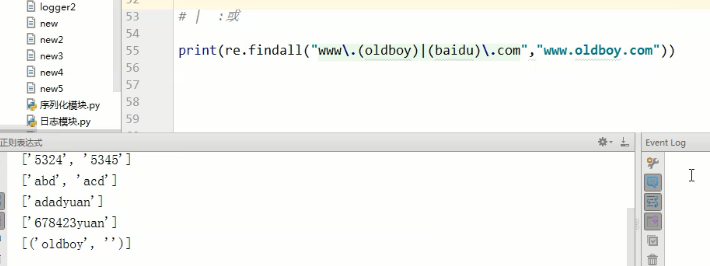
如上图,|是或的意思
如果或后面没有匹配到则显示空。
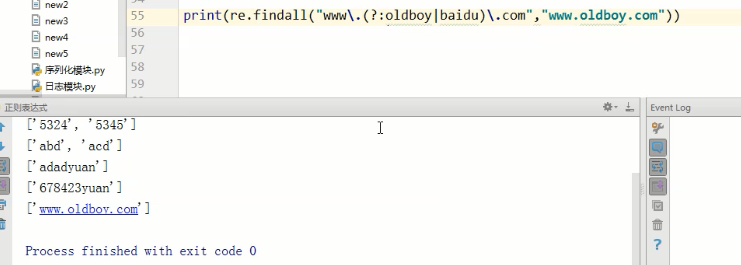
如上图,上面这种可以直接匹配出网址。
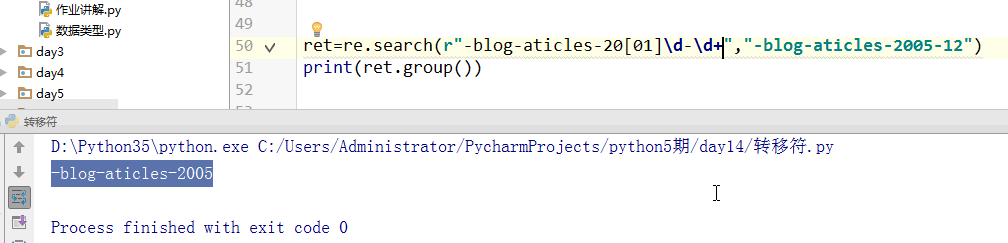
\ 转译,能将字母转译成特殊意义,也能将特殊意义的字符转移成普通字符
\d 代表0-9的任意一个字符
\w 代表任意数字或字母的字符
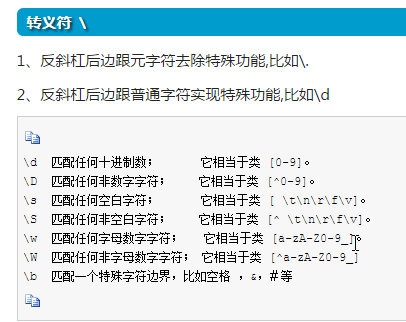
\. 点变成普通符号
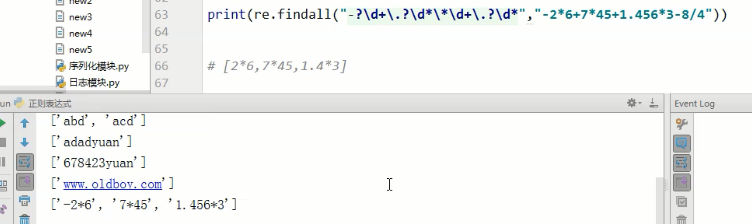
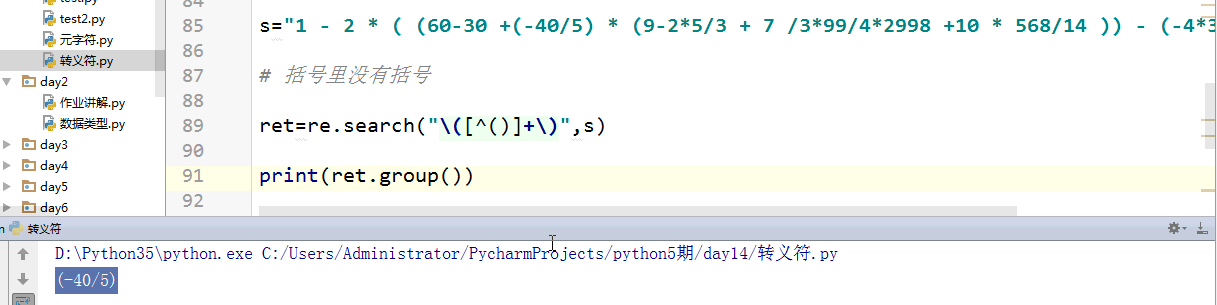
复杂一点的

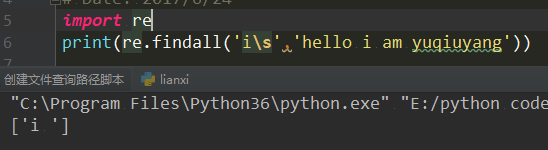
\s 取出来有个空格
search方法
找到一个对应的就不再向后匹配

match方法
只匹配开头,如果开头没有则返回None
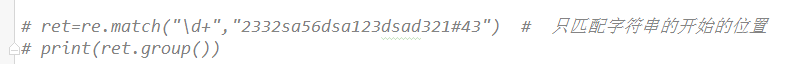
作业
分组给组起名字,根据名字来取内容

字符集中可以用的特殊符号
|管道符