python爬取京东商品评论
可爬取的内容
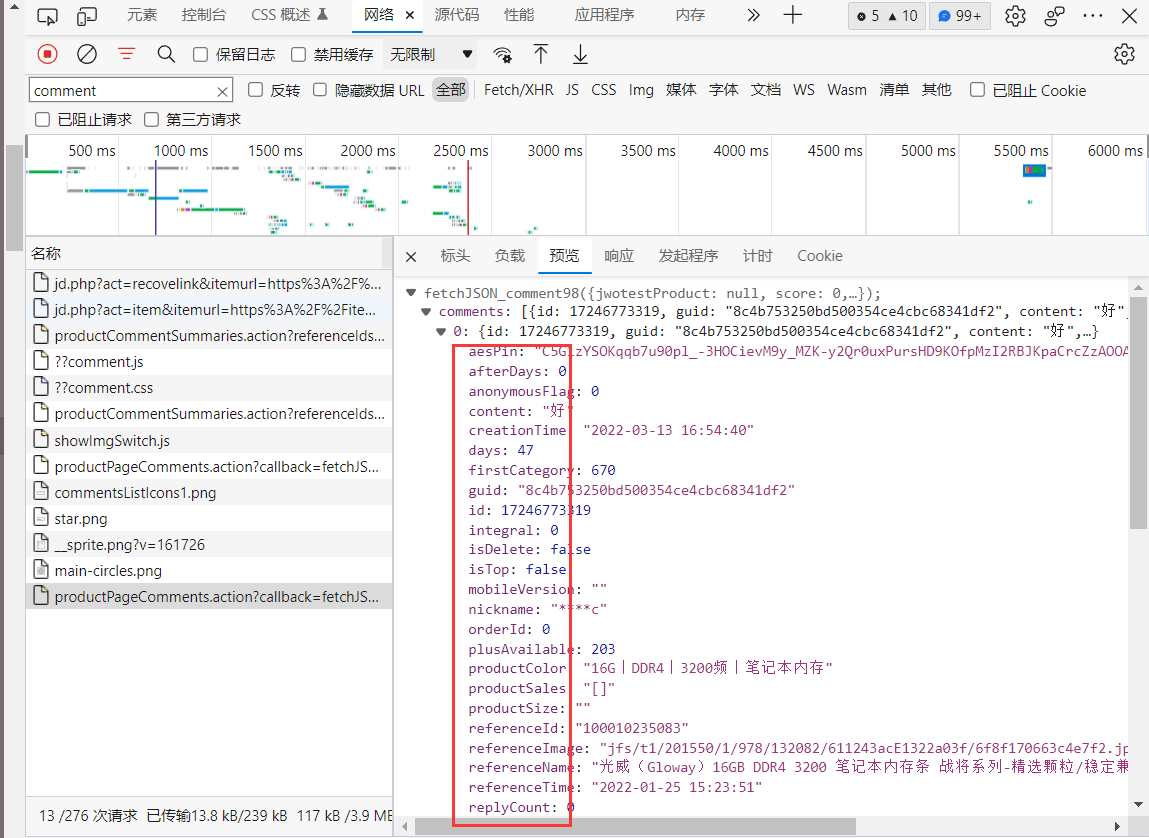
上代码
import requests import json import csv from lxml import etree from bs4 import BeautifulSoup import time ''' #如果ip被封,可以使用这个进行ip设置 proxy ='114.239.148.103' proxies={ 'http':'http://'+proxy, 'https':'https://'+proxy, } ''' comment_url = 'https://sclub.jd.com/comment/productPageComments.action?callback' # 获取评论 def get_comment(productid, name): headers = { # 'cookie': 'shshshfpa=4e6c0f90-587c-a46f-5880-a7debd7d4393-1544616560; __jdu=1126324296; PCSYCityID=412; user-key=44089d07-befa-4522-87fc-bcc039ec7045; pinId=qopcdCj6kcR3U84v0KTTbrV9-x-f3wj7; pin=jd_769791719e9e9; unick=jd_769791719e9e9; _tp=nc%2FbpB%2BkeSbk3jZ6p2H0FlWrdUa1gbgi16QiQ7NBXKY%3D; _pst=jd_769791719e9e9; cn=9; ipLoc-djd=1-72-2799-0; mt_xid=V2_52007VwMSUVpaUV8cQR5sUWMDEgUIUVBGGEofWhliABNUQQtQWkpVHVVXb1ZGB1lYW11LeRpdBW4fElFBW1VLH0ESXgJsAhpiX2hSahxLGFsFZwcRUG1bWlo%3D; shshshfpb=bRnqa4s886i2OeHTTR9Nq6g%3D%3D; unpl=V2_ZzNtbUZTSxJ3DURTLk0LAmJXFVlKAkdAIQ1PUXseCVIzU0UKclRCFXwURldnGlUUZwcZXERcQRdFCHZXchBYAWcCGllyBBNNIEwHDCRSBUE3XHxcFVUWF3RaTwEoSVoAYwtBDkZUFBYhW0IAKElVVTUFR21yVEMldQl2VHsaWwdkBhFVRWdzEkU4dl17HVwDYDMTbUNnAUEpAUJRfRpcSGcDEVpAVEYWfQ92VUsa; __jda=122270672.1126324296.1544405080.1545968922.1545980857.16; __jdc=122270672; ceshi3.com=000; TrackID=11EpDXYHaqwJE15W6paeMk_GMm05o3NUUeze9XyIcFs33GGxX8knxMpxWTeID75qSiUlj31s8CtKJs4hJUV-7CvKuiOEyDd8bvOCH7zzigeI; __jdv=122270672|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_55963436def64e659d5de48416dfeaff|1545980984854; 3AB9D23F7A4B3C9B=OA3G4SO3KYLQB6H3AIX36QQAW34BF376WJN66IUPEQAG6FUA2NWGM6R6MBDL32HLDG62WL2FICMYIVMOU6ISUWHKPE; shshshfp=1ed96ad08a7585648cd5017583df22bd; _gcl_au=1.1.162218981.1545981094; JSESSIONID=305879A97D4EA21F4D5C4207BB81423F.s1; shshshsID=c8c51ee0c5b1ddada7c5544abc3eea8a_5_1545981289039; __jdb=122270672.11.1126324296|16.1545980857; thor=3A30EBABA844934A836AC9AA37D0F4B85306071BD7FC64831E361A626E76F6977EC7794D06F2A922AEABF7D3D7DC22FBE2EB6B240F81A13F5A609368D4185BA0081D7C34A93760063D2F058F5B916835B4960EC8A9122008745971D812BA9E4AE48542CCC5A42E5CD786CC93770E520E36F950614C06A7EB05C8E1DD93EEA844B2EBA9B0136063FCFB6B7C83AECA828774041A9FED7BD98496689496122822FF', "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36", "Referer": "https://item.jd.com/%s.html" % (productid) } for i in range(300): # 此处设置爬取几页的评论 page = i params = { "productId": 100010235083, # 商品id 'score': 0, # 如果想要爬取全部评论设置为0,好评为3,中评为2,差评为1,晒图评价为4,追评为5 'sortType': 5, 'page': page, 'pageSize': 10, } comment_resp = requests.get(url=comment_url, params=params, headers=headers) comment_str = comment_resp.text if comment_str == '': print("获取内容为空") comment_dict = json.loads(comment_str) comments = comment_dict['comments'] load(comments, name, productid) # 数据存储 def load(comments, name, productid): for comment in comments: nickname = comment['nickname'] content = comment['content'].replace('\n', '').replace('\r', '') g_uid = comment['guid'] creationTime = comment['creationTime'] is_Top = comment['isTop'] plus = comment['plusAvailable'] referenceTime = comment['referenceTime'] score = comment['score'] days = comment['days'] is_Mobile = comment['userClient'] if(is_Top == False): is_Top = "非置顶" else: is_Top = "置顶" if(is_Mobile == 2): is_Mobile = "IOS客户端" elif (is_Mobile == 0): is_Mobile = "PC端" elif(is_Mobile == 4): is_Mobile = "Android客户端" if(plus == 201): plus = "PLUS会员" else: plus = "非会员" test = g_uid \ + '\t' + nickname \ + '\t' + content \ + '\t' + str(score) \ +'\t' + creationTime \ + '\t' + str(is_Top) \ + '\t' + plus \ + '\t' + referenceTime \ + '\t' + str(days) \ + '\t' + is_Mobile # print(infor) with open('C:/Users/wuhao/Desktop/JD评论/' + '%s' % (name) + '.csv', 'a', newline='')as csv_file: text = [] text.append(test) writer = csv.writer(csv_file) writer.writerow(text) # 获取搜索商品名界面的每个商品的序号 def get_number(name): headers = { 'cookie': 'shshshfpa=4e6c0f90-587c-a46f-5880-a7debd7d4393-1544616560; __jdu=1126324296; PCSYCityID=412; user-key=44089d07-befa-4522-87fc-bcc039ec7045; pinId=qopcdCj6kcR3U84v0KTTbrV9-x-f3wj7; pin=jd_769791719e9e9; unick=jd_769791719e9e9; _tp=nc%2FbpB%2BkeSbk3jZ6p2H0FlWrdUa1gbgi16QiQ7NBXKY%3D; _pst=jd_769791719e9e9; cn=9; ipLoc-djd=1-72-2799-0; mt_xid=V2_52007VwMSUVpaUV8cQR5sUWMDEgUIUVBGGEofWhliABNUQQtQWkpVHVVXb1ZGB1lYW11LeRpdBW4fElFBW1VLH0ESXgJsAhpiX2hSahxLGFsFZwcRUG1bWlo%3D; shshshfpb=bRnqa4s886i2OeHTTR9Nq6g%3D%3D; unpl=V2_ZzNtbUZTSxJ3DURTLk0LAmJXFVlKAkdAIQ1PUXseCVIzU0UKclRCFXwURldnGlUUZwcZXERcQRdFCHZXchBYAWcCGllyBBNNIEwHDCRSBUE3XHxcFVUWF3RaTwEoSVoAYwtBDkZUFBYhW0IAKElVVTUFR21yVEMldQl2VHsaWwdkBhFVRWdzEkU4dl17HVwDYDMTbUNnAUEpAUJRfRpcSGcDEVpAVEYWfQ92VUsa; __jda=122270672.1126324296.1544405080.1545968922.1545980857.16; __jdc=122270672; ceshi3.com=000; TrackID=11EpDXYHaqwJE15W6paeMk_GMm05o3NUUeze9XyIcFs33GGxX8knxMpxWTeID75qSiUlj31s8CtKJs4hJUV-7CvKuiOEyDd8bvOCH7zzigeI; __jdv=122270672|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_55963436def64e659d5de48416dfeaff|1545980984854; 3AB9D23F7A4B3C9B=OA3G4SO3KYLQB6H3AIX36QQAW34BF376WJN66IUPEQAG6FUA2NWGM6R6MBDL32HLDG62WL2FICMYIVMOU6ISUWHKPE; shshshfp=1ed96ad08a7585648cd5017583df22bd; _gcl_au=1.1.162218981.1545981094; JSESSIONID=305879A97D4EA21F4D5C4207BB81423F.s1; shshshsID=c8c51ee0c5b1ddada7c5544abc3eea8a_5_1545981289039; __jdb=122270672.11.1126324296|16.1545980857; thor=3A30EBABA844934A836AC9AA37D0F4B85306071BD7FC64831E361A626E76F6977EC7794D06F2A922AEABF7D3D7DC22FBE2EB6B240F81A13F5A609368D4185BA0081D7C34A93760063D2F058F5B916835B4960EC8A9122008745971D812BA9E4AE48542CCC5A42E5CD786CC93770E520E36F950614C06A7EB05C8E1DD93EEA844B2EBA9B0136063FCFB6B7C83AECA828774041A9FED7BD98496689496122822FF', "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36", } response = requests.get("https://search.jd.com/Search?keyword=%s&enc=utf-8" % (name), headers=headers) html = BeautifulSoup(response.text, 'lxml') list = html.find_all("li", class_='gl-item') numbers = [] for number in list: numbers.append(int(number.get("data-sku"))) return numbers def main(): get_comment(100010235083, "光威(Gloway)16GB DDR4 3200 笔记本内存条 ") #time.sleep(0.5) print("爬取完毕") main()
经过本人的实验,虽然京东评论现在不直接显示来自哪种客户端,但userclient为0代表网页端,2代表IOS端,4代表Android端
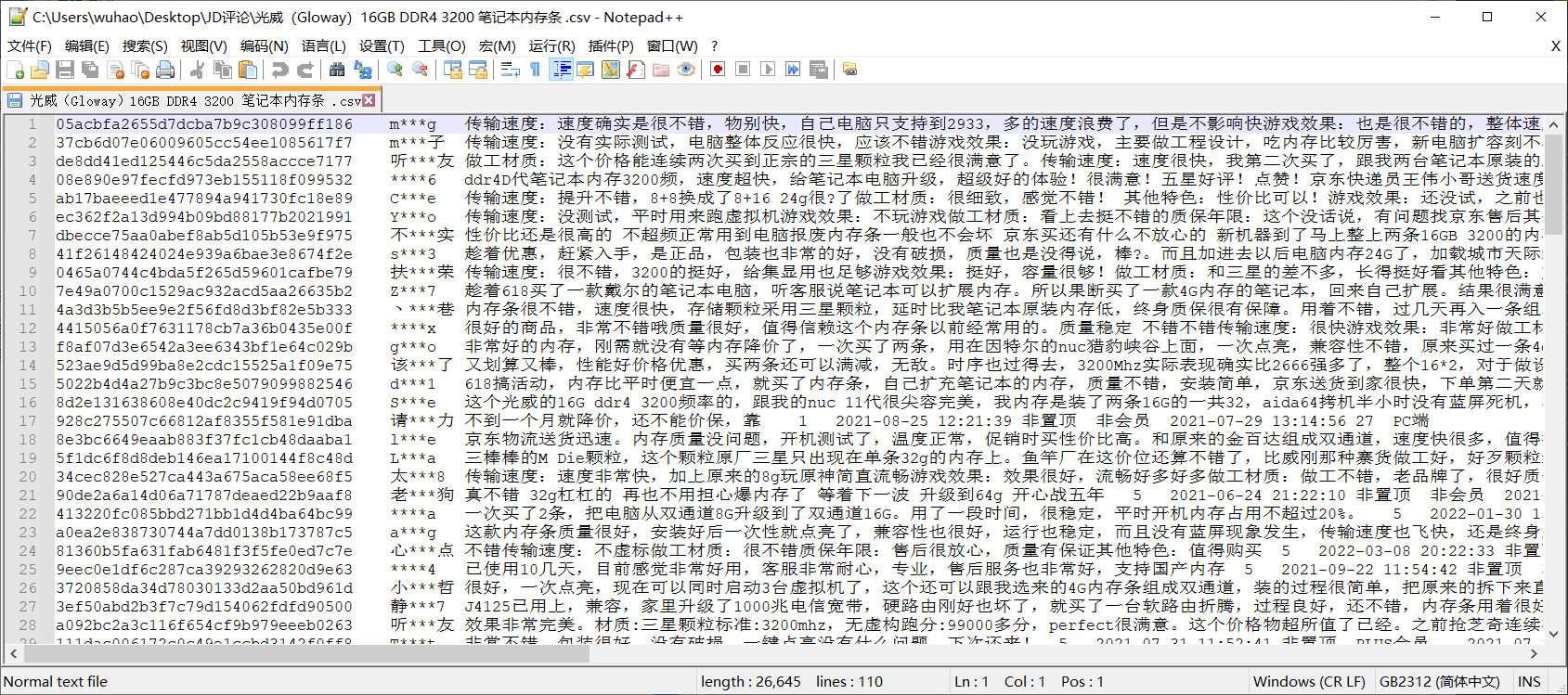
效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号