观影大数据分析(中)
6.Json数据转换
**说明:**genres,keywords,production_companies,production_countries,cast,crew 这 6 列都是 json 数据,需要处理为列表进行分析。 处理方法: json 本身为字符串类型,先转换为字典列表,再将字典列表转换为,以’,'分割的字符串
#Json格式处理 json_column = ['genres', 'keywords', 'production_companies', 'production_countries', 'cast', 'crew'] # 1-json本身为字符串类型,先转换为字典列表 for i in json_column: df[i] = df[i].apply(json.loads) # 提取name # 2-将字典列表转换为以','分割的字符串 def get_name(x): return ','.join([i['name'] for i in x]) df['cast'] = df['cast'].apply(get_name) # 提取derector def get_director(x): for i in x: if i['job'] == 'Director': return i['name'] df['crew'] = df['crew'].apply(get_director) for j in json_column[0:4]: df[j] = df[j].apply(get_name) # 重命名 rename_dict = {'cast': 'actor', 'crew': 'director'} df.rename(columns=rename_dict, inplace=True) df.info() print(df.head(5).genres) print(df.head(5).keywords) print(df.head(5).production_companies) print(df.head(5).production_countries) print(df.head(5).actor) print(df.head(5).director)
运行结果


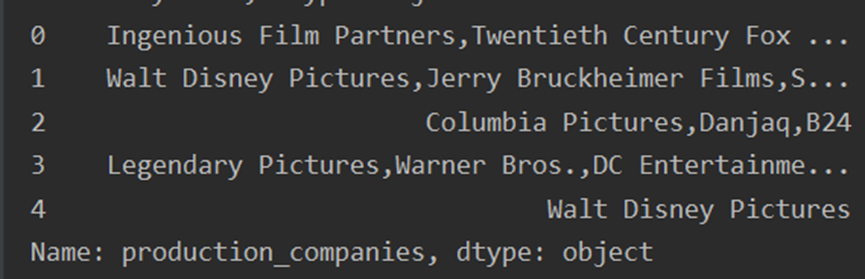

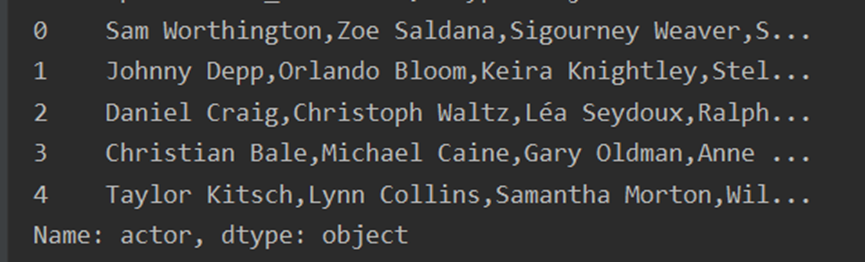
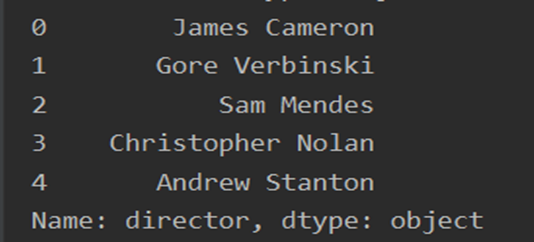
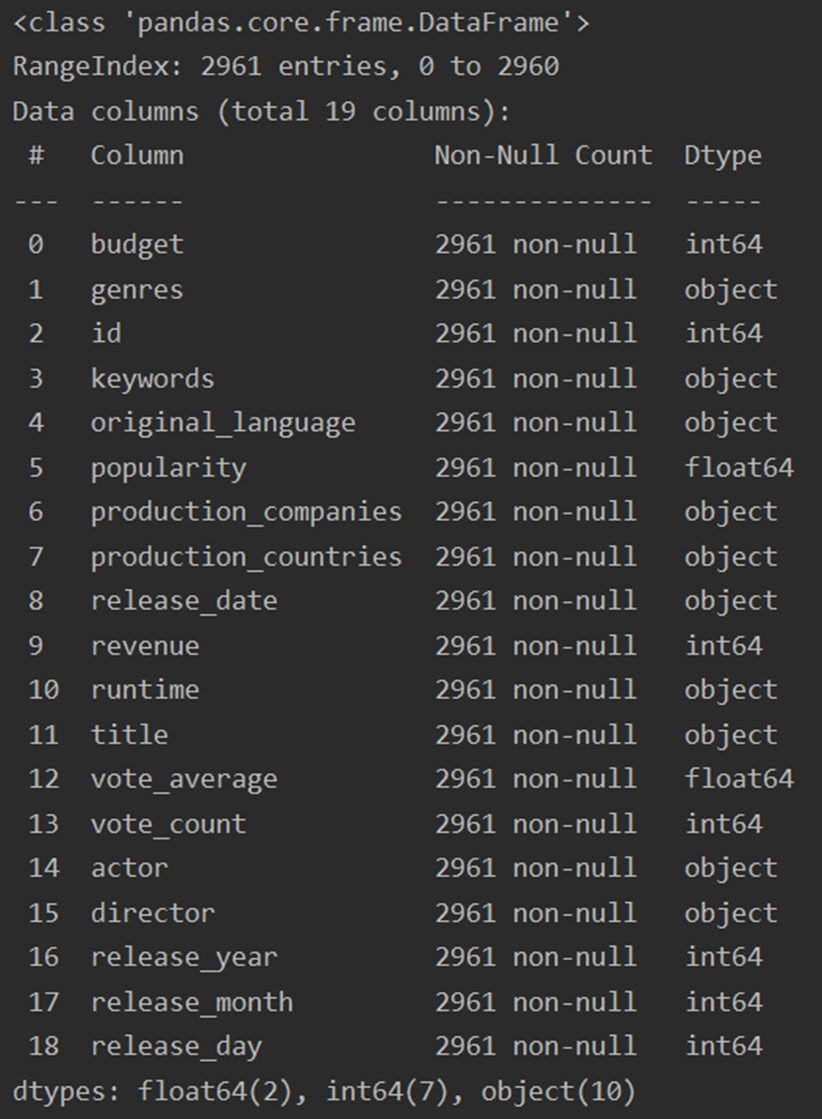
7.数据备份
#数据备份 org_df = df.copy() df.reset_index().to_csv("TMDB_5000_Movie_Dataset_Cleaned.csv")
数据预处理阶段完成
————————————————————————————————————————————————————————————————
8.数据分析
8.1 Why
想要探索影响票房的因素,从电影市场趋势,观众喜好类型,电影导演,发行时间,评分与 关键词等维度着手,给从业者提供合适的建议
8.2 What
8.2.1 电影类型:定义一个集合,获取所有的电影类型
# 定义一个集合,获取所有的电影类型 genre = set() for i in df['genres'].str.split(','): # 去掉字符串之间的分隔符,得到单个电影类型 genre = set().union(i,genre) # 集合求并集 # genre.update(i) #或者使用update方法 print(genre)
运行结果

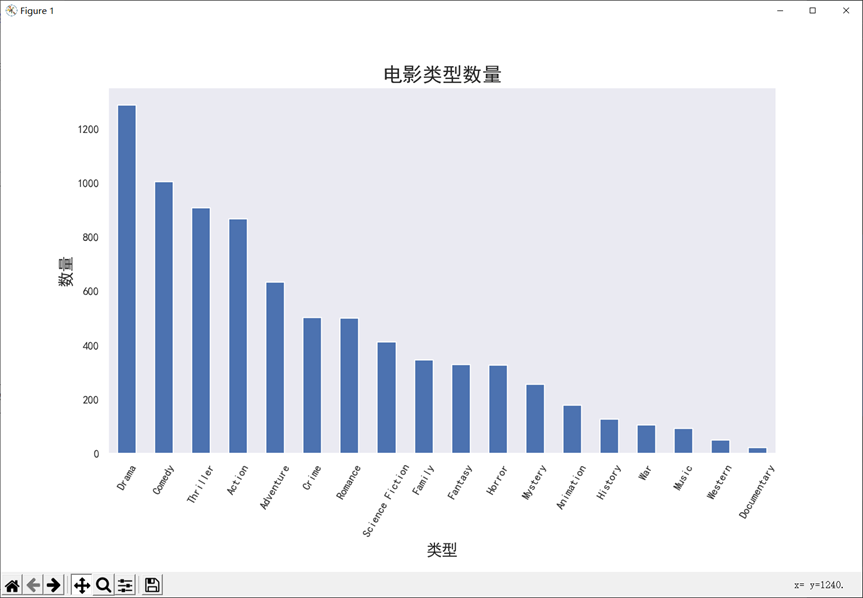
8.2.2 电影类型数量,绘制条形图
创建类型集合,更改索引为‘年份’
#将genre转变成列表 genre_list = list(genre) # 创建数据框-电影类型 genre_df = pd.DataFrame() #对电影类型进行one-hot编码 for i in genre_list: # 如果包含类型 i,则编码为1,否则编码为0 genre_df[i] = df['genres'].str.contains(i).apply(lambda x: 1 if x else 0) #将数据框的索引变为年份 genre_df.index = df['release_year']
绘图
# 计算得到每种类型的电影总数目,并降序排列 grnre_sum = genre_df.sum().sort_values(ascending = False) # 可视化 plt.rcParams['font.sans-serif'] = ['SimHei'] #用来显示中文 grnre_sum.plot(kind='bar',label='genres',figsize=(12,9)) plt.title('电影类型数量',fontsize=20) plt.xticks(rotation=60) plt.xlabel('类型',fontsize=16) plt.ylabel('数量',fontsize=16) plt.grid(False) plt.savefig("电影类型数量-条形图.png",dpi=300) #在 plt.show() 之前调用 plt.savefig() plt.show()
运行结果
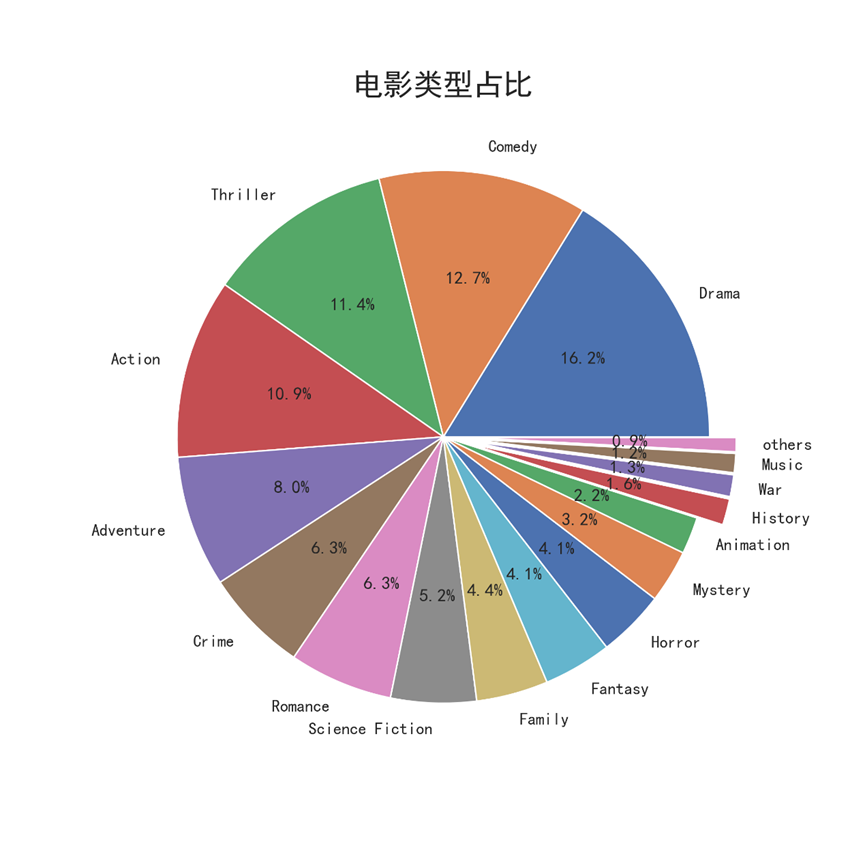
8.2.3 电影类型占比,绘制饼图
#绘制饼图 gen_shares = grnre_sum / grnre_sum.sum() # 设置other类,当电影类型所占比例小于%1时,全部归到other类中 others = 0.01 gen_pie = gen_shares[gen_shares >= others] gen_pie['others'] = gen_shares[gen_shares < others].sum() # 设置分裂属性 # 所占比例小于或等于%2时,增大每块饼片边缘偏离半径的百分比 explode = (gen_pie <= 0.02)/10 gen_pie.plot(kind='pie',label='',explode=explode,startangle=0,shadow=False,autopct='%3.1f%%',figsize=(8,8)) plt.title('电影类型占比',fontsize=20) plt.savefig("电影类型占比-饼图.png",dpi=300) plt.show()
运行结果
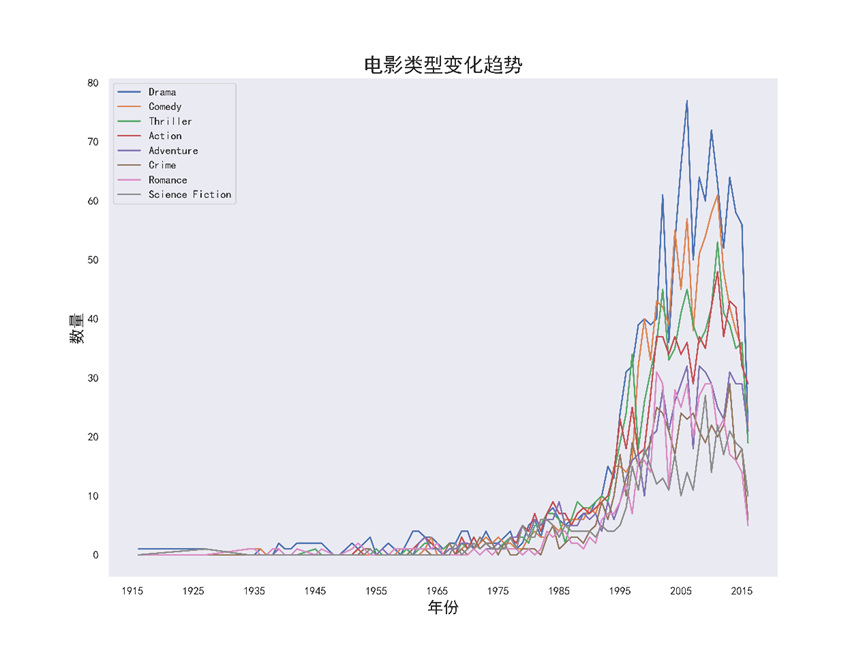
8.2.4 电影类型变化趋势,绘制折线图
绘制电影类型随时间变化的趋势
gen_year_sum = genre_df.sort_index(ascending = False).groupby('release_year').sum() gen_year_sum_sub = gen_year_sum[['Drama','Comedy','Thriller','Action','Adventure','Crime','Romance','Science Fiction']] gen_year_sum_sub.plot(figsize=(12,9)) plt.legend(gen_year_sum_sub.columns) plt.xticks(range(1915,2018,10)) plt.xlabel('年份', fontsize=16) plt.ylabel('数量', fontsize=16) plt.title('电影类型变化趋势', fontsize=20) plt.grid(False) plt.savefig("电影类型变化趋势-折线图.png",dpi=600) plt.show()
运行结果
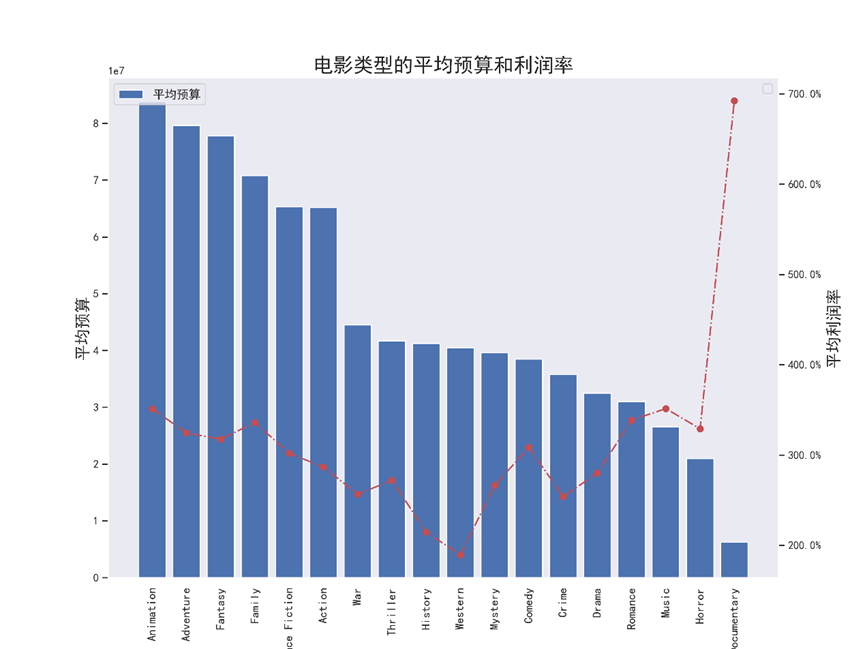
8.2.5 不同电影类型预算/利润,绘制组合图
首先计算不同类型的电影利润
# Step1-创建profit_dataframe profit_df = pd.DataFrame() profit_df = pd.concat([genre_df.reset_index(), df['revenue']], axis=1) # Step2-创建profit_series,横坐标为genre profit_s=pd.Series(index=genre_list) # Step3-求出每种genre对应的利润均值 for i in genre_list: profit_s.loc[i]=profit_df.loc[:,[i,'revenue']].groupby(i, as_index=False).mean().loc[1,'revenue'] profit_s = profit_s.sort_values(ascending = True)
再计算不同类型的电影预算
# 计算不同类型电影的budget # Step1-创建profit_dataframe budget_df = pd.DataFrame() budget_df = pd.concat([genre_df.reset_index(), df['budget']], axis=1) # Step2-创建budget_series,横坐标为genre budget_s=pd.Series(index=genre_list) # Step3-求出每种genre对应的预算均值 for j in genre_list: budget_s.loc[j]=budget_df.loc[:,[j,'budget']].groupby(j, as_index=False).mean().loc[1,'budget']
合并结果集
profit_budget = pd.concat([profit_s, budget_s], axis=1) profit_budget.columns = ['revenue', 'budget']
计算利润率(利润/预算*100%)
profit_budget['rate'] = (profit_budget['revenue']/profit_budget['budget'])*100
美观图像,根据预算降序排序
profit_budget_sort=profit_budget.sort_values(by='budget',ascending = False)
开始绘图:
(1)组合图(条形预算+折现利润率)
# 绘制不同类型电影平均预算和利润率(组合图) x = profit_budget_sort.index y1 = profit_budget_sort.budget y2 = profit_budget_sort.rate # 返回profit_budget的行数 length = profit_budget_sort.shape[0] fig = plt.figure(figsize=(12,9)) # 左轴 ax1 = fig.add_subplot(1,1,1) plt.bar(range(0,length),y1,color='b',label='平均预算') plt.xticks(range(0,length),x,rotation=90, fontsize=12) # 更改横坐标轴名称 ax1.set_xlabel('年份') # 设置x轴label ,y轴label ax1.set_ylabel('平均预算',fontsize=16) ax1.legend(loc=2,fontsize=12) #右轴 # 共享x轴,生成次坐标轴 ax2 = ax1.twinx() ax2.plot(range(0,length),y2,'ro-.') ax2.set_ylabel('平均利润率',fontsize=16) ax2.legend(loc=1,fontsize=12) # 将利润率坐标轴以百分比格式显示 import matplotlib.ticker as mtick fmt='%.1f%%' yticks = mtick.FormatStrFormatter(fmt) ax2.yaxis.set_major_formatter(yticks) # 设置图片title ax1.set_title('电影类型的平均预算和利润率',fontsize=20) ax1.grid(False) ax2.grid(False) plt.savefig("电影类型的平均预算和利润率-组合图.png",dpi=300) plt.show()
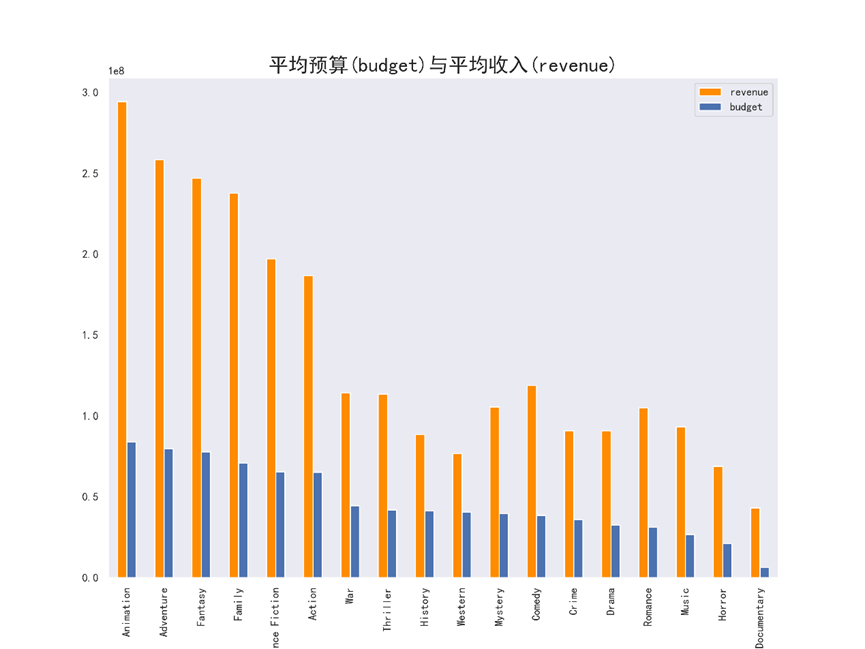
(2)不同电影类型的预算和收入,条形图
# 绘制不同类型电影预算和收入(条形图) profit_budget_sort.iloc[:,0:2].plot(kind='bar', figsize=(12,9),color = ['darkorange','b']) plt.title('平均预算(budget)与平均收入(revenue)',fontsize = 20) plt.xlabel('len',fontsize = 16) plt.grid(False) plt.savefig('电影类型的平均预算和平均收入-条形图.png',dpi=300) plt.show()
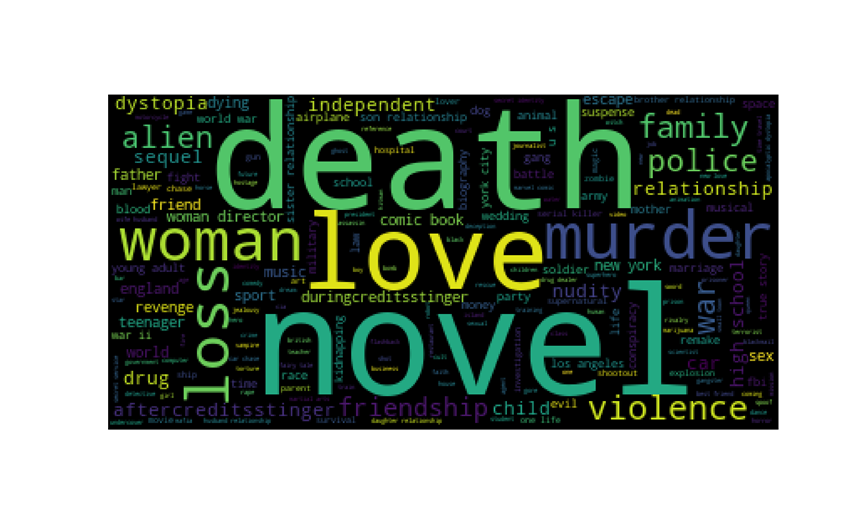
8.2.6 电影关键词,词云图
#keywords关键词分析 keywords_list = [] for i in df['keywords']: keywords_list.append(i) # print(keywords_list) #把字符串列表连接成一个长字符串 lis = ''.join(keywords_list) lis.replace('\'s','') #设置停用词 stopwords = set(STOPWORDS) stopwords.add('film') stopwords.add('based') wordcloud = WordCloud( background_color = 'black', random_state=9, # 设置一个随机种子,用于随机着色 stopwords = stopwords, max_words = 3000, scale=1).generate(lis) plt.figure(figsize=(10,6)) plt.imshow(wordcloud) plt.axis('off') plt.savefig('词云图.png',dpi=300) plt.show()
8.3 When
8.3.1 修改数据类型
查看runtime数据类型
print(df.runtime.head(5))
发现是Object类型

先将其转换为数值类型,float64,便于数字统计
df.runtime = df.runtime.astype(float) print(df.runtime.head(5))

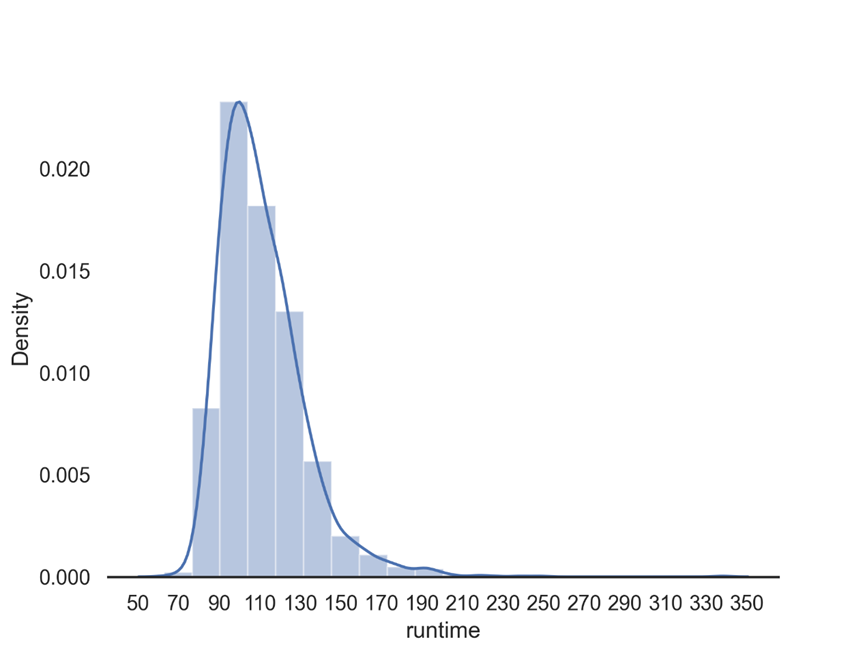
8.3.2 绘制电影时长直方图
sns.set_style('white') sns.distplot(df.runtime,bins = 20) sns.despine(left = True) # 使用despine()方法来移除坐标轴,默认移除顶部和右侧坐标轴 plt.xticks(range(50,360,20)) plt.savefig('电影时长直方图.png',dpi=300) plt.show()
8.3.3 绘制每月电影数量和单片平均票房
fig = plt.figure(figsize=(8,6)) x = list(range(1,13)) y1 = df.groupby('release_month').revenue.size() y2 = df.groupby('release_month').revenue.mean()# 每月单片平均票房 # 左轴 ax1 = fig.add_subplot(1,1,1) plt.bar(x,y1,color='b',label='电影数量') plt.grid(False) ax1.set_xlabel(u'月份')# 设置x轴label ,y轴label ax1.set_ylabel(u'每月电影数量',fontsize=16) ax1.legend(loc=2,fontsize=12) # 右轴 ax2 = ax1.twinx() plt.plot(x,y2,'ro--',label=u'单片平均票房') ax2.set_ylabel(u'每月单片平均票房',fontsize=16) ax2.legend(loc=1,fontsize=12) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.savefig('每月电影数量和单片平均票房.png',dpi=300) plt.rc("font",family="SimHei",size="15") plt.show()
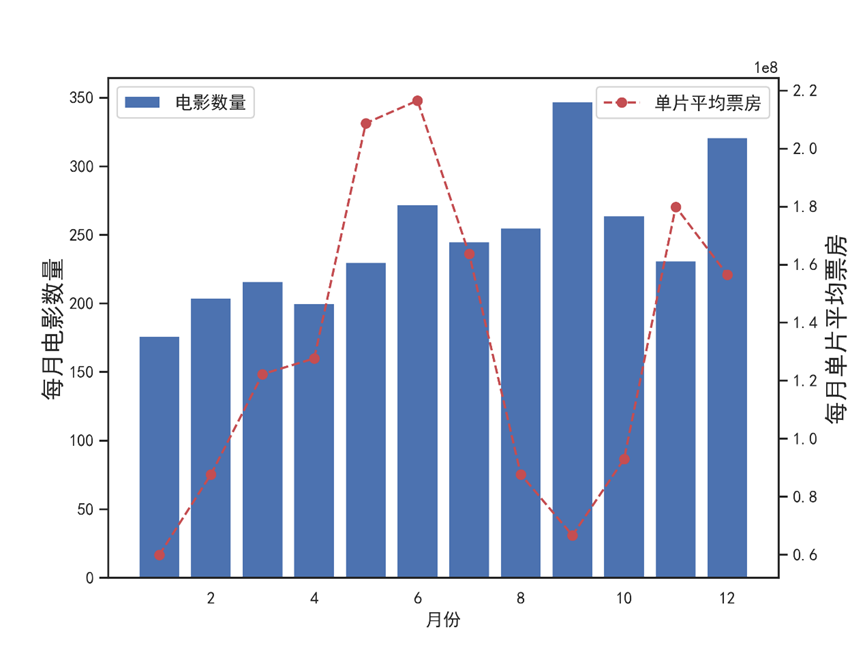
8.4 Where
本数据集收集的是美国地区的电影数据,对于电影的制作公司以及制作国家,在本次的故事 背景下不作分析。
8.5 Who
8.5.1 分析票房分布及票房 Top10 的导演
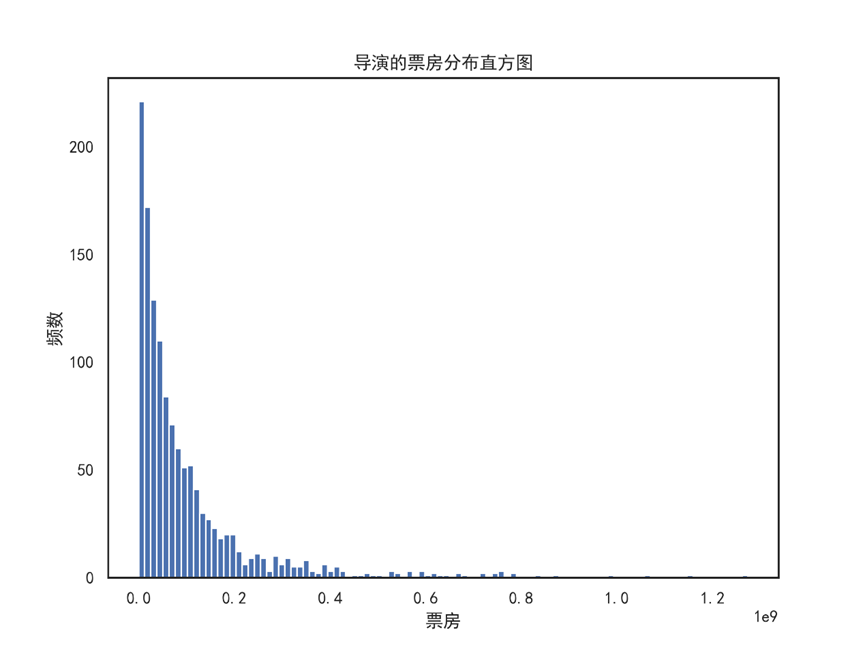
#票房分布及票房Top10的导演 # 创建数据框 - 导演 director_df = pd.DataFrame() director_df = df[['director','revenue','budget','vote_average']] director_df['profit'] = (director_df['revenue']-director_df['budget']) director_df = director_df.groupby(by = 'director').mean().sort_values(by='revenue',ascending = False) # 取均值 director_df.info() # 绘制票房分布直方图 director_df['revenue'].plot.hist(bins=100, figsize=(8,6)) plt.xlabel('票房') plt.ylabel('频数') plt.title('导演的票房分布直方图') plt.savefig('导演的票房分布直方图.png',dpi = 300) plt.show() # 票房均值Top10的导演 director_df.revenue.sort_values(ascending = True).tail(10).plot(kind='barh',figsize=(8,6)) plt.xlabel('票房',fontsize = 16) plt.ylabel('导演',fontsize = 16) plt.title('票房排名Top10的导演',fontsize = 20) plt.savefig('票房排名Top10的导演.png',dpi = 300) plt.show()
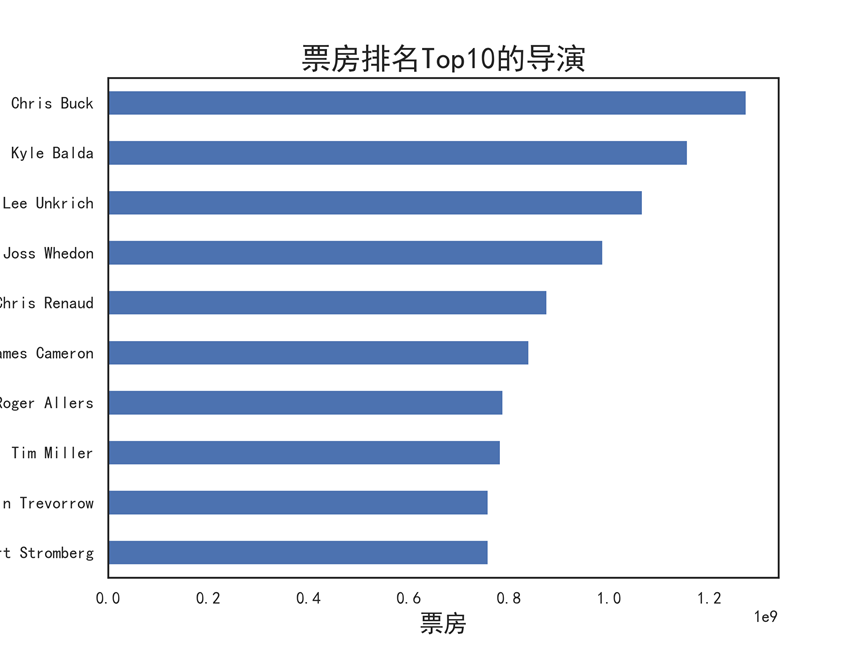
8.5.2 分析评分分布及评分 Top10 的导演
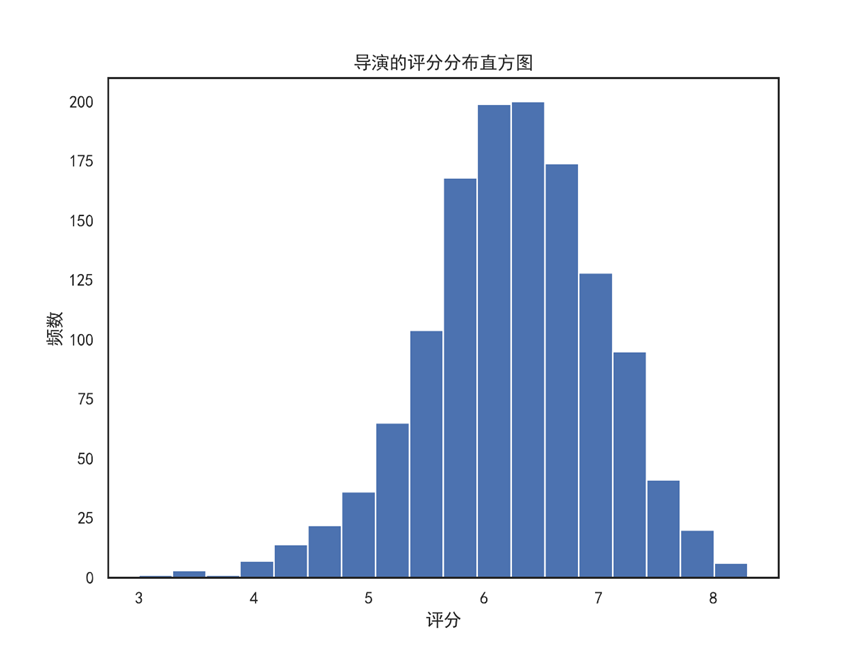
#评分分布及评分Top10的导演 # 绘制导演评分直方图 director_df['vote_average'].plot.hist(bins=18, figsize=(8,6)) plt.xlabel('评分') plt.ylabel('频数') plt.title('导演的评分分布直方图') plt.savefig('导演的评分分布直方图.png',dpi = 300) plt.show() # 评分均值Top10的导演 director_df.vote_average.sort_values(ascending = True).tail(10).plot(kind='barh',figsize=(8,6)) plt.xlabel('评分',fontsize = 16) plt.ylabel('导演',fontsize = 16) plt.title('评分排名Top10的导演',fontsize = 20) plt.savefig('评分排名Top10的导演.png',dpi = 300) plt.show()
运行结果
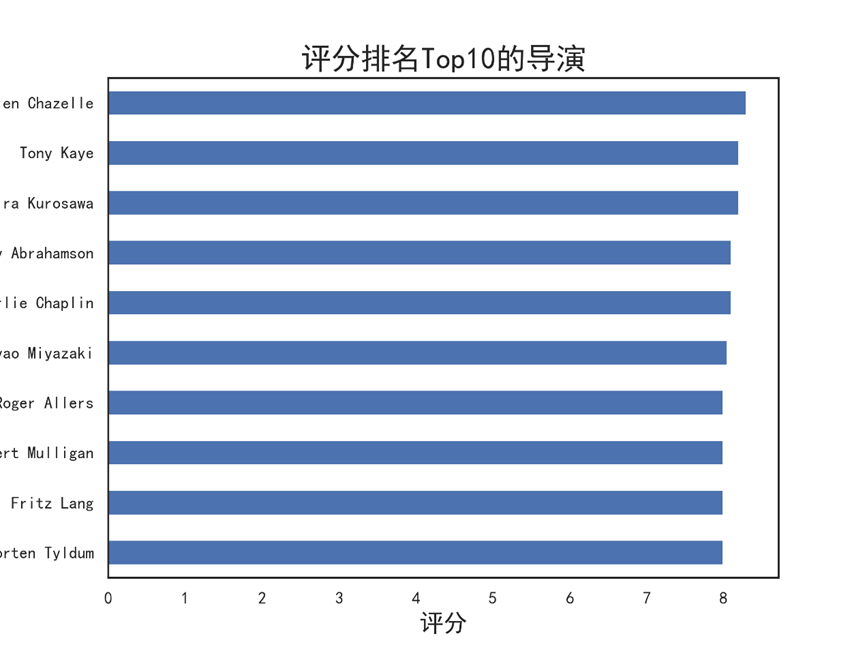
8.6 How
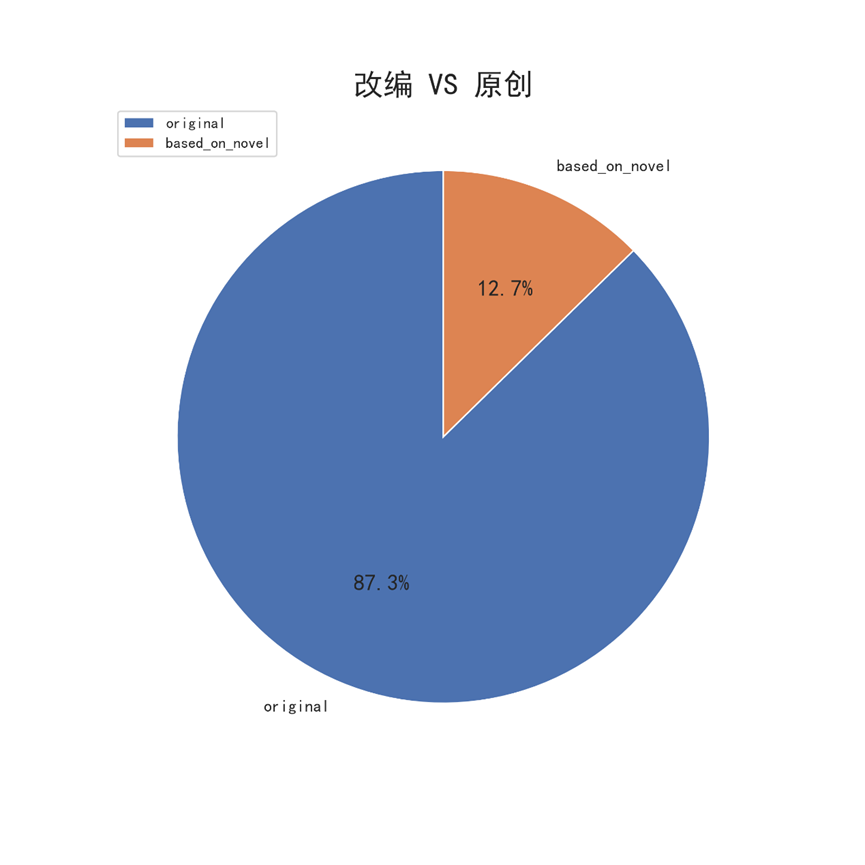
8.6.1 原创 VS 改编占比(饼图)
#原创 VS 改编占比(饼图) # 创建数据框 original_df = pd.DataFrame() original_df['keywords'] = df['keywords'].str.contains('based on').map(lambda x: 1 if x else 0) original_df['profit'] = df['revenue'] - df['budget'] original_df['budget'] = df['budget'] # 计算 novel_cnt = original_df['keywords'].sum() # 改编作品数量 original_cnt = original_df['keywords'].count() - original_df['keywords'].sum() # 原创作品数量 # 按照 是否原创 分组 original_df = original_df.groupby('keywords', as_index = False).mean() # 注意此处计算的是利润和预算的平均值 # 增加计数列 original_df['count'] = [original_cnt, novel_cnt] # 计算利润率 original_df['profit_rate'] = (original_df['profit'] / original_df['budget'])*100 # 修改index original_df.index = ['original', 'based_on_novel'] # 计算百分比 original_pie = original_df['count'] / original_df['count'].sum() # 绘制饼图 original_pie.plot(kind='pie',label='',startangle=90,shadow=False,autopct='%2.1f%%',figsize=(8,8)) plt.title('改编 VS 原创',fontsize=20) plt.legend(loc=2,fontsize=10) plt.savefig('改编VS原创-饼图.png',dpi=300) plt.show()
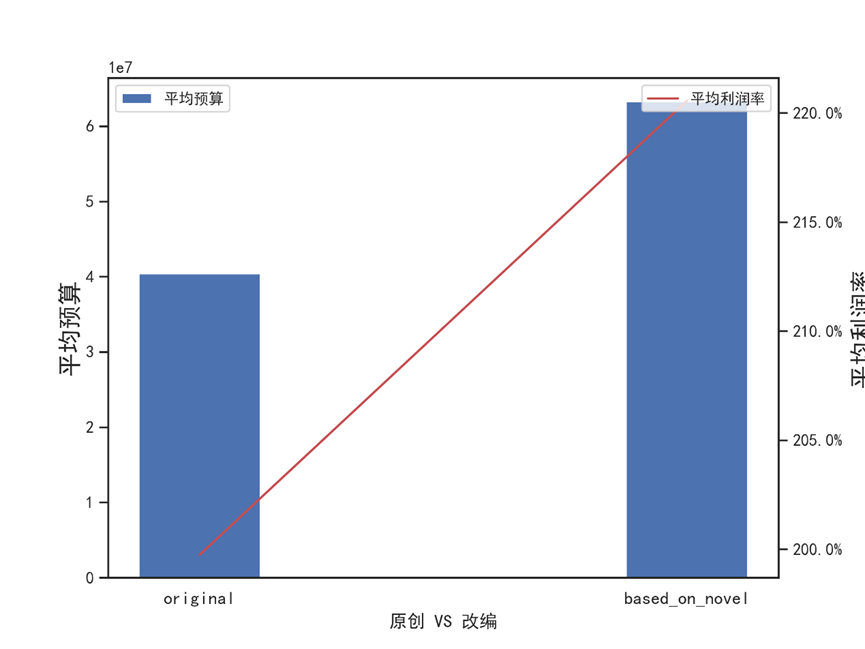
8.6.2 原创 VS 改编预算/利润率(组合图)
#原创VS改编 预算/利润率(组合图) x = original_df.index y1 = original_df.budget y2 = original_df.profit_rate fig= plt.figure(figsize = (8,6)) # 左轴 ax1 = fig.add_subplot(1,1,1) plt.bar(x,y1,color='b',label='平均预算',width=0.25) plt.xticks(rotation=0, fontsize=12) # 更改横坐标轴名称 ax1.set_xlabel('原创 VS 改编') # 设置x轴label ,y轴label ax1.set_ylabel('平均预算',fontsize=16) ax1.legend(loc=2,fontsize=10) #右轴 # 共享x轴,生成次坐标轴 ax2 = ax1.twinx() ax2.plot(x,y2,color='r',label='平均利润率') ax2.set_ylabel('平均利润率',fontsize=16) ax2.legend(loc=1,fontsize=10) # loc=1,2,3,4分别表示四个角,和四象限顺序一致 # 将利润率坐标轴以百分比格式显示 import matplotlib.ticker as mtick fmt='%.1f%%' yticks = mtick.FormatStrFormatter(fmt) ax2.yaxis.set_major_formatter(yticks) plt.savefig('改编VS原创的预算以及利润率-组合图.png',dpi=300) plt.show()
8.7 How much
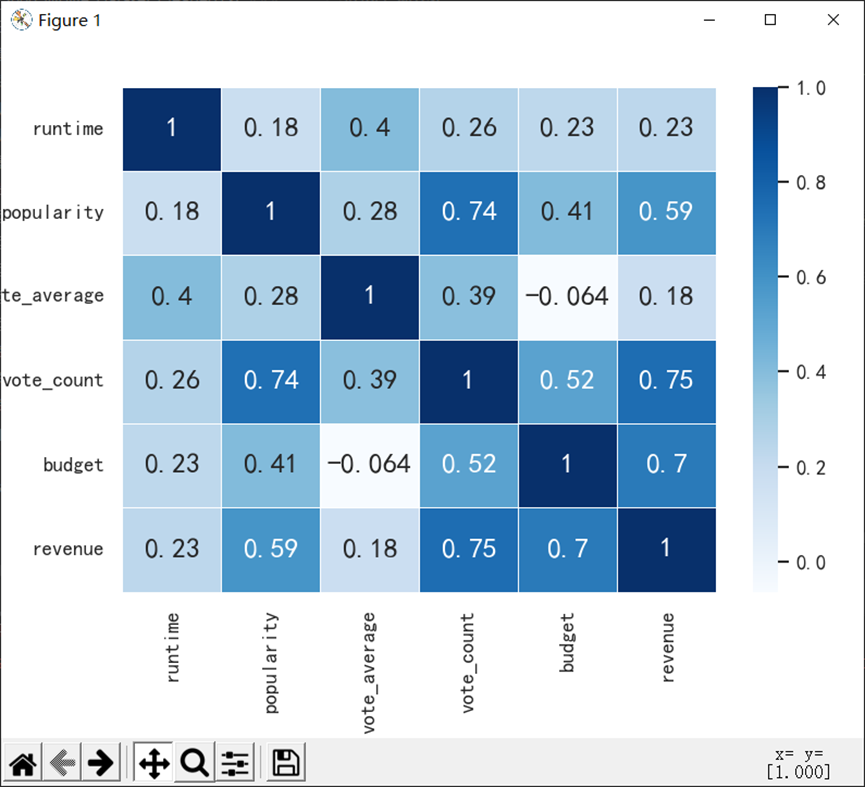
8.7.1 计算相关系数(票房相关系数矩阵)
revenue_corr = df[['runtime','popularity','vote_average','vote_count','budget','revenue']].corr() sns.heatmap( revenue_corr, annot=True, # 在每个单元格内显示标注 cmap="Blues", # 设置填充颜色:黄色,绿色,蓝色 cbar=True, # 显示color bar linewidths=0.5, # 在单元格之间加入小间隔,方便数据阅读 ) plt.savefig('票房相关系数矩阵.png',dpi=300) plt.show()
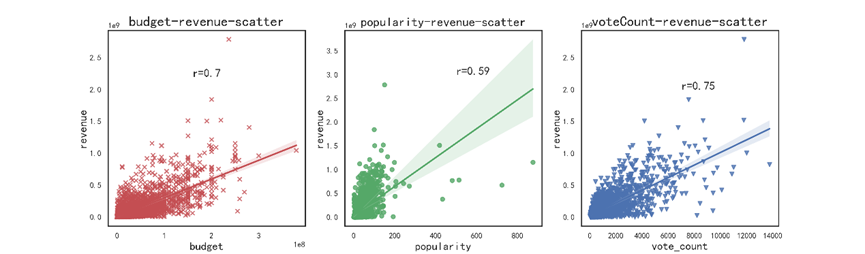
8.7.2 票房影响因素散点图
fig = plt.figure(figsize=(17,5)) ax1 = plt.subplot(1,3,1) ax1 = sns.regplot(x='budget', y='revenue', data=df, x_jitter=.1,color='r',marker='x') # marker: 'x','o','v','^','<' # jitter:抖动项,表示抖动程度 ax1.text(1.6e8,2.2e9,'r=0.7',fontsize=16) plt.title('budget-revenue-scatter',fontsize=20) plt.xlabel('budget',fontsize=16) plt.ylabel('revenue',fontsize=16) ax2 = plt.subplot(1,3,2) ax2 = sns.regplot(x='popularity', y='revenue', data=df, x_jitter=.1,color='g',marker='o') ax2.text(500,3e9,'r=0.59',fontsize=16) plt.title('popularity-revenue-scatter',fontsize=18) plt.xlabel('popularity',fontsize=16) plt.ylabel('revenue',fontsize=16) ax3 = plt.subplot(1,3,3) ax3 = sns.regplot(x='vote_count', y='revenue', data=df, x_jitter=.1,color='b',marker='v') ax3.text(7000,2e9,'r=0.75',fontsize=16) plt.title('voteCount-revenue-scatter',fontsize=20) plt.xlabel('vote_count',fontsize=16) plt.ylabel('revenue',fontsize=16) plt.savefig('revenue.png',dpi=300) plt.show()
散点图:
数据分析结束
————————————————————————————————————————————————————————————————
结论明天再分析
相关:
观影大数据分析(上) - Arisf - 博客园 (cnblogs.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号