观影大数据分析(上)
王 S 聪想要在海外开拓万 D 电影的市场,这次他在考虑:怎么拍商业电影才 能赚钱?毕竟一些制作成本超过 1 亿美元的大型电影也会失败。这个问题对电影 业来说比以往任何时候都更加重要。 所以,他就请来了你(数据分析师)来帮 他解决问题,给出一些建议,根据数据分析一下商业电影的成功是否存在统一公 式?以帮助他更好地进行决策。
解决的终极问题是:电影票房的影响因素有哪些?
接下来我们就分不同的维度分析:
• 观众喜欢什么电影类型?有什么主题关键词?
• 电影风格随时间是如何变化的?
• 电影预算高低是否影响票房?
• 高票房或者高评分的导演有哪些?
• 电影的发行时间最好选在啥时候?
• 拍原创电影好还是改编电影好?
本次使用的数据来自于 Kaggle 平台(TMDb 5000 Movie Database)。收录了 美国地区 1916-2017 年近 5000 部电影的数据,包含预算、导演、票房、电影评 分等信息。原始数据集包含 2 个文件:
• tmdb_5000_movies:电影基本信息,包含 20 个变量
• tmdb_5000_credits:演职员信息,包含 4 个变量
请使用 Python 编程,完成下列问题:
(1)使用附件中的 tmdb_5000_movies.csv 和 tmdb_5000_credits.csv 数据集,进 行数据清洗、数据挖掘、数据分析和数据可视化等,研究电影票房的影响因素有 哪些?从不同的维度分析电影,讨论并分析你的结果。
(2)附件 tmdb_1000_predict.csv 中包含 1000 部电影的基本信息,请你选择 合适的指标,进行特征提取,建立机器学习的预测模型,预测 1000 部电影的 vote_average 和 vote_count,并保存为 tmdb_1000_predicted.csv。
————————————————————————————————————————————————————————————————
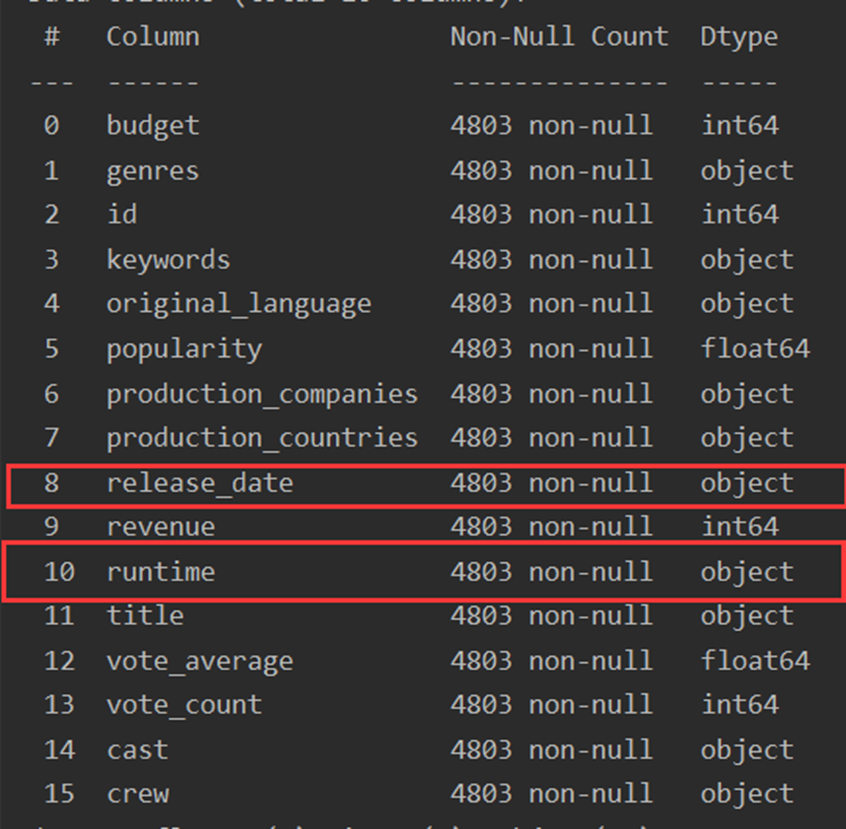
1.pandas数据导入
movies = pd.read_csv('tmdb_5000_movies.csv', encoding='utf_8') credits = pd.read_csv('tmdb_5000_credits.csv', encoding='utf_8') # 查看信息 movies.info() credits.info()
导入结果:
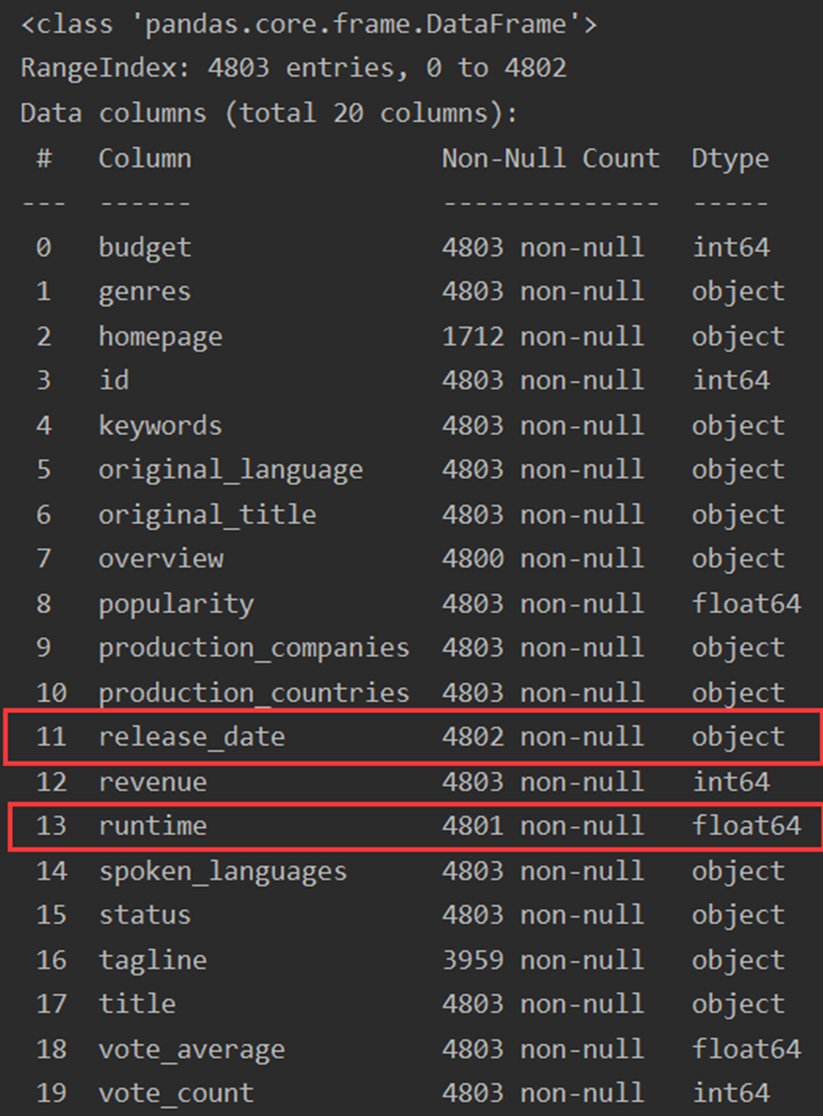
tmdb_5000_credits.csv表
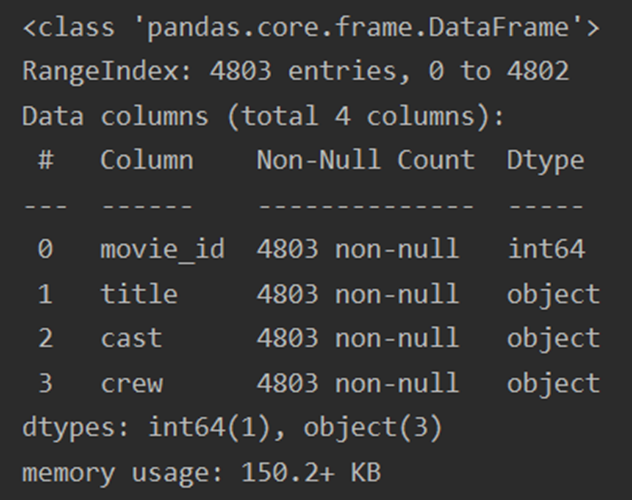
release_date缺失一条数据;runtime缺失两条数据,共有数据4803条。
合并表,删除重复列与不需要的列
(1)删除重复列:credits.title、movies. original_title
del credits['title'] del movies['original_title']
(2)合并表
merged = pd.merge(movies, credits, left_on='id', right_on='movie_id', how='left')
(3)删除不需要的字段
df=merged.drop(['homepage','overview','spoken_languages','status','tagline','movie_id'],axis=1)
(4)查看结果
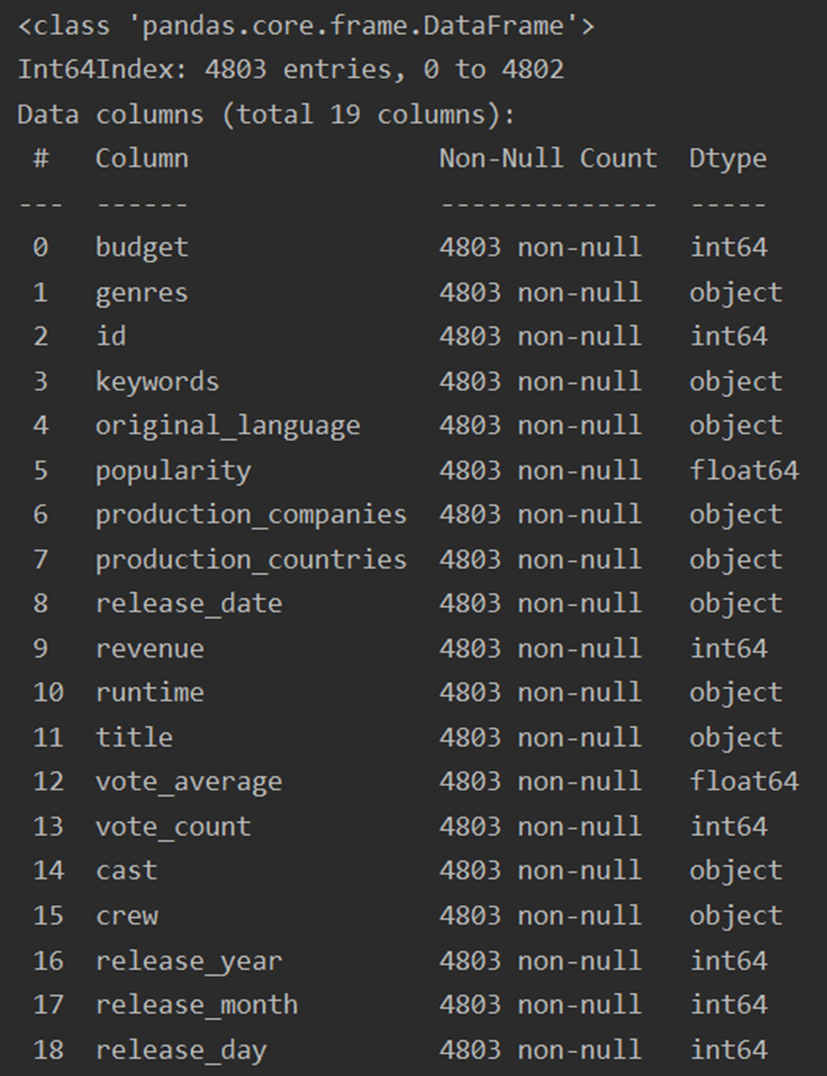
df.info()
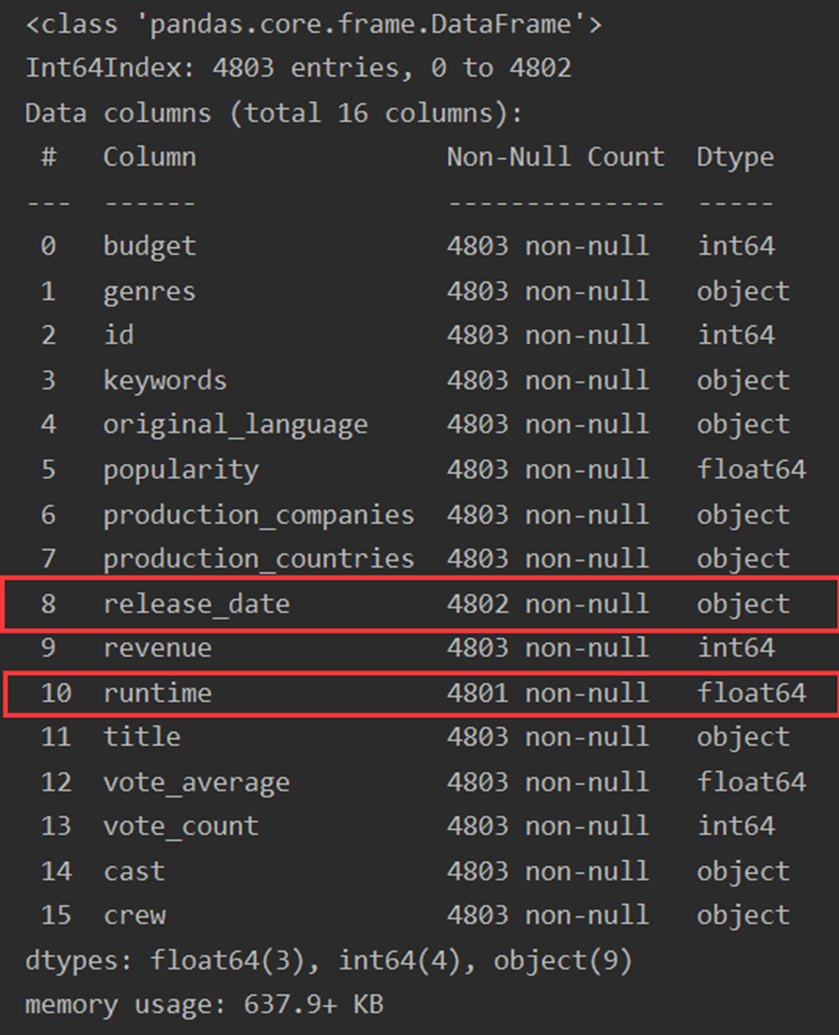
release_date缺失一条数据;runtime缺失两条数据。
2.数据补全
查找缺失记录
# 查找缺失值记录-release_date var = df[df.release_date.isnull()] print(var.title) # 查找缺失值记录-runtime var = df[df.runtime.isnull()] print(var.title)
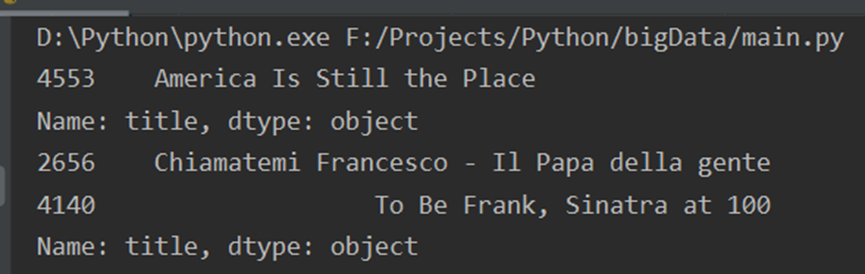
缺失发布日期的电影为
《America Is Still the Place》
缺失时长的两部电影为
《Chiamatemi Francesco - Il Papa della gente》
《To Be Frank, Sinatra at 100》
补全数据
df['release_date'] = df['release_date'].fillna('2014-06-01') df.loc[2656] = df.loc[2656].fillna('94, limit=1') df.loc[4140] = df.loc[4140].fillna('240, limit=1') df.info()
3.重复值处理
print(len(df.id.unique()))
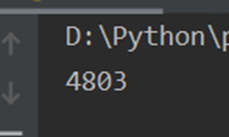
有4803个不重复id,与数据总数一致,可以认为无重复数据
4.日期值处理
df['release_year'] = pd.to_datetime(df.release_date, format = '%Y-%m-%d',errors='coerce').dt.year df['release_month'] = pd.to_datetime(df.release_date).apply(lambda x: x.month) df['release_day'] = pd.to_datetime(df.release_date).apply(lambda x: x.day) df.info() print(df['release_year'],df['release_month'],df['release_day'])
查看运行结果
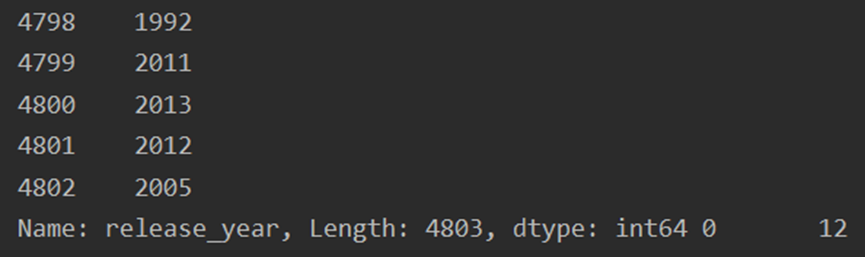
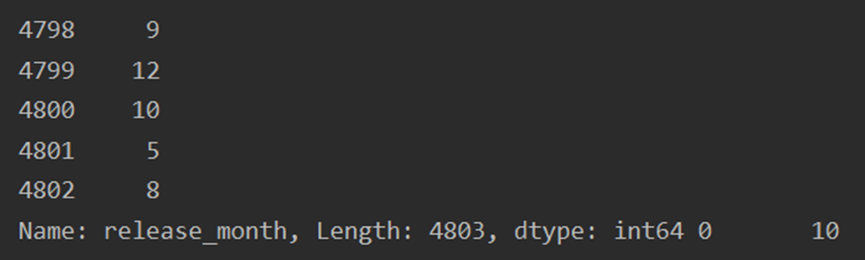
5.筛选数据
票房、预算、受欢迎程度、评分为0的数据应该去除
评分人数过低的电影,评分不具有统计意义,筛选评分人数大于50的数据
df = df[(df.vote_count >= 50) &(df.budget * df.revenue * df.popularity * df.vote_average !=0)].reset_index(drop = 'True') df.info()
运行结果
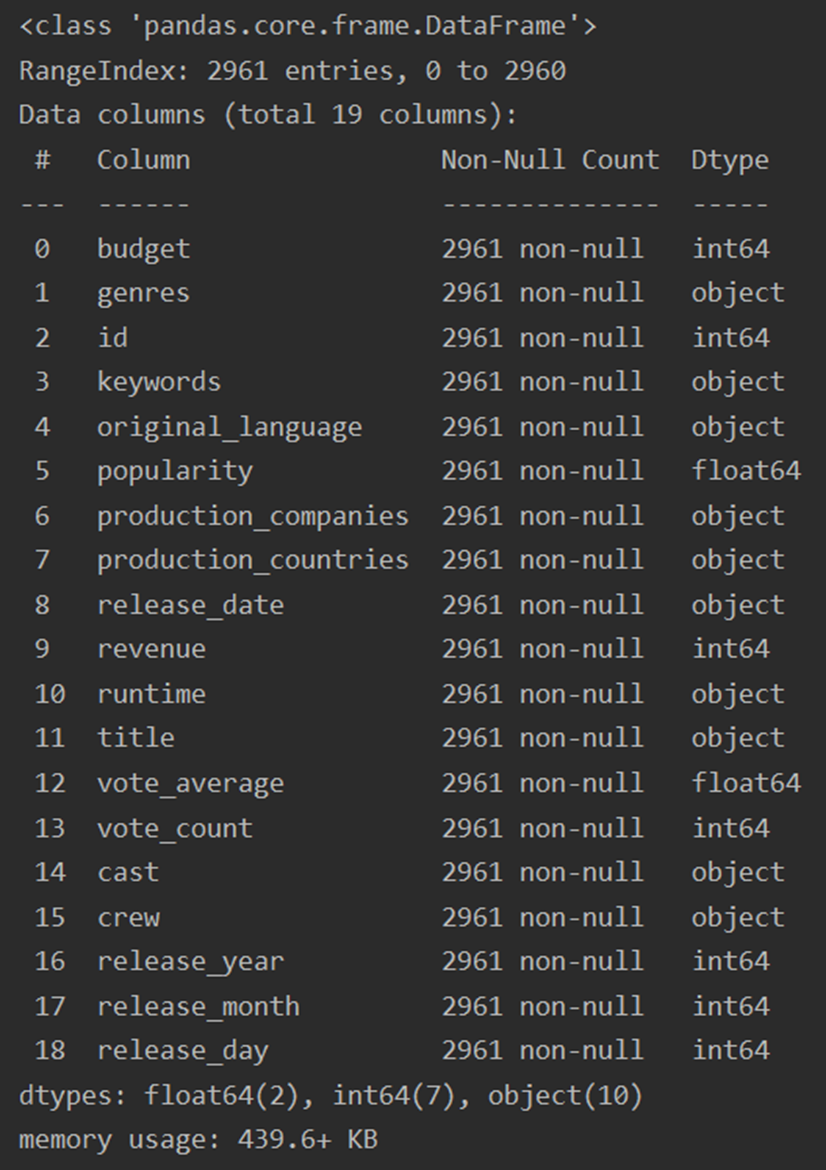
剩下2961条样本
博客园字数限制,太长了,接下一篇
—————————————————————————————————————————————————————————————————————————————————————————————
相关:
观影大数据分析(上) - Arisf - 博客园 (cnblogs.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号