自编码器
自编码器
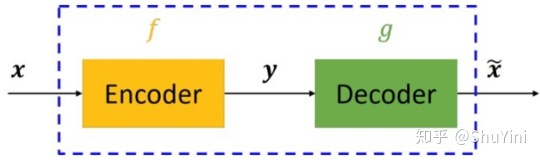
- 构成
- 编码器(Encoder)
- 解码器(Decoder)
- 目的
- 将输入变量\(x\)编码为中间变量\(y\),再将中间变量\(y\)解码为输出变量\(\widetilde{x}\)
- 对比输入\(x\)与输出\(\widetilde{x}\),使二者无限接近
深度学习中的自编码器
在深度学习中,自编码模型是一种无监督的神经网络模型。
直观来看,自编码模型可以用于:
- 特征降维,类似于主成分分析PCA,但其性能比PCA更强
- 特征压缩,当模型输入包含大量特征信息时,可以通过Encoder对输入进行“压缩”,缩减输入信息量,通过Decoder进行解压缩,再将学习到的特征送入有监督模型中进行学习
- (首先需要对自编码模型进行训练,实现网络参数的初始化。在下游任务中,通常只会用到Encoder)
自编码模型的特点
- 自编码模型是数据相关(data-specific / data-dependet)的
- 自编码模型只能应用于与训练数据类似的下游任务。例如,通过人脸数据训练得到的自编码模型,在压缩其他类别的图片时性能很差。
- 自编码模型是有损的
- Decoder输出的特征与原始输入相比是退化的。
- 自编码模型是从数据样本中自动学习的,意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作
自编码模型的搭建
- 编码器
- \(y=h(x)\)
- 解码器
- \(\widetilde{x}=f(y)=f(h(x))\)
- 损失函数
- \({Loss}=\widetilde{x}-x\)
- 反向传播
为什么说BERT是自编码模型
-
引入噪声
- 通过了解BERT/ALBERT模型的训练过程,可以发现,其在预训练过程中惊醒了以下操作:
-
随机mask掉15%的token
-
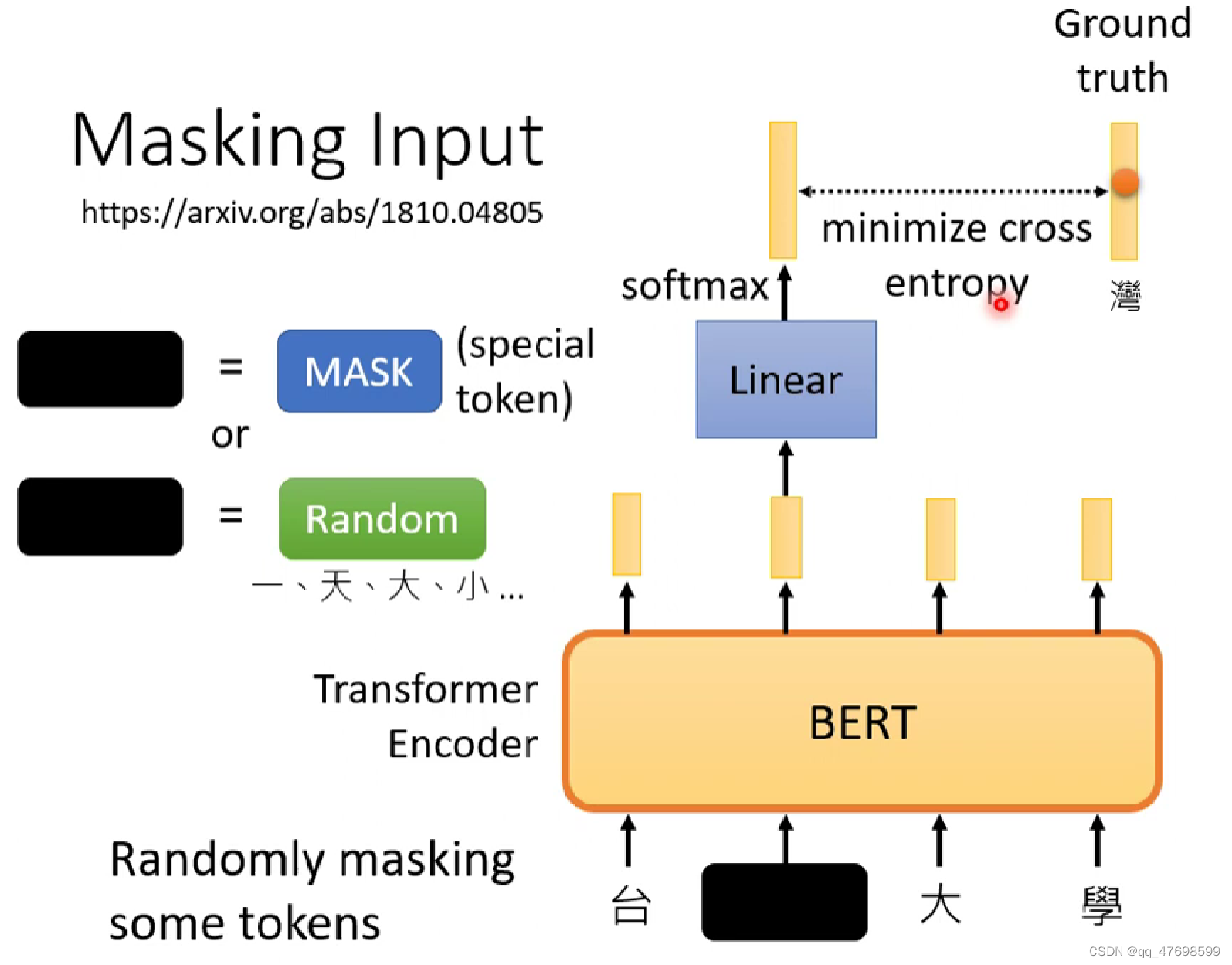
-
随机做n-gram mask \(\rightarrow\) 增强连续mask的数量,使得完形填空更加困难
-
50%概率交换两个文本段
-
15%的token会进行文本乱序
-
- 通过在输入端进行mask引入噪声,能够自然的融入双向语言模型。缺点是导致Pre-train阶段与Finetune阶段任务不一致。
- 通过了解BERT/ALBERT模型的训练过程,可以发现,其在预训练过程中惊醒了以下操作:
-
降噪
- 模型在预训练阶段引入了噪声,而还原[MASK]、消除引入的噪声的过程,即为自编码过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号