Tensor基础概念
Tensor
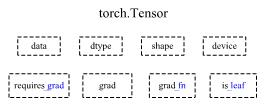
dtype: 张量的数据类型,如torch.FloatTensor,torch.cuda.FloatTensorshape: 张量形状device: 张量所在设备requires_grad: 指示是否需要梯度grad: data的梯度grad_fn: 创建Tensor的Function(记录计算图的入口),是自动求导的关键is_leaf: 指示是否为叶子节点
设置.requires_grad = True后,该Tensor的任何操作会被记录下来,通过追踪其上的所有操作,利用链式法则完成梯度传播。
完成计算后,可以调用.backward()计算梯度。该梯度将被累积到.grad属性中。
若不想继续跟踪Tensor操作,可调用.detach()将其从追踪记录中分离,使梯度无法传递,防止未来的计算被保留。
此外,还可通过with torch.no_grad()将不想被记录的代码块包裹起来,这种操作常用于模型的eval阶段。因为在评估模型时,不需要计算可训练参数(requires_grad=True)的梯度。
Function类
Tensor与Function的结合可构建一个记录整个计算过程的有向无环图(Directed Acyclic Graph, DAG)。
Tensor的.grad_fn属性对应创建该Tensor的Function。若Tensor是通过某些运算得到的,则返回与这些运算相关的对象,否则为None。
DAG
DAG的节点是Function对象,边表示数据依赖,从输出指向输入。
每对Tensor进行一次运算,就会产生一个Function对象,该对象产生运算结果,记录运算的发生及运算的输入。
Tensor通过.grad_fn属性记录DAG的入口。反向传播过程中,autograd按照逆序,通过Function的backward依次计算梯度。
Example
import torch
x = torch.ones(2,3,requires_grad=True)
y = x+2
print(x)
# tensor([[1., 1., 1.],
# [1., 1., 1.]], requires_grad=True)
print(y)
# tensor([[3., 3., 3.],
# [3., 3., 3.]], grad_fn=<AddBackward0>)
# x是直接创建的,所以没有grad_fn
print(x.grad_fn)
# None
# y是通过一个加法创建的,所以有一个<AddBackward>的grad_fn
print(y.grad_fn)
# <AddBackward0 object at 0x0000016CF13EDD90>
# x是直接创建的,所以是叶子节点。(叶子节点的grad_fn为None)
print(x.is_leaf, y.is_leaf)
# True False

