optimizer.step(), scheduler.step()
lr_scheduler
PyTorch中torch.optim.lr_scheduler封装的API:
-
lr_scheduler.LambdaLR
-
lr_scheduler.MultiplicativeLR
-
lr_scheduler.StepLR
-
lr_scheduler.MultiStepLR
-
lr_scheduler.ExponentialLR
-
lr_scheduler.CosineAnnealingLR
-
lr_scheduler.ReduceLROnPlateau
-
lr_scheduler.CyclicLR
-
lr_scheduler.OneCycleLR
-
lr_scheduler.CosineAnnealingWarmRestarts
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
# 需要在优化器参数更新后再调整学习率
scheduler_1.step()
- optimizer:根据反向传播的梯度信息来更新网络参数,以降低loss
- scheduler.step(): 更新优化器的学习率,一般按照epoch为单位进行更新
- 两个属性:
optimizer.defaults(dict): 继承自torch.optim.Optimizer父类,存放优化器的初始参数。
dict.keys():lr,betas,eps,weight_decay,amsgradoptimizer.param_groups(list): 每个元素都是一个字典,每个元素包含的key:params,lr,betas,eps,weight_decay,amsgrad,params类是各个网络的参数放在了一起。这个属性也继承自torch.optim.Optimizer父类。- 将网络参数放入优化器
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
# 实例化
net_1 = model()
# 实例化一个Adam优化器
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
# 实例化LambdaLR对象,lr_lambda是更新函数
scheduler_1 = LambdaLR(optimizer_1, lr_lambda=lambda epoch: 1/(epoch+1))
# 初始lr。optimizer_1.defaults保存了初始参数
print("初始化的学习率:", optimizer_1.defaults['lr'])
lr_list = []
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
# 由于只给optimizer传了一个网络,所以optimizer_1.param_groups长度为1
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lr_list.append(optimizer_1.param_groups[0]['lr'])
# 更新学习率
scheduler_1.step()
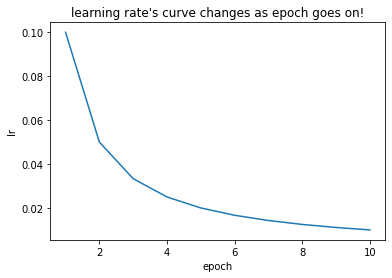
# 画出lr的变化
plt.plot(list(range(1, 11)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()
output:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.050000
第3个epoch的学习率:0.033333
第4个epoch的学习率:0.025000
第5个epoch的学习率:0.020000
第6个epoch的学习率:0.016667
第7个epoch的学习率:0.014286
第8个epoch的学习率:0.012500
第9个epoch的学习率:0.011111
第10个epoch的学习率:0.010000
Scheduler
torch.optim.lr_scheduler提供了根据epoch训练次数调整学习率的方法。
- 以LambdaLR为例
Sets the learning rate of each parameter group to the initial lr times a given function. When last_epoch=-1, sets initial lr as lr.
将每个参数组的学习率设置为初始 lr 乘以给定函数。当 last_epoch=-1 时,设置初始 lr 为 lr。
- 更新策略:
- 其中, 是更新后的学习率,是初始学习率, 是通过参数 和epoch得到的。
参数
optimizer(Optimizer): 优化器lr_lambda(function or list): 给定函数last_epoch: last epoch 的 index, 默认:-1verbose(bool): True-每次更新输出一条信息; 默认:False- Example
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
- 将optimizer传给scheduler后,scheduler类会在optimizer.param_groups列表中增加一个
key='initial_lr'表示初始学习率,value=optimizer.defaults['lr']
get_lr()
def get_lr(self):
if not self._get_lr_called_within_step:
warnings.warn("To get the last learning rate computed by the scheduler, "
"please use `get_last_lr()`.")
# 更新学习率
return [base_lr * lmbda(self.last_epoch)
for lmbda, base_lr in zip(self.lr_lambdas, self.base_lrs)]
自定义scheduler
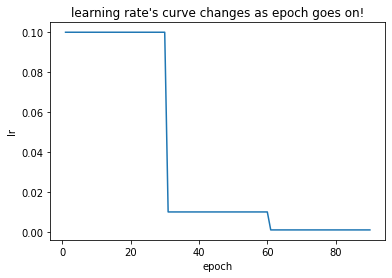
若API中没有实践中需要的调整策略,则可自定义adjust_learning_rate方法来改变param_group中lr的值。
假设实验需要学习率每30 epoch下降原来的1/10,且API中没有符合要求的方法,则通过自定义函数来动态调整学习率。
def adjust_learning_rate(optimizer, epoch):
lr = initial_lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
for epoch in range(1, 91):
# train
optimizer_1.zero_grad()
optimizer_1.step()
lr_list.append(optimizer_1.param_groups[0]['lr'])
# 更新学习率
# scheduler_1.step()
adjust_learning_rate(optimizer_1,epoch)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现
2021-04-05 colab读取Google网盘文件