Transformer的相关知识
Transformer为什么需要MHSA
将模型分为多个head,形成多个子空间,可以使模型关注到不同方面的信息,最终再综合各方面信息。
多次attention综合的效果可以起到增强模型的作用,也可类比CNN中同时使用多个卷积核的作用。
直观上讲,MHSA利于 capture more valuable and contributive infromation/feature.
Transformer较于RNN/LSTM的优势
- RNN-based模型无法并行计算。当前时刻计算依赖于上一时刻的计算结果。
- Transformer的特征抽取能力更好。
残差链接(Skip-connection)
Resnet中的skip-block
将输出表述为输入与输入的一个非线性变换的叠加
\[\begin{aligned}
y &= F(x)+x\\
&=H(x,W_H)+x
\end{aligned}
\]
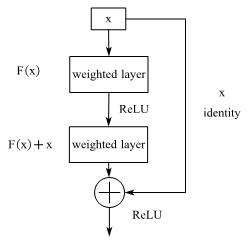
为什么要使用残差链接
网络越深,模型表达能力越强,但容易引发梯度消失/爆炸的问题
如:
卷积:f
$ f = f(x,W_f) $ , 激活:g: $ g= g(f) $, 分类:k: $ y= k(g) $
\[loss = criteon(y,y')
\]
loss对f的导数为:
\[\frac{d(loss)}{d(k)} \cdot \frac{d(k)}{d(g)} \cdot \frac{d(g)}{d(f)} \cdot \frac{d(f)}{W_f}
\]
一旦其中一项很小,后续的梯度便越来越小,若使用残差连接,相当于在每个导数后加一个恒等项1
\[\frac{d(h)}{x} = \frac{d(f+x)}{x} = \frac{d(f)}{x} + 1
\]

