torchtext
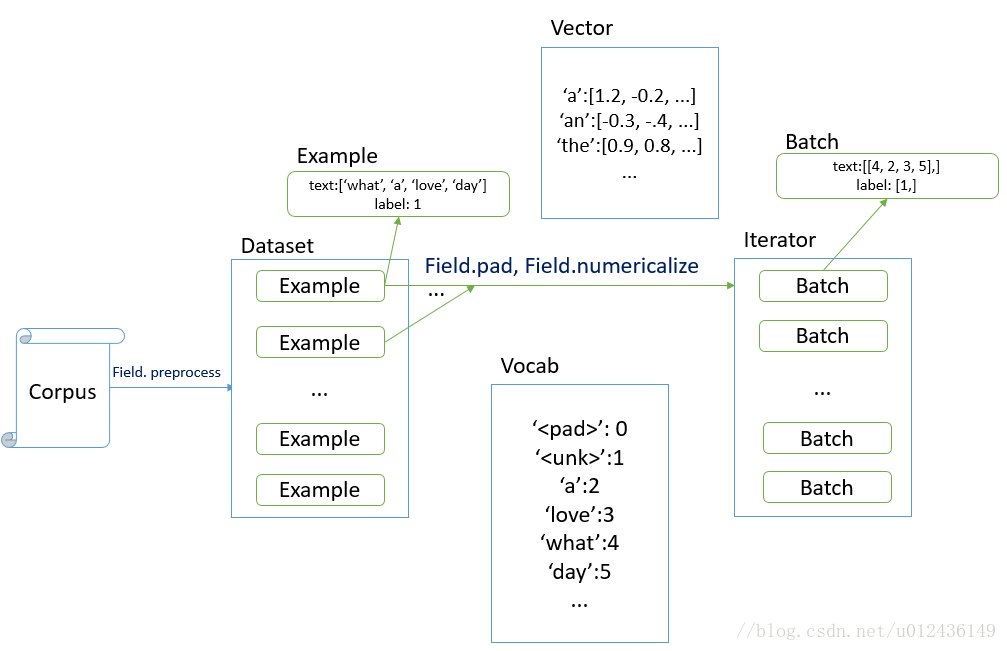
torchtext.legacy.data
- torchtext.legacy.data.Example : 用来表示一个样本,数据+标签
- torchtext.legacy.vocab.Vocab: 词汇表相关
- torchtext.legacy.data.Datasets: 数据集类,getitem 返回 Example实例
- torchtext.legacy.data.Field : 用来定义字段的处理方法(文本字段,标签字段)
创建 Example时的 预处理
batch 时的一些处理操作。 - torchtext.legacy.data.Iterator: 迭代器,用来生成 batch
- torchtext.legacy.datasets: 包含了常见的数据集.
Torchtext的功能
File Loading: 加载不同文件格式的 corpus
Tokenization: 将句子分解成 词列表。
Vocab: 构建 当前 corpus 的词汇表
Numericalize/Indexify: 将 词 映射成 index
Word Vector: 词向量
Batching: generate batches of training sample (padding is normally happening here)
举例:
"The quick fox jumped over a lazy dog."
-> (tokenization)
["The", "quick", "fox", "jumped", "over", "a", "lazy", "dog", "."]
-> (vocab)
{"The" -> 0,
"quick"-> 1,
"fox" -> 2,
...}
-> (numericalize/indexify)
[0, 1, 2, ...]
-> (embedding lookup)
[
[0.3, 0.2, 0.5],
[0.6, 0., 0.1],
...
]
Torchtext使用流程
定义字段的处理操作
torchtext.legacy.data.Field
TEXT = Field(sequential=True, tokenization=tokenizer, lower=True)
LABEL = Field(sequential=False, use_vocab=False)
# 如果LABEL是整型,不需要 numericalize , 就需要将 use_vocab=False.
加载corpus(String)
torchtext.legacy.data.Datasets
- 将corpus中每个字段处理为Example实例
- 创建Example时,会调用Field.preprocess方法
# 假设语料库: train.tsv, val.tsv, test.tsv
train, val, test = TabularDataset.splits(
path='./data/', train='train.tsv',
validation='val.tsv', test='test.tsv', format='tsv',
fields=[('Text', TEXT), ('Label', LABEL)])
## 创建词汇表,将string word 映射为id
Field.build_vocab()
* string token ---> index
* index ---> string token
* string token ---> word vector
```python
# 构建语料库的 Vocabulary, 同时,加载预训练的 word-embedding
# 可以后端会下载 word vectors 并加载。也可以通过 vocab.Vectors 使用自定义的 vectors.
TEXT.build_vocab(train, vectors="glove.6B.100d")
# 在创建字典时, 希望仅仅保存出现频率最高的 k 个单词
# 可在 .build_vocab 时使用 max_size 参数指定
构造batch: torch.legacy.data.Iterator
- 将 Datasets 中的数据 batch 化
- 其中会包含一些 pad 操作,保证一个 batch 中的 example 长度一致
- 在这里将 string token 转化成index。
tokenization,vocab, numericalize, embedding lookup 和 TorchText 数据预处理阶段的对应关系是:
# 运行在 CPU 上,需要设置 device=-1
# 如果运行在GPU 上,需要设置device=0 。
# torchtext 使用了动态 padding,意味着 batch内的所有句子会 pad 成 batch 内最长的句子长度。
train_iter, val_iter, test_iter = Iterator.splits(
(train, val, test), sort_key=lambda x: len(x.Text),
batch_sizes=(32, 256, 256), device=-1)
batch = next(iter(train_iter))
print("batch text: ", batch.Text) # 对应 Fileld 的 name
print("batch label: ", batch.Label)
- tokenization —> Dataset 的构造函数中,由 Field 的 tokenize 操作
- vocab —> field.build_vocab 时,由 Field 保存 映射关系
- numericalize —> 发生在 iterator 准备 batch 的时候,由 Field 执行 numericalize 操作
- embedding lookup —> 由 pytorch Embedding Layer 提供此功能。
batch.Text 和 batch.Label 都是 torch.LongTensor 类型的值,保存的是 index 。
如果我们想获得** word vector**,应该怎么办呢?
- Field 的 vocab 属性保存了 word vector 数据,可以把这些数据拿出来,然后使用 Pytorch 的 Embedding Layer 来解决 embedding lookup 问题。
vocab = TEXT.vocab
self.embed = nn.Embedding(len(vocab), emb_dim)
self.embed.weight.data.copy_(vocab.vectors)
如何指定 Vector 缺失值的初始化方式
-
vector.unk_init = init.xavier_uniform 这种方式指定完再传入 build_vocab
————————————————
版权声明:本文为CSDN博主「u012436149」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012436149/article/details/79310176

 浙公网安备 33010602011771号
浙公网安备 33010602011771号