13. table定位
<!DOCTYPE html> <meta charset="UTF-8"> <!-- for HTML5 --> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <html> <head> <title>成绩单</title> </head> <body> <table border="1" id="myTable"> <tr> <th>学号</th> <th>姓名</th> <th>成绩</th> </tr> <tr> <td>2019001</td> <td>张三</td> <td>96</td> </tr> <tr> <td>2019002</td> <td>李四</td> <td>82</td> </tr> </table> </body> </html>
以上为一个简单的成绩单表格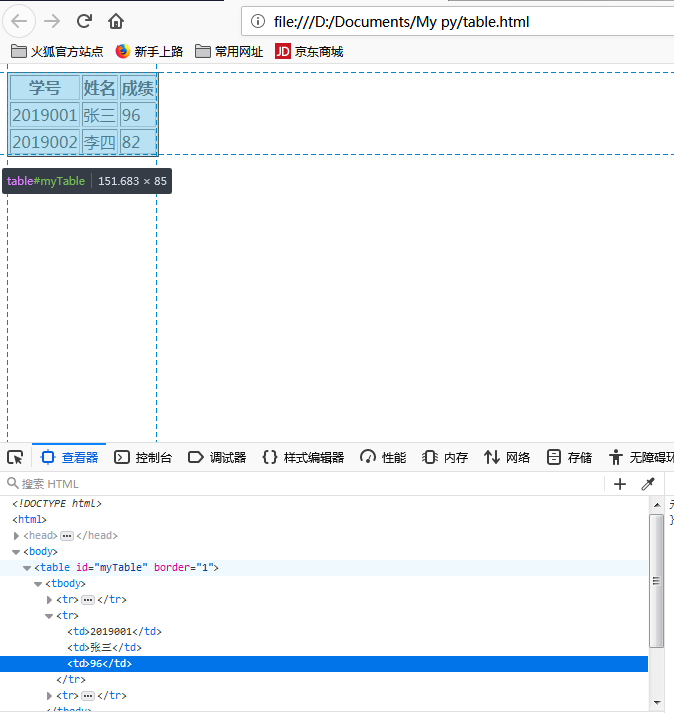
通过selenium+python实现读取table中cell的值的思路
- 方法一:
- 通过id,name等元素属性定位到table标签,即上图中的<table id="my table" border="1">
- 获取table中总的列数,即<tr></tr>的对数
- 获取table中总的行数,即每一个<tr>下的<th>标签数,对应上表的“学号,姓名,成绩”
- 获取table表中单个cell的值
-
from selenium import webdriver import time url='file:///D:/Documents/My%20py/table.html' driver=webdriver.Firefox() driver.get(url) time.sleep(5) #根据id定位到table标签 table1=driver.find_element_by_id('myTable') #根据tag name定位到tr,即表格总行数,包含标题 table_rows=driver.find_elements_by_tag_name('tr') R=len(table_rows) print (R) #在table中找到第一个tr,下面所有的th,即为table总列数 table_cols=table_rows[0].find_elements_by_tag_name('th') S=len(table_cols) print (S) #获取某个单元格的文本值:如获取第二行第三列的text(不算标题行) cell=table_rows[2].find_elements_by_tag_name('td')[2].text print(cell)
- 方法二:根据XPath/CSS直接定位table并读取cell的值
-
-
from selenium import webdriver import time url='file:///D:/Documents/My%20py/table.html' driver=webdriver.Firefox() driver.get(url) time.sleep(5) #使用xpath定位到第二行第三列的text info=driver.find_elements_by_xpath(".//*[@id='myTable']/tbody/tr[3]/td[3]") ''' #使用css定位到第二行第三列的text info=driver.find_elements_by_css_selector('#myTable > tbody:nth-child(1) > tr:nth-child(3) > td:nth-child(3)')''' #上面使用css或者xpath定位获取的都是结果合集,需要指定到具体位置,如info[0] T=info[0].text print (T)
-
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号