
[机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录:
1. 关键参数:k值 && 距离计算方式 && 分类决策规则
2. k=1, 即只取最近点,容易过拟合,k取较大值,容易欠拟合。k值越小,模型越复杂。k = 3 or 5 works well.
3. k近邻算法的一个实现:kd树(k-k维空间,二叉树),分两步:构造kd树--搜索kd树。复杂度O(logN). 下图是一个kd树及对应二叉树:
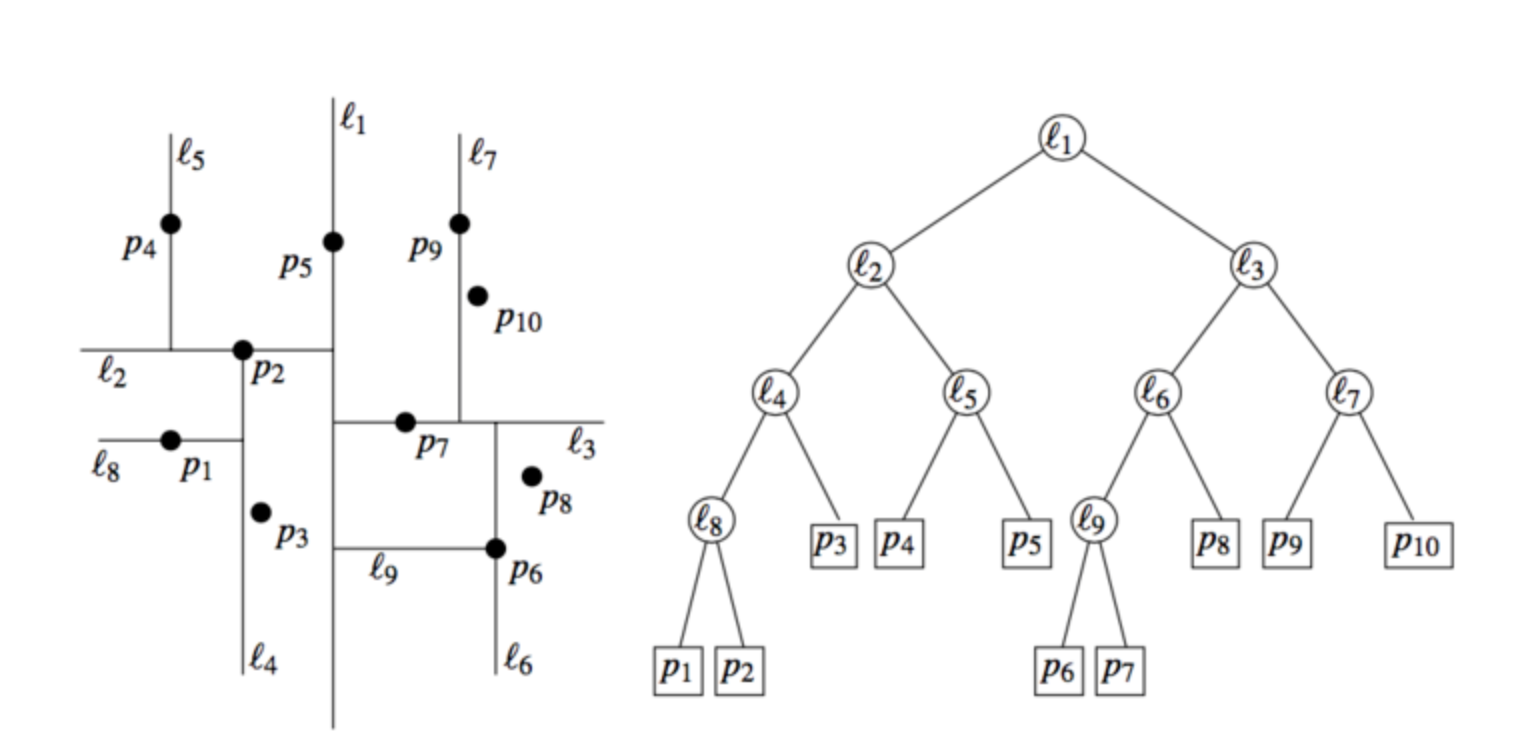
4. 优点:方法简单易理解, 构建模型快。缺点:对稀疏矩阵或者特征维度比较高的情况下表现不好。
参考:
a. 《Introduction to Machine Learning with Python》
b. 《统计学习方法》
c. 十五分钟理解kd树 https://www.jianshu.com/p/ffe52db3e12b
/* 人应该感到渺小,在宇宙面前,在美面前,在智慧面前;
而在人群中,应该意识到自己的尊严。*/

