[转] 关于Multi-head的为什么
参考资料和说明都挺清楚的:
一.Attention is all you need论文中讲模型分为多个头,形成多个子空间,每个头关注不同方面的信息。
如果Multi-Head作用是关注句子的不同方面,那么不同的head就应该关注不同的Token;当然也有可能是关注的pattern相同,但是关注的内容不同,即V不同。
但是大量的paper表明,transformer或Bert的特定层有独特的功能,底层更偏向于关注语法;顶层更偏向于关注语义。
所以对Multi-head而言,同一层Transformer_block关注的方面应该整体是一致的。不同的head关注点也是一样。但是可视化同一层的head后,发现总有那么一两个头独一无二的,和其他头的关注不一样。
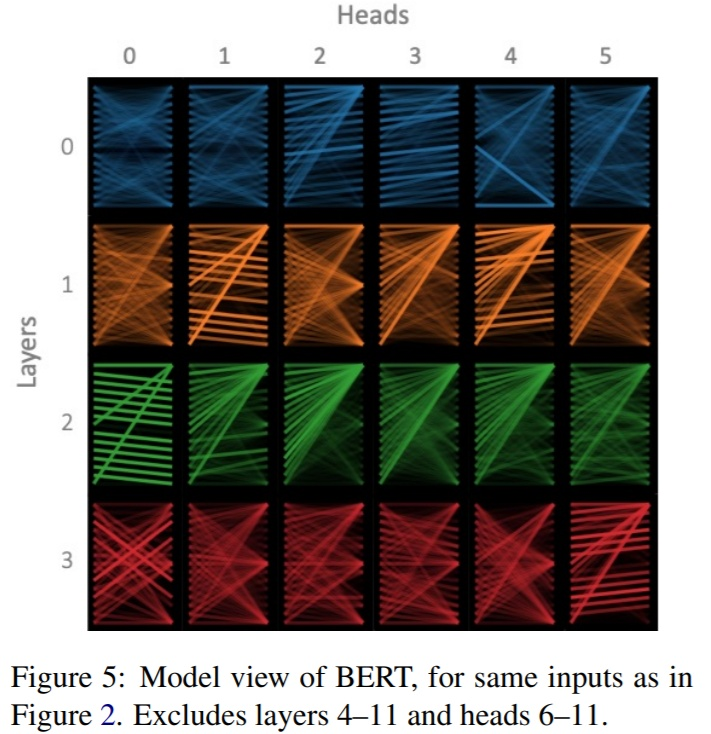
二.问题:
1.在一层中,不同头之间差距有多少(hi度量),这个差距的作用是什么?
2.同一层中,不同头可能对hi带来影响?
3.hi是否随层数的变化而变化?
4.初始化如何影响hi?能否通过初始化控制hi?
三.对于第一个问题前半部分和第三个问题?
如下图:从第一层的深蓝色到第六层的浅蓝色再到第十二层的深红色,如果趋势可信,则能推断:头之间的差距是随着层数的加大而变小。差距变小就说明不同头之间的方差在随着层数的增大而减小;
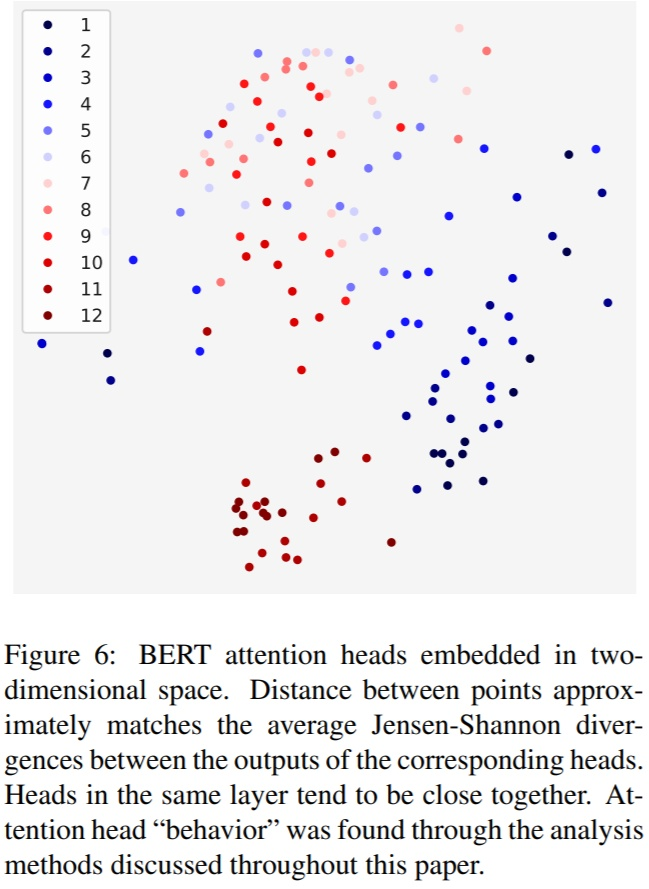
但是这种随着层数变大,不同层头之间的差距在变小,这种差距的变小的作用,还没有人证明解释。
猜测1.:一种可能的解释是,它类似一种 noise,或者 dropout,而不是去关注不同的方面。也就是说,无论多少层,既然都会出现与众不同的头,那么这个(些)头就是去使得模型收敛(效果最优)的结果,反过来说,模型可能认为,全部一样的头不会使效果最优(至少在梯度下降的方法上)。这样的话,把这个(些)头解释为模型的一种 “试探”,或者噪声,是可能合理的。
猜测2:Transformer 对初始化比较敏感,一些初始化点必然导致不同的头,但这样解释就很难从直觉上解释了。
在Attention is all you need论文中,4,6,8个head效果差别都不大。这种差别究竟是多头带来的还是参数量带来的也不确定。
四.对于第四个问题:
https://arxiv.org/pdf/1908.11365.pdf讨论了初始化对 Transformer 各层方差的影响,最终缓解梯度消失的问题。从这个角度讲,Transformer 底层的头方差大是因为 Transformer 存在的梯度消失问题,也就是说,并不是模型自己觉得底层的方差大是好的,而是自己没有办法让它变好。所以,合理的初始化应该可以减少底层头的方差,提高效果。
pic:

五.其他论文:
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned( https://arxiv.org/pdf/1905.09418.pdf)
探究的四个问题:
1.翻译的质量在何种程度上依赖单个头?
2.头的模型是否一致?其中对翻译最重要的是什么模式?
3.哪种 Attention(encoder self-attention, decoder self-attention, encoder-decoder self-attention)对头的数量和所在层数最敏感?
4.能否去掉一些头而不失效果?
结论:
只有一小部分头对翻译是重要的,其他的头都是次要的(可以丢掉)。
重要的头有一种或者多个专有的关注模式。
作者的工作:
1.使用了自信度和LRP(Layer-wise Relevance Propagation)描述头的重要度。结果见1a,1b,2a,2c
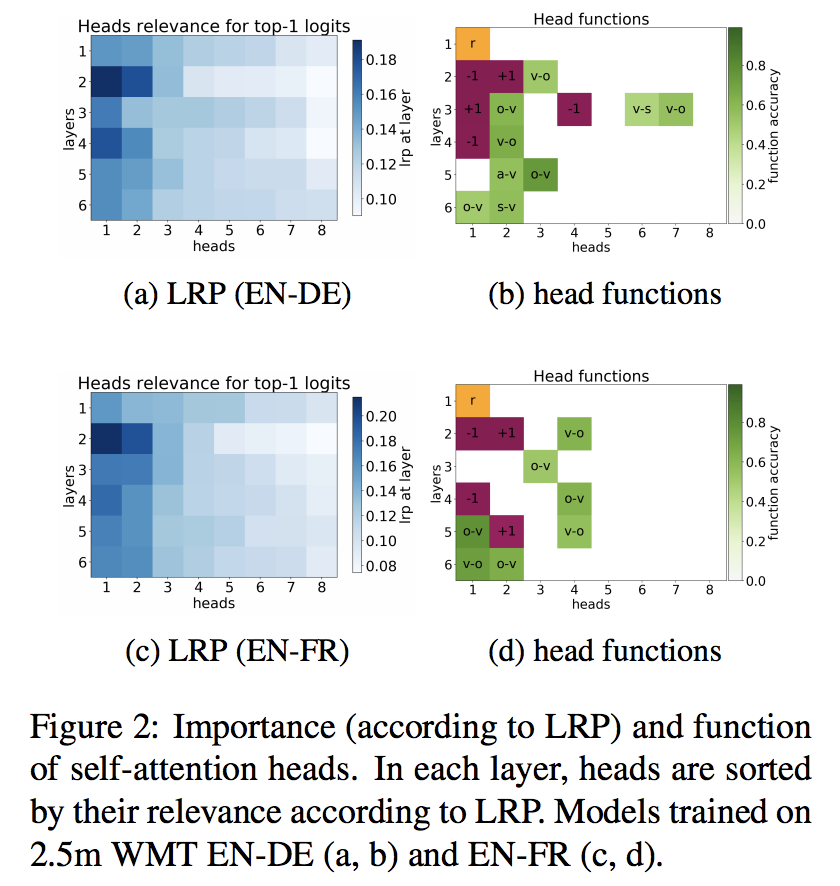
2.考虑了不同头的功能:结果:1c,2b,2d,3,4,5
紫色关注左右的token
绿色关注语法
橙色关注罕见词

结论:
Positional Heads 和高confidence 和LRP相符合
一些头确实编码了语法信息
在所有模型的第一层,总有一个头去关注rare words
3.表明了一些头具有一定的模式和具有可解释性,但是并没有探索头之间的关系。它们是否也有相同的模式,是否是多余的。为此,作者对头进行剪枝。

剪枝 encoder。图 7 展示了对 encoder 剪枝的结果,结果表明剪去大部分头并不会怎么影响结果,剪掉太多才会迅速破坏效果,但这可能是参数量的减少带来的。图 8 是剪枝后的头的作用分布,可以看到,无论头是多少,这几种功能的头分布是大致相同的,大概都是一个 rare words 头,2:1 的语法:位置头,还有一些不明意义的头。而且,这些不明意义的头是优先被剪去的。


结论:
head数量并不是越多越好,去掉一些头效果依旧有不错的效果(效果些许下降,也许是由于参数量下降引起的) 。作者理解是,当有足够多的head,已经能够关注位置信息,语法信息,关注罕见词的能力了,再多一些头,可能是enhance也可能是noise。
六.其他相关paper:
A Multiscale Visualization of Attention in the Transformer Model https://arxiv.org/pdf/1906.05714.pdf
What Does BERT Look At? An Analysis of BERT’s Attention https://arxiv.org/pdf/1906.04341v1.pdf
Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention https://arxiv.org/pdf/1908.11365.pdf
Adaptively Sparse Transformershttps://arxiv.org/pdf/1909.00015.pdf
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned https://arxiv.org/pdf/1905.09418.pdf
————————————————
版权声明:本文为CSDN博主「咕噜咕噜day」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36533552/article/details/102529241

 浙公网安备 33010602011771号
浙公网安备 33010602011771号