[转] 为什么分类问题的损失函数采用交叉熵而不是均方误差MSE?
这篇写的比较详细:
from: https://zhuanlan.zhihu.com/p/35709485
这篇文章中,讨论的Cross Entropy损失函数常用于分类问题中,但是为什么它会在分类问题中这么有效呢?我们先从一个简单的分类例子来入手。
1. 图像分类任务
我们希望根据图片动物的轮廓、颜色等特征,来预测动物的类别,有三种可预测类别:猫、狗、猪。假设我们当前有两个模型(参数不同),这两个模型都是通过sigmoid/softmax的方式得到对于每个预测结果的概率值:
模型1:
| 预测 | 真实 | 是否正确 |
|---|---|---|
| 0.3 0.3 0.4 | 0 0 1 (猪) | 正确 |
| 0.3 0.4 0.3 | 0 1 0 (狗) | 正确 |
| 0.1 0.2 0.7 | 1 0 0 (猫) | 错误 |
模型1对于样本1和样本2以非常微弱的优势判断正确,对于样本3的判断则彻底错误。
模型2:
| 预测 | 真实 | 是否正确 |
|---|---|---|
| 0.1 0.2 0.7 | 0 0 1 (猪) | 正确 |
| 0.1 0.7 0.2 | 0 1 0 (狗) | 正确 |
| 0.3 0.4 0.3 | 1 0 0 (猫) | 错误 |
模型2对于样本1和样本2判断非常准确,对于样本3判断错误,但是相对来说没有错得太离谱。
好了,有了模型之后,我们需要通过定义损失函数来判断模型在样本上的表现了,那么我们可以定义哪些损失函数呢?
1.1 Classification Error(分类错误率)
最为直接的损失函数定义为:
模型1:
模型2:
我们知道,模型1和模型2虽然都是预测错了1个,但是相对来说模型2表现得更好,损失函数值照理来说应该更小,但是,很遗憾的是, 并不能判断出来,所以这种损失函数虽然好理解,但表现不太好。
1.2 Mean Squared Error (均方误差)
均方误差损失也是一种比较常见的损失函数,其定义为:
模型1:
对所有样本的loss求平均:
模型2:
对所有样本的loss求平均:
我们发现,MSE能够判断出来模型2优于模型1,那为什么不采样这种损失函数呢?主要原因是在分类问题中,使用sigmoid/softmx得到概率,配合MSE损失函数时,采用梯度下降法进行学习时,会出现模型一开始训练时,学习速率非常慢的情况(MSE损失函数)。
有了上面的直观分析,我们可以清楚的看到,对于分类问题的损失函数来说,分类错误率和均方误差损失都不是很好的损失函数,下面我们来看一下交叉熵损失函数的表现情况。
1.3 Cross Entropy Loss Function(交叉熵损失函数)
1.3.1 表达式
(1) 二分类
在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为 和
,此时表达式为:
其中:
- —— 表示样本
的label,正类为
,负类为
- —— 表示样本
预测为正类的概率
(2) 多分类
多分类的情况实际上就是对二分类的扩展:
其中:
- ——类别的数量
- ——符号函数(
或
),如果样本
的真实类别等于
取
,否则取
- ——观测样本
属于类别
的预测概率
现在我们利用这个表达式计算上面例子中的损失函数值:
模型1:
对所有样本的loss求平均:
模型2:
对所有样本的loss求平均:
可以发现,交叉熵损失函数可以捕捉到模型1和模型2预测效果的差异。
2. 函数性质
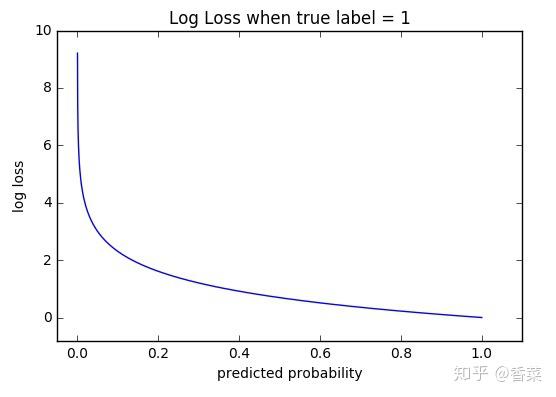
可以看出,该函数是凸函数,求导时能够得到全局最优值。
3. 学习过程
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
我们用神经网络最后一层输出的情况,来看一眼整个模型预测、获得损失和学习的流程:
- 神经网络最后一层得到每个类别的得分scores(也叫logits);
- 该得分经过sigmoid(或softmax)函数获得概率输出;
- 模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算。
学习任务分为二分类和多分类情况,我们分别讨论这两种情况的学习过程。
3.1 二分类情况
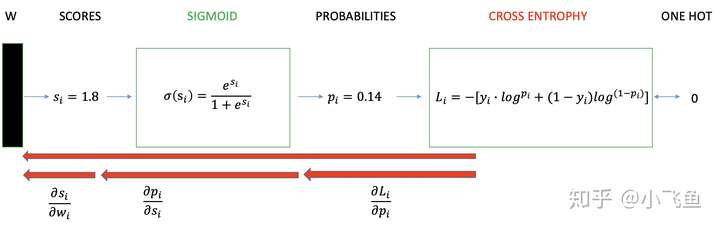 二分类交叉熵损失函数学习过程
二分类交叉熵损失函数学习过程
如上图所示,求导过程可分成三个子过程,即拆成三项偏导的乘积:
3.1.1 计算第一项: ![[公式]](https://www.zhihu.com/equation?tex=%5Cfrac%7B%5Cpartial+L_i%7D%7B%5Cpartial+p_i%7D)
- 表示样本
预测为正类的概率
- 为符号函数,样本
为正类时取
,否则取
3.1.2 计算第二项: ![[公式]](https://www.zhihu.com/equation?tex=%5Cfrac%7B%5Cpartial+p_i%7D%7B%5Cpartial+s_i%7D+)
这一项要计算的是sigmoid函数对于score的导数,我们先回顾一下sigmoid函数和分数求导的公式:
3.1.3 计算第三项: ![[公式]](https://www.zhihu.com/equation?tex=%5Cfrac%7B%5Cpartial+s_i%7D%7B%5Cpartial+w_i+%5C%5C%7D)
一般来说,scores是输入的线性函数作用的结果,所以有:
3.1.4 计算结果 ![[公式]](https://www.zhihu.com/equation?tex=%5Cfrac%7B%5Cpartial+L_i%7D%7B%5Cpartial+w_i%7D)
可以看到,我们得到了一个非常漂亮的结果,所以,使用交叉熵损失函数,不仅可以很好的衡量模型的效果,又可以很容易的的进行求导计算。
3.2 多分类情况
待整理
4. 优缺点
4.1 优点
在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:一、学习率;二、偏导值。其中,学习率是我们需要设置的超参数,所以我们重点关注偏导值。从上面的式子中,我们发现,偏导值的大小取决于 和
,我们重点关注后者,后者的大小值反映了我们模型的错误程度,该值越大,说明模型效果越差,但是该值越大同时也会使得偏导值越大,从而模型学习速度更快。所以,使用逻辑函数得到概率,并结合交叉熵当损失函数时,在模型效果差的时候学习速度比较快,在模型效果好的时候学习速度变慢。
4.2 缺点
Deng [4]在2019年提出了ArcFace Loss,并在论文里说了Softmax Loss的两个缺点:1、随着分类数目的增大,分类层的线性变化矩阵参数也随着增大;2、对于封闭集分类问题,学习到的特征是可分离的,但对于开放集人脸识别问题,所学特征却没有足够的区分性。对于人脸识别问题,首先人脸数目(对应分类数目)是很多的,而且会不断有新的人脸进来,不是一个封闭集分类问题。
另外,sigmoid(softmax)+cross-entropy loss 擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。基于这个问题的优化有很多,比如对softmax进行改进,如L-Softmax、SM-Softmax、AM-Softmax等。
5. 参考
[1]. 博客 - 神经网络的分类模型 LOSS 函数为什么要用 CROSS ENTROPY
[2]. 博客 - Softmax as a Neural Networks Activation Function
[3]. 博客 - A Gentle Introduction to Cross-Entropy Loss Function
[4]. Deng, Jiankang, et al. "Arcface: Additive angular margin loss for deep face recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
这篇也不错
from: https://zhuanlan.zhihu.com/p/104130889
假设给定输入为x,label为y,其中y的取值为0或者1,是一个分类问题。我们要训练一个最简单的Logistic Regression来学习一个函数f(x)使得它能较好的拟合label,如下图所示。

其中 ,
。
也即,我们要学的函数 。目标为使a(x)与label y越逼近越好。用哪种Loss来衡量这个逼近呢?我们可以回忆下交叉熵Loss和均方差Loss定义是什么:
- 最小均方误差,MSE(Mean Squared Error)Loss
- 交叉熵误差CEE(Cross Entropy Error)Loss
我们想衡量模型输出a和label y的逼近程度,其实这两个Loss都可以。但是为什么Logistic Regression采用的是交叉熵作为损失函数呢?看下这两个Loss function对w的导数,也就是SGD梯度下降时,w的梯度。
- 最小均方差
- 交叉熵
由于,则:
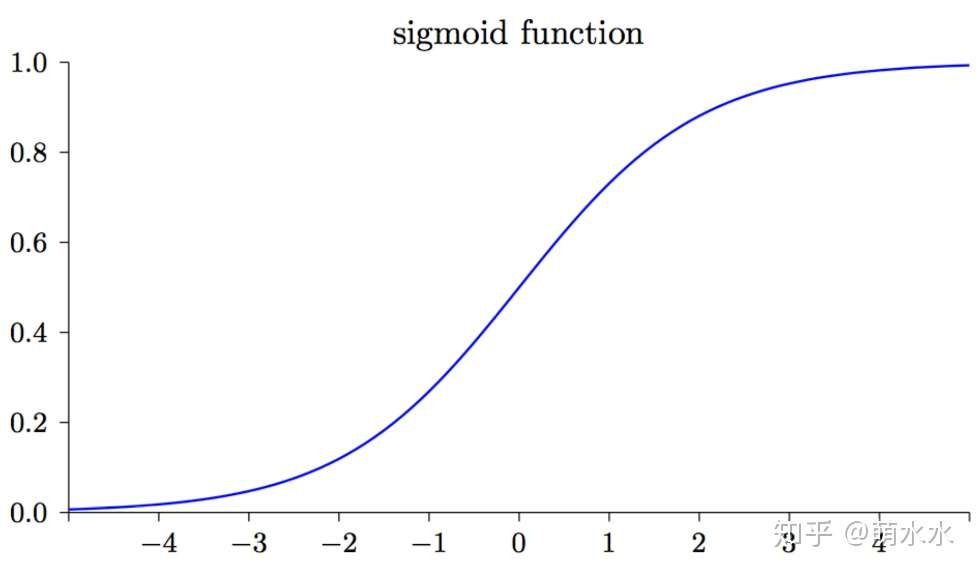
sigmoid函数 如下图所示,可知的导数sigmoid
在输出接近 0 和 1 的时候是非常小的,故导致在使用最小均方差Loss时,模型参数w会学习的非常慢。而使用交叉熵Loss则没有这个问题。为了更快的学习速度,分类问题一般采用交叉熵损失函数。
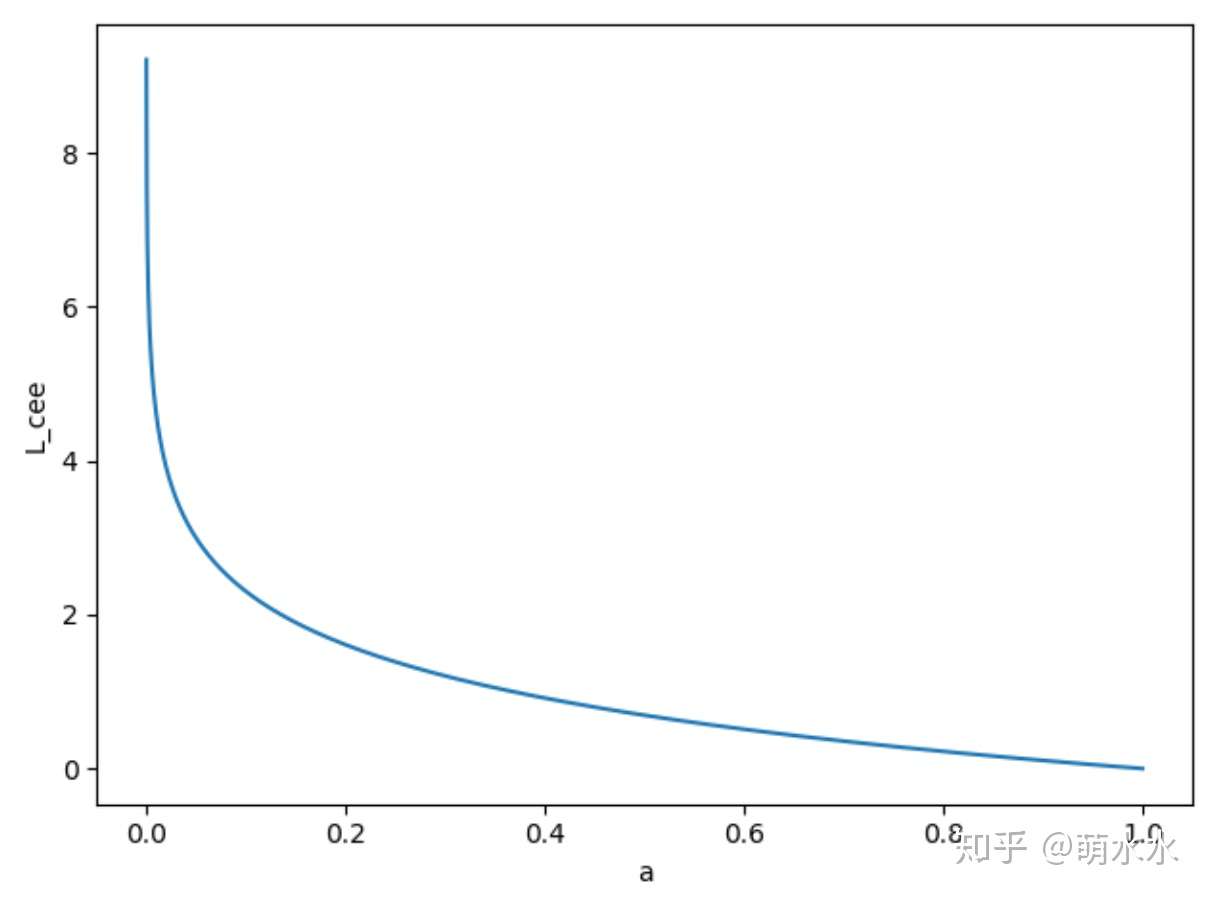
当label = 1,也即 ,交叉熵损失函数
如图所示,可知交叉熵损失函数的值域为