
[转] 各种激活函数对比
常规路径,再过一遍各种激活函数
from: https://zhuanlan.zhihu.com/p/32610035
每个激活函数的输入都是一个数字,然后对其进行某种固定的数学操作。激活函数给神经元引入了非线性因素,如果不用激活函数的话,无论神经网络有多少层,输出都是输入的线性组合。
激活函数的发展经历了Sigmoid -> Tanh -> ReLU -> Leaky ReLU -> Maxout这样的过程,还有一个特殊的激活函数Softmax,因为它只会被用在网络中的最后一层,用来进行最后的分类和归一化。本文简单来梳理这些激活函数是如何一步一步演变而来的。
总结如下,先贴图:
Sigmoid
数学公式:
sigmoid非线性函数的数学公式是
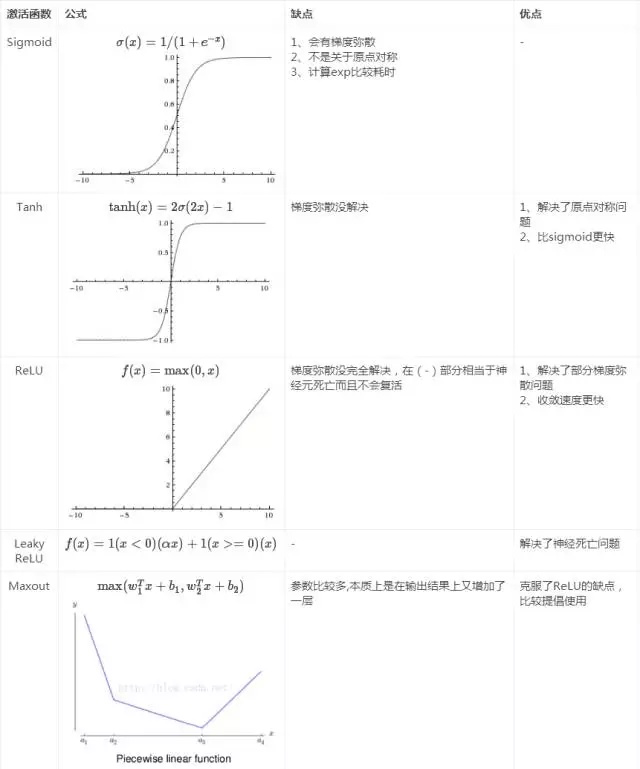
函数图像如下图所示。它输入实数值并将其“挤压”到0到1范围内,适合输出为概率的情况,但是现在已经很少有人在构建神经网络的过程中使用sigmoid。
 Sigmoid函数图像
Sigmoid函数图像
存在问题:
- Sigmoid函数饱和使梯度消失。当神经元的激活在接近0或1处时会饱和,在这些区域梯度几乎为0,这就会导致梯度消失,几乎就有没有信号通过神经传回上一层。
- Sigmoid函数的输出不是零中心的。因为如果输入神经元的数据总是正数,那么关于
的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数,这将会导致梯度下降权重更新时出现z字型的下降。
Tanh
数学公式:
Tanh非线性函数的数学公式是
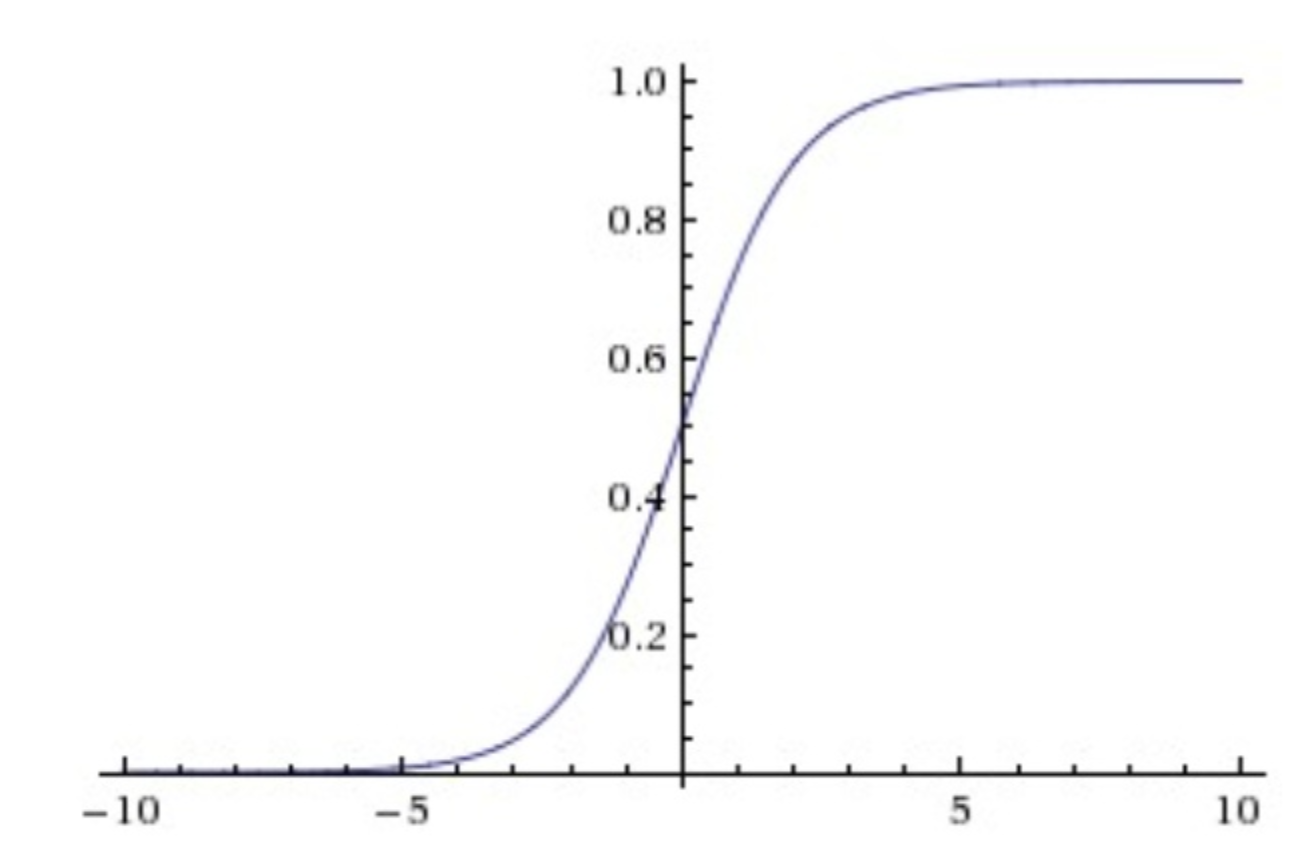
Tanh非线性函数图像如下图所示,它将实数值压缩到[-1,1]之间。
 Tanh函数图像
Tanh函数图像
存在问题:
Tanh解决了Sigmoid的输出是不是零中心的问题,但仍然存在饱和问题。
为了防止饱和,现在主流的做法会在激活函数前多做一步batch normalization,尽可能保证每一层网络的输入具有均值较小的、零中心的分布。
ReLU
数学公式:
函数公式是
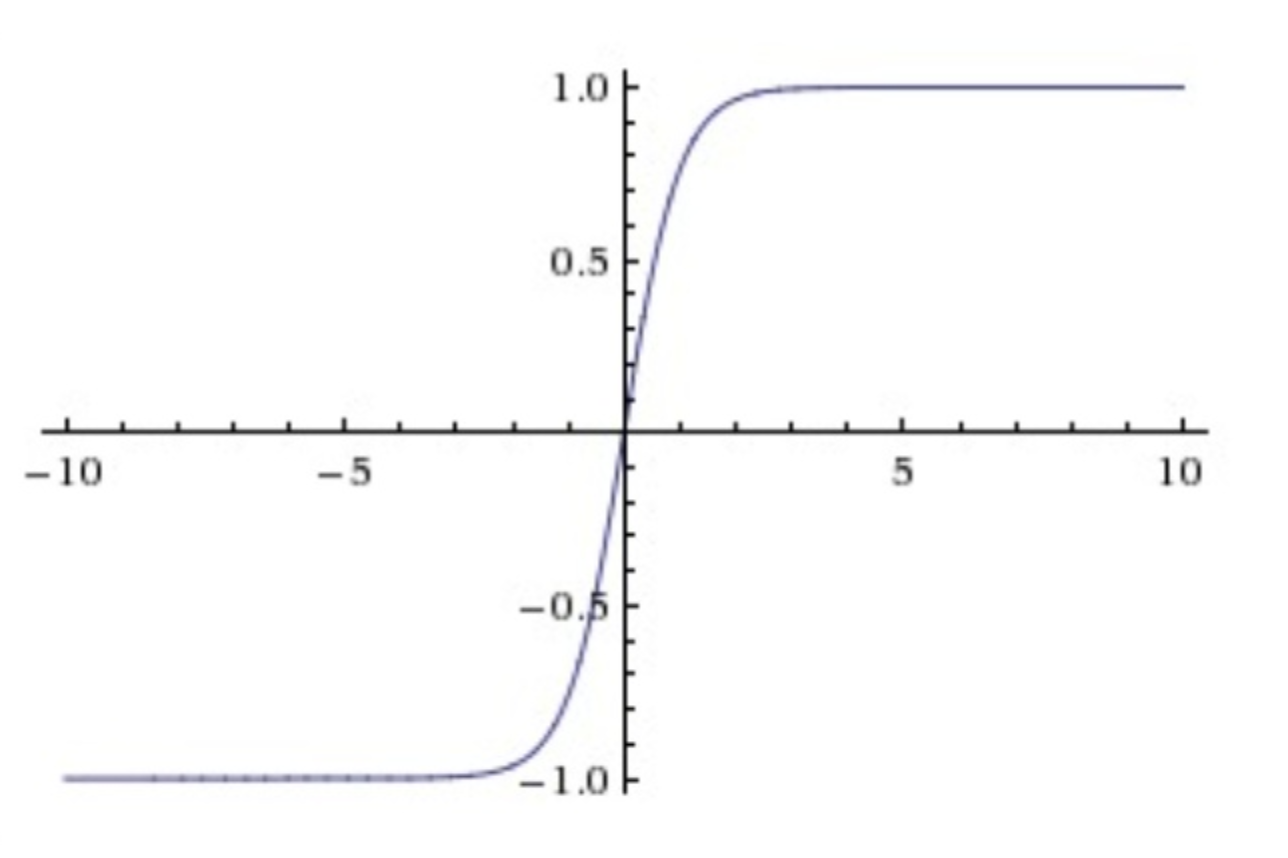
ReLU非线性函数图像如下图所示。相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用;sigmoid和tanh在求导时含有指数运算,而ReLU求导几乎不存在任何计算量。
对比sigmoid类函数主要变化是:
1)单侧抑制;
2)相对宽阔的兴奋边界;
3)稀疏激活性。
 ReLU函数图像
ReLU函数图像
存在问题:
ReLU单元比较脆弱并且可能“死掉”,而且是不可逆的,因此导致了数据多样化的丢失。通过合理设置学习率,会降低神经元“死掉”的概率。
Leaky ReLU
数学公式:
函数公式是
其中 是很小的负数梯度值,比如0.01,Leaky ReLU非线性函数图像如下图所示。这样做目的是使负轴信息不会全部丢失,解决了ReLU神经元“死掉”的问题。更进一步的方法是PReLU,即把
当做每个神经元中的一个参数,是可以通过梯度下降求解的。
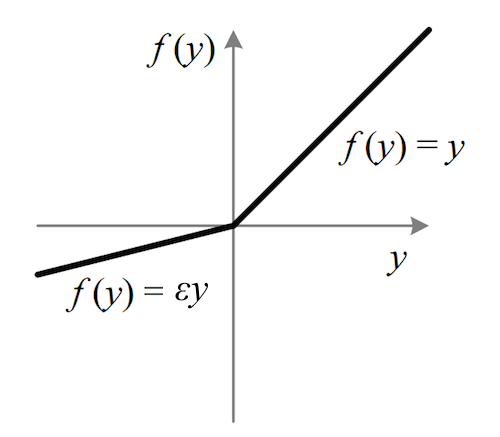 Leaky ReLU函数图像
Leaky ReLU函数图像
Maxout
数学公式:
Maxout是对ReLU和leaky ReLU的一般化归纳,函数公式是
Maxout非线性函数图像如下图所示。Maxout具有ReLU的优点,如计算简单,不会 saturation,同时又没有ReLU的一些缺点,如容易go die。
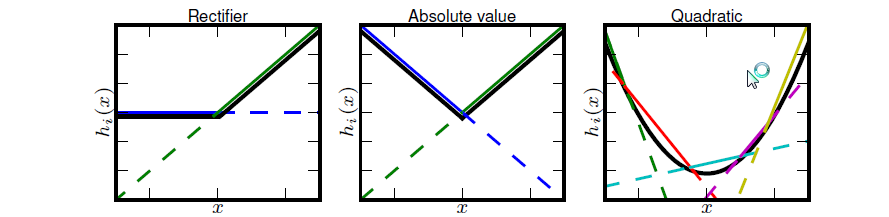 Maxout函数图像
Maxout函数图像
存在问题:
每个神经元的参数double,这就导致整体参数的数量激增。
Softmax
数学公式:
Softmax用于多分类神经网络输出,目的是让大的更大。函数公式是
示意图如下。
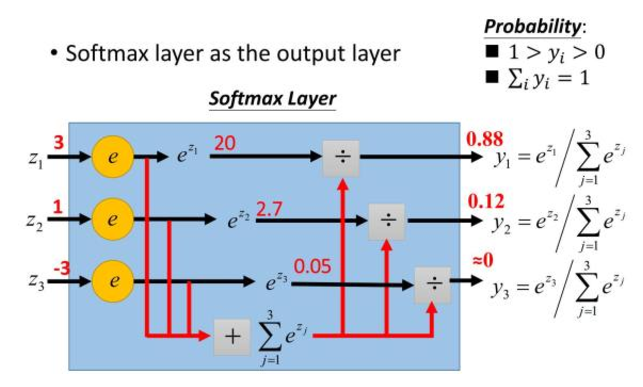 Softmax示意图
Softmax示意图
Softmax是Sigmoid的扩展,当类别数k=2时,Softmax回归退化为Logistic回归。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号