
[转] 理解信息熵&交叉熵&KL散度
from: https://www.jianshu.com/p/43318a3dc715
and: https://www.zhihu.com/question/41252833
作者:Peiwen
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
讨论这个问题需要从香农的信息熵开始。
小明在学校玩王者荣耀被发现了,爸爸被叫去开家长会,心里悲屈的很,就想法子惩罚小明。到家后,爸爸跟小明说:既然你犯错了,就要接受惩罚,但惩罚的程度就看你聪不聪明了。这样吧,我们俩玩猜球游戏,我拿一个球,你猜球的颜色,我可以回答你任何问题,你每猜一次,不管对错,你就一个星期不能玩王者荣耀,当然,猜对,游戏停止,否则继续猜。当然,当答案只剩下两种选择时,此次猜测结束后,无论猜对猜错都能100%确定答案,无需再猜一次,此时游戏停止(因为好多人对策略1的结果有疑问,所以请注意这个条件)。
题目1:爸爸拿来一个箱子,跟小明说:里面有橙、紫、蓝及青四种颜色的小球任意个,各颜色小球的占比不清楚,现在我从中拿出一个小球,你猜我手中的小球是什么颜色?
为了使被罚时间最短,小明发挥出最强王者的智商,瞬间就想到了以最小的代价猜出答案,简称策略1,小明的想法是这样的。

在这种情况下,小明什么信息都不知道,只能认为四种颜色的小球出现的概率是一样的。所以,根据策略1,1/4概率是橙色球,小明需要猜两次,1/4是紫色球,小明需要猜两次,其余的小球类似,所以小明预期的猜球次数为:
H = 1/4 * 2 + 1/4 * 2 + 1/4 * 2 + 1/4 * 2 = 2
题目2:爸爸还是拿来一个箱子,跟小明说:箱子里面有小球任意个,但其中1/2是橙色球,1/4是紫色球,1/8是蓝色球及1/8是青色球。我从中拿出一个球,你猜我手中的球是什么颜色的?
小明毕竟是最强王者,仍然很快得想到了答案,简称策略2,他的答案是这样的。
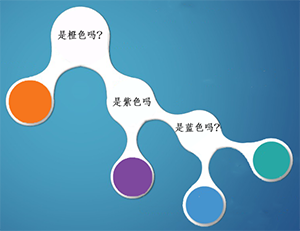
在这种情况下,小明知道了每种颜色小球的比例,比如橙色占比二分之一,如果我猜橙色,很有可能第一次就猜中了。所以,根据策略2,1/2的概率是橙色球,小明需要猜一次,1/4的概率是紫色球,小明需要猜两次,1/8的概率是蓝色球,小明需要猜三次,1/8的概率是青色球,小明需要猜三次,所以小明猜题次数的期望为:
H = 1/2 * 1 + 1/4 * 2 + 1/8 * 3 + 1/8 * 3= 1.75
题目3:其实,爸爸只想让小明意识到自己的错误,并不是真的想罚他,所以拿来一个箱子,跟小明说:里面的球都是橙色,现在我从中拿出一个,你猜我手中的球是什么颜色?
最强王者怎么可能不知道,肯定是橙色,小明需要猜0次。
上面三个题目表现出这样一种现象:针对特定概率为p的小球,需要猜球的次数 = ,例如题目2中,1/4是紫色球,
= 2 次;1/8是蓝色球,
= 3次,这叫做一个事件得自信息(self-information)。那么,针对整个系统,有多种可能发生的事件,预期的猜题次数为:
,这就是信息熵,上面三个题目的预期猜球次数都是由这个公式计算而来,第一题的信息熵为2,第二题的信息熵为1.75,最三题的信息熵为1 *
= 0 。
当然,信息量和信息熵都有着严格的定义,这边简单介绍下。在信息论中,信息量,或者叫自信息(self-information),其代表一个事件所能够提供信息的多少,具体计算方式为: 。其是基于这样的想法进行信息量化的,一个不太可能发生的事件发生了,要比一个非常可能发生的事件提供更多的信息(概率小,log值高)。但是,自信息只能衡量单个事件的信息量,而整个系统呈现的是一个分布(例如题目一的分布就是1/4,1/4,1/4,1/4),因此在信息论中,使用信息熵来对概率分布进行量化,即
那么信息熵代表着什么含义呢?
信息熵代表的是随机变量或整个系统的不确定性,熵越大,随机变量或系统的不确定性就越大。上面题目1的熵 > 题目2的熵 > 题目3的熵。在题目1中,小明对整个系统一无所知,只能假设所有的情况出现的概率都是均等的,此时的熵是最大的。题目2中,小明知道了橙色小球出现的概率是1/2及其他小球各自出现的概率,说明小明对这个系统有一定的了解,所以系统的不确定性自然会降低,所以熵小于2。题目3中,小明已经知道箱子中肯定是橙色球,爸爸手中的球肯定是橙色的,因而整个系统的不确定性为0,也就是熵为0。所以,在什么都不知道的情况下,熵会最大,针对上面的题目1~~题目3,这个最大值是2,除此之外,其余的任何一种情况,熵都会比2小。
所以,每一个系统都会有一个真实的概率分布,也叫真实分布,题目1的真实分布为(1/4,1/4,1/4,1/4),题目2的真实分布为(1/2,1/4,1/8,1/8),而根据真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性,而这个代价大小就是信息熵,记住,信息熵衡量了系统的不确定性,而我们要消除这个不确定性,所要付出的【最小努力】(猜题次数、编码长度等)的大小就是信息熵。具体来讲,题目1只需要猜两次就能确定任何一个小球的颜色,题目2只需要猜测1.75次就能确定任何一个小球的颜色。
现在回到题目2,假设小明只是钻石段位而已,智商没王者那么高,他使用了策略1,即
爸爸已经告诉小明这些小球的真实分布是(1/2,1/4, 1/8,1/8),但小明所选择的策略却认为所有的小球出现的概率相同,相当于忽略了爸爸告诉小明关于箱子中各小球的真实分布,而仍旧认为所有小球出现的概率是一样的,认为小球的分布为(1/4,1/4,1/4,1/4),这个分布就是非真实分布。此时,小明猜中任何一种颜色的小球都需要猜两次,即1/2 * 2 + 1/4 * 2 + 1/8 * 2 + 1/8 * 2 = 2。
很明显,针对题目2,使用策略1是一个坏的选择,因为需要猜题的次数增加了,从1.75变成了2。因此,当我们知道根据系统的真实分布制定最优策略去消除系统的不确定性时,我们所付出的努力是最小的,但并不是每个人都和最强王者一样聪明,我们也许会使用其他的策略(非真实分布)去消除系统的不确定性,就好比如我将策略1用于题目2(原来这就是我在白银的原因),那么,当我们使用非最优策略消除系统的不确定性,所需要付出的努力的大小我们该如何去衡量呢?
这就需要引入交叉熵,其用来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。
正式的讲,交叉熵的公式为: ,其中
表示真实分布,
表示非真实分布。例如上面所讲的将策略1用于题目2,真实分布
, 非真实分布
,交叉熵为
,比最优策略的1.75来得大。
因此,交叉熵越低,这个策略就越好,最低的交叉熵也就是使用了真实分布所计算出来的信息熵,因为此时 ,交叉熵 = 信息熵。这也是为什么在机器学习中的分类算法中,我们总是最小化交叉熵,因为交叉熵越低,就证明由算法所产生的策略最接近最优策略,也间接证明我们算法所算出的非真实分布越接近真实分布。
最后,我们如何去衡量不同策略之间的差异呢?这就需要用到相对熵,其用来衡量两个取值为正的函数或概率分布之间的差异,即:
KL(f(x) || g(x)) =
现在,假设我们想知道某个策略和最优策略之间的差异,我们就可以用相对熵来衡量这两者之间的差异。即,相对熵 = 某个策略的交叉熵 - 信息熵(根据系统真实分布计算而得的信息熵,为最优策略),公式如下:
KL(p || q) = H(p,q) - H(p) =
所以将策略1用于题目2,所产生的相对熵为2 - 1.75 = 0.25.
Kullback-Leibler Divergence,即K-L散度,是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。
K-L散度定义见文末附录1。另外在附录5中解释了为什么在深度学习中,训练模型时使用的是Cross Entropy 而非K-L Divergence。
我们从下面这个问题出发思考K-L散度。
假设我们是一群太空科学家,经过遥远的旅行,来到了一颗新发现的星球。在这个星球上,生存着一种长有牙齿的蠕虫,引起了我们的研究兴趣。我们发现这种蠕虫生有10颗牙齿,但是因为不注意口腔卫生,又喜欢嚼东西,许多蠕虫会掉牙。收集大量样本之后,我们得到关于蠕虫牙齿数量的经验分布,如下图所示


这些数据很有价值,但是也有点问题。我们距离地球🌍太远了,把这些概率分布数据发送回地球过于昂贵。还好我们是一群聪明的科学家,用一个只有一两个参数的简单模型来近似原始数据会减小数据传送量。最简单的近似模型是均分布,因为蠕虫牙齿不会超过10颗,所以有11个可能值,那蠕虫的牙齿数量概率都为 1/11。分布图如下:

显然我们的原始数据并非均分布的,但也不是我们已知的分布,至少不是常见的分布。作为备选,我们想到的另一种简单模型是二项式分布binomial distribution。蠕虫嘴里面共有n=10个牙槽,每个牙槽出现牙齿与否为独立事件,且概率均为p。则蠕虫牙齿数量即为期望值E[x]=n*p,真实期望值即为观察数据的平均值,比如说5.7,则p=0.57,得到如下图所示的二项式分布:

对比一下原始数据,可以看出均分布和二项分布都不能完全描述原始分布。

可是,我们不禁要问,哪一种分布更加接近原始分布呢?
已经有许多度量误差的方式存在,但是我们所要考虑的是减小发送的信息量。上面讨论的均分布和二项式分布都把问题规约到只需要两个参数,牙齿数量和概率值(均分布只需要牙齿数量即可)。那么哪个分布保留了更多的原始数据分布的信息呢?这个时候就需要K-L散度登场了。
数据的熵
K-L散度源于信息论。信息论主要研究如何量化数据中的信息。最重要的信息度量单位是熵Entropy,一般用H表示。分布的熵的公式如下:

上面对数没有确定底数,可以是2、e或10,等等。如果我们使用以2为底的对数计算H值的话,可以把这个值看作是编码信息所需要的最少二进制位个数bits。上面空间蠕虫的例子中,信息指的是根据观察所得的经验分布给出的蠕虫牙齿数量。计算可以得到原始数据概率分布的熵值为3.12 bits。这个值只是告诉我们编码蠕虫牙齿数量概率的信息需要的二进制位bit的位数。
可是熵值并没有给出压缩数据到最小熵值的方法,即如何编码数据才能达到最优(存储空间最优)。优化信息编码是一个非常有意思的主题,但并不是理解K-L散度所必须的。熵的主要作用是告诉我们最优编码信息方案的理论下界(存储空间),以及度量数据的信息量的一种方式。理解了熵,我们就知道有多少信息蕴含在数据之中,现在我们就可以计算当我们用一个带参数的概率分布来近似替代原始数据分布的时候,到底损失了多少信息。请继续看下节内容。↓↓↓
K-L散度度量信息损失
只需要稍加修改熵H的计算公式就能得到K-L散度的计算公式。设p为观察得到的概率分布,q为另一分布来近似p,则p、q的K-L散度为:

显然,根据上面的公式,K-L散度其实是数据的原始分布p和近似分布q之间的对数差值的期望。如果继续用2为底的对数计算,则K-L散度值表示信息损失的二进制位数。下面公式以期望表达K-L散度:

一般,K-L散度以下面的书写方式更常见:

注:log a - log b = log (a/b)
OK,现在我们知道当用一个分布来近似另一个分布时如何计算信息损失量了。接下来,让我们重新回到最开始的蠕虫牙齿数量概率分布的问题。
对比两种分布
首先是用均分布来近似原始分布的K-L散度:

接下来计算用二项式分布近似原始分布的K-L散度:

通过上面的计算可以看出,使用均分布近似原始分布的信息损失要比用二项式分布近似小。所以,如果要从均分布和二项式分布中选择一个的话,均分布更好些。
散度并非距离
很自然地,一些同学把K-L散度看作是不同分布之间距离的度量。这是不对的,因为从K-L散度的计算公式就可以看出它不符合对称性(距离度量应该满足对称性)。如果用我们上面观察的数据分布来近似二项式分布,得到如下结果:

所以,Dkl (Observed || Binomial) != Dkl (Binomial || Observed)。
也就是说,用p近似q和用q近似p,二者所损失的信息并不是一样的。
使用K-L散度优化模型
前面使用的二项式分布的参数是概率 p=0.57,是原始数据的均值。p的值域在 [0, 1] 之间,我们要选择一个p值,建立二项式分布,目的是最小化近似误差,即K-L散度。那么0.57是最优的吗?
下图是原始数据分布和二项式分布的K-L散度变化随二项式分布参数p变化情况:

通过上面的曲线图可以看出,K-L散度值在圆点处最小,即p=0.57。所以我们之前的二项式分布模型已经是最优的二项式模型了。注意,我已经说了,是而像是模型,这里只限定在二项式模型范围内。
前面只考虑了均分布模型和二项式分布模型,接下来我们考虑另外一种模型来近似原始数据。首先把原始数据分成两部分,1)0-5颗牙齿的概率和 2)6-10颗牙齿的概率。概率值如下:

即,一只蠕虫的牙齿数量
x=i的概率为p/5; x=j的概率为(1-p) / 6,i=0,1,2,3,4,5; j=6,7,8,9,10。Aha,我们自己建立了一个新的(奇怪的)模型来近似原始的分布,模型只有一个参数
p,像前面那样优化二项式分布的时候所做的一样,让我们画出K-L散度值随p变化的情况:

当p=0.47时,K-L值取最小值0.338。似曾相识吗?对,这个值和使用均分布的K-L散度值是一样的(这并不能说明什么)!下面我们继续画出这个奇怪模型的概率分布图,看起来确实和均分布的概率分布图相似:

我们自己都说了,这是个奇怪的模型,在K-L值相同的情况下,更倾向于使用更常见的、更简单的均分布模型。
回头看,我们在这一小节中使用K-L散度作为目标方程,分别找到了二项式分布模型的参数p=0.57和上面这个随手建立的模型的参数p=0.47。是的,这就是本节的重点:使用K-L散度作为目标方程来优化模型。当然,本节中的模型都只有一个参数,也可以拓展到有更多参数的高维模型中。
变分自编码器VAEs和变分贝叶斯法
如果你熟悉神经网络,你肯能已经猜到我们接下来要学习的内容。除去神经网络结构的细节信息不谈,整个神经网络模型其实是在构造一个参数数量巨大的函数(百万级,甚至更多),不妨记为f(x),通过设定目标函数,可以训练神经网络逼近非常复杂的真实函数g(x)。训练的关键是要设定目标函数,反馈给神经网络当前的表现如何。训练过程就是不断减小目标函数值的过程。
我们已经知道K-L散度用来度量在逼近一个分布时的信息损失量。K-L散度能够赋予神经网络近似表达非常复杂数据分布的能力。变分自编码器(Variational Autoencoders,VAEs)是一种能够学习最佳近似数据集中信息的常用方法,Tutorial on Variational Autoencoders 2016是一篇关于VAEs的非常不错的教程,里面讲述了如何构建VAE的细节。 What are Variational Autoencoders? A simple explanation简单介绍了VAEs,Building Autoencoders in Keras介绍了如何利用Keras库实现几种自编码器。
变分贝叶斯方法(Variational Bayesian Methods)是一种更常见的方法。这篇文章介绍了强大的蒙特卡洛模拟方法能够解决很多概率问题。蒙特卡洛模拟能够帮助解决许多贝叶斯推理问题中的棘手积分问题,尽管计算开销很大。包括VAE在内的变分贝叶斯方法,都能用K-L散度生成优化的近似分布,这种方法对棘手积分问题能进行更高效的推理。更多变分推理(Variational Inference)的知识可以访问Edward library for python。
因为本人没有学习过VAE和变分推理,所以本节内容质量无法得到保证,我会联系这方面的朋友来改善本节内容,也欢迎大家在评论区给出建议
译自:Kullback-Leibler Divergence Explained
作者:Will Kurt
If you enjoyed this post please subscribe to keep up to date and follow @willkurt!
If you enjoyed this writing and also like programming languages, you might like the book on Haskell I just finished due in print July 2017 (though nearly all the content is available online today).
附录
-
K-L 散度的定义
 define K-L divergence
define K-L divergence -
计算K-L的注意事项
 notice
notice -
遇到
log 0时怎么办
 example for K-L smoothing
example for K-L smoothing -
信息熵、交叉熵、相对熵



- 信息熵,即熵,香浓熵。编码方案完美时,最短平均编码长度。
- 交叉熵,cross-entropy。编码方案不一定完美时(由于对概率分布的估计不一定正确),平均编码长度。是神经网络常用的损失函数。
- 相对熵,即K-L散度,relative entropy。编码方案不一定完美时,平均编码长度相对于最小值的增加值。
更详细对比,见知乎如何通俗的解释交叉熵与相对熵?
- 为什么在神经网络中使用交叉熵损失函数,而不是K-L散度?
K-L散度=交叉熵-熵,即DKL( p||q )=H(p,q)−H(p)。
在神经网络所涉及到的范围内,H(p)不变,则DKL( p||q )等价H(p,q)。
更多讨论见Why do we use Kullback-Leibler divergence rather than cross entropy in the t-SNE objective function?和Why train with cross-entropy instead of KL divergence in classification?
作者:Aspirinrin
链接:https://www.jianshu.com/p/43318a3dc715
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

