
[转] 自然语言处理全家福:纵览当前NLP中的任务、数据、模型与论文
from: https://zhuanlan.zhihu.com/p/38445982
选自Github,作者:Sebastian Ruder,机器之心编译。
自然语言处理有非常多的子领域,且很多都没有达到令人满意的性能。本文的目的是追踪自然语言处理(NLP)的研究进展,并简要介绍最常见 NLP 任务的当前最佳研究和相关数据集。作者 Sebastian Ruder 在文中覆盖了传统的和核心的 NLP 任务,例如依存句法分析和词性标注。以及更多近期出现的任务,例如阅读理解和自然语言推理。本文最主要的目的是为读者提供基准数据集和感兴趣任务的当前最佳研究的快速概览,作为未来研究的垫脚石。
目录(任务和对应数据集)
1.CCG 超级标记
- CCGBank
2.分块
- Penn Treebank
3.选区解析
- Penn Treebank
4.指代消歧
- CoNLL 2012
5.依存解析
- Penn Treebank
6.对话
- 第二对话状态追踪挑战赛
7.域适应
- 多领域情感数据集
8.语言建模
- Penn Treebank
- WikiText-2
9.机器翻译
- WMT 2014 EN-DE
- WMT 2014 EN-FR
10.多任务学习
- GLUE
11.命名实体识别
- CoNLL2003
12.自然语言推理
- SNLI
- MultiNLI
- SciTail
13.词性标注
- UD
- WSJ
14.阅读理解
- ARC
- CNN/Daily Mail
- QAngaroo
- RACE
- SQuAD
- Story Cloze Test
- Winograd Schema Challenge
15.语义文本相似性
- SentEval
- Quora Question Pairs
16.情感分析
- IMDb
- Sentihood
- SST
- Yelp
17.情感解析
- WikiSQL
18.语义作用标记
- OntoNotes
19.自动摘要
- CNN/Daily Mail
20.文本分类
- AG News
- DBpedia
- TREC
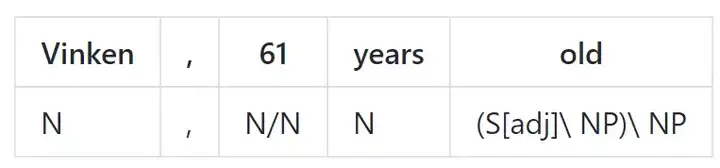
CCG 超级标记
组合范畴语法(CCG; Steedman, 2000)是一种高度词汇化的形式主义。Clark 和 Curran 2007 年提出的标准解析模型使用了超过 400 个词汇语类(或超级标记(supertag)),典型的解析器通常只包含大约 50 个词性标注。
示例:
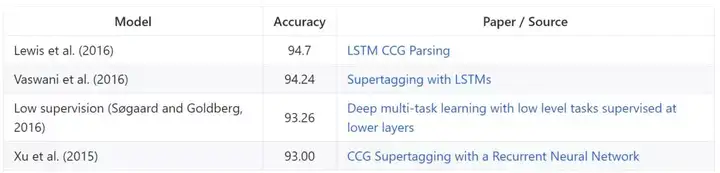
CCGBank
CCGBank 是 CCG 衍生物的语料库,以及从 Hockenmaier 和 Steedman 2007 年提出的 Penn Treebank 中提取的依存结构。第 2-21 部分用于训练,第 00 部分用于开发,第 23 部分用作域内测试集。其性能仅在 425 个最常用的标签上计算。模型基于准确率来评估。
分块
分块(chunking)是解析的浅层形式,可以识别构成合成单元(例如名词词组或动词词组)的标记的连续跨度。
示例:
Penn Treebank-分块
Penn Treebank 通常用于评估分块。第 15-18 部分用于训练,第 19 部分用于开发,第 20 部分用于测试。模型基于 F1 评估。
选区解析
选区解析(constituency parsing)的目的是从根据词组结构语法来表征其合成结构的句子中提取基于选区的解析树。
示例:
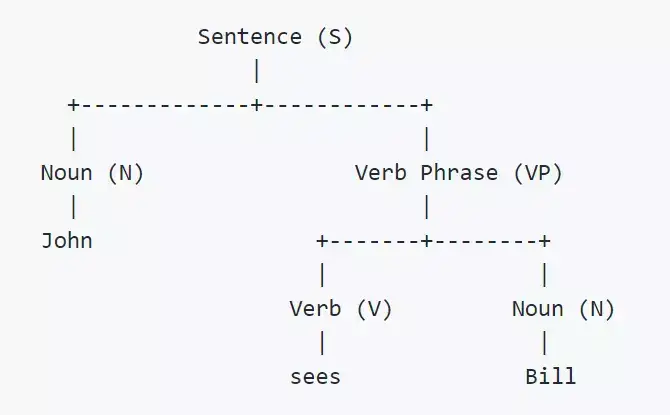
近期发展出来的方法(《Grammar as a Foreign Language》)将解析树转换为按深度优先遍历的序列,从而能应用序列到序列模型到该解析树上。以上解析树的线性化版本表示为:(S (N) (VP V N))。
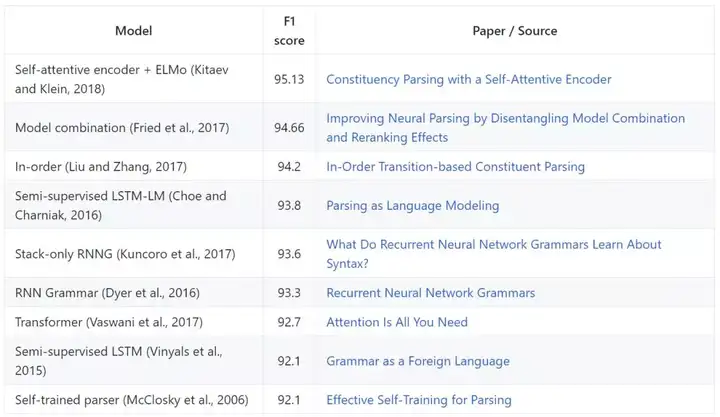
Penn Treebank-选区解析
Penn Treebank 的「Wall Street Journal」部分用于评估选区解析器。第 22 部分用于开发,第 23 部分用于评估。模型基于 F1 评估。以下大多数模型整合了外部数据或特征。要对比仅在 WSJ 上训练的单个模型,参见《Constituency Parsing with a Self-Attentive Encoder》。
指代消歧
指代消歧(coreference resolution)是聚类文本中的涉及相同潜在真实世界实体的提述的任务。
示例:
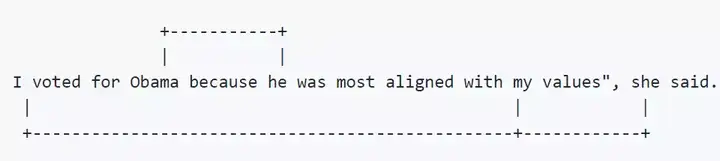
「I」、「my」和「she」属于相同的聚类,「Obama」和「he」属于相同的聚类。
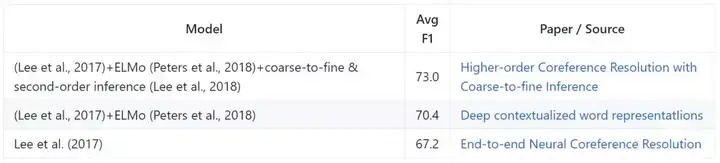
CoNLL 2012
实验是构建在《CoNLL-2012 shared task》的数据集之上的,其使用了 OntoNotes 的共指标注。论文使用官方 CoNLL-2012 评估脚本报告了精度、召回率和 MUC 的 F1、B3 以及 CEAFφ4 指标。主要的评估指标是三个指标的平均 F1。
依存解析
依存解析(dependency parsing)是从表征其语法结构中提取的依存解析,并定义标头词和词之间的关系,来修改那些标头词。
示例:

词之间的关系在句子之上用定向、标记的弧线(从标头词到依存)展示,+表示依存。
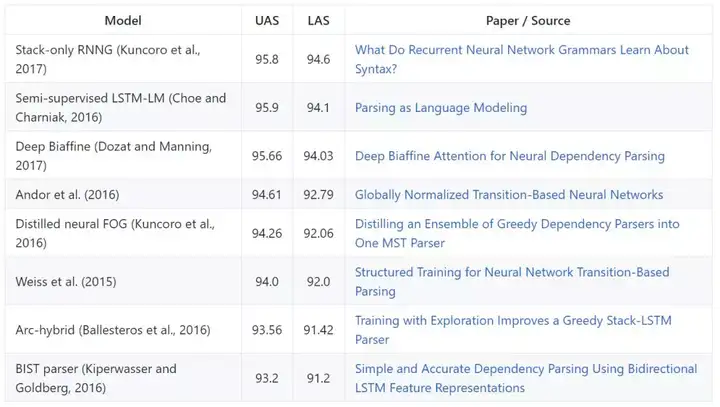
Penn Treebank-依存解析
模型在《Stanford typed dependencies manual》中提出的 Penn Treebank 的 Stanford Dependency 变换和预测词类标记上进行评估。评估指标是未标记依附分数(unlabeled attachment score,UAS)和标记依附分数(LAS)。
对话
众所周知,对话任务是很难评估的。以前的方法曾经使用了人类评估。
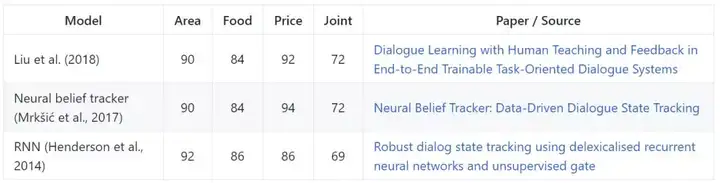
第二对话状态追踪挑战赛
对于目标导向的对话,第二对话状态追踪挑战赛(Second dialog state tracking challenge,DSTSC2)的数据集是一个常用的评估数据集。对话状态追踪涉及确定在对话的每个回合用户在当前对话点的目标的完整表征,其包含了一个目标约束、一系列请求机会(requested slot)和用户的对话行为。DSTC2 聚焦于餐厅搜索领域。模型基于单独的和联合的机会追踪的准确率进行评估。
领域自适应
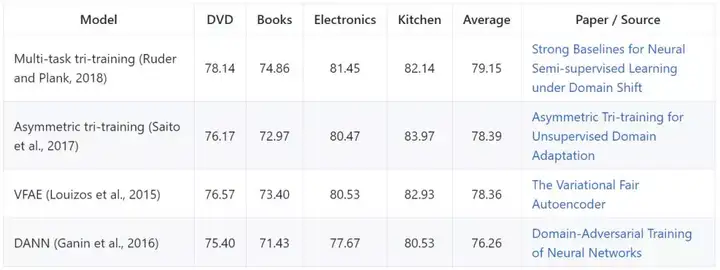
多领域情感数据集
多领域情感数据集(Multi-Domain Sentiment Dataset)是情感分析的领域自适应常用评估数据集。它包含了来自亚马逊的不同产品类别(当成不同领域)的产品评价。这些评价包括星级评定(1 到 5 颗星),通常被转换为二值标签。模型通常在一个和训练时的源域不同的目标域上评估,其仅能访问目标域的未标记样本(无监督域适应)。评估标准是准确率和对每个域取平均的分值。
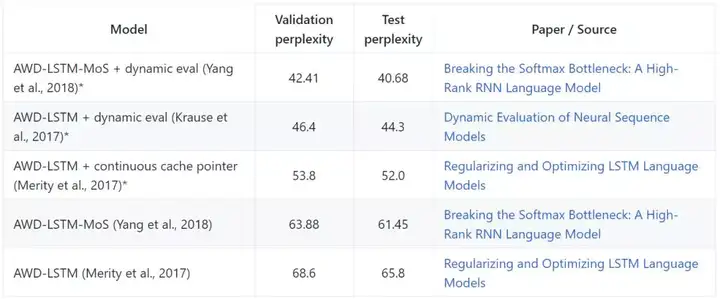
语言建模
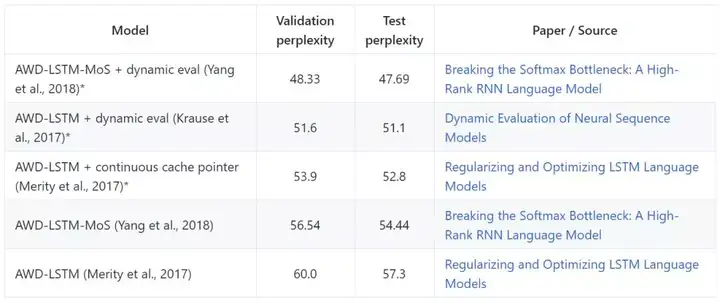
语言建模是预测文本中下一个词的任务。*表示模型使用了动态评估。
Penn Treebank-语言建模
语言建模的常用评估数据集是 Penn Treebank,已经过 Mikolov 等人的预处理(《Recurrent neural network based language model》)。该数据集由 929k 个训练单词、73k 个验证单词和 82k 个测试单词构成。作为预处理的一部分,单词使用小写格式,数字替换成 N,换行符用空格表示,并且所有其它标点都被删除。其词汇是最频繁使用的 10k 个单词,并且剩余的标记用一个标记替代。模型基于困惑度评估,即平均每个单词的对数概率(per-word log-probability),越低越好。
WikiText-2
WikiText-2(《Pointer Sentinel Mixture Models》)相比于 Penn Treebank,其在语言建模中是更接近实际的基准。WikiText-2 由大约两百万个从维基百科文章中提取的单词构成。
机器翻译
机器翻译是将句子从源语言转换为不同的目标语言的任务。带*的结果表示基于 21 个连续评估的平均验证集 BLEU 分数的平均测试分数,正如 Chen 等人的论文《The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation》所报告的。
WMT 2014 EN-DE
模型在第九届统计机器翻译研讨会(VMT2014)的 English-German 数据集上进行评估(根据 BLEU 分数)。
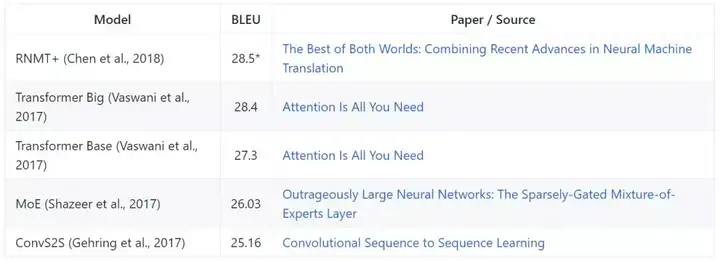
WMT 2014 EN-FR
类似的,在第九届统计机器翻译研讨会(VMT2014)的 English-French 数据集上进行评估(根据 BLEU 分数)。

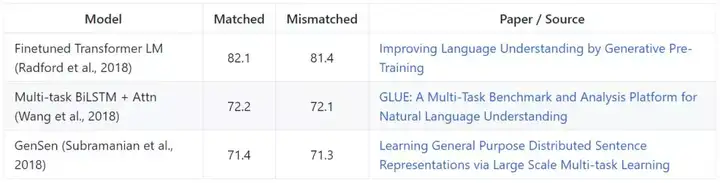
多任务学习
多任务学习的目标是同时学习多个不同的任务,并最大化其中一个或全部任务的性能。
GLUE
通用语言理解评估基准(GLUE)是用于评估和分析多种已有自然语言理解任务的模型性能的工具。模型基于在所有任务的平均准确率进行评估。
当前最佳结果可以在公开 GLUE 排行榜上查看:https://gluebenchmark.com/leaderboard。
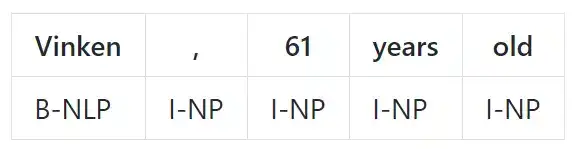
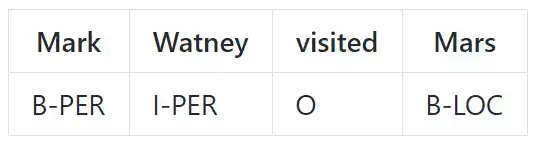
命名实体识别
命名实体识别(NER)是在文本中以对应类型标记实体的任务。常用的方法使用 BIO 记号,区分实体的起始(begining,B)和内部(inside,I)。O 被用于非实体标记。
示例:
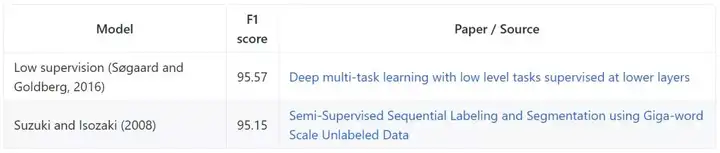
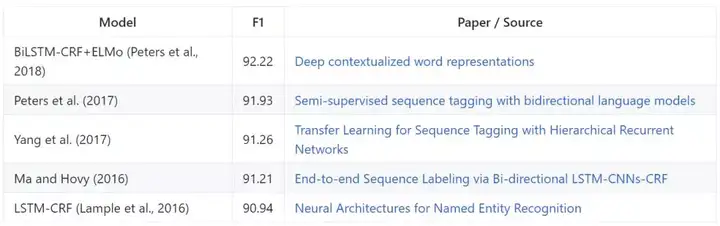
CoNLL 2003
CoNLL 2003 任务包含来自 Reuters RCV1 语料库的新闻通讯文本,以 4 种不同的实体类型进行标注(PER、LOC、ORG、MISC)。模型基于(基于跨度的)F1 评估。
自然语言推理
自然语言推理是给定一个「前提」,确定一个「假设」为真(蕴涵)、假(矛盾)或者不确定(中性)的任务。
示例:
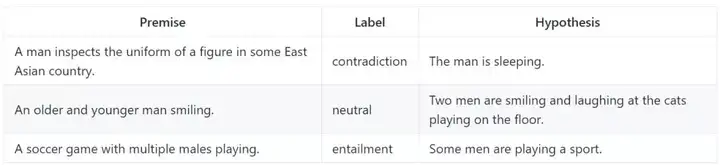
SNLI
斯坦福自然语言推理(SNLI)语料库包含大约 550k 个假设/前提对。模型基于准确率评估。
可以在 SNLI 的网站上查看当前最佳结果:https://nlp.stanford.edu/projects/snli/
MultiNLI
多语型自然语言推理(MultiNLI)语料库包含大约 433k 个假设/前提对。它和 SNLI 语料库相似,但覆盖了多种口头和书面文本的语型(genre),并支持跨语型的评估。数据可以从 MultiNLI 网站上下载:https://www.nyu.edu/projects/bowman/multinli/
语型内(匹配)和跨语型(不匹配)评估的公开排行榜可查看(但这些条目没有对应已发表的论文):
- https://www.kaggle.com/c/multinli-matched-open-evaluation/leaderboard
- https://www.kaggle.com/c/multinli-mismatched-open-evaluation/leaderboard
SciTail
SciTail(《SCITAIL: A Textual Entailment Dataset from Science Question Answering》)导出数据集包含 27k 个条目。和 SNLI、MultiNLI 不同,它不是众包数据集,但是从已有的句子中创建的,假设是从科学问题和对应答案候选中创建的,同时相关网站的来自大型语料库的句子被用作前提。模型基于准确率评估。

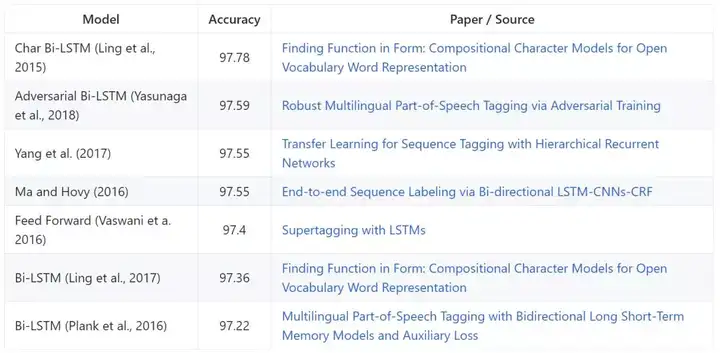
词性标注
词性标注(POS tagging)是一种标注单词在文本中所属成分的任务。词性表示单词所属的类别,相同的类别一般有相似的语法属性。一般英语的词性标注主要有名词、动词、形容词、副词、代词、介词和连词等。
示例:
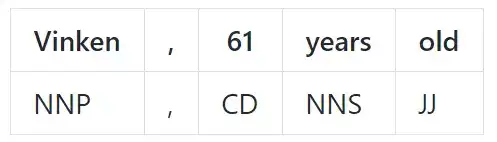
UD
Universal Dependencies(UD)是一个跨语言语法标注的框架,它包含超过 60 多种语言的 100 多个 treebanks。模型一般通过 28 种语言中的平均测试准确率进行评估。

Penn Treebank—POS tagging
用于词性标注的标准数据集是华尔街日报(WSJ)分配的 Penn Treebank,它包含 45 个不同的词性标签。其中 0-18 用于训练、19-21 用于验证其它 22-24 用于测试。模型一般都通过准确率进行评估。
阅读理解/问答任务
问答是一种自动回答问题的任务。大多数当前的数据集都将该任务是为阅读理解,其中问题是段落或文本,而回答通常是文档之间的跨度。UCL 的机器阅读研究组还介绍了阅读理解任务的概览:https://uclmr.github.io/ai4exams/data.html。
ARC
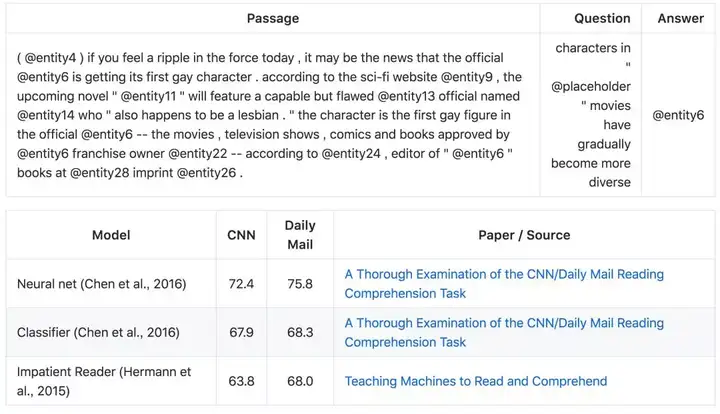
AI2 Reasoning Challenge(ARC)是一个问答数据集,其中它包含了 7787 个真实的小学水平多项选择科学问题。数据集分割为了困难集与简单集,困难集只包含那些基于词检索算法和词共现算法所无法正确回答的问题。模型同样通过准确率评估。
ARC 公开排行榜:http://data.allenai.org/arc/
示例:
QAngaroo
QAngaroo 是两个阅读理解数据集,它们需要结合多个文档的多个推断步骤。第一个数据集 WikiHop 是一个开放领域,且专注于维基文章的数据集,第二个数据集 MedHop 是一个基于 PubMed 论文摘要的数据集。
该数据集的排行榜可参见:http://qangaroo.cs.ucl.ac.uk/leaderboard.html
RACE
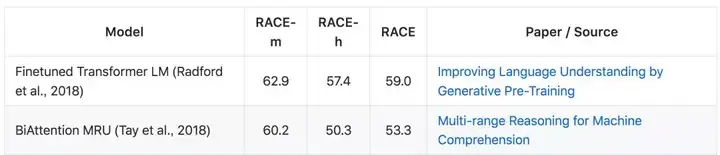
RACE 数据集是一个从中国初中和高中英语测试收集的阅读理解数据集。该数据集包含 28000 多篇短文和近 100000 条问题。模型可基于中学测试(RACE-m)、高中测试(RACE-h)和完整数据集(RACE)使用准确率进行评估。
数据集下载地址:http://www.cs.cmu.edu/~glai1/data/race/
SQuAD
斯坦福问答数据集(SQuAD)是一个阅读理解数据集,它包含由众包基于维基文章提出的问题。回答为对应阅读短文的文本片段。最近 SQuAD 2.0 已经发布了,它引入了与 SQuAD 1.1 中可回答问题类似的不可回答问题,难度高于 SQuAD 1.1。此外,SQuAD 2.0 还获得了 ACL 2018 最佳短论文。
Story Cloze Test
Story Cloze Test 是一个用于故事理解的数据集,它提供了 four-sentence 形式的故事和两个可能的结局,系统将尝试选择正确的故事结局。
Winograd Schema 挑战赛
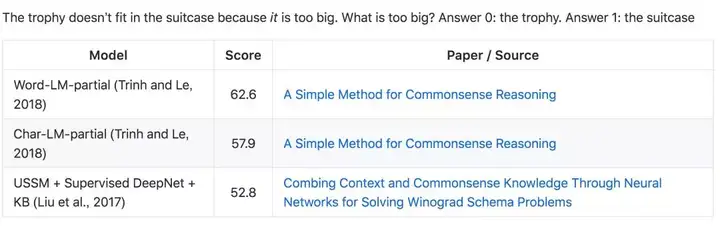
Winograd Schema Challenge 是一个用于常识推理的数据集。它使用 Winograd Schema 问题以要求人称指代消歧:系统必须明确陈述中有歧义指代的先行词。模型同样基于准确率评估。
示例:
语义文本相似性
语义文本相似性在于推断两段文本之间的距离,例如我们可以分配 1 到 5 来表示文本有多么相似。对应任务有释义转换和重复识别。
SentEval
SentEval 是一个用于评估句子表征的工具包,它包含 17 个下游任务,包括一般的语义文本相似性任务。语义文本相似性(STS)从 2012 到 2016(STS12、STS13、STS14、STS15、STS16、STSB)的基准任务基于两个表征之间的余弦相似性度量了两句子之间的相关性。评估标准一般是皮尔森相关性。
SICK 相关性(SICK-R)任务训练一个线性模型以输出 1 到 5 的分数,并指代两句子之间的相关性。相同数据集(SICK-E)能视为使用蕴含标签的二元分类问题。SICK-R 的度量标准也是皮尔森相关性,SICK-E 可以通过文本分类准确度度量。
Microsoft Research Paraphrase Corpus(MRPC)语料库是释义识别的数据集,其中系统旨在识别两个语句是否相互为释义句。评估标准为分类准确度和 F1 分数。
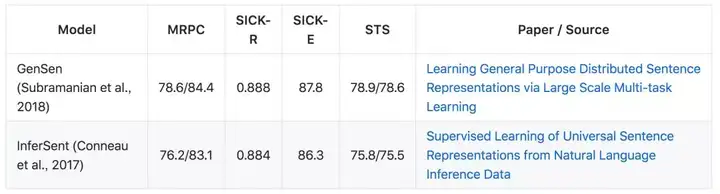
Quora Question Pairs
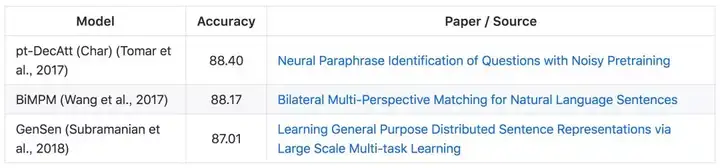
Quora Question Pairs 数据集由 400000 对 Quora 问答组成,系统需要识别一个问题是不是其它问题的副本。模型也是通过准确率度量。
情感分析
情感分析是在给定文本下识别积极或消极情感的任务。
IMDb
IMDb 是一个包含 50000 条评论的二元情感分析数据集,评论都来自与互联网电影数据库(IMDb),且标注为积极或消极两类。模型同样通过准确率进行评估。
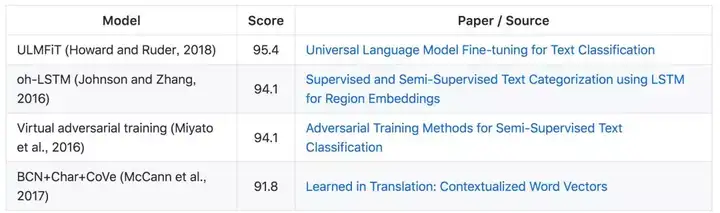
Sentihood
Sentihood 是一个用于针对基于方面的情感分析(TANSA)数据集,它旨在根据具体的方面识别细粒度的情感。数据集包含 5215 个句子,其中 3862 个包含单个目标,其它有多个目标。该任务使用 F1 分数评估检测的方面,而使用准确率评估情感分析。

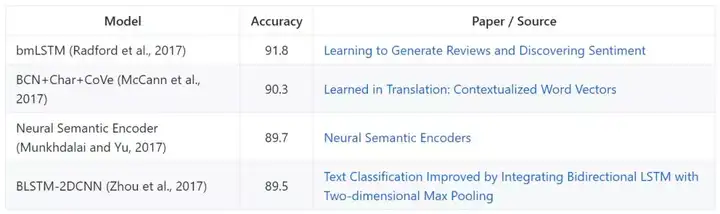
SST
Stanford Sentiment Treebank 包含 215154 条短语,且 11855 条电影评论语句都以解析树的方式有细粒度的情感标注。模型根据准确率评估细粒度和二元分类效果。
细粒度分类:

二元分类:
Yelp
Yelp 评论数据集包含超过 500000 条 Yelp 评论。它们同时有二元和细粒度(5 个类别)级别的数据集,模型通过误差率(1 - 准确率,越低越好)评估。
细粒度分类:

二元分类:

情感解析
情感解析是一种将自然语言转化为正式语义表征的任务。正式表征可能是 SQL 等可执行的语言,或更抽象的 Abstract Meaning Representation(AMR)表征等。
WikiSQL
WikiSQL 数据集包含 87673 个问题样本、SQL 查询语句和由 26521 张表中建立的数据库表。该数据集提供了训练、开发和测试集,因此每一张表只分割一次。模型基于执行结果匹配的准确率进行度量。
示例:

语义功能标注
语义功能标注旨在建模语句的述词论元结构,它经常描述为回答「Who did what to whom」。BIO 符号经常用于语义功能标注。
示例:

OntoNotes—语义功能标注
模型通常通过基于 F1 的 OntoNotes 基准进行评估(《Towards Robust Linguistic Analysis Using OntoNotes》)。

自动摘要
自动摘要是一种总结原文本语义为短文本的任务。
CNN/日常邮件摘要
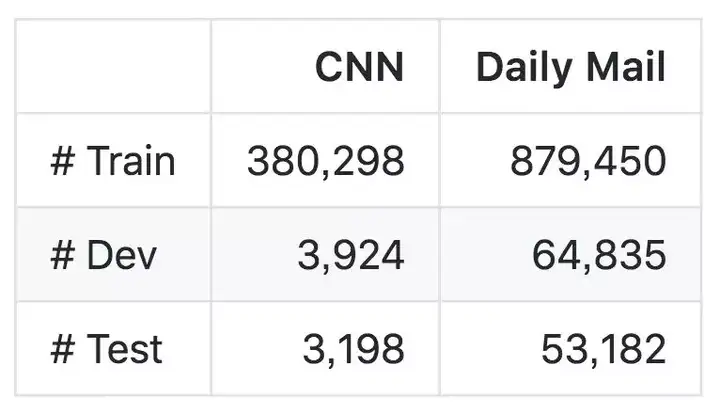
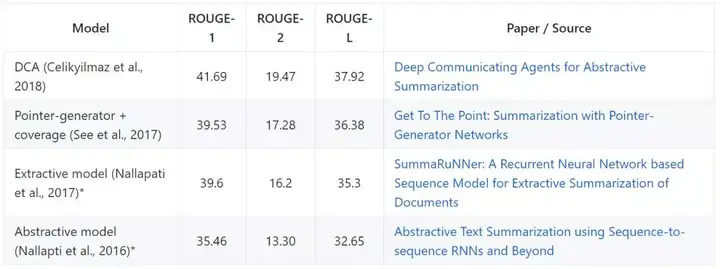
CNN / Daily Mail 数据集是由 Nallapati et al. (2016) 处理并发布,它已经用于评估自动摘要。该数据集包含带有多句摘要(平均 3.75 个句子或 56 个词)的再现新闻文章(平均 781 个词)。经处理的版本包含 287226 个训练对、13368 个验证对和 11490 个测试对。模型基于 ROUGE-1、ROUGE-2 和 ROUGE-L 进行评估,* 表示模型在匿名数据集上进行训练与评估。
文本分类
文本分类是将句子或文本分配合适类别的任务。类别取决于选择的数据集,可以有不同的主题。
AG News
AG News 语料库包含来自「AG's corpus of news articles」的新文章,在 4 个最大的类别上预训练。该数据集包含每个类别的 30000 个训练样本,以及每个类别的 1900 个测试样本。模型基于误差率评估。

DBpedia
DBpedia ontology 数据集包含 14 个非重叠类别的每一个的 40000 个训练样本和 5000 个测试样本。模型基于误差率评估。

TREC
TREC(《The TREC-8 Question Answering Track Evaluation》)是用于问题分类的数据集,包含开放域、基于事实的问题,并被分成广泛的语义类别。它有六类别(TREC-6)和五类别(TREC-50)两个版本。它们都有 4300 个训练样本,但 TREC-50 有更精细的标签。模型基于准确率评估。
TREC-6:

TREC-50:


