Windows11下私有化部署大语言模型实战 langchain+llama2
一、本机环境
1.硬件环境:
CPU:锐龙5600X
显卡:GTX3070
内存:32G
注:硬件配置仅为博主的配置,不是最低要求配置,也不是推荐配置。该配置下计算速度约为40tokens/s。实测核显笔记本(i7-1165g7)也能跑,速度3tokens/s。
2.软件环境:
Windows系统版本:Win11专业版23H2
Python版本:3.11
Cuda版本:12.3.2
VS版本:VS2022 17.8.3
langchain版本:0.0.352
llama-cpp-python版本:0.2.27
二、安装准备工作
1.模型下载
大模型有很多种格式,比如Meta官网下载的pth格式,Huggingface下载的ggml格式、gguf格式等。(博主最开始下的Meta官网的版本,结果发现langchain框架用不了,走了不少弯路)
langchain框架使用的是gguf格式(老版本则是ggml格式 llama.cpp <= 0.1.48),所以我们在Huggingface上下载gguf格式的模型,下载链接为TheBloke/Llama-2-7B-Chat-GGUF at main (huggingface.co),本文选择的模型为llama-2-7b-chat.Q4_K_M.gguf。
不同模型的大小、硬件需求、计算速度、精度不同,具体区别详见网站的README.md文档。
| 模型名称 | 量化方式 | 模型精度 | 大小 | 最小内存要求 | 备注 |
|---|---|---|---|---|---|
| llama-2-7b-chat.Q2_K.gguf | Q2_K | 2 | 2.83 GB | 5.33 GB | 模型最小, 质量最差 - 不推荐 |
| llama-2-7b-chat.Q3_K_S.gguf | Q3_K_S | 3 | 2.95 GB | 5.45 GB | 模型很小, 质量较差 |
| llama-2-7b-chat.Q3_K_M.gguf | Q3_K_M | 3 | 3.30 GB | 5.80 GB | 模型很小, 质量较差 |
| llama-2-7b-chat.Q3_K_L.gguf | Q3_K_L | 3 | 3.60 GB | 6.10 GB | 模型小, 质量略差 |
| llama-2-7b-chat.Q4_0.gguf | Q4_0 | 4 | 3.83 GB | 6.33 GB | 常规;模型小, 质量很差 - 相比更推荐 Q3_K_M |
| llama-2-7b-chat.Q4_K_S.gguf | Q4_K_S | 4 | 3.86 GB | 6.36 GB | 模型小, 质量稍好 |
| llama-2-7b-chat.Q4_K_M.gguf | Q4_K_M | 4 | 4.08 GB | 6.58 GB | 模型中等, 质量中等 - 推荐 |
| llama-2-7b-chat.Q5_0.gguf | Q5_0 | 5 | 4.65 GB | 7.15 GB | 常规; 模型中等, 质量中等 - 相比更推荐 Q4_K_M |
| llama-2-7b-chat.Q5_K_S.gguf | Q5_K_S | 5 | 4.65 GB | 7.15 GB | 模型大, 质量稍好 - 推荐 |
| llama-2-7b-chat.Q5_K_M.gguf | Q5_K_M | 5 | 4.78 GB | 7.28 GB | 模型大, 质量较好 - 推荐 |
| llama-2-7b-chat.Q6_K.gguf | Q6_K | 6 | 5.53 GB | 8.03 GB | 模型很大, 质量很好 |
| llama-2-7b-chat.Q8_0.gguf | Q8_0 | 8 | 7.16 GB | 9.66 GB | 模型很大, 质量最好 - 不推荐 |
2.VS2022安装
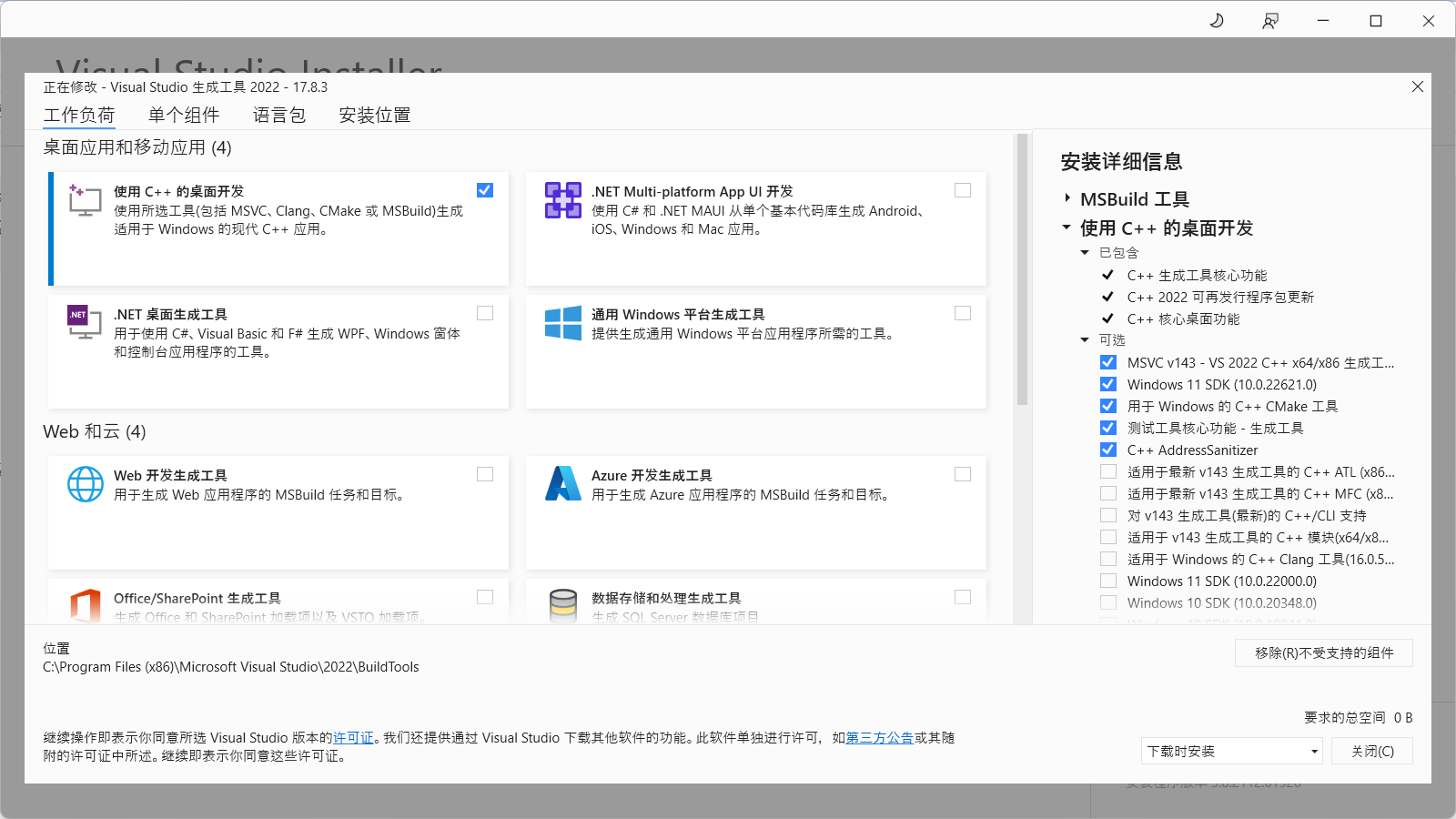
下载Microsoft C++ 生成工具 - Visual Studio,在安装页面勾选使用C++的桌面开发,完成安装。
3.Cuda安装
注:Cuda用于N卡加速模型计算,langchain+llama2支持只用cpu加速,如不用gpu加速可不安装。
下载Cuda完成安装,下载链接CUDA Toolkit 12.3 Update 2 Downloads | NVIDIA Developer
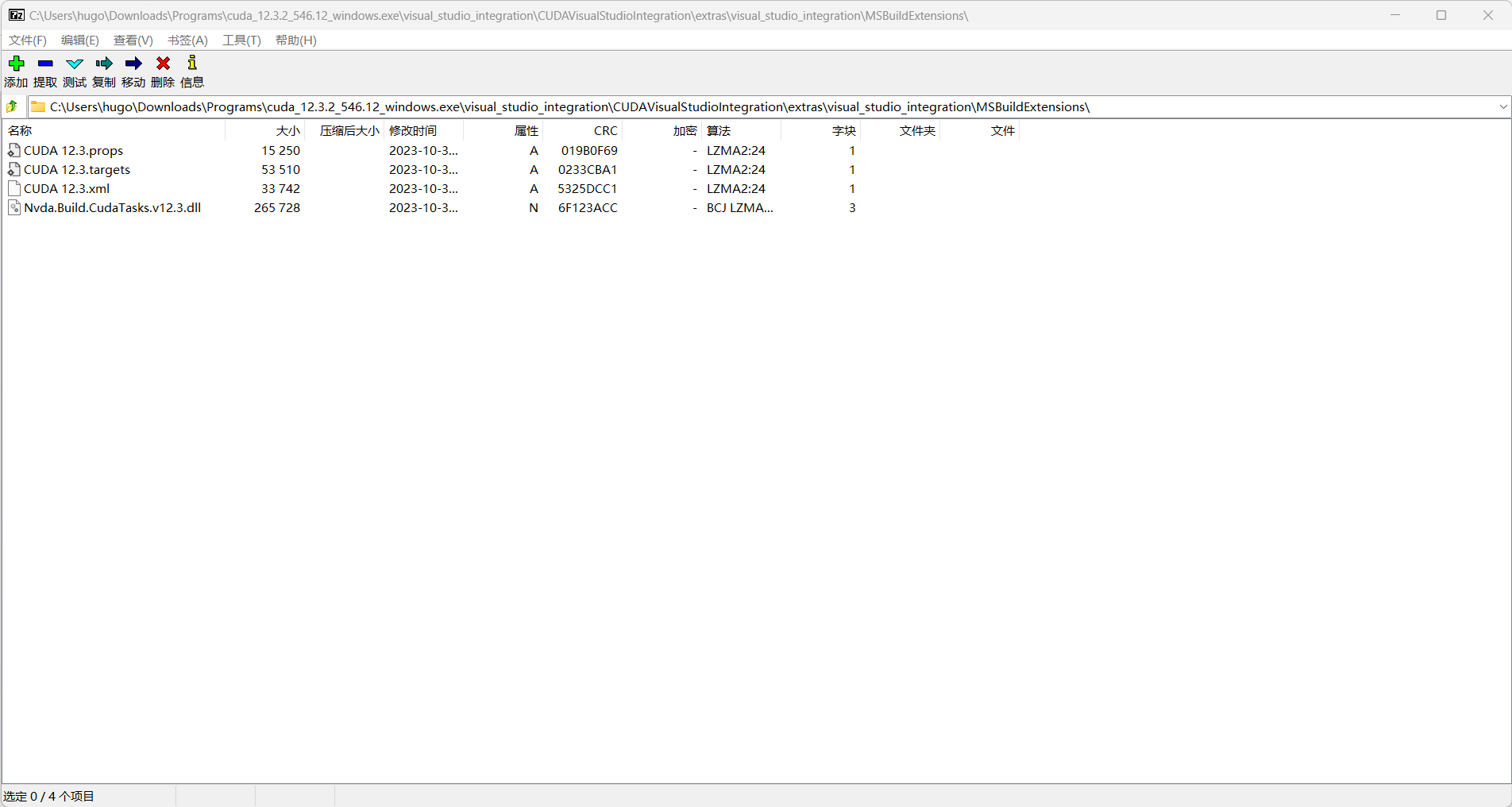
注:后续安装python包llama-cpp-python时可能会遇到No Cuda toolset found问题,需要将Cuda安装包当作压缩包打开,在cuda_12.3.2_546.12_windows.exe\visual_studio_integration\CUDAVisualStudioIntegration\extras\visual_studio_integration\MSBuildExtensions\文件夹中找到以下4个文件,将这4个文件放入VS2022的目录中,博主的路径为C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\MSBuild\Microsoft\VC\v170
4.Python及其余pip包安装
python安装
Python安装方式请查阅其余教程:安装 python at windows - PanPan003 - 博客园 (cnblogs.com)
langchain安装
打开powershell,输入以下命令安装langchain框架
pip install langchain
llama-cpp-python安装
由于我们要用cuda加速模型计算,安装llama-cpp-python前需要配置powelshell环境,使llama-cpp-python启用cuda。如果仅用cpu跑模型,可不输入此行代码,不同配置的详细说明参照abetlen/llama-cpp-python:llama.cpp 的 Python 绑定 (github.com)
$env=CMAKE_ARGS="-DLLAMA_CUBLAS=on"
输入以下命令安装llama-cpp-python包
pip install llama-cpp-python
如果之前已经安装过llama-cpp-python,想用不同的配置方式重新安装,需要在配置好环境变量后输入
pip install --upgrade --force-reinstall llama-cpp-python
三、运行代码
请将模型与python代码文件放在同一目录下,或自行修改目录。
from langchain.callbacks.manager import CallbackManager from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp template = """Question: {question} Answer: Let's work this out in a step by step way to be sure we have the right answer.""" prompt = PromptTemplate(template=template, input_variables=["question"]) # Callbacks support token-wise streaming callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) n_gpu_layers = 40 # Change this value based on your model and your GPU VRAM pool. n_batch = 512 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU. # Make sure the model path is correct for your system! llm = LlamaCpp( model_path="llama-2-7b.Q4_K_M.gguf", n_gpu_layers=n_gpu_layers, n_batch=n_batch, callback_manager=callback_manager, verbose=True, # Verbose is required to pass to the callback manager ) llm_chain = LLMChain(prompt=prompt, llm=llm) question = "What NFL team won the Super Bowl in the year Justin Bieber was born?" llm_chain.run(question)
参考链接:
1.llama2介绍
Llama 2 来袭 - 在 Hugging Face 上玩转它
关于 Llama 2 的一切资源,我们都帮你整理好了 - HuggingFace - 博客园 (cnblogs.com)
2.langchain介绍
LangChain 中文文档 v0.0.291 | 🦜️🔗 Langchain
3.llama-cpp-python编译相关问题
Windows CMake编译错误:No CUDA toolset found解决方法
Error while installing python package: llama-cpp-python - Stack Overflow
c++ - CUDA compile problems on Windows, Cmake error: No CUDA toolset found - Stack Overflow
4.带GUI的实战
本地部署开源大模型的完整教程:LangChain + Streamlit+ Llama - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号