Kubernetes 篇章(六)
 资源清单
资源清单
1. 资源类型
k8s中所有的资源都会抽象为资源,资源实例化之后,叫做对象。
分为以下三种:
- 名称空间级别
- 集群级别
- 元数据型级别
1.1 名称空间级别
-
服务发现及负载均衡型资源( ServiceDiscovery LoadBalance): Service(SVC)、Ingress、……
-
配置与存储型资源: Volume(存储卷)、CSI(容器存储接口,可以扩展各种各样的第三方存储卷)
-
特殊类型的存储卷: ConfigMap(当配置中心来使用的资源类型)、Secret(保存敏感数据)、DownwardAPI(把外部环境中的信息输出给容器)
-
工作负载型资源(workload): Pod(pause)、Replicase、 Deployment、StatefulSet、DaemonSet、Job、Cron Job(Replication Controller在v1.11版本被废弃)
1.2 集群级资源级别
- Namespace
- Node
- Role
- Clusterrole
- RoleBinding
- ClusterRoleBinding
1.3 元数据型资源
-
HPA
-
PodTemplate
-
Limi tRange
2. 资源清单
在k8s中,一般使用yaml格式的文件来创建符合我们预期期望的pod,这样的yaml文件我们一般称为资源清单
2.1 yaml语法格式
是一个可读性高,用来表达数据序列的格式。YAML 的意思其实是:仍是一种标记语言,但为了强调这种语言以数据做为中心,而不是以标记语言为重点。
基本语法
- 缩进时不允许使用Tab键,只允许使用空格
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- # 标识注释,从这个字符一直到行尾,都会被解释器忽略
YAML 支持的数据结构
- 对象:键值对的集合,又称为映射(mapping)、哈希(hashes)、字典(dictionary)
- 数组:一组按次序排列的值,又称为序列(sequence)、列表(list)
- 纯量(scalars):单个的、不可再分的值
对象类型:对象的一组键值对,使用冒号结构表示
name: Steve
age: 18
Yaml 也允许另一种写法,将所有键值对写成一个行内对象
hash: { name: Steve, age: 18 }
数组类型:一组连词线开头的行,构成一个数组
animal
- Cat
- Dog
数组也可以采用行内表示法
animal: [Cat, Dog]
复合结构:对象和数组可以结合使用,形成复合结构
languages:
- Ruby
- Perl
- Python
websites:
YAML: yaml.org
Ruby: ruby-lang.org
Python: python.org
Perl: use.perl.org
纯量:纯量是最基本的、不可再分的值。以下数据类型都属于纯量
1 字符串布尔值整数浮点数 Null
2 时间 日期
数值直接以字面量的形式表示
number: 12.30
布尔值用true和false表示
isSet: true
null用 ~ 表示
parent: ~
时间采用 ISO8601 格式
iso8601: 2001-12-14t21:59:43.10-05:00
日期采用复合 iso8601 格式的年、月、日表示
date: 1976-07-31
YAML允许使用两个感叹号,强制转换数据类型
e: !!str 123
f: !!str true
字符串
字符串默认不使用引号表示
str: 这是一行字符串
如果字符串之中包含空格或特殊字符,需要放在引号之中
str: '内容:字符串'
单引号和双引号都可以使用,双引号不会对特殊字符转义
s1: '内容\n字符串'
s2: "内容\n字符串"
单引号之中如果还有单引号,必须连续使用两个单引号转义
str: 'labor''s day'
字符串可以写成多行,从第二行开始,必须有一个单空格缩进。换行符会被转为空格
str: 这是一段
多行
字符串
多行字符串可以使用|保留换行符,也可以使用>折叠换行
this: |
Foo
Bar
that: >
Foo
Bar
+ 表示保留文字块末尾的换行,- 表示删除字符串末尾的换行
s1: |
Foo
s2: |+
Foo
s3: |-
Foo
2.2 k8s剧本的常用字段
必须存在的属性
| 参数名 | 字段类型 | 说明 |
|---|---|---|
| apiVersion | String | K8S API 的版本,目前基本是v1,可以用 kubectl api-version 命令查询 |
| kind | String | 这里指的是 yaml 文件定义的资源类型和角色, 比如: Pod |
| metadata | Object | 元数据对象,固定值写 metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名Pod的名字 |
| metadata.namespace | String | 元数据对象的命名空间,由我们自身定义 |
| Spec | Object | 详细定义对象,固定值写Spec |
| spec.containers[] | list | 这里是Spec对象的容器列表定义,是个列表 |
| spec.containers[].name | String | 这里定义容器的名字 |
| spec.containers[].image | String | 这里定义要用到的镜像名称 |
主要属性【这些属性比较重要,如果不指定的话系统会自动补充默认值】
| 参数名称 | 字段类型 | 说明 |
|---|---|---|
| spec.containers[].name | String | 这里定义容器的名字 |
| spec.containers[].image | String | 这里定义要用到的镜像名称 |
| spec.containers[].imagePullPolicy | String | 定义镜像拉取策略,有Always、Never、IfNotPresent三个值可选(1)Always:意思是每次都尝试重新拉取镜像(2)Never:表示仅使用本地镜像(3)lfNotPresent:如果本地有镜像就使用本地镜像,没有就拉取在线镜像。上面三个值都没设置的话,默认是Always。 |
| spec.containers[].command[] | List | 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令。 |
| spec.containers[].args[] | List | 指定容器启动命令参数,因为是数组可以指定多个。 |
| spec.containers[].workingDir | String | 指定容器的工作目录,进入容器时默认所在的目录 |
| spec.containers[].volumeMounts[] | List | 指定容器内部的存储卷配置 |
| spec.containers[].volumeMounts[].name | String | 指定可以被容器挂载的存储卷的名称 |
| spec.containers[].volumeMounts[].mountPath | String | 指定可以被容器挂载的存储卷的路径 |
| spec.containers[].volumeMounts[].readOnly | String | 设置存储卷路经的读写模式,true或者false,默认为读写模式 |
| spec.containers[].ports[] | List | 指定容器需要用到的端口列表 |
| spec.containers[].ports[].name | String | 指定端口名称 |
| spec.containers[].ports[].containerPort | String | 指定容器需要监听的端口号 |
| spec.containers[].ports[].hostPort | String | 指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) |
| spec.containers[].ports[].protocol | String | 指定端口协议,支持TCP和UDP,默认值为 TCP |
| spec.containers[].env[] | List | 指定容器运行前需设置的环境变量列表 |
| spec.containers[].env[].name | String | 指定环境变量名称 |
| spec.containers[].env[].value | String | 指定环境变量值 |
| spec.containers[].resources | Object | 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) |
| spec.containers[].resources.limits | Object | 指定设置容器运行时资源的运行上限 |
| spec.containers[].resources.limits.cpu | String | 指定CPU的限制,单位为core数,将用于docker run --cpu-shares参数这里前面文章 Pod资源限制有讲过) |
| spec.containers[].resources.limits.memory | String | 指定MEM内存的限制,单位为MlB、GiB |
| spec.containers[].resources.requests | Object | 指定容器启动和调度时的限制设置 |
| spec.containers[].resources.requests.cpu | String | CPU请求,单位为core数,容器启动时初始化可用数量 |
| spec.containers[].resources.requests.memory | String | 内存请求,单位为MIB、GiB,容器启动的初始化可用数量 |
额外的参数项
| 参数名称 | 字段类型 | 说明 |
|---|---|---|
| spec.restartPolicy | String | 定义Pod的重启策略,可选值为Always、OnFailure,默认值为Always。1.Always:Pod一旦终止运行,则无论容器是如何终止的,kubelet服务都将重启它。2.OnFailure:只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它。3.Never:Pod终止后,kubelet将退出码报告给Master,不会重启该Pod。 |
| spec.nodeSelector | Object | 定义Node的Label过滤标签,以key:value格式指定,选择node节点去运行 |
| spec.imagePullSecrets | Object | 定义pull镜像时使用secret名称,以name:secretkey格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机上启动第二个副本。 |
查看资源有那些资源清单属性,使用以下命令
kubectl explain pod
查看属性说明,使用以下命令
kubectl explain pod.apiVersion
资源清单格式
apiVersion: group/apiversion # 如果没有给定group名称,那么默认为core,可以使用kubectlapi-versions命令获取当前k8s版本上所有的apiversion版本信息(每个版本可能不同)
kind: # 资源类别
metadata: # 资源元数据
name:
namespace:
lables:
annotations: # 主要目的是方便用户阅读查找
spec: # 期望的状态(disired state)
status: # 当前状态,本字段由Kubernetes自身维护,用户不能去定义
资源清单的常用命令
1.获取apiVersion版本信息
kubectl api-versions
2.获取资源的apiVersion的版本信息(以pod为例),该命令同时输出属性设置帮助文档
kubectl explain pod
字段配置格式
apiVersion <string> # 表示字符串类型
metadata <Object> # 表示需要嵌套多层字段
labels <map[string]string> # 表示由k:v组成的映射
finalizers <[]string> # 表示字串列表
ownerReferences <[]Object> # 表示对象列表
hostPID <boolean> # 布尔类型
priority <integer> # 整型
name <string> -required- # 如果类型后面接-required-,表示为必填字段
示例:通过定义清单文件创建Pod
# 当前K8S API 的版本
apiVersion: v1
# 资源类型
kind: Pod
# 元数据
metadata:
# pod名称
name: k8s-apache-pod
# pod的名称空间
namespace: default
# pod的标签
labels:
app: httpd
# 对象的详细信息
spec:
# 容器信息
containers:
# 容器名称
- name: web01
# 这个容器使用的镜像
image: hub.lemon.com/library/httpd:v1
通过yaml文件创建pod
kubectl apply -f xxx.yaml
获取资源的资源配置文件
# 使用 -o 参数 加 yaml,可以将资源的配置以yaml的格式输出出来,也可以使用json,输出为json格式
kubectl get pod {podName} -o yaml
3、pod的生命周期
pod对象自从创建开始至终止退出的时间范围称为生命周期,在这段时间中,pod会处于多种不同的状态,并执行一些操作;其中,创建主容器为必须的操作,其他可选的操作还包括运行初始化容器(init container)、容器启动后钩子(start hook)、容器的存活性探测(liveness probe)、就绪性探测(readiness probe)以及容器终止前狗子(pre stop hook)等,这些操作是否执行则取决于pod的定义
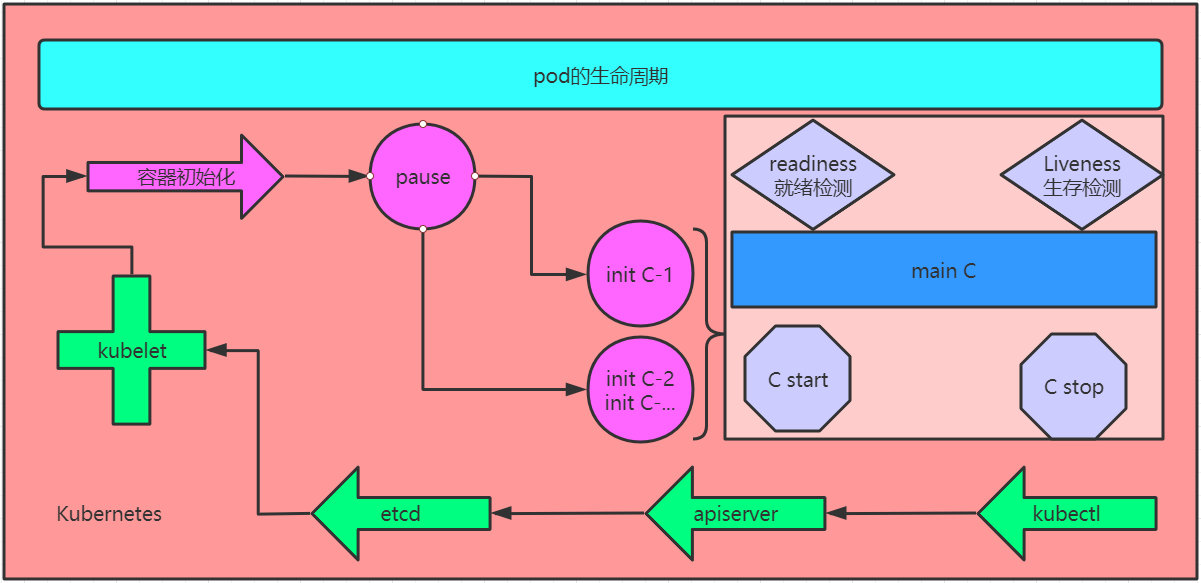
init C & start-stop & readiness & liveness 整体流程:
1、kubectl 调用 apiserver –> etcd –> kubelet –> CRI 进行容器初始化
2、首先会先启动一个pause容器(任何pod启动时都会先pause容器)
3、init C 容器不会伴随整个pod的生命周期;如果是正常退出(0),进入main C,否则(非0),一直重启 失败。
4、进入main C后有两个参数,start:在刚启动时可以允许他执行一个命令,stop:退出时也可以允许他执行一个命令。
5、readiness模板:可以在main C运行的多少秒之后进行就绪检测;检测通过后,pod状态就为running,否则为failed。
6、liveness模板:伴随着整个main C的生命周期,当main C里面的进程 与 liveness检测结果不一致时,就可以执行对应的命令。
3.1 Init C
Pod能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的Init容器
Init容器与普通的容器非常像,除了如下两点:
- Init容器总是运行到成功完成为止
- 每个Init容器都必须在下一个Init容器启动之前成功完成
如果Pod的Init容器失败,Kubernetes会不断地重启该Pod,直到Init容器成功为止。然而,如果Pod对应的restartPolicy为Never,它不会重新启动, 因为Init容器具有与应用程序容器分离的单独镜像,所以它们的启动相关代码具有如下优势:
- 它们可以包含并运行实用工具,但是出于安全考虑,是不建议在应用程序容器镜像中包含这些实用工具的。
- 它们可以包含使用工具和定制化代码来安装,但是不能出现在应用程序镜像中。例如,创建镜像没必要FROM另一个镜像,只需要在安装过程中使用类似sed、awk、python或dig这样的工具。
- 应用程序镜像可以分离出创建和部署的角色,而没有必要联合它们构建一个单独的镜像。
- Init容器使用LinuxNamespace,所以相对应用程序容器来说具有不同的文件系统视图。因此,它们能够具有访问Secret的权限,而应用程序容器则不能。
- 它们必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以Init容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法,直到满足了一组先决条件。
Init C 特殊说明:
- 在Pod启动过程中,Init容器会按顺序在网络和数据卷初始化之后启动。每个容器必须在下一个容器启动之前成功退出。
- 如果由于运行时或失败退出,将导致容器启动失败,它会根据Pod的restartPolicy指定的策略进行重试。然而,如果Pod的restartPolicy设置为Always,Init容器失败时会使用RestartPolicy策略。
- 在所有的Init容器没有成功之前,Pod将不会变成Ready状态。Init容器的端口将不会在Service中进行聚集。正在初始化中的Pod处于Pending状态,但应该会将Initializing状态设置为true。
- 如果Pod重启,所有Init容器必须重新执行。
- 对Init容器spec的修改被限制在容器image字段,修改其他字段都不会生效。更改Init容器的image字段,等价于重启该Pod。
- Init容器具有应用容器的所有字段。除了readinessProbe,因为Init容器无法定义不同于完成(completion)的就绪(readiness)之外的其他状态。这会在验证过程中强制执行。
- 在Pod中的每个app和Init容器的名称必须唯一;与任何其它容器共享同一个名称,会在验证时抛出错误
Init 容器示例
apiVersion: v1
kind: Pod
metadata:
name: lemon-pod
labels:
app: lemon01
spec:
# main容器字段
containers:
- name: main-container
image: busybox:latest
# 容器启动后执行的命令
command: ['sh', '-c', 'echo The main-container is running! && sleep 3600']
# init容器字段
initContainers:
# 第一个init容器
- name: init-container01
image: busybox:latest
command: ['sh', '-c', 'until test -e /live01; do echo waiting for live01; sleep 10; done;']
# 第二个init容器
- name: init-container02
image: busybox:latest
command: ['sh', '-c', 'until test -e /live02; do echo waiting for live02; sleep 10; done;']
$ kubectl exec -it lemon-pod -c init-container01 -- touch /live01
$ kubectl exec -it lemon-pod -c init-container02 -- touch /live02
3.2 容器探针
探针是由kubelet对容器执行的定期诊断。要执行诊断,kubelet调用由容器实现的Handler。
探测方式:
- readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与Pod匹配的所有Service的端点中删除该Pod的IP地址。初始延迟之前的就绪状态默认为Failure。如果容器不提供就绪探针,则默认状态为Success。
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则kubelet会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为Success。
有三种类型的处理程序:
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为0则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的IP地址进行TCP检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的IP地址执行HTTPGet请求。如果响应的状态码大于等于200且小于400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动
Init 容器init 模板检测探针 - 就绪检测
readinessProbe-httpget
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
namespace: default
labels:
app: lemon02
spec:
containers:
- name: readiness-httpget-container
image: httpd:latest
imagePullPolicy: IfNotPresent
readinessProbe:
httpGet:
port: 80
path: /index01.html
initialDelaySeconds: 1
periodSeconds: 3
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-httpget-pod 0/1 Running 0 11m
$ kubectl log -f readiness-httpget-pod
10.244.1.1 - - [25/Feb/2021:08:19:11 +0000] "GET /index01.html HTTP/1.1" 404 196
10.244.1.1 - - [25/Feb/2021:08:19:14 +0000] "GET /index01.html HTTP/1.1" 404 196
$ kubectl exec -it readiness-httpget-pod -- /bin/sh
# echo 'lemon' > /usr/local/apache2/htdocs/index01.html
$ kubectl log -f readiness-httpget-pod
10.244.1.1 - - [25/Feb/2021:08:28:53 +0000] "GET /index01.html HTTP/1.1" 200 6
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-httpget-pod 1/1 Running 0 22m
liveness 检测探针 - 存活检测
livenessProbe-exec
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec-pod
namespace: default
labels:
app: lemon03
spec:
containers:
- name: liveness-exec-container
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "touch /tmp/live ; sleep 60; rm -rf /tmp/live; sleep 3600"]
livenessProbe:
exec:
command: ["test", "-e", "/tmp/live"]
initialDelaySeconds: 1
periodSeconds: 3
$ kubectl get pod -w
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 0 9s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-exec-pod 1/1 Running 1 100s
livenessProbe-httpget
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: httpd:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-httpget-pod 1/1 Running 0 102s
$ kubectl exec -it liveness-httpget-pod -- rm /usr/local/apache2/htdocs/index.html
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-httpget-pod 1/1 Running 1 2m53s
livenessProbe-tcp
apiVersion: v1
kind: Pod
metadata:
name: probe-tcp
spec:
containers:
- name: nginx
image: nginx:latest
livenessProbe:
initialDelaySeconds: 5
timeoutSeconds: 1
tcpSocket:
port: 8080
# 一段时间时候就会自动重启pod,原因nginx容器没开8080端口,tomcat就不会重启
3.3 Pod hook
Podhook(钩子)是由Kubernetes管理的kubelet发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。可以同时为Pod中的所有容器都配置hook。
Hook的类型包括两种:
- exec:执行一段命令
- HTTP:发送HTTP请求
start、stop 动作
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx:latest
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /var/message"]
preStop:
exec:
command: ["/bin/sh", "-c", "echo Hello from the poststop handler > /var/message"]
3.4 Init C & 探针 整合使用
init-readiness-liveness-hook.yaml
apiVersion: v1
kind: Pod
metadata:
name: lemon-pod-irlp
labels:
app: lemon01
spec:
initContainers:
- name: init-container01
image: busybox:latest
command: ['sh', '-c', 'until test -e /live01; do echo waiting for live01; sleep 10; done;']
- name: init-container02
image: busybox:latest
command: ['sh', '-c', 'until test -e /live02; do echo waiting for live02; sleep 10; done;']
containers:
- name: main-container
image: busybox:latest
command: ['sh', '-c', 'echo The main-container is running! && sleep 3600']
imagePullPolicy: IfNotPresent
readinessProbe:
httpGet:
port: 80
path: /index01.html
initialDelaySeconds: 1
periodSeconds: 3
livenessProbe:
exec:
command: ["test", "-e", "/tmp"]
initialDelaySeconds: 1
periodSeconds: 3
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /var/message"]
preStop:
exec:
command: ["/bin/sh", "-c", "echo Hello from the poststop handler > /var/message"]
# init_c
$ kubectl exec -it lemon-pod-irlp -c init-container01 -- touch /live01
$ kubectl exec -it lemon-pod-irlp -c init-container02 -- touch /live02
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
lemon-pod-irlp 0/1 Running 0 51m
# Readiness
$ kubectl describe pod lemon-pod-irlp
Readiness probe failed: Get http://10.244.2.12:80/index01.html
$ kubectl exec -it lemon-pod-irlp -c main-container -- /bin/sh
/ # echo 'lemon' > /var/www/index01.html && httpd -p 80 -h /var/www/ && netstat -anptu | grep httpd
tcp 0 0 :::80 :::* LISTEN 287/httpd
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
lemon-pod-irlp 1/1 Running 0 4m42s
# Liveness
$ kubectl exec -it lemon-pod-irlp -c main-container -- rm -rf /tmp/
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
lemon-pod-irlp 1/1 Running 0 5m35s
lemon-pod-irlp 0/1 Running 1 6m1s
$ kubectl describe pod lemon-pod-irlp
Liveness probe failed:
# Pod hook
$ kubectl exec -it lemon-pod-irlp -- cat /var/message
Hello from the postStart handler
3.5 Pod的相位
Pod的status字段是一个PodStatus对象,PodStatus中有一个phase字段。
无论是手动创建还是通过控制器创建pod,pod对象总是应该处于其生命进程中以下几个相位之一:
挂起(Pending):Pod已被Kubernetes系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度Pod的时间和通过网络下载镜像的时间,这可能需要花点时间。
运行中(Running):该Pod已经绑定到了一个节点上,Pod中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
成功(Succeeded):Pod中的所有容器都被成功终止,并且不会再重启。
失败(Failed):Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
未知(Unknown):因为某些原因无法取得Pod的状态,通常是因为与Pod所在主机通信失败。
4、controllers 控制器
kubernetes不会直接创建pod,而是通过controller来管理pod的,所以controller负责维护集群的状态,比如故障检测、自动扩展、滚动更新。
Kubernetes中会有很多的controller(控制器),这些就相当于一个状态机(快照),用来控制Pod的具体状态和行为。
1. ReplicationController
ReplicationController(RC)用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的 Pod 来替代;而如果异常多出来的容器也会自动回收;
2. ReplicaSet
在新版本的 Kubernetes 中建议使用 ReplicaSet来取代 ReplicationController 。ReplicaSet 跟ReplicationController 没有本质的不同,只是名字不一样,并且 ReplicaSet 支持集合式的 selector;
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: web
template:
metadata:
labels:
tier: web
spec:
containers:
- name: nginx
image: nginx:latest
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80
$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend-d8rs5 1/1 Running 0 29s tier=web
frontend-gczvb 1/1 Running 0 29s tier=web
frontend-twj7z 1/1 Running 0 29s tier=web
$ kubectl label pod frontend-d8rs5 tier=lemon --overwrite=true
pod/frontend-d8rs5 labeled
$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend-d8rs5 1/1 Running 0 3m3s tier=lemon
frontend-gczvb 1/1 Running 0 3m3s tier=web
frontend-mrm8n 1/1 Running 0 10s tier=web
frontend-twj7z 1/1 Running 0 3m3s tier=web
$ kubectl delete pod --all
pod "frontend-d8rs5" deleted
pod "frontend-gczvb" deleted
pod "frontend-mrm8n" deleted
pod "frontend-twj7z" deleted
$ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
frontend-26xlj 1/1 Running 0 11s tier=web
frontend-m4vhl 1/1 Running 0 11s tier=web
frontend-zs9tk 1/1 Running 0 11s tier=web
# 删除 RS
$ kubectl delete rs frontend -n default
3. Deployment
Deployments(无状态,守护进程类,只关注群体不关注个体)
- 一个 Deployment 控制器为 Pods和 ReplicaSets 提供声明式的更新能力。
- 虽然 ReplicaSet可以独立使用,但一般还是建议使用 Deployment来自动管理ReplicaSe,这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSe不支持rolling-update 但 Deployment支持)。
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 (declarative) 方法,用来替代以前的ReplicationController 来方便的管理应用。典型的应用场景包括;
- 定义 Deployment 来创建 Pod 和 ReplicaSet
- 应用扩容和缩容
- 滚动升级和回滚
- 暂停和继续 Deployment
3.1 创建一个 deployment 对象
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: web
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 62s
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-687dc75df7 3 3 3 65s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-687dc75df7-88tkk 1/1 Running 0 68s
nginx-deployment-687dc75df7-b6whp 1/1 Running 0 68s
nginx-deployment-687dc75df7-ljh46 1/1 Running 0 68s
3.2 Deployment 扩容缩
$ kubectl scale deployment nginx-deployment --replicas=5
deployment.extensions/nginx-deployment scaled
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-687dc75df7-88tkk 1/1 Running 0 7m22s
nginx-deployment-687dc75df7-b6whp 1/1 Running 0 7m22s
nginx-deployment-687dc75df7-ljh46 1/1 Running 0 7m22s
nginx-deployment-687dc75df7-rnjzt 1/1 Running 0 8s
nginx-deployment-687dc75df7-wfx74 1/1 Running 0 8s
$ kubectl scale deployment nginx-deployment --replicas=2
deployment.extensions/nginx-deployment scaled
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-687dc75df7-88tkk 1/1 Running 0 8m18s
nginx-deployment-687dc75df7-ljh46 1/1 Running 0 8m18s
如果集群支持 horizontal pod autoscaling 的话,还可以为Deployment设置自动扩展
kubectl autoscale deployment nginx-deployment --min=10--max=15--cpu-percent=80
3.3 滚动升级和回滚
Deployment 更新策略
Deployment 可以保证在升级时只有一定数量的 Pod 是 down 的。默认的,它会确保至少有比期望的Pod数量少一个是up状态(最多一个不可用)。
Deployment 同时也可以确保只创建出超过期望数量的一定数量的 Pod。默认的,它会确保最多比期望的Pod数量多一个的 Pod 是 up 的(最多1个 surge )。
未来的 Kuberentes 版本中,将从1-1变成25%-25% 。
# 滚动升级
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
$ kubectl describe deploy nginx-deployment | grep -i 'image'
Image: nginx:1.9.1
# 回滚
$ kubectl rollout undo deployment/nginx-deployment
$ kubectl describe deploy nginx-deployment | grep -i 'image'
Image: nginx:1.7.9
# 也可以使用edit命令来编辑 Deployment
$ kubectl edit deployment nginx-deployment
40 - image: nginx:latest
deployment.extensions/nginx-deployment edited
$ kubectl describe deploy nginx-deployment | grep -i 'image'
Image: nginx:latest
# 更新镜像实际上就是重新创建了一个rs
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-5458686b99 2 2 2 23s
nginx-deployment-687dc75df7 0 0 0 18m
nginx-deployment-6df444bb79 0 0 0 5m55s
Rollover(多个rollout并行)
假如您创建了一个有5个niginx:1.7.9 replica的 Deployment,但是当还只有3个nginx:1.7.9的 replica 创建出来的时候您就开始更新含有5个nginx:1.9.1 replica 的 Deployment。在这种情况下,Deployment 会立即杀掉已创建的3个nginx:1.7.9的 Pod,并开始创建nginx:1.9.1的 Pod。它不会等到所有的5个nginx:1.7.9的Pod 都创建完成后才开始改变航道。
$ kubectl rollout history deployment nginx-deployment
deployment.extensions/nginx-deployment
REVISION CHANGE-CAUSE
2 <none>
3 <none>
4 <none>
# 可以使用 --revision参数指定某个历史版本
$ kubectl rollout undo deployment nginx-deployment --to-revision=2
deployment.extensions/nginx-deployment rolled back
$ kubectl describe deploy nginx-deployment | grep -i 'image'
Image: nginx:1.9.1
$ ps: kubectl rollout pause deployment nginx-deployment ## 暂停 deployment 的更新
# 删除DeployMent
$ kubectl delete deployment nginx-deployment -n default
清理 Policy
可以通过设置.spec.revisonHistoryLimit项来指定 deployment 最多保留多少 revision 历史记录。默认的会保留所有的 revision;如果将该项设置为0,Deployment 就不允许回退了
4. DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行glusterd、ceph
- 在每个 Node 上运行日志收集 daemon,例如fluentd、logstash
- 在每个 Node 上运行监控 daemon,例如Prometheus Node Exporter、collectd、Datadog 代理、New Relic 代理,或 Ganglia gmond
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: deamonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: deamonset-example
template:
metadata:
labels:
name: deamonset-example
spec:
containers:
- name: daemonset-example
image: nginx:latest
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
deamonset-example-tqmfx 1/1 Running 0 94s
deamonset-example-wqvsm 1/1 Running 0 94s
# 删除 DaemonSet
$ kubectl delete daemonset deamonset-example -n default
5. Jobs :一次性任务
一次性任务,运行完成后pod销毁,不再重新启动新容器。还可以任务定时运行。
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束
特殊说明:
-
spec.template 格式同 Pod
-
RestartPolicy 仅支持 Never 或 OnFailure
-
单个Pod时,默认 Pod 成功运行后 Job 即结束
-
spec.completions 标志 Job 结束需要成功运行的 Pod 个数,默认为1
-
spec.parallelism 标志并行运行的 Pod 的个数,默认为1
-
spec.activeDeadlineSeconds 标志失败Pod的重试最大时间,超过这个时间不会继续重试
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl","-Mbignum=bpi","-wle","print bpi(2000)"]
restartPolicy: Never
$ kubectl get job
NAME COMPLETIONS DURATION AGE
pi 1/1 3m26s 8m54s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-bfmq8 0/1 Completed 0 9m1s
$ kubectl log -f pi-bfmq8
log is DEPRECATED and will be removed in a future version. Use logs instead.
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275905
# 删除 Job
$ kubectl delete job pi -n default
6. CronJob :定时任务
cronjob 其实就是在job的基础上加上了时间调度,可以:在给定的时间点运行一个任务,也可以周期性的在给定时间点运行。(与linux中的crontab类似)
Cron Job管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
使用前提条件:当前使用的Kubernetes集群,版本 >= 1.8(对 CronJob)。对于先前版本的集群,版本 <1.8,启动 API Server时,通过传递选项--runtime-config=batch/v2alpha1=true可以开启 batch/v2alpha1API。
典型的用法如下所示:
- 在给定的时间点调度 Job 运行
- 创建周期性运行的 Job,例如:数据库备份、发送邮件
特殊说明:
-
spec.template 格式同 Pod
-
RestartPolicy 仅支持 Never 或 OnFailure
-
单个 Pod 时,默认 Pod 成功运行后 Job 即结束
-
spec.completions 标志 Job 结束需要成功运行的 Pod 个数,默认为1
-
spec.parallelism 标志并行运行的 Pod 的个数,默认为1
-
spec.activeDeadlineSeconds 标志失败 Pod 的重试最大时间,超过这个时间不会继续重试
-
spec.schedule:调度,必需字段,指定任务运行周期,格式同 Cron
-
spec.jobTemplate:Job 模板,必需字段,指定需要运行的任务,格式同 Job
-
spec.startingDeadlineSeconds:启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
-
spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:
-
Allow(默认):允许并发运行 Job
-
Forbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个
-
Replace:取消当前正在运行的 Job,用一个新的来替换
注意, 当前策略只能应用于同一个Cron Job创建的Job。如果存在多个Cron Job, 它们创建的 Job 之间总是允许并发运行。
-
-
spec.suspend:挂起,该字段也是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为false。
-
spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为3和1。设置限制的值为0,相关类型的 Job 完成后将不会被保留。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 1 10s 22s
$ kubectl get job
NAME COMPLETIONS DURATION AGE
hello-1614322500 1/1 3s 62s
hello-1614322560 0/1 2s 2s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-1614322500-p7wmh 0/1 Completed 0 6s
hello-1614322560-vsz58 0/1 Completed 0 27s
$ kubectl logs -f hello-1614322500-p7wmh
Sat Mar 20 13:03:17 UTC 2021
Hello from the Kubernetes cluster
# 删除 cronjob
$ kubectl delete cronjob hello -n default
7. StateFulSet
StatefulSets(管理有状态应用) 作为 Controller 为 Pod 提供唯一的标识。它可以保证部署和 scale 的顺序StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现。
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现。
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现。
- 有序收缩,有序删除(即从N-1到0)。
8. Horizontal Pod Autoscaler
Horizontal Pod Autoscaler 应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,让service中的Pod个数自动调整呢?这就有赖于Horizontal Pod Autoscaler了,顾名思义,使Pod水平自动缩放。
5、Service
Kubernetes Service定义了这样一种抽象:一个Pod的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。这一组Pod能够被Service访问到,通常是通过Label Selector 。
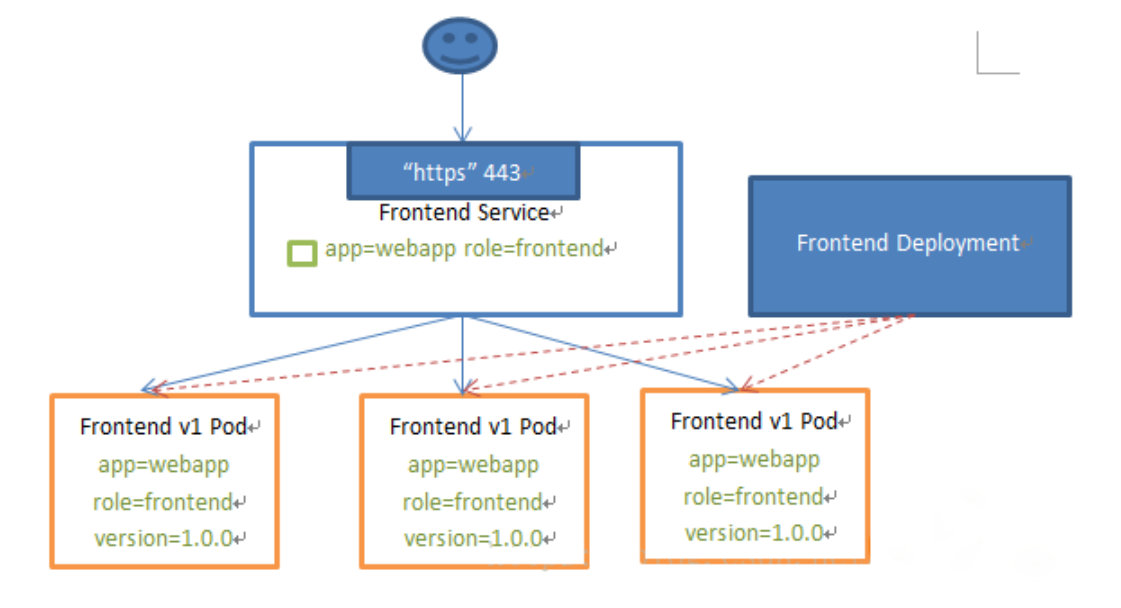
Service能够提供负载均衡的能力,但是在使用上有个限制:Service 只提供 4 层负载均衡能力,而没有 7 层功能, 但有时可能需要更多的匹配规则来转发请求,这点上 4 层负载均衡是不支持的。
5.1 Service 的类型
Service 在 K8s 中有以下四种类型:
- ClusterIp:默认类型,自动分配一个仅 Cluster 内部可以访问的虚拟 IP
- NodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过: NodePort 来访问该服务
- LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部负载均衡器,并将请求转发到: NodePort
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有 kubernetes 1.7 或更高版本的 kube-dns 才支持
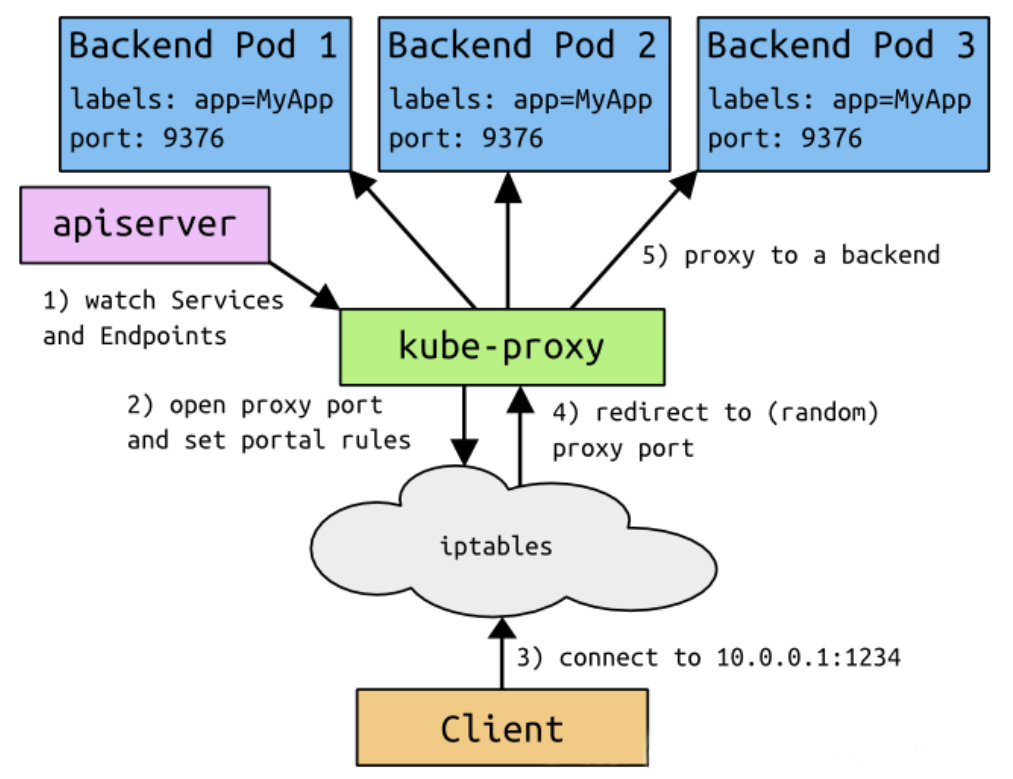
5.2 VIP 和 Service 代理
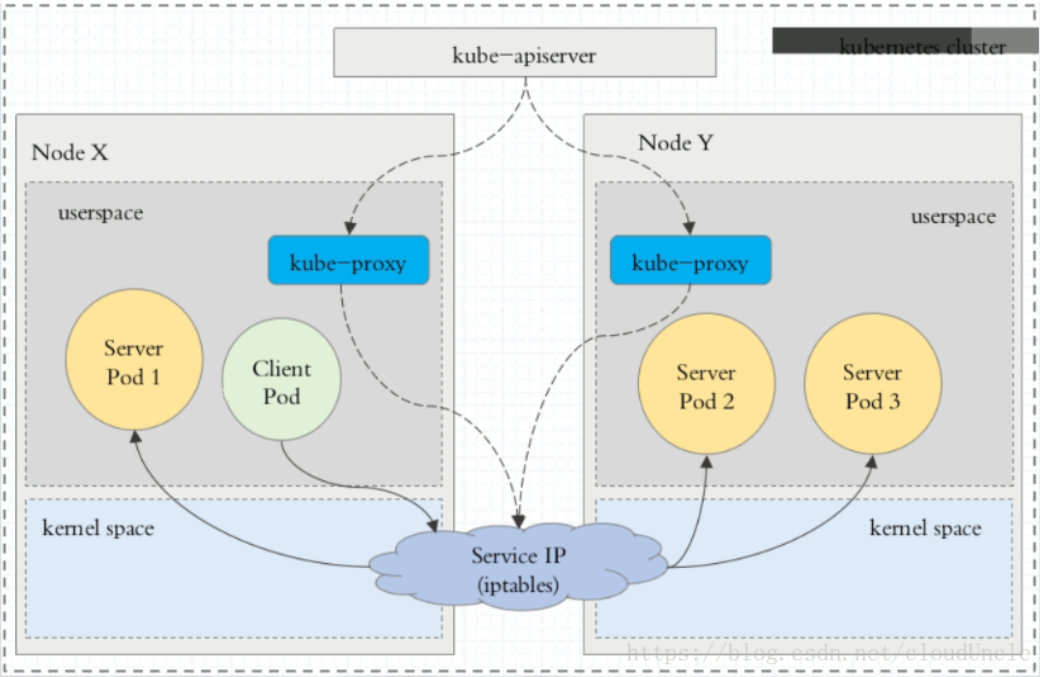
在 Kubernetes 集群中,每个 Node 运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP(虚拟 IP)的形式,而不是ExternalName的形式。在 Kubernetes v1.0 版本,代理完全在 userspace。在Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。从 Kubernetes v1.2 起,默认就是iptables 代理。在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理。
在 Kubernetes 1.14 版本开始默认使用ipvs 代理。
在 Kubernetes v1.0 版本,Service是 “4层”(TCP/UDP over IP)概念。在 Kubernetes v1.1 版本,新增了Ingress API(beta 版),用来表示 “7层”(HTTP)服务。
代理模式的分类如下:
1、userspace 代理模式
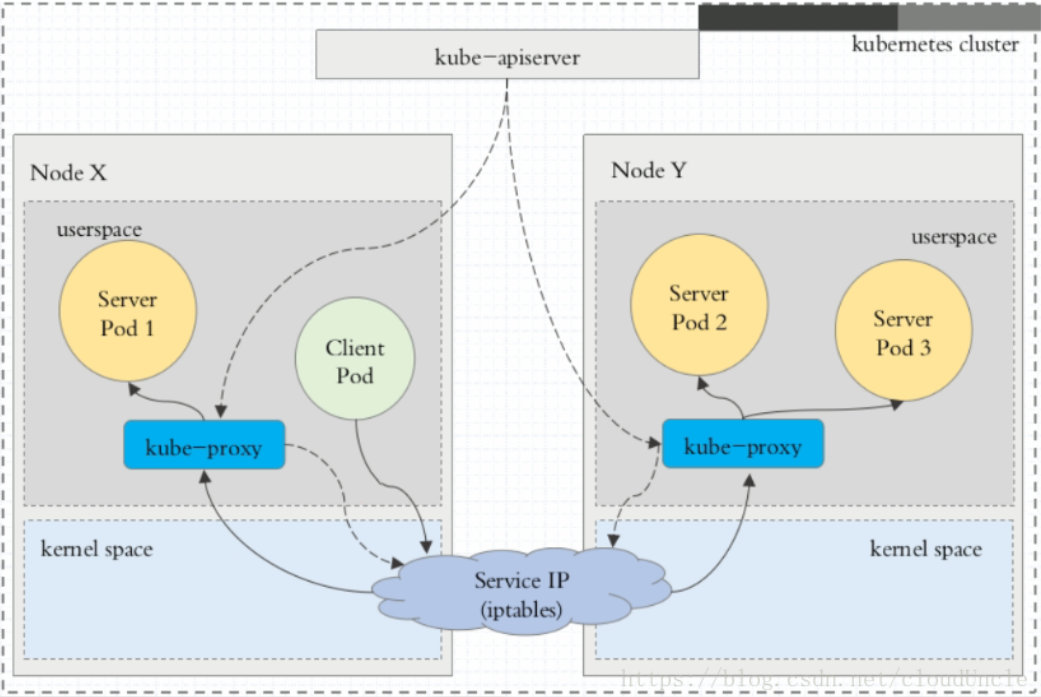
2、iptables 代理模式
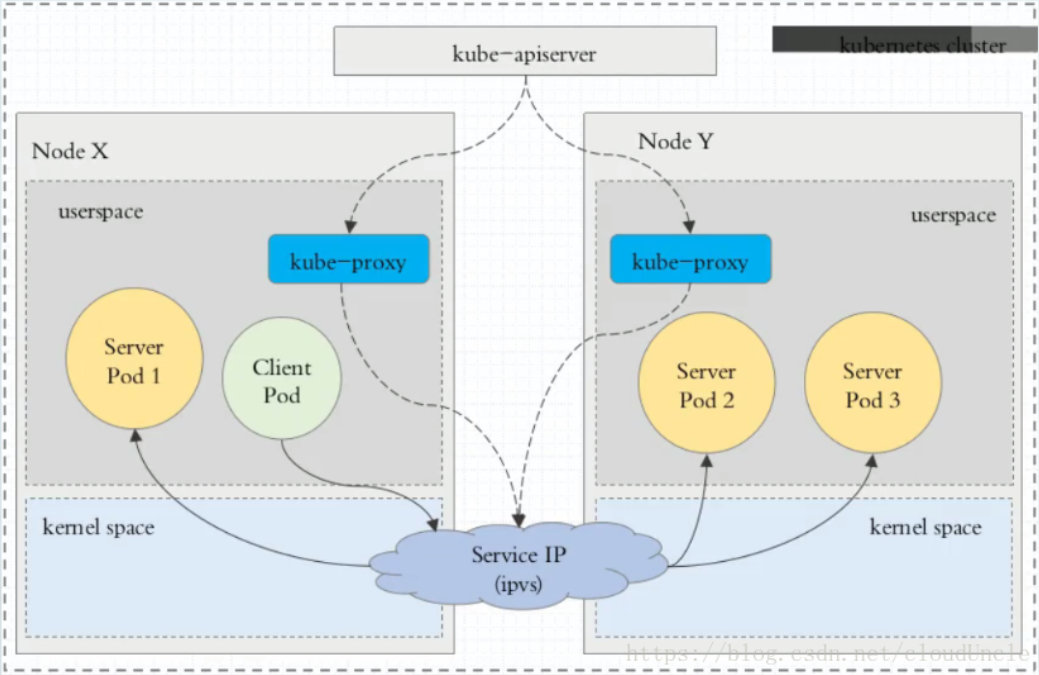
3、ipvs 代理模式
这种模式,kube-proxy 会监视 Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs 规则并定期与 Kubernetes Service对象和Endpoints对象同步 ipvs 规则,以确保 ipvs 状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。
与 iptables 类似,ipvs 于 netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs 可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs 为负载均衡算法提供了更多选项,例如:
- rr:轮询调度
- lc:最小连接数
- dh:目标哈希
- sh:源哈希
- sed:最短期望延迟
- nq:不排队调度
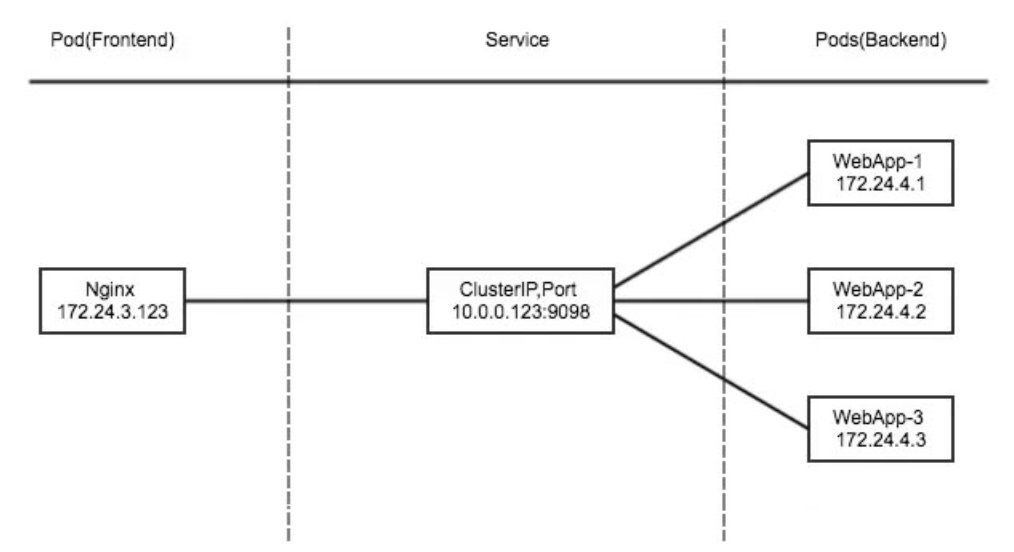
5.3 ClusterIP
clusterIP 主要在每个 node 节点使用 IPVS,将发向 clusterIP 对应端口的数据,转发到 kube-proxy 中。然后 kube-proxy 自己内部实现有负载均衡的方法,并可以查询到这个 service 下对应 pod 的地址和端口,进而把数据转发给对应的 pod 的地址和端口。
为了实现图上的功能,主要需要以下几个组件的协同工作:
- apiserver 用户通过kubectl命令向apiserver发送创建service的命令,apiserver接收到请求后将数据存储到etcd中
- kube-proxy kubernetes的每个节点中都有一个叫做kube-porxy的进程,这个进程负责感知service,pod的变化,并将变化的信息写入本地的 IPVS 规则中
- IPVS 使用NAT等技术将virtualIP的流量转至endpoint中
创建 myapp-deploy-svc.yaml 文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
env: test
spec:
containers:
- name: myapp
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
查看 IPVSADM
$ kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172d <none>
myapp ClusterIP 10.104.132.57 <none> 80/TCP 3m10s app=myapp,release=stabel
$ ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 192.168.2.1:6443 Masq 1 3 0
TCP 10.96.0.10:53 rr
-> 10.244.0.14:53 Masq 1 0 0
-> 10.244.0.15:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.0.14:9153 Masq 1 0 0
-> 10.244.0.15:9153 Masq 1 0 0
TCP 10.104.132.57:80 rr
-> 10.244.1.40:80 Masq 1 0 3
-> 10.244.1.41:80 Masq 1 0 3
-> 10.244.2.40:80 Masq 1 0 3
UDP 10.96.0.10:53 rr
-> 10.244.0.14:53 Masq 1 0 0
-> 10.244.0.15:53 Masq 1 0 0
5.4 Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP 。遇到这种情况,可以通过指定 ClusterIP(spec.clusterIP) 的值为 “None” 来创建 Headless Service 。这类 Service 并不会分配 Cluster IP, kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
clusterIP: "None"
ports:
- port: 80
targetPort: 80
$ kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172d <none>
myapp ClusterIP 10.104.132.57 <none> 80/TCP 5m30s app=myapp,release=stabel
myapp-headless ClusterIP None <none> 80/TCP 19s app=myapp
$ dig -t A myapp-headless.default.svc.cluster.local. @10.96.0.10
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-16.P2.el7_8.6 <<>> -t A myapp-headless.default.svc.cluster.local. @10.96.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5421
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;myapp-headless.default.svc.cluster.local. IN A
;; ANSWER SECTION:
myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.41
myapp-headless.default.svc.cluster.local. 30 IN A 10.244.1.40
myapp-headless.default.svc.cluster.local. 30 IN A 10.244.2.40
;; Query time: 0 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: 四 3月 04 10:36:53 CST 2021
;; MSG SIZE rcvd: 237
5.5 NodePort
nodePort 的原理在于在 node 上开了一个端口,将向该端口的流量导入到 kube-proxy,然后由 kube-proxy 进一步到给对应的 pod
apiVersion: v1
kind: Service
metadata:
name: myapps
namespace: default
spec:
type: NodePort
selector:
app: web
release: stabel
ports:
- name: http
port: 80
targetPort: 80
$ kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172d <none>
myapp ClusterIP 10.104.132.57 <none> 80/TCP 11m app=myapp,release=stabel
myapp-headless ClusterIP None <none> 80/TCP 6m42s app=myapp
myapps NodePort 10.100.41.94 <none> 80:32195/TCP 42s app=web,release=stabel
# 查询流程,并且在每台节点上都会打开一个32195端口
ipvsadm -Ln
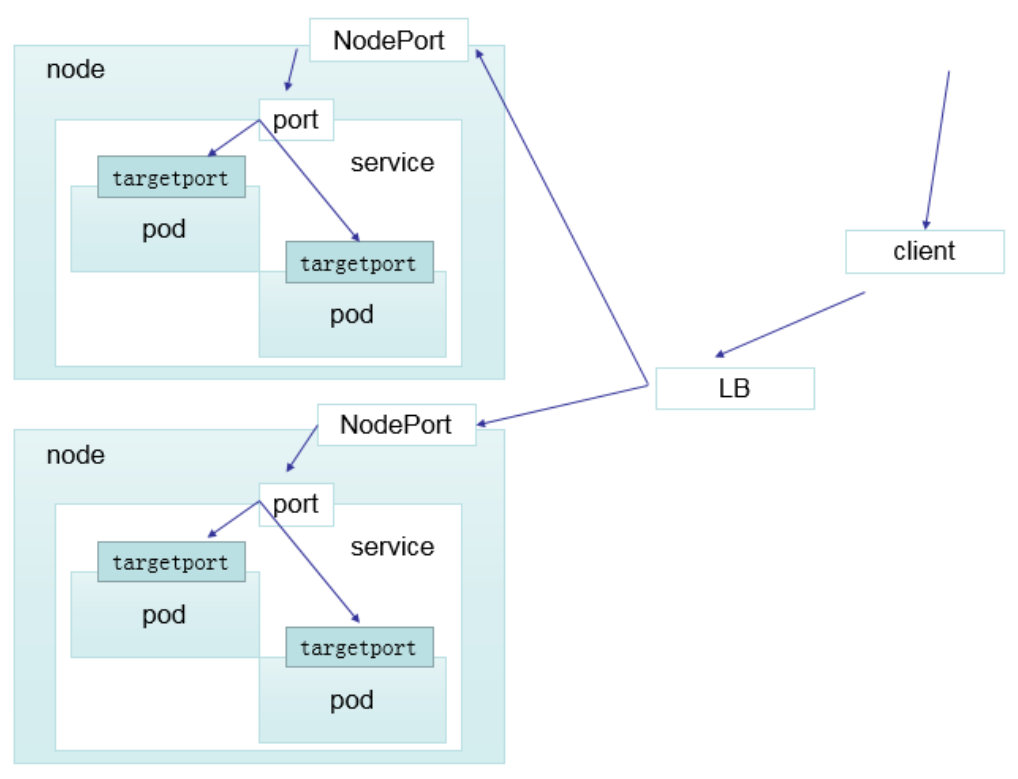
5.6 LoadBalancer
loadBalancer 和 nodePort 其实是同一种方式。区别在于 loadBalancer 比 nodePort 多了一步,就是可以调用cloud provider 去创建 LB 来向节点导流。
5.7 ExternalName
这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容( 例如:hub.atguigu.com )。
ExternalName Service 是 Service 的特例,它没有 selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
apiVersion: v1
kind: Service
metadata:
name: my-service-1
namespace: default
spec:
type: ExternalName
externalName: hub.armin.com
$ kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172d <none>
my-service-1 ExternalName <none> hub.armin.com <none> 29s <none>
myapp ClusterIP 10.104.132.57 <none> 80/TCP 21m app=myapp,release=stabel
myapp-headless ClusterIP None <none> 80/TCP 15m app=myapp
myapps NodePort 10.100.41.94 <none> 80:32195/TCP 9m51s app=web,release=stabel
$ dig -t A hub.armin.com.svc.cluster.local. @10.96.0.10
当查询主机 my-service.defalut.svc.cluster.local ( SVC_NAME.NAMESPACE.svc.cluster.local )时,集群的DNS 服务将返回一个值 my.database.example.com 的 CNAME 记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在 DNS 层,而且不会进行代理或转发。
6、Ingress
必须具有 Ingress 控制器 才能满足 Ingress 的要求。 仅创建 Ingress 资源本身没有任何效果。
需要部署 Ingress 控制器,例如 ingress-nginx。 你可以从许多 Ingress 控制器 中进行选择。
理想情况下,所有 Ingress 控制器都应符合参考规范。但实际上,不同的 Ingress 控制器操作略有不同。
mandatory.yaml
apiVersion: v1
kind: Namespace
metadata:
name: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-configuration
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: tcp-services
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: udp-services
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: nginx-ingress-clusterrole
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses/status
verbs:
- update
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: nginx-ingress-role
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- pods
- secrets
- namespaces
verbs:
- get
- apiGroups:
- ""
resources:
- configmaps
resourceNames:
# Defaults to "<election-id>-<ingress-class>"
# Here: "<ingress-controller-leader>-<nginx>"
# This has to be adapted if you change either parameter
# when launching the nginx-ingress-controller.
- "ingress-controller-leader-nginx"
verbs:
- get
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- create
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: nginx-ingress-role-nisa-binding
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: nginx-ingress-role
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: nginx-ingress-clusterrole-nisa-binding
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: nginx-ingress-clusterrole
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
annotations:
prometheus.io/port: "10254"
prometheus.io/scrape: "true"
spec:
# wait up to five minutes for the drain of connections
terminationGracePeriodSeconds: 300
serviceAccountName: nginx-ingress-serviceaccount
nodeSelector:
kubernetes.io/os: linux
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.30.0
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 101
runAsUser: 101
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
protocol: TCP
- name: https
containerPort: 443
protocol: TCP
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
lifecycle:
preStop:
exec:
command:
- /wait-shutdown
---
apiVersion: v1
kind: LimitRange
metadata:
name: ingress-nginx
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
limits:
- min:
memory: 90Mi
cpu: 100m
type: Container
service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: ingress-nginx
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
- name: https
port: 443
targetPort: 443
protocol: TCP
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
创建 ingress-nginx
[root@k8s-master-192 ingress-nginx]# kubectl apply -f ./
namespace/ingress-nginx created
configmap/nginx-configuration created
configmap/tcp-services created
configmap/udp-services created
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole configured
role.rbac.authorization.k8s.io/nginx-ingress-role created
rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding created
clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding configured
deployment.apps/nginx-ingress-controller created
limitrange/ingress-nginx created
service/ingress-nginx created
#查看ingress-nginx控制器
[root@k8s-master-192 ingress-nginx]# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
nginx-ingress-controller-7fcf8df75d-7jj4z 1/1 Running 0 85s
nginx-ingress-controller-7fcf8df75d-l9bwc 1/1 Running 0 85s
#查看service
[root@k8s-master-192 ingress-nginx]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.100.56.91 <none> 80:31352/TCP,443:30499/TCP 80s
6.2 准备service 和 pod
为了方便后续的实验,创建下图所示的模型

创建 tomcat-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: ingress-nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-deployment
namespace: ingress-nginx
spec:
replicas: 3
selector:
matchLabels:
app: tomcat-pod
template:
metadata:
labels:
app: tomcat-pod
spec:
containers:
- name: tomcat
image: tomcat:8.5-jre10-slim
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: ingress-nginx
spec:
selector:
app: nginx-pod
clusterIP: None
type: ClusterIP
ports:
- port: 80
targetPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
namespace: ingress-nginx
spec:
selector:
app: tomcat-pod
clusterIP: None
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
[root@k8s-master-192 ingress-nginx]# kubectl apply -f tomcat-nginx.yaml
deployment.apps/nginx-deployment created
deployment.apps/tomcat-deployment created
service/nginx-service created
service/tomcat-service created
# 查看deploy
[root@k8s-master-192 ingress-nginx]# kubectl get deploy -n ingress-nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 83s
nginx-ingress-controller 2/2 2 2 7m16s
tomcat-deployment 3/3 3 3 83s
# 查看svc
[root@k8s-master-192 ingress-nginx]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx NodePort 10.100.56.91 <none> 80:31352/TCP,443:30499/TCP 6m42s
nginx-service ClusterIP None <none> 80/TCP 48s
tomcat-service ClusterIP None <none> 8080/TCP 48s
6.3 Http代理
创建ingress-http.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-http
namespace: dev
spec:
rules:
- host: nginx.test.com
http:
paths:
- path: /
backend:
serviceName: nginx-service
servicePort: 80
- host: tomcat.test.com
http:
paths:
- path: /
backend:
serviceName: tomcat-service
servicePort: 8080
使用配置文件
[root@k8s-master-192 ingress-nginx]# kubectl apply -f ingress-http.yaml
ingress.extensions/ingress-http created
# 查看ingress规则
[root@k8s-master-192 ingress-nginx]# kubectl get ingress -n ingress-nginx
NAME HOSTS ADDRESS PORTS AGE
ingress-http nginx.test.com,tomcat.test.com 10.100.56.91 80 45s
# 查看详细信息
[root@k8s-master-192 ingress-nginx]# kubectl describe ing ingress-http -n ingress-nginx
Name: ingress-http
Namespace: ingress-nginx
Address: 10.100.56.91
Default backend: default-http-backend:80 (<none>)
Rules:
Host Path Backends
---- ---- --------
nginx.test.com
/ nginx-service:80 (10.244.3.72:80,10.244.3.74:80,10.244.4.63:80) # 这些ip就是对应pod的
tomcat.test.com
/ tomcat-service:8080 (10.244.3.73:8080,10.244.4.64:8080,10.244.4.65:8080)
Annotations:
kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"extensions/v1beta1","kind":"Ingress","metadata":{"annotations":{},"name":"ingress-http","namespace":"ingress-nginx"},"spec":{"rules":[{"host":"nginx.test.com","http":{"paths":[{"backend":{"serviceName":"nginx-service","servicePort":80},"path":"/"}]}},{"host":"tomcat.test.com","http":{"paths":[{"backend":{"serviceName":"tomcat-service","servicePort":8080},"path":"/"}]}}]}}
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CREATE 109s nginx-ingress-controller Ingress ingress-nginx/ingress-http
Normal CREATE 109s nginx-ingress-controller Ingress ingress-nginx/ingress-http
Normal UPDATE 99s nginx-ingress-controller Ingress ingress-nginx/ingress-http
Normal UPDATE 99s nginx-ingress-controller Ingress ingress-nginx/ingress-http
修改本机的hosts文件,添加如下内容
master虚拟机的IP地址 nginx.test.com
masete虚拟机的IP地址 tomcat.test.com
查看ingress为service提供的端口号
[root@k8s-master-192 ingress-nginx]# kubectl get svc -n ingress-nginx|grep ingress-nginx
ingress-nginx NodePort 10.100.56.91 <none> 80:31352/TCP,443:30499/TCP 16m
在浏览器中测试访问, 是能够访问通
6.4 Https代理
创建证书
[root@k8s-master-192 ingress-nginx]# openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/C=CN/ST=BJ/L=BJ/O=nginx/CN=test.com"
Generating a 2048 bit RSA private key
...........................................................................+++
....................................+++
writing new private key to 'tls.key'
-----
创建密钥
[root@k8s-master-192 ingress-nginx]# kubectl create secret tls tls-secret --key tls.key --cert tls.crt
secret/tls-secret created
创建 ingress-https.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-https
namespace: ingress-nginx
spec:
tls:
- hosts:
- nginx.test.com
- tomcat.test.com
secretName: tls-secret #指定密钥
rules:
- host: nginx.test.com
http:
paths:
- path: /
backend:
serviceName: nginx-service
servicePort: 80
- host: tomcat.test.com
http:
paths:
- path: /
backend:
serviceName: tomcat-service
servicePort: 8080
使用配置文件
[root@k8s-master-192 ingress-nginx]# kubectl create -f ingress-https.yaml
ingress.extensions/ingress-https created
[root@k8s-master-192 ingress-nginx]# kubectl describe ing ingress-https -n ingress-nginx
Name: ingress-https
Namespace: ingress-nginx
Address: 10.100.56.91
Default backend: default-http-backend:80 (<none>)
TLS:
tls-secret terminates nginx.test.com,tomcat.test.com
Rules:
Host Path Backends
---- ---- --------
nginx.test.com
/ nginx-service:80 (10.244.3.72:80,10.244.3.74:80,10.244.4.63:80)
tomcat.test.com
/ tomcat-service:8080 (10.244.3.73:8080,10.244.4.64:8080,10.244.4.65:8080)
Annotations:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CREATE 40s nginx-ingress-controller Ingress ingress-nginx/ingress-https
Normal CREATE 40s nginx-ingress-controller Ingress ingress-nginx/ingress-https
Normal UPDATE 34s nginx-ingress-controller Ingress ingress-nginx/ingress-https
Normal UPDATE 34s nginx-ingress-controller Ingress ingress-nginx/ingress-https
获取端口,左边的是http使用的端口,右边是https使用的端口,因此要使用的端口是30499
[root@k8s-master-192 ingress-nginx]# kubectl get svc -n ingress-nginx|grep ingress-nginx
ingress-nginx NodePort 10.100.56.91 <none> 80:31352/TCP,443:30499/TCP 32m
使用浏览器访问

7、K8S - 存储
- ConfigMap
- Secret
- volume
- Persistent Volume(PV)
7.1 ConfigMap
ConfigMap 功能在 Kubernetes1.2 版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。ConfigMap API 给我们提供了向容器中注入配置信息的机制,ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制大对象。
7.1.1 ConfigMap 的创建
- 目录创建
- 文件创建
- 字面值创建
使用目录创建
$ ll /etc/kubernetes/configmap-dir/
game.properties
ui.properties
$ cat /etc/kubernetes/configmap-dir/game.properties
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
$ cat /etc/kubernetes/configmap-dir/ui.properties
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
# --from-file 指定在目录下的所有文件都会被用在 ConfigMap 里面创建一个键值对,键的名字就是文件名,值就是文件的内容。
$ kubectl create configmap game-config-1 --from-file=/etc/kubernetes/configmap-dir
$ kubectl get configmap -n default -owide
NAME DATA AGE
game-config-1 2 <invalid>
$ kubectl get configmap -n default -o yaml
apiVersion: v1
items:
- apiVersion: v1
data:
game.properties: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
kind: ConfigMap
metadata:
creationTimestamp: "2021-03-08T11:54:57Z"
name: game-config-1
namespace: default
resourceVersion: "15839"
selfLink: /api/v1/namespaces/default/configmaps/game-config-1
uid: cb84c4f5-e509-4ecb-8513-68184b8b57af
kind: List
metadata:
resourceVersion: ""
selfLink: ""
$ kubectl describe configmap game-config-1 -n default
Name: game-config-1
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
ui.properties:
----
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
Events: <none>
使用文件创建
只要指定为一个文件就可以从单个文件中创建 ConfigMap
$ kubectl create configmap game-config-2 --from-file=/etc/kubernetes/configmap-dir/game.properties
$ kubectl get configmaps game-config-2 -o yaml
# --from-file这个参数可以使用多次,你可以使用两次分别指定上个实例中的那两个配置文件,效果就跟指定整个目录是一样的。
使用字面值创建
使用文字值创建,利用--from-literal参数传递配置信息,该参数可以使用多次
$ kubectl create configmap game-config-3 --from-literal=k1.how=v1 --from-literal=k2.how=v2
$ kubectl get configmaps game-config-3 -o yaml
apiVersion: v1
data:
k1.how: v1
k2.how: v2
kind: ConfigMap
metadata:
creationTimestamp: "2021-03-08T12:01:19Z"
name: game-config-3
namespace: default
resourceVersion: "16388"
selfLink: /api/v1/namespaces/default/configmaps/game-config-3
uid: b9e048f3-a17d-4517-bfe5-311c51377aaa
7.1.2 Pod 中使用 ConfigMap
使用 ConfigMap 来替代环境变量
- env: 指定导入k/v
- envFrom: 全部导入
# cat cm-test-01.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
namespace: default
data:
special.how: very
special.sam: charm
special.lep: value
---
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config
namespace: default
data:
log_level: INFO
log_level: DEBUG
---
apiVersion: v1
kind: Pod
metadata:
name: cm-test-pod-01
spec:
containers:
- name: test-container
image: arminto/my_nginx:v1
command: [ "/bin/sh", "-c", "env" ]
env:
- name: SPECIAL_HOW_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.how
- name: SPECIAL_SAM_KEY
valueFrom:
configMapKeyRef:
name: special-config
key: special.sam
envFrom:
- configMapRef:
name: env-config
restartPolicy: Never
$ kubectl apply -f cm-test-01.yaml
$ kubectl logs cm-test-pod-01 | grep SPECIAL
SPECIAL_HOW_KEY=very
SPECIAL_SAM_KEY=charm
用 ConfigMap 设置命令行参数
# cat cm-test-02.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: config-01
namespace: default
data:
a: b
c: d
---
apiVersion: v1
kind: Pod
metadata:
name: cm-test-pod-02
spec:
containers:
- name: test-container
image: arminto/my_nginx:v1
command: ["/bin/sh","-c","echo $(KEY-01) $(KEY-02)"]
env:
- name: KEY-01
valueFrom:
configMapKeyRef:
name: config-01
key: a
- name: KEY-02
valueFrom:
configMapKeyRef:
name: config-01
key: c
restartPolicy: Never
$ kubectl logs cm-test-pod-02
b d
通过数据卷插件使用ConfigMap
# cat cm-test-03.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: config-02
namespace: default
data:
how: HOW
sam: SAM
---
# 在数据卷里面使用这个 ConfigMap,有不同的选项。最基本的就是将文件填入数据卷,在这个文件中,键就是文件名,键值就是文件内容。
apiVersion: v1
kind: Pod
metadata:
name: test-pod-02
spec:
containers:
- name: test-container
image: arminto/my_nginx:v1
command: ["/bin/sh","-c","sleep 36000"]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: config-02
restartPolicy: Never
$ kubectl exec -it test-pod-02 -- ls -lh /etc/config
total 0
lrwxrwxrwx 1 root root 10 Mar 9 08:44 how -> ..data/how
lrwxrwxrwx 1 root root 10 Mar 9 08:44 sam -> ..data/sam
$ kubectl exec -it test-pod-02 -- cat /etc/config/how
HOW
$ kubectl exec -it test-pod-02 -- cat /etc/config/sam
SAM
7.1.3 ConfigMap 的热更新
apiVersion: v1
kind: ConfigMap
metadata:
name: log-config
namespace: default
data:
log_level: INFO
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas: 1
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: arminto/my_nginx:v1
ports:
- containerPort: 80
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: log-config
$ kubectl exec -it my-nginx-7b6584d96d-hpbml -- cat /etc/config/log_level
INFO
修改 ConfigMap,将其INFO改为DEBUG
$ kubectl edit configmap log-config
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
log_level: DEBUG
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"log_level":"DEBUG"},"kind":"ConfigMap","metadata":{"annotations":{},"name":"log-config","namespace":"default"}}
creationTimestamp: "2021-03-09T09:04:08Z"
name: log-config
namespace: default
resourceVersion: "36210"
selfLink: /api/v1/namespaces/default/configmaps/log-config
uid: 8e2f15fc-cc05-414b-ad2f-9597cacf7c9a
修改log_level的值为DEBUG等待大概 10 秒钟时间,再次查看环境变量的值
$ kubectl exec -it my-nginx-7b6584d96d-hpbml -- cat /etc/config/log_level
DEBUG
7.2 Secret
Secret 解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者 Pod Spec中。
并且,Secret 可以以 Volume 或者 环境变量的方式使用。
Secret 有三种类型
- Service Account
- Opaque
- kubernetes.io/dockerconfigjson
7.2.1 Service Account
大致了解一下即可,Service Account 用来访问 Kubernetes API,由 Kubernetes 自动创建,并且会自动挂载到 Pod的/run/secrets/kubernetes.io/serviceaccount目录中。
PS : 只有与 apiserver 组件进行交互的 pod 才会有如下的 证书、命名空间、tekon密钥。
$ kubectl exec -it kube-proxy-2x7r8 -n kube-system -- ls -lh /run/secrets/kubernetes.io/serviceaccount
total 0
lrwxrwxrwx 1 root root 13 Mar 10 02:50 ca.crt -> ..data/ca.crt
lrwxrwxrwx 1 root root 16 Mar 10 02:50 namespace -> ..data/namespace
lrwxrwxrwx 1 root root 12 Mar 10 02:50 token -> ..data/token
# 这几个文件是 default-token 提供的,而 default-token 是 k8s 默认为每一个namespace 创建的,用于Service Account
$ kubectl get secret
NAME TYPE DATA AGE
default-token-c6vqw kubernetes.io/service-account-token 3 46d
$ kubectl describe secret default-token-c6vqw
…………………………………………………………………………
Data
====
ca.crt: 1025 bytes
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImRlZmF1bHQtdG9rZW4tYzZ2cXciLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGVmYXVsdCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjJjNjlmMjkzLTcwNTQtNDY4My05ODNmLTljYmQyNTBlZTQ1ZiIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0OmRlZmF1bHQifQ.WdQ32P2ndcKUNbyrsKouTgBEVQf8Smq1mSd9zRpBou1KN2DUJ6UPWHvMdDlqwvN2CACOWZcri0eN8NABvNEW6cQMv7O7-GoVsuv5HLDxmO1IC1tTVUr8d-uBxULiSiQZ_Mj2LK1QKYNAHzVYRlEozzI3wZAOWBDqA7ZFVpXRQMES0lzlRc9ETZqQmxIHgF_hyTzpsRaLkR480vppOTORejZGrm_wiSvYVKKvNe3H35TRtHARCZDlGv7DAickld2rnYuKSyLdZz29CmDiE6L0ZyzTCMgPalNkmjcuij28XG19I4GLio7IiS5ZMDrQsmr_4t3G449PPSiH_0C78LICuA
7.2.2 Opaque Secret
base64编码格式的Secret,用来存储密码、密钥等。
Opaque 类型的数据是一个 map 类型,要求 value 是 base64 编码格式。
1、创建 Opaque-Secret
# base64 -d 选项为解密
$ echo -n "admin" | base64
YWRtaW4=
$ echo -n "1f2d1e2e67df" | base64
MWYyZDFlMmU2N2Rm
# cat opaque-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: op-secret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
$ kubectl get secret
NAME TYPE DATA AGE
default-token-c6vqw kubernetes.io/service-account-token 3 46d
op-secret Opaque 2 11s
$ kubectl describe secret op-secret
…………………………………………………………………………
Data
====
password: 12 bytes
username: 5 bytes
2、使用方式
- 将 Secret 挂载到 Volume 中
# cat volume-secret.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
name: seret-test
name: seret-test
spec:
volumes:
- name: secrets
secret:
secretName: op-secret
containers:
- image: arminto/my_nginx:v1
name: db
volumeMounts:
- name: secrets
mountPath: '/etc/secrets'
readOnly: true
$ kubectl exec -it seret-test -- ls -l /etc/secrets
total 0
lrwxrwxrwx 1 root root 15 Mar 10 03:25 password -> ..data/password
lrwxrwxrwx 1 root root 15 Mar 10 03:25 username -> ..data/username
# 并且 secret 是会自己进行解密的
$ kubectl exec -it seret-test -- cat /etc/secrets/password
1f2d1e2e67df
$ kubectl exec -it seret-test -- cat /etc/secrets/username
admin
- 将 Secret 导出到环境变量中
# cat env-secret.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: pod-deployment
spec:
replicas: 2
template:
metadata:
labels:
app: pod-deployment
spec:
containers:
- name: pod-1
image: arminto/my_nginx:v1
ports:
- containerPort: 80
env:
- name: TEST_USER
valueFrom:
secretKeyRef:
name: op-secret
key: username
- name: TEST_PASSWORD
valueFrom:
secretKeyRef:
name: op-secret
key: password
$ kubectl exec -it pod-deployment-7cfd69dcf7-222q2 -- /bin/sh
/ # echo $TEST_USER
admin
/ # echo $TEST_PASSWORD
1f2d1e2e67df
7.2.3 dockerconfigjson
用来存储私有 docker registry 的认证信息。
1、使用 Kuberctl 创建 docker registry 认证的 secret(注:针对私有仓库)
$ kubectl create secret docker-registry myregistrykey --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD
# --docker-server 仓库地址
# --docker-username 仓库用户
# --docker-password 仓库密码
2、在创建 Pod 的时候,通过 imagePullSecrets 来引用刚创建的 myregistrykey
# cat key-secret.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: foo
image: hub.lemon.com/library/my_nginx:v1
imagePullSecrets:
- name: myregistrykey
7.3 Volume
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次,在Pod中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的Volume抽象就很好的解决了这些问题。
Kubernetes 中的卷有明确的寿命 —— 与封装它的 Pod 相同。所f以,卷的生命比 Pod 中的所有容器都长,当这个容器重启时数据仍然得以保存。当然,当 Pod 不再存在时,卷也将不复存在。也许更重要的是,Kubernetes支持多种类型的卷,Pod 可以同时使用任意数量的卷。
Kubernetes 支持以下类型的卷:
- awsElasticBlockStore、azureDisk、azureFile、cephfs、csi、downwardAPI、emptyDir
- fc、flocker、gcePersistentDisk、gitRepo、glusterfs、hostPath、iscsi、local、nfs
- persistentVolumeClaim、projected、portworxVolume、quobyte、rbd、scaleIO、secret
- storageos、vsphereVolume
比较常用的两类 emptyDir、hostPath
7.3.1 emptyDir
当 Pod 被分配给节点时,首先创建emptyDir卷,并且只要该 Pod 在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。Pod 中的容器可以读取和写入emptyDir卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,emptyDir中的数据将被永久删除。
emptyDir的用法有:
- 暂存空间,例如用于基于磁盘的合并排序
- 用作长时间计算崩溃恢复时的检查点
- Web服务器容器提供数据时,保存内容管理器容器提取的文件
# cat emptyDir.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- name: test-container01
image: arminto/my_nginx:v1
volumeMounts:
- mountPath: /cache01
name: cache-volume
- name: test-container02
image: tomcat:latest
volumeMounts:
- mountPath: /cache02
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
$ kubectl exec -it test-pd -c test-container01 -- /bin/sh
/ # cd /cache01
/cache01 # hostname >> test.log
/cache01 # cat test.log
test-pd
$ kubectl exec -it test-pd -c test-container02 -- /bin/sh
# cd /cache02
# ls
test.log
# cat test.log
test-pd
7.3.2 hostPath
hostPath卷将主机节点的文件系统中的文件或目录挂载到集群中。
hostPath 的用途如下:
- 运行需要访问 Docker 内部的容器;使用 /var/lib/docker 的 hostPath
- 在容器中运行 cAdvisor;使用 /dev/cgroups 的 hostPath
- 允许 pod 指定给定的 hostPath 是否应该在 pod 运行之前存在,是否应该创建,以及它应该以什么形式存在
除了所需的path属性之外,用户还可以为hostPath卷指定type
| 值 | 行为 |
|---|---|
| 空字符串(默认)用于向后兼容,这意味着在挂载 hostPath 卷之前不会执行任何检查。 | |
| DirectoryOrCreate | 如果在给定的路径上没有任何东西存在,那么将根据需要在那里创建一个空目录,权限设置为 0755,与 Kubelet 具有相同的组和所有权。 |
| Directory | 给定的路径下必须存在目录。 |
| FileOrCreate | 如果在给定的路径上没有任何东西存在,那么会根据需要创建一个空文件,权限设置为 0644,与 Kubelet 具有相同的组和所有权。 |
| File | 给定的路径下必须存在文件。 |
| Socket | 给定的路径下必须存在 UNIX 套接字。 |
| CharDevice | 给定的路径下必须存在字符设备。 |
| BlockDevice | 给定的路径下必须存在块设备。 |
使用这种卷类型是请注意,因为:
- 由于每个节点上的文件都不同,具有相同配置(例如从 podTemplate 创建的)的 pod 在不同节点上的行为可能会有所不同。
- 当 Kubernetes 按照计划添加资源感知调度时,将无法考虑hostPath使用的资源。
- 在底层主机上创建的文件或目录只能由 root 写入。您需要在特权容器中以 root 身份运行进程,或修改主机上的文件权限以便写入hostPath卷。
# cat hostpath.yaml
apiVersion: v1
kind: Pod
metadata:
name: h-pod
spec:
containers:
- image: arminto/my_nginx:v1
name: test-container
volumeMounts:
- mountPath: /hv
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE
h-pod 0/1 ContainerCreating 0 7s <none> k8s-node-192.168.2.22
$ hostname
k8s-node-192.168.2.22
$ echo 'hv test' > /data/h-test.log
$ kubectl exec -it h-pod -- cat /hv/h-test.log
hv test
7.4 Persistent Volume(PV)
PersistentVolume(简称PV) 是 Volume 之类的卷插件,也是集群中的资源,但独立于Pod的生命周期(即不会因Pod删除而被删除),不归属于某个Namespace。
PersistentVolumeClaim(简称PVC)是用户存储的请求,PVC消耗PV的资源,可以请求特定的大小和访问模式,需要指定归属于某个Namespace,在同一个Namespace 的 Pod才可以指定对应的PVC。
PV (持久化卷),是对底层的共享存储的一种抽象,PV 由管理员进行创建和配置, 它和具体的底层的共享存储技术的实现方式有关,比如Ceph、GlusterFS、NFS等,都是通过插件机制完成与共享存储的对接。
PVC (持久化卷声明),PVC 是用户存储的一种声明,PVC 和 Pod 比较类型,Pod 是消耗节点,PVC 消耗的是 PV 资源,Pod 可以请求 CPU 的内存,而 PVC 可以请求特定的存储空间和访问模式。对于真正存储的用户不需要关心底层的存储实现细节,只需要直接使用PVC即可。
但是通过PVC请求一定的存储空间也很有可能不足以满足对于存储设备的各种需求,而且不同的应用程序对于存储性能的要求也能也不尽相同,比如读写速度、并发性能等,为了解决这一问题,Kubernetes又为我们引入了一个新的资源对象: StorageClass,通过StorageClass的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,用户根据StorageClass的描述就可以非常直观的知道各种存储资源特性了,这样就可以根据应用的特性去申请合适的存储资源了。
7.4.1 PV 和 PVC的生命周期
PV 可以看作可用的存储资源,PVC则是对存储资源的需求,PV 和 PVC的互相关系遵循如下图
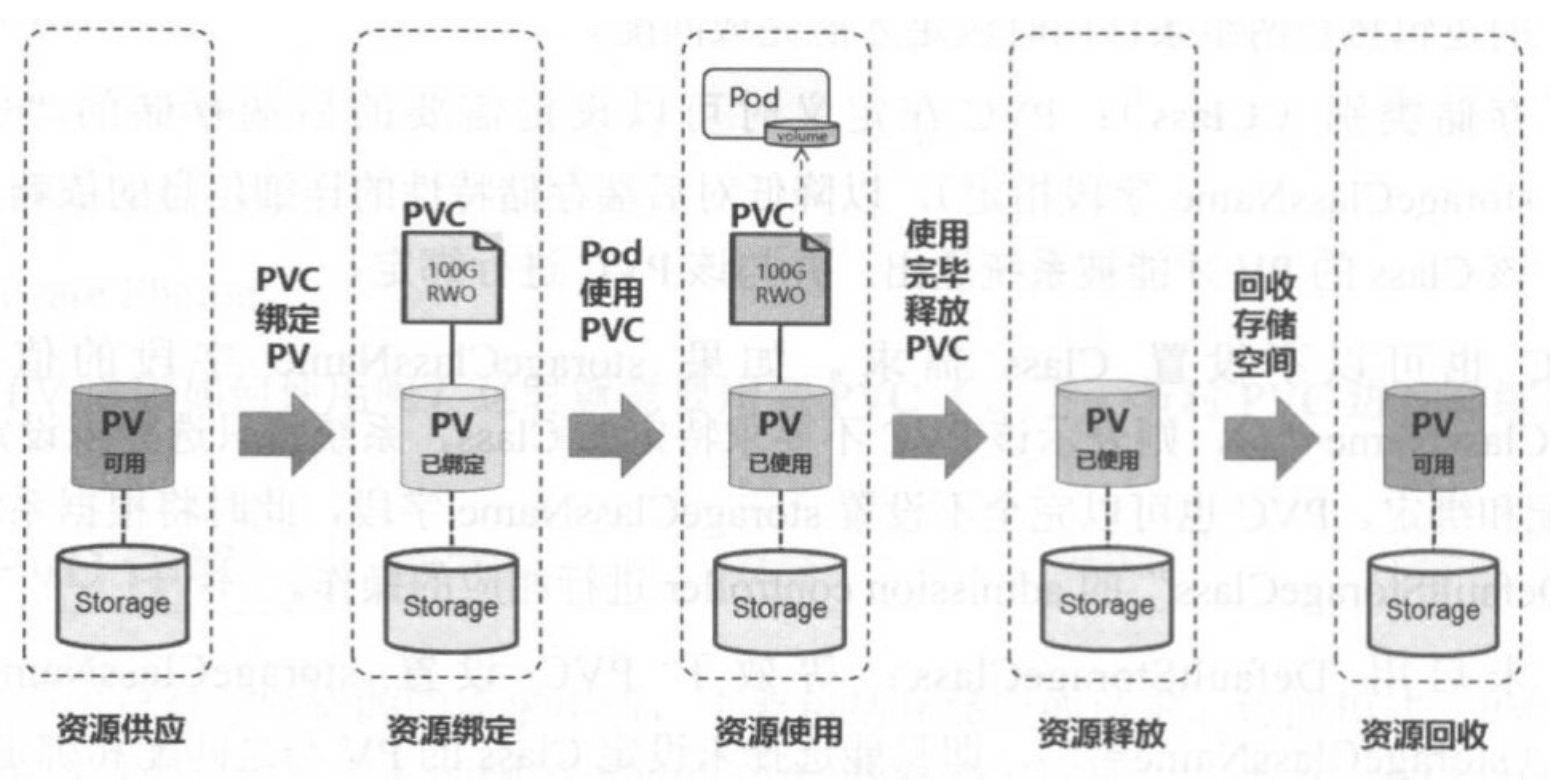
7.4.2 资源供应 (Provisioning)
Kubernetes支持两种资源的供应模式:静态模式(Staic)和动态模式(Dynamic)。资源供应的结果就是创建好的PV。
- 静态模式:集群管理员手工创建许多 PV,在定义 PV 时需要将后端存储的特性进行设置。
- 动态模式:集群管理员无须手工创建 PV,而是通过 StorageClass 的设置对后端存储进行描述,标记为某种 “类型(Class)”。此时要求 PVC 对存储的类型进行声明,系统将自动完成 PV 的创建及 PVC 的绑定。
- PVC 可以声明 Class 为””,说明该 PVC 禁止使用动态模式。
1、静态资源下,通过PV和PVC完成绑定,并供Pod使用的存储管理机制
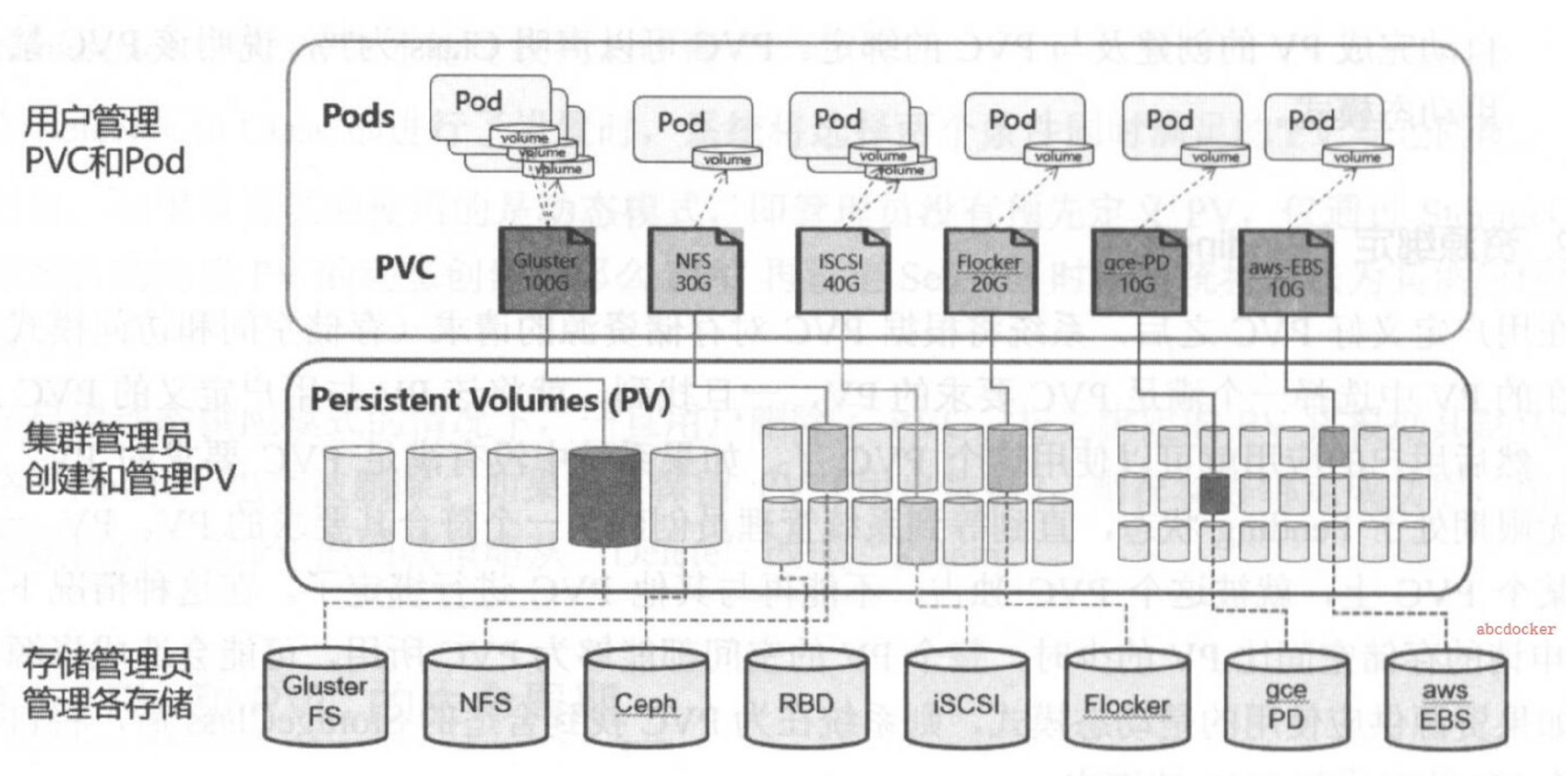
2.动态资源下,通过StorageClass和PVC完成资源动态绑定 (系统自动生成PV,并供Pod使用的存储管理机制)
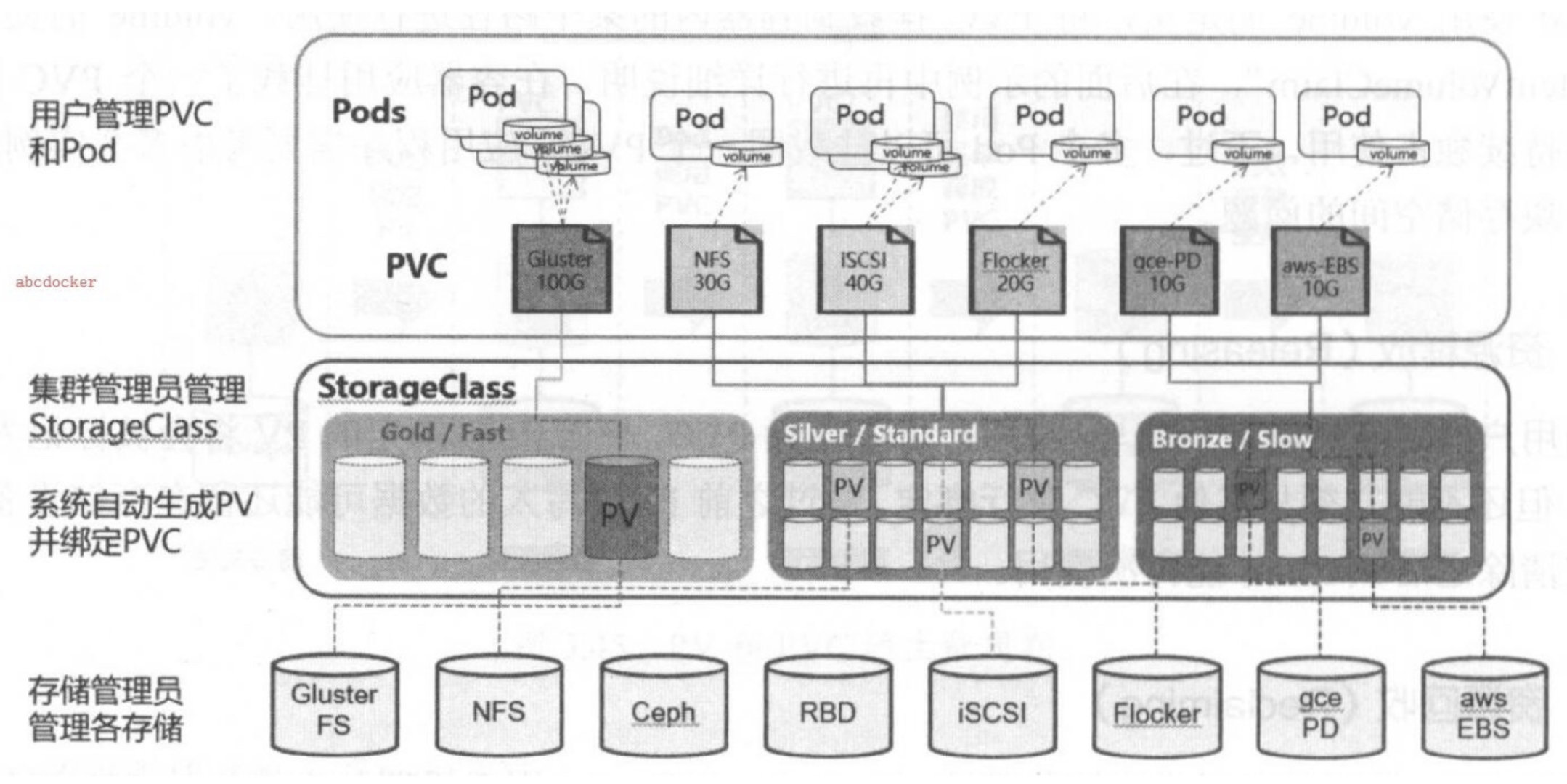
7.4.3 资源绑定 (Binding)
在用户定义好PVC后,系统将根据PVC对存储资源的请求 (存储空间和访问模式)在已存在的PV中选择一个满足PVC要求的PV,一旦找到,就将该PV与用户定义的PVC进行绑定,然后用户的应用就可以使用这个PVC了。如果系统中没有满足PVC要求的PV,PVC则会无限期处于Pending状态,直到等到系统管理员创建了一个符合要求的PV。PV一旦绑定在某个PVC上,就被这个PVC独占,不能再与其他PVC进行绑定了。在这种情况下,当PVC申请的存储空间比PV的少时,整个PV的空间都能够为PVC所用,可能会造成资源的浪费。如果资源供应使用的是动态模式,则系统在PVC找到合适的StorageClass后,将会自动创建PV并完成PVC的绑定。
7.4.4 资源使用 (Using)
Pod 使用volume的定义, 将 PVC 挂载到容器内的某个路径进行使用。volume 的类型为 persistentVoulumeClaim , 在容器应用挂载了一个 PVC 后, 就能被持续独占使用。
不过, 多个Pod可以挂载同一个PVC, 应用程序需要考虑多个实例共同访问一块存储空间的问题。
7.4.5 资源释放 (Releasing)
当用户对存储资源使用哪个完毕后,用户可以删除PVC,与该PVC绑定的PV将会被标记为已释放,但还不能立刻与其他PVC进行绑定。通过之前PVC写入的数据可能还留在存储设备上,只有在清除之后该PV才能继续使用。
7.4.6 资源回收 (Reclaiming)
对于PV,管理员可以设定回收策略(Reclaim Policy)用于设置与之绑定的PVC释放资源之后,对于遗留数据如何处理。只有PV的存储空间完成回收,才能供新的PVC绑定和使用。
7.4.7 持久化卷声明的保护
PVC 保护的目的是确保由 pod 正在使用的 PVC 不会从系统中移除,因为如果被移除的话可能会导致数据丢失,当启用 PVC 保护 alpha 功能时,如果用户删除了一个 pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用。
7.4.8 PV 的类型 及 访问模式
PersistentVolume 类型以插件形式实现。以下仅列部分常用类型:
- GCEPersistentDisk
- AWSElasticBlockStore
- NFS
- RBD (Ceph Block Device)
- CephFS、Glusterfs
PV 的访问模式 有三种 ReadWriteOnce 、 ReadOnlyMany 、 ReadWriteMany
PersistentVolume 可以以资源提供者支持的任何方式挂载到主机上。如下表所示,供应商具有不同的功能,每个PV 的访问模式都将被设置为该卷支持的特定模式。例如,NFS 可以支持多个读/写客户端,但特定的 NFS PV 可能以只读方式导出到服务器上。每个 PV 都有一套自己的用来描述特定功能的访问模式。
- ReadWriteOnce——该卷可以被单个节点以读/写模式挂载(命令行缩写:RWO)
- ReadOnlyMany——该卷可以被多个节点以只读模式挂载(命令行缩写:ROX)
- ReadWriteMany——该卷可以被多个节点以读/写模式挂载(命令行缩写:RWX)
一个卷一次只能使用一种访问模式挂载,即使它支持很多访问模式。以下只列举部分常用插件
| Volume 插件 | ReadWriteOnce | ReadOnlyMany | ReadWriteMany |
|---|---|---|---|
| AWSElasticBlockStore | ✓ | - | - |
| CephFS | ✓ | ✓ | ✓ |
| GCEPersistentDisk | ✓ | ✓ | - |
| Glusterfs | ✓ | ✓ | ✓ |
| HostPath | ✓ | - | - |
| NFS | ✓ | ✓ | ✓ |
| RBD | ✓ | ✓ | - |
7.4.9 PV 的回收策略 及 阶段状态
回收策略包括
- Retain(保留)——手动回收
- Recycle(回收)——基本擦除( rm -rf /thevolume/* )【ps 在新版本中该策略已被弃用】
- Delete(删除)——关联的存储资产(例如 AWS EBS、GCE PD、Azure Disk 和 OpenStack Cinder 卷)将被删除。
当前,只有 NFS 和 HostPath 支持回收策略。AWS EBS、GCE PD、Azure Disk 和 Cinder 卷支持删除策略。
PV 可以处于以下的某种状态
- Available(可用)——一块空闲资源还没有被任何声明绑定
- Bound(已绑定)——卷已经被声明绑定
- Released(已释放)——声明被删除,但是资源还未被集群重新声明
- Failed(失败)——该卷的自动回收失败
命令行会显示绑定到 PV 的 PVC 的名称。
7.4.10 PV 的实验演练 - NFS
1、安装 NFS 服务器
# 所有的节点都需要安装 nfs-utils 和 rpcbind
$ yum install -y nfs-common nfs-utils rpcbind
$ mkdir -p /nfs01 /nfs02 /nfs03 /nfs04
$ chmod 777 /nfs01 /nfs02 /nfs03 /nfs04
$ chown nfsnobody /nfs01 /nfs02 /nfs03 /nfs04
$ cat /etc/exports
/nfs01 *(rw,no_root_squash,no_all_squash,sync)
/nfs02 *(rw,no_root_squash,no_all_squash,sync)
/nfs03 *(rw,no_root_squash,no_all_squash,sync)
/nfs04 *(rw,no_root_squash,no_all_squash,sync)
$ systemctl start rpcbind nfs
# 登陆k8s任意一台节点上测试下nfs
$ showmount -e 192.168.245.44
Export list for 192.168.245.44:
/nfs01 *
/nfs02 *
/nfs03 *
/nfs04 *
$ mkdir /test
$ mount -t nfs 192.168.245.44:/nfs01 /test/
$ cd /test/
$ touch tset.txt
$ echo lemon > test.txt
$ cat test.txt
lemon
$ umount /test
$ rm -rf /test
2、部署 PV
# cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfs01
server: 192.168.245.44
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv2
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfs02
server: 192.168.245.44
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv3
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfs03
server: 192.168.245.44
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv4
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: static
nfs:
path: /nfs04
server: 192.168.245.44
3、创建服务并使用 PVC
# cat pvc.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: arminto/my_nginx:v1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs"
resources:
requests:
storage: 1Gi
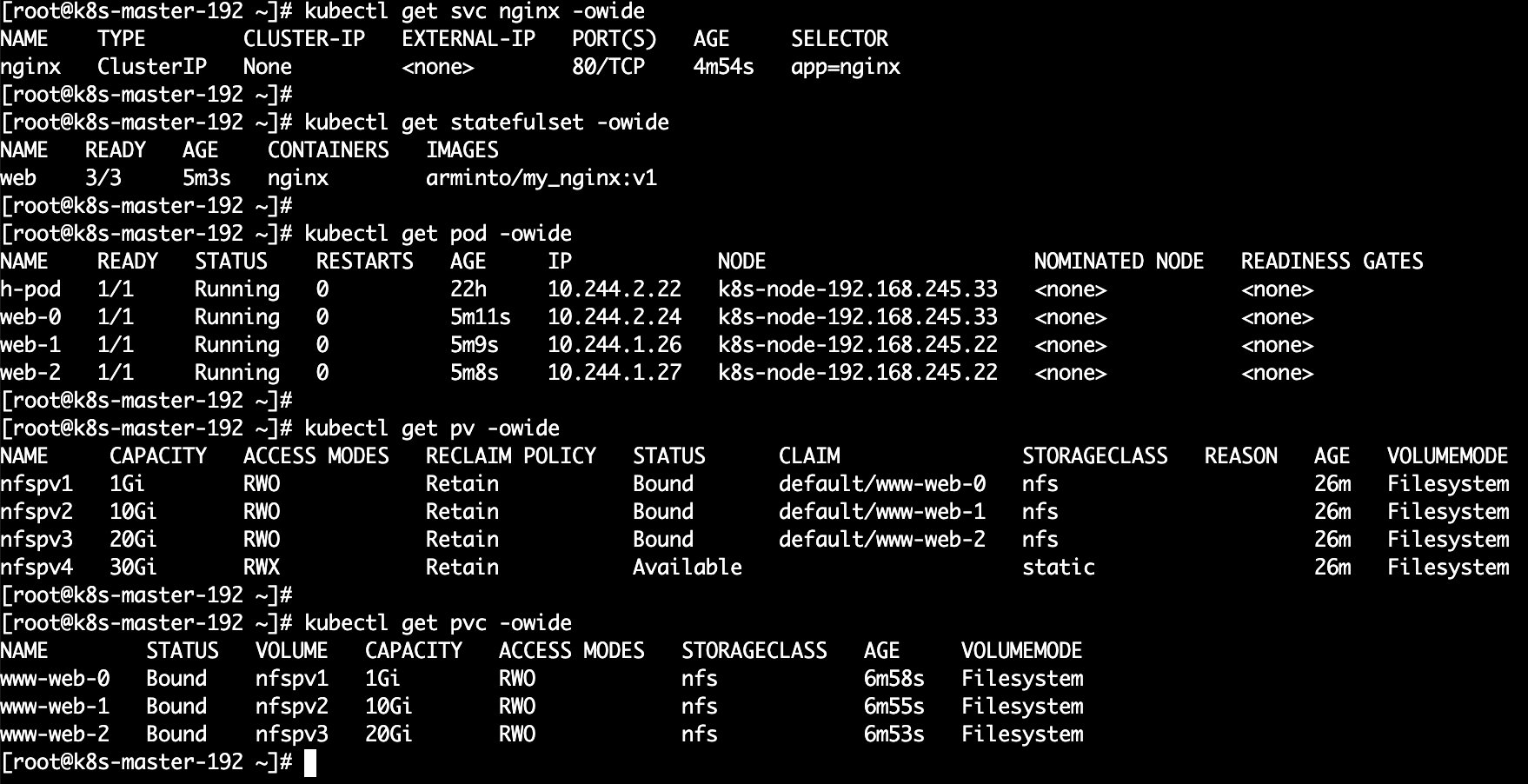
$ echo 'web-0' > /nfs01/index.html
$ echo 'web-1' > /nfs02/index.html
$ echo 'web-2' > /nfs03/index.html
$ curl 10.244.2.24
web-0
$ curl 10.244.1.26
web-1
$ curl 10.244.1.27
web-2
7.4.11 关于 StatefulSet 的说明
- 匹配 Pod name ( 网络标识 ) 的模式为:$(statefulset名称)-$(序号),比如上面的示例:web-0,web-1,web-2 。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
h-pod 1/1 Running 0 23h
web-0 1/1 Running 0 48m
web-1 1/1 Running 0 48m
web-2 1/1 Running 0 48m
- StatefulSet 为每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为: $(podname).(headless servername),也就意味着服务间是通过Pod域名来通信而非 Pod IP,因为当Pod所在Node发生故障时, Pod 会被飘移到其它 Node 上,Pod IP 会发生变化,但是 Pod 域名不会有变化。
$ kubectl exec -it h-pod -- /bin/sh
/ # ping -c 3 web-0.nginx
PING web-0.nginx (10.244.2.24): 56 data bytes
64 bytes from 10.244.2.24: seq=0 ttl=64 time=0.137 ms
64 bytes from 10.244.2.24: seq=1 ttl=64 time=0.056 ms
64 bytes from 10.244.2.24: seq=2 ttl=64 time=0.076 ms
- StatefulSet 使用 Headless 服务来控制 Pod 的域名,这个域名的 FQDN 为:$(servicename).$(namespace).svc.cluster.local,其中,“cluster.local” 指的是集群的域名。
$ kubectl get pod -owide -n kube-system | grep coredns
coredns-5c98db65d4-4v4kd 1/1 Running 13 47d 10.244.1.17
coredns-5c98db65d4-9k5xw 1/1 Running 7 47d 10.244.0.9
$ dig -t A nginx.default.svc.cluster.local. @10.244.0.9
;; ANSWER SECTION:
nginx.default.svc.cluster.local. 11 IN A 10.244.2.24
nginx.default.svc.cluster.local. 11 IN A 10.244.1.26
nginx.default.svc.cluster.local. 11 IN A 10.244.1.27
- 根据 volumeClaimTemplates,为每个 Pod 创建一个 pvc,pvc 的命名规则匹配模式:(volumeClaimTemplates.name)-(pod_name),比如上面的 volumeMounts.name=www, Podname=web-[0-2],因此创建出来的 PVC 是 www-web-0、www-web-1、www-web-2 。
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound nfspv1 1Gi RWO nfs 173m
www-web-1 Bound nfspv2 10Gi RWO nfs 172m
www-web-2 Bound nfspv3 20Gi RWO nfs 172m
- 删除 Pod 不会删除其 pvc,手动删除 pvc 将自动释放 pv
Statefulset的启停顺序
- 有序部署:部署StatefulSet时,如果有多个Pod副本,它们会被顺序地创建(从0到N-1)并且,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态。
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS
nfspv1 1Gi RWO Retain Available nfs
nfspv2 10Gi RWO Retain Available static
nfspv3 20Gi RWO Retain Available slow
$ kubectl apply -f pvc.yaml
service/nginx created
statefulset.apps/web created
# 这里可以看到第二个 pod 一直处于 pending 状态,导致第三个 pod 都没有创建出来
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 19s
web-1 0/1 Pending 0 16s
- 有序删除:当Pod被删除时,它们被终止的顺序是从N-1到0。
$ kubectl get pod -owide -n default -w
$ kubectl delete statefulset web -n default
- 有序扩展:当对 Pod 执行扩展操作时,与部署一样,它前面的Pod必须都处于Running和Ready状态。
$ kubectl scale statefulset/web --replicas=4
StatefulSet使用场景
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现。
- 稳定的网络标识符,即 Pod 重新调度后其 PodName 和 HostName 不变。
- 有序部署,有序扩展,基于 init containers 来实现。
- 有序收缩。
7.4.12 PV卷 的资源释放流程
生产环境下要再三确认后才可以进行如下操作
# statefulset > svc > pvc > 使用 edit 删除 pv 卷上的 pvc 记录
$ kubectl delete -f pvc.yaml
$ kubectl delete pvc www-web-0 www-web-1 www-web-2
# 虽然已经删除了 pvc,但实际上还并没有释放 pv,因为在pv的记录信息里面还是有使用者信息的,需要手工删除后才会释放
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS
nfspv1 1Gi RWO Retain Released default/www-web-0 nfs
nfspv2 10Gi RWO Retain Released default/www-web-1 nfs
nfspv3 20Gi RWO Retain Released default/www-web-2 nfs
nfspv4 30Gi RWX Retain Available static
# 手动删除这一段,pv 就会释放资源了, 其他的 pod 也就可以继续使用这些 pv 卷了
$ kubectl get pv nfspv1 -o yaml
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: www-web-0
namespace: default
resourceVersion: "69260"
uid: e175a86b-aa2c-4900-a7c4-faa1865315ab
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS
nfspv1 1Gi RWO Retain Available nfs
nfspv2 10Gi RWO Retain Available nfs
nfspv3 20Gi RWO Retain Available nfs
nfspv4 30Gi RWX Retain Available static
# 如果这些卷及数据都不想要了的话,直接在对应的nfs机器上删除挂在点上的数据,并在master上删除pv卷 kubectl delete pv xx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号