Prometheus 监控
 时序监控
时序监控
1、prometheus 架构介绍
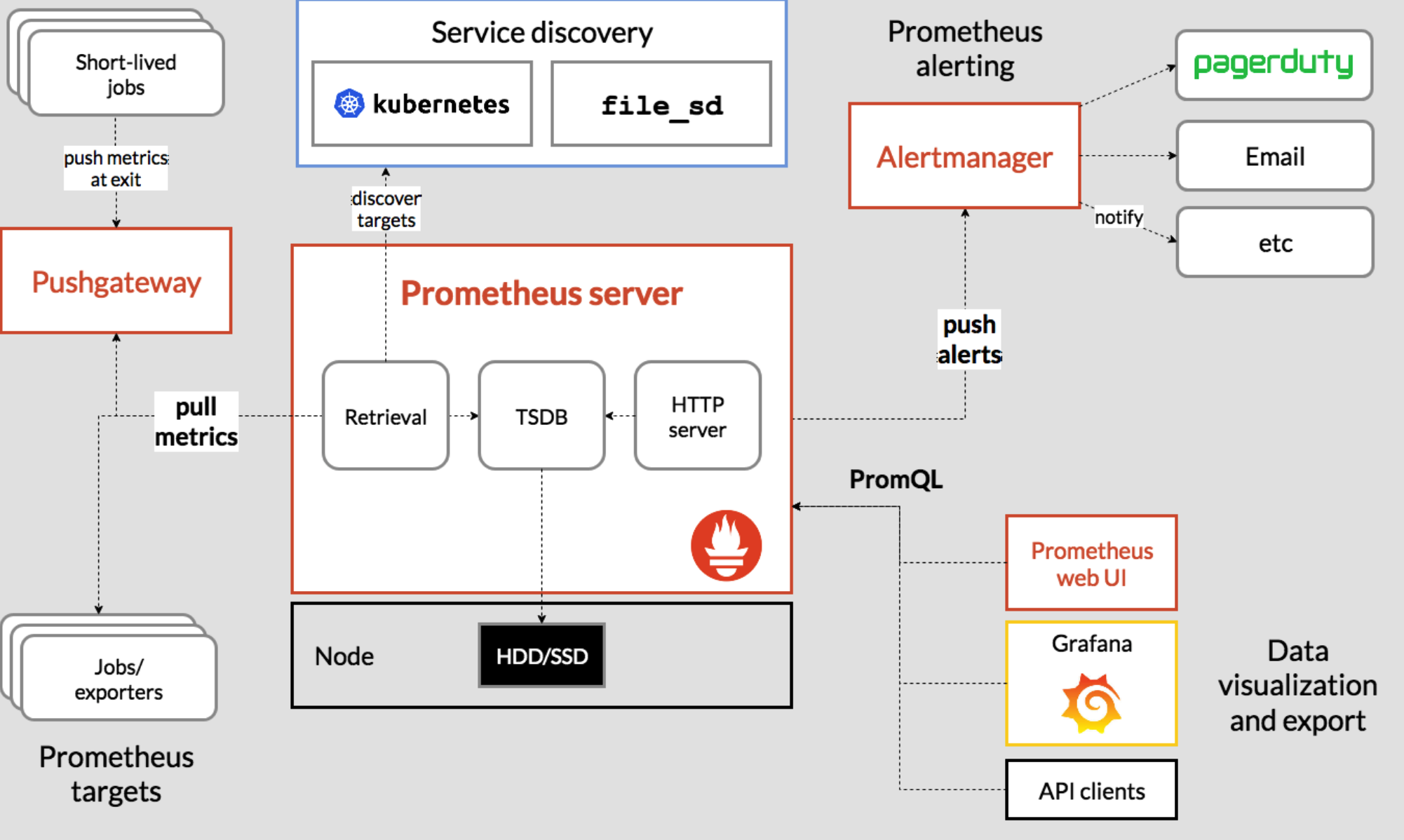
1.1 组件说明
prometheus server 是 Prometheus 组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
exporter 简单说是采集端,通过 http 服务的形式保留一个 url 地址,prometheus server 通过访问该 exporter 提供的 endpoint 端点,即可获取到需要采集的监控数据。
AlertManager 在 prometheus 中,支持基于 PromQL 创建告警规则,如果满足定义的规则,则会产生一条 告警信息,进入 AlertManager 进行处理。可以集成邮件,微信或者通过 webhook 自定义报 警。
Pushgateway 由于 Prometheus 数据采集采用 pull 方式进行设置的, 内置必须保证 prometheus server 和 对应的 exporter 必须通信,当网络情况无法直接满足时,可以使用 pushgateway 来进行中转, 可以通过 pushgateway 将内部网络数据主动 push 到 gateway 里面去,而 prometheus 采用 pull 方式拉取 pushgateway 中数据。
1.2 总结:
prometheus 负责从 pushgateway 和 job 中采集数据, 存储到后端 Storatge 中,可以通过 PromQL 进行查询, 推送 alerts 信息到 AlertManager。 AlertManager 根据不同的路由规则 进行报警通知。
2、prometheus 部署
准备物料包
# 修改主机名称
$ hostnamectl set-hostname prometheus
# 创建物料包目录
$ mkdir /usr/local/software/ && cd /usr/local/software/
# 上传 prometheus 软件包
$ ls /usr/local/software/
prometheus-2.31.1.linux-amd64.tar.gz
# 解压安装
$ tar xf prometheus-2.31.1.linux-amd64.tar.gz
$ mv prometheus-2.31.1.linux-amd64 /usr/local/prometheus-2.31.1
$ ln -s /usr/local/prometheus-2.31.1/ /usr/local/prometheus
$ mkdir /data
# 添加到系统服务
$ cat /usr/lib/systemd/system/prometheus.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/usr/local/prometheus/prometheus --storage.tsdb.path=/usr/local/prometheus/data --config.file=/usr/local/prometheus/prometheus.yml
[Install]
WantedBy=multi-user.target
# 启动prometheus
$ systemctl start prometheus && systemctl enable prometheus
访问 http://ip:9090
3、Prometheus 配置文件介绍
global: 此片段指定的是 prometheus 的全局配置, 比如采集间隔,抓取超时时间等。
rule_files: 此片段指定报警规则文件, prometheus 根据这些规则信息,会推送报警信息到 alertmanager 中。
scrape_configs: 此片段指定抓取配置,prometheus 的数据采集通过此片段配置。
alerting: 此片段指定报警配置, 这里主要是指定 prometheus 将报警规则推送到指定的 alertmanager 实例地址。
remote_write: 指定后端的存储的写入 api 地址。
remote_read: 指定后端的存储的读取 api 地址。
Global 配置参数
# How frequently to scrape targets by default.
[ scrape_interval: <duration> | default = 1m ] # 抓取间隔
# How long until a scrape request times out.
[ scrape_timeout: <duration> | default = 10s ] # 抓取超时时间
# How frequently to evaluate rules.
[ evaluation_interval: <duration> | default = 1m ] # 评估规则间隔
scrapy_config 配置参数,一个 scrape_config 片段指定一组目标和参数, 目标就是实例,指定采集的端点, 参数描述如何采集这些实例, 主要参数如下:
scrape_interval: 抓取间隔,默认继承 global 值。
scrape_timeout: 抓取超时时间,默认继承 global 值。
metric_path: 抓取路径, 默认是/metrics
*_sd_configs: 指定服务发现配置
static_configs: 静态指定服务 job。
relabel_config: relabel 设置。
4、PromQL 介绍
Prometheus 提供了一种名为 PromQL (Prometheus 查询语言)的函数式查询语言,允许用户实 时选择和聚合时间序列数据。表达式的结果既可以显示为图形,也可以在 Prometheus 的表 达式浏览器中作为表格数据查看,或者通过 HTTP API 由外部系统使用。
运算
-
乘:*
-
除:/
-
加:+
-
减:-
常用函数
- sum() 函数:求出找到所有 value 的值
- irate() 函数:统计平均速率
- by (标签名)
范围匹配
- 5 分钟之内 [5m]
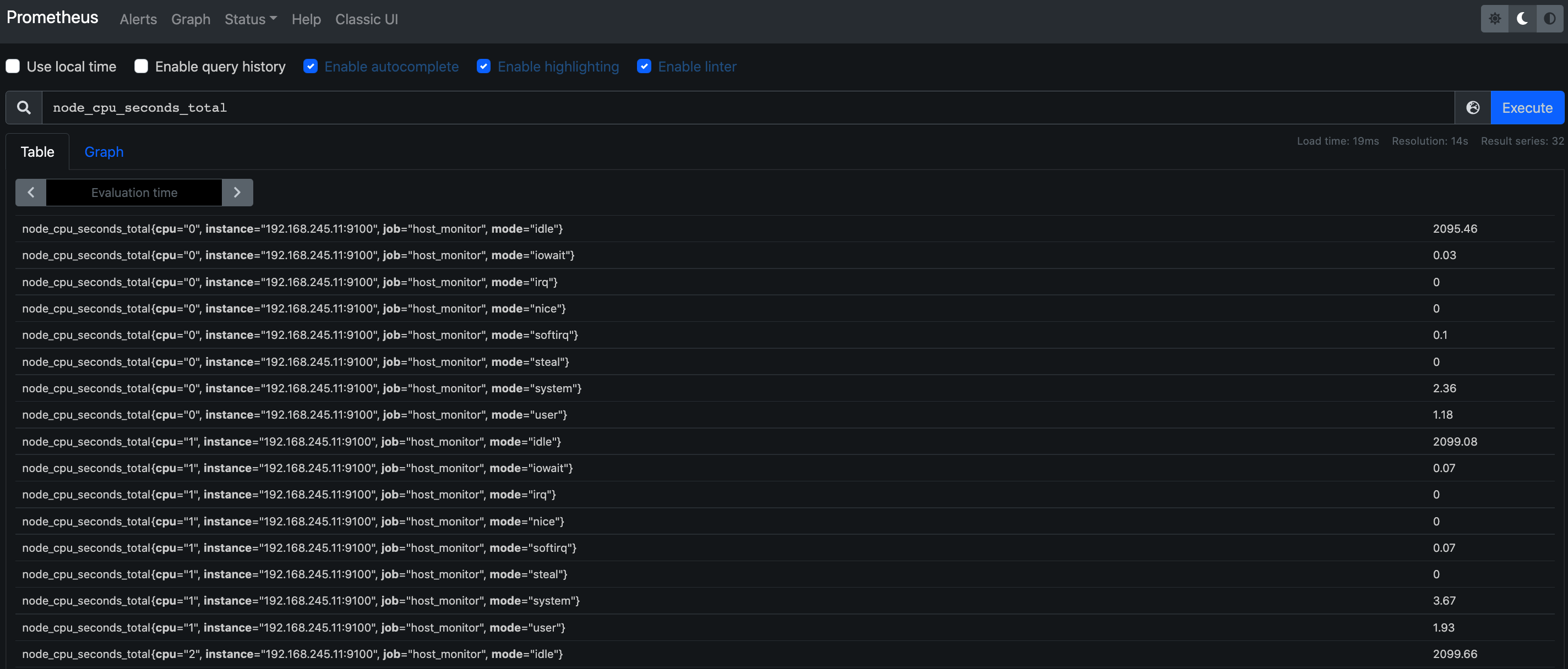
4.1 查询指定 mertic_name
需要先安装node_exporter组件(8.1节有详细步骤)
node_cpu_seconds_total
4.2 带标签的查询
node_cpu_seconds_total{mode="iowait"}

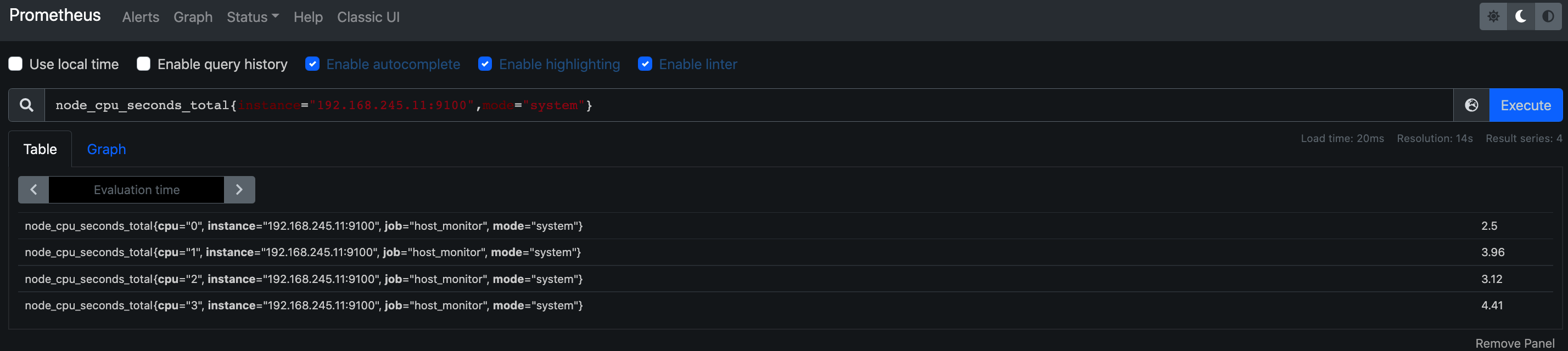
4.3 多标签查询
node_cpu_seconds_total{instance="192.168.245.11:9100",mode="system"}
4.4 计算 CPU 使用率
100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100)

4.5 计算内存使用率
100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100

4.6 计算磁盘使用率
100 - (((node_filesystem_size_bytes{fstype=~"xfs|ext4"} - node_filesystem_free_bytes{fstype=~"xfs|ext4"}) / node_filesystem_size_bytes{fstype=~"xfs|ext4"}) * 100)

4.7 主机检测状态
1 代表健康;2代表死亡

5、grafana 接入 prometheus
官方 https://grafana.com/ 下载物料包
$ yum localinstall grafana-enterprise-8.2.3-1.x86_64.rpm -y
$ systemctl start grafana-server && systemctl enable grafana-server
检查grafana服务是否正常启动

访问 Http://ip:3000 默认用户名 密码 admin/admin
登录后提示需要修改密
随后就进入主页面
添加 prometheus 数据源,简单写下配置保存即可
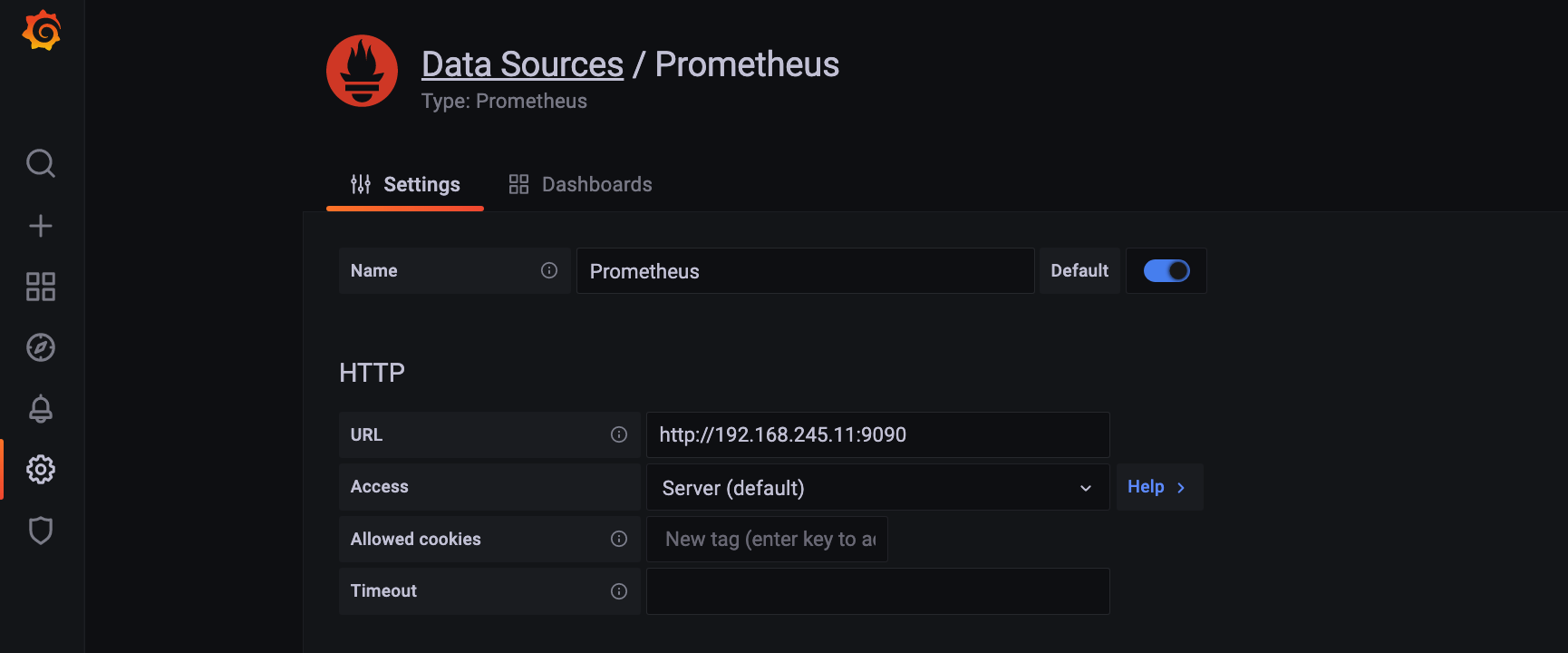
点击 save & test 这步必须通过

6、Alertermanager 告警模块部署
上传 alertermanager 物料包
# 安装alertmanager
$ tar xf alertmanager-0.23.0.linux-amd64.tar.gz
$ mv alertmanager-0.23.0.linux-amd64 /usr/local/alertmanager-0.23.0
$ ln -s /usr/local/alertmanager-0.23.0/ /usr/local/alertmanager
# 启动脚本
$ cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager System
Documentation=alertmanager System
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
# 备份配置文件
$ cd /usr/local/alertmanager && cp alertmanager.yml alertmanager.yml.bak
# 检查语法
$ ./amtool check-config alertmanager.yml
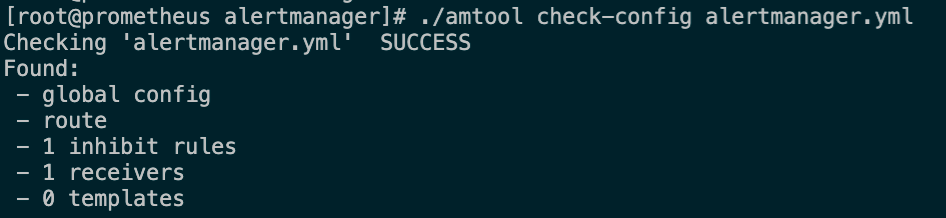
至此alertmanager就已部署完毕
7、prometheus 告警实战
7.1 邮件告警配置
编辑alertmanager.yml配置文件
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'lemon_row@163.com'
smtp_auth_username: 'lemon_row@163.com'
smtp_auth_password: 'XWJRKRFQVZHPCXHC'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'lemon_row@163.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
检查配置文件是否有语法问题
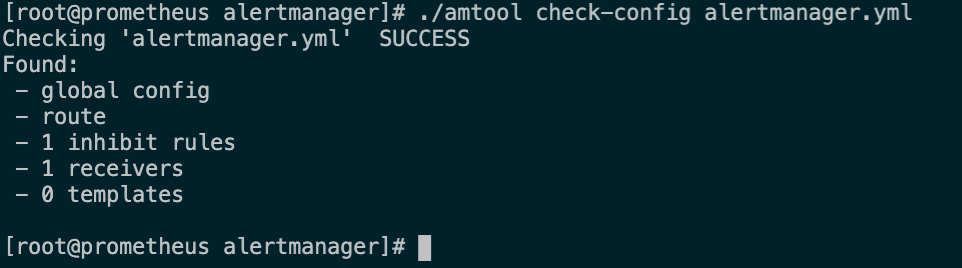
启动alertmanager服务
systemctl start alertmanager && systemctl enable alertmanager

修改 prometheus.yml 配置文件
1、修改 prometheus.yml 的 alerting 部分
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.245.11:9093
2、定义告警文件
rule_files:
- rules/*.yml
7.2 编写告警规则并验证
$ cd /usr/local/prometheus && mkdir rules && cd rules/
$ cat host_monitor.yml
groups:
# 告警规则的名称。
- name: node-up
rules:
- alert: node-up
# 基于 PromQL 表达式告警触发条件,用于计算是否有时间序列满足该条件。
expr: up == 0
# for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在 等待期间新产生告警的状态为 pending。
for: 15s
# 自定义标签,允许用户指定要附加到告警上的一组附加标签。
labels:
# 告警级别
severity: 1
team: node
# 用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations 的内容在告警产生时会一同作为参数发送到 Alertmanager。
annotations:
# 描述告警的概要信息,description 用于描述告警的详细信息。(同时 Alertmanager 的 UI 也会根据这两个标签值,显示告警信息。)
summary: "{{$labels.instance}}Instance has been down for more than 15 seconds"
$ ./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 1 rule files found
Checking rules/host_monitor.yml
SUCCESS: 1 rules found
# 最后重启prometheus服务生效
$ systemctl restart prometheus
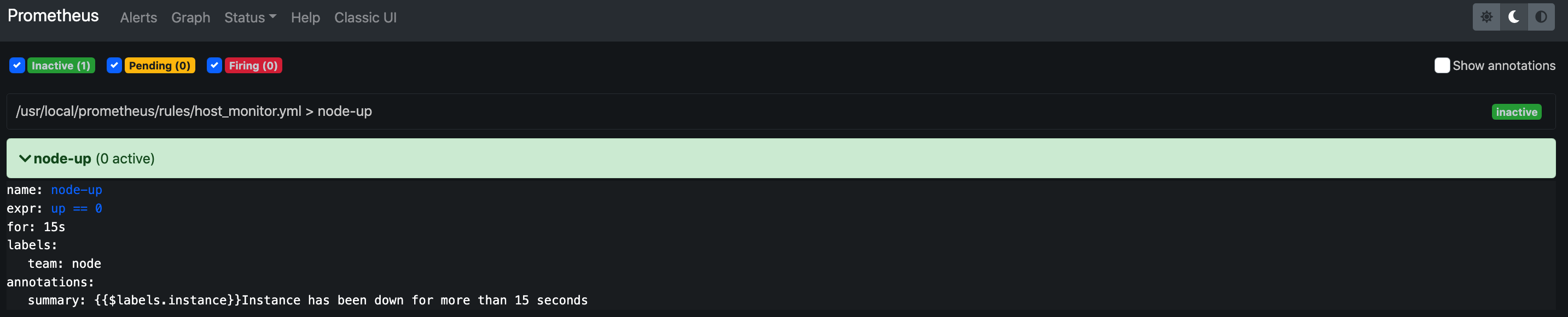
状态说明 Prometheus Alert 告警状态有三种状态:Inactive、Pending、Firing。
1、Inactive:非活动状态,表示正在监控,但是还未有任何警报触发。
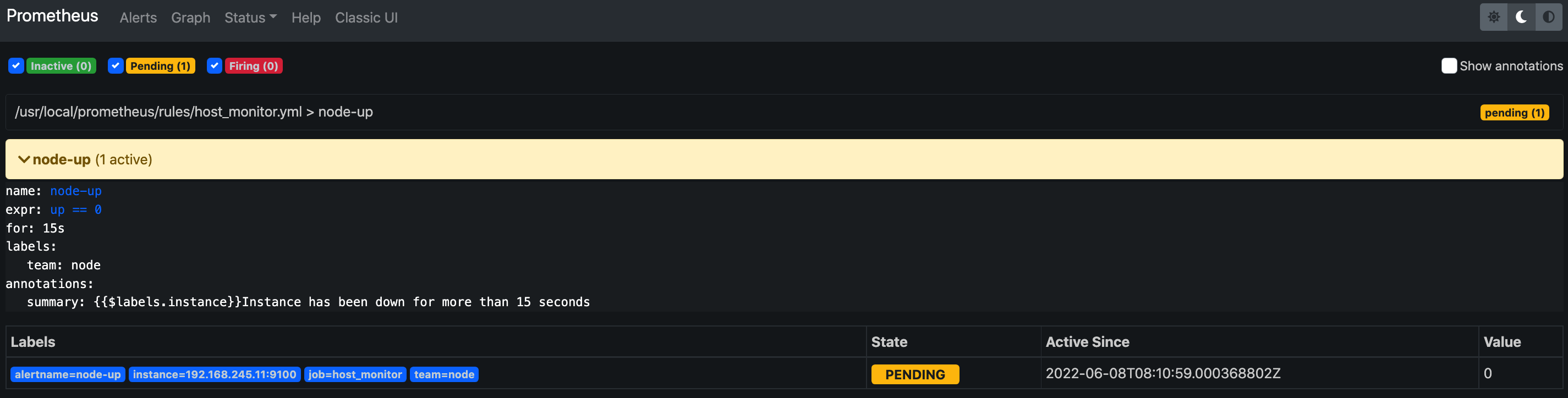
2、Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所 以等待验证,一旦所有的验证都通过,则将转到 Firing 状态。
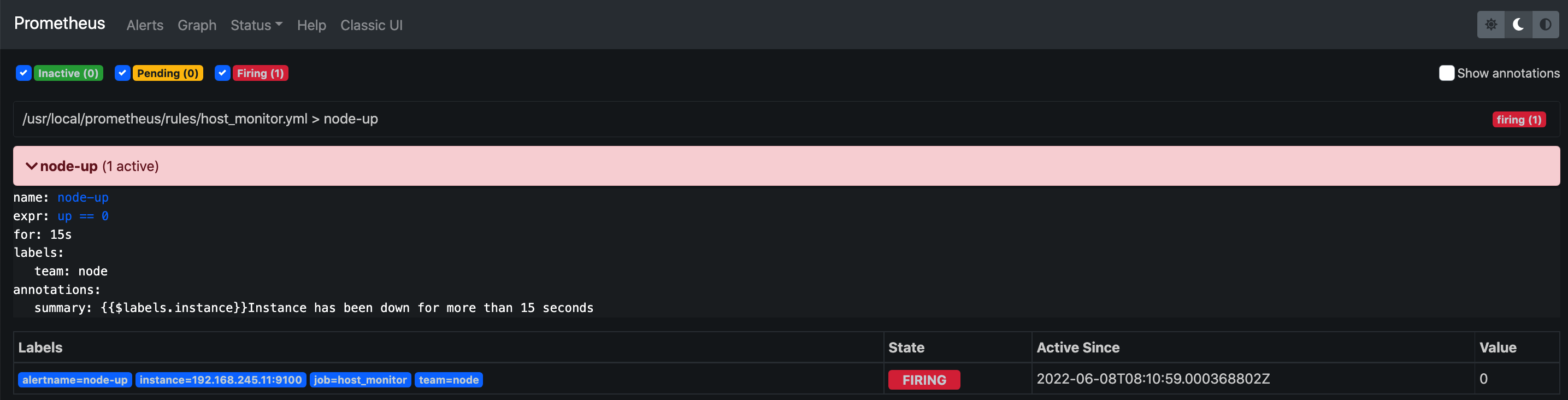
3、Firing:将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警 报解除,则将状态转到 Inactive,如此循环。
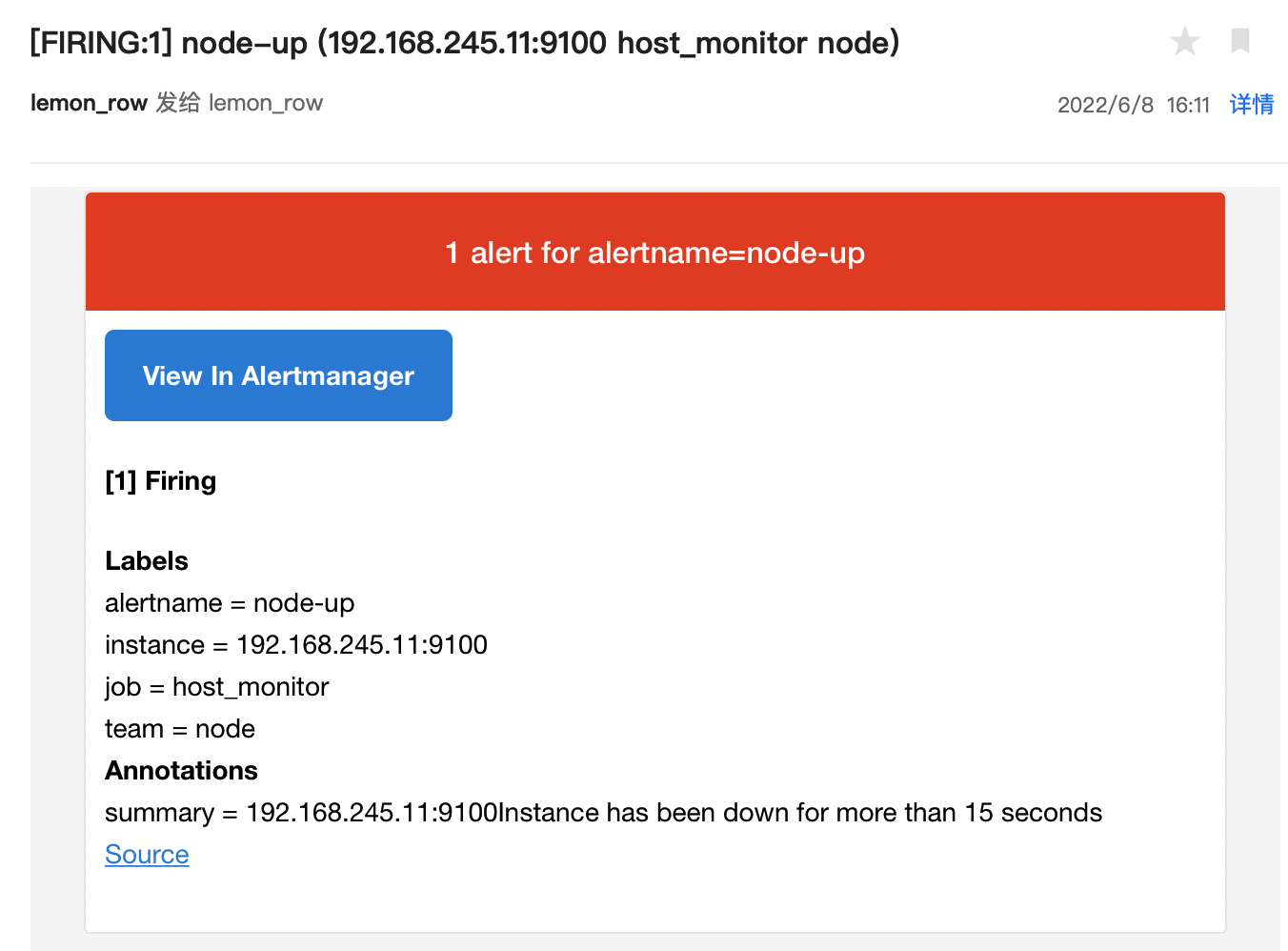
停止node_exporter 观察alerts和邮件告警
systemctl stop node_exporter
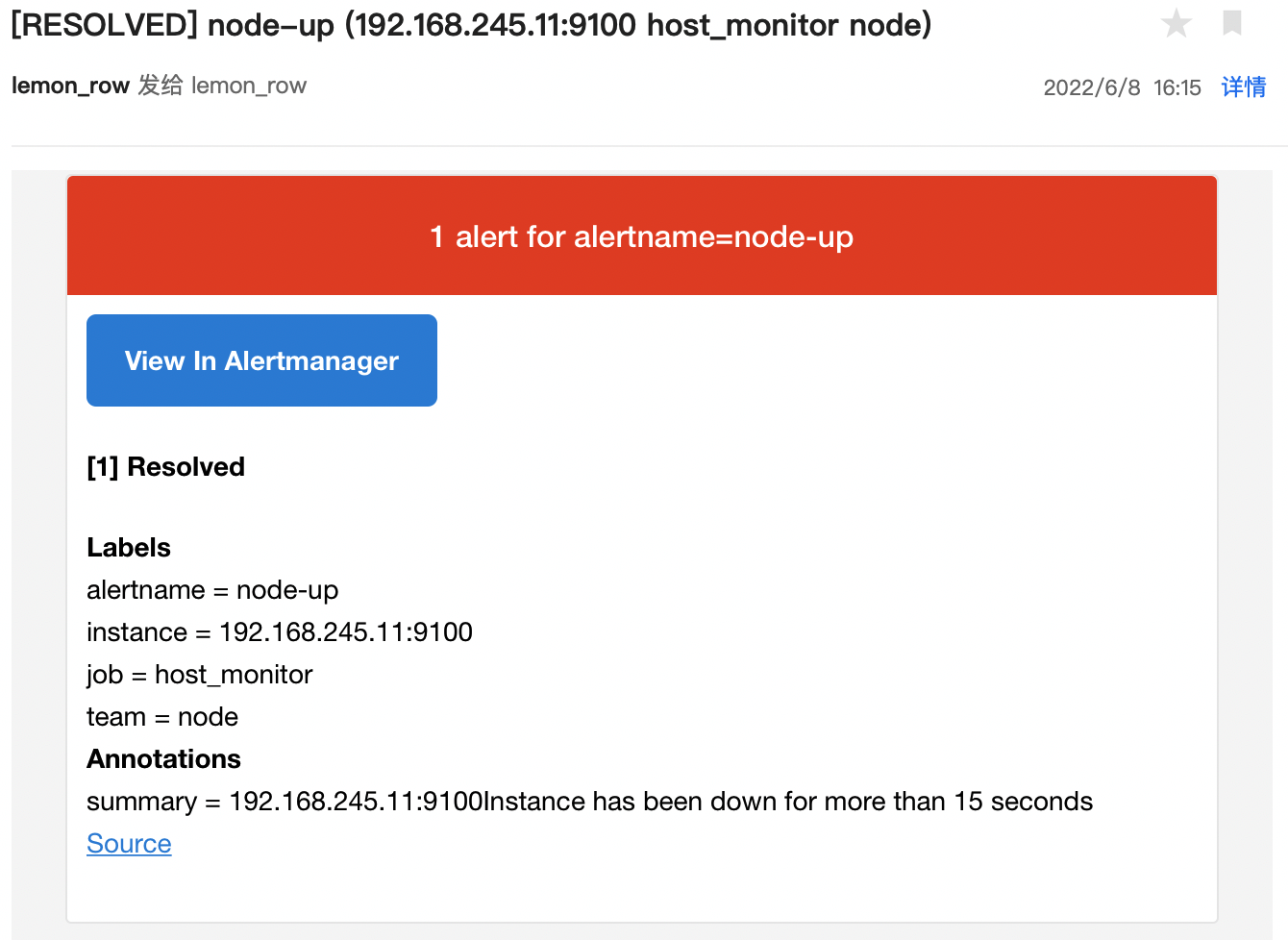
恢复node_exporter 观察alerts和邮件告警
systemctl start node_exporter

7.3 优化告警模板
1、新建模板文件
cat /usr/local/alertmanager/email.tmpl
{{ define "email.to.html" }}
{{ if gt (len .Alerts.Firing) 0 }}{{ range .Alerts }}
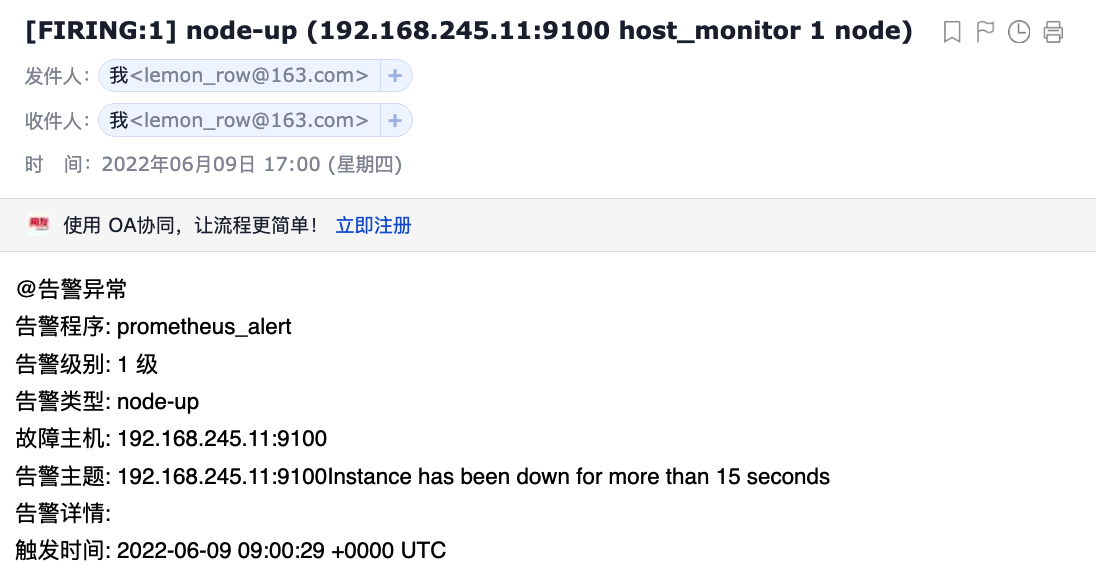
@告警异常 <br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt }} <br>
{{ end }}
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}{{ range .Alerts }}
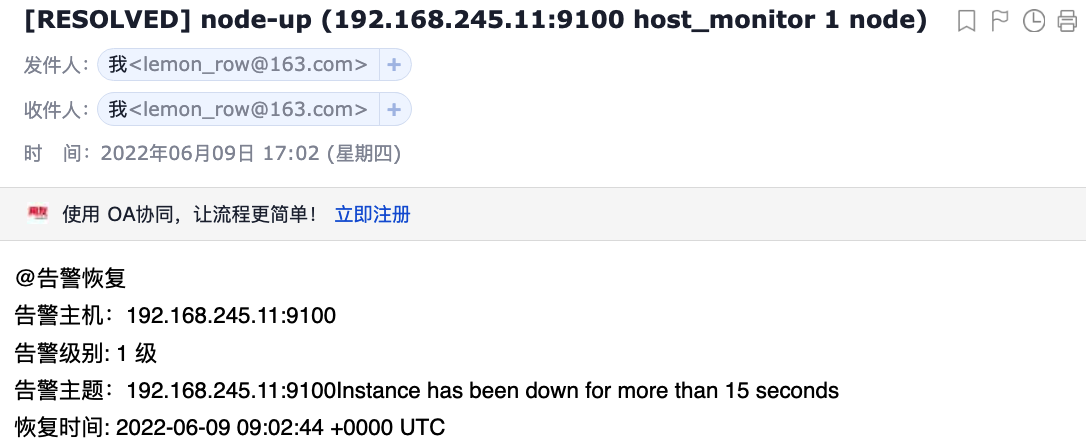
@告警恢复 <br>
告警主机: {{ .Labels.instance }} <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警主题: {{ .Annotations.summary }} <br>
恢复时间: {{ .EndsAt }} <br>
{{ end }}
{{ end }}
{{ end }}
2、修改配置文件使用模板
cat /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'lemon_row@163.com'
smtp_auth_username: 'lemon_row@163.com'
smtp_auth_password: 'XWJRKRFQVZHPCXHC'
smtp_require_tls: false
# 引用模版发送, 不写默认就会引用默认的
templates:
- '/usr/local/alertmanager/email.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
# 使用模板的方式发送
- to: 'lemon_row@163.com'
html: '{{ template "email.to.html" . }}'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
3、重启alertmanager生效
systemctl restart alertmanager
4、停止node_exporter 观察邮件告警
systemctl stop node_exporter
5、开启node_exporter 观察邮件告警
systemctl start node_exporter
7.4 企业微信告警
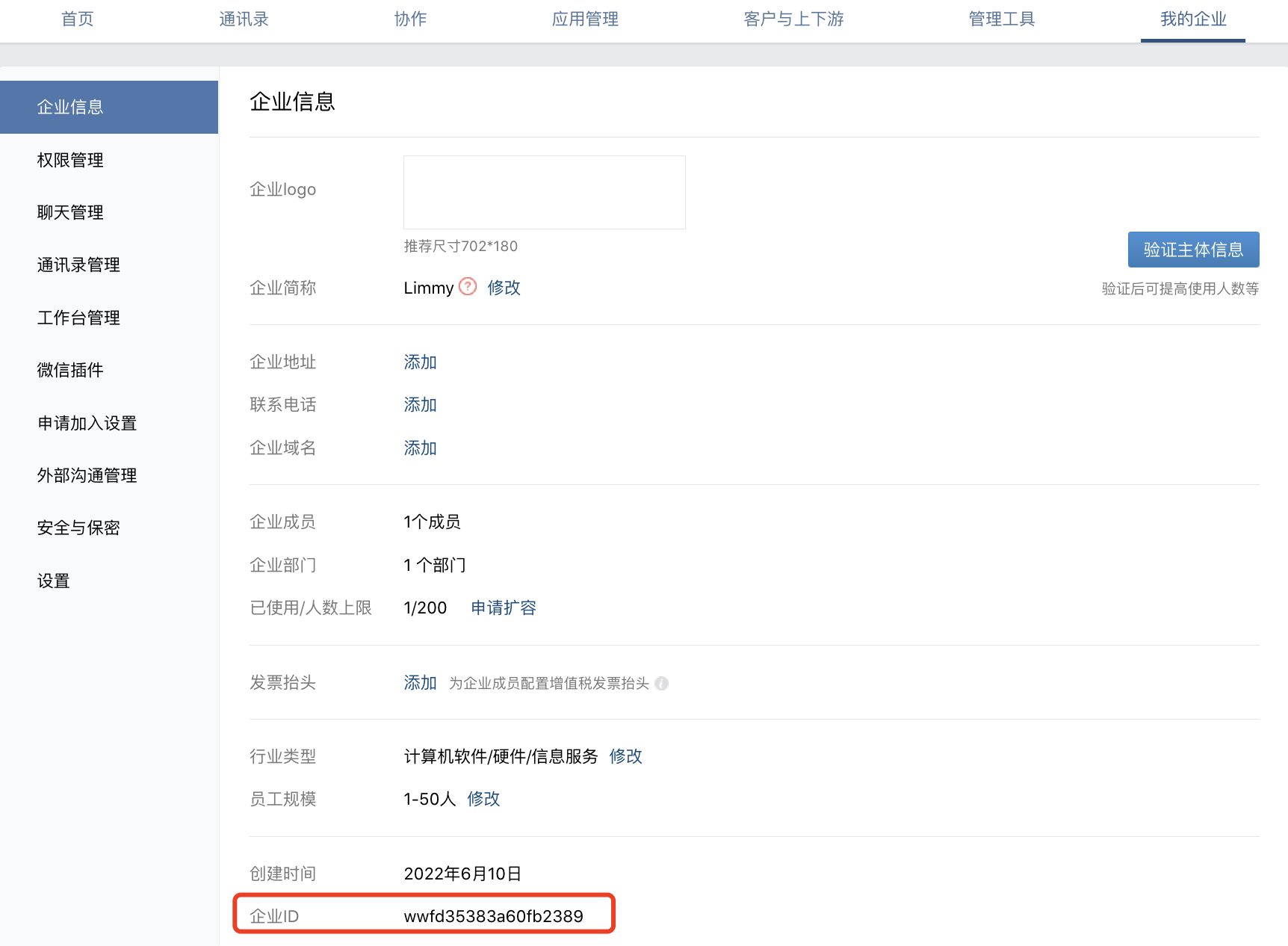
1、corp_id: 企业微信账号唯一 ID, 可以在我的企业中查看;
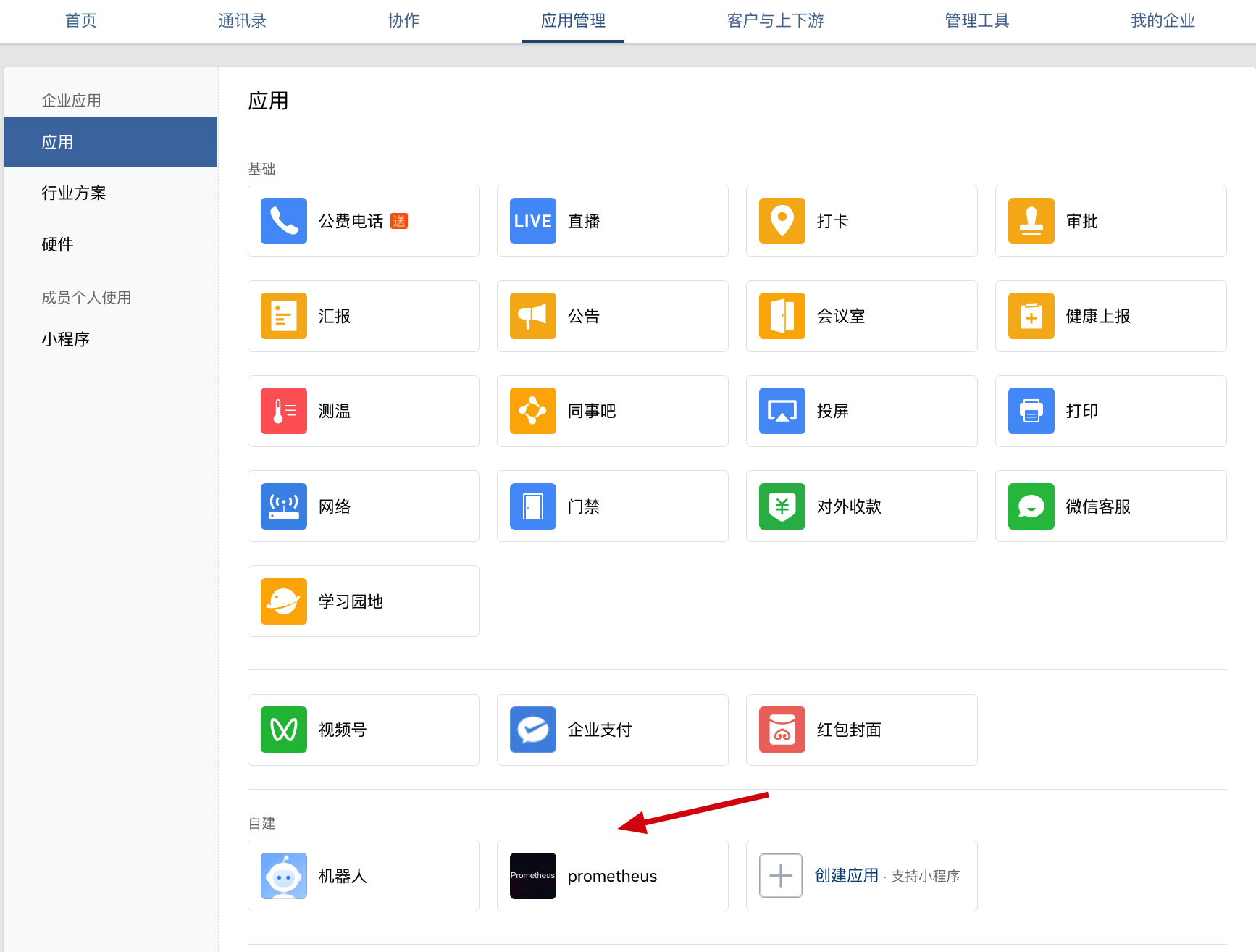
2、agent_id & api_secret 第三方企业应用的 ID和密钥

3、to_party,需要发送的组(部门ID)

4、修改alertmanager配置
cat /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
templates:
- '/usr/local/alertmanager/wechat.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
# 企业ID
- corp_id: 'wwfd35383a60fb2389'
# 应用ID
agent_id: '1000002'
# 部门ID
to_party: '1'
# 应用密钥
api_secret: '_2aocwGZYKTBQYW9oyK4dbUT_U_wYgxk-UPnlOsj8Tg'
send_resolved: true
message: '{{ template "wechat.tmpl" . }}'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
5、编写企微告警模板
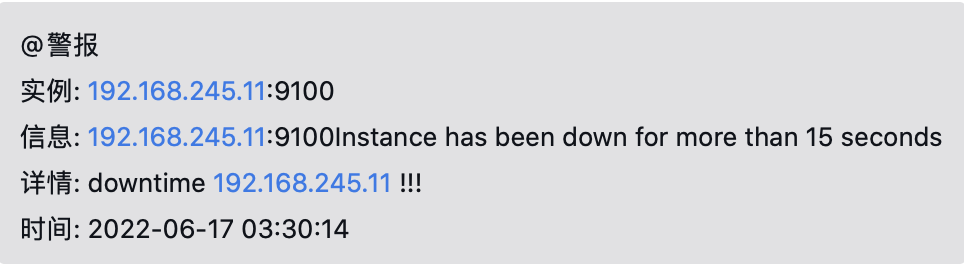
cat /usr/local/alertmanager/wechat.tmpl
{{ define "wechat.tmpl" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
@警报
实例: {{ .Labels.instance }}
信息: {{ .Annotations.summary }}
详情: downtime 192.168.245.11 !!!
时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
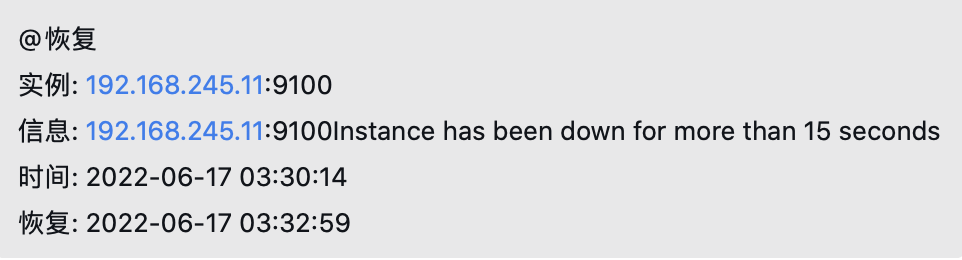
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
@恢复
实例: {{ .Labels.instance }}
信息: {{ .Annotations.summary }}
时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
恢复: {{ .EndsAt.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- end }}
6、重启alertmanager生效配置
systemctl restart alertmanager
7、关闭 开启 node_exporter进行验证
systemctl stop node_exporter
systemctl start node_exporter
7.5 告警的标签、路由、分组


 浙公网安备 33010602011771号
浙公网安备 33010602011771号