Docker
 容器引擎
容器引擎
一、Docker简介
Docker是基于Go语言实现的云开源项目

1. what - 什么是Docker ?
为什么会有Docker出现?
一款产品从开发到上线, 从操作系统, 到运行环境, 再到应用配置。作为开发 + 运维之间的协作就需要关心很多东西, 这也是很多互联网公司都不得不面对的问题,特别是各种版本的迭代之后,不同版本环境的兼容,对运维人员都是考验。
环境配置如此麻烦, 换一台机器, 就要重来一次, 费力费时。很多人想到, 能不能从根本上解决问题, 软件能否可以带环境安装? 也就是说, 安装的时候, 把原始环境一模一样地复制过来。开发人员利用 Docker 可以消除协作编码时“在我的机器上可正常工作”的问题。
传统上认为,软件编码开发/测试结束后,所产出的成果即是程序或是能够编译执行的二进制字节码等(java为例)。而为了让这些程序可以顺利执行,开发团队也得准备完整的部署文件,让维运团队得以部署应用程式,开发需要清楚的告诉运维部署团队,用的全部配置文件 + 所有软件环境;不过,即便如此,仍然常常发生部署失败的状况。Docker镜像的设计使得Docker可以打破过去「程序即应用」的观念。透过镜像(images)将作业系统核心除外,运作应用程式所需要的系统环境,由下而上打包,达到应用程式跨平台间的无缝接轨运作。
Docker 的理念是什么?
Docker的主要目标 “构建、发布和运行任何应用程序在任何地方”,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP(可以是一个WEB应用或数据库应用等等)及其运行环境能够做到 “一次封装,到处运行”。
2. why - 为什么使用Docker?
时光倒流
传统部署时代: 早期,组织在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况,结果,其他应用程序的性能将下降。一个解决方案是在不同的物理服务器上运行每个应用程序。但这并没有随着资源利用不足而扩展,并且组织维护许多物理服务器的成本很高。
虚拟化部署时代: 作为解决方案,引入了虚拟化。它允许您在单个物理服务器的CPU上运行多个虚拟机(VM)。虚拟化允许在VM之间隔离应用程序,并提供安全级别,因为一个应用程序的信息不能被另一应用程序自由访问。
虚拟化可以更好地利用物理服务器中的资源,并可以实现更好的可伸缩性,因为可以轻松地添加或更新应用程序,降低硬件成本等等。借助虚拟化,您可以将一组物理资源呈现为一组一次性虚拟机。
每个VM都是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代: 容器类似于VM,但是它们具有轻松的隔离属性,可以在应用程序之间共享操作系统(OS)。因此,容器被认为是轻质的。与VM相似,容器具有自己的文件系统,CPU,内存,进程空间等。由于它们与基础架构分离,因此可以跨云和OS分发进行移植。
容器之所以受欢迎,是因为它们提供了额外的好处,例如:
- 敏捷的应用程序创建和部署:与使用VM映像相比,容器映像创建的简便性和效率更高。
- 持续的开发,集成和部署:通过快速简便的回滚(由于图像不可更改),提供可靠且频繁的容器映像构建和部署。
- 开发和运营的关注点分离:在构建/发布时间而不是部署时间创建应用程序容器映像,从而将应用程序与基础架构分离。
- 可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他信号。
- 跨开发,测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 云和操作系统分发的可移植性:可在Ubuntu,RHEL,CoreOS,本地,主要公共云以及其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行操作系统到使用逻辑资源在操作系统上运行应用程序。
- 松散耦合,分布式,弹性,解放的微服务:应用程序被分解成较小的独立部分,并且可以动态部署和管理–而不是在一台大型单机上运行的整体堆栈。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
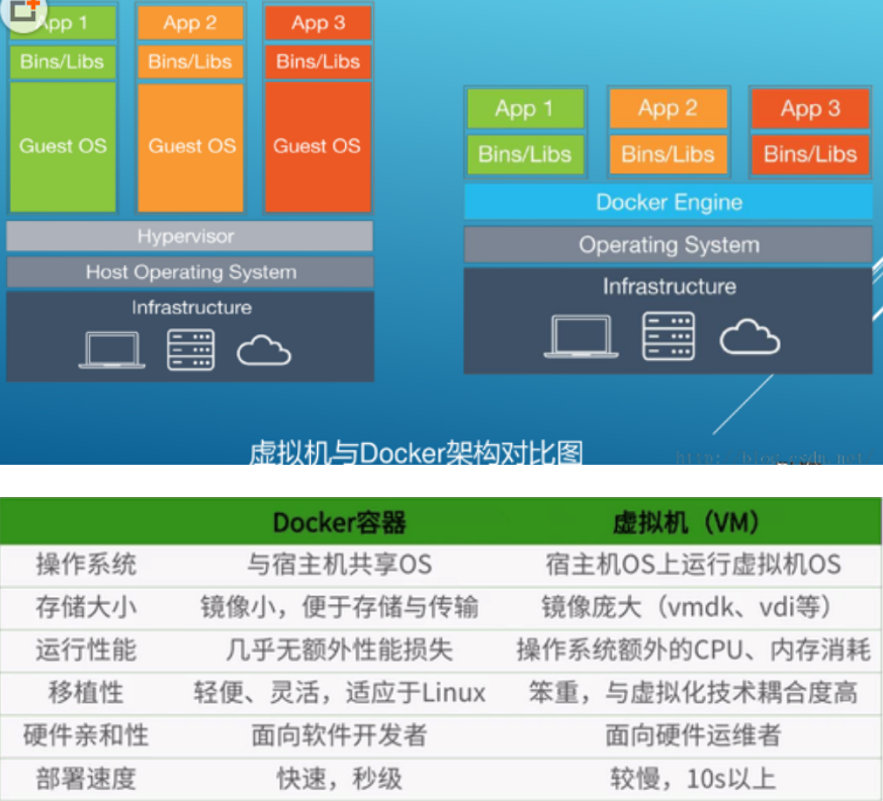
Docker与集装箱的对比
| 特性 | 集装箱 | Docker |
|---|---|---|
| 打包对象 | 几乎任何货物 | 任何软件及依赖 |
| 硬件依赖 | 标准形状和接口允许集装箱被装卸到各种交通工具上 | 容器无需修改便可运行在几乎所有平台 |
| 隔离性 | 集装箱可以重叠起来一起运输,🍌再也不会被铁桶压烂了 | 资源、网络、库都是隔离的,不会出现依赖性问题 |
| 自动化 | 标准接口使集装箱很容易自动装卸和移动 | 提供 run、start、stop等标准化操作 |
| 高效性 | 无需开箱,可在各种交通工具间快速搬运 | 轻量级,能够快速启动和迁移 |
| 指责分工 | 货主只需考虑把什么放到集装箱中;承运方只需关心怎样运输集装箱 | 开发人员只需考虑怎么写代码,运维人员只需关心如何解决配置基础环境 |
| 一句话:容器使软件具备了超强的可移植能力。 |
为什么Docker 比 KVM快
1、docker有着比虚拟机更少的抽象层。由于docker不需要Hypervisor实现硬件资源虚拟化,运行在docker容器上的程序直接使用的都是实际物理机的硬件资源。因此在CPU、内存利用率上docker将会在效率上有明显优势。
2、docker利用的是宿主机的内核,而不需要Guest OS。因此,当新建一个容器时,docker不需要和虚拟机一样重新加载一个操作系统内核。仍而避免引寻、加载操作系统内核返个比较费时费资源的过程,当新建一个虚拟机时,虚拟机软件需要加载Guest OS,返个新建过程是分钟级别的。而docker由于直接利用宿主机的操作系统,则省略了返个过程,因此新建一个docker容器只需要几秒钟。
3、如下图所示:
3. How to install – 怎么安装 ?
Docker安装要求
Docker 运行在 CentOS 7 上,要求系统为64位、系统内核版本为 3.10 以上。
Docker 运行在 CentOS-6. 5 或更高的版本上,要求系统为64位、系统内核版本为 2. 6.32-431 或者更高版本。
Centos7 安装 ( 通过 uname -r 命令查看你当前的内核版本是否达到要求 )

从2017年3月开始docker在原来的基础上分为两个分支版本:
-
DockerCE 即社区免费版。
-
DockerEE 即企业版,强调安全,但需付费使用。
本次介绍 Docker CE 的安装使用
//安装docker所需依赖包
[root@docker ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
//下载docker软件源
[root@docker ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
//安装docker-ce
[root@docker ~]# yum -y install containerd.io docker-ce docker-ce-cli
注:在生产环境一般使用固定版本号,并且在此版本上经过了充分的测试,推荐版本号安装,下面列出所有版本:版本号由高到低排序
[root@docker ~]# yum list docker-ce --showduplicates | sort -r

//安装指定版本的命令:
[root@docker ~]# yum install containerd.io docker-ce-18.09.6 docker-ce-cli-18.09.6
//启动docker并查看安装版本
[root@docker ~]# systemctl start docker
[root@docker ~]# systemctl enable docker
[root@docker ~]# docker -v
Docker version 18.09.6, build 481bc77156
//下载最小的镜像来验证安装是否正确
[root@docker ~]# docker run hello-world
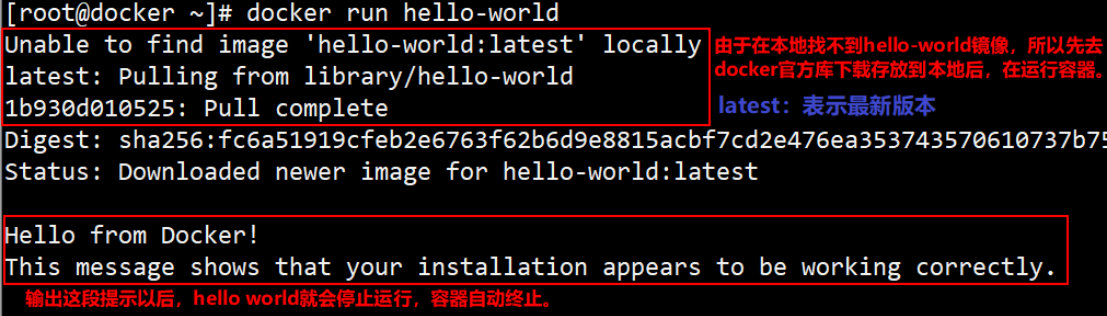
执行这条命令过程如下图:
//查看本地镜像
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest fce289e99eb9 13 months ago 1.84kB
更换Docker镜像源
//去阿里上拿加速器地址,注:要先登入阿里才能复制地址
阿里地址:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
//修改文件使用阿里加速地址
[root@docker ~]# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://p8hkkij9.mirror.aliyuncs.com"]
}
//重启docker
[root@docker ~]# systemctl daemon-reload
[root@docker ~]# systemctl restart docker
//体验飞一样的感觉
[root@docker ~]# docker pull nginx
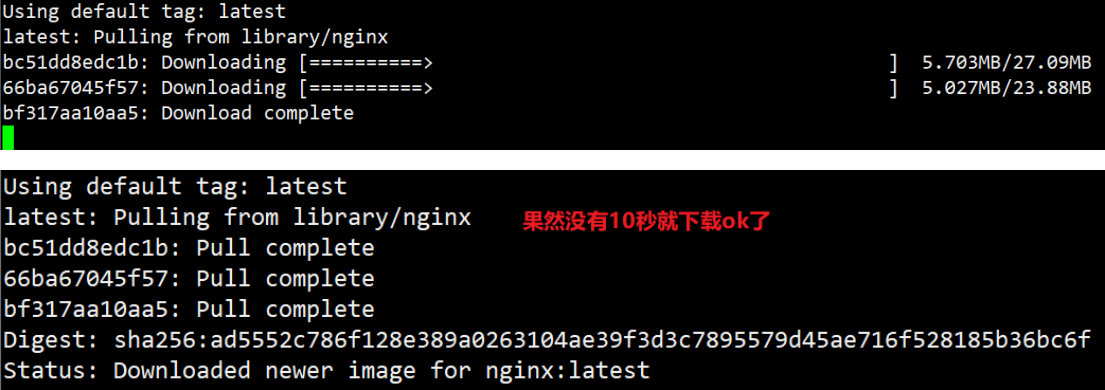
//查看nginx镜像是否下载到本地
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 207330bcb60e 2 weeks ago 127MB
hello-world latest fce289e99eb9 13 months ago 1.84kB
至此Docker安装完成
二、Docker架构
整体架构图如下:
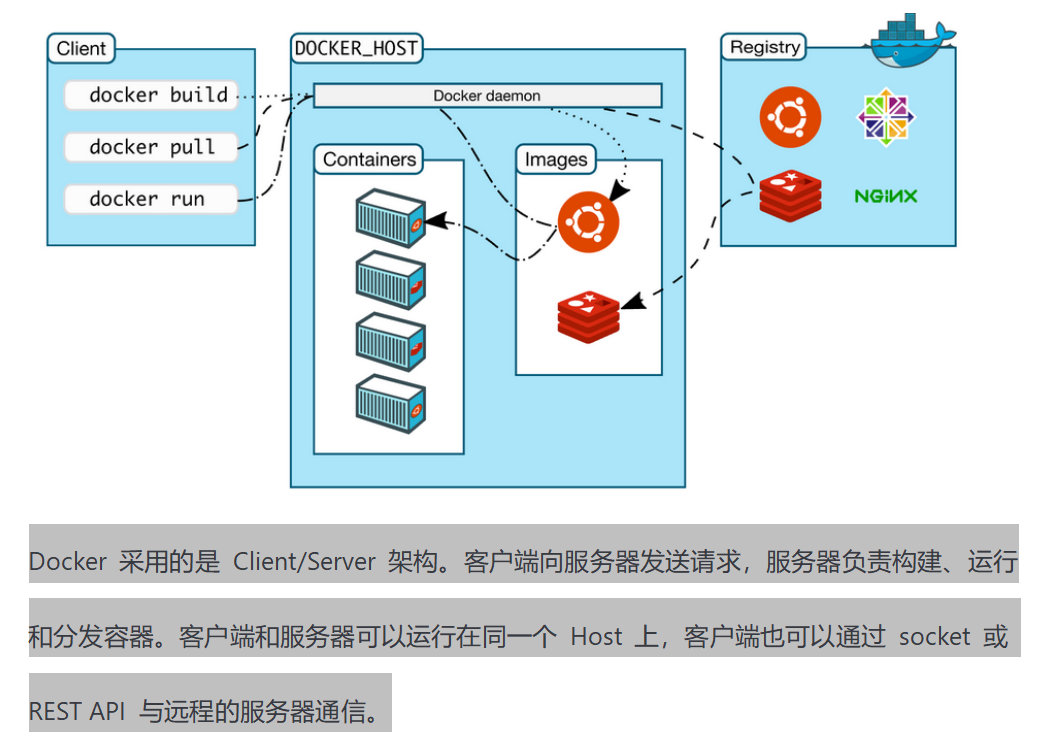
1. Docker 的核心组件
-
Docker 客户端 - Client
-
Docker 服务器 - Docker daemon
-
Docker 镜像 - Image
-
Registry 仓库 – Registry
-
Docker 容器 - Container
2. Docker客户端
最常用的 Docker 客户端就是 docker 命令。通过 docker命令 我们可以方便地在 Host 上构建和运行容器。
除了docker 命令行工具,用户也可以通过 REST API 与服务器通信。
具体命令参考:https://blog.csdn.net/top_explore/article/details/100057199
Docker 支持很多操作(子命令):
容器生命周期管理
容器操作
容器rootfs命令
镜像仓库
本地镜像管理
info|version
3. Docker服务端
Docker daemon 是服务器组件,以 Linux 后台服务的方式运行。
Docker daemon运行在Docker host上,负责创建、运行、监控容器,构建、存储镜像。
默认配置下,Docker daemon 只能响应来自本地 Host 的客户端请求。如果要允许远程客户端请求,需要在配置文件中打开 TCP 监听,步骤如下:
- 编辑配置文件/usr/lib/systemd/system/docker.service,在环境变量 ExecStart 后面添加 -H tcp://0.0.0.0,允许来自任意 IP 的客户端连接:

- 如果,还想要在本地连接,还要添加如下:

- 重启 Docker daemon:

- 从 IP 为192.168.1.2的客户端中在命令行里加上 -H 参数,即可与远程服务器通信。

4. Docker 镜像
可将 Docker 镜像看作为只读模板,通过它可以创建 Docker 容器。
镜像有多种生成方法
① 可以从无到有开始创建镜像(从0开始,白手起家)【开发】
② 也可以下载并使用别人创建好的现成的镜像(伸手党)【运维】
③ 还可以在现有镜像上创建新的镜像(用别人写好的镜像进行二次开发)【运维开发】
我们可以将镜像的内容和创建步骤描述在一个文本文件中,这个文件被称作 Dockerfile,还可以通过执行 docker build <docker-file> 命令构建出 Docker 镜像。
5. Docker 容器
Docker 容器就是 Docker 镜像的运行实例。
用户可以通过 CLI(docker)命令使 API 启动、停止、移动或删除容器。可以这么认为,对于应用软件,镜像是软件生命周期的构建和打包阶段,而容器则是启动和运行阶段。
存放 Docker 镜像的仓库,Registry 分 私有 和 公有两种。
Docker Hub 是默认的 Registry,由 Docker 公司维护,上面有数以万计的镜像,用户可以自由下载和使用。
出于对速度或安全的考虑,用户也可以创建自己的私有 Registry。后面会学习如何搭建私有 Registry。
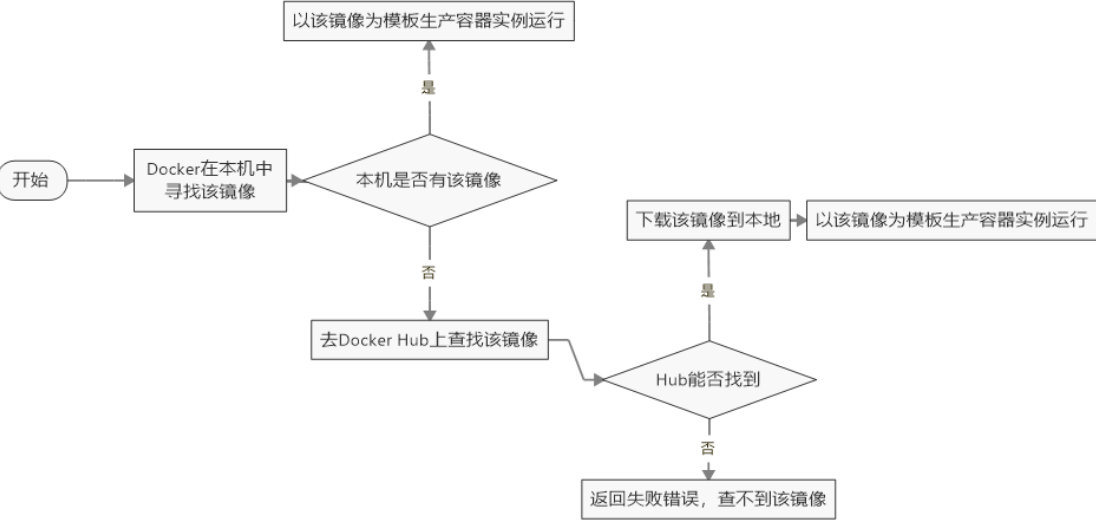
docker pull 命令可以从 Registry 下载镜像。
docker run 命令则是先下载镜像(如果本地没有),然后再启动容器。
6. Docker 组件如何协作?
还记得在上面运行的第一个最小的容器吗?现在通过它来体会一下 Docker 各个组件是如何协作的。
容器的启动过程
-d 后台运行容器,并返回容器ID
-p 指定要映射的端口,一个指定端口只能绑定一个容器

1、Docker 客户端执行 docker run 命令。
2、Docker daemon 发现本地没有 httpd 镜像。
3、daemon 从 Docker Hub 下载镜像。
4、下载完成,镜像 httpd 被保存到本地。
5、Docker daemon 启动容器。
现在 docker images 可以查看到 httpd 已经下载到本地。

docker ps 或者 docker container ls 显示正在运行的容器。


7. 镜像内部的浅度剖析
镜像是 Docker 容器的基石,容器是镜像的运行实例,有了镜像才能启动容器。
最小的镜像(了解即可)
hello-world 是 Docker 官方提供的一个镜像,通常用来验证 Docker 是否安装成功。
通过 docker pull 从 Docker Hub 下载它。

在用 docker images 命令查看镜像的信息;会发现hello-world连2KB都不到 !!!

通过 docker run 运行。 运行之后会自动退出

通过 docker ps -a 运行查看所有容器,包括未运行的

如果想删除下面未运行的容器则使用 docker rm 容器ID 例如:删除hello-world

如果想删除正在运行的容器使用单纯的 rm 是不行的;需要加上 -f 选项,但是不推荐,建议先停止容器,然后在删除容器。
例如:删除正在运行的httpd容器

其实我们更关心 hello-world 镜像包含哪些内容。
Dockerfile 是镜像的描述文件,定义了如何构建 Docker 镜像。
Dockerfile 的语法简洁且可读性强,后面我们会专门讨论如何编写 Dockerfile。
hello-world 镜像 的 Dockerfile 内容如下:
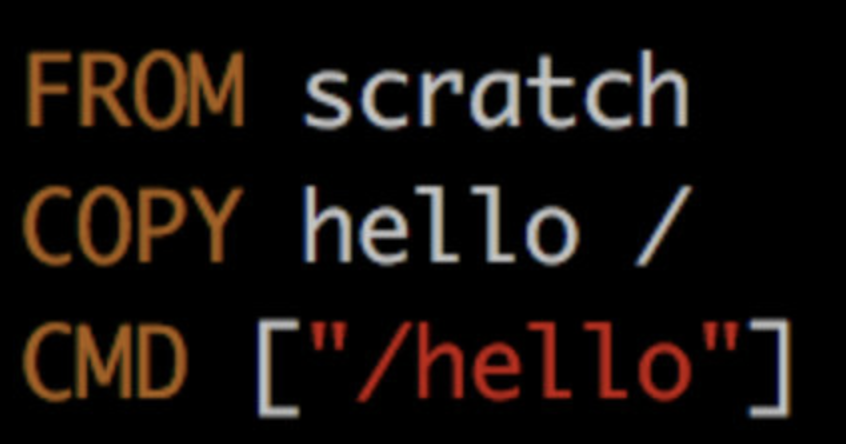
只有短短三条指令: https://www.cnblogs.com/lingfengblogs/p/11093246.html
FROM scratch
此镜像是从白手起家,从 0 开始构建。
COPY hello /
将文件“hello”复制到镜像的根目录。
CMD ["/hello"]
容器启动时,执行 /hello
# 镜像 hello-world 中就只有一个可执行文件 “hello”,其功能就是打印出 “Hello from Docker ......” 等信息。
# /hello 就是文件系统的全部内容,连最基本的 /bin,/usr, /lib, /dev 都没有。
# hello-world 虽然是一个完整的镜像,但它并没有什么实际用途。通常来说,我们希望镜像能提供一个基本的操作系统环境,用户可以根据需要安装和配置软件。这样的镜像我们称作 base 镜像。
base 镜像(重点知识)
base镜像有两层含义:
-
不依赖其他镜像,从scratch 构建。
-
其他镜像可以为之基础进行扩展。(常用)
所以,能称作基础base 镜像的通常都是各种 Linux 发行版的 Docker 镜像,比如Ubuntu, Debian, CentOS 等。
下面以 CentOS 为例考察 base 镜像包含哪些内容
下载镜像:docker pull centos
查看镜像:docker images

一个 CentOS 才 200MB ?平时安装一个 CentOS 至少都有几个 GB,怎么可能才 200MB ! 这是为什么呢 ?
在此之前我们先了解一下Linux系统的组成,Linux 操作系统由内核空间 和 用户空间组成。
-
Rootfs --->(用户空间)
-
Bootfs --->(内核空间)
Bootfs: 内核空间是kernel, Linux 刚启动时会加载bootfs文件系统,之后bootfs会被卸载掉。
Rootfs: 用户空间的文件系统是rootfs, 包含我们熟悉的/dev, /proc, /bin 等目录。
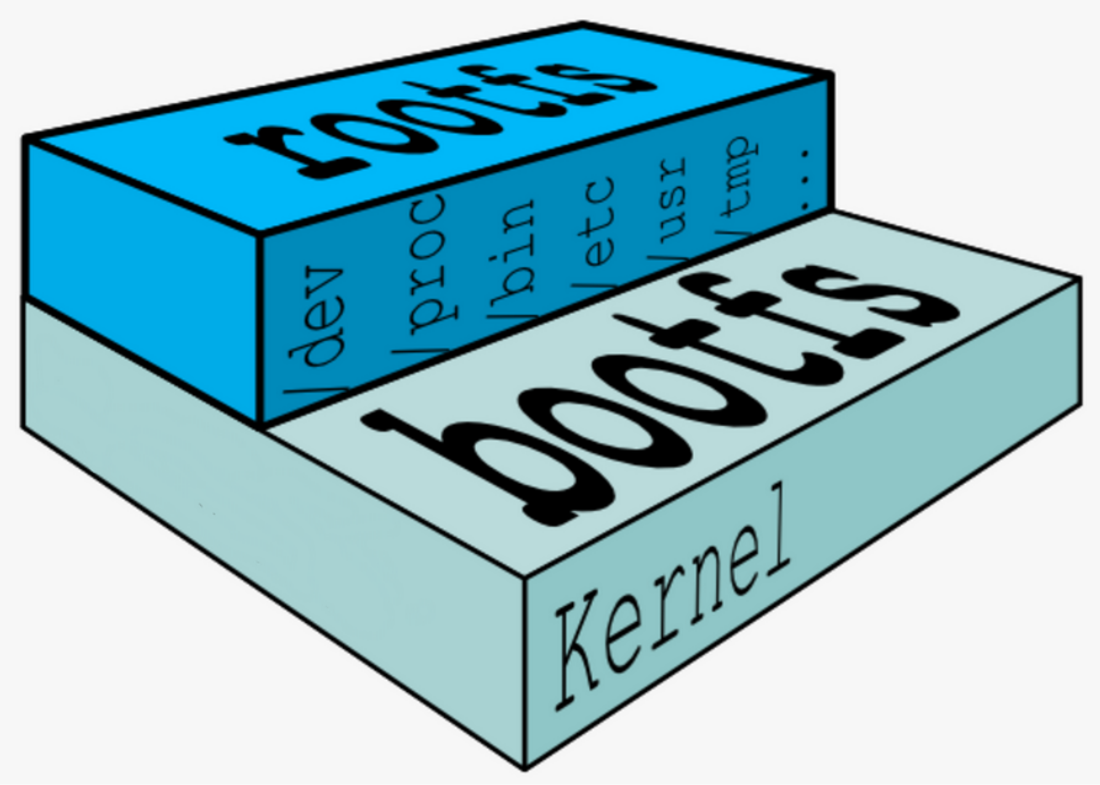
重点如下:
-
对于 base 镜像来说,底层直接用 Host真机 的 kernel,自己只需要提供 rootfs 就行了。
-
而对于一个精简的OS,rootfs可以很小,只需要有最基本的命令、工具和程序库就可以了。
-
平时安装的 CentOS 除了 rootfs 还会选装很多软件、服务、图形桌面等,需要好几个 GB 也就不足为奇了。
-
所有容器都是共享宿主真机也就是我们的docker服务器系统内核;也就是说所有的容器都是没有bootfs内核空间这一层的。
base 镜像提供的是最小安装的 Linux 发行版
下面是 CentOS 镜像的 Dockerfile 的内容:
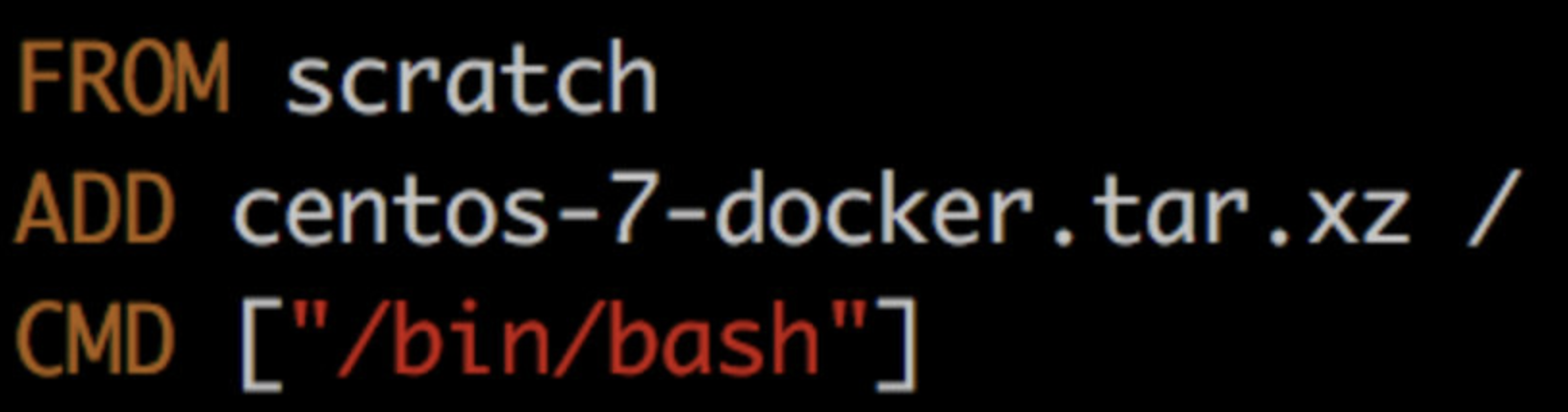
第二行 ADD 指令添加到镜像的 tar 包就是 CentOS 7 的 rootfs。
在制作镜像时,这个 tar 包会自动解压到镜像的 / 目录下,生成 /dev, /proc, /bin 等目录。
简述COPY 与 ADD的区别
-
COPY指令是直接将源文件拷贝到给予的目标位置;不会有任何别的操作。
-
ADD指令是直接将源文件拷贝到给予的目标位置;但如果是压缩包文件的话,它会自动解压。
-
注:可在 Docker Hub 的镜像描述页面中查看 Dockerfile 。
支持运行多种 Linux OS
-
不同 Linux 发行版的区别主要就是 rootfs。
-
比如 Ubuntu 14.04 使用 upstart 管理服务,apt 管理软件包;而 CentOS 7 使用 systemd 和 yum。这些都是用户空间上的区别,Linux kernel 差别不大。
-
所以 Docker 可以同时支持多种 Linux 镜像,模拟出多种操作系统环境。
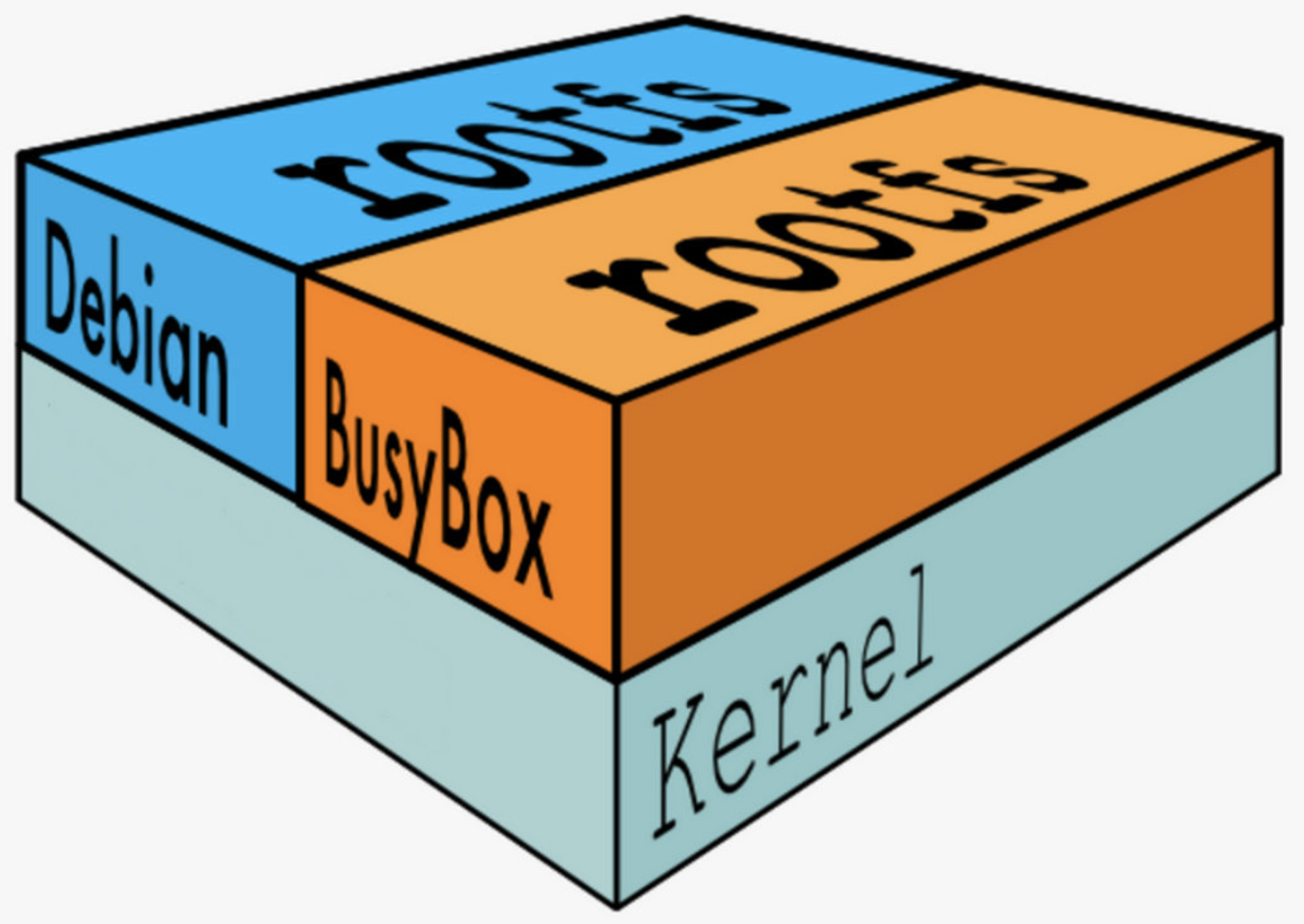
上图 Debian 和 BusyBox(一种嵌入式 Linux)上层提供各自的 rootfs,底层共用 Docker Host 的 kernel。
这里需要说明的是:base 镜像只是在用户空间与发行版一致,kernel 版本与发行版是不同的 !!!
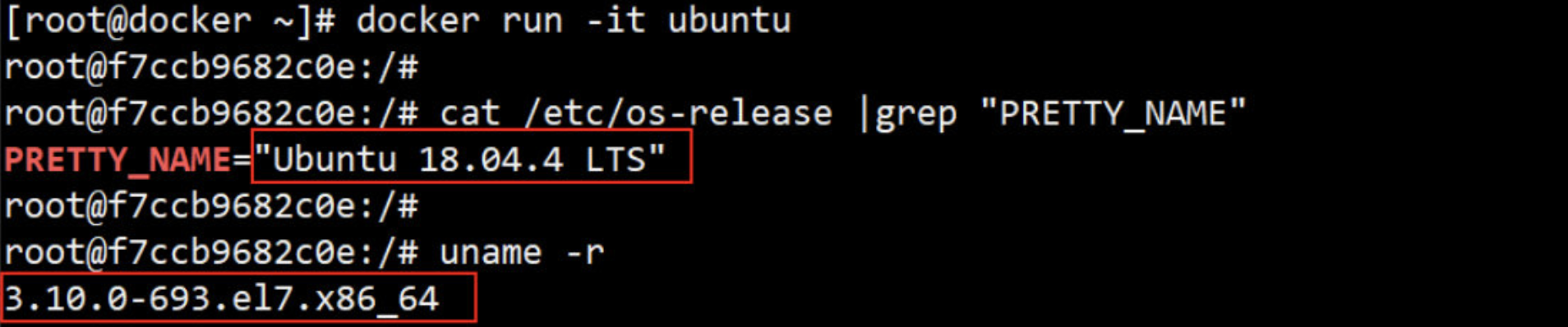
例如:使用Ubuntu.x.x 的 kernel镜像容器, 如果 Docker Host 是 CentOS 7.4, 那么在 Ubuntu 容器中使用的实际上是 Host 3.10.0-693的 kernel。
1、下载ubuntu镜像


2、查看 宿主Docker Host 系统、内核

3、启动并进入Ubuntu容器,并验证上面所述是否正确
-
Host kernel 为 3.10.0-693
-
启动并进入 Ubuntu 容器
-
验证容器是 Ubuntu
-
验证Ubuntu容器的 kernel 版本与 Host版本 一致
选项解释: -i 以交互模式运行容器,通常与 -t 同时使用; -t 为容器重新分配一个伪输入终端,通常与 -i 同时使用
小结:
容器只能使用 Host 的 kernel,并且不能修改。
所有容器都共用 host 的 kernel,在容器中没办法对 kernel 升级。如果容器对 kernel 版本有要求(比如应用只能在某个 kernel 版本下运行),则不建议用容器,这种场景虚拟机可能更合适。
三、Docker 镜像的分层结构
Docker 支持通过现有镜像来创建新的镜像
实际上,Docker Hub 中 99% 的镜像都是通过在 base 镜像中安装和配置需要的软件构建出来的。比如我们现在构建一个新的镜像,Dockerfile 如下:

① 新镜像不再是从 scratch 开始,而是直接在 Centos base 镜像上构建。
② 安装 emacs编辑器
③ 安装 apache服务。
④ 容器启动时运行 bash 给予容器运行终端。
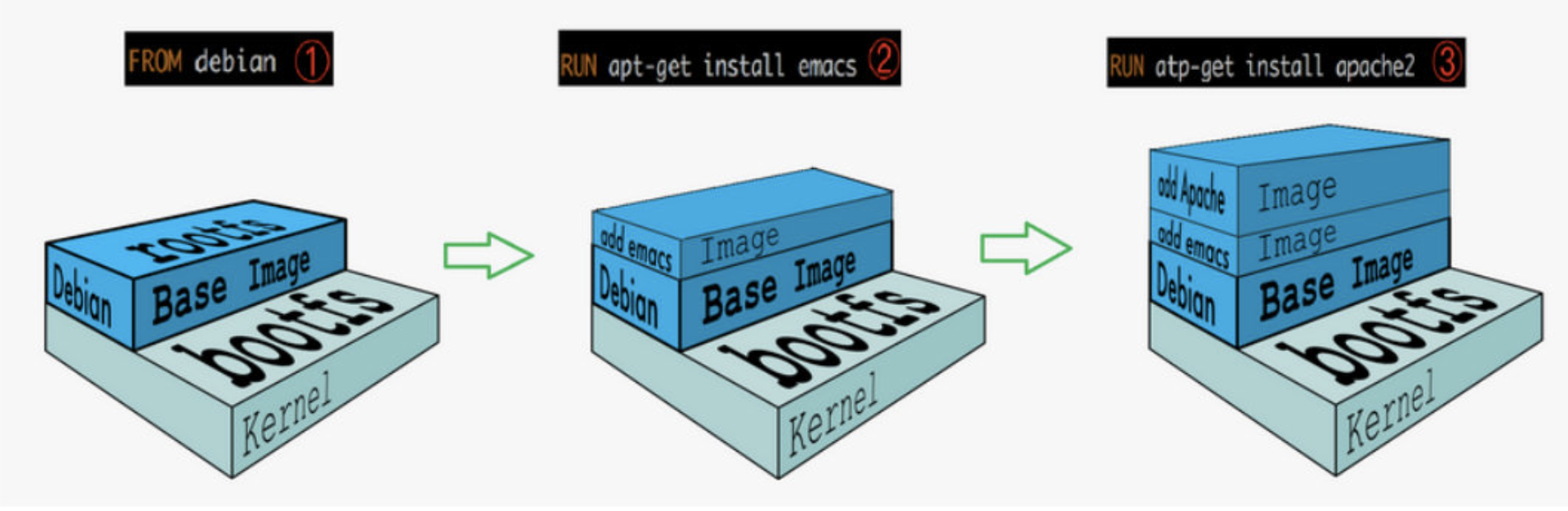
可以看到,新镜像是从 基础base 镜像一层一层 叠加生成的; 每安装一个软件,就在现有镜像的基础上增加一层。
为什么 Docker 镜像要采用这种分层结构呢 ?
最大的一个好处就是 - 共享资源。
比如:
有多个镜像都从相同的 base 镜像构建而来, 那么 Docker Host 只需在磁盘上保存一份 base 镜像; 同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了,而且镜像的每一层都可以被共享。后面会更深入地讨论这个特性。
那如果多个容器共享一份基础镜像, 当某个容器修改了基础镜像的内容, 比如 /etc 下的文件, 这时其他容器的 /etc 是否也会被修改?
答案是不会的!修改会被限制在单个容器内。这就是接下来要学习的容器 Copy-on-Write 特性。
1. 可写的容器层 (copy-on-Write)
当容器启动时,一个新的可写层被加载到镜像的顶部。
这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。
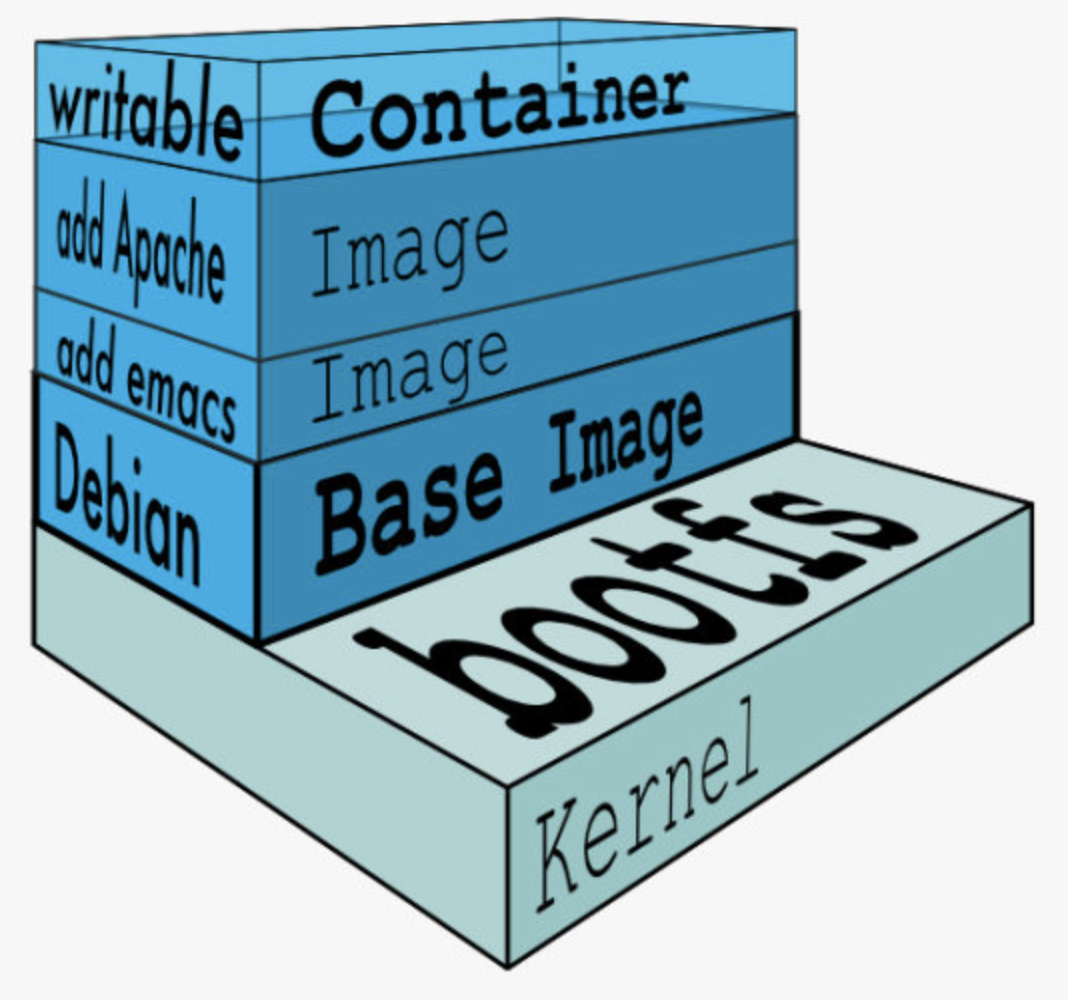
所有对容器的改动 - 无论添加、删除、还是修改文件都只会发生在容器层中。
只有容器层是可写的,容器层下面的所有镜像层都是只读的。
镜像 与 容器 的关系就有点类似于Python里面的 类 与 对象。
下面继续深入讨论容器层的细节(重点)

1、添加文件 在容器中创建文件时,新文件被添加到容器层中。
2、读取文件 在容器中读取某个文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,立即将其复制到容器层,然后打开并读入内存。
3、修改文件 在容器中修改已存在的文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,立即将其复制到容器层,然后修改之。
4、删除文件 在容器中删除文件时,Docker 也是从上往下依次在镜像层中查找此文件。找到后,会在容器层中记录下此删除操作。
只有当需要修改时才复制一份数据,这种特性被称作 Copy-on-Write。可见,容器层保存的是镜像变化的部分,不会对镜像本身进行任何修改。这样就解释了我们前面提出的问题:容器层记录对镜像的修改,所有镜像层都是只读的,不会被容器修改,所以镜像可以被多个容器共享共用。
四、Docker 的镜像构建详解
Docker镜像概述:
对于 Docker 用户来说, 最好的情况是不需要自己创建镜像。几乎所有常用的数据库、中间件、应用软件等 都有现成的 Docker 官方镜像或其他人和组织创建的镜像,我们只需要稍作配置就可以直接使用。
使用现成镜像的好处除了省去自己做镜像的工作量外, 更重要的是可以利用前人的经验。特别是使用那些官方镜像,因为 Docker 的工程师知道如何更好的在容器中运行软件。
但在某些情况下我们也不得不自己构建镜像,比如:
找不到现成的镜像,比如自己开发的应用程序。
需要在镜像中加入特定的功能,比如官方镜像几乎都不提供 ssh。
官方不提供ssh的主要原因:
不想让镜像变得笨重,构建镜像的原则(用啥装啥,其它多余的一个不装)
不能把容器当作KVM来用(最主要的原因)
容器在公司里最好的使用图景:对容器的所有操作,一律都在容器外部。(也就是宿主机上面)
Docker 提供了两种构建镜像的方法
① docker commit 命令
② Dockerfile 构建文件
1. docker commit(构建镜像)
docker commit 命令是创建新镜像最直观的方法,其过程包含三个步骤:
- 运行容器
- 修改容器
- 将修改完的容器保存为新的镜像
例如:在 Centos base 镜像中安装 net-tools包生成 ifconfig命令 并保存为新镜像。
1、第一步, 运行容器

2、安装 net-tools后,验证ifconfig命令是否存在


3、exit退出容器后,在新窗口中使用docker ps -a查看容器的随机名。

4、执行 docker commit 命令将容器保存为镜像。新镜像命名为 centos-ifconfig。

5、查看新镜像的属性。注:尽可能地不要安装跟自己服务非必须的软件
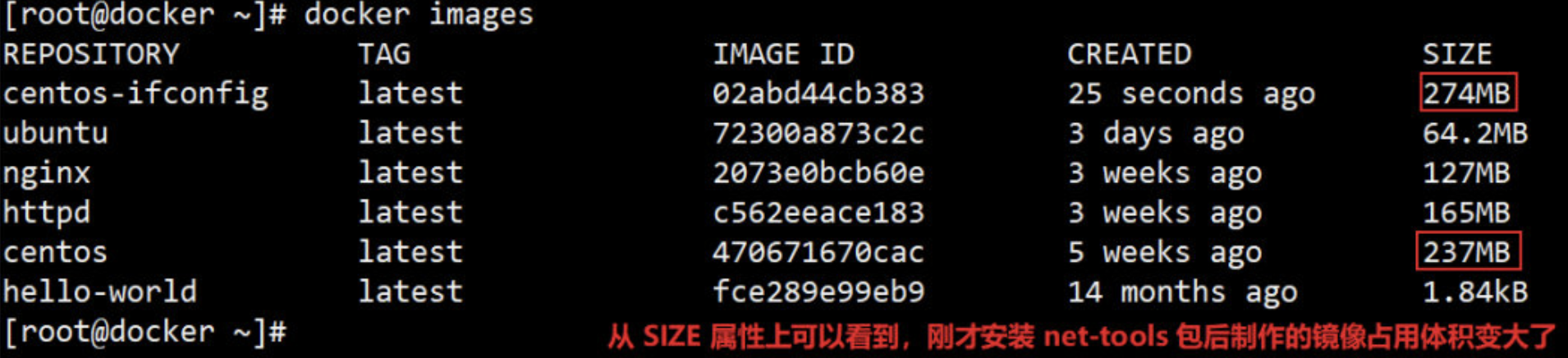
6、使用新镜像启动容器,验证 ifconfig命令 已经可以使用。
以上演示了如何用 docker commit 创建新镜像。然而,Docker 并不建议用户通过这种方式构建镜像。原因如下:
- 这是一种手工创建镜像的方式,容易出错,效率低且可重复性弱。比如要在 debian base 镜像中也加入 ifconfig,还得重复前面的所有步骤。
- 更重要的:使用者并不知道镜像是如何创建出来的,里面是否有恶意程序。也就是说无法对镜像进行审计,存在安全隐患。
既然 docker commit 不是推荐的方法,那干嘛还要花时间学习呢?
原因是:即便是用 Dockerfile(推荐方法)构建镜像,底层也是 docker commit 一层一层构建新镜像的。学习 docker commit 能够更加深入地理解构建过程和镜像的分层结构。
2. Dockerfile(构建镜像)
Dockerfile 就是一个文本文件,记录了镜像构建的所有步骤。
第一个 Dockerfile, 用 Dockerfile 创建 centos-vim,其内容则为:

下面运行 docker build 命令构建镜像并详细分析每个细节。
[root@docker ~]# docker build -f /root/Dockerfile -t centos-vim:v1 .
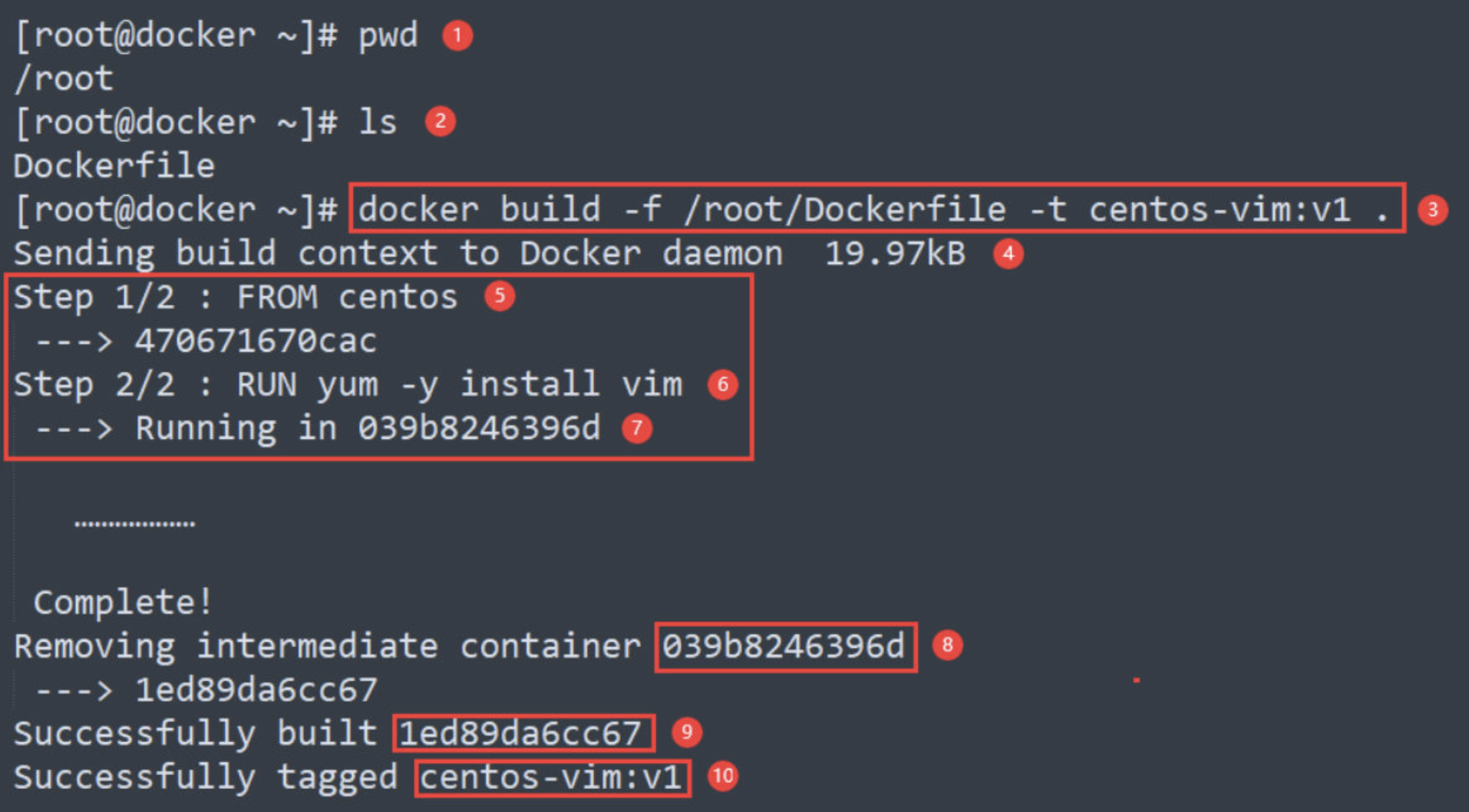
解释:
① 当前目录为 /root。
② Dockerfile 准备就绪。
③ 运行 docker build 命令,-t 将新镜像命名为 centos-vim,标签为 v1;-f 参数指定 Dockerfile 的位置;命令末尾的 . 指明 build context 为当前目录。Docker 默认会从 build context 中查找 Dockerfile 文件。
④ 从这步开始就是镜像真正的构建过程。 首先 Docker 将 build context 中的所有文件发送给 Docker daemon。
⑤ Step 1:执行 FROM,将 centos 作为 base 镜像。
centos 镜像 ID 为 470671670cac。
⑥ Step 2:执行 RUN,安装 vim,具体步骤为 ⑦、⑧、⑨。
⑦ 启动 ID 为 039b8246396d 的临时容器,在容器中通过 yum 安装 vim。
⑧ 删除临时容器ID 039b8246396d。
⑨ 然后将容器保存为镜像,其 ID 为 1ed89da6cc67。
⑩ 其镜像名centos-vim,标签名v1;镜像构建成功。
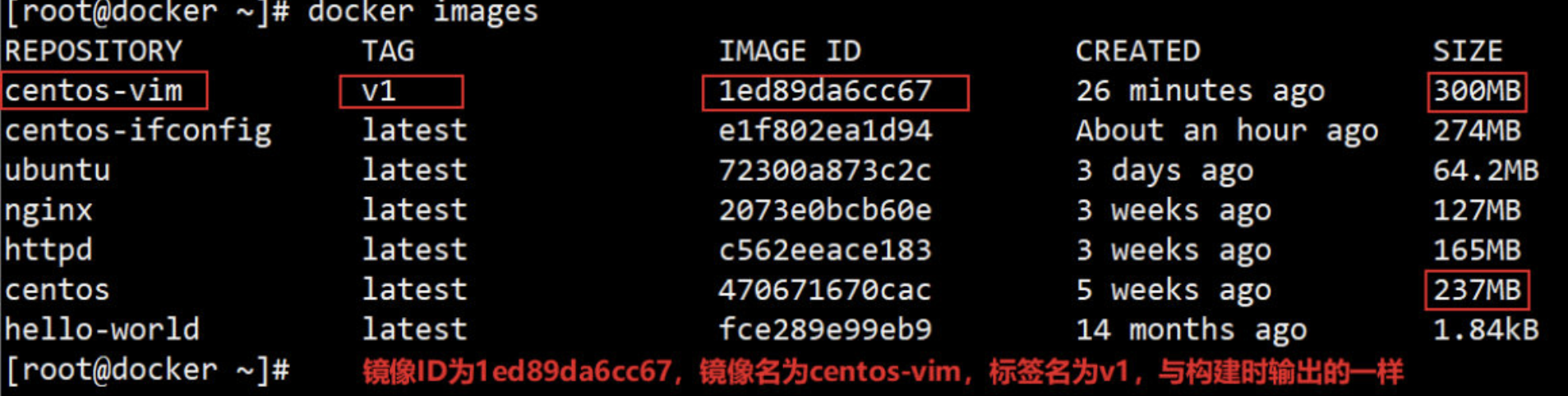
通过 docker images 查看镜像信息。
在上面的构建过程中, 我们要特别注意指令 RUN 的执行过程 ⑦、⑧、⑨。Docker 会在启动的临时容器中执行操作,并通过 commit 保存为新的镜像。
查看镜像分层结构
centos-vim 是通过在 base 镜像的顶部添加一个新的镜像层而得到的。
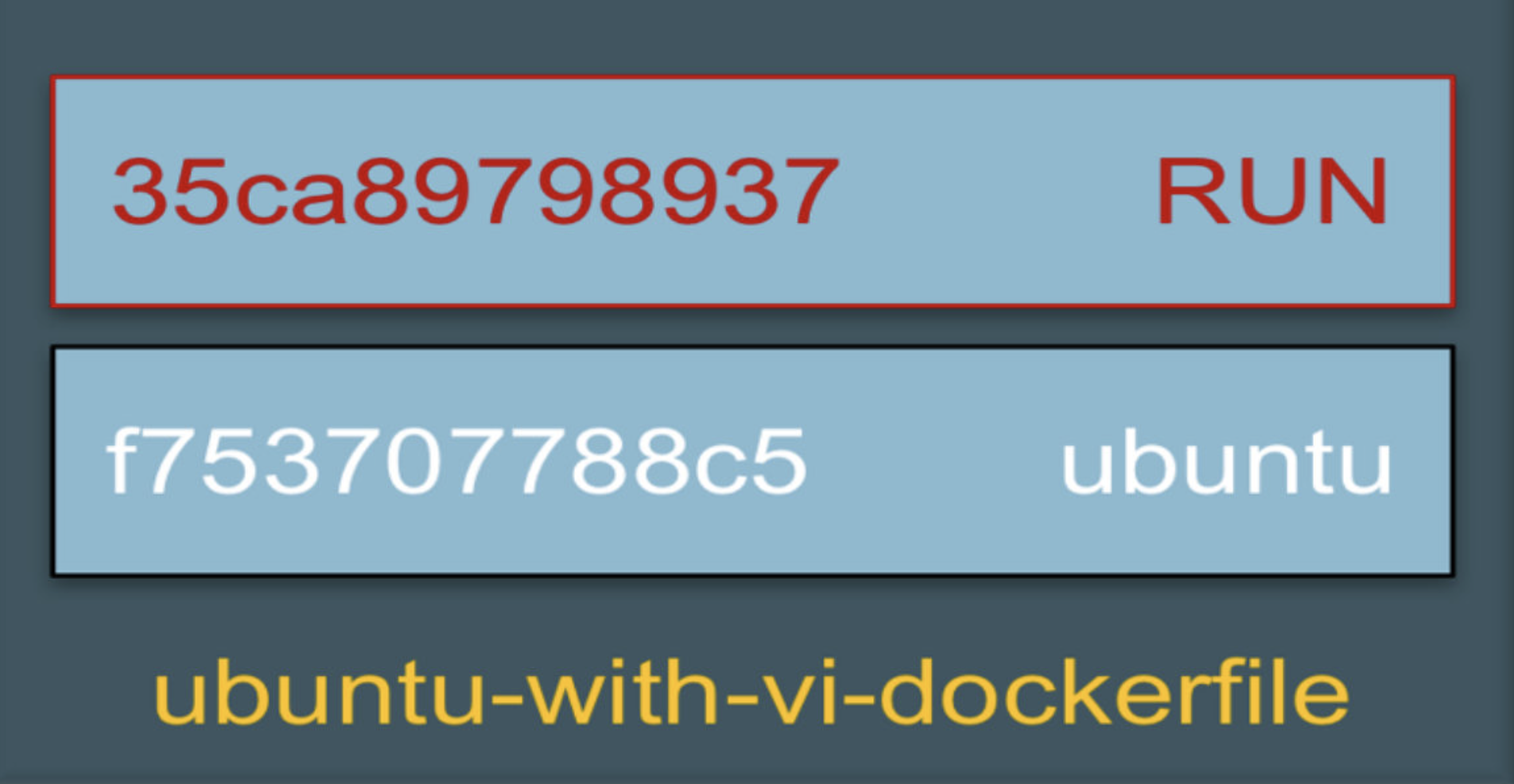
这个新镜像层的内容由 RUN yum -y install vim 生成。这一点我们可以通过 docker history 命令验证。

docker history 会显示镜像的构建历史,也就是 Dockerfile 的执行过程。
centos-vim与centos镜像相比,确实只是多了顶部的一层 1ed89da6cc67,由 yum命令创建,大小为 62.9MB。 docker history 也向我们展示了镜像的分层结构,每一层由上至下排列。
注:表示无法获取 IMAGE ID,通常从 Docker Hub 下载的镜像会有这个问题。
3. Docker 镜像的缓存特性
Docker 会缓存已有镜像的镜像层,构建新镜像时,如果某镜像层已经存在,就直接使用,无需重新创建。
举例说明:
在上面的 Dockerfile 中添加一点新内容,往镜像中复制一个文件:

[root@docker ~]# echo 'lemon is a very good!!!' > testfile
[root@docker ~]# docker build -f /root/Dockerfile -t centos-vim:v2 .
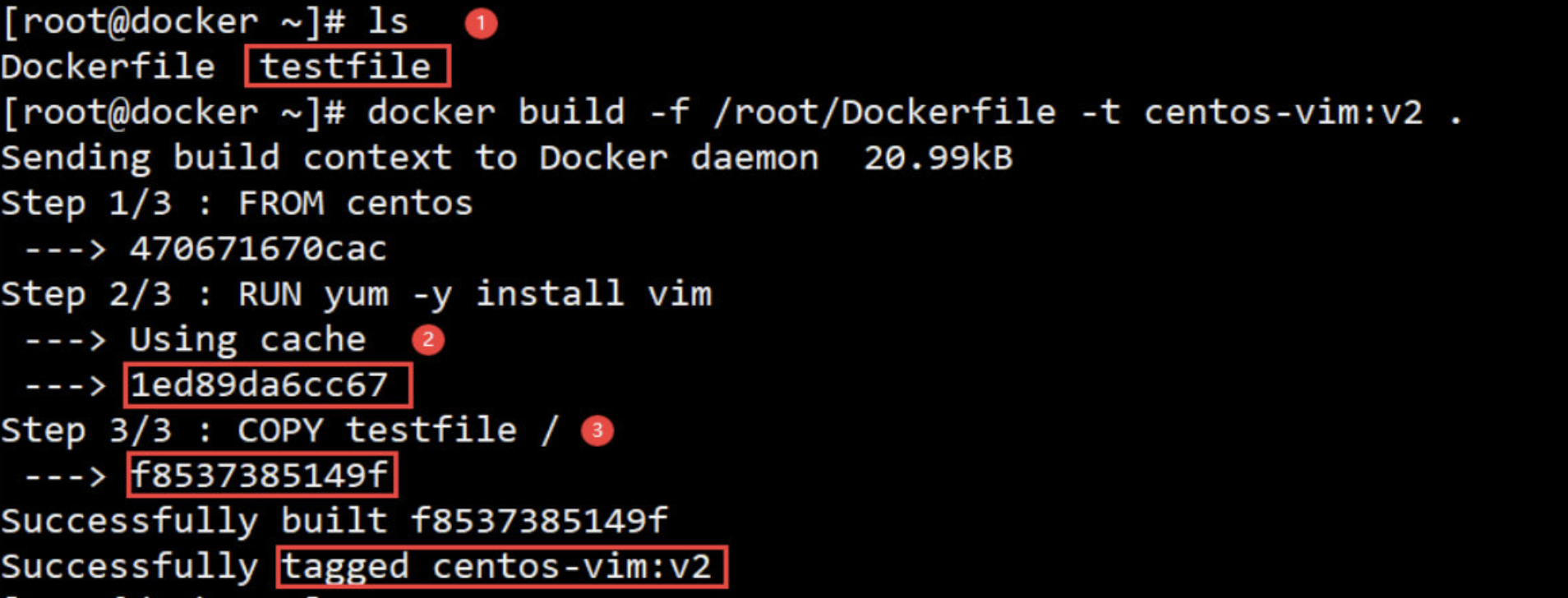
[root@docker ~]# docker images
[root@docker ~]# docker run -it centos-vim:v2 cat testfile
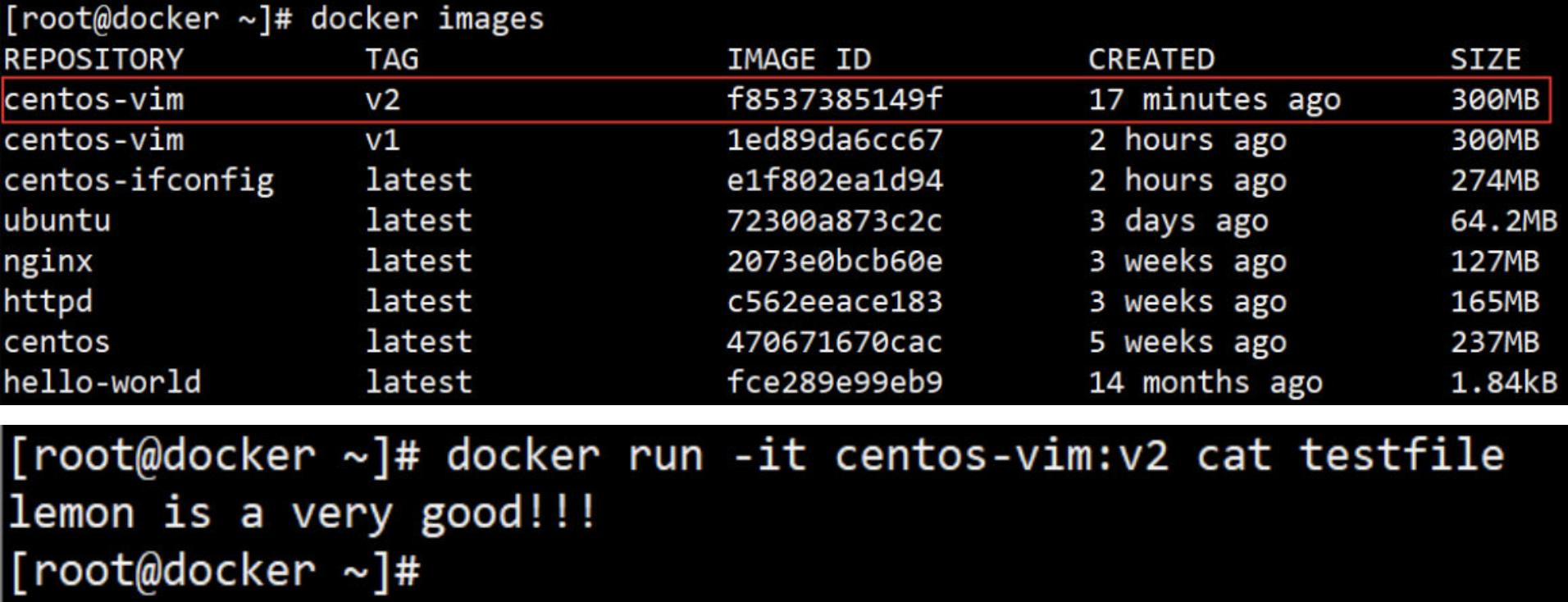

① 确保 testfile文件 已存在。
② 之前已经运行过相同的 RUN 指令,这次直接使用缓存中的镜像层1ed89da6cc67(重点)
③ 执行 COPY 指令。
其过程就是启动临时容器,复制 testfile,提交新的镜像层f8537385149f。
在 centos-vim:v1 镜像上直接添加一层就得到了新的镜像 centos-vim:v2

如果希望在构建镜像时不使用缓存,可以在 docker build 命令中加上 --no-cache 参数。
Dockerfile 中每一个指令都会创建一个镜像层,上层是依赖于下层的。无论什么时候,只要某一层发生变化,其上面所有层的缓存都会失效。
就是说,如果我们改变 Dockerfile 指令的执行顺序,或者修改、添加指令,都会使缓存失效。
举例说明,比如交换前面 RUN 和 COPY 的顺序:

虽然在逻辑上这种改动对镜像的内容没有影响,但由于分层的结构特性,Docker 必须重建受影响的镜像层。(v2 和 v3 镜像的内容不会因为RUN顺序从而改变)
[root@docker ~]# docker build -f /root/Dockerfile -t centos-vim:v3 .
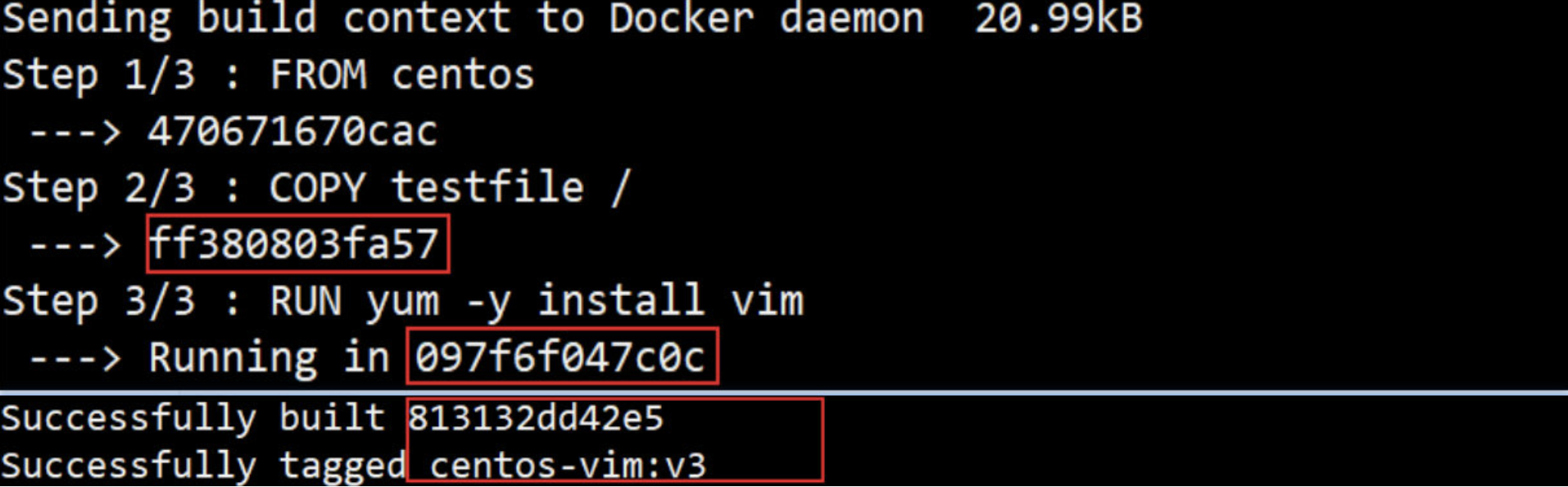


从上面的输出可以看到生成了新的镜像层ff380803fa57,缓存已经失效。
除了构建时使用缓存,Docker 下载镜像时也会使用。例如我们在下载一次 httpd 镜像
4. Dockerfile 排错方法
包括 Dockerfile 在内的任何脚本和程序都会出错。有错并不可怕,但必须有办法排查!!!
直接上案例,Dockerfile 内容如下:

[root@docker ~]# docker build -f /root/Dockerfile -t image-debug .
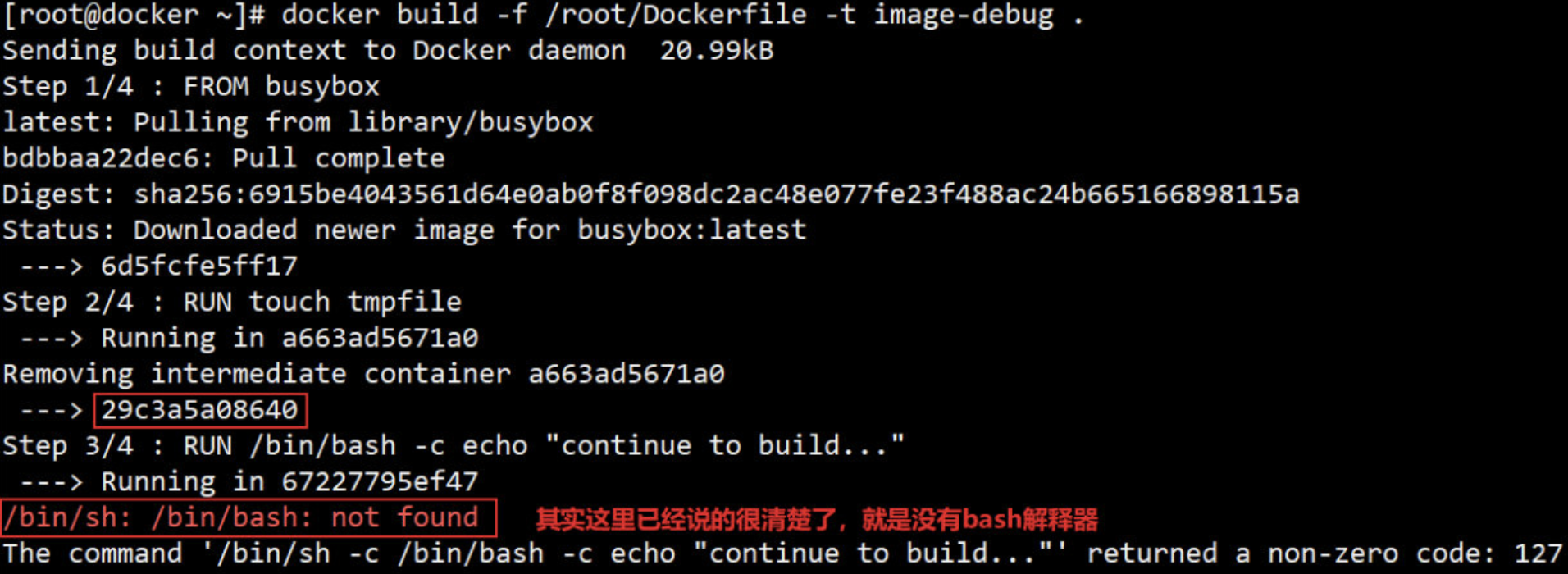
# 查看一下构建时出现问题的镜像[root@docker ~]# docker images
Dockerfile 在执行第三步 RUN 指令时失败。我们可以利用第二步创建的镜像 29c3a5a08640 进行调试,方式是通过 docker run -it 启动镜像的一个容器。

手工执行 RUN 指令很容易定位失败的,报错的原因是 busybox 镜像中没有 /bin/bash解释器。虽然这是个极其简单的例子,但它很好地展示了调试 Dockerfile 的方法。
五、Dockerfile 指令使用详解
1. 认识 DockerFile
Dockerfile是一个文本文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建,最终通过读取Dockerfile中的指令自动生成映像。
docker build命令用于从 Dockerfile 构建映像。可以在docker build命令中使用-f标志指向文件系统中任何位置的 Dockerfile。
2. Dockerfile常用指令
- FROM
- MAINTAINER
- COPY
- ADD
- WORKDIR
- VOLUME
- EXPOSE
- ENV
- RUN
- CMD
- ENTRYPOINT
- HEALTHCHECK
- ONBUILD
- USER
- ARG
- SHELL
- STOPSIGNAL
- …………
3. 如何编写DockerFile
3.1 Dockerfile 编写的基本结构
Dockerfile 一般分为四部分:
基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令;’#’ 为注释
1、要指定基于哪一个镜像来构建新的镜像,所以dockerfile的第一层必须是FROM
2、维护者信息,此镜像是由谁构建的,不是非必须,用到的指令是MAINTAINER
3、镜像操作指令,在基础镜像之上,你要运行哪些命令,用到的指令:RUN等……
4、容器启动时执行的命令,用到的指令:CMD、ENTRY POINT
3.2 一台主机可以有多个Dockerfile
想使用多个Dockerfile创建镜像, 可以在不同目录编写Dockerfile,然后在Dockerfile 所在的目录下构建新的镜像
注意:Dockerfile 中所包含的需要的内容;如COPY的文件、目录等,都需要在Dockerfile 同级目录下存在;
3.3 使用 build 基于Dockerfile制作镜像的命令
① 格式:
- docker build [OPTIONS] PATH | URL | -
② 选项:
- -t:打标签
- -f:指定Dockerfile文件路径
- -c,- cpu-shares int :CPU份额(相对权重)
- -m,- memory bytes:内存限制
- --build-arg:设置构建时变量,就是构建的时候修改ARG指令的参数
注意:在使用 docker build 时在最后一定要加上 ‘ . ’
4. DockerFile使用案例
4.1 FROM 指令
FROM指令介绍
- 指令格式:
FROM <repository>[:<tag>] 或 FROM <repository>@<digest>
注:
- <repository> 指定作为base image的名称
- <tag> base image的标签,省略时默认latest
- <digest> 是镜像的哈希码;使用哈希码会更安全一点
-
FROM 指令必须是 Dockerfile 中 非注释行的第一个指令,即一个 Dockerfile 从FROM语句;
-
FROM 指令用于 为镜像文件构建过程指定基础镜像,后续的指令运行于此基础镜像所提供的运行环境;
-
FROM可以在一个 Dockerfile 中出现多次,如果有需求在一个 Dockerfile 中创建多个镜像。
-
如果FROM语句没有指定镜像标签,则默认使用latest标签。
-
实践中,基准镜像可以是任何可用镜像文件, 默认情况下, docker build会在docker主机上查找指定的镜像文件, 在其不存在时, 则会自动从Docker的公共库 pull 镜像下来。如果找不到指定的镜像文件,docker build 会返回一个错误信息;
FROM使用示例
# Description: test image
FROM busybox:latest
4.2 MAINTAINER 指令
MAINTAINER 指令介绍
- 指令格式:
MAINTAINER "<authtors detail>"
-
用于让dockerfile制作者提供本人的详细信息
-
dockerfile 并不限制 MAINTAINER 指令可在出现的位置,但推荐将其放置于FROM指令之后
MAINTAINER 使用示例
FROM busybox:latest
MAINTAINER "lemon <lemon_row@163.com>"
4.3 COPY 指令
COPY 指令介绍
- 指令格式:
COPY <src>... <dest> 或者 COPY ["<src>",... "<dest>"]
注:
- 在路径中有空白字符时,通常使用第二种格式
- <src>:要复制的源文件或目录,支持使用通配符
- <dest>:目标路径,即正在创建的image的文件系统路径;建议<dest>使用绝对路径,否则,COPY指定以WORKDIR为起始路径
- 文件复制准则
- <src>的文件或目录必须是build上下文中的路径,不能是父目录中的文件,意思就是<src>的文件或目录必须是在dockerfile文件所在的目录中;
- 如果<src>是目录,则其内部文件或子目录会被递归复制,但<src>目录自身不会被复制;如果想将<src>目录自身及子目录子文件都复制过去的话,需要在<dest>结尾上也写上<src>的目录名。
- 如果指定了多个<src>,或在<src>中使用了通配符,则<dest>必须是一个目录,且必须以 / 结尾;
- 如果<dest>目录不存在,他将会被自动创建,这包括父目录路径。
COPY 使用示例
# 案例一 : COPY 文件
(1)编写Dockerfile文件;要确保dockerfile 同级路径下有这两个.html文件
# Description: test image
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
COPY ["index.html", "tools", "/data/web/html/"]
(2)在dockerfile同级目录下准备好.html文件
[root@docker lemon]# mkdir -p tools/swarm
[root@docker lemon]# echo '<h1>Busybox httpd server-1</h1>' > index.html
[root@docker lemon]# echo '<h1>Busybox httpd server-2</h1>' > tools/test.html
(3)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.1 .
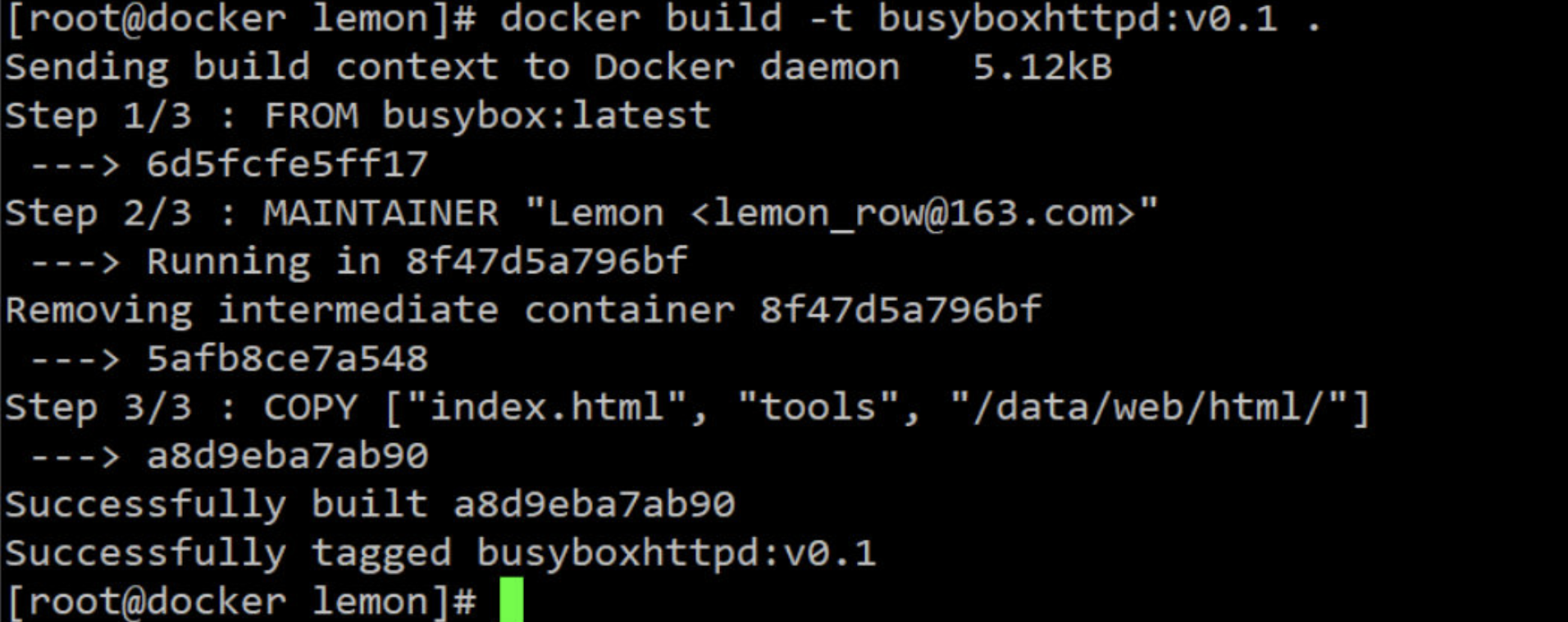

(4)基于此新建镜像运行容器,进行验证
[root@docker lemon]# docker run --name web1 --rm busyboxhttpd:v0.1 ls /data/web/html/

# 案例二 : COPY 目录
(1)编写dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
COPY index.html /data/web/html/
COPY yum.repos.d /etc/yum.repos.d/ #需要把复制目录名字也写在容器中要复制的路径下!
(2)在dockerfile同级目录下准备好yum.repos.d 目录

(3)使用build 制作镜像
[root@along img1]# docker build -t busyboxhttpd:v0.2 .
(4)基于此新建镜像运行容器,进行验证
[root@docker lemon]# docker run --rm busyboxhttpd:v0.2 ls /etc/yum.repos.d/
yum.repo
4.4 ADD 指令
ADD 指令介绍
- 指令格式:
ADD <src> .. <dest> 或 ADD ["<src>".. "<dest>"]
-
ADD 指令类似于COPY指令,但ADD支持<src>使用TAR文件和URL路径
-
操作准则
- 同COPY指令
- 如果<src>为URL且<dest>不以 / 结尾,则<src>指定的文件将被下载并直接被创建为<dest>; 如果<dest>以 / 结尾,则文件名URL指定的文件将被直接下载并保存为<dest>/ <filename>
- 如果<src>是一个本地系统上的压缩格式的tar文件,它将被展开为一个目录,其行为类似于"tar-x"命令;然而,通过URL获取到的tar文件将不会自动展开;
- 如果<src>有多个,或其间接或直接使用了通配符,则<dest>必须是一个以/结尾的目录路径 ;如果<dest>不以/结尾,则其被视作一个普通文件,<src>的内容将被直接写入到<dest>;
ADD 使用示例
案例一 : COPY 网上路径(URL)的tar包
(1)编写dockerfile文件
# 注:ADD 的<src> 是网上的nginx下载路径;docker服务器要有网!COPY是当前本地路径
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
COPY httpd-2.4.18.tar.gz /usr/local/src/
ADD http://nginx.org/download/nginx-0.1.12.tar.gz /usr/local/src/
(2)确保dockerfile其目录下有httpd包
httpd-2.4.18.tar.gz
(3)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.3 .
(4)基于此新建镜像运行容器,验证两种复制指令的不同之处
[root@docker lemon]# docker run --rm busyboxhttpd:v0.3 ls /usr/local/src

[root@docker lemon]# echo 'net.ipv4.ip_forward = 1'>>/usr/lib/sysctl.d/00-system.conf
[root@docker lemon]# systemctl restart network
[root@docker lemon]# docker run --rm busyboxhttpd:v0.3 ls /usr/local/src
httpd-2.4.18.tar.gz #可以看到上面的警告已经没有了
nginx-0.1.12.tar.gz
# 案例二 : COPY 本地的路径的tar包
# 这次我们在“ADD”指令中使用本地的压缩包,验证我上面所说的是否正确
(1)修改dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
COPY httpd-2.4.18.tar.gz /usr/local/src/
ADD nginx-0.1.12.tar.gz /usr/local/src/ # 将<src>改成本地
(2)在dockerfile同级目录下准备好压缩包
[root@docker lemon]# ls httpd-2.4.18.tar.gz nginx-0.1.12.tar.gz
httpd-2.4.18.tar.gz nginx-0.1.12.tar.gz
(3)使用build 制作镜像,然后再基于此镜像启动容器来验证两种复制指令的不同之处
#在构建之前先将之前构建v0.3镜像删除
[root@docker lemon]# docker rmi 61f741f13035
#从新构建一次v0.3镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.3 .
#查看镜像
[root@tx_lemon ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
busyboxhttpd v0.3 f5927a4727cb 19 seconds ago 9.59MB
[root@docker lemon]# docker run --rm busyboxhttpd:v0.3 ls -lh /usr/local/src

看到此图,证明我上面在案例一中所说是正确的,“ADD”指令只针对本地压缩包才会先解压再拷贝到容器;但是针对网路URL的压缩包不生效!
4.5 WORKDIR 指令
WORKDIR 指令介绍
- 指令格式:
WORKDIR <dirpath>
- 用于为Dockerfile中所有的RUN、CMD、ENTRYPOINT、COPY和ADD指定设定工作目录(就相当于linux系里的“ cd ”命令)
- 在Dockerfile文件中,WORKDIR指令可出现多次,其路径可以为相对路径也可以为绝对路径;另外,WORKDIR也可调用由ENV指定定义的变量。
WORKDIR 使用示例
(1)修改dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
WORKDIR /usr/local/
ADD nginx-0.1.12.tar.gz ./src/
(2)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.4 .
(3)运行容器
[root@docker lemon]# docker run -it --rm busyboxhttpd:v0.4 sh

4.6 VOLUME 指令
VOLUME 指令介绍
- 指令格式:
VOLUME <mountpoint> 或 VOLUME ["<mountpoint>"]
注:如果挂载点目录路径下此前文件存在,docker run命令会在卷挂载完成后将此前的所有文件复制到新挂载的卷中
- 用于在image中创建一个挂载点目录,以挂载Docker host.上的卷或其它容器上的卷
- 意思就是将docker宿主机目录挂载到容器的目录;宿主机目录有什么,容器目录就有什么。
- 抽象比喻:宿主目录 块设备 容器目录 挂载点
VOLUME 使用示例
(1)编写dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
VOLUME /data/mysql
WORKDIR /data/mysql
(2)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.5 .
(3)基于此新建镜像运行容器,进行验证
[root@docker lemon]# docker run --name web1 --rm -it busyboxhttpd:v0.5 /bin/sh

(4)打开一个终端,用下面命令查看宿主机挂载的目录;inspect:查看容器详细信息
[root@docker ~]# docker inspect -f {{.Mounts}} web1
[{volume 58e3db45096afd5008d4d8c19aae35ea7504a867c3429e00f7f667bce816e741 /var/lib/docker/volumes/58e3db45096afd5008d4d8c19aae35ea7504a867c3429e00f7f667bce816e741/_data /data/mysql local true }]
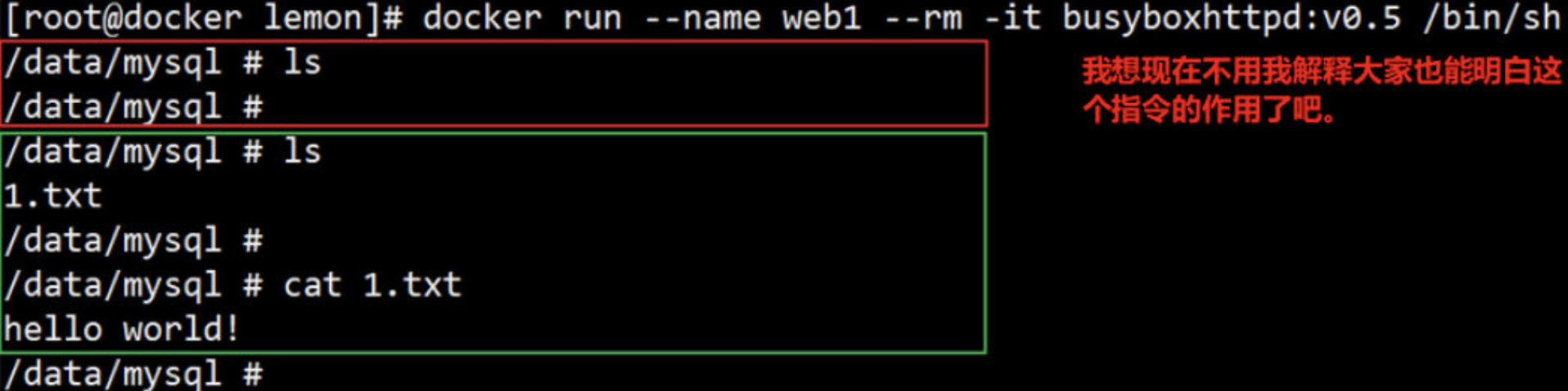
(5)进入上面的volume目录,然后创建一个1.txt文件

(6)再回到容器中,ls查看一次 /data/mysql/ 目录
4.7 EXPOSE 指令
EXPOSE 指令介绍
- 指令格式:
EXPOSE <port>[/ <protocol>] [<port>[/ <protocol>] ....
注:
- <protocol>用于指定传输层协议,可为tcp或udp二者之一,默认为TCP协议
- EXPOSE指令可一次指定多个端口,例如:EXPOSE 11211/udp 11211/tcp
- 用于为容器打开指定要监听的端口以实现与外部通信
EXPOSE 使用示例
(1)编写dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
COPY test.html /data/web/html/
EXPOSE 80/tcp
(2)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.6 .
(3)基于此新建镜像运行容器,进行验证
[root@docker lemon]# docker run --name web1 -P --rm -itd busyboxhttpd:v0.6 /bin/httpd -f -h /data/web/html
# 启动httpd服务,在启动时指定网页存放路径;
# -P将容器内部开放的网络端口随机映射到宿主机的一个端口上;
# -p指定要映射的端口,一个指定端口上只可以绑定一个容器;
(4)另打开一个终端,验证httpd 服务的80端口
[root@docker ~]# docker inspect -f {{.NetworkSettings.IPAddress}} web1
172.17.0.2 # 查看容器的ip地址
[root@docker ~]# docker port web1 # 只查看web1容器的PORTS信息
80/tcp -> 0.0.0.0:32768
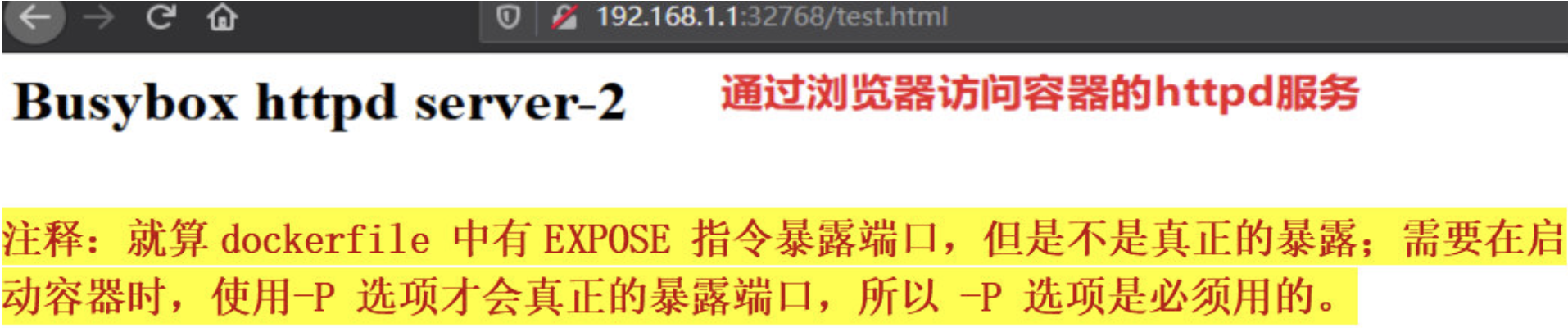
[root@docker ~]# curl 172.17.0.2:80/test.html # 通过容器的端口访问httpd 服务
<h1>Busybox httpd server-2</h1>
[root@docker ~]# curl 127.0.0.1:32768/test.html # 通过宿主机的端口访问httpd 服务
<h1>Busybox httpd server-2</h1>
4.8 ENV 指令
ENV 指令介绍
- 指令格式:
ENV <key> <value> 或 ENV <key>=<value> . .
注:
- 第一种格式中,<key>之后的所有内容均会被视作其<value>的组成部分, 因此,一次只能设置一个变量;
- 第二种格式可用一次设置多个变量,每个变量为一个”<key>=<value>"的键值对,如果<value>中包含空格,可以以反斜线(\)进行转义,也可通过对<value>加引号进行标识;另外,反斜线也可用于续行;
- 定义多个变量时,建议使用第二种方式,以便在同一层中完成所有功能
- 用于为镜像定义所需的环境变量,并可被Dockerfile文件中位于其后的其它指令(ENV、ADD、COPY等)所调用
- 调用格式为$variable_ name 或 $
ENV 使用示例
(1)编写dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
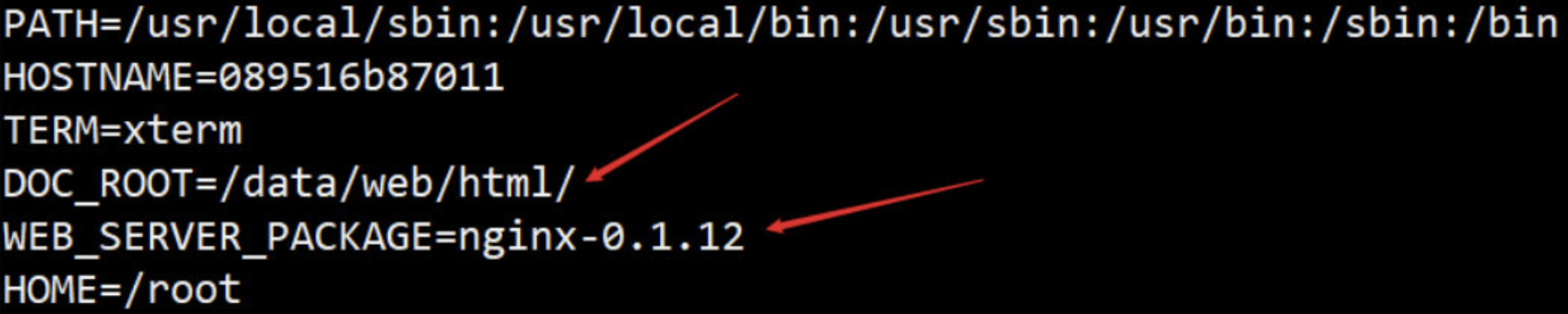
ENV DOC_ROOT=/data/web/html/ \
WEB_SERVER_PACKAGE="nginx-0.1.12"
COPY index.html ${DOC_ROOT}
WORKDIR /usr/local/
ADD ${WEB_SERVER_PACKAGE}.tar.gz ./src/
EXPOSE 8080:80/tcp
(2)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.7 .
(3)基于此新建镜像运行容器,进行验证
[root@docker lemon]# docker run --rm -it busyboxhttpd:v0.7 ls /usr/local/src /data/web/html

--- 也可以使用printenv 查看变量验证
[root@docker lemon]# docker run --name web1 --rm -it busyboxhttpd:v0.7 printenv
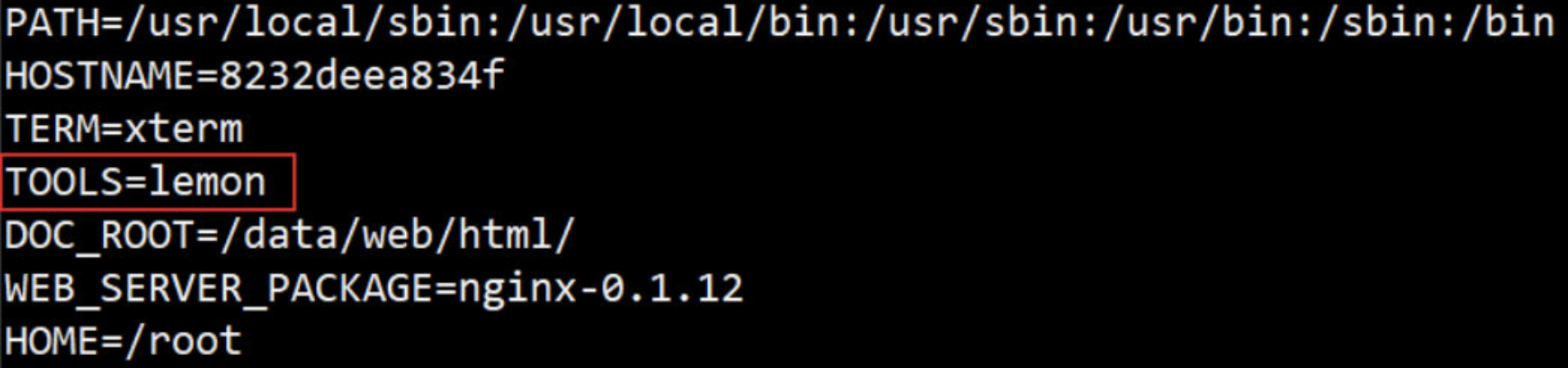
--- 在启动容器时,使用docker run -e 添加或修改变量
[root@docker lemon]# docker run --name web1 -e TOOLS="lemon" --rm -it busyboxhttpd:v0.7 printenv
4.9 RUN 指令
RUN 指令介绍
- 指令格式:
RUN <command> 或 RUN ["<executable>", "<param1>", "<param2>"]
注:
- 第一种格式中,<command>通常是一个shell命令, 且以“/bin/sh -c”来运行它,这意味着此进程在容器中的PID不为1,不能接收Unix信号,因此,当使用docker stop <container>命令停止容器时,此进程接收不到SIGTERM信号;
- 第二种语法格式中的参数是一个JSON格式的数组,其中<executable>为要运行的命令,后面的 <paramN>为传递给命令的选项或参数;然而,此种格式指定的命令不会以“/bin/sh -c”来发起,因此常见的shell操作如变量替换以及通配符(?,*等)替换将不会进行;不过,如果要运行的命令依赖于此shell特性的话,可以将其替换为类似下面的格式。比如:RUN ["/bin/bash", "-c", "<executable>", "<param1>"]
RUN 使用示例
(1)编写dockerfile文件:使用RUN 执行解压命令
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
ENV DOC_ROOT=/data/web/html/ \
WEB_SERVER_PACKAGE="nginx-0.1.12"
COPY index.html ${DOC_ROOT}
WORKDIR /usr/local/
COPY ${WEB_SERVER_PACKAGE}.tar.gz ./src/
EXPOSE 8080:80/tcp
RUN cd ./src && \
tar -xf ${WEB_SERVER_PACKAGE}.tar.gz
(2)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.8 .
(3)基于此新建镜像运行容器,进行验证:已经执行了解压命令
[root@docker lemon]# docker run --name web1 -P --rm -it busyboxhttpd:v0.8 ls /usr/local/src
nginx-0.1.12 nginx-0.1.12.tar.gz
4.10 CMD 指令
CMD 指令介绍
- 指令格式
CMD <command> 或 CMD ["<executable>","<param1>","<param2>"]
注:
- 前两种语法格式的意义同RUN
- 第三种则用于为ENTRYPOINT指令提供默认参数
- json数组中,要使用双引号,单引号会出错
- 在Dockerfile中也可以存在多个CMD指令,但仅最后一个会生效
- 类似于RUN指令,CMD指令也可用于运行任何命令或应用程序,不过,二者的运行时间点不同
- RUN指令运行于映像文件构建过程中,而CMD指令运行于基于Dockerfile构建出的新映像文件启动一个容器时
- CMD指令的首要目的在于为启动的容器指定默认要运行的程序,且其运行结束后,容器也将终止;不过,CMD指定的命令其可以被docker run的命令行选项所覆盖
CMD 使用示例
(1)编写dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
ENV WEB_DOC_ROOT="/data/web/html/"
COPY index.html ${WEB_DOC_ROOT}
CMD /bin/httpd -f -h ${WEB_DOC_ROOT}
(2)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v0.9 .
(3)基于此新建镜像运行容器,进行验证,httpd正常运行
[root@docker lemon]# docker run --name web1 --rm -d -p 80:80 busyboxhttpd:v0.9
[root@docker lemon]# curl 192.168.1.1
<h1>Busybox httpd server-1</h1>
--- 可以使用exec 进入web1容器内进行验证
[root@docker lemon]# docker exec -it web1 /bin/sh

--- 也可以使用CMD定义的命令,在启动容器时,会被后面追加的指令覆盖
[root@docker lemon]# docker kill web1
[root@docker lemon]# docker run --name web1 --rm busyboxhttpd:v0.9 ls /
bin
data
……
[root@docker lemon]# curl 172.17.0.2 # 被ls /覆盖,所以没有执行httpd服务
curl: (7) Failed connect to 172.17.0.2:80; 没有到主机的路由
4.11 ENTRYPOINT 指令
ENTRYPOINT 指令介绍
- 指令格式
ENTRYPOINT <command> 或 ENTRYPOINT ["<executable>", "<param1>", "<param2>"]
注:
- docker run命令传入的命令参数会覆盖CMD指令的内容并且附加到ENTRYPOINT命令最后做为其参数使用
- Dockerfile文件中也可以存在多个ENTRYPOINT指令,但仅有最后一个会生效
- 类似CMD指令的功能,用于为容器指定默认运行程序,从而使得容器像是一个单独的可执行程序
- 与CMD不同的是,由ENTRYPOINT启动的程序不会被docker run命令行指定的参数所覆盖,而且,这些命令行参数会被当作参数传递给ENTRYPOINT指定指定的程序;但docker run命令的
--entrypoint选项能覆盖ENTRYPOINT 指令指定的程序
ENTRYPOINT 使用示例
(1)编写dockerfile文件
FROM busybox:latest
MAINTAINER "Lemon <lemon_row@163.com>"
ENV WEB_DOC_ROOT="/data/web/html/"
COPY index.html ${WEB_DOC_ROOT}
ENTRYPOINT /bin/httpd -f -h ${WEB_DOC_ROOT}
(2)使用build 制作镜像
[root@docker lemon]# docker build -t busyboxhttpd:v1.1 .
(3)基于此新建镜像运行容器,进行验证
[root@docker lemon]# docker run --name web2 --rm busyboxhttpd:v1.1 ls /

(4)打开一个终端,验证
[root@docker ~]# curl 172.17.0.2 # httpd服务仍然执行,没有被ls / 指令覆盖
<h1>Busybox httpd server-1</h1>
4.12 ONBUILD 指令
ONBUILD 指令介绍
- 指令格式
ONBUILD < Instruction>
注:
- 尽管任何指令都可注册成为触发器指令,但ONBUILD不能自我嵌套,且不会触发FROM和MAINTAINER指令
- 使用包含ONBUILD指令的Dockerfile构建的镜像应该使用特殊的标签,例如ruby:2.0-onbuil
- 在ONBUILD指令中使用ADD或COPY指令应该格外小心,因为新构建过程的上下文在缺少指定的源文件时会失败
- 用于在Dockerfile中定义一个触发器
- Dockerfile用于build映像文件,此映像文件亦可作为base image被另一个Dockerfile用作FROM指令的参数,并以之构建新的映像文件
- 在后面的这个Dockerfile中的FROM指令在build过程中被执行时,将会“触发”创建其base image的Dockerfile文件中的ONBUILD指令定义的触发器
ONBUILD 使用示例
(1)编写第一个Dockerfile文件,准备作为第二个Dockerfile文件的FROM基础镜像
FROM busybox
MAINTAINER "Lemon <lemon_row@163.com>"
ENV WEB_DOC_ROOT="/data/web/html"
RUN mkdir -p ${WEB_DOC_ROOT} && \
echo "<h1>Busybox httpd server1</h1>" > ${WEB_DOC_ROOT}/index.html
ONBUILD RUN echo "<h1>Busybox httpd server2</h1>" >> /data/web/html/index.html
(2)编写第2个Dockerfile文件,FROM 基于第1个Dockerfile
FROM busyboxhttpd:v1.3
(3)基于两个Dockerfile文件新建镜像,并运行容器,进行验证
① 基于第1个Dockerfile文件新建镜像
[root@docker lemon]# docker build -t busyboxhttpd:v1.3 .
② 基于第2个Dockerfile文件新建镜像
[root@docker tom]# docker build -t busyboxhttpd:v1.4 .
③ 基于上面两个新镜像启动容器验证
[root@docker lemon]# docker run --name web2 --rm busyboxhttpd:v1.3 cat /data/web/html/index.html
<h1>Busybox httpd server1</h1>
--- 证明ONBUILD指令,只在第2个Dockerfile文件中生效
[root@docker lemon]# docker run --name web2 --rm busyboxhttpd:v1.4 cat /data/web/html/index.html
<h1>Busybox httpd server1</h1>
<h1>Busybox httpd server2</h1>
六、Docker 容器的操作控制
1. 运行容器
docker run启动容器的方法
语法格式 : docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
OPTIONS说明:
-i: 以交互模式运行容器,通常与 -t 同时使用
-t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用
-d: 后台运行容器,并返回容器ID
-v: 挂在绑定一个数据卷
-P: 随机端口映射,容器内部端口随机映射到主机的端口
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
-h: 指定容器的hostname
-m:设置容器使用内存最大值
--name="nginx-lb": 为容器指定一个名称
--cpuset="0-2" or --cpuset="0,1,2": 绑定容器到指定CPU运行
--net="bridge": 指定容器的网络连接类型,支持 bridge/host/none/container: 四种类型
示例
[root@docker ~]# docker run -it centos:latest pwd
/ # 容器启动时执行 pwd,返回的 / 是容器中的当前目录。
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 咦,怎么没有容器?用 docker ps -a 或 docker container ls -a 看看。
[root@docker ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8c736027fc53 centos:latest "pwd" 3 minutes ago Exited (0) 3 amazing_lederberg
# -a 会显示所有状态的容器,可以看到,之前的容器已经退出了,状态为Exited。
这种“一闪而过”的容器通常不是我们想要的结果,我们希望容器能够保持 runing 状态,这样才能被我们使用。
2. 让容器长期运行
因为容器的生命周期依赖于启动时执行的命令,只要该命令不结束,容器也就不会退出。
理解了这个原理,我们就可以通过执行一个长期运行的命令来保持容器的运行状态。
例如执行下面的命令:

while 语句让 bash 不会退出。我们可以打开另一个终端查看容器的状态:

可见容器仍处于运行状态。不过这种方法有个缺点:它占用了一个终端。
我们可以加上参数 -d 以后台方式启动容器。先删除掉之前运行的容器 docker rm -f -v $(docker ps -qa)

容器启动后回到了 docker host 的终端。这里看到 docker 返回了一串字符,这是容器的 ID。
通过 docker ps 查看容器:

现在有了两个正在运行的容器。这里注意一下容器的 CONTAINER ID 和 NAMES 这两个字段:
- CONTAINER ID 是容器的 “短ID”,前面启动容器时返回的是 “长ID”。短ID是长ID的前12个字符。
- NAMES 字段显示容器的名字,在启动容器时可以通过 --name 参数显示地为容器命名,如果不指定,docker 会自动为容器分配名字。
上面通过 while 启动的容器虽然能够保持运行,但实际上没有干什么有意义的事情。容器常见的用途是运行后台服务,例如前面已经看到的 http server:

docker history httpd
httpd- foreground:是用来启动httpd的, 而且这个命令会在容器的前台运行,占用当前终端,因此httpd镜像在启动成容器时,容器并不会退出,你要把容器当做linux系统中的一个进程来看。

3. 两种进入容器的方法
有时候经常需要进到容器里去做一些工作,比如查看日志、调试、启动其他进程等。
有两种方法进入容器:
- docker attach container (不推荐使用)
- docker exec container (推荐使用)
通过 docker attach 进入容器:
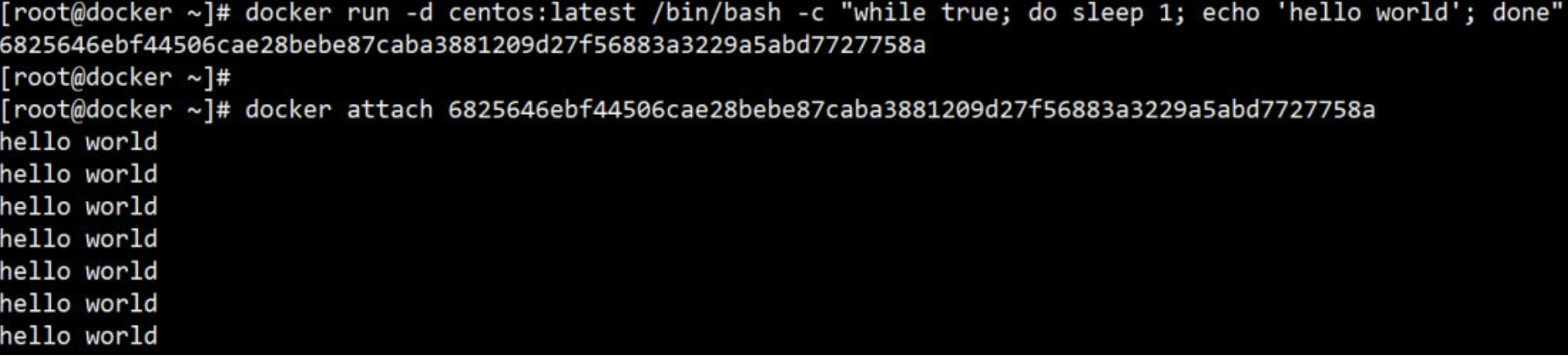
这次我们通过 “长ID” attach 到了容器的启动命令终端,之后看到的是echo 每隔一秒打印的信息;使用attach进入容器后就意味着只要你退出或关闭当前这个终端的话,容器就会停止运行。(所以不推荐使用这个方法)
通过 docker exec 进入容器:
docker exec -it <container> bash|sh 是执行 exec 最常用的方式
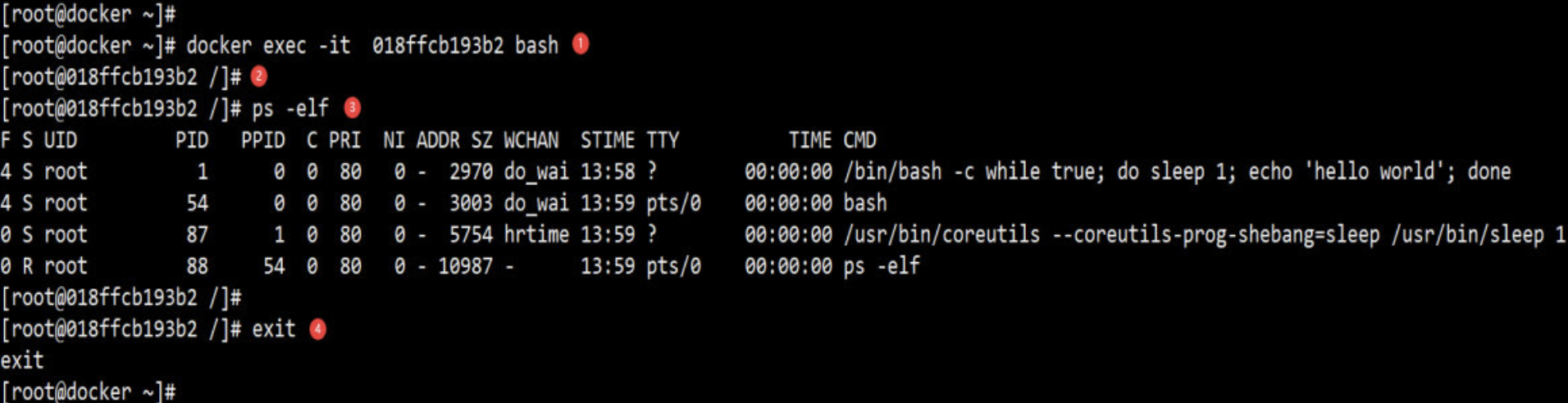
说明如下
① -it 以交互模式打开 pseudo-TTY,执行 bash,其结果就是打开了一个 bash 终端。
② 进入到容器中,容器的 hostname 就是其 “短ID”。
③ 可以像在普通 Linux 中一样执行命令。ps -elf 显示了容器启动进程while 以及当前的 bash 进程。
④ 执行 exit 退出容器,回到 docker host。
当然,如果只是为了查看容器启动命令的输出,可以使用 docker logs 命令:
-f 的作用与 tail -f 类似,能够持续打印输出。
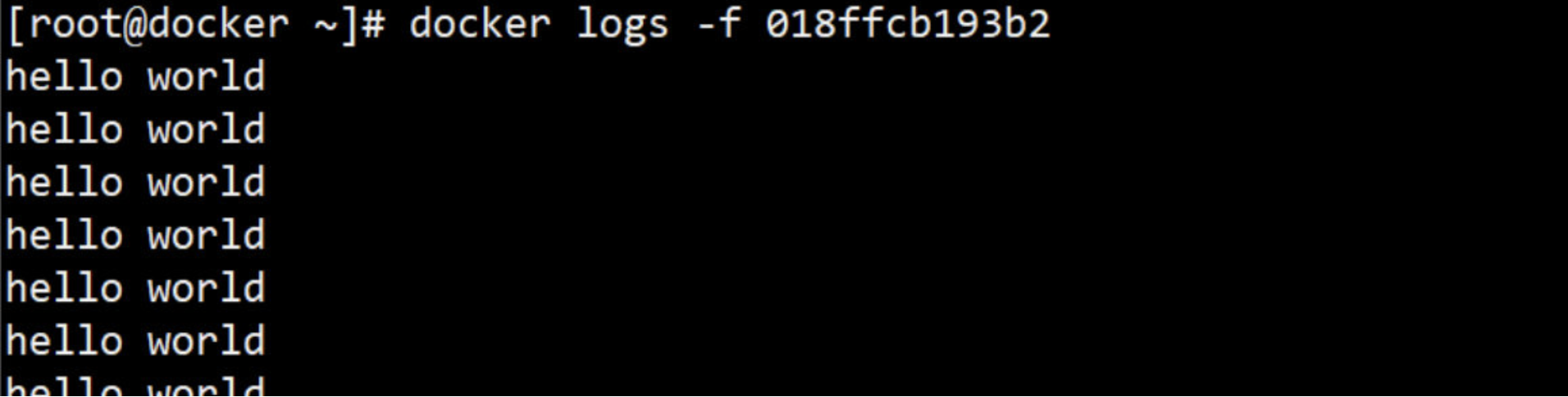
4. 常用的容器操作
stop / start / restart 容器
通过 docker stop 可以停止运行的容器。
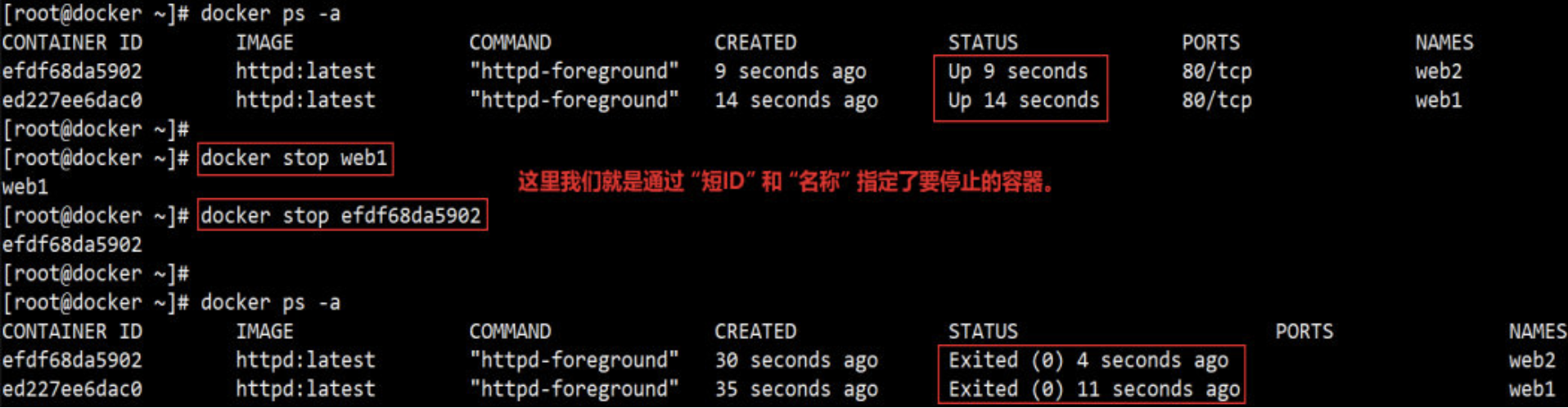
容器在 docker host 中实际上是一个进程,docker stop 命令本质上是向该进程发送一个 SIGTERM 信号。如果想快速停止容器,可使用 docker kill 命令,其作用是向容器进程发送 SIGKILL 信号。

对于处于停止状态的容器,可以通过 docker start 重新启动。

docker start 会保留容器第一次启动时的所有参数。
docker restart 可以重启容器,其作用就是依次执行 docker stop 和docker start。
容器可能会因某种错误而停止运行。对于服务类容器,我们通常希望在这种情况下容器能够自动重启。启动容器时设置 --restart 就可以达到这个效果。
--restart=always 意味着无论容器因何种原因退出(包括正常退出),就立即重启。
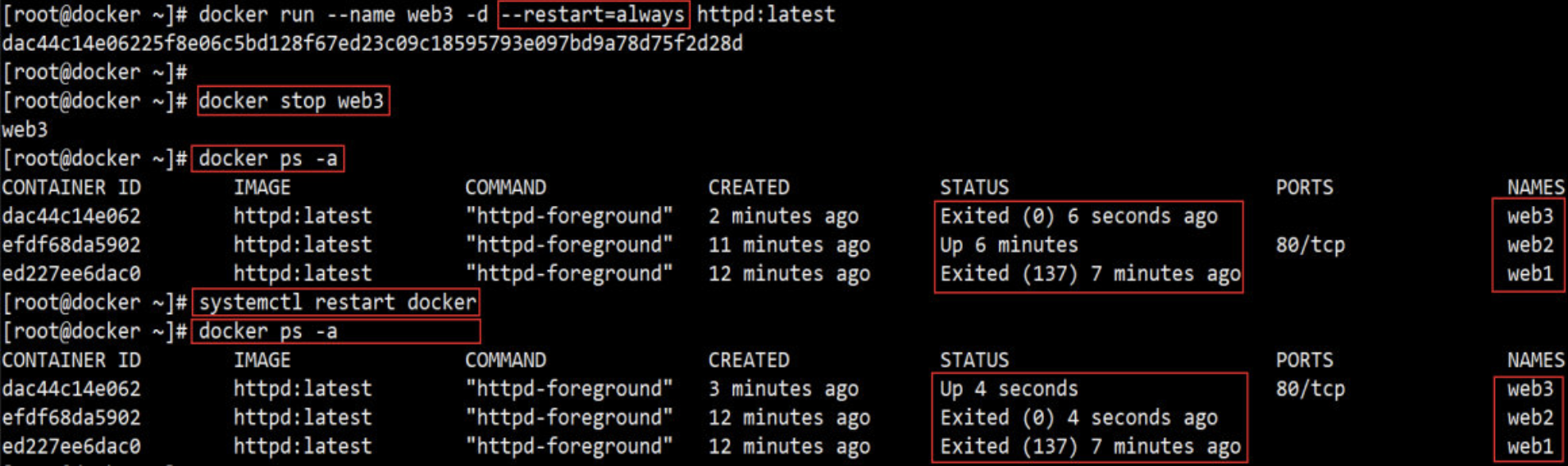
pause / unpause 容器
有时我们只是希望暂时让容器暂停工作一段时间,比如要对容器的文件系统打个快照,或者 dcoker host 需要使用 CPU,这时可以执行 docker pause。

处于暂停状态的容器不会占用 CPU 资源,直到通过 docker unpause 恢复运行。

删除容器
使用 docker 一段时间后,host 上可能会有大量已经退出了的容器。

这些容器依然会占用 host 的文件系统资源,如果确认不会再重启使用此类容器,可以通过 docker rm 删除。

如果希望批量删除所有已经退出的容器,可以执行如下命令:

顺便说一句:docker rm 是删除容器,而 docker rmi 是删除镜像。
5. 限制容器的操作
限制容器对内存的使用
一个 docker host 上会运行若干个容器,每个容器都需要 CPU、内存和 IO 等资源。对于 KVM,VMware 等虚拟化技术,用户可以控制分配多少 CPU、内存资源给每个虚拟机。对于容器,Docker 也提供了类似的机制避免某个容器因占用太多资源而影响其他容器乃至整个 host 的性能。
内存限额
与操作系统类似,容器可使用的内存包括两部分:物理内存 和 swap。 Docker 通过下面两组参数来控制容器内存的使用量。
-
-m或--memory:设置 内存的使用限额,例如 100M, 2G。 -
--memory-swap:设置 内存 + swap 的使用限额。
当执行命令:docker run -m 200M --memory-swap=300M centos:latest
其含义是允许该容器最多使用 200M 的物理内存和 100M 的 swap。默认情况下,上面两组参数为 -1,即对容器内存 和 swap 的使用没有限制。
下面使用 progrium/stress 镜像来学习如何为容器分配内存。该镜像可用于对容器执行压力测试。
执行如下命令:
docker run -it -m 200M --memory-swap=300M progrium/stress --vm 1 --vm-bytes 280M
解释:
- --vm 1:启动 1 个内存工作线程。
- --vm-bytes 280M:每个线程分配 280M 内存。
- 注:在真正分配内存时,是没必要使用 --vm 和 --vm-bytes参数的
运行结果如下:
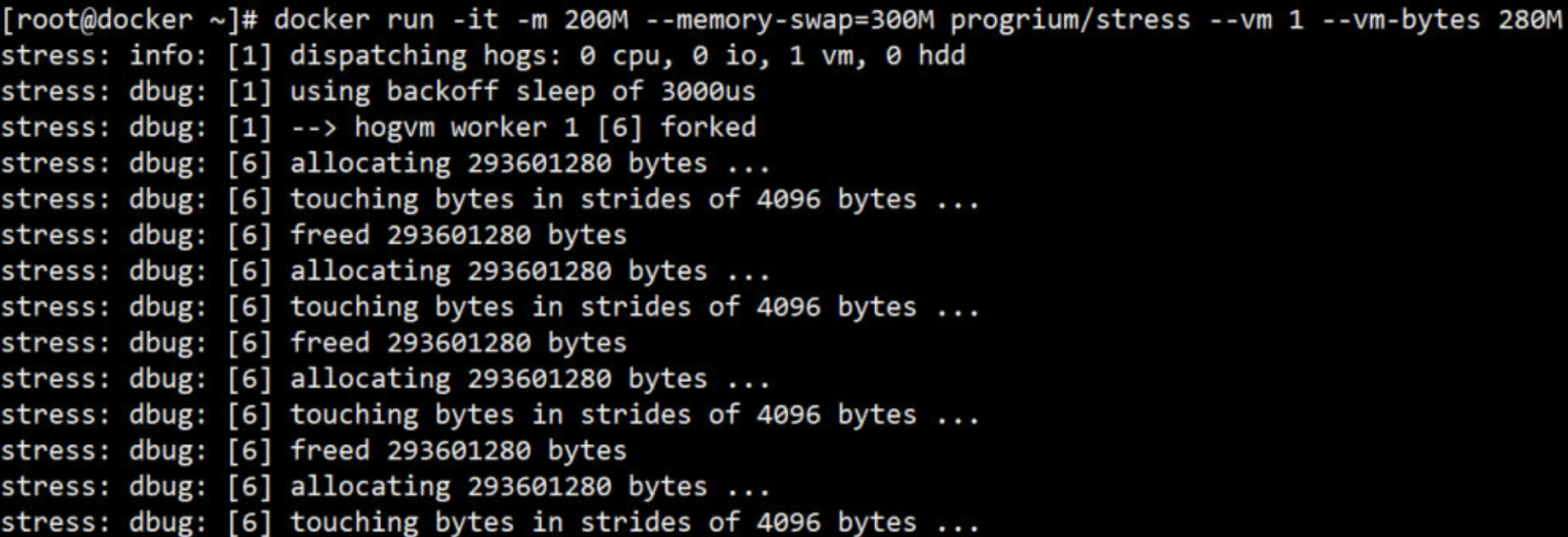
因为 280M 在可分配的范围(300M)内,所以工作线程能够正常工作,其过程是:
分配 280M 内存。
释放 280M 内存。
再分配 280M 内存。
再释放 280M 内存。
一直循环......
如果让工作线程分配的内存超过 300M,结果如下:
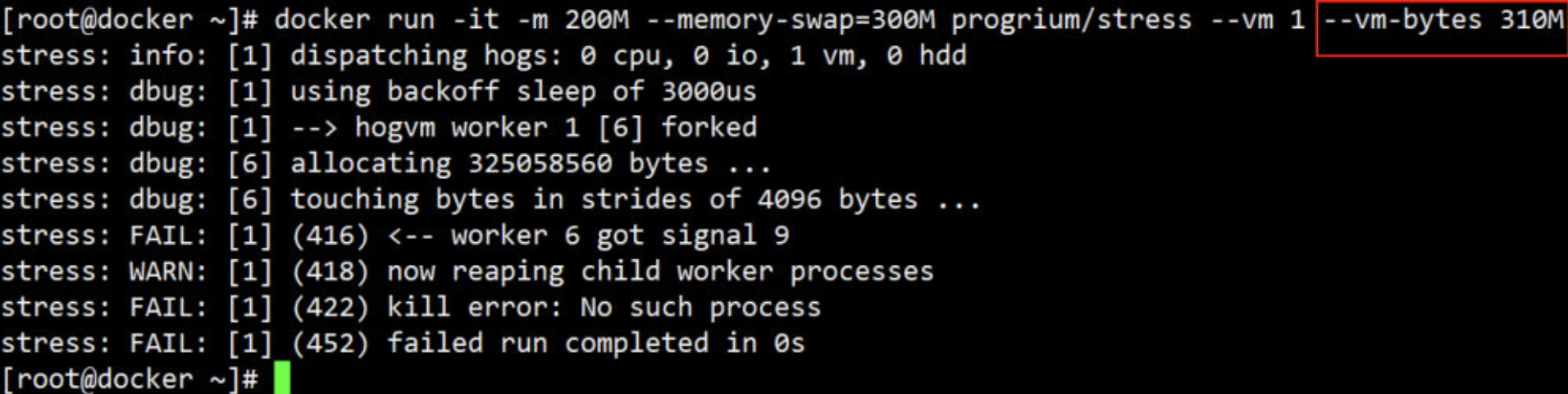
分配的内存超过限额,stress 线程报错,容器退出。
如果在启动容器时只指定 -m 而不指定 --memory-swap,那么 --memory-swap 默认为 -m 的两倍,比如:docker run -it -m 200M ubuntu,此时容器最多使用 200M 物理内存 和 400M swap。
限制容器对CPU的使用
默认设置下,所有容器可以平等地使用 host CPU 资源并且没有限制。
Docker 可以通过 -c 或 --cpu-shares 设置容器使用 CPU 的权重。如果不指定,默认值为 1024。
与内存限额不同,通过 -c 设置的 cpu share 并不是 CPU 资源的绝对数量,而是一个相对的权重值。
某个容器最终能分配到的 CPU 资源取决于它的 cpu share 占所有容器 cpu share 总和比例。
换句话说:通过 cpu share 可以设置容器使用 CPU 的优先级。
比如在 docker host 中启动了两个容器:
-
docker run --name "container_A" -c 1024 centos -
docker run --name "container_B" -c 512 centos
此时container_A 的 cpu share 1024,是 container_B 的两倍。当两个容器都需要 CPU 资源时,container_A 可以得到的 CPU 是 container_B 的两倍。
需要特别注意的是, 这种按权重分配 CPU 只会发生在 CPU 资源紧张的情况下, 如果 container_A 处于空闲状态, 这时, 为了充分利用 CPU 资源, container_B 也可以分配到全部可用的 CPU。
下面继续用 progrium/stress 做实验。
1、启动 lemon1,cpu share 为 1024
docker run --name lemon1 -it -c 1024 progrium/stress --cpu 4
--cpu 用来设置工作线程的数量。因为当前 host 有 4 颗 CPU,所以需要4个工作线程才能将 CPU 压满。如果 host 有多颗 CPU,则需要相应增加 --cpu 的数量。
注:在真正环境中 --cpu 选项是不需要使用的,这里使用是为了方便实验测试
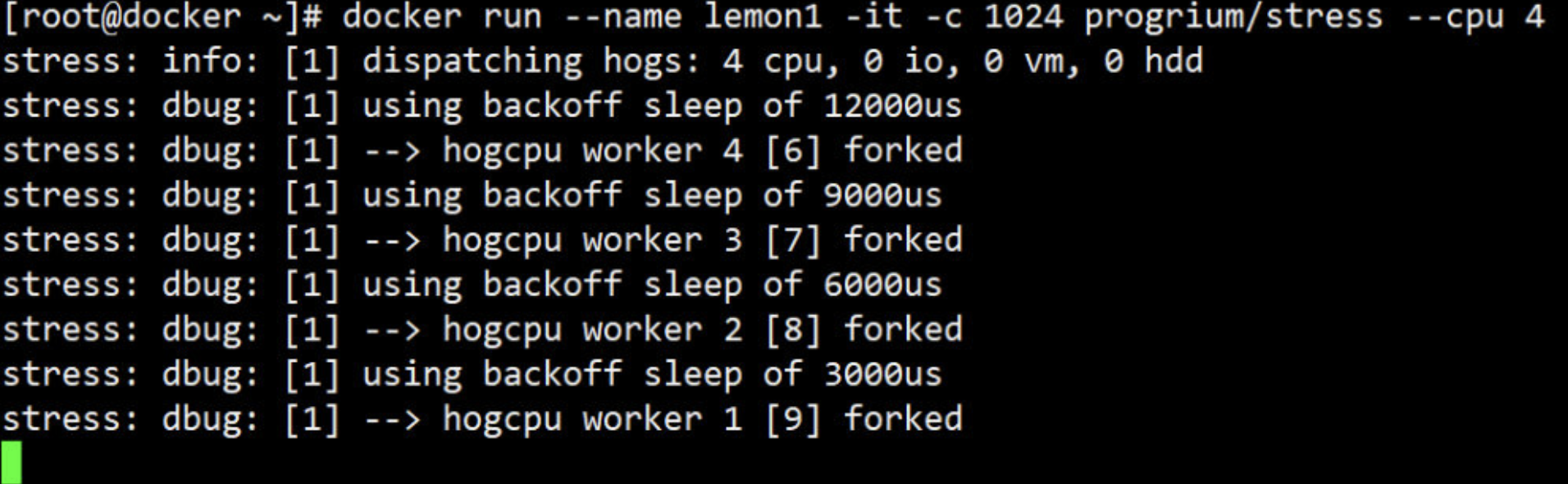
2、启动 lemon2,cpu share 为 512
docker run --name lemon2 -it -c 512 progrium/stress --cpu 4
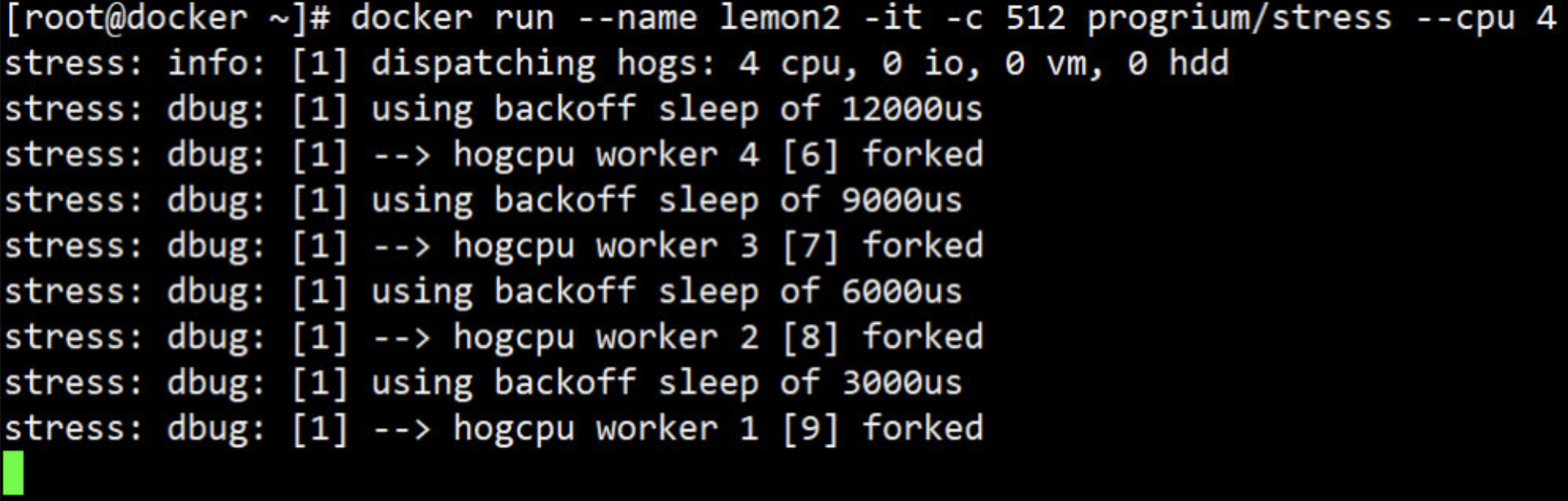
3、在 host 中执行 top,查看容器对 CPU 的使用情况
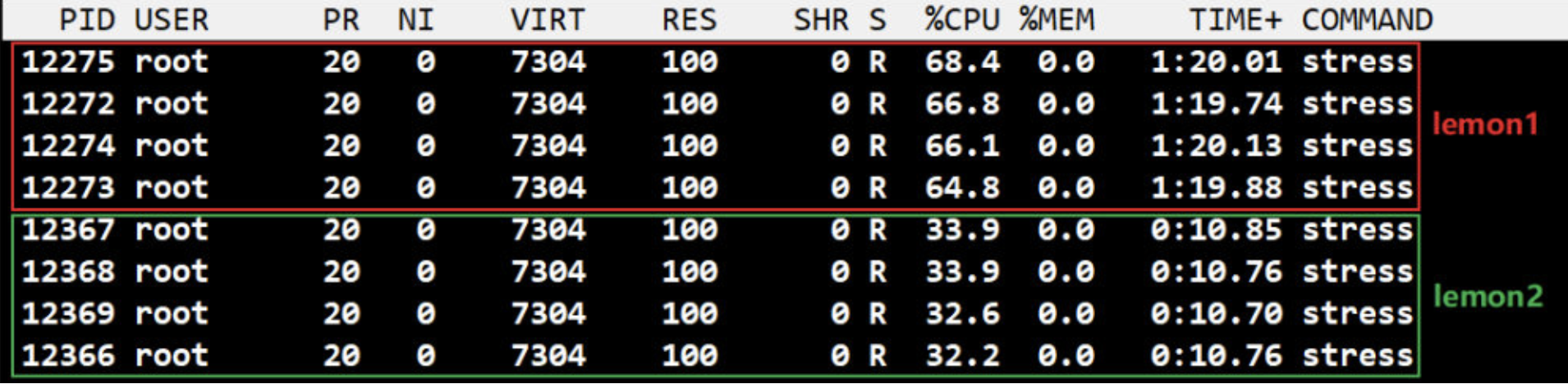
4、现在暂停 lemon1

5、top 显示 lemon2 在 lemon1 空闲的情况下是能够用满整颗 CPU

限制容器的 Block IO
Block IO 是另一种可以限制容器使用的资源。Block IO 指的是磁盘的读 / 写,docker 可通过设置权重、限制 bps 和 iops 的方式控制容器读写磁盘的带宽。
注:目前 Block IO 限额只对 direct IO(不使用文件缓存)有效。
block IO 权重
默认情况下,所有容器能平等地读写磁盘,可以通过设置 --blkio-weight 参数来改变容器 block IO 的优先级。
--blkio-weight 与 --cpu-shares 类似,设置的是相对权重值,默认为 500。在下面的例子中,lemon1读写磁盘的带宽是 lemon2 的两倍。
-
docker run -it --name lemon1 --blkio-weight 600 ubuntu -
docker run -it --name lemon2 --blkio-weight 300 ubuntu
……
限制 bps 和 iops
-
bps 是 byte per second,每秒读写的数据量。
-
iops 是 io per second,每秒 IO 的次数。
可通过以下参数控制容器的 bps 和 iops:
- --device-read-bps,限制读某个设备的 bps。
- --device-write-bps,限制写某个设备的 bps。
- --device-read-iops,限制读某个设备的 iops。
- --device-write-iops,限制写某个设备的 iops。
下面这个例子限制容器写 /dev/sda 的速率为20 MB/s
docker run -it --device-write-bps /dev/sda:20MB centos
time dd if=/dev/zero of=test.out bs=1M count=800 oflag=direct
来看看实验结果:
通过 dd 测试在容器中写磁盘的速度, 因为容器的文件系统是在 host /dev/sda 上的, 在容器中写文件相当于对 host /dev/sda 进行写操作。另外,oflag=direct 指定用 direct IO 方式写文件,这样 --device-write-bps 才能生效。
结果表明,bps 21.0 MB/s
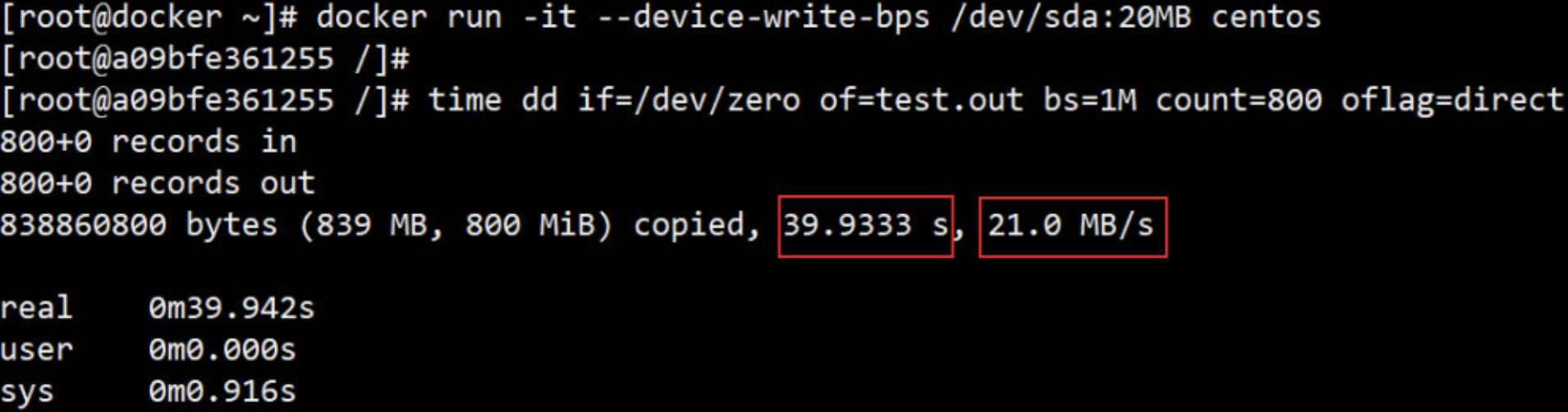
作为对比测试,如果不限速,结果如下:

为什么要限制容器?
比如:我现在有两个正在运行的容器 “web1” 和 “web2”

此处的 web1 和 web2 都会占用系统资源,甚至会和系统抢占资源(CPU 内存 网络 硬盘),所以我们要限制容器,不然就会出现我上面所说的情况!!
七、Docker 隔离及限制的底层技术
cgroup 和 namespace 是最重要的两种技术。cgroup 实现系统资源限额, namespace 实现资源隔离。
1. cgroup
cgroup 全称 Control Group。
-
Linux 操作系统就是通过 cgroup 可以设置进程使用 CPU、内存 和 IO 资源的限额。
-
前面用到的
--cpu-shares、-m、--device-write-bps实际上就是在配置 cgroup。
cgroup 到底长什么样子呢?可以在 /sys/fs/cgroup 中找到它。
- 还是用例子来说明,启动一个容器,设置 --cpu-shares=512:
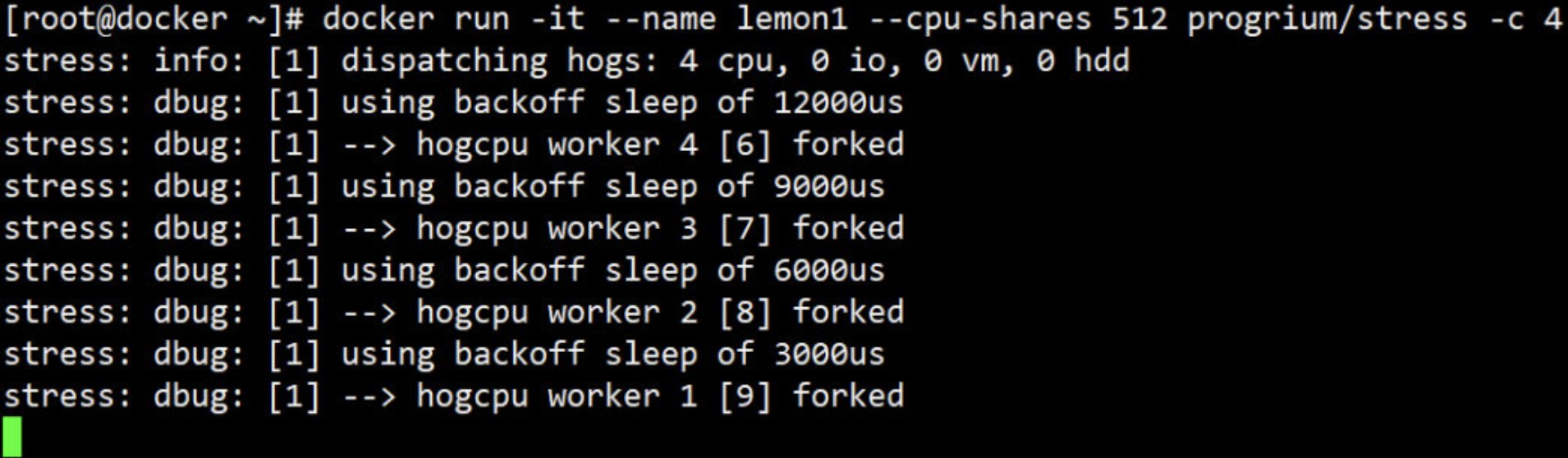
- 查看容器的 ID:

- 在
/sys/fs/cgroup/cpu/docker目录中,Linux 会为每个容器创建一个 cgroup 目录,以容器长ID 命名:
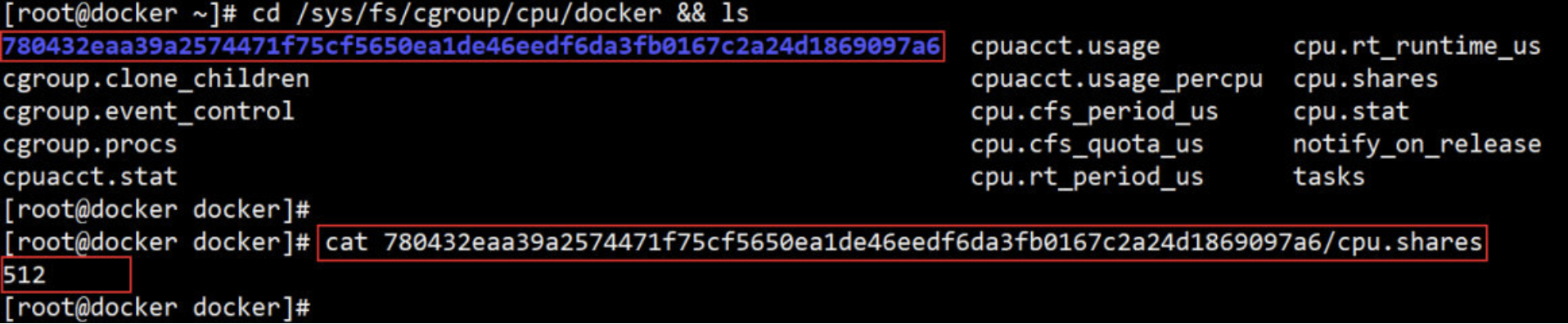
目录中包含所有与 cpu 相关的 cgroup 配置,cpu.shares 文件保存的就是 --cpu-shares 的配置,值为 512
同样, /sys/fs/cgroup/memory/docker 和 /sys/fs/cgroup/blkio/docker 中保存的是内存以及 Block IO 的 cgroup 配置
2. namespace
在每个容器中, 都能看到文件系统, 网卡等资源, 这些资源看上去就好像是容器自己的, 拿网卡来说, 每个容器都会认为自己有一块独立的网卡, 即使 host 上只有一块物理网卡, 这种方式非常好, 它使得容器更像一个独立的计算机。
Linux 使用了六种 namespace,分别对应六种资源:Mount、UTS、IPC、PID、Network 和 User,下面分别介绍。
Mount namespace(文件系统的资源隔离)
Mount namespace 让容器看上去拥有整个文件系统。
容器有自己的 / 目录,可以执行 mount 和 umount 命令。当然我们知道这些操作只在当前容器中生效,不会影响到 host 和其他容器。

UTS namespace (主机名称的资源隔离)
简单的说,UTS namespace 让容器有自己的 hostname。 默认情况下,容器的 hostname 是它的短ID,可以通过 -h 或 --hostname 参数设置。

PID namespace (进程号的资源隔离)
前面提到过,容器在 host 中以进程的形式运行。
例如当前 host 中运行了两个容器:
IPC namespace (内存的资源隔离)
IPC namespace 让容器拥有自己的共享内存和信号量(semaphore)来实现进程间通信,而不会与 host 和其他容器的 IPC 混在一起。
Network namespace(网络的资源隔离)
Network namespace 让容器拥有自己独立的网卡、IP、路由等资源。这个在下面网络章节详细讨论。
User namespace (用户的资源隔离)
User namespace 让容器能够管理自己的用户,host 不能看到容器中创建的用户。
八、Docker 单主机网络
本章开始讨论 Docker 网络;首先学习 Docker 提供的几种原生网络,以及如何创建自定义网络;然后探讨容器之间如何通信,以及容器与外界如何交互。
Docker 安装时会自动在 host 上创建三个网络,我们可用 docker network ls 命令查看

在安装完docker之后,默认有3个原生网络bridge、host、none,运行容器时可以使用--network选项来指定你要运行的网络模式、如若不指定默认容器运行的是bridge网络模式。
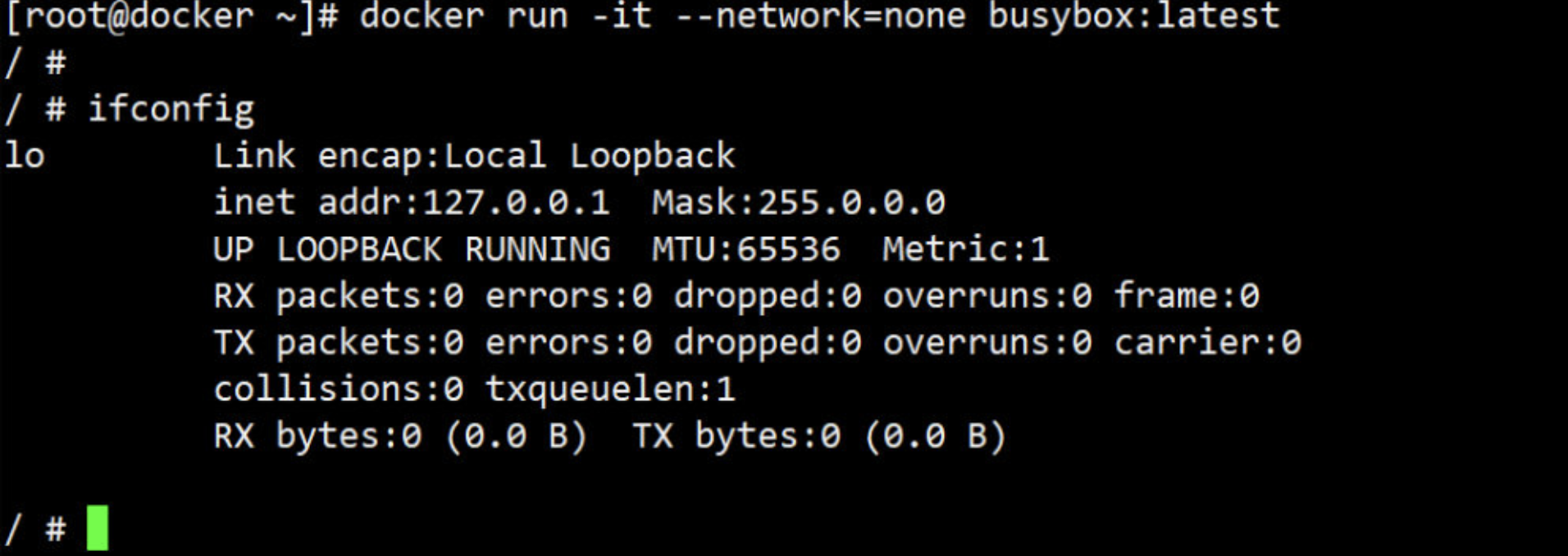
1. none 网络
故名思议,none 网络就是什么都没有的网络;挂在这个网络下的容器除了 lo,没有其他任何网卡。
这样一个封闭的网络有什么用呢?
-
其实还真有应用场景。封闭意味着隔离,一些对安全性要求高并且不需要联网的应用可以使用 none 网络。
-
比如某个容器的唯一用途是生成随机密码,就可以放到 none 网络中避免密码被窃取。
-
当然大部分容器是需要网络的,我们接着看 host 网络。
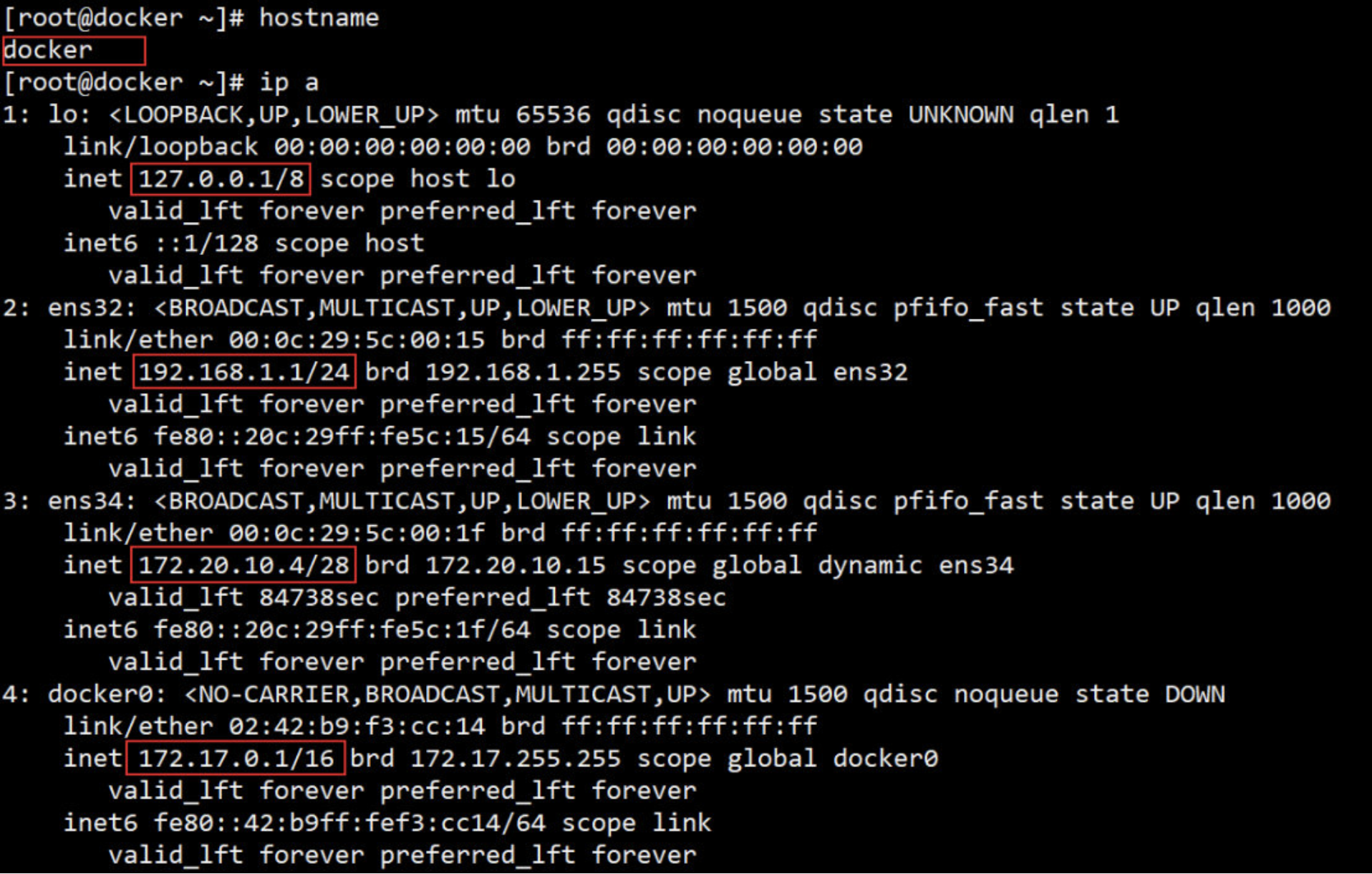
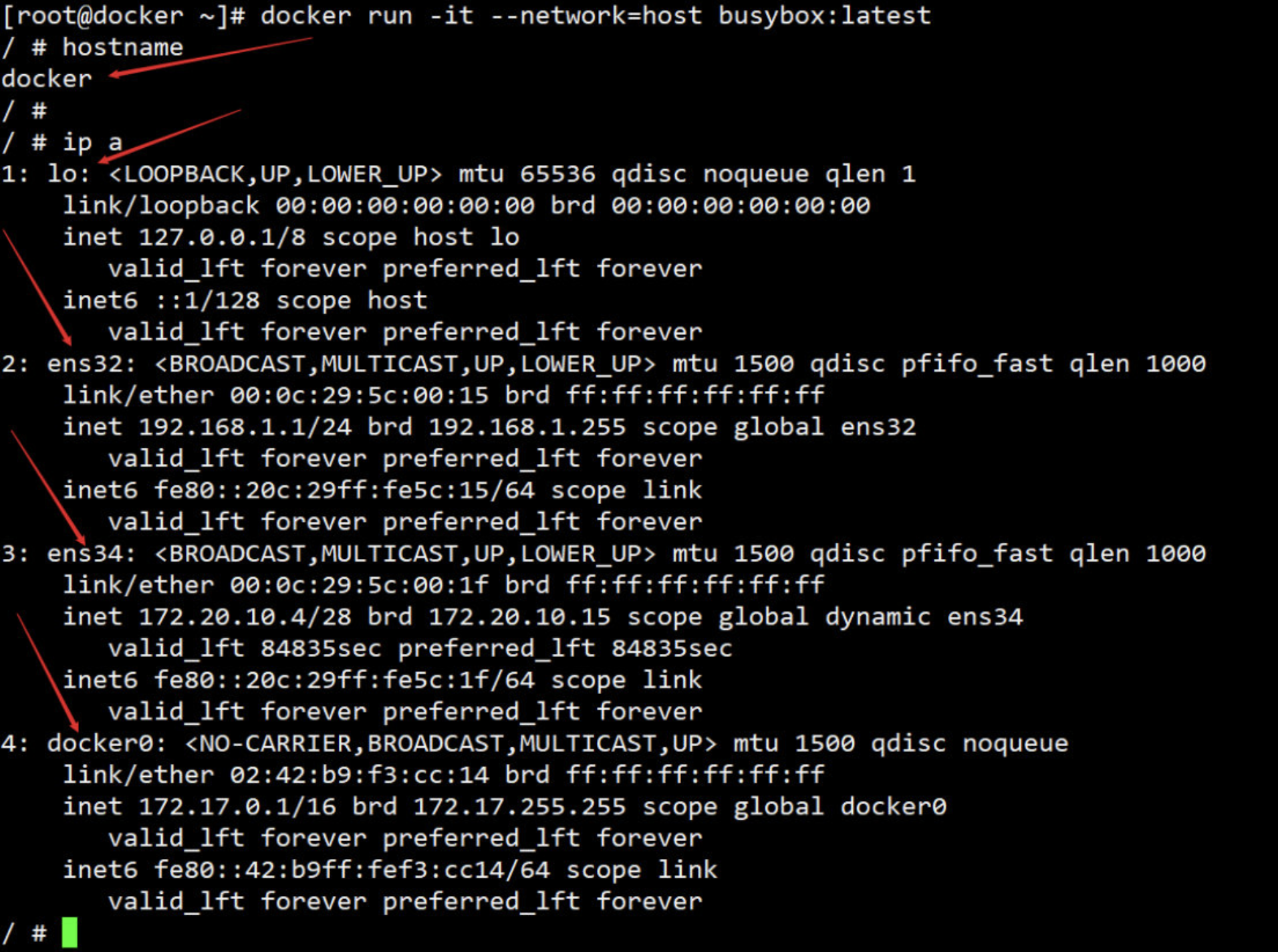
2. host 网络
连接到 host 网络的容器共享 Docker host 的网络栈,容器的网络配置与 host 完全一样。
在容器中可以看到 host 的所有网卡,并且就连 hostname 也是 host 的。
那 host 网络的使用场景又是什么呢?
-
直接使用 Docker host 的网络最大的好处就是性能,如果容器对网络传输效率有较高要求,则可以选择 host 网络。当然不便之处就是牺牲一些灵活性,比如要考虑端口冲突问题,Docker host 上已经使用的端口在容器上就不能再用了。
-
Docker host 的另一个用途是让容器可以直接配置 host 网路。比如某些跨 host 的网络解决方案,其本身也是以容器方式运行的,这些方案需要对网络进行配置,比如管理 iptables 。
3. Bridge网络(重点)
Docker 安装时会在host上创建一个命名为 docker0 的 linux bridge。如果不指定 --network,创建的容器默认都会挂到 docker0 上。
本小节比较重要,所以这里就是用阿里云服务器来演示了
查看 host 全部网卡
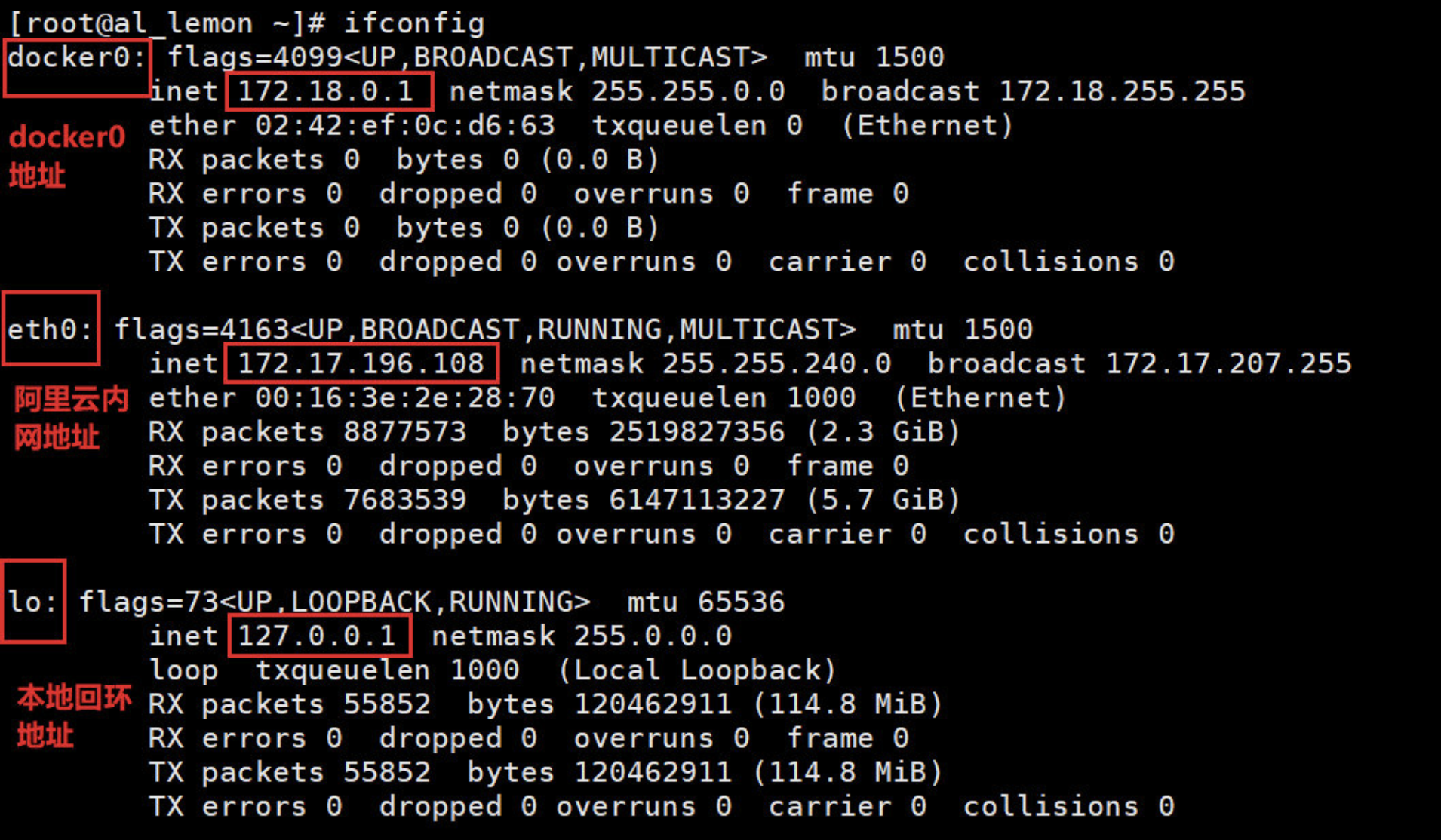
查看 host 的网桥列表
yum -y install bridge-utils # 安装工具包

可以看到当前 docker0网桥上没有任何其他网络设备,我们创建一个容器看看有什么变化。
[root@al_lemon ~]# docker run -itd -P --name tomcat01 tomcat

然后再查看一下host 和 容器的网卡
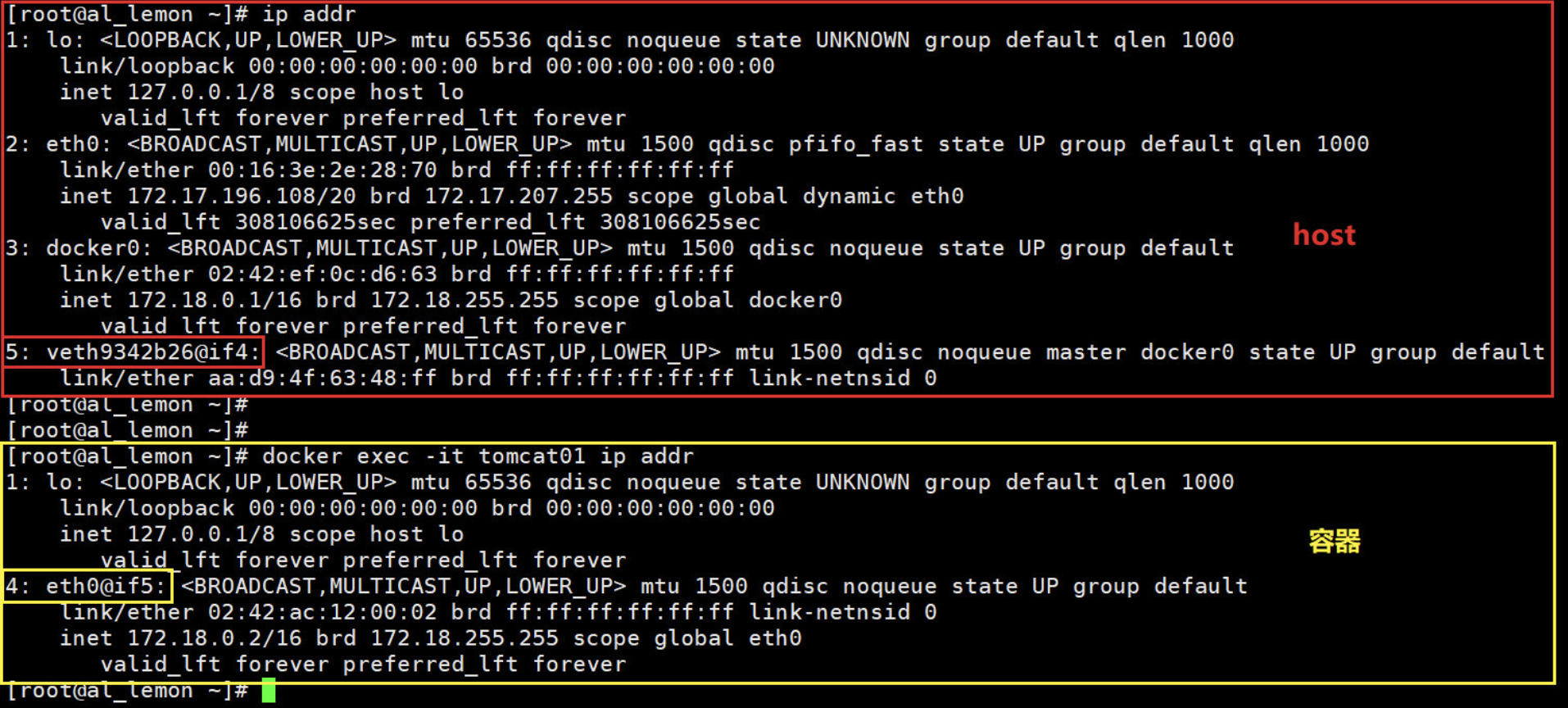
如此可见一个新的网络接口 veth9342b26 被挂到了 docker0 上,veth9342b26 就是新创建容器的虚拟网卡或者也可以说是虚拟接口。
原理
每启动一个容器,docker就会给容器非配一个ip地址,只要安装了docker,host上就会有一个docker0网卡(网桥),这里使用的技术是 veth-pair (重点)!!!
再来看一下 host 上新出来的那块网卡
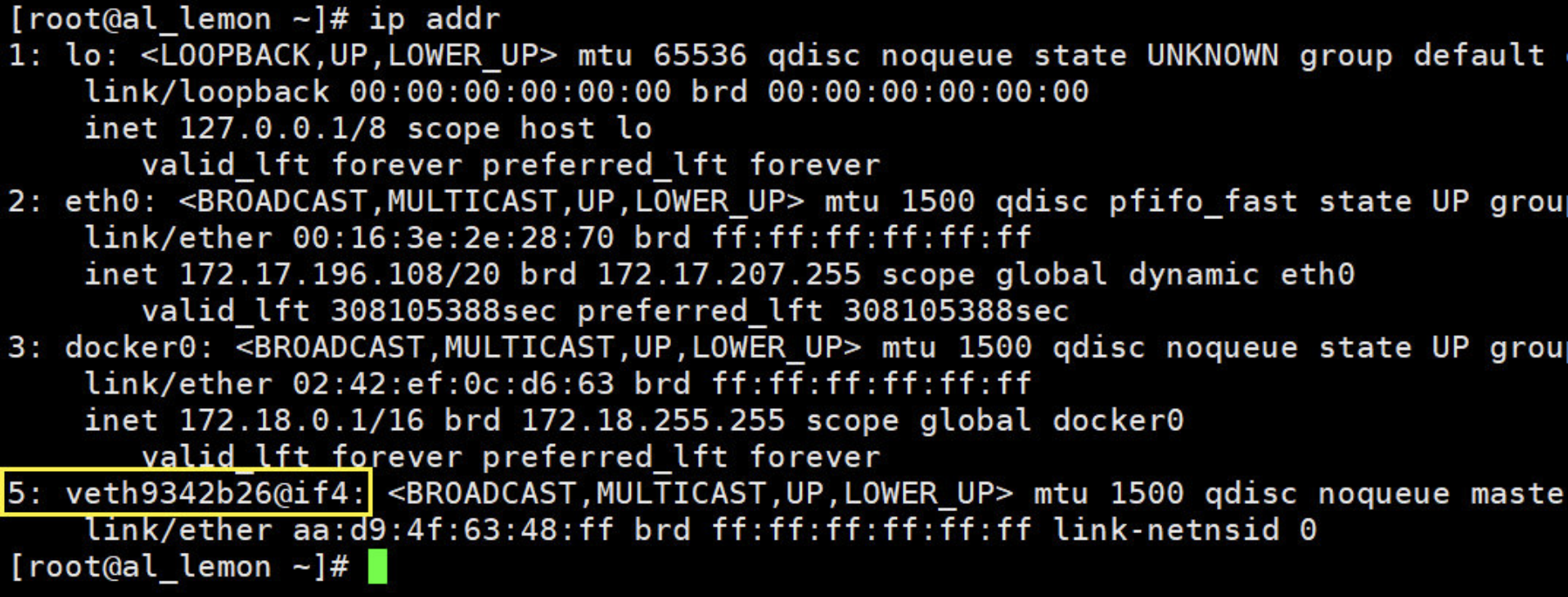
再来启动一个容器,会发现又多了一对网卡!!!
[root@al_lemon ~]# docker run -itd -P --name tomcat02 tomcat
再来看一下host 和 容器的网卡,相信现在应该可以察觉到了吧,我每创建一个容器docker都会生产一对网卡!!
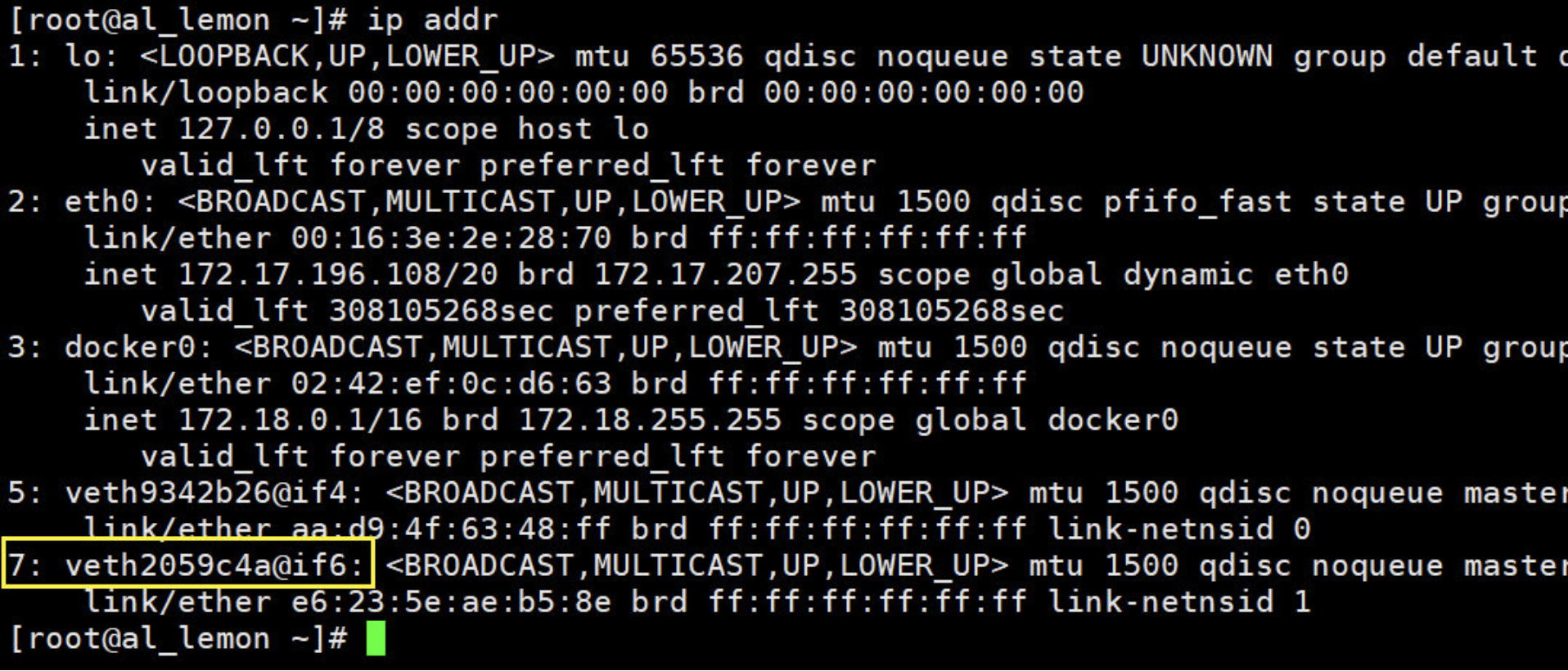
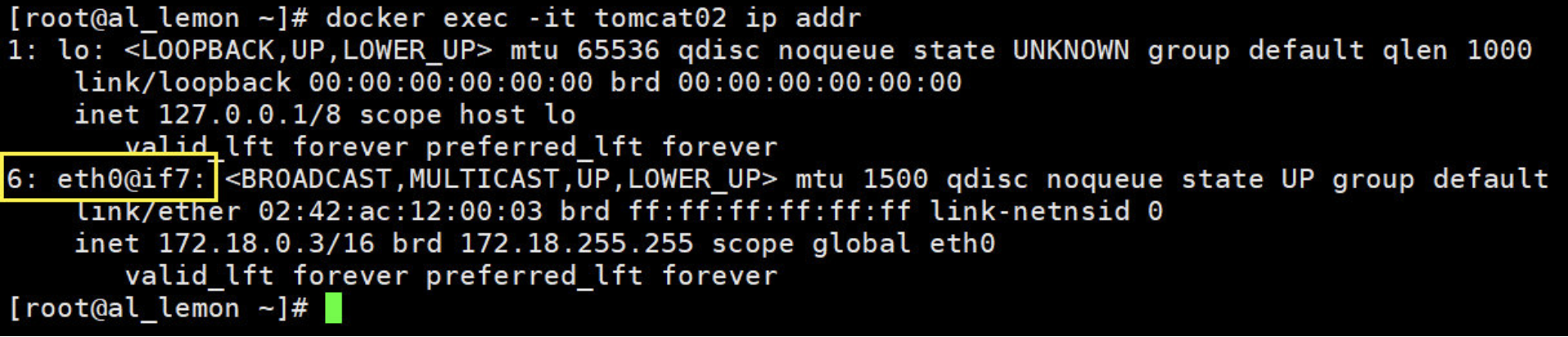
# 会发现我每创建运行一个容器,都会生成一对网卡,host上一个,容器上一个。
# veth-pair就是一对的虚拟设备接口,她都是成对出现的,host上的那块网卡你可以把它理解为交换机或接口。
tomcat01 和 tomcat02 之间能不能相互通信?
[root@al_lemon ~]# docker exec -it tomcat01 ping -c 3 172.18.0.3
PING 172.18.0.3 (172.18.0.3) 56(84) bytes of data.
64 bytes from 172.18.0.3: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 172.18.0.3: icmp_seq=2 ttl=64 time=0.061 ms
64 bytes from 172.18.0.3: icmp_seq=3 ttl=64 time=0.069 ms
[root@al_lemon ~]# docker exec -it tomcat02 ping -c 3 172.18.0.2
PING 172.18.0.2 (172.18.0.2) 56(84) bytes of data.
64 bytes from 172.18.0.2: icmp_seq=1 ttl=64 time=0.075 ms
64 bytes from 172.18.0.2: icmp_seq=2 ttl=64 time=0.072 ms
64 bytes from 172.18.0.2: icmp_seq=3 ttl=64 time=0.065 ms
原理模型图
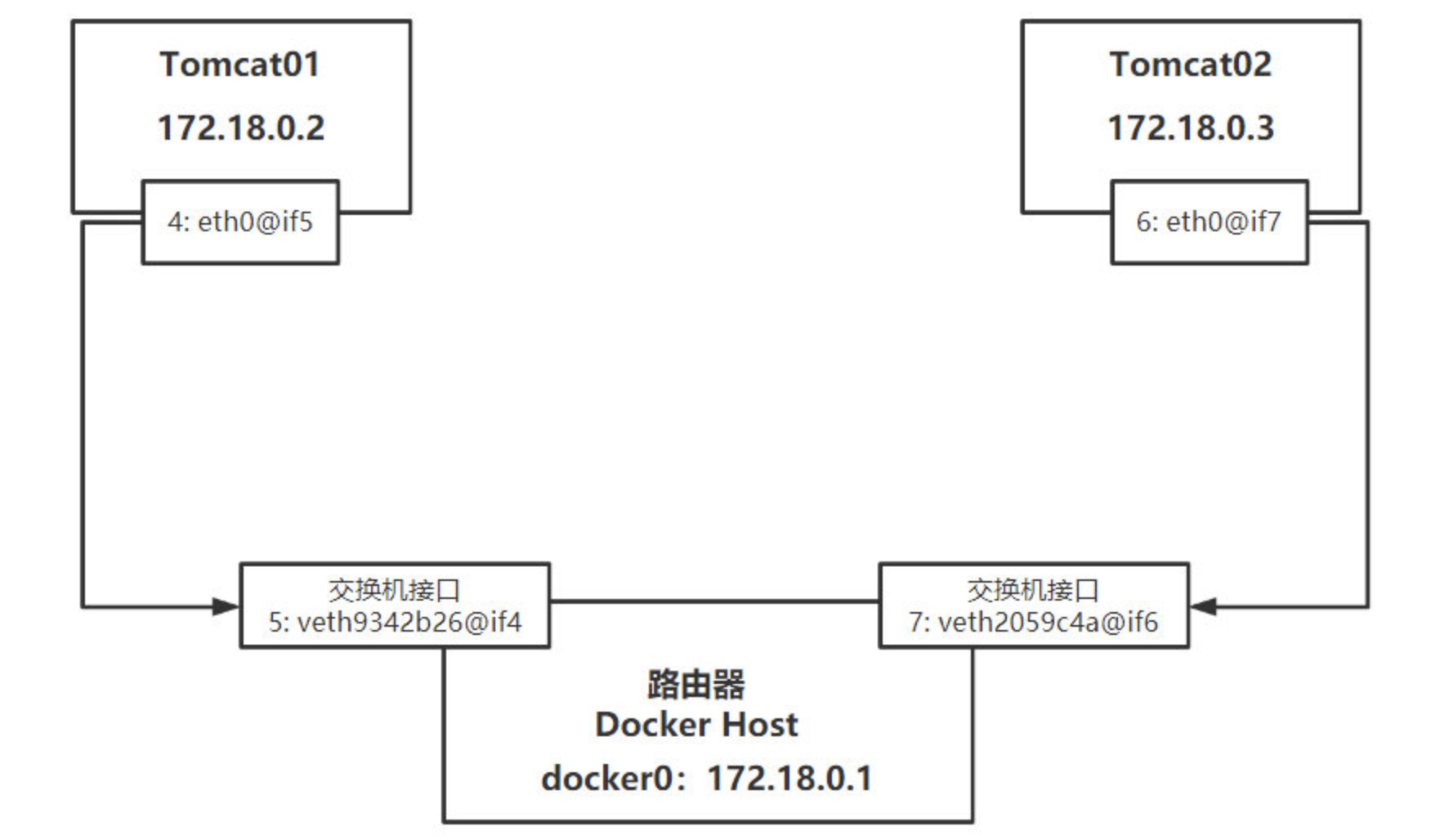
结论: tomcat01 和 tomcat02 是共用的一个路由器(docker0), 所以只要用的是同一个网络的容器就可以通信。
容器能不能与外界通信?
测试一下
[root@al_lemon ~]# docker exec -it tomcat01 ping -c 3 www.baidu.com
PING www.a.shifen.com (220.181.38.149) 56(84) bytes of data.
64 bytes from 220.181.38.149 (220.181.38.149): icmp_seq=1 ttl=53 time=5.24 ms
64 bytes from 220.181.38.149 (220.181.38.149): icmp_seq=2 ttl=53 time=5.34 ms
64 bytes from 220.181.38.149 (220.181.38.149): icmp_seq=3 ttl=53 time=5.33 ms
[root@al_lemon ~]# docker exec -it tomcat02 ping -c 3 www.baidu.com
PING www.a.shifen.com (220.181.38.150) 56(84) bytes of data.
64 bytes from 220.181.38.150 (220.181.38.150): icmp_seq=1 ttl=53 time=5.66 ms
64 bytes from 220.181.38.150 (220.181.38.150): icmp_seq=2 ttl=53 time=5.69 ms
64 bytes from 220.181.38.150 (220.181.38.150): icmp_seq=3 ttl=53 time=5.65 ms
# 结论:是可以访问的
原理模型图

这个问题一会还会在下小节 容器如何访问的外部世界 中继续深度探究~~
删除上面的两个容器那这个veth-pair接口会不会消失?
[root@al_lemon ~]# docker rm -f -v $(docker ps -qa)
a66599b3cbc1
e93b04812bb3
结论:这些个成对的 veth-pair 网桥是会随着容器的消失而消失!!!
4. 自定义网络(重点)
Docker 提供三种 user-defined 网络驱动:bridge, overlay 和 macvlan。overlay 和 macvlan 用于创建跨主机的网络,这个后面有章节单独讨论。
直接可通过 bridge 驱动创建类似前面默认的 bridge 网络
1、若要解决使用ifconfig命令可以看到docker1的问题,可以执行以下几步命令
[root@al_lemon ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
7641b78b9c7e bridge bridge local
1fb28082d011 host host local
6df43af5872b none null local
2、查看bridge的信息,确认能在ifconfig中显示网桥名称的选项,com.docker.network.bridge.name
[root@al_lemon ~]# docker network inspect bridge
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
3、创建docker1网桥
[root@al_lemon ~]# docker network create my_net01 \
--driver=bridge --subnet=192.168.10.0/24 --gateway=192.168.10.254 \
-o com.docker.network.bridge.name=docker1
4、查看一下当前 docker host 的网络
[root@al_lemon ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
7641b78b9c7e bridge bridge local
1fb28082d011 host host local
7f75481e2278 my_net01 bridge local
6df43af5872b none null local
5、查看一下当前 docker host 的网桥
[root@al_lemon ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242ef0cd663 no
docker1 8000.0242f0fb530f no
6、查看一下 docker host 的docker1 网卡信息
[root@al_lemon ~]# ifconfig docker1
docker1: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.10.254 netmask 255.255.255.0 broadcast 192.168.10.255
ether 02:42:f0:fb:53:0f txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
7、查看一下 my_net01 网络的配置信息
[root@al_lemon ~]# docker network inspect my_net01
[
{
"Name": "my_net01",
"Id": "7f75481e2278c85a205baad5df88bb863d72a7e712dfce2f69fbc6b31b49331b",
"Created": "2020-08-16T12:28:03.368583315+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "192.168.10.0/24",
"Gateway": "192.168.10.254"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {
"com.docker.network.bridge.name": "docker1"
},
"Labels": {}
}
]
容器要使用新的网络,需要在启动时通过
--network指定:
docker run -it --name web01 --network=my_net01 busybox:latest
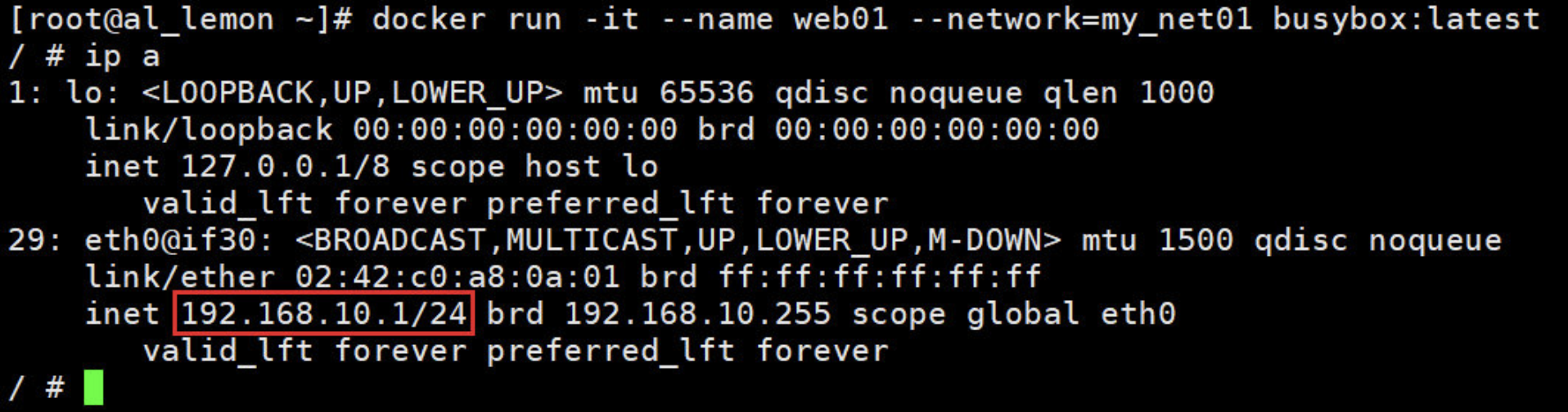
容器分配到的 IP 为 192.168.10.1。
目前为止,容器的IP都是docker自动从subnet中分配,我们能否指定一个静态 IP 呢?
答案是:可以,通过
--ip指定。
docker run -it --name web02 --network=my_net01 --ip=192.168.10.111 busybox:latest
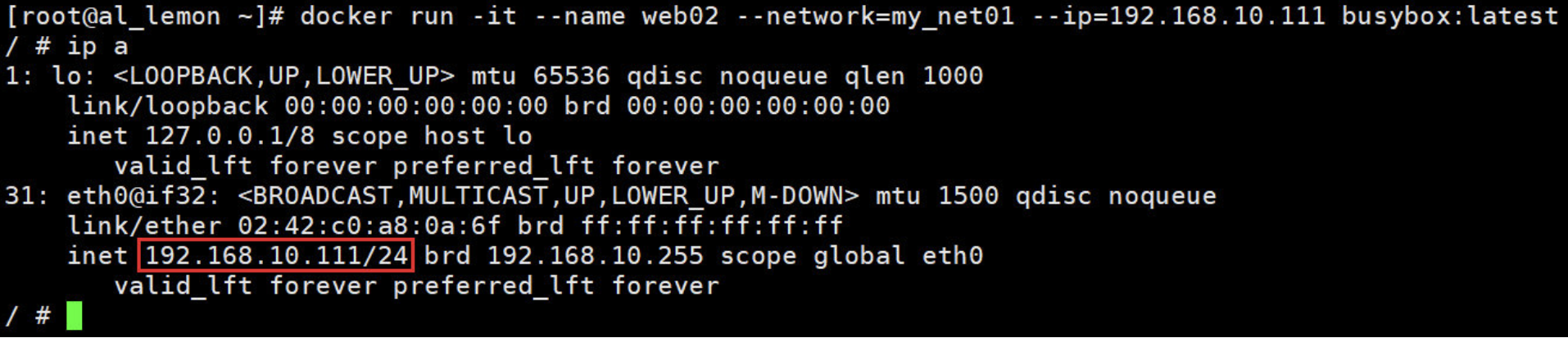
注:只有使用 --subnet 创建的网络才能指定静态 IP。
5. 不同网络的容器之间如何通信
网络拓扑结构:
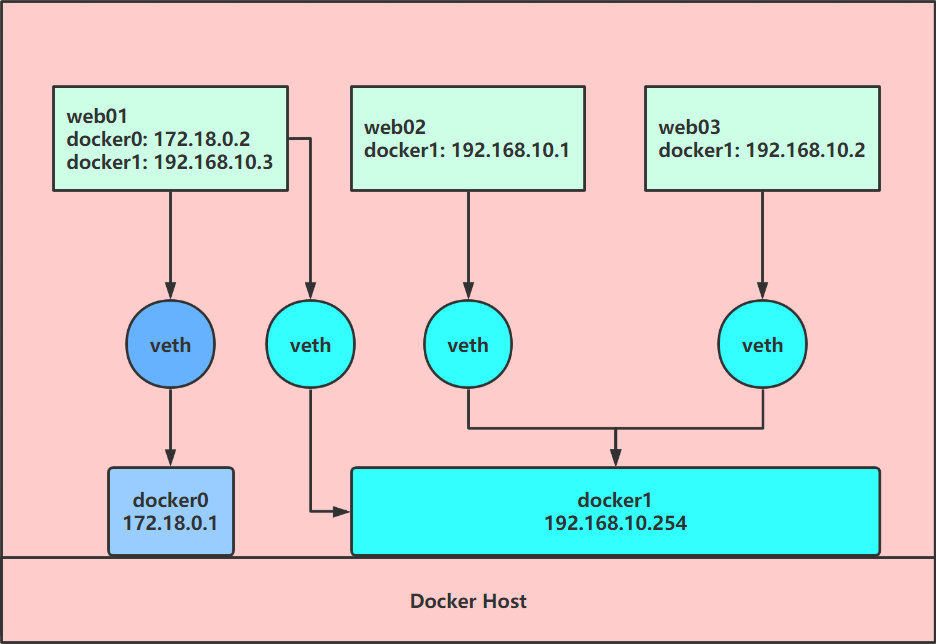
模拟上图网络扩展
1、查看 docker host 网络
[root@al_lemon ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:16:3e:2e:28:70 brd ff:ff:ff:ff:ff:ff
inet 172.17.196.108/20 brd 172.17.207.255 scope global dynamic eth0
valid_lft 308060958sec preferred_lft 308060958sec
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ef:0c:d6:63 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global docker0
valid_lft forever preferred_lft forever
27: docker1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:f0:fb:53:0f brd ff:ff:ff:ff:ff:ff
inet 192.168.10.254/24 brd 192.168.10.255 scope global docker1
valid_lft forever preferred_lft forever
2、基于两个网络创建 三个容器 web01、web02、web03
[root@al_lemon ~]# docker run -itd --name web01 --network=bridge busybox:latest
76b5b2aafc829a0a21fad02b23f3b301571dbb007b478c98f701b40c8e720eea
[root@al_lemon ~]# docker run -itd --name web02 --network=my_net01 busybox:latest
c06fc02d0a666b1e6ca9dce5f73c090ca57da642cd41c13f8685772729dea49b
[root@al_lemon ~]# docker run -itd --name web03 --network=my_net01 busybox:latest
e3e5b535f2f5c3ee64b2a37027020e275a5daccc71795340e90a8e98b661fbb5
3、查看这三个容器的 IP 地址
[root@al_lemon ~]# docker exec -it web01 ip a|grep "eth0"
33: eth0@if34: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
[root@al_lemon ~]# docker exec -it web02 ip a|grep "eth0"
35: eth0@if36: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
inet 192.168.10.1/24 brd 192.168.10.255 scope global eth0
[root@al_lemon ~]# docker exec -it web03 ip a|grep "eth0"
37: eth0@if38: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
inet 192.168.10.2/24 brd 192.168.10.255 scope global eth0
开始测试网络的连通性
1、web02 能否与 web03 互相通信?
[root@al_lemon ~]# docker exec -it web02 ping -c 3 192.168.10.2
PING 192.168.10.2 (192.168.10.2): 56 data bytes
64 bytes from 192.168.10.2: seq=0 ttl=64 time=0.120 ms
64 bytes from 192.168.10.2: seq=1 ttl=64 time=0.089 ms
64 bytes from 192.168.10.2: seq=2 ttl=64 time=0.101 ms
[root@al_lemon ~]# docker exec -it web03 ping -c 3 192.168.10.1
PING 192.168.10.1 (192.168.10.1): 56 data bytes
64 bytes from 192.168.10.1: seq=0 ttl=64 time=0.101 ms
64 bytes from 192.168.10.1: seq=1 ttl=64 time=0.101 ms
64 bytes from 192.168.10.1: seq=2 ttl=64 time=0.108 ms
# 答案 : 是可以的。因为他们两个是用的同一个网络创建出来的!!
2、思考 : web01 能否与 web02、web03通信呢?
[root@al_lemon ~]# docker exec -it web01 ping -c 3 192.168.10.1
PING 192.168.10.1 (192.168.10.1): 56 data bytes
[root@al_lemon ~]# docker exec -it web01 ping -c 3 192.168.10.2
PING 192.168.10.2 (192.168.10.2): 56 data bytes
# 答案 : 是不可以的。因为web01是基于my_net01创建的,而web02 和 web03 是基于默认的bridge创建的!!
3、那为什么会这样呢?来看看iptables
[root@al_lemon ~]# iptables-save
……
-A DOCKER -i docker1 -j RETURN
-A DOCKER -i docker0 -j RETURN
……
# 原因就在这里了:iptables DROP 掉了网桥 docker0 与 docker1 之间双向的流量。
# 从规则的命名 DOCKER-ISOLATION 可知 docker 在设计时就是要隔离不同的 netwrok。
4、那么接下来的问题是:怎样才能让 172.18.0.0 与 192.168.10.0不同的网段通信呢?
# 答案 : 给 172.18.0.0 的容器里(web01)也添加一块 my_net01 的网卡。
[root@al_lemon ~]# docker network connect my_net01 web01
# 回到容器中查看一下网络配置
[root@al_lemon ~]# docker exec -it web01 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
33: eth0@if34: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
valid_lft forever preferred_lft forever
39: eth1@if40: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:c0:a8:0a:03 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.3/24 brd 192.168.10.255 scope global eth1
valid_lft forever preferred_lft forever
# 可以看到多了一块网卡eth1@if40,现在再试试与另外两个容器通信看
[root@al_lemon ~]# docker exec -it web01 ping -c 3 192.168.10.1
PING 192.168.10.1 (192.168.10.1): 56 data bytes
64 bytes from 192.168.10.1: seq=0 ttl=64 time=0.120 ms
64 bytes from 192.168.10.1: seq=1 ttl=64 time=0.120 ms
64 bytes from 192.168.10.1: seq=2 ttl=64 time=0.095 ms
[root@al_lemon ~]# docker exec -it web01 ping -c 3 192.168.10.2
PING 192.168.10.2 (192.168.10.2): 56 data bytes
64 bytes from 192.168.10.2: seq=0 ttl=64 time=0.117 ms
64 bytes from 192.168.10.2: seq=1 ttl=64 time=0.101 ms
64 bytes from 192.168.10.2: seq=2 ttl=64 time=0.090 ms
# 完美解决
5、但是思考一个问题,另外两个容器能否可以与web01通信呢?
[root@al_lemon ~]# docker exec -it web02 ping -c 3 172.18.0.2
PING 172.18.0.2 (172.18.0.2): 56 data bytes
[root@al_lemon ~]# docker exec -it web03 ping -c 3 172.18.0.3
PING 172.18.0.3 (172.18.0.3): 56 data bytes
# 答案 : 是不能的。因为这两个容器是没有bridge这个网络的,所以无法通信!!!
# 想要通信的话,就按照上面的操作再把bridge的网络加入的这两个容器中就可以了!!!
6. 容器通信的两种方式
IP 通信
两个容器要能通信,必须要有属于同一个网络的网卡。
[root@al_lemon ~]# docker run -itd --name web01 busybox:latest
f1cfbd4daf3e72307cb4e8191a915f75f260c2a37913d3e69faff80ef1bbd0fa
[root@al_lemon ~]# docker run -itd --name web02 busybox:latest
03f1b728dc770121b7a9fe3474aa7fa6be5ef1ed1eb05fc9629e847e3334eca5
[root@al_lemon ~]# docker exec -it web01 ip a|grep eth0
22: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
[root@al_lemon ~]# docker exec -it web02 ip a|grep eth0
24: eth0@if25: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
inet 172.18.0.3/16 brd 172.18.255.255 scope global eth0
[root@al_lemon ~]# docker exec -it web01 ping -c 3 172.18.0.3
PING 172.18.0.3 (172.18.0.3): 56 data bytes
64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.111 ms
64 bytes from 172.18.0.3: seq=1 ttl=64 time=0.106 ms
64 bytes from 172.18.0.3: seq=2 ttl=64 time=0.098 ms
[root@al_lemon ~]# docker exec -it web02 ping -c 3 172.18.0.2
PING 172.18.0.2 (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.103 ms
64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.098 ms
64 bytes from 172.18.0.2: seq=2 ttl=64 time=0.103 ms
DNS Server 通信
通过 IP 访问容器虽然满足了通信的需求,但还是不够灵活。
因为在部署应用之前可能无法确定 IP,部署之后再指定要访问的 IP 会比较麻烦。
对于这个问题,可以通过 docker 自带的 DNS 服务解决。
从 Docker 1.10 版本开始,docker daemon 实现了一个内嵌的 DNS server,使容器可以直接通过“容器名”通信。
方法很简单,只要在启动时用 --name 为容器命名就可以了。
1、启动两个容器 bbox1 和 bbox2
[root@al_lemon ~]# docker run -itd --network=my_net01 --name=bbox1 busybox:latest
[root@al_lemon ~]# docker run -itd --network=my_net01 --name=bbox2 busybox:latest
2、测试能否使用hostname进行通信
[root@al_lemon ~]# docker exec -it bbox1 ping -c 2 bbox2
PING bbox2 (192.168.10.5): 56 data bytes
64 bytes from 192.168.10.5: seq=0 ttl=64 time=0.096 ms
64 bytes from 192.168.10.5: seq=1 ttl=64 time=0.113 ms
[root@al_lemon ~]# docker exec -it bbox2 ping -c 2 bbox1
PING bbox1 (192.168.10.4): 56 data bytes
64 bytes from 192.168.10.4: seq=0 ttl=64 time=0.063 ms
64 bytes from 192.168.10.4: seq=1 ttl=64 time=0.102 ms
# 答案 : 是可以的!!!
3、原理其实将对应的容器IP/ID加入到了hosts文件
[root@al_lemon ~]# docker exec -it bbox1 cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.10.4 4b72d8bc0bee
但是注意:
- 使用 docker DNS 有个限制,只能在 user-defined 网络中使用。
- 也就是说,默认的 bridge 网络是无法使用 DNS 的 !!!
下面验证一下:
1、使用docker默认的bridge网络创建bbox3、bbox4容器
[root@al_lemon ~]# docker run -itd --name=bbox3 --network=bridge busybox:latest
[root@al_lemon ~]# docker run -itd --name=bbox4 --network=bridge busybox:latest
2、测试docker默认的bridge网络能否使用hostname进行通信
[root@al_lemon ~]# docker exec -it bbox3 ping -c 2 bbox4
ping: bad address 'bbox4'
[root@al_lemon ~]# docker exec -it bbox4 ping -c 2 bbox3
ping: bad address 'bbox3'
#答案 : 是不能的
7. 容器如何访问的外部世界
容器访问外部世界(nat的源地址转换)
注意:这里说的是同一台主机不同容器之间的通信;而不是跨主机的容器通信!
在当前的实验环境下,docker host 是可以访问外网的。
[root@al_lemon ~]# ping -c 3 www.baidu.com
PING www.a.shifen.com (220.181.38.149) 56(84) bytes of data.
64 bytes from 220.181.38.149 (220.181.38.149): icmp_seq=1 ttl=54 time=5.26 ms
64 bytes from 220.181.38.149 (220.181.38.149): icmp_seq=2 ttl=54 time=5.24 ms
64 bytes from 220.181.38.149 (220.181.38.149): icmp_seq=3 ttl=54 time=5.26 ms
现在来看一下容器是否也能访问外网呢?
[root@al_lemon ~]# docker run -it busybox:latest
/ # ping -c 3 www.baidu.com
PING www.baidu.com (220.181.38.150): 56 data bytes
64 bytes from 220.181.38.150: seq=0 ttl=53 time=5.671 ms
64 bytes from 220.181.38.150: seq=1 ttl=53 time=5.734 ms
64 bytes from 220.181.38.150: seq=2 ttl=53 time=5.720 ms
# 可见,容器默认就能访问外网!!!
# 这里外网指的是容器网络以外的网络环境,并非特指 internet。
现象很简单,但更重要的是应该理解现象下的本质。
在上面的例子中,busybox 位于 docker0 这个私有 bridge 网络中(172.18.0.0/16),当 busybox 从容器向外 ping 时,数据包是怎样到达 baidu.com 的呢?
这里的关键就是 NAT。我们查看一下 docker host 上的 iptables 规则:
[root@al_lemon ~]# iptables -t nat -S
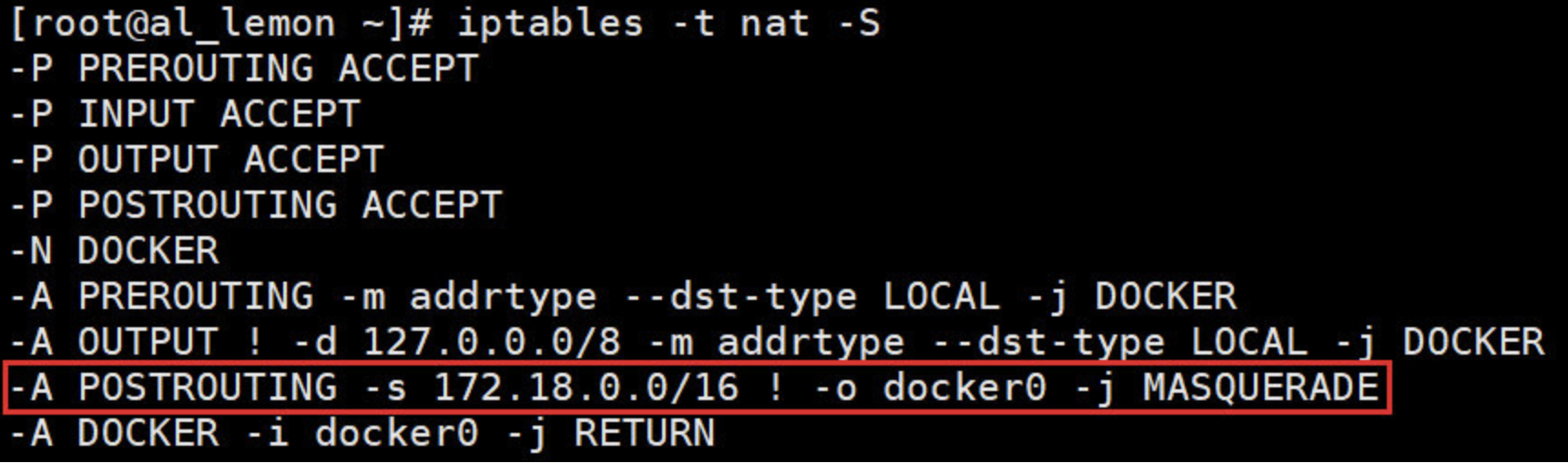
在 NAT 表中,有这么一条规则:
-A POSTROUTING -s 172.18.0.0/16 ! -o docker0 -j MASQUERADE
其含义是:来自 172.18.0.0/16 网段的包, 如果目标地址是外网 (! -o docker0) , 就把它交给 MASQUERADE 处理。
而 MASQUERADE 的处理方式是将包的源地址替换成 host 的地址发送出去, 即做了一次网络地址转换(NAT)。
-
SNAT:用于外网IP固定不变的
-
MASQUERADE:用于外网IP地址不固定的
下面通过 tcpdump 查看地址是如何转换的。
首先来查看 docker host 的路由表:

默认路由通过 eth0 发出去,所以要同时监控 eth0 和 docker0 上的 icmp(ping)数据包。
当 busybox ping baidu.com 时,tcpdump 输出如下:
/ # ping baidu.com
PING baidu.com (220.181.38.148): 56 data bytes
64 bytes from 220.181.38.148: seq=0 ttl=53 time=4.745 ms
64 bytes from 220.181.38.148: seq=1 ttl=53 time=4.726 ms
64 bytes from 220.181.38.148: seq=2 ttl=53 time=4.697 ms
……………………
[root@al_lemon ~]# tcpdump -i docker0 -n icmp

docker0 收到 busybox 的 ping 包,源地址为容器 IP 172.18.0.2,这没问题,交给 MASQUERADE 处理。
而这时,在 eth0 上看到了变化:
[root@al_lemon ~]# tcpdump -i eth0 -n icmp

ping 包的源地址变成了 eth0 的 IP 172.17.196.108 !!!
这就是 iptable NAT 规则处理的结果,从而保证数据包能够到达外网。
下面用一张网络图来说明这个过程:
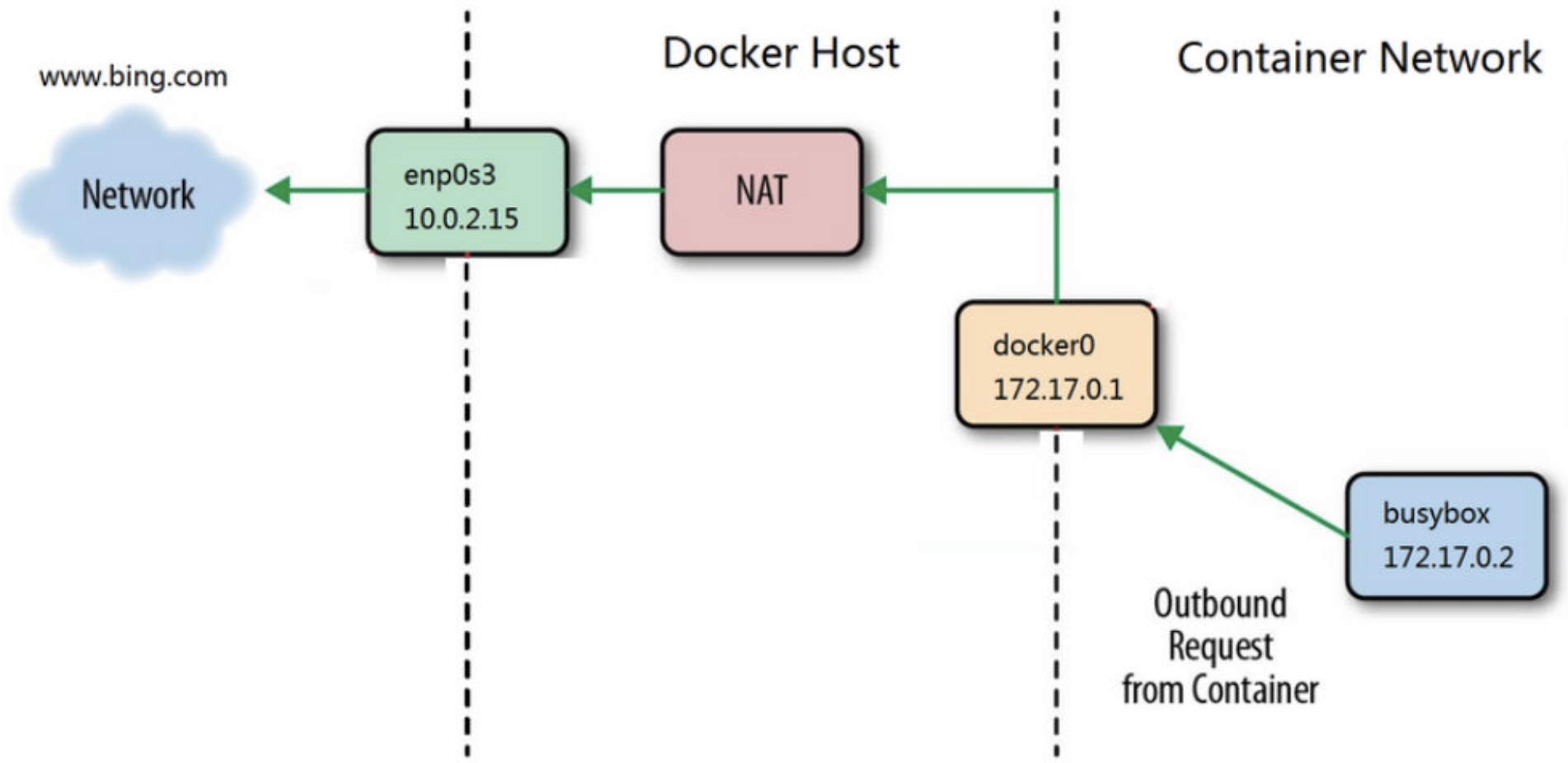
busybox 发送 ping 包:172.17.0.2 > www.bing.com。
docker0 收到包,发现是发送到外网的,交给 NAT 处理。
NAT 将源地址换成 enp0s3 的 IP:10.0.2.15 > www.bing.com。
ping 包从 enp0s3 发送出去,从而到达 www.bing.com。
所以容器是通过 NAT,docker 实现了容器对外网的访问。
8. 外部世界如何访问的容器
外部世界访问容器(docker-proxy的端口映射)
注意:这里说的是同一台主机不同容器之间的通信;而不是跨主机的容器通信!
docker 可将容器对外提供服务的端口映射到 host 的某个端口,外网通过该端口访问容器。
容器启动时通过 -p 或者 -P 参数映射端口:
[root@al_lemon ~]# docker run -d --name web -p 88:80 httpd:latest


除了指定映射端口,也可在 -p 中不指定映射host port到 host 某个特定端口,这种就属于动态映射端口。例如:
[root@al_lemon ~]# docker run -itd --name lemon -p 80 httpd:latest

每一个映射的端口,host 都会启动一个 docker-proxy 进程来处理访问容器的流量:

下面用一张网络图来说明这个过程:
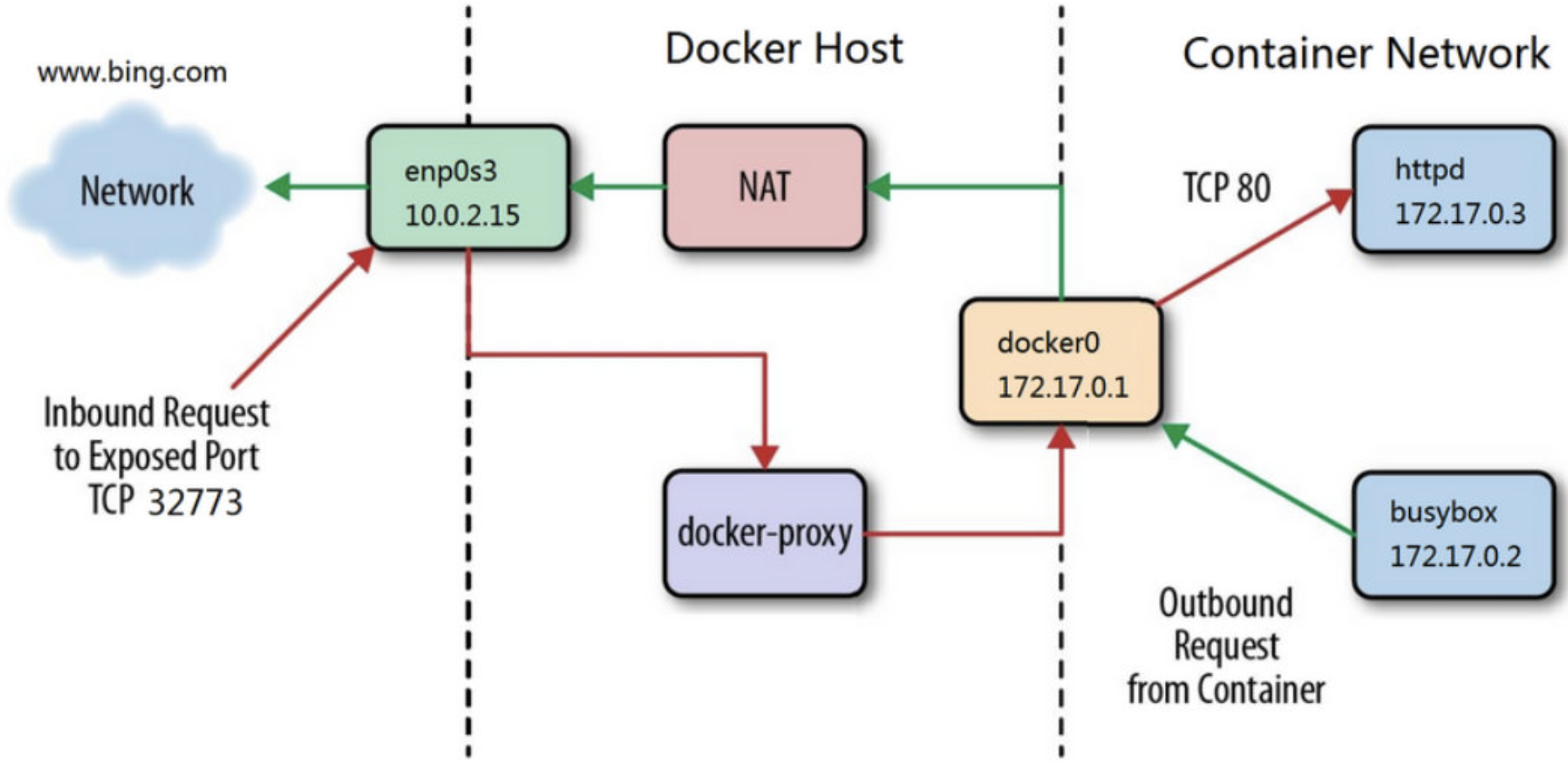
docker-proxy 监听 host 的 32773 端口。
当 curl 访问 10.0.2.15:32773 时,docker-proxy 会通过 docker0 转发给容器 172.17.0.2:80。
最终 httpd 容器响应请求并返回结果。
九、Docker 跨主机网络
前面已经学习了 Docker 的几种网络方案:none、host、bridge 和 joined 容器,它们解决了单个 Docker Host 内容器通信的问题。本章的重点则是讨论跨主机容器间通信的方案。
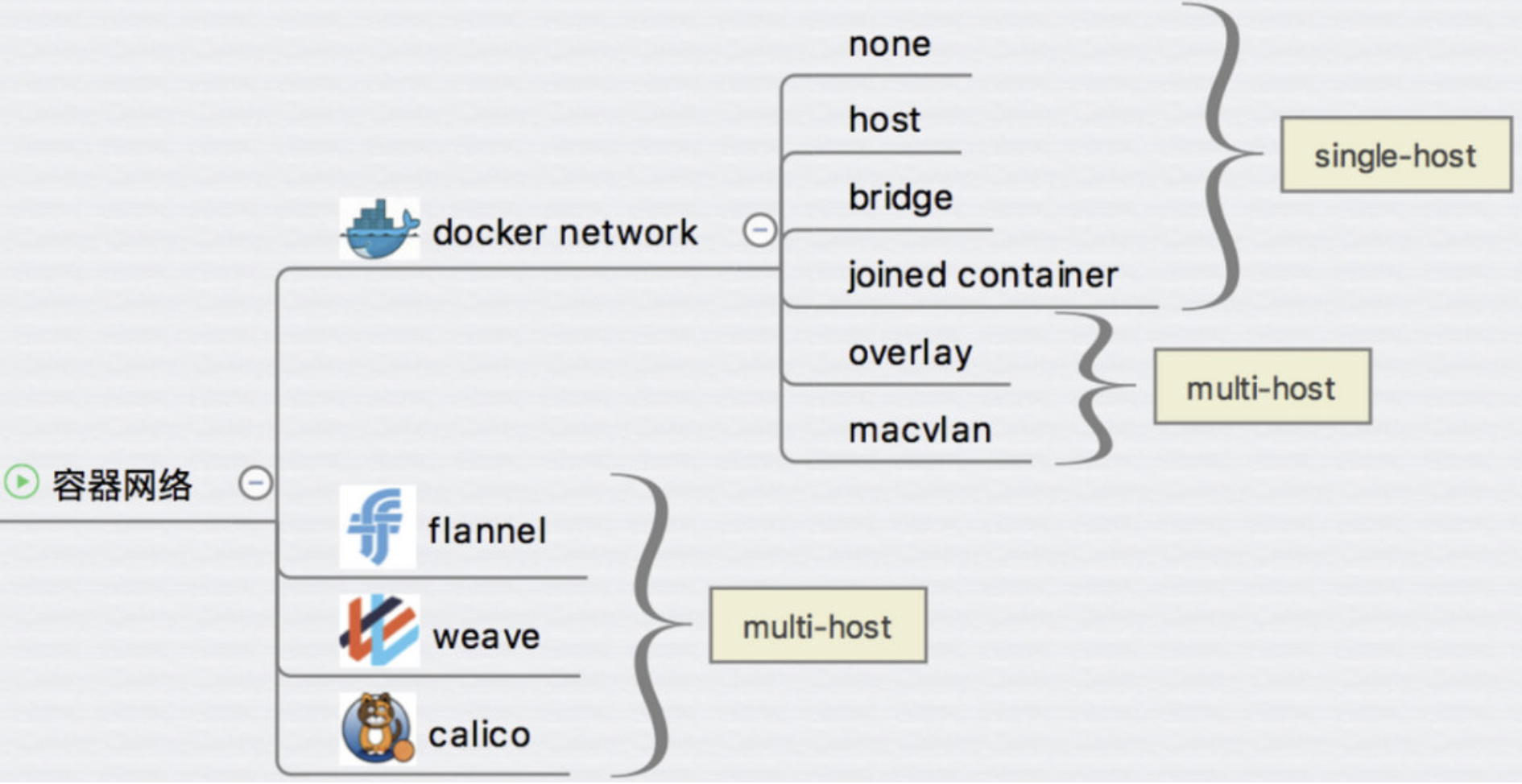
Overlay 和 macvlan属于不同主机之间的容器互相访问
跨主机网络方案包括
-
docker 原生的 overlay 和 macvlan。
-
第三方常用的包括 flannel、weave 和 calico。
docker 网络是一个非常活跃的技术领域,不断有新的方案开发出来,那么要问个非常重要的问题了
- 如此众多的方案是如何与 docker 集成在一起的?
- 答案是:libnetwork 以及 CNM。
1. libnetwork & CNM
libnetwork 是 docker 容器网络库,最核心的内容是其定义的 Container Network Model (CNM),这个模型对容器网络进行了抽象,由以下三类组件组成:
Sandbox(虚拟机交换机)
Sandbox 是容器的网络栈,包含容器的 interface、路由表和 DNS 设置。 Linux Network Namespace 是 Sandbox 的标准实现。Sandbox 可以包含来自不同 Network 的 Endpoint。
Endpoint(容器的网络驱动)
Endpoint 的作用是将 Sandbox 接入 Network。Endpoint 的典型实现是 veth pair,后面我们会举例。一个 Endpoint 只能属于一个网络,也只能属于一个 Sandbox。
Network(docker网络驱动)
Network 包含一组 Endpoint,同一 Network 的 Endpoint 可以直接通信。Network 的实现可以是 Linux Bridge、VLAN 等。
下面是 CNM 的示例:
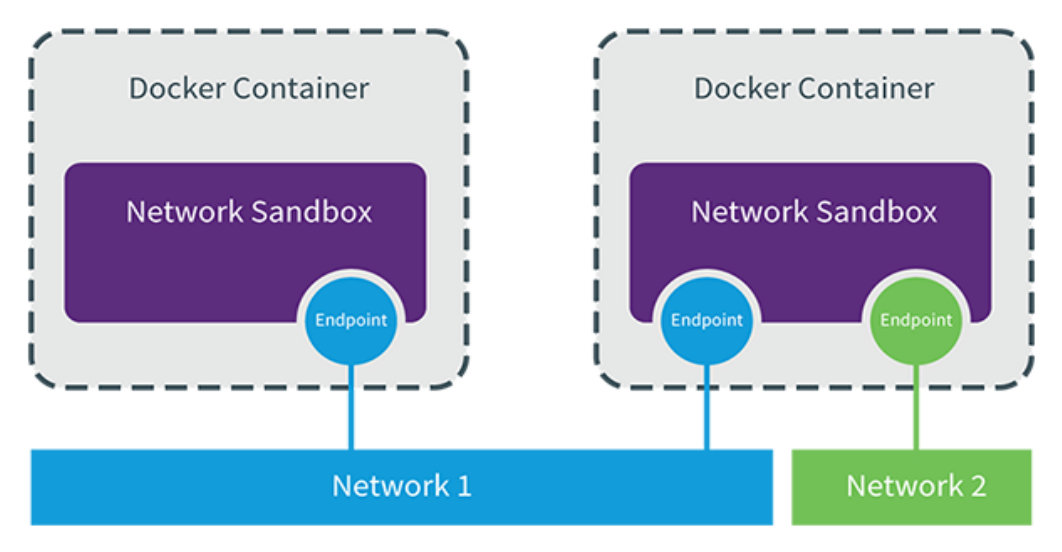
如图所示两个容器, 一个容器一个 Sandbox, 每个 Sandbox 都有一个 Endpoint 连接到 Network 1,第一个容器的第二个 Sandbox 的 Endpoint 将其接入 Network 2。
libnetwork CNM 定义了 docker 容器的网络模型,按照该模型开发出的 driver 就能与 docker daemon 协同工作,实现容器网络。
docker 原生的 driver 包括 none、bridge、host、overlay 和 macvlan,第三方 driver 包括 flannel、weave、calico 等。

2. overlay网络
概述:为支持容器跨主机通信,Docker 提供了 overlay driver,使用户可以创建基于 VxLAN 的 overlay 网络。VXLAN 可将二层数据封装到 UDP 进行传输,VXLAN 提供与 VLAN 相同的以太网二层服务,但是拥有更强的扩展性和灵活性。
overlay 网络驱动程序在多个 Docker 守护进程主机之间创建一个分布式网络。这个网络在允许容器连接并进行安全通信的主机专用网络之上(overlay 覆盖在上面)。Docker 透明地处理每个 Docker 守护进程与目标容器之间的数据包的路由。
Docker通过Overlay网络驱动程序支持多主机容器网络通信。要想使用Docker原生Overlay网络,需要满足以下任意条件:
- Docker运行在Swarm模式
- 使用键值存储的Docker主机集群
这里我选择第二种方式,需满足以下条件:
1)集群中主机连接到键值存储,Docker支持Consul、Etcd和Zookeeper
2)集群中主机运行一个Docker守护进程
3)集群中主机必须具有唯一的主机名,因为键值存储使用主机名来标识集群成员
4)集群中Linux主机内核版本3.10+,支持VXLAN数据包处理,否则可能无法通信
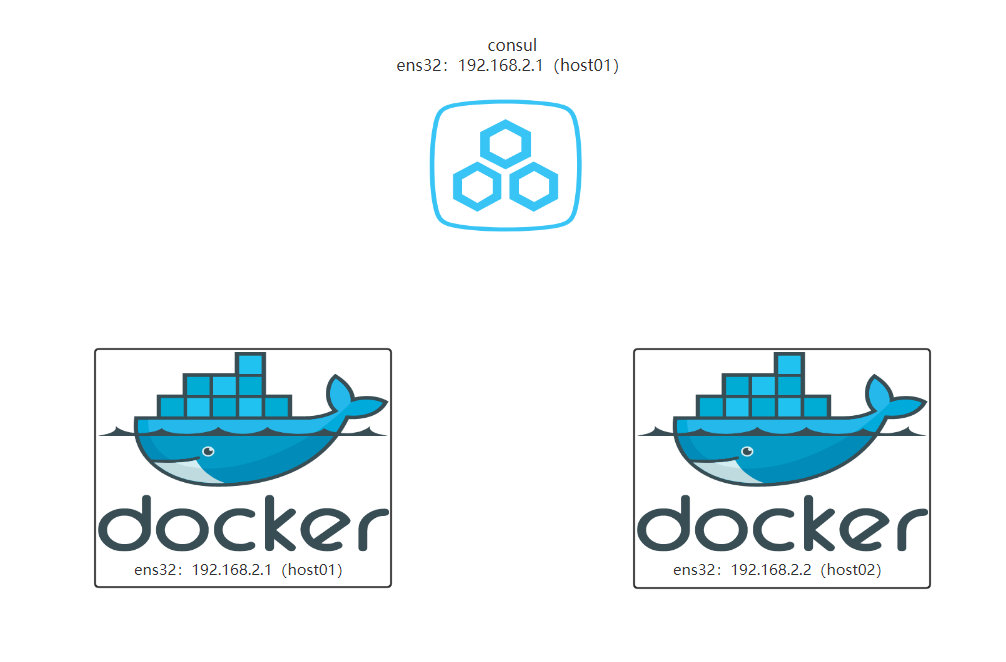
环境准备:
- 节点1:host01 192.168.2.1 键值存储
- 节点2:host02 192.168.2.2
整体架构
按道理是应该单独使用一个机器运行consul的,但这里为了节省机器,所以就和host01上部署了
实现过程:
1)在节点1上下载并安装consul
[root@host01 ~]# wget https://releases.hashicorp.com/consul/1.4.4/consul_1.4.4_linux_amd64.zip
[root@host01 ~]# unzip consul_1.4.4_linux_amd64.zip
[root@host01 ~]# mv consul /usr/bin/
[root@host01 ~]# chmod +x /usr/bin/consul
2)在节点1上启动consul服务
[root@host01 ~]# setsid consul agent -server -bootstrap -ui -data-dir /var/lib/consul \
-client=192.168.2.1 -bind=192.168.2.1 &>/var/log/consul.log
3)查看是否在后台运行
[root@host01 ~]# netstat -anptu|grep LISTEN|grep consul
tcp 0 0 192.168.2.1:8300 0.0.0.0:* LISTEN 1449/consul
tcp 0 0 192.168.2.1:8301 0.0.0.0:* LISTEN 1449/consul
tcp 0 0 192.168.2.1:8302 0.0.0.0:* LISTEN 1449/consul
tcp 0 0 192.168.2.1:8500 0.0.0.0:* LISTEN 1449/consul
tcp 0 0 192.168.2.1:8600 0.0.0.0:* LISTEN 1449/consul
[root@host01 ~]# ps -aux|grep consul
root 1449 0.1 3.5 175596 35304 ? Ssl 13:57 0:00 consul agent -server -bootstrap -ui -data-dir /var/lib/consul -client=192.168.2.1 -bind=192.168.2.1
4)修改集群上的docker守护进程(配置相同)
[root@host01 ~]# cat /usr/lib/systemd/system/docker.service|grep ExecStart
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --containerd=/run/containerd/containerd.sock --cluster-store=consul://192.168.2.1:8500 --cluster-advertise=ens32:2376
[root@host02 ~]# cat /usr/lib/systemd/system/docker.service|grep ExecStart
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --containerd=/run/containerd/containerd.sock --cluster-store=consul://192.168.2.1:8500 --cluster-advertise=ens32:2376
5)重启docker daemon
systemctl daemon-reload
systemctl restart docker
ps -ef|grep docker
root 16159 1 13 14:13 ? 00:00:00 /usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --containerd=/run/containerd/containerd.sock --cluster-store=consul://192.168.2.1:8500 --cluster-advertise=ens32:2376
6)到consul的UI界面查看节点是否添加
7)在docker主机上创建overlay网络
# 在 host01 中创建 overlay 网络 ov_net1:-d overlay 指定 driver 为 overaly。
[root@host01 ~]# docker network create -d overlay ov_net01
a83a1be396d606e5726bd69640465e1c473b18ab6dbb3d5e20d049e0bb6c9075
# 只需在集群中的其中一台docker主机上创建overlay网络即可,它会自动同步到另外一个节点上。
# 如果尝试到另外一个节点创建overlay网络,就会出现如下错误:
[root@host02 ~]# docker network create -d overlay ov_net01
Error response from daemon: network with name ov_net01 already exists
8)查看docker网络驱动
# local : 本地的
# global : 全球的
[root@host01 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
34b14fdbd9a4 bridge bridge local
5eace2ef6bca host host local
f4b2e8b03d3b none null local
a83a1be396d6 ov_net01 overlay global
[root@host02 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
26846ddafd85 bridge bridge local
761eec3c9f6f host host local
388d9ea974c1 none null local
a83a1be396d6 ov_net01 overlay global
9)查看 ov_net01 的详细信息
[root@host01 ~]# docker network inspect ov_net01
# IPAM 是指 IP Address Management,docker 自动为 ov_net01 分配的 IP 空间为 10.0.0.0/24
[
{
"Name": "ov_net01",
"Id": "a83a1be396d606e5726bd69640465e1c473b18ab6dbb3d5e20d049e0bb6c9075",
"Created": "2020-08-23T14:48:41.746822712+08:00",
"Scope": "global",
"Driver": "overlay",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "10.0.0.0/24",
"Gateway": "10.0.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
10)基于ov_net01网络创建容器
[root@host01 ~]# docker run -it -d --name bbox1 --network ov_net01 busybox
11)查看bbox1容器的网络信息
[root@host01 ~]# docker exec -it bbox1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
7: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:00:00:02 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.2/24 brd 10.0.0.255 scope global eth0
valid_lft forever preferred_lft forever
10: eth1@if11: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth1
valid_lft forever preferred_lft forever
# 分析:
bbox1 有两个网络接口 eth0 和 eth1。eth0 IP 为 10.0.0.2,连接的是 overlay 网络 ov_net01。eth1 IP 172.18.0.2,容器的默认路由是走 eth1,eth1 是哪儿来的呢?
# 答案:
其实,docker 会创建一个 bridge 网络 “docker_gwbridge”,为所有连接到 overlay 网络的容器提供访问外网的能力。说白了就是访问外网时用的是docker_gwbridge网络,容器互相访问时就是用的overlay网络。
[root@host01 ~]# docker network inspect docker_gwbridge
# 从输出可确认 docker_gwbridge 的 IP 地址范围是 172.18.0.0/16,当前连接的容器就是 bbox1(172.18.0.2)。
[
{
"Name": "docker_gwbridge",
"Id": "8407946e9aae50ec3473854aa8e2e75b7b45e2fcdeabc97375f7433a956aa8ae",
"Created": "2020-08-23T15:00:08.278899583+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"afa9bd135a3c61736a8a92a95dbe1f85a3b886bffcb4f467ef87b5e80de91b6d": {
"Name": "gateway_47294494fa93",
"EndpointID": "37b03272bf9a0e3daf64ec325d38f5d9eff7d1f01a06a95e2ddd7304b7fdf72b",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.enable_icc": "false",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.name": "docker_gwbridge"
},
"Labels": {}
}
]
11)测试能否跨主机通信
# 在 host02 中运行容器 bbox2
[root@host02 ~]# docker run -it -d --name bbox2 --network ov_net01 busybox
54ac14b698c9ba9cb4f79496341549470ee0d984678ae4c9b1b04cb16867b4f7
# 查看bbox2网络信息
[root@host02 ~]# docker exec -it bbox2 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
7: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:00:00:03 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.3/24 brd 10.0.0.255 scope global eth0
valid_lft forever preferred_lft forever
10: eth1@if11: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth1
valid_lft forever preferred_lft forever
# bbox2 IP 为 10.0.0.3,可以直接 ping bbox1
[root@host02 ~]# docker exec -it bbox2 ping -c 3 10.0.0.2
PING 10.0.0.2 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: seq=0 ttl=64 time=6.454 ms
64 bytes from 10.0.0.2: seq=1 ttl=64 time=0.639 ms
64 bytes from 10.0.0.2: seq=2 ttl=64 time=0.253 ms
--- 10.0.0.2 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.253/2.448/6.454 ms
# bbox1 IP 为 10.0.0.2,可以直接 ping bbox2
[root@host01 ~]# docker exec -it bbox1 ping -c 3 10.0.0.3
PING 10.0.0.3 (10.0.0.3): 56 data bytes
64 bytes from 10.0.0.3: seq=0 ttl=64 time=6.093 ms
64 bytes from 10.0.0.3: seq=1 ttl=64 time=0.701 ms
64 bytes from 10.0.0.3: seq=2 ttl=64 time=0.733 ms
--- 10.0.0.3 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.701/2.509/6.093 ms
12)测试能否和外网通信
[root@host01 ~]# docker exec -it bbox1 ping -c 3 www.baidu.com
PING www.baidu.com (182.61.200.6): 56 data bytes
64 bytes from 182.61.200.6: seq=0 ttl=50 time=31.233 ms
64 bytes from 182.61.200.6: seq=1 ttl=50 time=32.877 ms
64 bytes from 182.61.200.6: seq=2 ttl=50 time=30.466 ms
--- www.baidu.com ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 30.466/31.525/32.877 ms
[root@host02 ~]# docker exec -it bbox2 ping -c 3 www.baidu.com
PING www.baidu.com (182.61.200.6): 56 data bytes
64 bytes from 182.61.200.6: seq=0 ttl=50 time=39.688 ms
64 bytes from 182.61.200.6: seq=1 ttl=50 time=33.263 ms
64 bytes from 182.61.200.6: seq=2 ttl=50 time=33.584 ms
--- www.baidu.com ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 33.263/35.511/39.688 ms
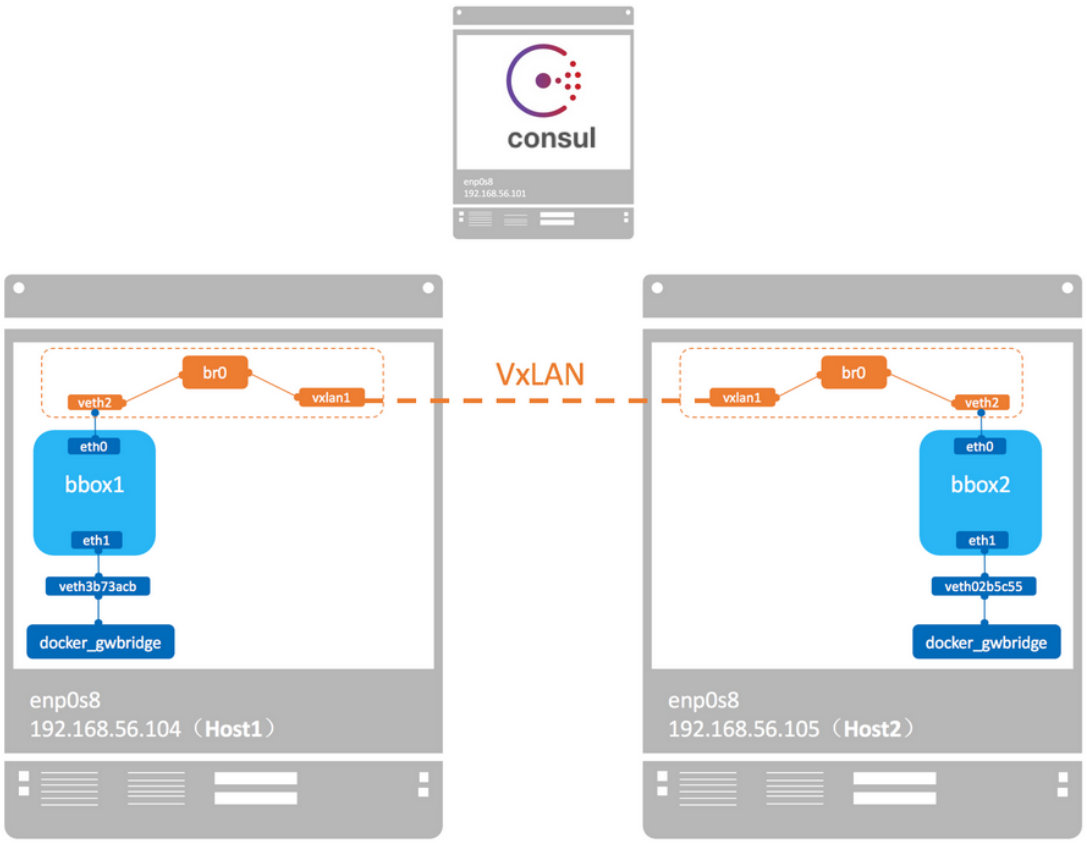
overlay 网络的具体实现
docker 会为每个 overlay 网络创建一个独立的 network namespace,其中会有一个 linux bridge br0,endpoint 还是由 veth-pair 实现,一端连接到容器中(即 eth0),另一端连接到 namespace 的 br0 上。
br0 除了连接所有的 endpoint,还会连接一个 vxlan 设备,用于与其他 host 建立 vxlan tunnel。容器之间的数据就是通过这个 tunnel 通信的。
逻辑网络拓扑结构如图所示:
要查看 overlay 网络的 namespace 可以在 host01 和 host02 上执行 ip netns(请确保在此之前执行过 ln -s /var/run/docker/netns /var/run/netns),可以看到两个 host 上有一个相同的 namespace “1-a83a1be396”
[root@host01 ~]# ip netns
47294494fa93 (id: 1)
1-a83a1be396 (id: 0)
[root@host02 ~]# ip netns
f9a284c0f94e (id: 1)
1-a83a1be396 (id: 0)
这就是 ov_net01 的 namespace,查看 namespace 中的 br0 上的设备。
[root@host01 ~]# ip netns exec 1-a83a1be396 brctl show
bridge name bridge id STP enabled interfaces
br0 8000.82eda6360e4d no veth0
vxlan0
overlay 是如何隔离的?
不同的 overlay 网络是相互隔离的。我们创建第二个 overlay 网络 ov_net02 并在host02上使用ov_net02网络运行容器 bbox3。
[root@host02 ~]# docker network create -d overlay ov_net02
[root@host02 ~]# docker network create -d overlay ov_net02
f11ddee04e3a3204dfdf545e5ec5674625a1c95c4b4cda974c280f599998068b
[root@host02 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
26846ddafd85 bridge bridge local
e2be38b12708 docker_gwbridge bridge local
761eec3c9f6f host host local
388d9ea974c1 none null local
a83a1be396d6 ov_net01 overlay global
f11ddee04e3a ov_net02 overlay global
[root@host02 ~]# docker run -it -d --name bbox3 --network ov_net02 busybox
# bbox3 分配到的 IP 是 10.0.1.2,尝试 ping bbox1(10.0.0.2)。
[root@host02 ~]# docker exec -it bbox3 ip a|grep 10.0.1
inet 10.0.1.2/24 brd 10.0.1.255 scope global eth0
[root@host02 ~]# docker exec -it bbox3 ping -c 3 10.0.0.2
PING 10.0.0.2 (10.0.0.2): 56 data bytes
--- 10.0.0.2 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
# ping 失败,可见不同 overlay 网络之间是隔离的。即便是通过 docker_gwbridge 也不能通信。注:但可以与外网通信
# 如果要实现 bbox3 与 bbox1 通信,可以将 bbox3 也连接到 ov_net1。
[root@host02 ~]# docker network connect ov_net01 bbox3
[root@host02 ~]# docker exec -it bbox3 ip a|grep 10.0
inet 10.0.1.2/24 brd 10.0.1.255 scope global eth0
inet 10.0.0.4/24 brd 10.0.0.255 scope global eth2
overlay IPAM
docker 默认为 overlay 网络分配 24 位掩码的子网(10.0.X.0/24),所有主机共享这个 subnet,容器启动时会顺序从此空间分配 IP。当然我们也可以通过--subnet指定 IP 空间。
例如:
docker network create -d overlay --subnet 192.168.10.0/24 --gateway 192.168.10.254 ov_net03
docker network inspect ov_net03
[
{
"Name": "ov_net03",
"Id": "b3abd53f700440af71d9e0cbb347ea9658acd66d263087ac08a904fd2a4cddd2",
"Created": "2020-08-23T15:37:27.660703548+08:00",
"Scope": "global",
"Driver": "overlay",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "192.168.10.0/24",
"Gateway": "192.168.10.254"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
综上,overlay网络的拓补如下:
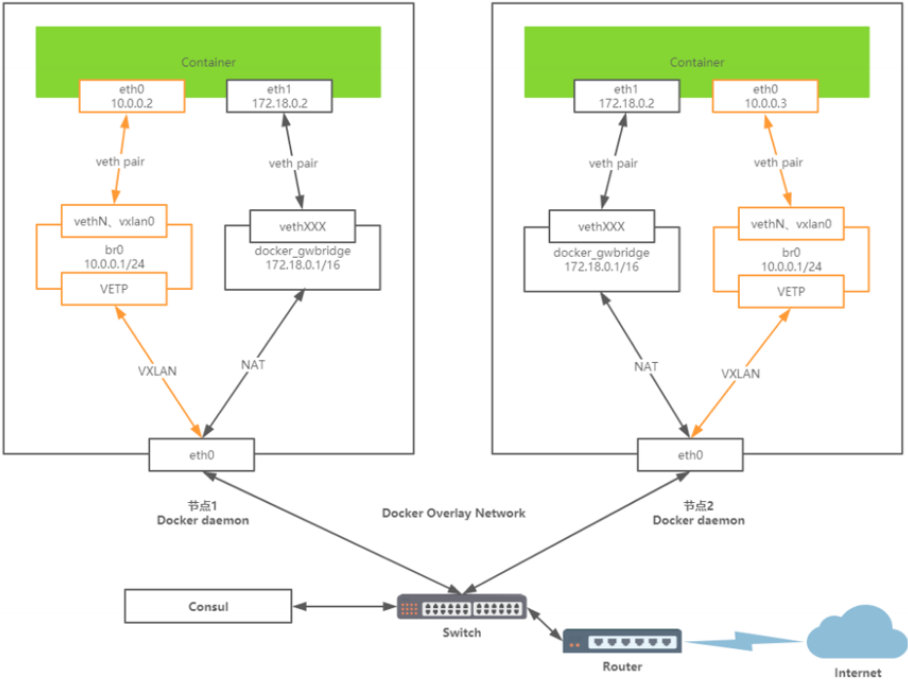
这里数据包的发送流程如下(以从左侧的容器发送到右侧的容器为例):
- 容器Container1会通过Container eth0 将这个数据包发送到 10.0.0.1 的网关。
- 网关将数据包发送出去后到达br0网桥。
- br0网桥针对VXLAN设备,主要用于捕获对外的数据包通过VETP进行数据包封装。
- 封装好将VXLAN格式数据包交给eth0,通过UDP方式交给Container2的eth0。
- Container2收到数据包后通过VETP将数据包解封装。
- 网桥通过网关将解封装的数据包转发给Container eth0,完毕通信。
因此,Docker容器的overlay网络的实现原理是:
-
docker会为每个overlay网络创建个单独的命名空间,在这个命名空间里创建了个br0的bridge。
-
在这个命名空间内创建两张网卡并挂载到br0上,创建一对veth pair端口 和vxlan设备。
-
veth pair一端接在namespace的br0上,另一端接在container上。
-
vxlan设备用于建立vxlan tunnel,vxlan端口的vni由docker-daemon在创建时分配,具有相同vni的设备才能通信。
-
docker主机集群通过key/value存储(我们这里用的是consul)共享数据,在7946端口上,相互之间通过gossip协议学习各个宿主机上运行了哪些容器。守护进程根据这些数据来在vxlan设备上生成静态MAC转发表。
-
vxlan设备根据静态mac转发表,通过host上的4789端口将数据发到目标节点。
-
根据流量包中的vxlan隧道ID,将流量转发到对端宿主机的overlay网络的网络命名空间中。
-
对端宿主机的overlay网络的网络命名空间中br0网桥,起到虚拟交换机的作用,将流量根据MAC地址转发到对应容器内部。
上述原理分析部分参考:https://www.bladewan.com/2017/11/17/docker_network_overlay/
补充:如需详细了解docker overlay网络的实现过程,可以参考:http://chenchun.github.io/docker/2015/12/29/km-docker-overlay
3. flannel网络
flannel 是 CoreOS 开发的容器网络解决方案。flannel 为每个 host 分配一个 subnet,容器从此 subnet 中分配 IP,这些 IP 可以在 host 间路由,容器间无需 NAT 和 port mapping 就可以跨主机通信。flannel 没有提供隔离。
Flannel实质上是一种“覆盖网络(overlay network)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持UDP、VxLAN、AWS VPC和GCE路由等数据转发方式。
数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
Flannel通过Etcd服务维护了一张节点间的路由表,详细记录了各节点子网网段 。
源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一下的有docker0路由到达目标容器。
默认的节点间数据通信方式是UDP转发。
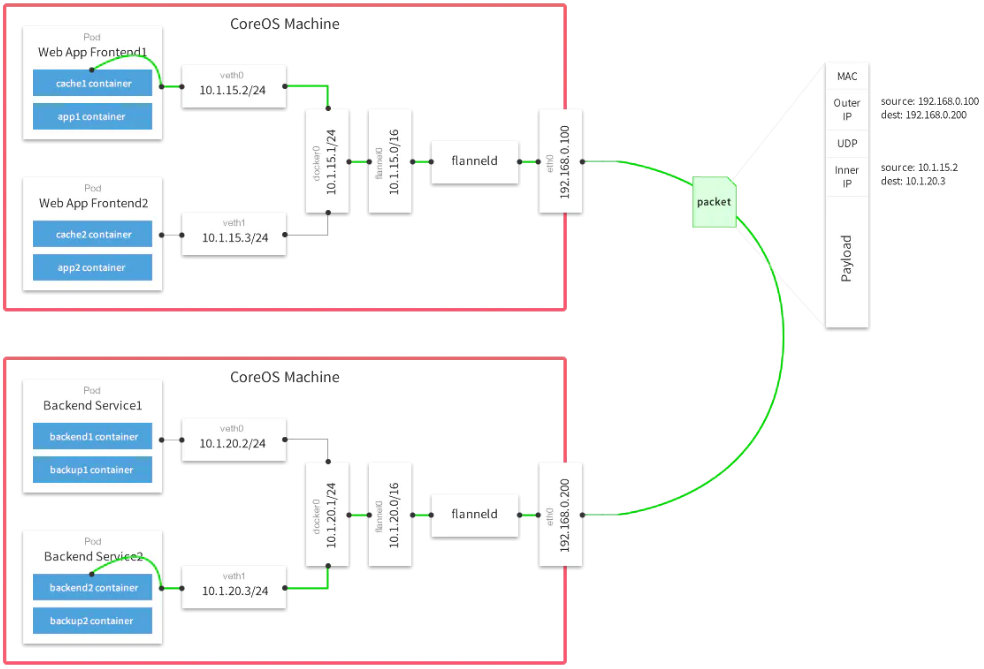
接下来就开始实践 flannel。
环境准备:
| 主机名 | IP地址 | 角色 |
|---|---|---|
| host01 | 192.168.2.1 | docker,flannel |
| host02 | 192.168.2.2 | docker,flannel |
| etcd | 192.168.2.3 | etcd |
在此之前,先将之前ovelay的环境清理一下(host2也要执行)
-
docker rm -f $(docker ps -qa)
-
docker network rm docker_gwbridge
-
将--cluster-store= 和 --cluster-advertise=删除 然后重启docker daemon
1、安装配置 etcd
[root@etcd ~]# mkdir -p /tmp/test-etcd
[root@etcd ~]# tar xf etcd-v2.3.7-linux-amd64.tar.gz -C /tmp/test-etcd/ --strip-components=1
# 该脚本从 github 上下载 etcd 的可执行文件并保存到 /usr/local/bin/,启动 etcd 并打开 2379 监听端口。
[root@etcd ~]# cp /tmp/test-etcd/etcd* /usr/local/bin/
[root@etcd ~]# setsid etcd -listen-client-urls http://192.168.2.3:2379 -advertise-client-urls http://192.168.2.3:2379
[root@etcd ~]# netstat -anptu|grep 2379
tcp 0 0 192.168.2.3:2379 0.0.0.0:* LISTEN 1407/etcd
# 测试 etcd 是否可用:
[root@etcd ~]# etcdctl --endpoints=192.168.2.3:2379 set foo "bar"
bar
[root@etcd ~]# etcdctl --endpoints=192.168.2.3:2379 get foo
bar
可以正常在 etcd 中存取数据了, 接下来需要安装和配置 flannel。
2、在两台host上安装配置 flannel
// 安装flannel(host2相同操作)
# flannel同样托管在github,现在已经提供二进制安装包,一般不用自己编译。
[root@host1 ~]# wget https://github.com/coreos/flannel/releases/download/v0.10.0/flannel-v0.10.0-linux-amd64.tar.gz
[root@host1 ~]# tar -zxvf flannel-v0.10.0-linux-amd64.tar.gz
[root@host1 ~]# mv flanneld /usr/bin/
// 配置flannel
flannel默认会读取etcd数据库上key为/coreos.com/network/config的值,也可以通过--etcd-prefix指定key。该key保存的是一个json配置,支持的选项有:
Network (string):CIDR形式的网络地址。必须设置
SubnetLen (integer):子网尺寸,默认为24。可选项
SubnetMin (string):开始分配的最小子网。可选项
SubnetMax (string):可分配的最大子网。可选项
Backend (dictionary):指定数据转发的后端。
// 配置文件示例:在etcd主机上写好 flannel 网络的配置信息后保存到 etcd
# 先将配置信息写到文件 config.json 中,内容为:
[root@etcd ~]# vim config.json
{
"Network": "10.10.0.0/16", # Network 定义该网络的 IP 池为 10.10.0.0/16。
"SubnetLen": 24, # SubnetLen 指定每个主机分配到的 subnet 大小为 24 位,即10.10.X.0/24。
"Backend": { # Backend 为 vxlan,即主机间通过 vxlan 通信,后面我们还会讨论host-gw。
"Type": "vxlan"
}
}
// 将写好的配置存入 etcd
[root@etcd ~]# etcdctl --endpoints=192.168.2.3:2379 set /docker-test/network/config < config.json
{
"Network": "10.10.0.0/16",
"SubnetLen": 24,
"Backend": {
"Type": "vxlan"
}
}
// 启动 flannel,在 host1 和 host2 上执行如下命令
flanneld -etcd-endpoints=http://192.168.2.3:2379 -iface=ens32 -etcd-prefix=/docker-test/network
Host1 上输出如下:【想看输出的话,就使用setsid】
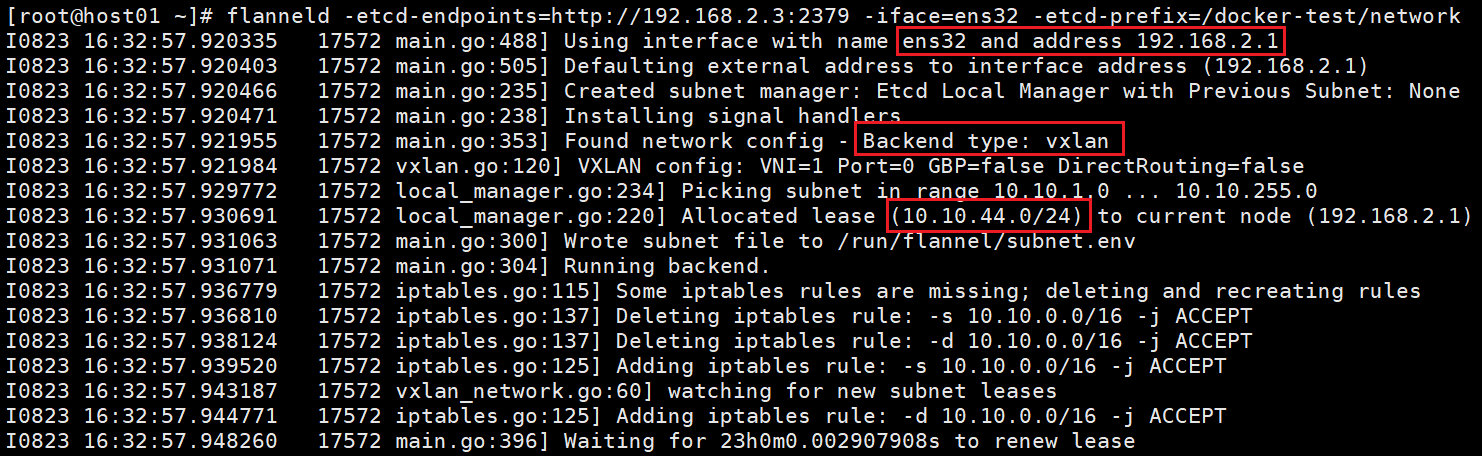
3、flanneld 启动后,host 内部网络会发生一些变化:
# 一个新的 interface flannel.1 被创建,而且配置上 subnet 的第一个 IP为 10.10.44.0。
[root@host01 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.10.44.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::e4ab:5ff:fe72:2cb9 prefixlen 64 scopeid 0x20<link>
ether e6:ab:05:72:2c:b9 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
# host1 添加了一条路由去往10.10.4.0/24的数据包从flannel.1出去
[root@host01 ~]# ip route
default via 192.168.1.1 dev ens34 proto static metric 100
10.10.4.0/24 via 10.10.4.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.1.0/24 dev ens34 proto kernel scope link src 192.168.1.101 metric 100
192.168.2.0/24 dev ens32 proto kernel scope link src 192.168.2.1 metric 100
# 再看host2主机,发现其IP为:10.10.4.0
[root@host02 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.10.4.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::8c4c:b5ff:fe7a:d1f5 prefixlen 64 scopeid 0x20<link>
ether 8e:4c:b5:7a:d1:f5 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
# 再看host2的路由,果然也添加了一条路由:10.10.44.0
[root@host02 ~]# ip route
default via 192.168.1.1 dev ens34 proto static metric 100
10.10.44.0/24 via 10.10.44.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.1.0/24 dev ens34 proto kernel scope link src 192.168.1.102 metric 100
192.168.2.0/24 dev ens32 proto kernel scope link src 192.168.2.2 metric 100
4、当前环境网络拓扑如图所示
5、在 Docker 中使用 flannel
配置 Docker 连接 flannel
编辑 host1 的 Docker 配置文件 /usr/lib/systemd/system/docker.service,设置 --bip 和 --mtu。
这两个参数的值必须与 /run/flannel/subnet.env 中 FLANNEL_SUBNET 和FLANNEL_MTU 一致。


# 重启 Docker daemon。
systemctl daemon-reload
systemctl restart docker.service
# Docker 会将 10.10.44.1 配置到 Linux bridge docker0 上,并添加 10.10.744.0/24 的路由。
[root@host01 ~]# ifconfig docker0 | grep netmask
inet 10.10.44.1 netmask 255.255.255.0 broadcast 10.10.44.255
[root@host01 ~]# ifconfig flannel.1|grep netmask
inet 10.10.44.0 netmask 255.255.255.255 broadcast 0.0.0.0
[root@host01 ~]# ip route
default via 192.168.1.1 dev ens34 proto static metric 100
10.10.4.0/24 via 10.10.4.0 dev flannel.1 onlink
10.10.44.0/24 dev docker0 proto kernel scope link src 10.10.44.1
192.168.1.0/24 dev ens34 proto kernel scope link src 192.168.1.101 metric 100
192.168.2.0/24 dev ens32 proto kernel scope link src 192.168.2.1 metric 100
# host02的配置与上面同理
在此省略……
6、当前环境网络拓扑如图所示
# 可见:flannel 没有创建新的 docker 网络,而是直接使用默认的 bridge docker0 网络。
# 同一主机的容器通过 docker0 连接,跨主机的容器通过 flannel.1 转发。
# 总结:flannel.1用于容器之间通信;docker0用于容器访问外网。
4、基于flannel网络创建容器
# 在 host1 中运行容器 bbox1:
docker run -itd --name bbox1 busybox
# 在 host2 中运行容器 bbox2:
docker run -itd --name bbox2 busybox
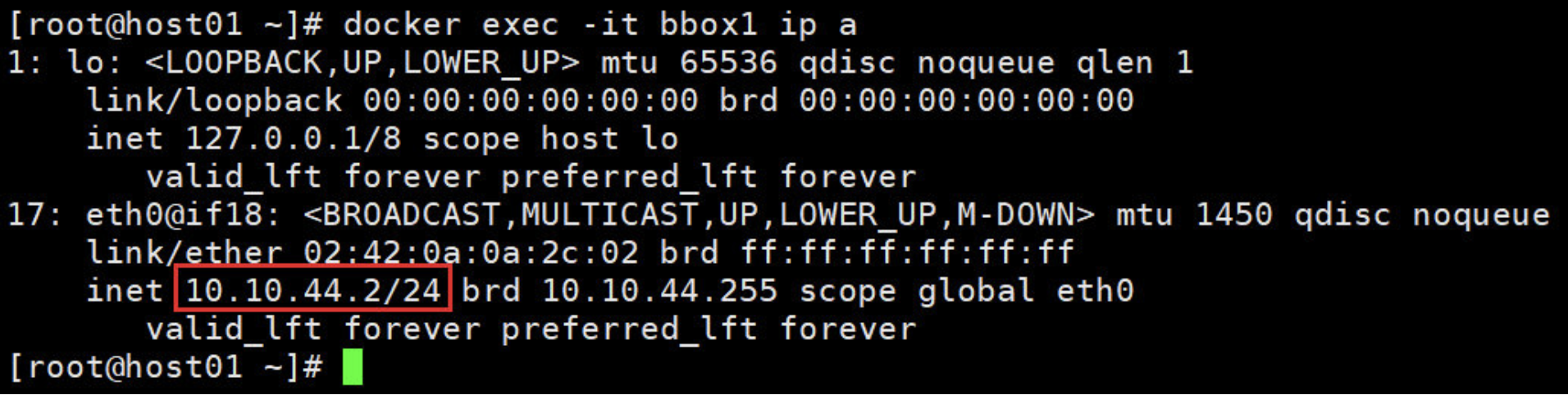
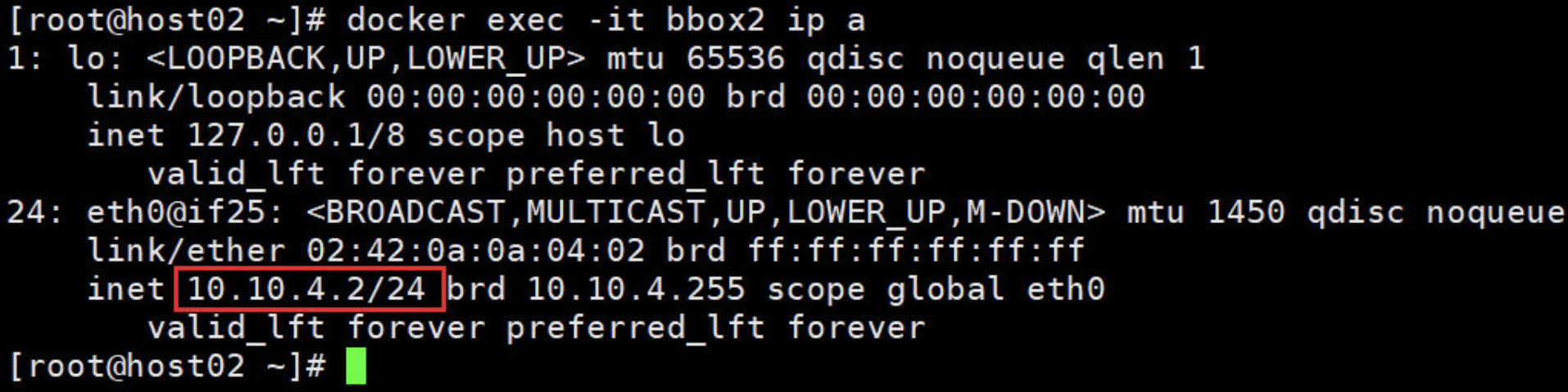
5、flannel 的连通与隔离
// flannel 网络连通性
# 测试 bbox1 和 bbxo2 的连通性
[root@host01 ~]# docker exec -it bbox1 ping 10.10.4.2
PING 10.10.4.2 (10.10.4.2): 56 data bytes
64 bytes from 10.10.4.2: seq=0 ttl=62 time=5.525 ms
64 bytes from 10.10.4.2: seq=1 ttl=62 time=1.147 ms
64 bytes from 10.10.4.2: seq=2 ttl=62 time=0.382 ms
[root@host02 ~]# docker exec -it bbox2 ping 10.10.44.2
PING 10.10.44.2 (10.10.44.2): 56 data bytes
64 bytes from 10.10.44.2: seq=0 ttl=62 time=5.771 ms
64 bytes from 10.10.44.2: seq=1 ttl=62 time=0.679 ms
64 bytes from 10.10.44.2: seq=2 ttl=62 time=0.435 ms
6、测试同一主机运行的容器能否通信,并验证上面所说的在同一主机运行的容器通信用的是不是docker0连接:
[root@host01 ~]# docker run -itd --name bbox3 busybox
d1e24edb54b1b080359ea9aa570f92f18f0be4340604f7e313b77c85270ba7d1
[root@host01 ~]# docker exec -it bbox3 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
19: eth0@if20: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:0a:2c:03 brd ff:ff:ff:ff:ff:ff
inet 10.10.44.3/24 brd 10.10.44.255 scope global eth0
valid_lft forever preferred_lft forever
[root@host01 ~]# docker exec -it bbox3 ping 10.10.44.2 # 下面可以看到,同一主机之间的容器是能通信的。
PING 10.10.44.2 (10.10.44.2): 56 data bytes
64 bytes from 10.10.44.2: seq=0 ttl=64 time=0.106 ms
64 bytes from 10.10.44.2: seq=1 ttl=64 time=0.046 ms
64 bytes from 10.10.44.2: seq=2 ttl=64 time=0.048 ms
7、使用 traceroute分析一下 bbox1 到 bbox3
[root@host01 ~]# docker exec -it bbox1 traceroute 10.10.4.3

[root@host01 ~]# docker exec -it bbox3 ip route #查看容器的默认路由是谁

[root@host01 ~]# ifconfig docker0|grep netmask #查看docker0网络

可以看到,每个容器的默认路由都是docker0,所以这就可以证明上面所说是正确的。
另外,flannel 是没有 DNS 服务的,容器无法通过 hostname 通信。
8、数据流向如图所示
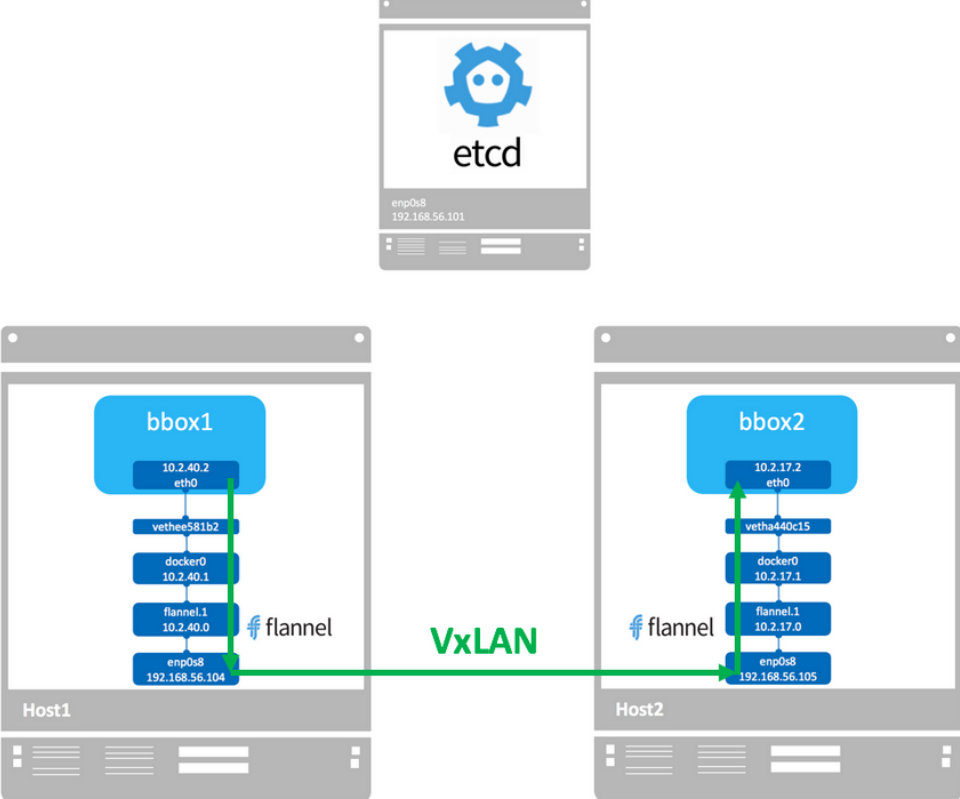
9、flannel与外网连通性
因为 flannel 网络利用的是默认的 bridge 网络,所以容器与外网的连通方式与 bridge 网络一样,即:
-
容器通过 docker0 NAT 访问外网
-
通过主机端口映射,外网可以访问容器
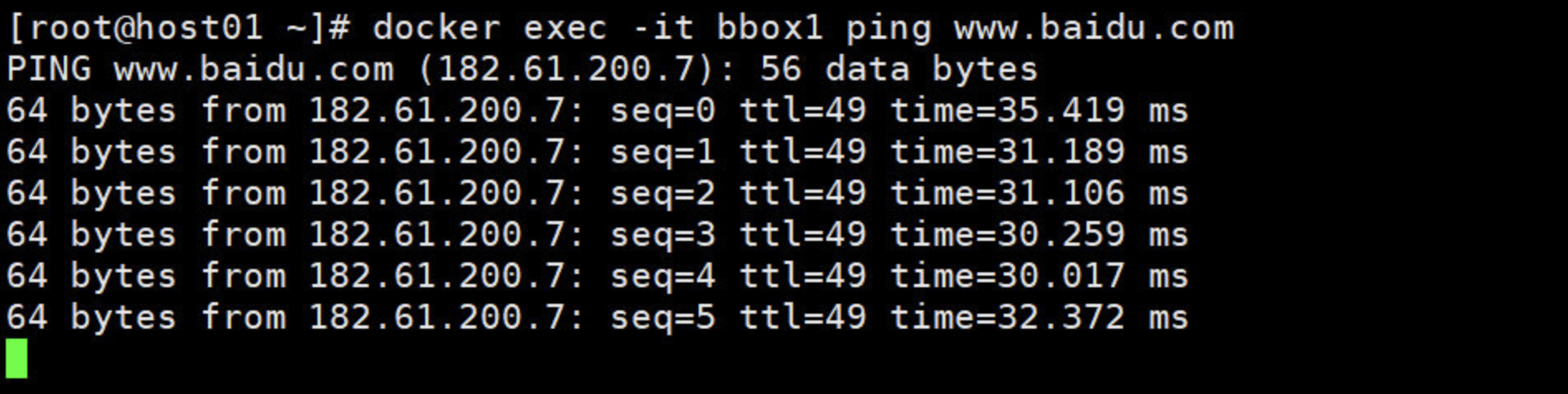
10、总结 flannel 实现的功能
- 单主机容器之间互相通信
- 多主机容器之间互相通信
- Flannel网络容器访问外网源地址转换
- Flannel网络外部访问容器内部端口映射
11、如何使用 flannel backend host-gw(推荐使用)
flannel 支持多种 backend,前面我们讨论的是 vxlan,host-gw 是 flannel 的另一个 backend,这次会将前面的 vxlan backend 切换成 host-gw。
与 vxlan 不同,host-gw 不会封装数据包,而是在主机的路由表中创建到其他主机 subnet 的路由条目,从而实现容器跨主机通信。
# 要使用 host-gw 首先修改 flannel 的配置 config.json
[root@etcd ~]# vim config.json
{
"Network": "10.10.0.0/16",
"SubnetLen": 24,
"Backend": {
"Type": "host-gw"
}
}
# Type 用 host-gw 替换原先的 vxlan。更新 etcd 数据库
[root@etcd ~]# etcdctl --endpoints=192.168.2.3:2379 set /docker-test/network/config < config.json
{
"Network": "10.10.0.0/16",
"SubnetLen": 24,
"Backend": {
"Type": "host-gw"
}
}
# 将之前 host1 和 host2 的容器删除 并把放在后台的flanneld 进程杀死
docker rm -f $(docker ps -qa)
kill -9 pid
# 启动host01 和 host02 flannel
[root@host01 ~]# setsid flanneld -etcd-endpoints=http://192.168.2.3:2379 -iface=ens32 -etcd-prefix=/docker-test/network
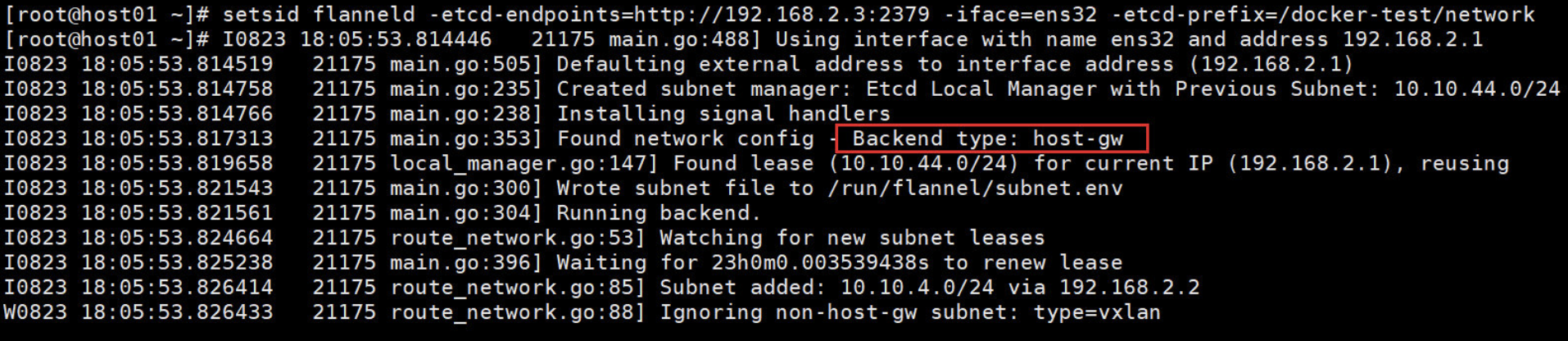
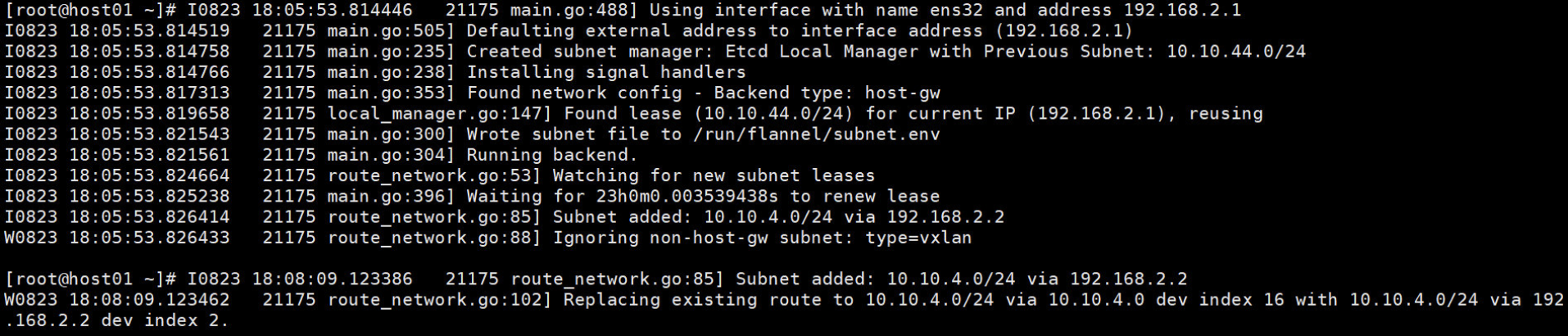
与之前 vxlan backend 启动时有几点不同:
① flanneld 检查到原先已分配的 subnet 10.10.44.0/24,重用之。
② flanneld 从 etcd 数据库中检索到 host1 的 subnet 10.10.44.0/24,但因为其 type=vxlan,立即忽略。
③ 两分钟后,再次发现 subnet 10.10.4.0/24,将其加到路由表中。这次没有忽略 subnet 的原因是此时我们在 host2 上重启了 flanneld,根据当前 etcd 的配置使用 host-gw backend。
查看 host1 的路由表,增加了一条到 10.10.44.0/24 的路由,网关为 host2 的IP 192.168.2.2。 类似的,host2 启动 flanneld 时会重用 subnet 10.10.4.0/24,并将 host1的subnet 10.10.44.0/24 添加到路由表中,网关为 host1 IP 192.168.2.1。


从 /run/flannel/subnet.env 可以看到 host-gw 使用的 MTU 为 1500:
cat /run/flannel/subnet.env|grep FLANNEL_MTU


这与 vxlan MTU=1450 不同,所以应该修改 docker 启动参数 --mtu=1500并重启 docker daemon:


systemctl daemon-reload && systemctl restart docker
在host01 和 host02 启动容器
[root@host01 ~]# docker run -itd --name bbox1 busybox
[root@host01 ~]# docker exec -it bbox1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
21: eth0@if22: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:0a:2c:02 brd ff:ff:ff:ff:ff:ff
inet 10.10.44.2/24 brd 10.10.44.255 scope global eth0
valid_lft forever preferred_lft forever
[root@host02 ~]# docker run -itd --name bbox2 busybox
[root@host02 ~]# docker exec -it bbox2 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
26: eth0@if27: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:0a:04:02 brd ff:ff:ff:ff:ff:ff
inet 10.10.4.2/24 brd 10.10.4.255 scope global eth0
valid_lft forever preferred_lft forever
测试通信
[root@host01 ~]# docker exec -it bbox1 ping www.baidu.com
PING www.baidu.com (182.61.200.7): 56 data bytes
64 bytes from 182.61.200.7: seq=0 ttl=49 time=38.791 ms
64 bytes from 182.61.200.7: seq=1 ttl=49 time=35.257 ms
64 bytes from 182.61.200.7: seq=2 ttl=49 time=32.473 ms
[root@host01 ~]# docker exec -it bbox1 ping 10.10.4.2
PING 10.10.4.2 (10.10.4.2): 56 data bytes
64 bytes from 10.10.4.2: seq=0 ttl=62 time=5.756 ms
64 bytes from 10.10.4.2: seq=1 ttl=62 time=0.358 ms
64 bytes from 10.10.4.2: seq=2 ttl=62 time=0.337 ms
[root@host02 ~]# docker exec -it bbox2 ping 10.10.44.2
PING 10.10.44.2 (10.10.44.2): 56 data bytes
64 bytes from 10.10.44.2: seq=0 ttl=62 time=6.262 ms
64 bytes from 10.10.44.2: seq=1 ttl=62 time=0.365 ms
64 bytes from 10.10.44.2: seq=2 ttl=62 time=0.385 ms
12、下面对 host-gw 和 vxlan 这两种 backend 做个简单比较
-
host-gw 把每个主机都配置成网关,主机知道其他主机的 subnet 和转发地址。vxlan 则在主机间建立隧道,不同主机的容器都在一个大的网段内(比如 10.2.0.0/16)。
-
虽然 vxlan 与 host-gw 使用不同的机制建立主机之间连接,但对于容器则无需任何改变,bbox1 仍然可以与 bbox2 通信。
-
由于 vxlan 需要对数据进行额外打包和拆包,性能会稍逊于 host-gw。
十、Docker 的两类存储类型
Docker 为容器提供了两种存放数据的资源:
- storage driver 存储驱动 管理的镜像层和容器层。
- Data Volume 数据卷 挂载点
1. storage driver
下面是ubuntu:15.04的镜像分层.一共是4层,每一层都由一些只读并且描绘系统区别的文件组成. 也可以使用命令 docker history ubuntu:15.04查看。
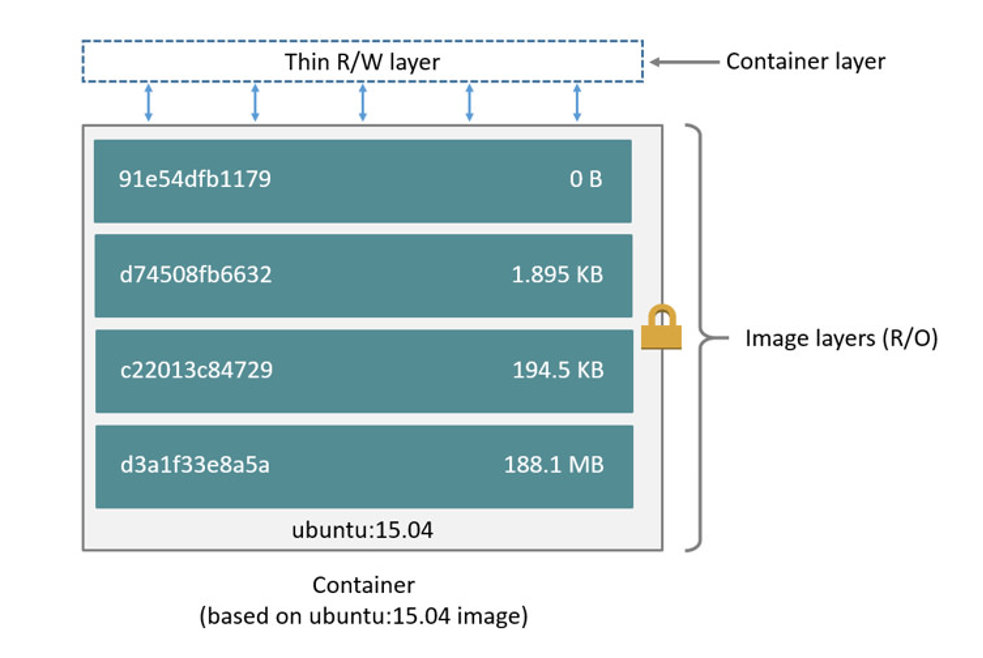
容器由最上面一个可写的容器层,以及若干只读的镜像层组成,容器的数据就存放在这些层中。
这样的分层结构最大的特性是 Copy-on-Write:
- 新数据会直接存放在最上面的容器层。
- 如果多个层中有命名相同的文件,用户只能看到最上面那层中的文件。
- 修改现有数据会先从镜像层将数据复制到容器层,修改后的数据直接保存在容器层中,镜像层保持不变。
分层结构使镜像和容器的创建、共享以及分发变得非常高效,而这些都要归功于 Docker storage driver。正是 storage driver 实现了多层数据的堆叠并为用户提供一个单一的合并之后的统一视图。
Docker 支持多种 storage driver,有 AUFS、Device Mapper、Btrfs、OverlayFS、VFS 和 ZFS。它们都能实现分层的架构,同时又有各自的特性。对于 Docker 用户来说,具体选择使用哪个 storage driver 是一个难题,因为:
- 没有哪个 driver 能够适应所有的场景。
- driver 本身在快速发展和迭代。
不过 Docker 官方给出了一个简单的答案:
- 优先使用 Linux 发行版默认的 storage driver。
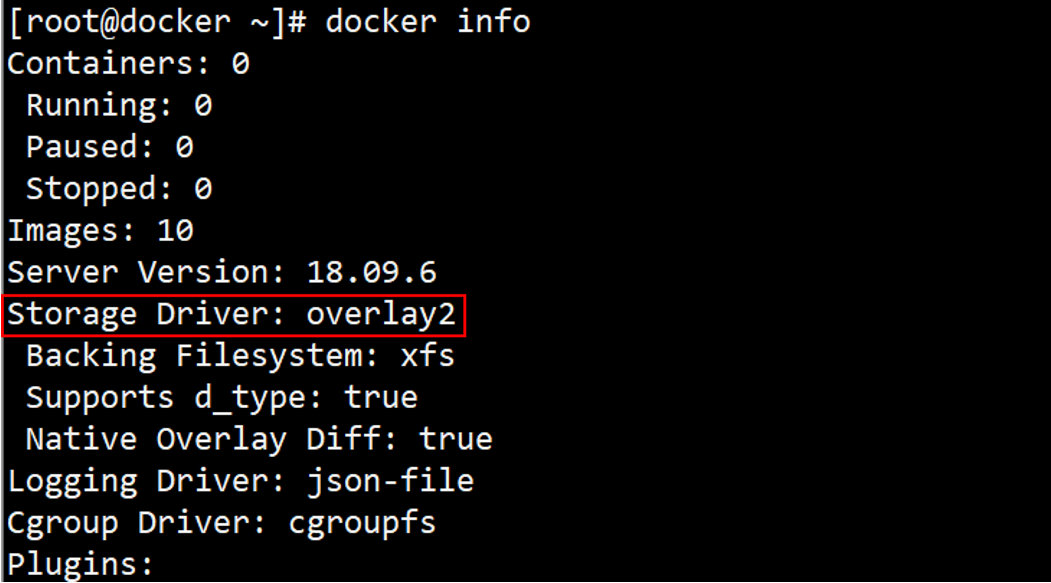
Centos7 用的 overlay2,底层文件系统是 xfs,各层数据存放在 /var/lib/docker。
对于某些容器,直接将数据放在由 storage driver 维护的层中是很好的选择,比如那些无状态的应用。无状态意味着容器没有需要持久化的数据,随时可以从镜像直接创建。
一句话描述:storage driver 就是将应用或数据打包到镜像层里,从而启动容器后直接使用。
比如 busybox镜像,它是一个工具箱,我们启动 busybox 是为了执行诸如 wget,ping 之类的命令,不需要保存数据供以后使用,使用完直接退出,容器删除时存放在容器层中的工作数据也一起被删除,这没问题,下次再启动新容器即可。
但对于另一类应用这种方式就不合适了,它们有持久化数据的需求,容器启动时需要加载已有的数据,容器销毁时希望保留产生的新数据,也就是说,这类容器是有状态的。
一句话描述:就是容器中的数据不会随着容器的删除而被删除,这一类数据需要持久化
这就要用到 Docker 的另一种存储机制:Data Volume
2. Data Volume
storage driver 和 data volume 是容器存放数据的两种方式,上一节学习了 storage driver,本节开始讨论 Data Volume。
Data Volume 本质上是 Docker Host 文件系统中的目录或文件,能够直接被 mount 到容器的文件系统中。
Data Volume 有以下特点:
-
Data Volume 是目录或文件,是格式化的磁盘(块设备)。
-
容器可以读写 volume 中的数据。
-
volume 数据可以被永久的保存,即使使用它的容器已经销毁。
思考:现在有driver 和 volume 都可以用来存放数据,具体使用的时候要怎样选择呢?考虑下面几个场景:
- Database 软件 vs Database 数据
- Web 应用 vs 应用产生的日志
- 数据分析软件 vs input/output 数据
- Apache Server vs 静态 HTML 文件
相信大家会做出这样的选择:
- 前者放在driver中。因为这部分内容是无状态的,应该作为镜像的一部分。
- 后者放在 Data Volume 中。这是需要持久化的数据,并且应该与镜像分开存放。
还有个比较关心的问题:如何设置 voluem 的容量?
- 因为 volume 实际上是 docker host 文件系统的一部分,所以 volume 的容量取决于文件系统当前未使用的空间,目前还没有方法设置 volume 的容量。
docker 提供了两种类型的
- volume:bind mount
- docker managed volume。
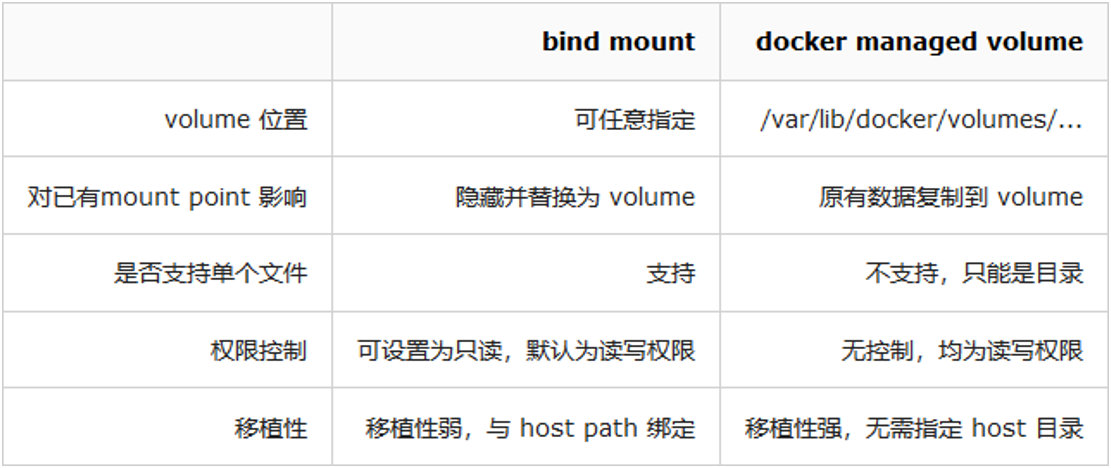
这两种类型最大的区别就是:bind mount是将宿主机的目录数据共享给容器,而docker managed volume是相反的
bind mount
bind mount 是将 host 上已存在的目录或文件 mount 到容器。
例如 docker host 上有目录 /htdocs:

通过 -v 将其 mount 到 httpd 容器的网页存放路径:

-v 的格式为 <host path>:<container path>。/usr/local/apache2/htdocs 就是 apache server 存放静态文件的地方。
由于 /usr/local/apache2/htdocs 已经存在,原有数据会被隐藏起来,取而代之的是 host /htdocs/ 中的数据,这与 linux mount 命令的行为是一致的。

curl 显示当前的主页确实是 /htdocs/index.html 中的内容。
更新一下,看是否能生效:

host 中的修改确实生效了,bind mount 可以让 host 与容器共享数据。这在管理上是非常方便的。
下面将容器销毁,看看对 bind mount 有什么影响:
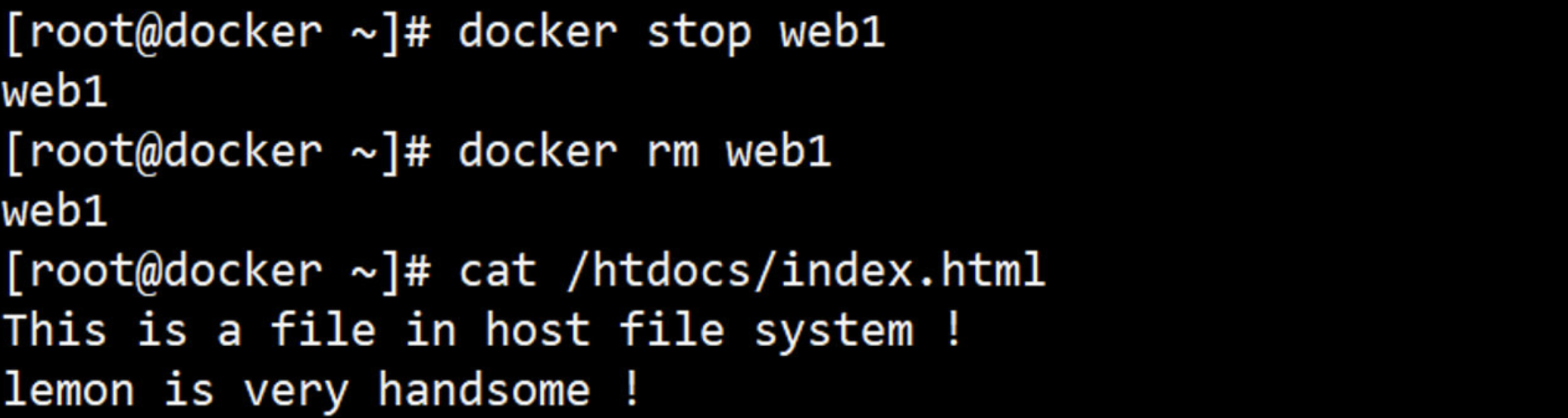
可见,即使容器没有了,bind mount 也还在。这也合理,bind mount 是 host 文件系统中的数据,只是借给容器用用,哪能随便就删了啊。
另外,bind mount 时还可以指定数据的读写权限,默认是可读可写,可指定为只读:

ro 设置了只读权限,在容器中是无法对 bind mount 数据进行修改的。只有 host 有权修改数据,提高了安全性。
除了 bind mount 目录,还可以单独指定一个文件:

使用 bind mount 单个文件的场景:只需要向容器添加文件,不希望覆盖整个目录。在上面的例子中,将 html 文件加到 apache 中,同时也保留了容器原有的数据。
使用单一文件有一点要注意:host 中的源文件必须要存在,不然会当作一个新目录 bind mount 给容器。
mount point 有很多应用场景,比如我们可以将源代码目录 mount 到容器中,在 host 中修改代码就能看到应用的实时效果。再比如将 mysql 容器的数据放在 bind mount 里,这样 host 可以方便地备份和迁移数据。
bind mount 的使用直观高效,易于理解,但它也有不足的地方:bind mount 需要指定 host 文件系统的特定路径,这就限制了容器的可移植性,当需要将容器迁移到其他 host,而该 host 没有要 mount 的数据或者数据不在相同的路径时,操作会失败。
docker managed volume
docker managed volume 与 bind mount 在使用上的最大区别是不需要指定 mount 源,指明 mount point 就行了。
他分为两种挂在:
- 匿名挂载 —> 格式:
docker run -itd -v volumePath image:latest- 具名挂在 —> 格式:
docker run -itd -v 目录名称:volumePath image:latest
还是以 httpd 容器为例:

通过 -v 告诉 docker 需要一个 data volume,并将其 mount 到 /usr/local/apache2/htdocs。那么这个 data volume 具体在哪儿呢?这个答案可以在容器的配置信息中找到,执行 docker inspect 命令:

docker inspect 的输出很多,现在 只看 Mounts 这部分,这里会显示容器当前使用的所有 data volume,包括 bind mount 和 docker managed volume。
Source 就是该 volume 在 host 上的目录。
每当容器申请 mount manged volume时, docker 都会在/var/lib/docker/volumes下生成一个目录,这个目录就是 mount 源。
下面继续研究这个 volume,看看里面有些什么东西:

volume 的内容跟容器原有 /usr/local/apache2/htdocs 完全一样,这是怎么回事呢?
这是因为:如果 mount point 指向的是已有目录,原有数据会被复制到 volume 中。
但要明确一点:此时的 /usr/local/apache2/htdocs 已经不再是由 storage driver 管理的层数据了,它已经是一个 data volume。
现在可以像 bind mount 一样对数据进行操作,例如更新数据:

简单回顾一下 docker managed volume 的创建过程:
-
容器启动时,简单的告诉 docker "我需要一个 volume 存放数据,帮我 mount 到目录 /abc"。
-
docker 在 /var/lib/docker/volumes 中生成一个随机目录作为 mount 源。
-
如果 /abc 已经存在,则将数据复制到 mount 源,
-
将 volume mount 到 /abc
除了通过 docker inspect 查看 volume,我们也可以用 docker volume 命令:
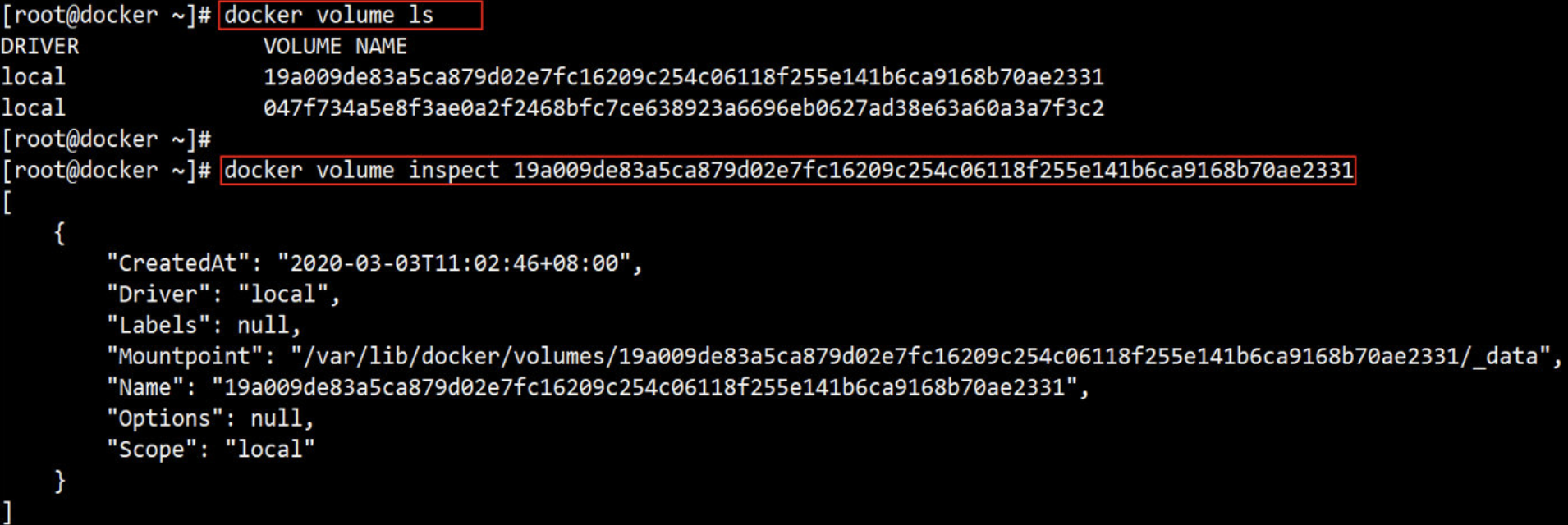
目前,docker volume 只能查看 docker managed volume,还看不到 bind mount;同时也无法知道 volume 对应的容器,这些信息还得靠docker inspect。
上面的就属于匿名挂在,能看到宿主机的目录名是很长的字串,非常不好记,那么就可以具名挂在volume了(推荐使用)
很简单,如下:
[root@docker ~]# docker run -itd --name web2 -p 88:80 -v html:/usr/local/apache2/htdocs httpd:latest
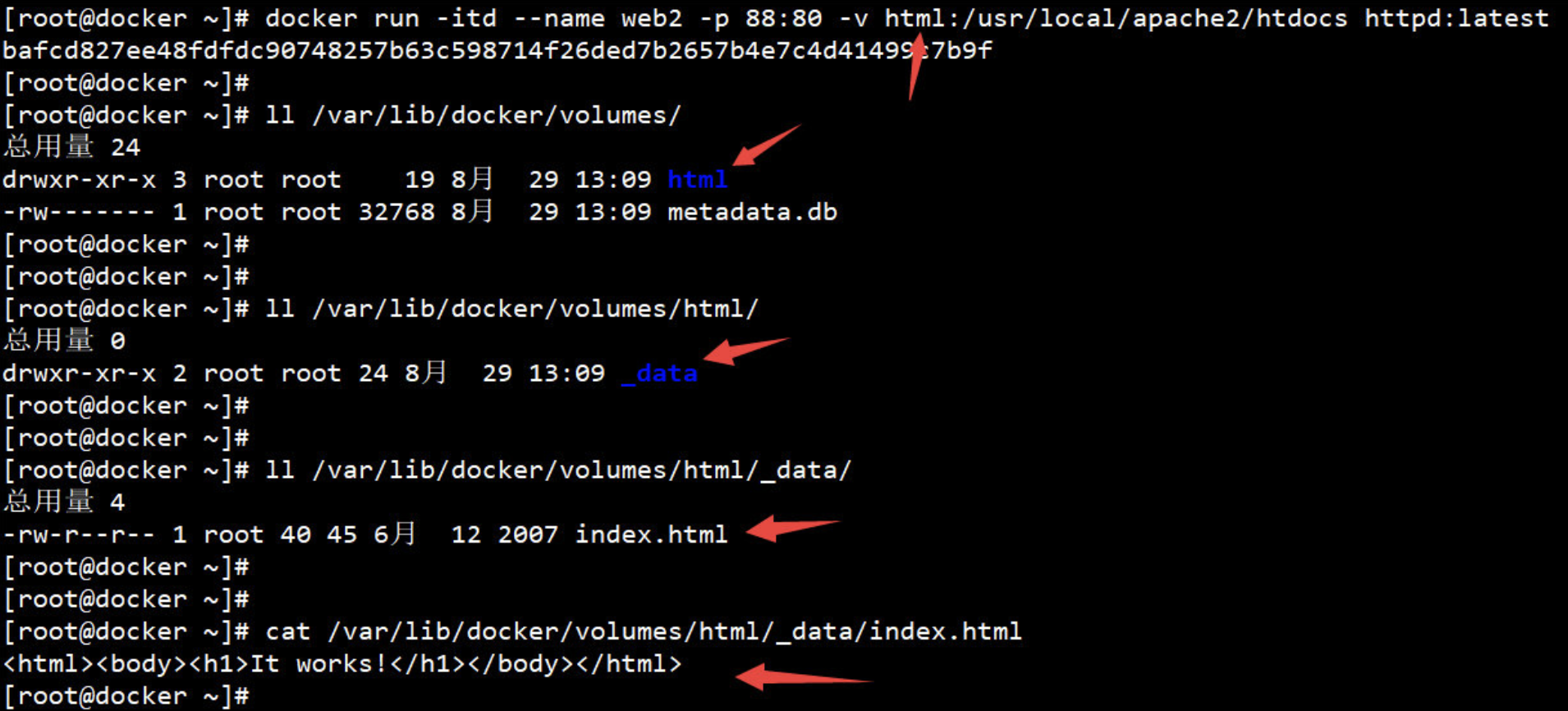
3. 如何共享数据?
数据共享是 volume 的关键特性,本节会详细讨论通过 volume 如何在容器与 host 之间,容器与容器之间共享数据。
bind mount 共享数据
第一种方法是将共享数据放在 bind mount 中,然后将其 mount 到多个容器。
还是以 httpd 为例,不过这次的场景复杂些,我们要创建由三个 httpd 容器组成的 web server 集群,它们使用相同的 html 文件。
操作如下:
1、将 /htdocs mount 到三个 httpd 容器。
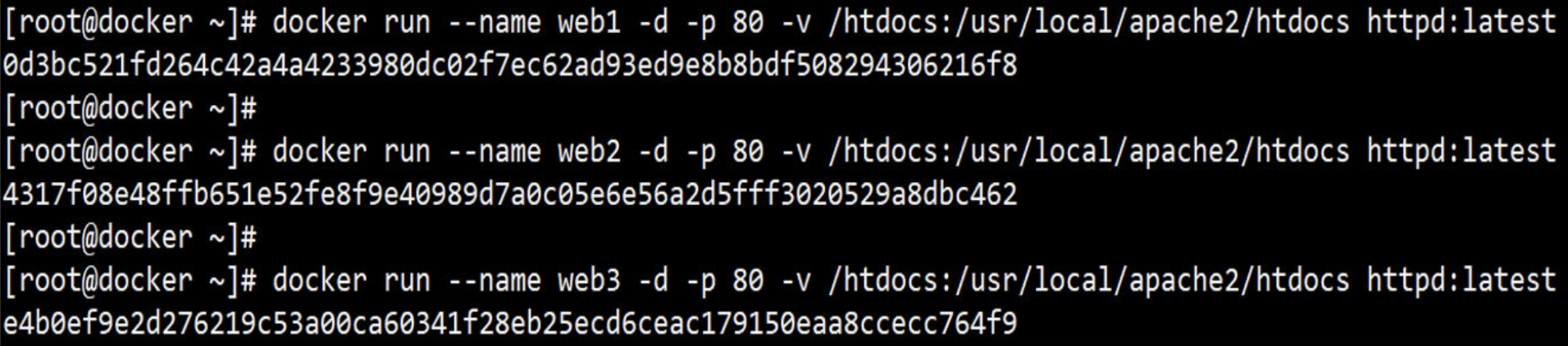
2、查看当前主页内容。
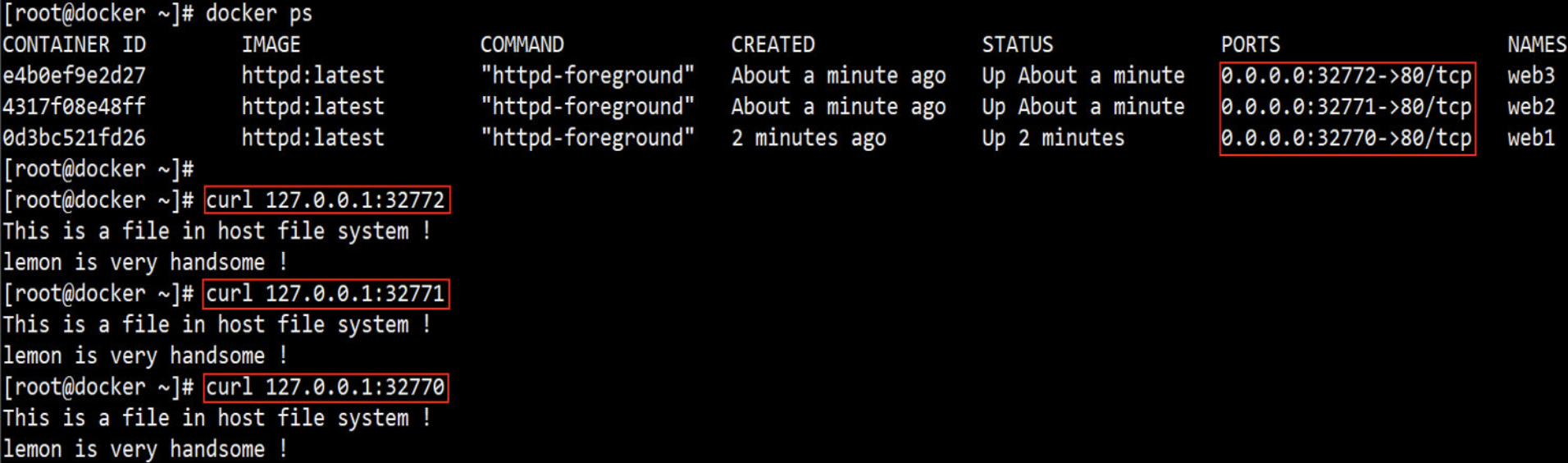
3、修改 volume 中的主页文件,再次查看并确认所有容器都使用了新的主页。
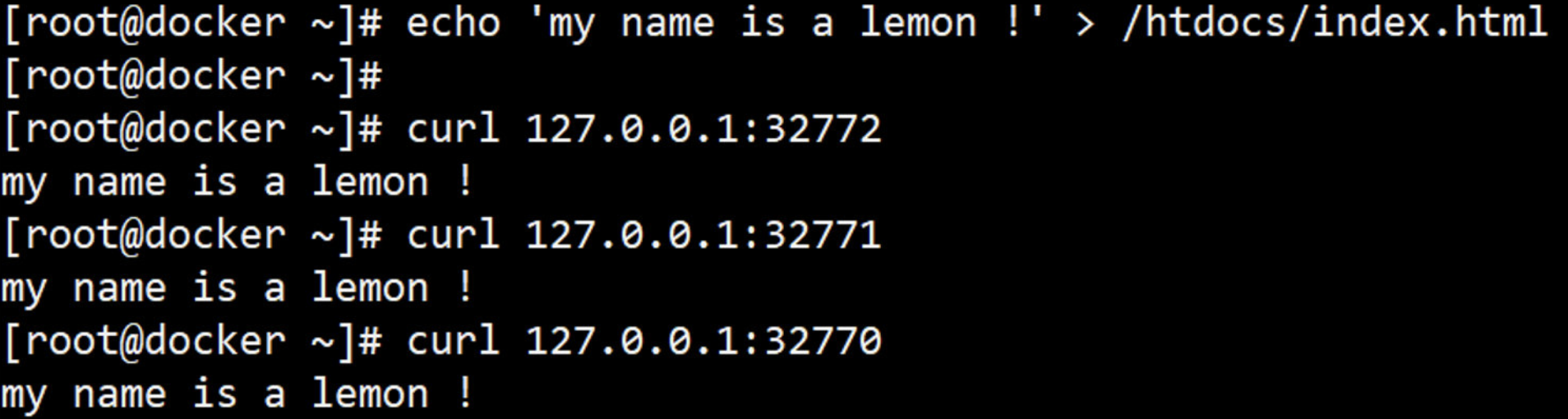
volume container 共享数据(容器卷)
第二种方法是 volume container ,专门为其他容器提供 volume 的容器,它提供的卷可以是 bind mount,也可以是 docker managed volume。
下面创建一个 volume container:
docker create --name vc_data -v /htdocs:/usr/local/apache2/htdocs -v /other/useful/tools busybox

这里将容器命名为 vc_data(vc 是 volume container 的缩写)。
这里执行的 docker create 命令,是因为 volume container 的作用只是提供数据,它本身不需要处于运行状态。
容器 mount 了两个 volume:
- bind mount,存放 web server 的静态文件。
- docker managed volume,存放一些实用工具(当然现在是空的,这只是做个示例)。
通过 docker inspect 可以查看到这两个 volume。
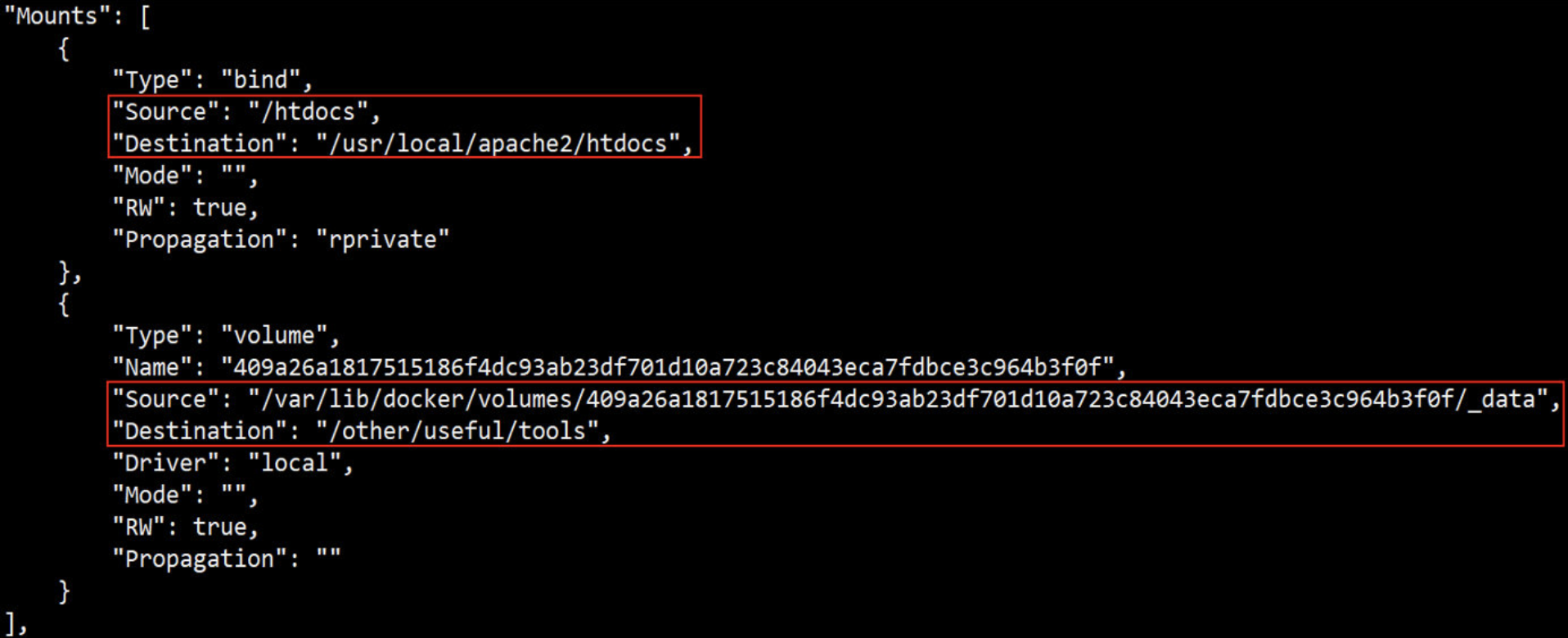
其他容器可以通过 --volumes-from 使用 vc_data 这个 volume container:
docker run --name web4 -d -p 80 --volumes-from vc_data httpd
docker run --name web5 -d -p 80 --volumes-from vc_data httpd
docker run --name web6 -d -p 80 --volumes-from vc_data httpd
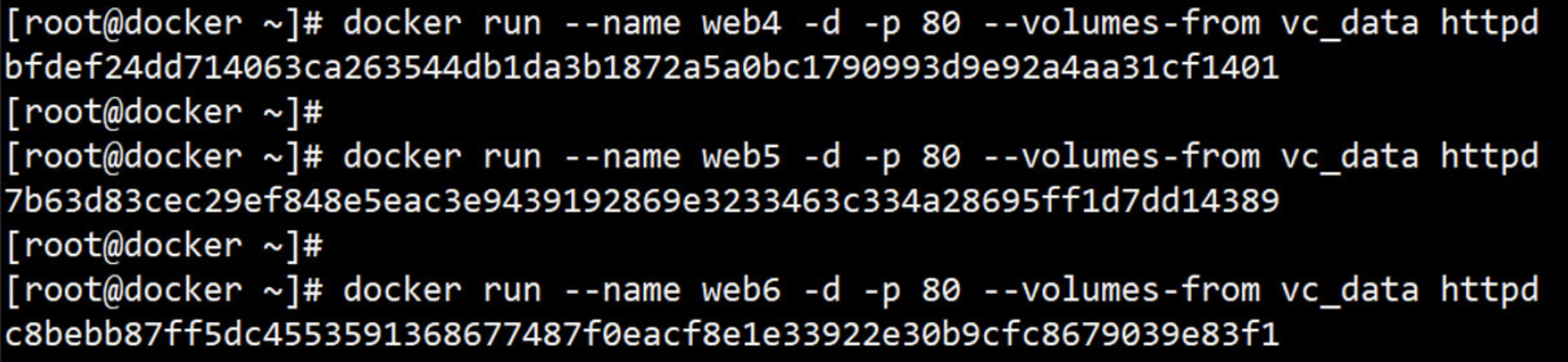
docker inspect web4
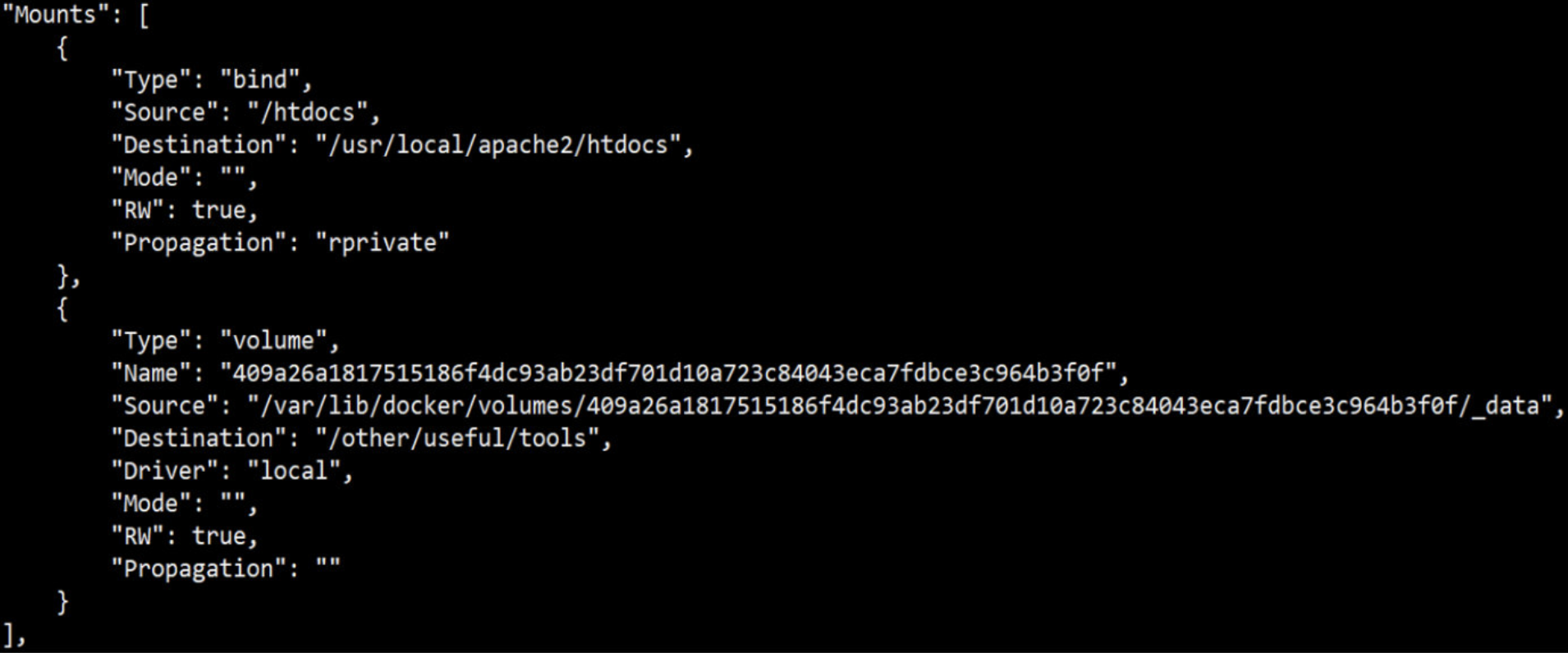
web4 容器使用的就是 vc_data 的 volume,而且连 mount point 都是一样的。
验证一下数据共享的效果:
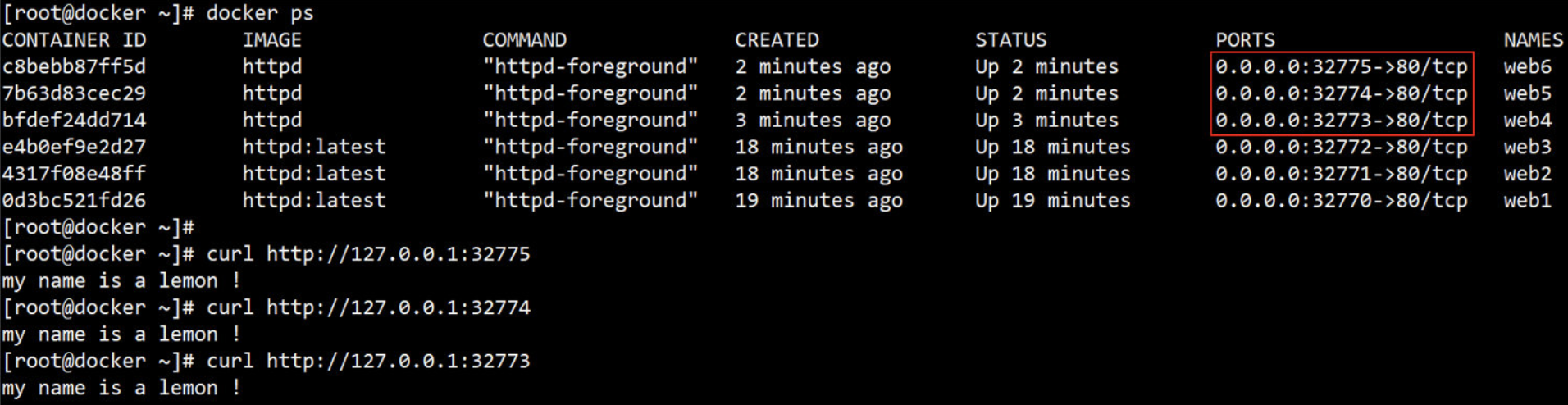
可见,三个容器已经成功共享了 volume container 中的 volume。
下面我们讨论一下 volume container 的特点:
-
与 bind mount 相比,不必为每一个容器指定 host path,所有 path 都在 volume container 中定义好了,容器只需与 volume container 关联,实现了容器与 host 的解耦。
-
使用 volume container 的容器其 mount point 是一致的,有利于配置的规范和标准化,但也带来一定的局限,使用时需要综合考虑。
data-packed volume container 共享数据
上面的两个方法其实都是宿主机和容器之间的volume共享,而这次的方法就属于容器与容器之间的容器共享
上面例子中 volume container 的数据归根到底还是在 host 里,有没有办法将数据完全放到 volume container 中,同时又能与其他容器共享呢?
当然可以! 通常简称这种容器为 data-packed volume container。
其原理是将数据打包到镜像中,然后通过 docker managed volume 共享。
用下面的 Dockfile 构建镜像:
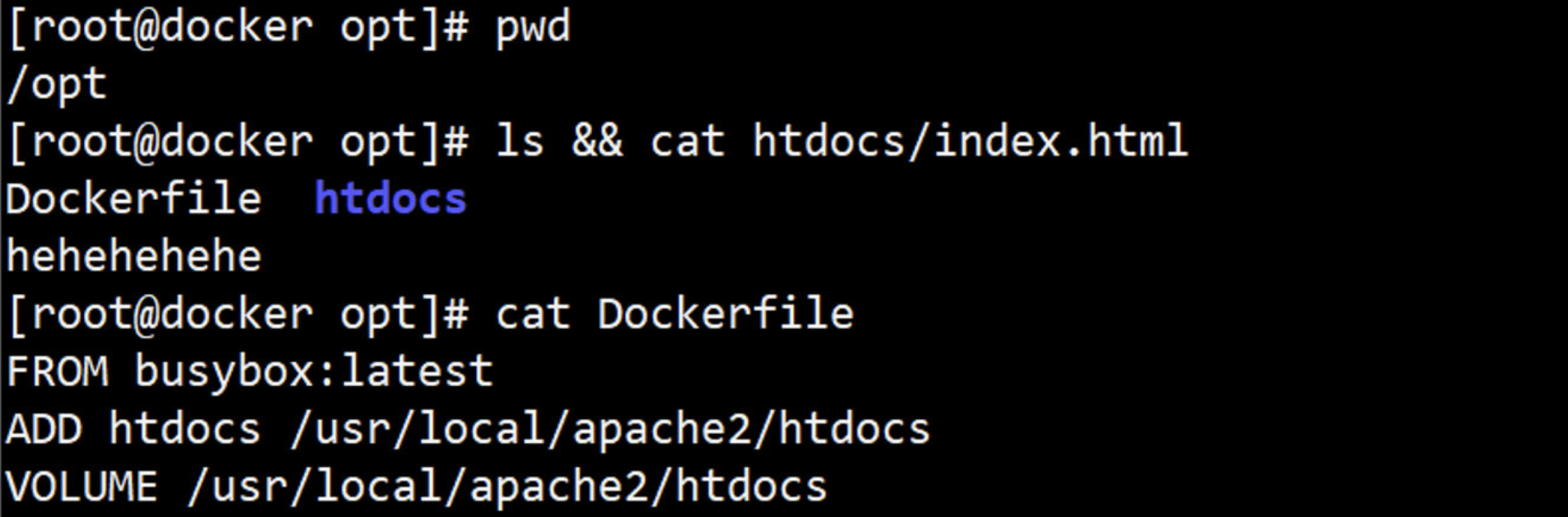
ADD 将静态文件添加到容器目录 /usr/local/apache2/htdocs。
VOLUME 的作用与 -v 等效,用来创建 docker managed volume,mount point 为 /usr/local/apache2/htdocs,因为这个目录就是 ADD 添加的目录,所以会将已有数据拷贝到 volume 中。
build 新镜像 datapacked:
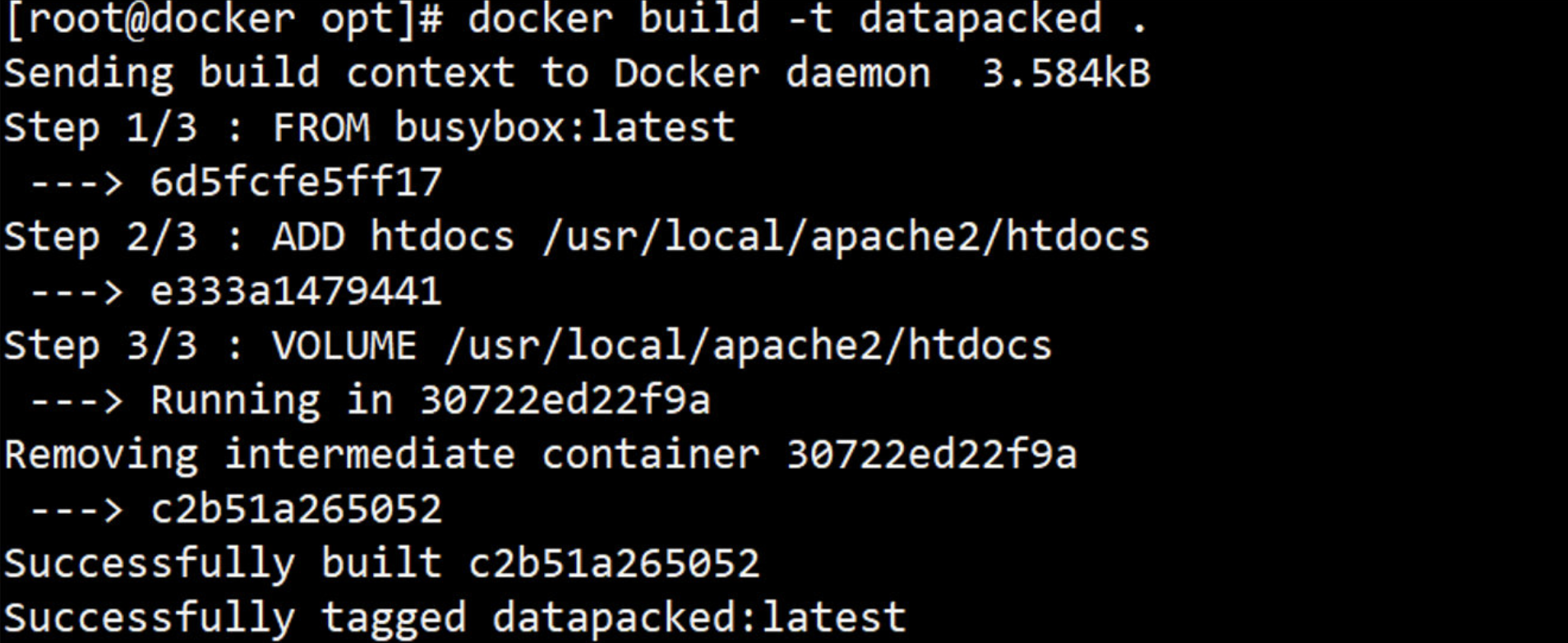
用新镜像创建 data-packed volume container:

因为在 Dockerfile 中已经使用了 VOLUME 指令,这里就不需要指定 volume 的 mount point 了。启动 httpd 容器并使用 data-packed volume container:
docker run -d -p 80 --name web7 --volumes-from vc_data2 httpd
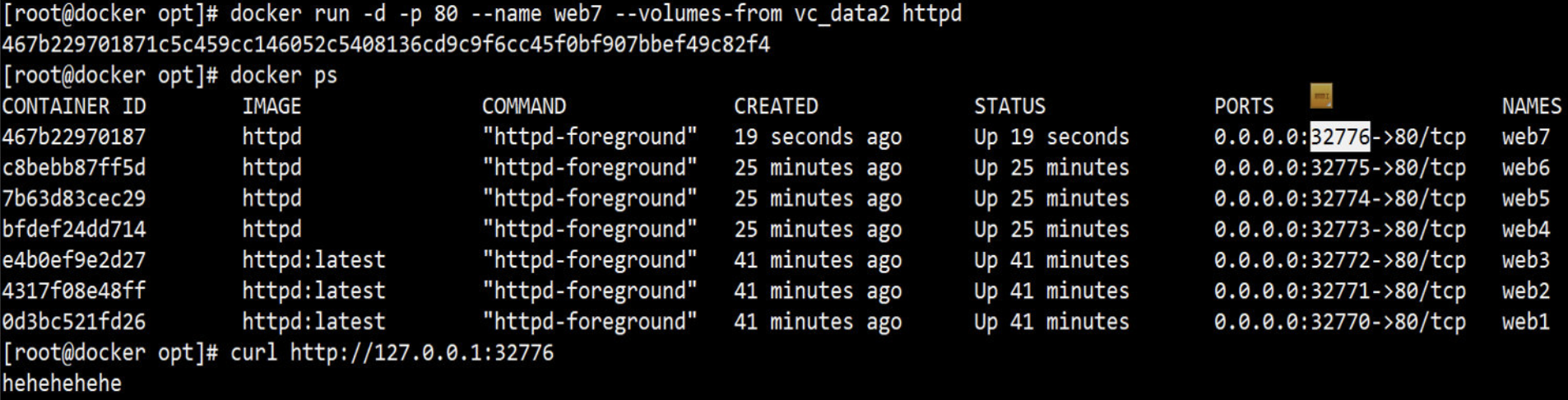
docker inspect web7

容器能够正确读取 volume 中的数据。data-packed volume container 是自包含的,不依赖 host 提供数据,具有很强的移植性,非常适合只使用静态数据的场景,比如应用的配置信息、web server 的静态文件等。
4. volume 生命周期管理
Data Volume 中存放的是重要的应用数据,如何管理 volume 对应用至关重要。前面主要关注的是 volume 的创建、共享和使用,本节将讨论如何备份、恢复、迁移和销毁 volume。
1. 备份
因为volume实际上是host 文件系统中的目录和文件,所以volume的备份实际上是对文件系统的备份。
还记得前面我们是如何搭建本地Registry 的吗?
docker run -d -p 5000:5000 -v /myregistry:/var/lib/registry registry:2
所有的本地镜像都存在host的 /myregistry 目录中,我们要做的就是定期备份这个目录。
2. 恢复
volume 的恢复也很简单,如果数据损坏了,直接用之前备份的数据拷贝到 /myregistry 就可以了。
3. 迁移
如果我们想使用更新版本的 Registry, 这就涉及到数据迁移,方法是:
docker stop 当前 Registry 容器
启动新版本容器并 mount 原有 volume。
docker run -d -p 5000:5000 -v /myregistry:/var/lib/registry registry:latest
当然,在启用新容器前要确保新版本的默认数据路径是否发生变化。
4. 销毁
可以删除不再需要的 volume,但一定要确保知道自己正在做什么,volume 删除后数据是找不回来的!!!
Docker不会销毁 bind mount,删除数据的工作只能由host负责。对于 docker managed volume,在执行 docker rm 删除容器时可以带上 -v 参数,docker 会将容器使用到的 volume一并删除,但前提是没有其他容器 mount 该 volume,目的是保护数据。
如果删除容器时没有带 -v 呢?
这样就会产生孤儿 volume,好在 docker 提供了 volume 子命令可以对 docker managed volume 进行维护。
请看下面的例子:
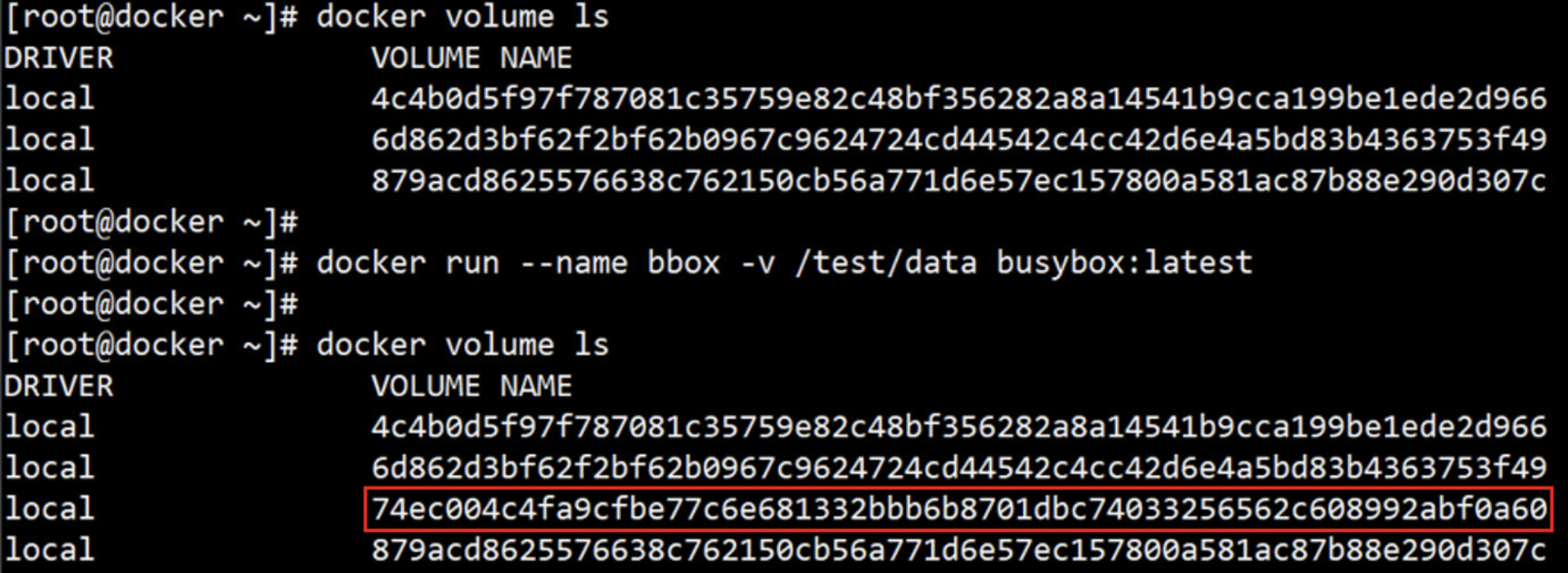
容器 bbox 使用的docker managed volume可以通过docker volume ls 查看到。
删除 bbox:
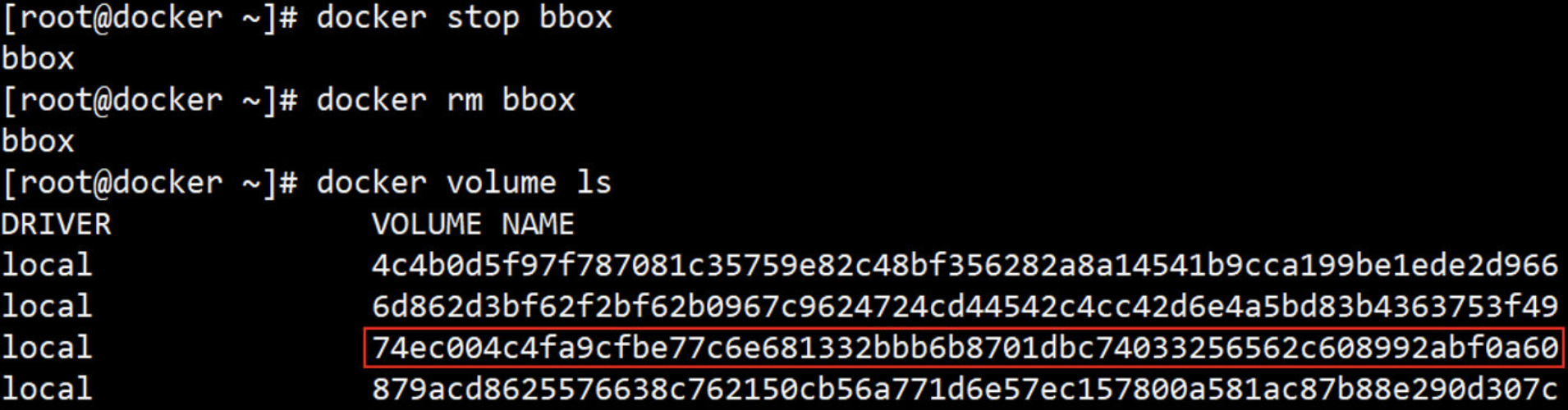
因为没有使用 -v,volume 遗留了下来。对于这样的孤儿 volume,可以用 docker volume rm 删除:
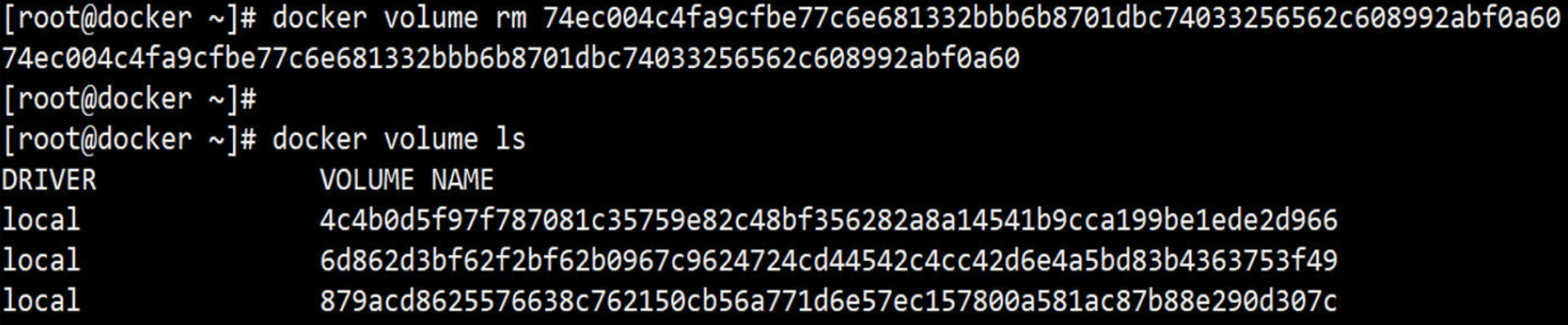
如果想批量删除孤儿 volume,可以执行:
docker volume rm $(docker volume ls -q)
5. 小结
本章学习了以下内容:
-
docker 为容器提供了两种存储资源:数据层和 Data Volume。
-
数据层包括镜像层和容器层,由 storage driver 管理。
-
Data Volume 有两种类型:bind mount 和 docker managed volume。
-
bind mount 可实现容器与 host 之间,容器与容器之间共享数据。
-
volume container 是一种具有更好移植性的容器间数据共享方案,特别是 data-packed volume container。
-
最后学习了如何备份、恢复、迁移和销毁 Data Volume。
这章我们学习的只是单个 docker host 中的存储方案。
而跨主机存储也是一个重要的主题,当然也更复杂,我们会在容器进阶技术章节详细讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号