SQL Server 堆表与栈表的对比(大表)
- 环境准备
使用1个表,生成1000万行来进行性能对比(勉强也算比较大了),对比性能差别。
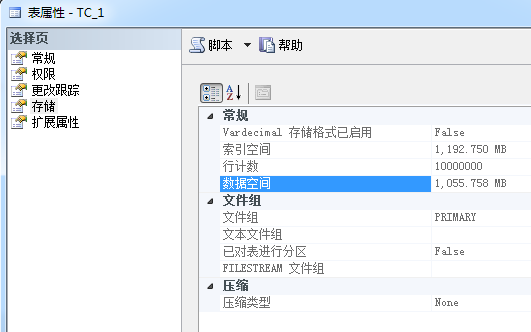
为了简化过程,不提供生成随机数据的过程。该表初始为非聚集索引(堆表),测试过程中会改为聚集索引(栈表)。
CREATE TABLE [dbo].[TC_1]( [sys_guid] [nvarchar](50) NOT NULL, -- 主键,非聚集索引 [valueF] [decimal](18, 2) NOT NULL, [valueN] [bigint] NOT NULL, [c] [bigint] IDENTITY(1,1) NOT NULL, [g] [int] NOT NULL, -- 1-4的随机整数,相当于随机分成4组(接近平均分) CONSTRAINT [PK_TC_1] PRIMARY KEY NONCLUSTERED ( [sys_guid] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO -- 先使用非聚集索引,再改为聚集索引进行相同查询 CREATE NONCLUSTERED INDEX [IX_TC_1_c] ON [dbo].[TC_1] ( [c] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO CREATE NONCLUSTERED INDEX [IX_TC_1_g] ON [dbo].[TC_1] ( [g] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
SELECT COUNT(*) FROM dbo.TC_1 SELECT TOP 10 * FROM dbo.TC_1
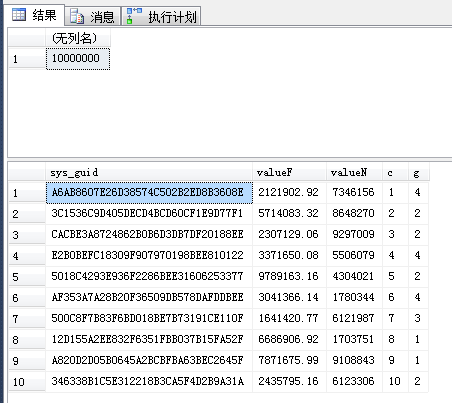
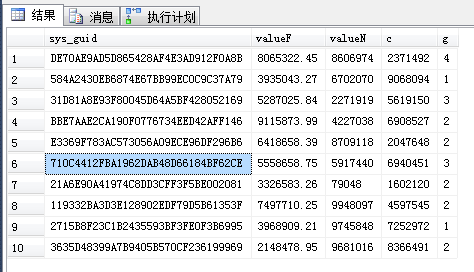
找出一行用于产生seek执行计划(用以下查询任挑一行):
SELECT TOP 10 * FROM dbo.TC_1 ORDER BY NEWID()
- 语句准备
-- 将c列的索引改为聚集索引的语句(时间会比较久): DROP INDEX IX_TC_1_c ON dbo.TC_1 GO CREATE CLUSTERED INDEX IX_TC_1_c ON dbo.TC_1 ( c ) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO
-- 清除缓存,每次测试前执行一下 CHECKPOINT DBCC DROPCLEANBUFFERS
比较以下几种常见的查询形式在堆表和栈表下的表现:
SELECT * FROM dbo.TC_1 WHERE c=6940451 -- 1.一般期望索引seek
SELECT * FROM dbo.TC_1 WHERE sys_guid=N'710C4412FBA1962DAB48D66184BF62CE' -- 2.一般期望索引seek
SELECT COUNT(*) FROM dbo.TC_1 -- 3.一般期望索引scan(基本不可能seek)
SELECT avg(valueF),avg(valueN) FROM dbo.TC_1 WHERE g = 1 GROUP BY g -- 4.一般只能是scan
- 进行测试
打开实际的执行计划和客户端统计信息,开始对比测试
运行以下语句打开时间和IO统计消息:
SET STATISTICS IO ON; SET STATISTICS TIME ON;
- 如何对比
执行时间与计算机整体状态有关,差别不大时我们不作为可靠结果去对比。由于我们总是清除缓存后再执行查询,因此读取次数是稳定的,这是对比的重点。
逻辑读与物理读,哪个更重要呢?
参考资料1 http://www.cnblogs.com/CareySon/archive/2011/12/23/2299127.html
参考资料2 http://www.canway.net/Original/shujuku/012CE2016.html
其中有一个结论:
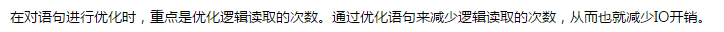
关于时间的对比,参考资料 http://www.cnblogs.com/xqhppt/p/4041799.html
其中有一个结论:

- 对比结果
红色√表示对比结果相对更好一点。
普通√表示可以或基本可以满足需求。
SELECT * FROM dbo.TC_1 WHERE c=6940451 -- 1.一般期望索引seek
| 堆表 | 栈表 | |
| 执行计划 | 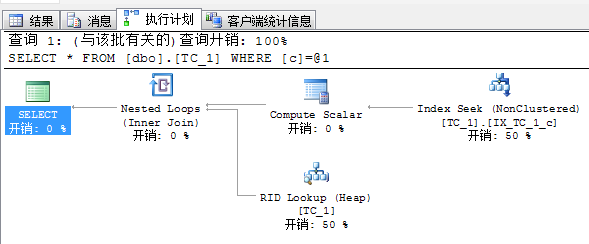 |
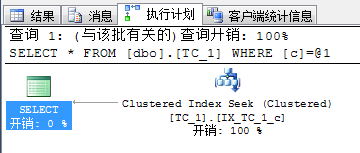 |
| 结果 |  |
 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 | 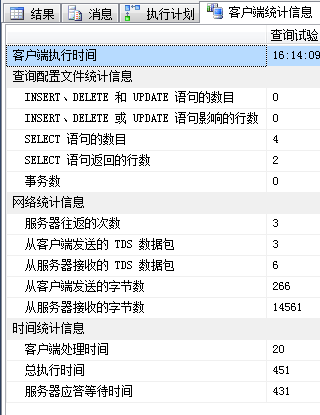 |
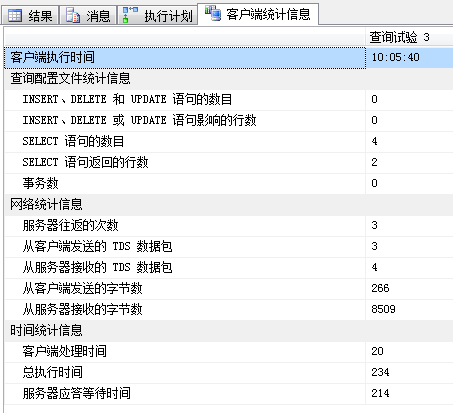 |
| 对比 | √ | √ |
| 栈表具有非常微弱的优势,这类查询一般只会返回很少的行,因此也可以认为差别不大。 | ||
SELECT * FROM dbo.TC_1 WHERE sys_guid=N'710C4412FBA1962DAB48D66184BF62CE' -- 2.一般期望索引seek
| 堆表 | 栈表 | |
| 执行计划 | 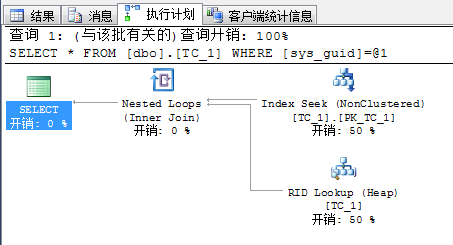 |
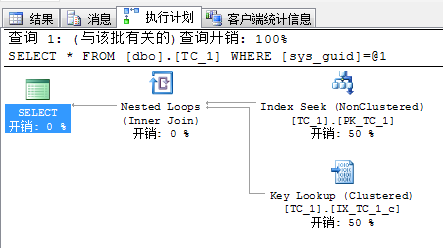 |
| 结果 |  |
 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 |  |
 |
| 对比 | √ | √ |
| 两者几乎一样。也可以认为堆表具有非常微弱的优势,因为栈表的逻辑读取次数略高于堆表。 | ||
SELECT COUNT(*) FROM dbo.TC_1 -- 3.一般期望索引scan(基本不可能seek)
| 堆表 | 栈表 | |
| 执行计划 |  |
 |
| 结果 | 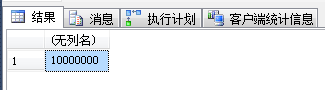 |
 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 |  |
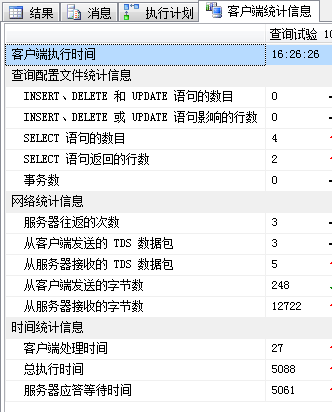 |
| 对比 | √ | √ |
| 可以认为基本没差别。 | ||
SELECT avg(valueF),avg(valueN) FROM dbo.TC_1 WHERE g = 1 GROUP BY g -- 4.一般只能是scan
| 堆表 | 栈表 | |
| 执行计划 |  |
 |
| 结果 | 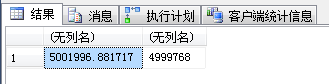 |
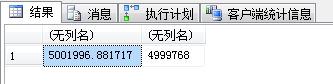 |
| 消息 |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
SQL Server 分析和编译时间: SQL Server 执行时间: (1 行受影响) (1 行受影响) SQL Server 执行时间: SQL Server 执行时间: |
| 客户端统计信息 | 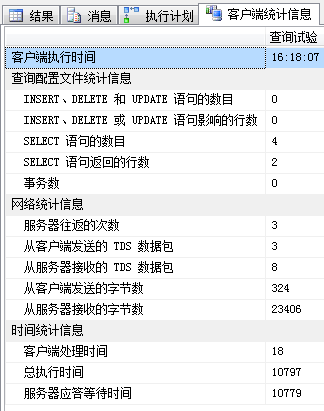 |
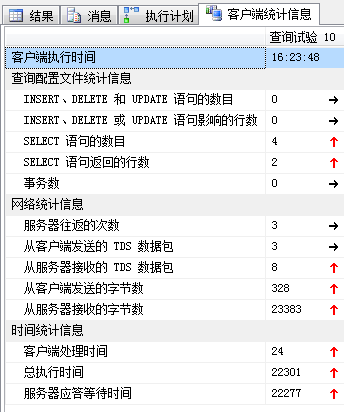 |
| 对比 | √ | √ |
| 堆表具有微弱优势(聚集索引扫描,实际上就等于表扫描了) | ||
- 结论
现实中大表的使用往往不可能只经过聚集索引去查找或统计,也往往会有多个索引,有些甚至高达20个以上的索引(这里不讨论其合理性)。
分两种情况讨论:
1.OLTP:一般认为以1、2、3三类语句为主,再考虑到高并发特点,还必须尽可能避免死锁,并提供一个可以接受的性能,从中找到一个比较满意的平衡点。由于若有修改聚集索引键会引起的所有非聚集索引更新,因此,可以认为栈表比堆表更有可能发生死锁(相同的写入操作涉及的索引可能更多),除非聚集索引是采用单向递增且永不更改的列,否则这将可能引起噩梦般的死锁频发。而堆表不存在某一个索引键修改就能引起其它所有索引的更新,可以认为其写入操作涉及的资源都是直接所需(相同的写入操作涉及的索引只是必需的范围),因此死锁的可能性相对更低。再看两者的性能表现差距,对于人类体验来说,大多数时候是感觉不到的。因此在OLTP系统中,为了减少死锁可能性,可以认为堆表更具有广泛适用性。
那么,栈表是否就没用了呢?答案当然是否定的。
如果能选择出一些单向递增且永不更改(或基本不会更改)的列,并且大部分查询也必须使用这些列作为条件(至少有一个必须的列),在这种情况下,使用满足这些条件的列作为聚集索引,并且选择这些列中使用率最高的一列作为聚集索引的第一列,这通常是会比堆表更好的。
只不过OLTP系统往往查询(包括读和写)是多样化的,避免死锁往往会更重要,因此,在不确定聚集索引是否合理时,使用堆表系统会更稳定;当然,性能上相应的可能会有所降低,只要在能接受的范围内,堆表可以说是更稳妥的选择。
2.OLAP:一般认为3、4两类语句的性能表现更重要,且不存在高并发写入操作(多是夜间定时批量更新)。在表扫描上,堆表反而具有微弱优势,这可能比较出人意料。我认为这应该是由于聚集索引扫描过程中需要访问更多的磁盘,因为聚集索引本身除了叶结点,还有B+树非叶结点的数据,而堆表相当于只有聚集索引的叶结点的数据,这导栈表扫描的致逻辑读和物理读比堆表扫描更高。但是除了扫描,更多的查询也一样是只需要索引seek就能查到结果,因此在OLAP系统,可以认为栈表更具有广泛适用性。
- 题外话
OLTP中的小表由于行数少,无论是栈表还是堆表,对于人类体验来说,区别一般都不会太大,往往是不可能感觉到的,因此不会成为关注的焦点,所以大多数小表可以认为无所谓;但如果存在频繁更新聚集索引键值且表上的索引总数也不少,同时还存在高并发,并且切实的导致了不少的死锁,则建议重新选择合适的聚集索引或使用堆表吧。
以上均以个人经验和测试结果得出的结论,欢迎大家拍砖指正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号