在Windows配置Spark环境
1、安装JDK
这里不再赘述。
2、安装Spark
到官网https://spark.apache.org/downloads.html选择合适的版本下载,注意Spark与Hadoop版本选择要相对应,建议下载预编译(Pre-built)好的版本,省得麻烦
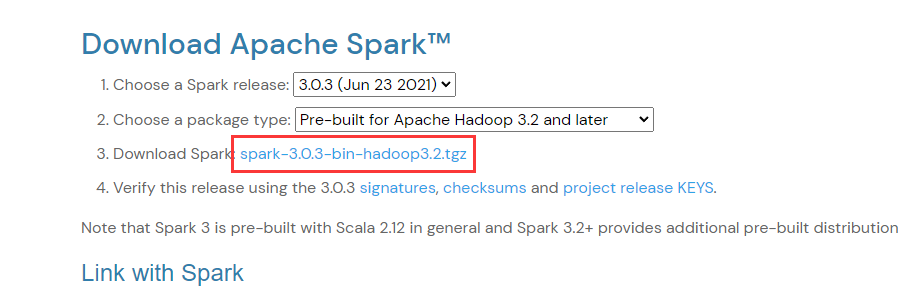
解压要需要的目录下,并配置环境变量SPARK_HOME以及在PATH下新增 %SPARK_HOME%\bin 和 %SPARK_HOME%\sbin
3、安装对应Spark版本的Hadoop
到官网https://hadoop.apache.org/releases.html下载与上边的Spark对应的版本。如上图所示,需要下载hadoop 3.2 。
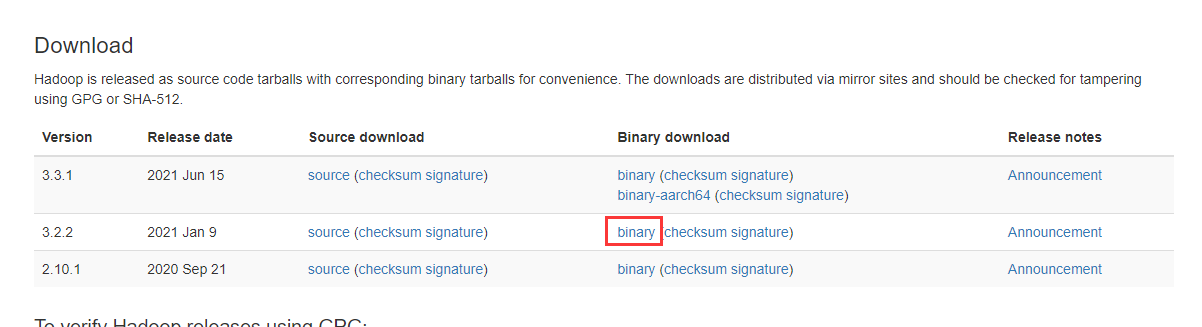
注意:不要把hadoop解压到带空格的目录中,比如常用的Program Files目录就识别不了。
解压并配置环境变量HADOOP_HOME以及在新增PATH下新增 %HADOOP_HOME%\bin 和 %HADOOP_HOME%\sbin
另外还需要配置环境变量 HADOOP_CONF_DIR =%HADOOP_HOME%\etc\hadoop
4、下载hadoop在windows下运行的工具
到这里https://github.com/cdarlint/winutils下载对应hadoop版本的工具,然后将其中的hadoop.dll和winutils.exe文件放入hadoop\bin目录下,并复制一份hadoop.dll放到C:\Windows\System32下。
最后,配置环境变量classpath:%HADOOP_HOME%\bin\winutils.exe,确保已经配置HADOOP_HOME。
5、验证Hadoop是否安装成功

这样就是安装成功了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号